Spark03-RDD01-简介+常用的Transformation算子
一、RDD的详解
1-1、为什么需要RDD
1. 背景:为什么不能直接用 Python 的 list 或 dict
你用 Python 的 list、dict 时,它们都存在你本地电脑的内存里,也就是说:
只能用 一台机器 的 CPU、内存来处理
数据量一大就撑爆内存
想并行处理时,需要你自己去写数据切分、网络传输、结果合并的代码,非常麻烦
但在 分布式计算 场景(比如 Spark),数据是分布在多台机器上的,我们要:
分区控制(决定数据放在哪台机器/哪个分区)
Shuffle 控制(需要把相同 key 的数据移动到同一个地方才能做统计)
存储 / 序列化 / 发送(数据要能跨网络发过去)
分布式计算 API(要能用简单的代码调用复杂的分布式操作)
这些功能,list、dict 根本帮不了你。
2. 引入 RDD:分布式世界的“超级 List”
RDD(Resilient Distributed Dataset) 就是 Spark 提供的一个统一的数据抽象,它就像一个“会自动帮你分布到多台机器、自动帮你计算的 List”。
你只需要:
rdd = sc.textFile("bigdata.txt") # 读取数据(分布在多台机器)
rdd2 = rdd.map(lambda x: x.upper()) # 转换
rdd3 = rdd2.filter(lambda x: "ERROR" in x) # 过滤
背后:
Spark 会自动把数据切成分区,分发到不同机器
在每台机器上执行你的
.map()、.filter()操作必要时自动触发 shuffle 来把数据重分组
结果也会分布式存储,不会占用一台机器的内存
你就像在用一个超级版的 list,但它帮你处理了所有分布式的麻烦事。
3. 一个类比:工厂流水线
想象你要加工 1 亿个零件:
list/dict = 你一个人坐在桌子前,手里有一堆零件,自己一个个加工(慢、累、放不下)
RDD = 你有一个大工厂(多台机器),有传送带(分区)、分拣机(shuffle)、加工机(map/filter),你只需要告诉工厂怎么加工,工厂就会帮你:
把零件分配到不同的加工站
把需要合并的零件送到同一地方
最终把结果送回来
你不关心每台机器怎么配合,你只需要定义加工规则(API)。
一句话总结
RDD 就是 Spark 提供的、为分布式计算量身打造的“超级集合”,它帮你隐藏了分区、网络传输、数据序列化、故障恢复等复杂细节,让你用本地集合一样的 API 就能在分布式环境中处理超大数据。
1-2、什么是RDD?

在 PySpark 里,RDD 其实就是“分布式的 Python list 集合”,每个 item 的类型没有限制,只要能被 序列化(序列化是为了跨节点传输)。
常见类型:
标量:
1,"hello"元组:
('a', 1)(很常见,尤其在 key-value 形式的算子里)列表:
[1, 2, 3]字典:
{'name': 'Alice', 'age': 20}自定义对象(比如自定义类的实例,只要可序列化就行)
1-3、RDD的五大特性

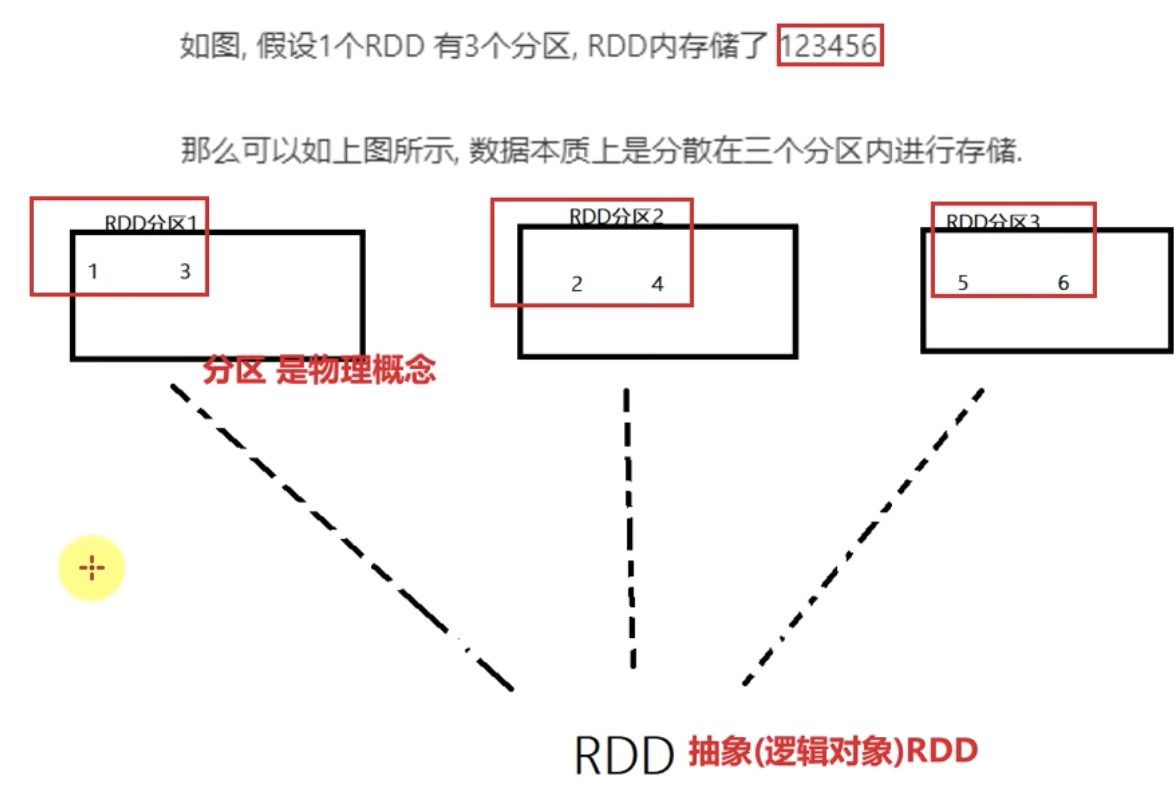
1、RDD是有分区的
RDD的分区是RDD数据存储的最小单位
一份RDD的数据,本质上就是分隔了多个分区。
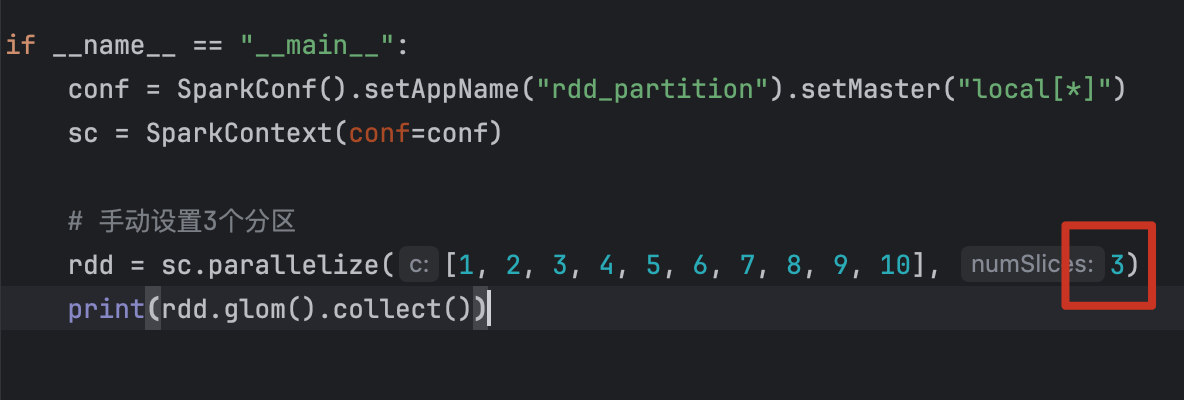
用代码验证RDD的分区:

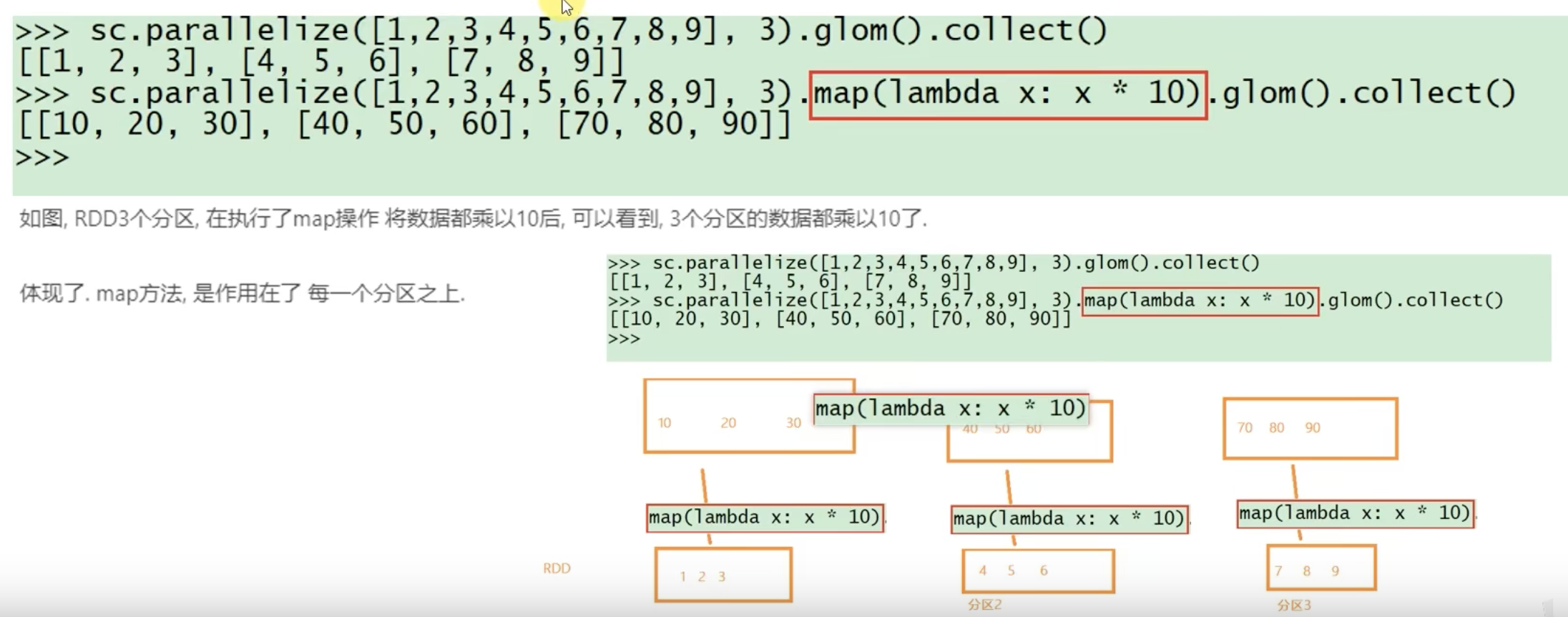
2、RDD的方法会作用在其所有的分区上
3、RDD之间是有依赖关系的(血缘关系)

4、K-V型的RDD可以有分区器

5、RDD的分区规划,会尽量靠近数据所在的服务器
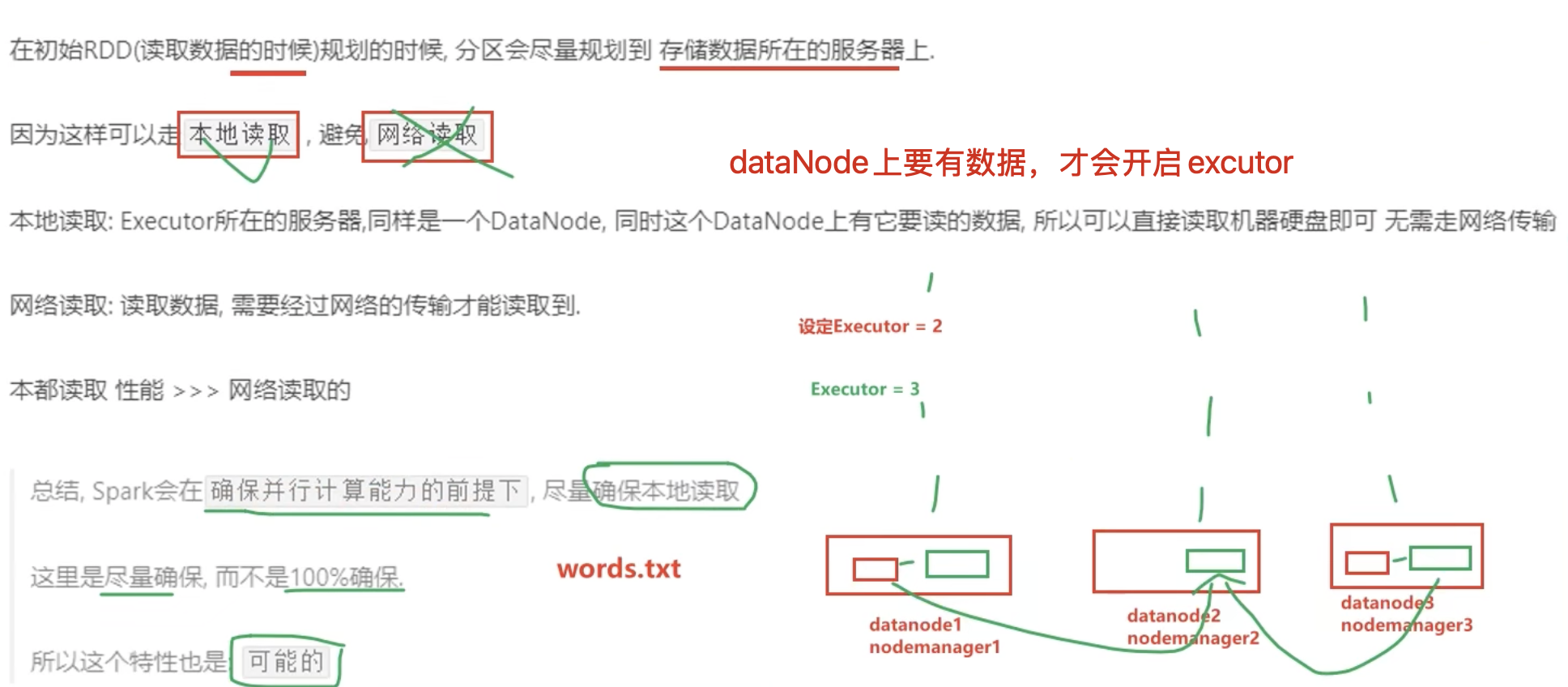
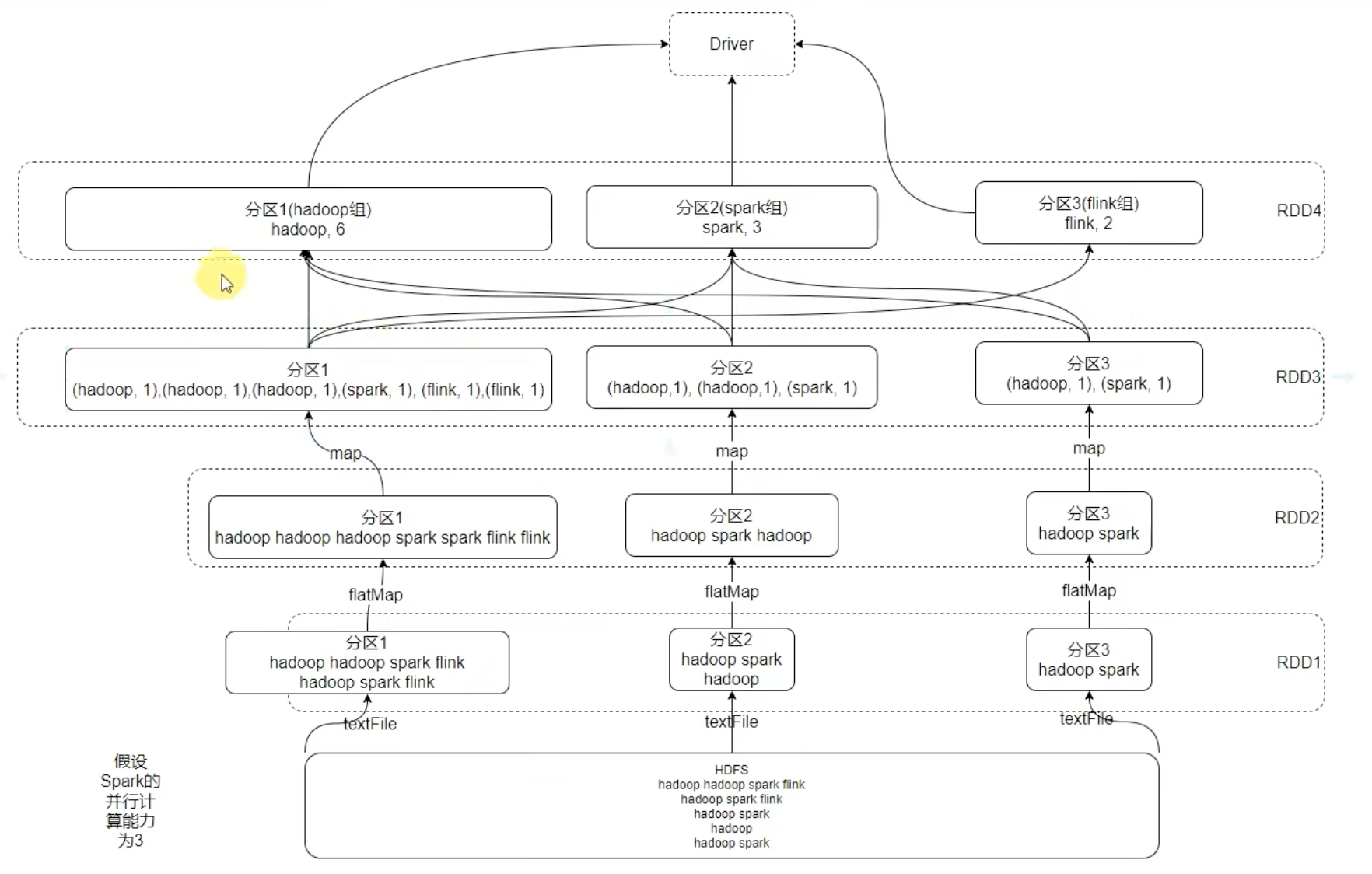
1-4、基于wordCount的RDD流程图
二、RDD的编程
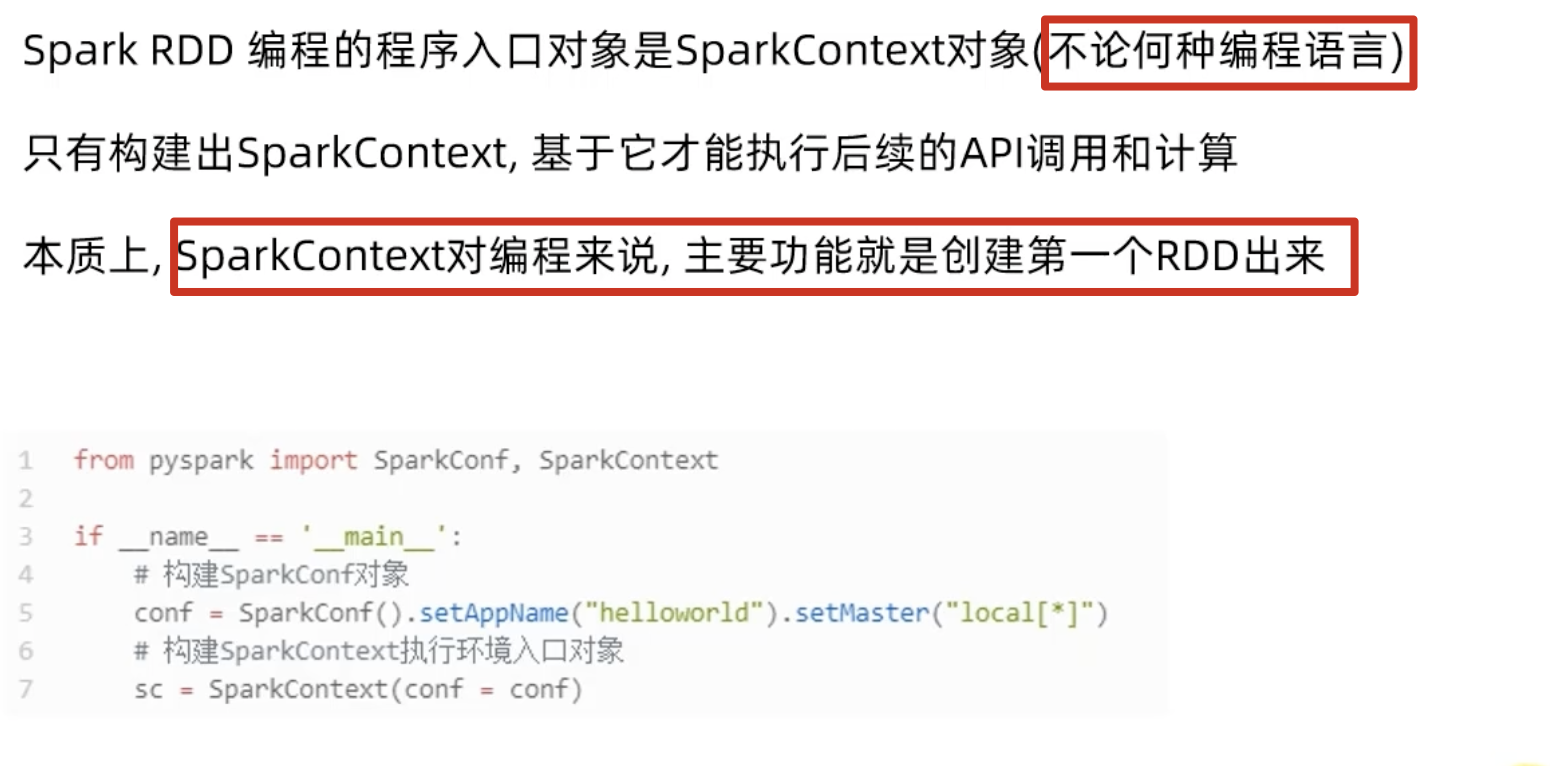
2-1、【回顾】:程序执行入口 SparkContext 对象
2-2、RDD的创建
1、并行化集合的创建
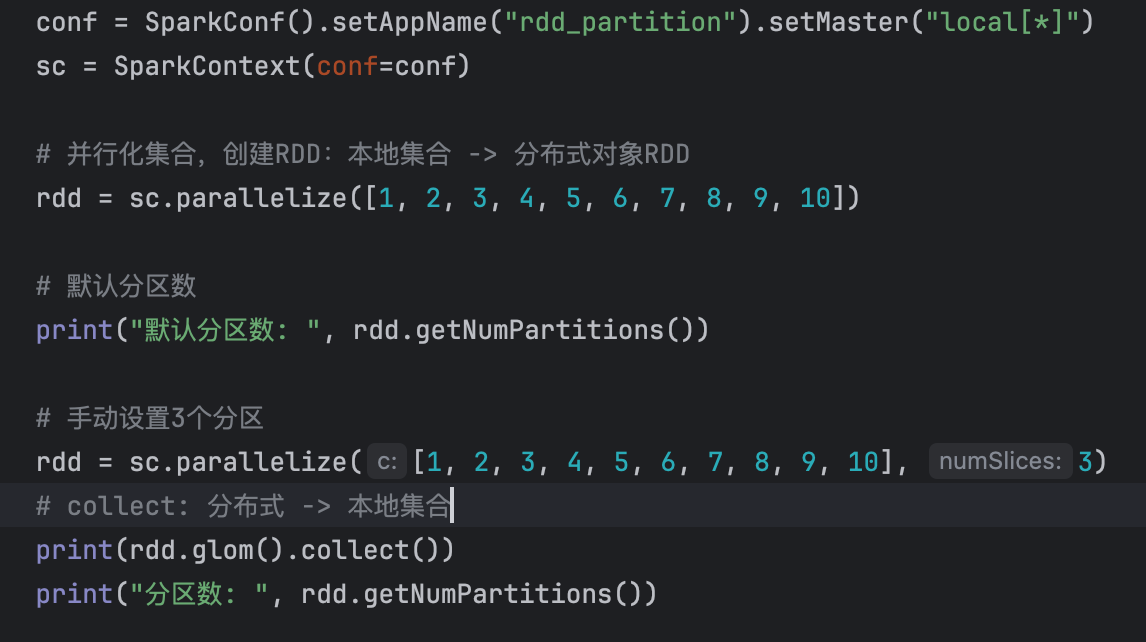

默认分区数,与本地的CPU内核数有关!
2、读取文件创建RDD
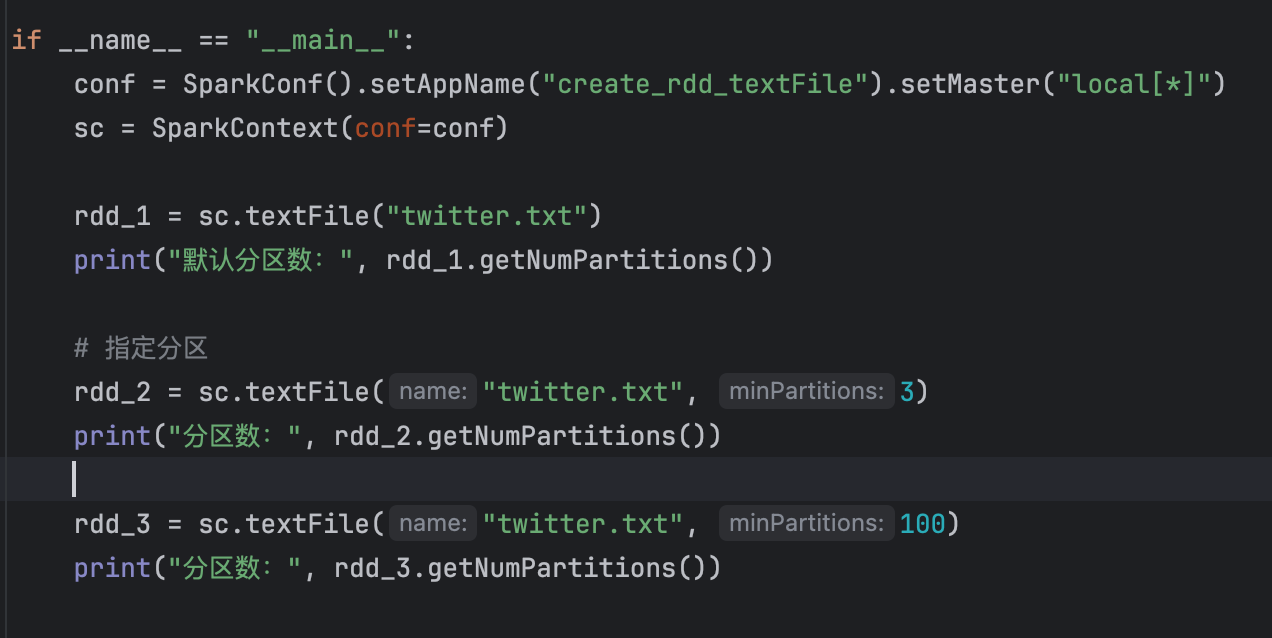
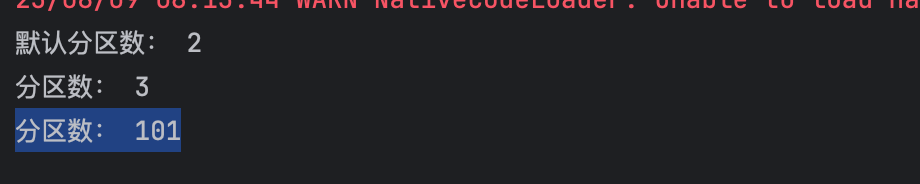
(1)、textFile API
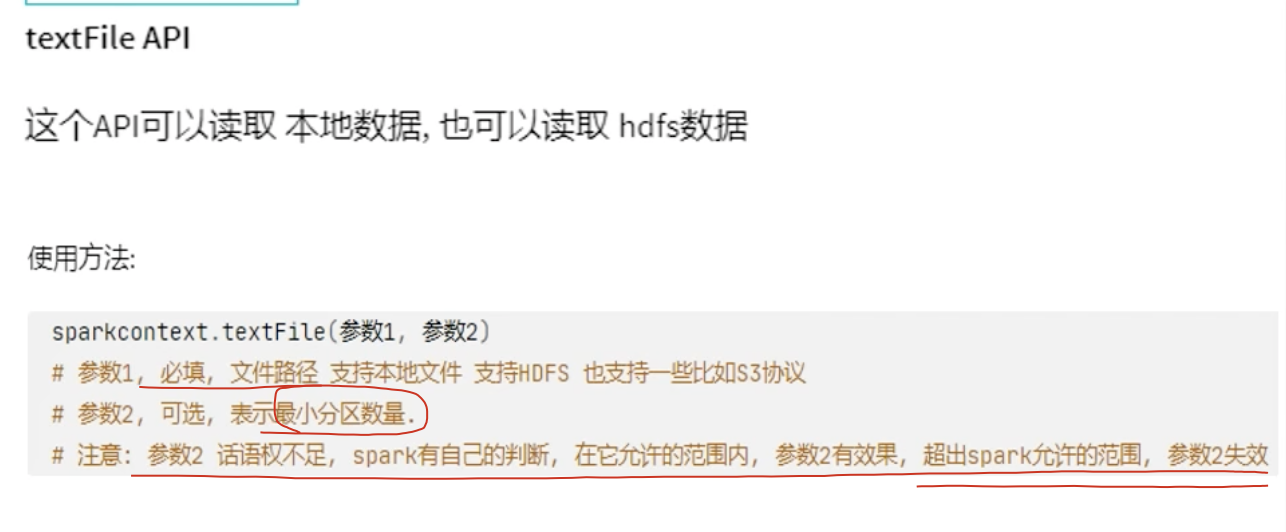
此时,默认分区数与本地的CPU无关,Spark 分区数的决定因素:
sc.textFile(path, minPartitions) 最终分区数 =
max(实际文件的分区块数, minPartitions)
实际文件的分区块数 取决于:
文件大小
底层文件系统的 block size(HDFS 默认 128MB,本地文件系统通常更小,比如 32MB 或者直接按 CPU 核数)
文件是放在 HDFS、S3、本地磁盘 还是其他系统
minPartitions 是你的传值
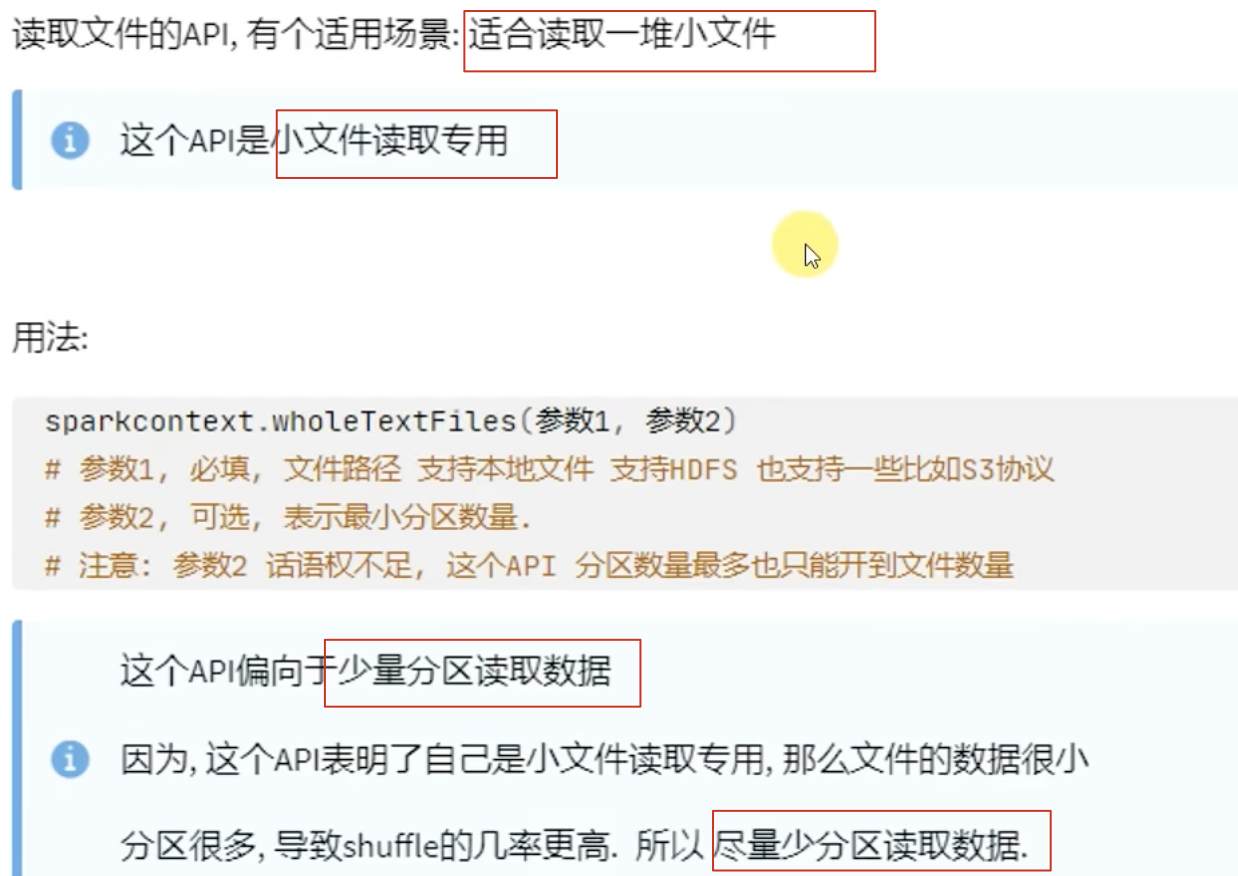
(2)、wholeTextFile API
示例:

返回结果:
[('file:/opt/project/my_test/tiny_files/file2.txt', 'this is week2, i am learning spark of rdd'), ('file:/opt/project/my_test/tiny_files/file3.txt', 'next week, i will learn rdd of join function.'), ('file:/opt/project/my_test/tiny_files/file1.txt', 'hello, my name is ws, i am learning big data')]
每一个list中的item,都是一个k-v元组:k-文件路径,v-文件内容。
直接获取文件内容:
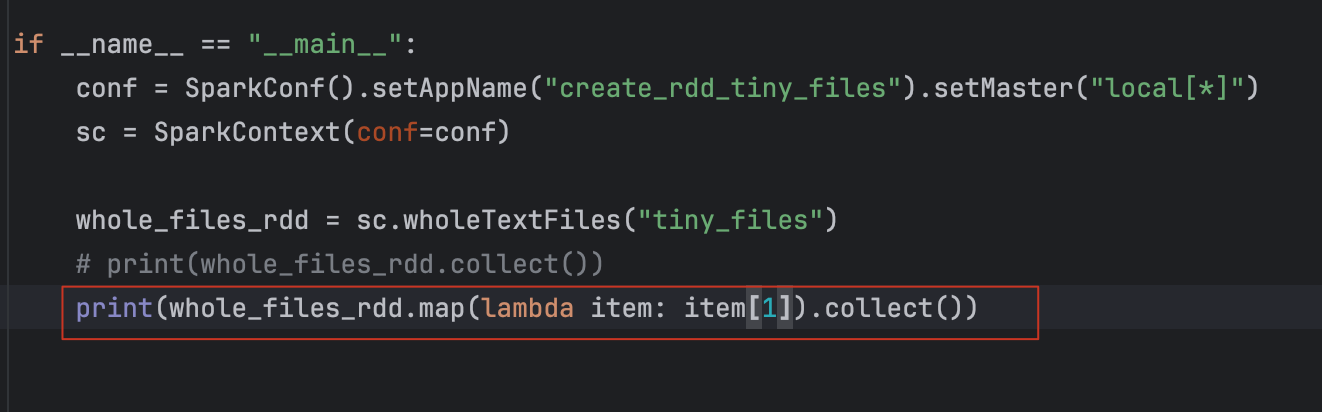

2-3、RDD算子
1、算子是什么
算子:分布式集合对象上的 API (方法)称之为算子.
方法 \ 函数:本地对象的 API, 叫做方法 \ 函数。
2、算子的分类
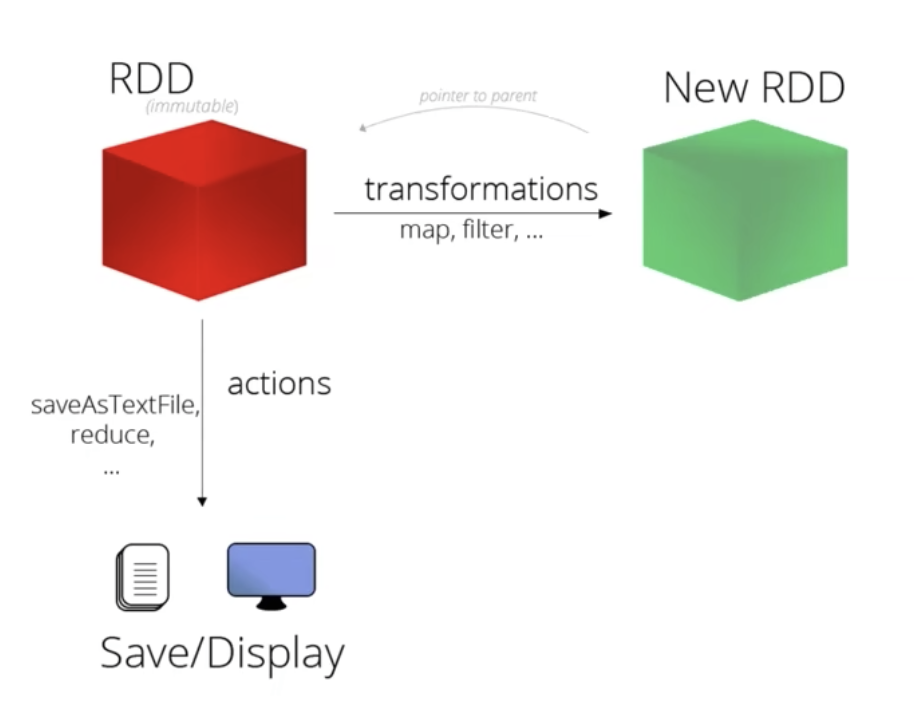
- Transformation: 转换算子
- Action: 动作算子
(1)、Transformation: 转换算子

(2)、action算子

2-4、常用的Transformation算子
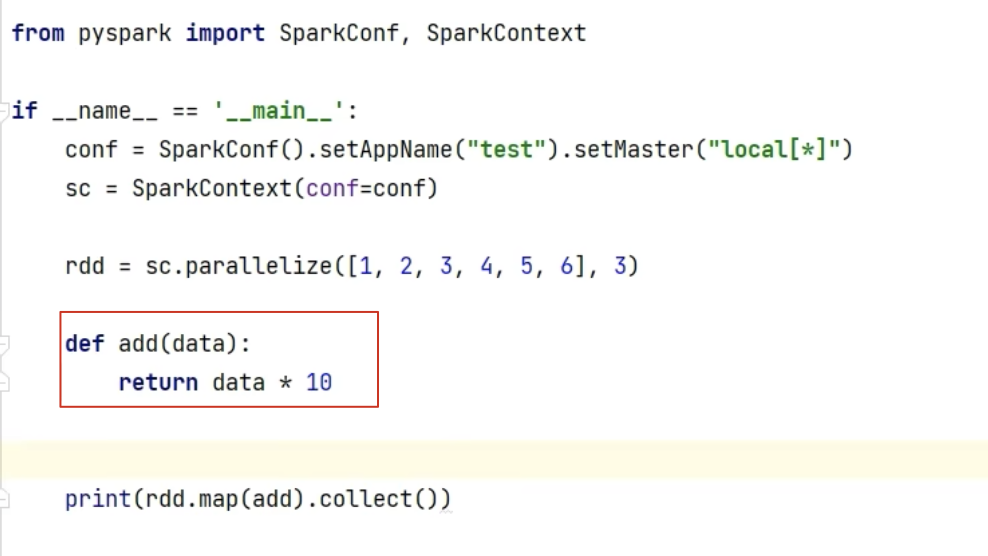
1、map算子
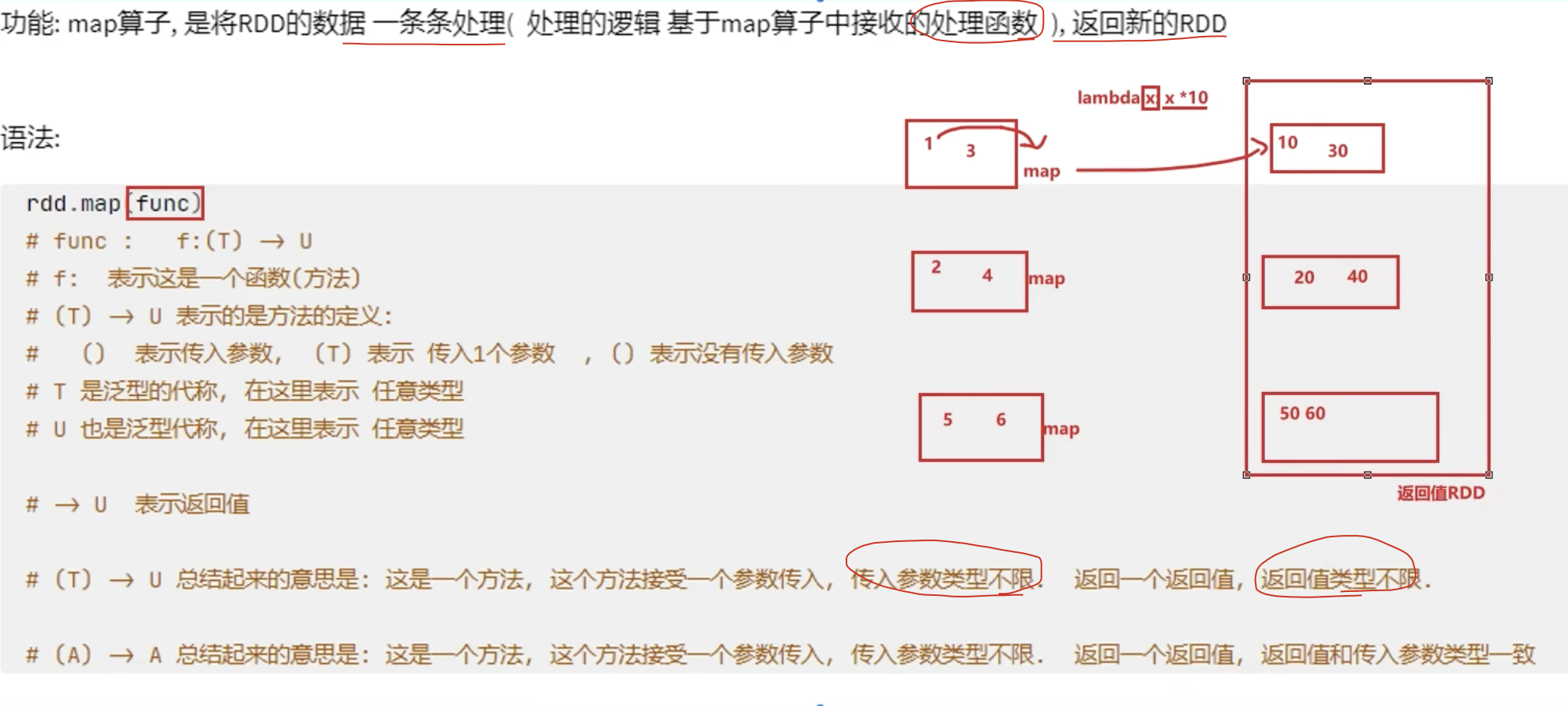
示例:

2、flapMap算子

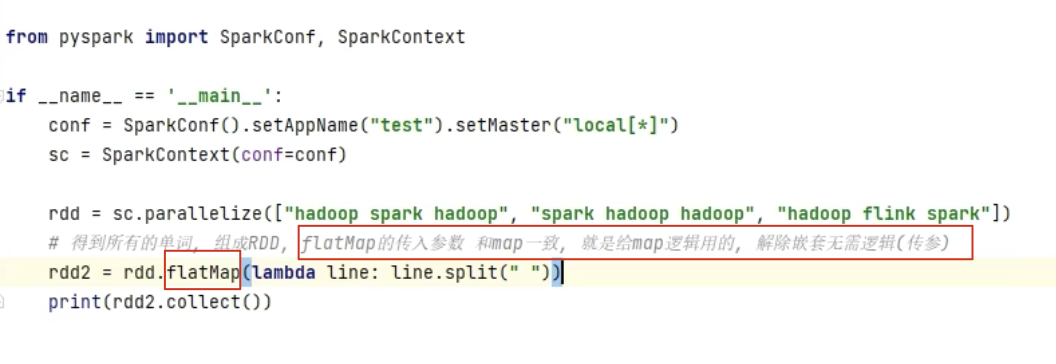

3、reduceByKey算子
功能:针对K-V型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据value的聚合操作。

【注意】:
两个传入的参数,类型要一致,这两个传入的参数都是K-V中的value,不要看key!
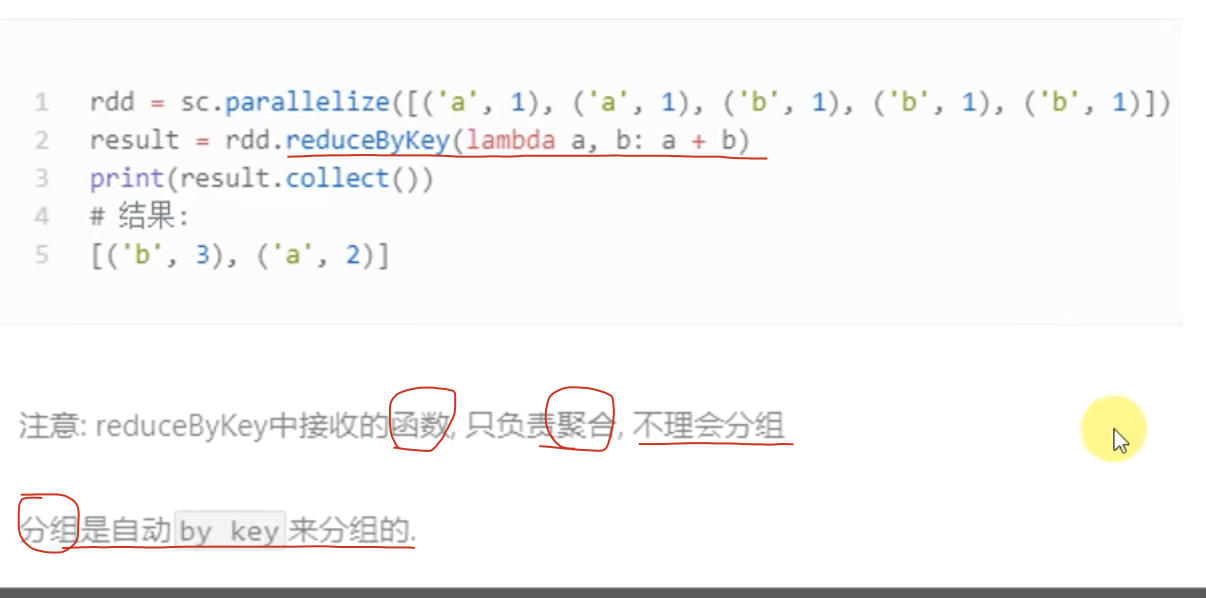
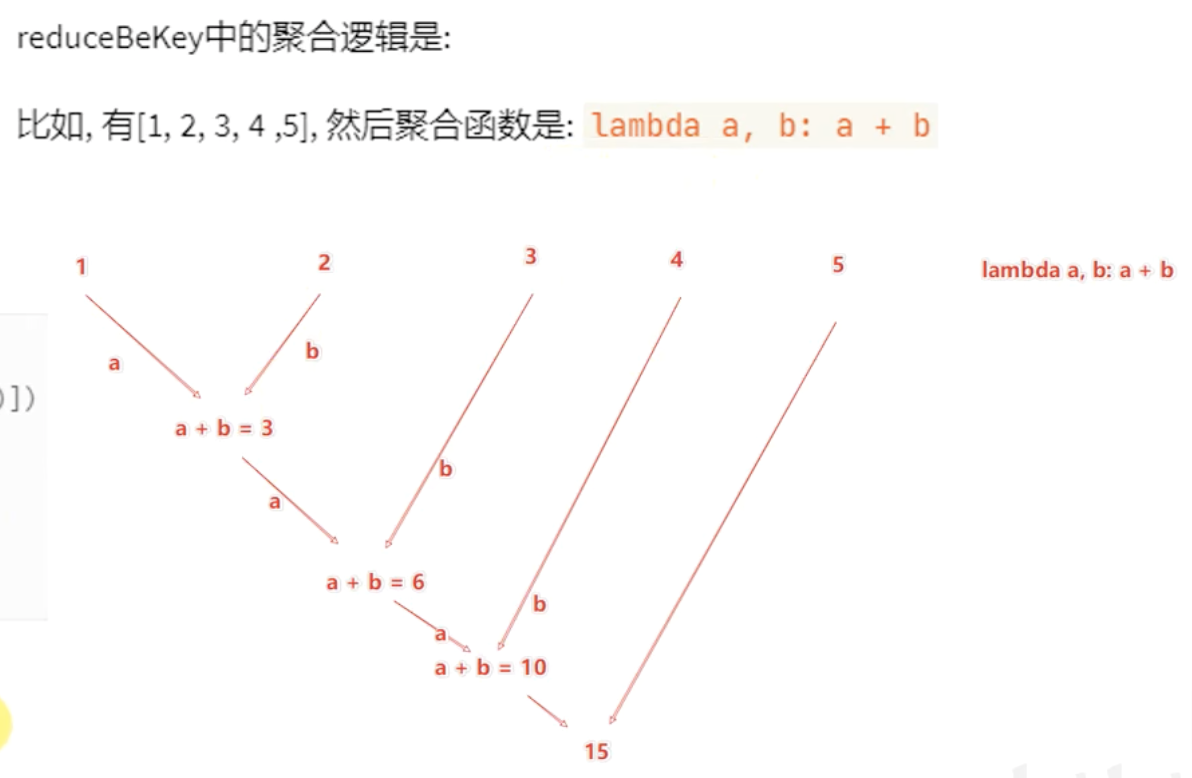
【注意】:
reduceByKey,有分组、有聚合的功能,但是分组是自动的按照key分组,我们定义的函数,只要求关注聚合的逻辑即可!
4、mapValues算子


【注意】:
此时的lambda x,中的x只是一个二元元组k-v中的value,如:('a', 1) 中的1。
对比map算子:

5、怎么看算子里面lambda 参数的类型
其实 PySpark 里 lambda 参数的类型 取决于 上一个 RDD 的数据结构 和 当前算子的语义。
举个例子:

(1) 单元素操作(map、filter)
map(lambda x: ...)→x就是 RDD 的一个元素(可能是二元组,也可能是单值)filter(lambda x: ...)→x同上

(2) Key-Value 专用操作(reduceByKey、groupByKey、mapValues、flatMapValues)
这些算子要求 RDD 元素是 (key, value) 形式的二元组:
reduceByKey(lambda a, b: ...)
a 和 b 是 同一个 key 的两个 value(不是整个二元组!)

mapValues(lambda v: ...)
v 只代表二元组的 value 部分

flatMapValues(lambda v: ...)
v 是 value,返回多个值会自动展开。
(3) 双 RDD 操作(join、cogroup)
这些算子返回的结构是嵌套的元组,比如:

lambda 里如果接这个结果,x 就是像 ('a', (1, 2)) 这样的结构。
(4)如何快速确认?
print(rdd.take(5))看一下 RDD 的前 5 个元素,就能立刻知道 lambda 会收到什么类型的参数。
6、groupBy算子

示例:
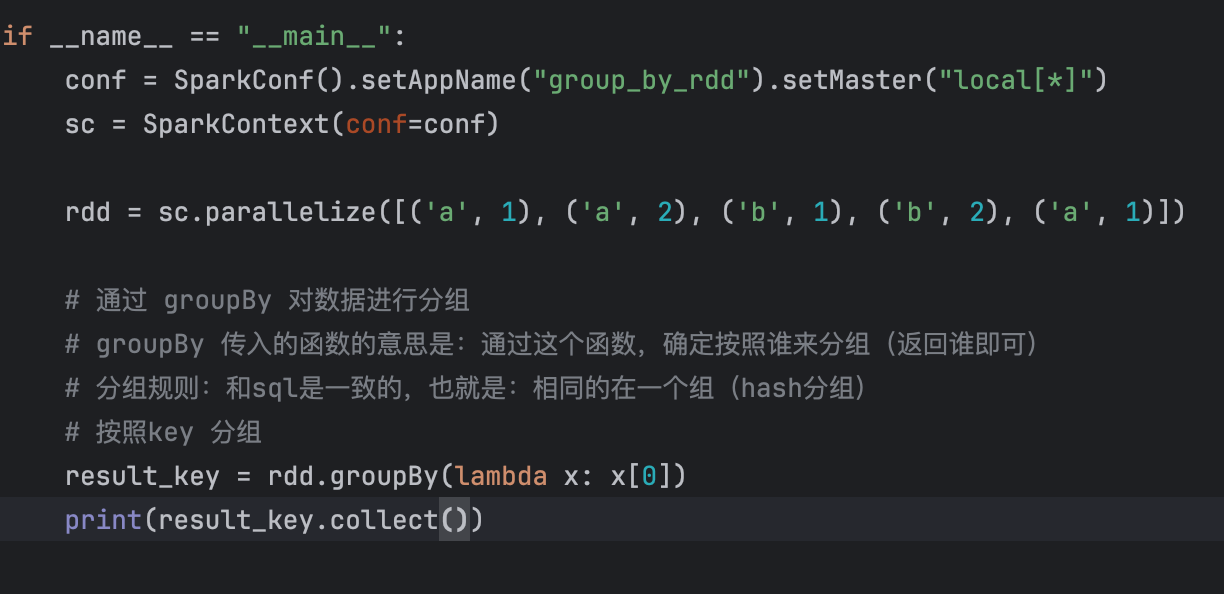
此时,返回的结果是:
[('a', <pyspark.resultiterable.ResultIterable object at 0x7f8648de23b0>), ('b', <pyspark.resultiterable.ResultIterable object at 0x7f8648de24a0>)]value是一个可迭代对象,要是想要用,直接强转为list即可。
【注意】:

7、Filter算子

示例:
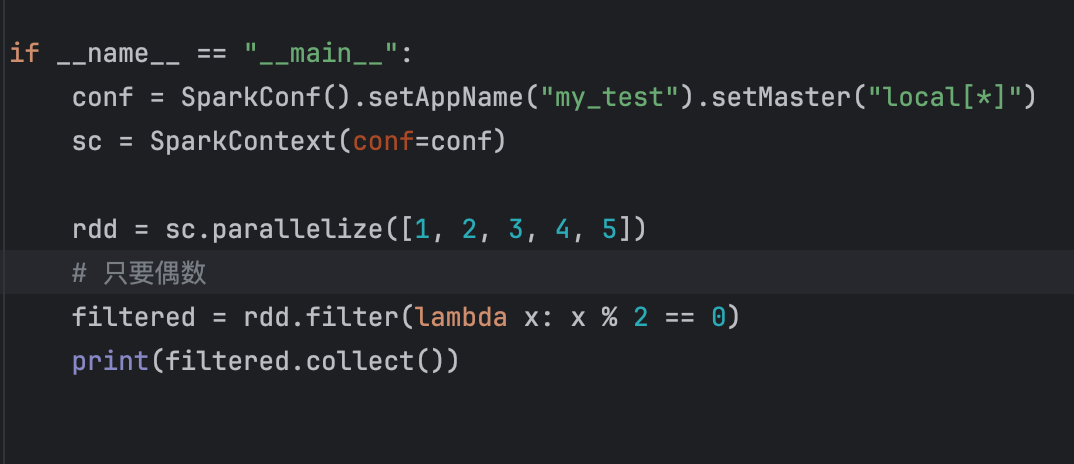
8、distinct算子

示例:
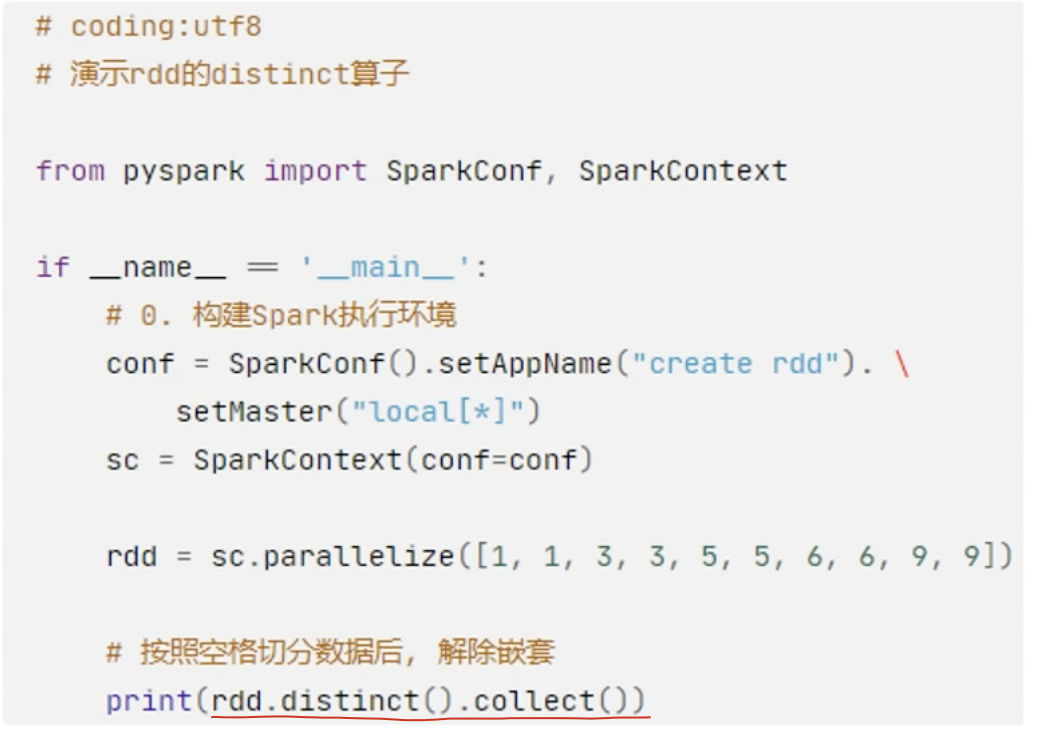
示例:
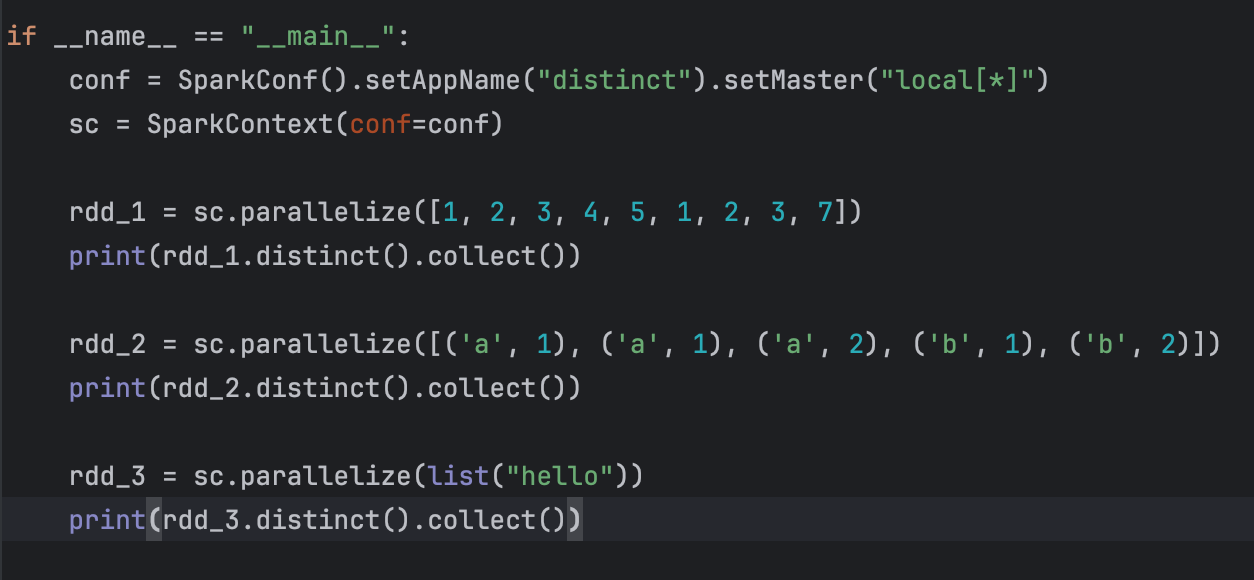
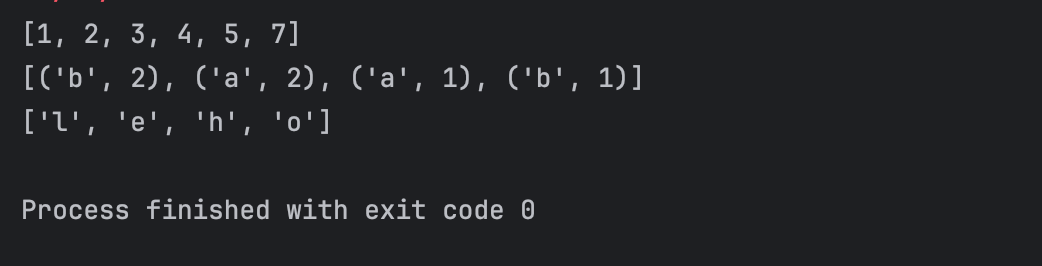
【注意】:
返回的结果根据数据汇总到driver的顺序决定,不一定是自定义的顺序,后续可以根据排序算子,决定顺序。
9、union算子

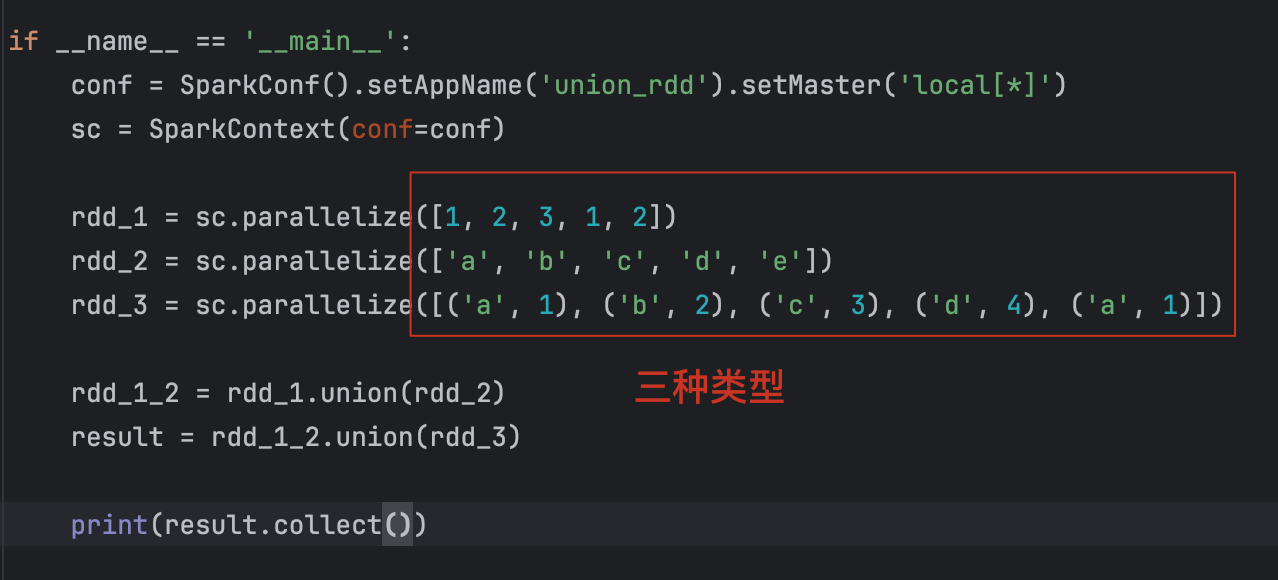
结果:

【注意】:
1、union算子,不会去重;
2、RDD的类型不同,也是可以合并的!
10、join算子

示例1:

join关联的规则:
自动按照二元元组的key进行关联,要是想要通过value关联,需要先用map将二元元组的key和value转换位置。
用部门和人员的例子,帮你直观解释一下 PySpark 里的 join、leftOuterJoin、rightOuterJoin,并且用数据演示返回结果的差异。
1. 数据准备
假设有两个 RDD:
部门表(departments)
departments = sc.parallelize([(1, "HR"),(2, "IT"),(3, "Finance")
])
格式
(部门ID, 部门名称)
员工表(employees)
employees = sc.parallelize([(1, "Alice"), # 部门 1(2, "Bob"), # 部门 2(2, "Charlie"), # 部门 2(4, "David") # 部门 4(不存在于部门表中)
])
格式
(部门ID, 员工姓名)
(1). join(内连接)
只保留两个 RDD 都存在的 key
departments.join(employees).collect()
结果:
[(1, ("HR", "Alice")),(2, ("IT", "Bob")),(2, ("IT", "Charlie"))
]
解释:
key=1:两个表都有 → HR, Alice
key=2:两个表都有 → IT, Bob / IT, Charlie
key=3:部门有,员工没有 → 不保留
key=4:员工有,部门没有 → 不保留
(2). leftOuterJoin(左外连接)
保留左表全部 key(部门表),右表没有的填
None
departments.leftOuterJoin(employees).collect()
结果:
[(1, ("HR", "Alice")),(2, ("IT", "Bob")),(2, ("IT", "Charlie")),(3, ("Finance", None))
]
解释:
key=3:部门有但员工没有 → value 填 None
key=4:员工有但部门没有 → 不保留(因为左表是部门)
(3). rightOuterJoin(右外连接)
保留右表全部 key(员工表),左表没有的填
None
departments.rightOuterJoin(employees).collect()
结果:
[(1, ("HR", "Alice")),(2, ("IT", "Bob")),(2, ("IT", "Charlie")),(4, (None, "David"))
]
解释:
key=4:员工有但部门没有 → 部门部分填 None
key=3:部门有但员工没有 → 不保留(因为右表是员工)
返回值的格式:
无论是 join、leftOuterJoin 还是 rightOuterJoin,它们返回的都是:

总结口诀
join→ 只要双方都有才要leftOuterJoin→ 左边全要,右边没有补 NonerightOuterJoin→ 右边全要,左边没有补 None
11、intersection算子
求2个rdd的交集,返回一个新的rdd
语法:
rdd1.intersection(rdd2)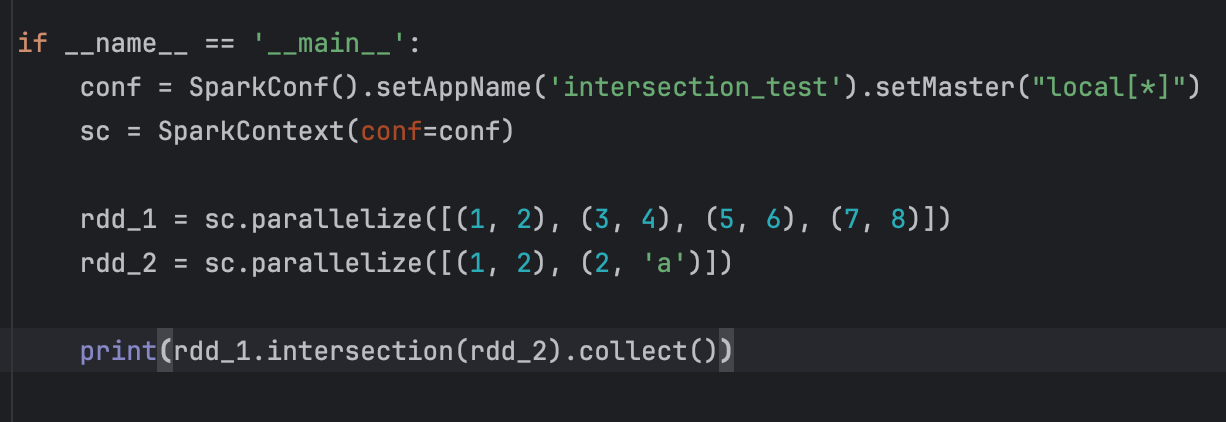
12、glom算子

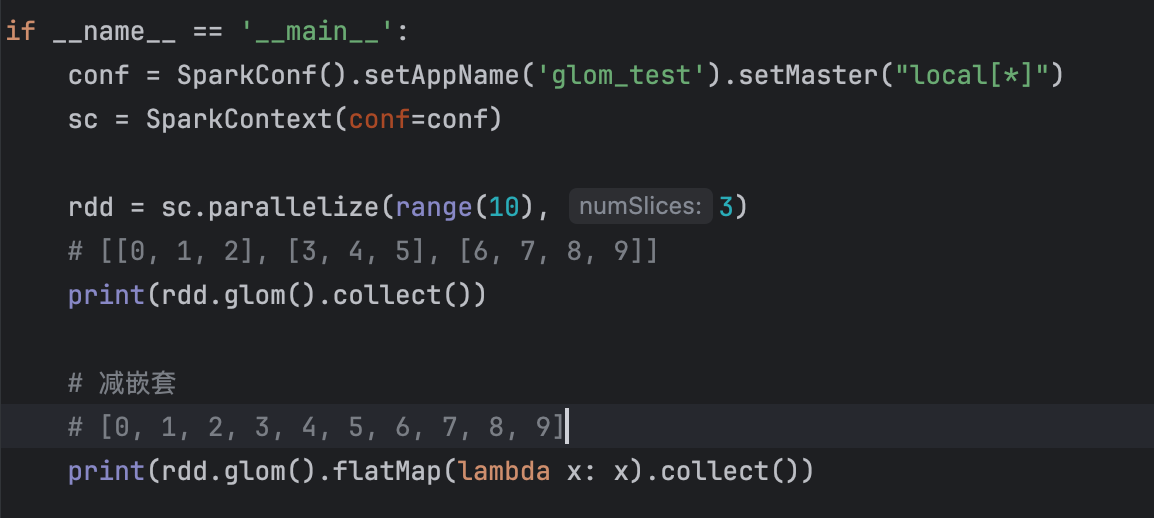
13、groupByKey算子

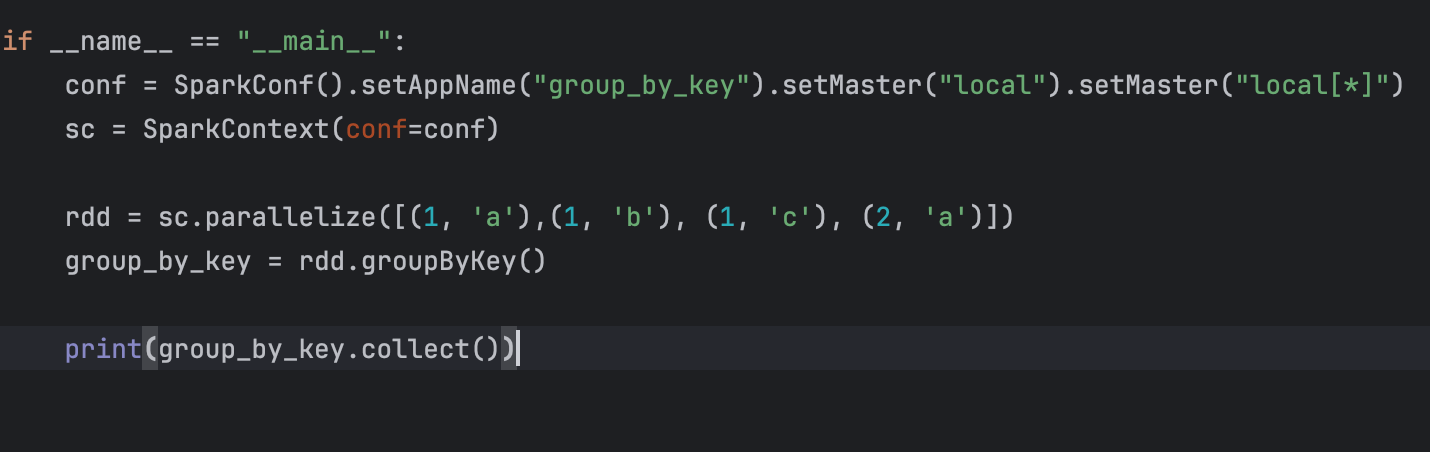
【注意】:
此时和groupBy() 一样,也是将所有的可迭代对象作为value返回了,要是想要获取,需要强转:
[(1, <pyspark.resultiterable.ResultIterable object at 0x7fb6ee84a740>), (2, <pyspark.resultiterable.ResultIterable object at 0x7fb6ee84a680>)]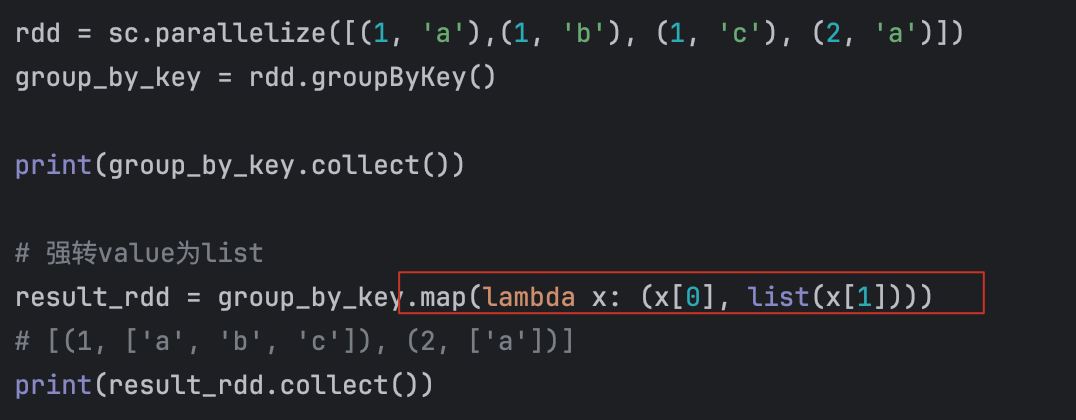
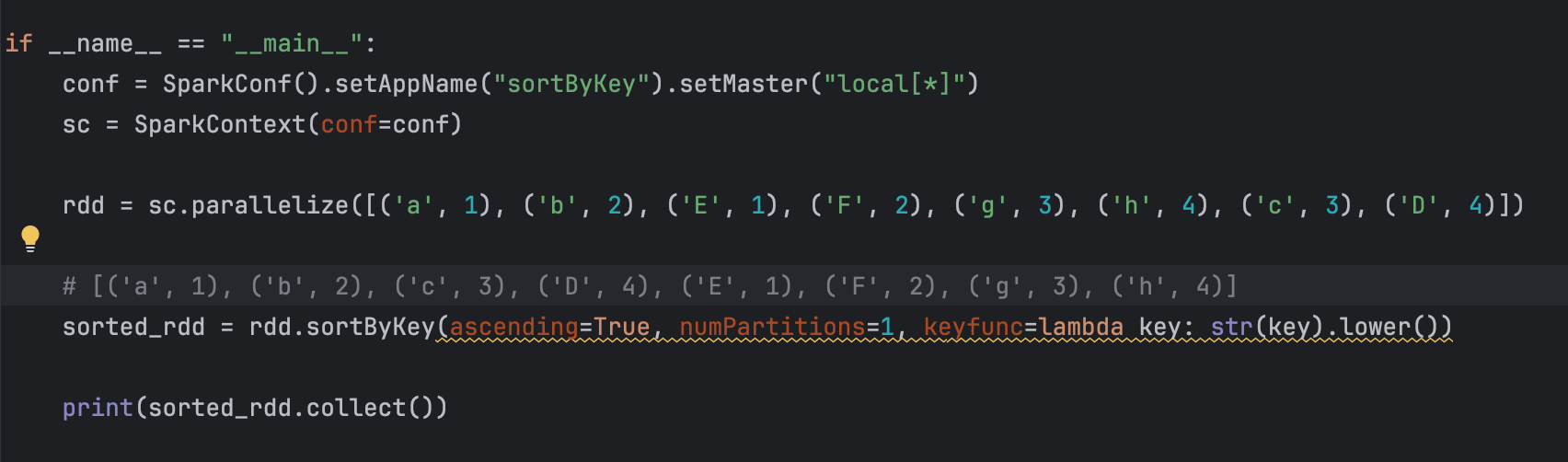
14、sortBy()排序
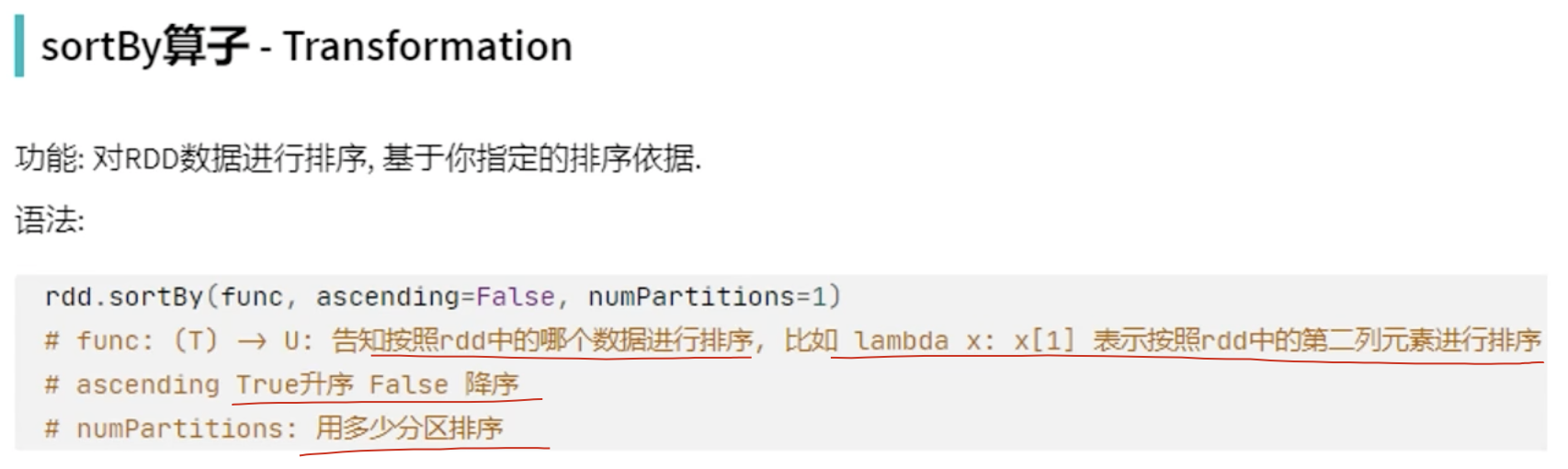
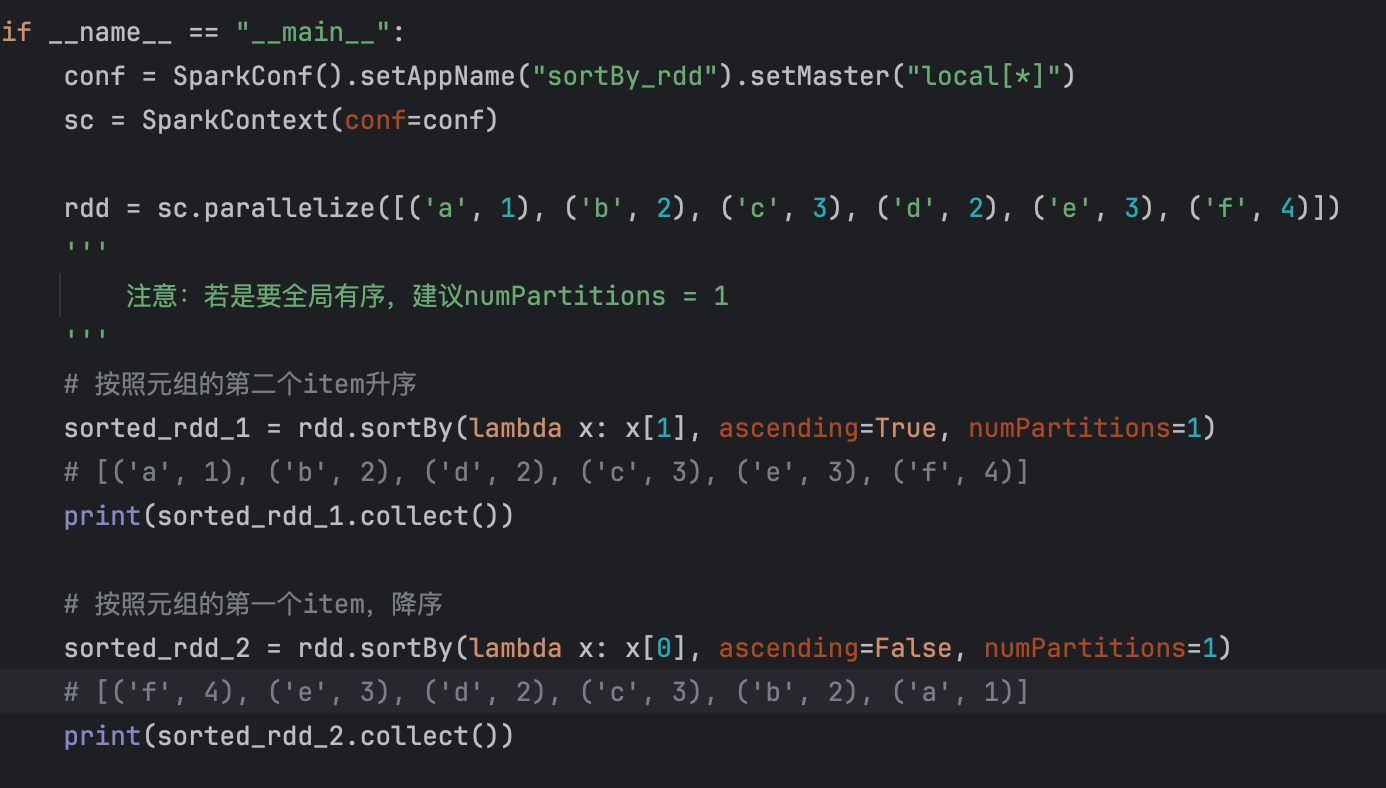
【注意】:
若是 numPartitions = x,因为实际执行的是excutor,有多个,很可能导致,组内有序,组外是无序的!所以建议:numPartitions = 1
15、sortByKey()