Spark 运行流程核心组件(二)任务调度
1、调度策略
| 参数 | 默认值 | 说明 |
|---|---|---|
spark.scheduler.mode | FIFO | 调度策略(FIFO/FAIR) |
spark.locality.wait | 3s | 本地性降级等待时间 |
spark.locality.wait.process | spark.locality.wait | PROCESS_LOCAL 等待时间 |
spark.locality.wait.node | spark.locality.wait | NODE_LOCAL 等待时间 |
spark.locality.wait.rack | spark.locality.wait | RACK_LOCAL 等待时间 |
调度策略:FIFO 按提交顺序处理;FAIR 支持权重分配。
本地化策略: 从 PROCESS_LOCAL 到 ANY 逐级降级,减少数据传输开销
val PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY = Value性能最优-> 最差
PROCESS_LOCAL -> NODE_LOCAL -> NO_PREF -> RACK_LOCAL -> ANY1、PROCESS_LOCAL
任务所需的数据就在同一个 Executor 进程的内存中2、NODE_LOCAL
任务所需的数据在同一个物理节点上,但不在同一个 Executor 进程的内存中。3、NO_PREF
没有位置偏好,数据来源本身是均匀分布或位置无关。4、RACK_LOCAL
不在同一个节点上,但在同一个机架5、ANY
在集群的其他机架2、核心组件
1、Schedulable
可调度实体的接口定义
1、Pool
调度树中的节点,可以是根节点或中间节点
- 调度模式(FIFO或FAIR)
- 权重(weight)
- 最小资源份额(minShare)
- 运行任务数(runningTasks)
- 子节点列表(schedulableQueue)
2、TaskSetManager
管理一个TaskSet(一组任务),负责任务调度、本地性处理、失败重试和推测执行
- 跟踪任务状态(待运行、运行中、已完成)
- 根据数据本地性选择任务
- 处理任务失败和重试逻辑
- 实现推测执行机制
2、TaskScheduler
Spark任务调度的核心实现,协调资源分配和任务调度
- 接收DAGScheduler提交的TaskSet
- 管理Executor资源状态
- 分配任务到可用Executor
- 处理任务状态更新
- 实现调度延迟和推测执行策略
3、SchedulableBuilder
调度树构建的抽象基类
1、FIFOSchedulableBuilder
实现先进先出调度策略的构建器
2、FairSchedulableBuilder
实现公平调度策略的构建器
3、核心设计
1、调度树
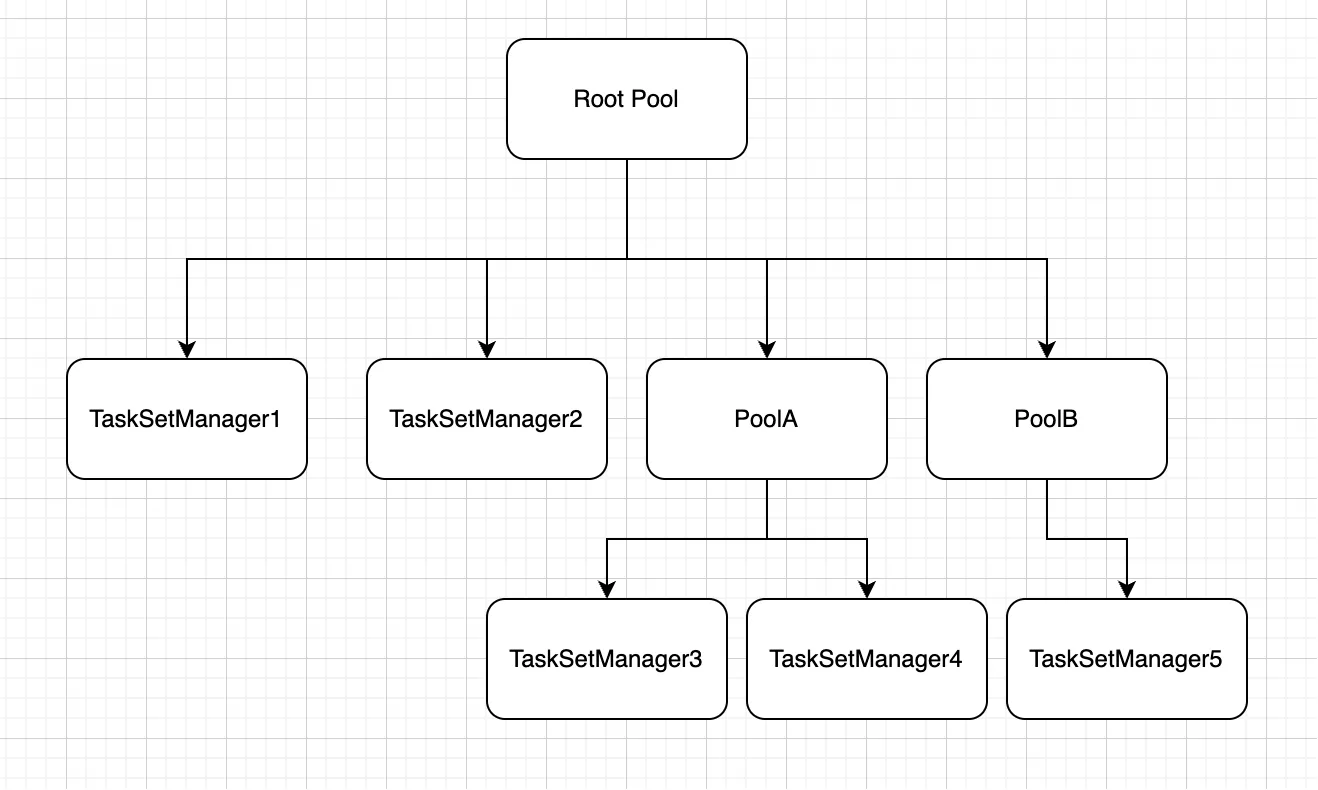
- Spark Standalone支持树形结构的调度池,每个池可以独立配置调度模式(FIFO/FAIR)
| 特性 | FIFO调度 | 公平调度 |
|---|---|---|
| 结构 | 单层Pool结构 | 多层Pool树结构 |
| 排序方式 | 按提交顺序 | 基于权重/minShare |
| 资源分配 | 独占式 | 按比例共享 |
| 适用场景 | 批处理作业 | 多用户/多作业环境 |
| 配置方式 | 无需配置 | XML配置文件定义Pool |
- 作业通过
sc.setLocalProperty("spark.scheduler.pool", "poolName")分配到指定的调度池 - 配置调度池配置文件
<!-- conf/fairscheduler.xml -->
<?xml version="1.0"?>
<allocations><pool name="production"><schedulingMode>FAIR</schedulingMode><weight>1</weight><minShare>2</minShare></pool><pool name="test"><schedulingMode>FIFO</schedulingMode><weight>2</weight><minShare>3</minShare></pool>
</allocations>
1、FIFO
// 优先级val priority1 = s1.priorityval priority2 = s2.priorityvar res = math.signum(priority1 - priority2)if (res == 0) {val stageId1 = s1.stageIdval stageId2 = s2.stageId// 先进先出res = math.signum(stageId1 - stageId2)}res < 0
2、FAIR
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {val minShare1 = s1.minShareval minShare2 = s2.minShareval runningTasks1 = s1.runningTasksval runningTasks2 = s2.runningTasks// 1. 满足minShare优先级val s1Needy = runningTasks1 < minShare1val s2Needy = runningTasks2 < minShare2// 2. 比较资源使用比例val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)// 3. 权重比较val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDoubleval taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDoublevar compare = 0if (s1Needy && !s2Needy) {return true} else if (!s1Needy && s2Needy) {return false} else if (s1Needy && s2Needy) {compare = minShareRatio1.compareTo(minShareRatio2)} else {compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)}if (compare < 0) {true} else if (compare > 0) {false} else {s1.name < s2.name}}
2、资源分配与任务调度
- Executor注册
executorAdded(o.executorId, o.host)
- Pool排序调度队列
val sortedTaskSets = rootPool.getSortedTaskSetQueue
- TaskSetManager资源分配请求
val (noDelayScheduleReject, minLocality) = resourceOfferSingleTaskSet(taskSet, currentMaxLocality, shuffledOffers, availableCpus,availableResources, tasks)val (taskDescOption, didReject, index) =taskSet.resourceOffer(execId, host, maxLocality, taskCpus, taskResAssignments)
- TaskSetManager本地性匹配
var allowedLocality = maxLocalityif (maxLocality != TaskLocality.NO_PREF) {allowedLocality = getAllowedLocalityLevel(curTime)if (allowedLocality > maxLocality) {// We're not allowed to search for farther-away tasksallowedLocality = maxLocality}}