稳定且高效:GSPO如何革新大型语言模型的强化学习训练?
稳定且高效:GSPO如何革新大型语言模型的强化学习训练?
本文将介绍Group Sequence Policy Optimization (GSPO),一种用于训练大型语言模型的稳定、高效且性能优异的强化学习算法。与之前采用token级重要性比率的算法不同,GSPO基于序列似然定义重要性比率,并执行序列级裁剪、奖励和优化,在Qwen3模型训练中取得了显著效果。
论文标题:Group Sequence Policy Optimization
来源:arXiv:2507.18071 [cs.LG],链接:http://arxiv.org/abs/2507.18071
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
强化学习已成为扩展语言模型的关键范式。通过大规模RL,语言模型能够处理复杂的任务,如竞赛级数学和编程,通过更深入和更长的推理过程。然而,当前最先进的RL算法(如GRPO)在训练大型语言模型时表现出严重的稳定性问题,经常导致灾难性和不可逆的模型崩溃,这阻碍了通过持续RL训练来推动语言模型能力边界的努力。
研究问题
- 当前最先进的RL算法(如GRPO)在训练大型语言模型时存在严重的稳定性问题,经常导致模型崩溃。
- GRPO算法的不稳定性源于其算法设计中重要性采样权重的根本误用和失效,引入了高方差训练噪声。
- 现有算法在处理长序列和MoE模型时效率低下,且需要复杂的稳定化策略。
主要贡献
- 提出GSPO算法,基于序列似然定义重要性比率,执行序列级裁剪、奖励和优化,从根本上解决了GRPO的稳定性问题。
- GSPO在训练稳定性、效率和性能方面显著优于GRPO,特别在MoE模型训练中表现出色,消除了对复杂稳定化策略的需求。
- GSPO通过序列级优化简化了RL基础设施设计,对精度差异更容忍,具有实际应用价值。
思维导图
方法论精要
GSPO: Group Sequence Policy Optimization
GSPO的核心创新在于基于序列似然定义重要性比率,而不是像GRPO那样使用token级重要性比率。GSPO的优化目标为:
JGSPO(θ)=Ex∼D,{yi}i=1G∼πθold(⋅∣x)[1G∑i=1Gmin(si(θ)A^i,clip(si(θ),1−ε,1+ε)A^i)]J_{GSPO}(\theta) = \mathbb{E}_{x\sim D,\{y_i\}_{i=1}^G\sim \pi_{\theta_{old}}(\cdot|x)}\left[ \frac{1}{G}\sum_{i=1}^G \min\left(s_i(\theta)\hat{A}_i, \text{clip}(s_i(\theta), 1-\varepsilon, 1+\varepsilon)\hat{A}_i\right) \right]JGSPO(θ)=Ex∼D,{yi}i=1G∼πθold(⋅∣x)[G1∑i=1Gmin(si(θ)A^i,clip(si(θ),1−ε,1+ε)A^i)]
其中,重要性比率si(θ)s_i(\theta)si(θ)基于序列似然定义:
si(θ)=(πθ(yi∣x)πθold(yi∣x))1∣yi∣=exp(1∣yi∣∑t=1∣yi∣logπθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t))s_i(\theta) = \left(\frac{\pi_\theta(y_i|x)}{\pi_{\theta_{old}}(y_i|x)}\right)^{\frac{1}{|y_i|}} = \exp\left(\frac{1}{|y_i|}\sum_{t=1}^{|y_i|} \log\frac{\pi_\theta(y_{i,t}|x,y_{i,<t})}{\pi_{\theta_{old}}(y_{i,t}|x,y_{i,<t})}\right)si(θ)=(πθold(yi∣x)πθ(yi∣x))∣yi∣1=exp(∣yi∣1∑t=1∣yi∣logπθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t))
优势估计采用组内归一化:
A^i=r(x,yi)−mean({r(x,yi)}i=1G)std({r(x,yi)}i=1G)\hat{A}_i = \frac{r(x,y_i) - \text{mean}(\{r(x,y_i)\}_{i=1}^G)}{\text{std}(\{r(x,y_i)\}_{i=1}^G)}A^i=std({r(x,yi)}i=1G)r(x,yi)−mean({r(x,yi)}i=1G)
这种方法将裁剪应用于整个响应而不是单个token,与序列级奖励和优化相匹配。
梯度分析
GSPO的梯度为:
∇θJGSPO(θ)=E[1G∑i=1G(πθ(yi∣x)πθold(yi∣x))1∣yi∣A^i⋅1∣yi∣∑t=1∣yi∣∇θlogπθ(yi,t∣x,yi,<t)]\nabla_\theta J_{GSPO}(\theta) = \mathbb{E}\left[ \frac{1}{G}\sum_{i=1}^G \left(\frac{\pi_\theta(y_i|x)}{\pi_{\theta_{old}}(y_i|x)}\right)^{\frac{1}{|y_i|}} \hat{A}_i \cdot \frac{1}{|y_i|}\sum_{t=1}^{|y_i|} \nabla_\theta \log\pi_\theta(y_{i,t}|x,y_{i,<t}) \right]∇θJGSPO(θ)=E[G1∑i=1G(πθold(yi∣x)πθ(yi∣x))∣yi∣1A^i⋅∣yi∣1∑t=1∣yi∣∇θlogπθ(yi,t∣x,yi,<t)]
相比之下,GRPO的梯度为:
∇θJGRPO(θ)=E[1G∑i=1GA^i⋅1∣yi∣∑t=1∣yi∣πθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t)∇θlogπθ(yi,t∣x,yi,<t)]\nabla_\theta J_{GRPO}(\theta) = \mathbb{E}\left[ \frac{1}{G}\sum_{i=1}^G \hat{A}_i \cdot \frac{1}{|y_i|}\sum_{t=1}^{|y_i|} \frac{\pi_\theta(y_{i,t}|x,y_{i,<t})}{\pi_{\theta_{old}}(y_{i,t}|x,y_{i,<t})} \nabla_\theta \log\pi_\theta(y_{i,t}|x,y_{i,<t}) \right]∇θJGRPO(θ)=E[G1∑i=1GA^i⋅∣yi∣1∑t=1∣yi∣πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)∇θlogπθ(yi,t∣x,yi,<t)]
GSPO对响应中的所有token采用相等权重,消除了GRPO的不稳定性因素。
GSPO-token: Token级目标变体
为了在多轮RL等场景中实现更细粒度的优势调整,GSPO还提供了token级目标变体:
JGSPO−token(θ)=E[1G∑i=1G1∣yi∣∑t=1∣yi∣min(si,t(θ)A^i,t,clip(si,t(θ),1−ε,1+ε)A^i,t)]J_{GSPO-token}(\theta) = \mathbb{E}\left[ \frac{1}{G}\sum_{i=1}^G \frac{1}{|y_i|}\sum_{t=1}^{|y_i|} \min\left(s_{i,t}(\theta)\hat{A}_{i,t}, \text{clip}(s_{i,t}(\theta), 1-\varepsilon, 1+\varepsilon)\hat{A}_{i,t}\right) \right]JGSPO−token(θ)=E[G1∑i=1G∣yi∣1∑t=1∣yi∣min(si,t(θ)A^i,t,clip(si,t(θ),1−ε,1+ε)A^i,t)]
其中:
si,t(θ)=sg[si(θ)]⋅πθ(yi,t∣x,yi,<t)sg[πθ(yi,t∣x,yi,<t)]s_{i,t}(\theta) = \text{sg}[s_i(\theta)] \cdot \frac{\pi_\theta(y_{i,t}|x,y_{i,<t})}{\text{sg}[\pi_\theta(y_{i,t}|x,y_{i,<t})]}si,t(θ)=sg[si(θ)]⋅sg[πθ(yi,t∣x,yi,<t)]πθ(yi,t∣x,yi,<t)
实验洞察
实验设置与基线
实验使用从Qwen3-30B-A3B-Base微调的冷启动模型,在以下基准上进行评估:
- AIME’24(32次采样的平均Pass@1)
- LiveCodeBench(202410-202502,8次采样的平均Pass@1)
- CodeForces(Elo Rating)
在RL训练中,每批rollout数据被分为四个小批次进行梯度更新。GSPO的左右裁剪范围分别设置为3e-4和4e-4,而GRPO的左右裁剪范围设置为0.2和0.27。
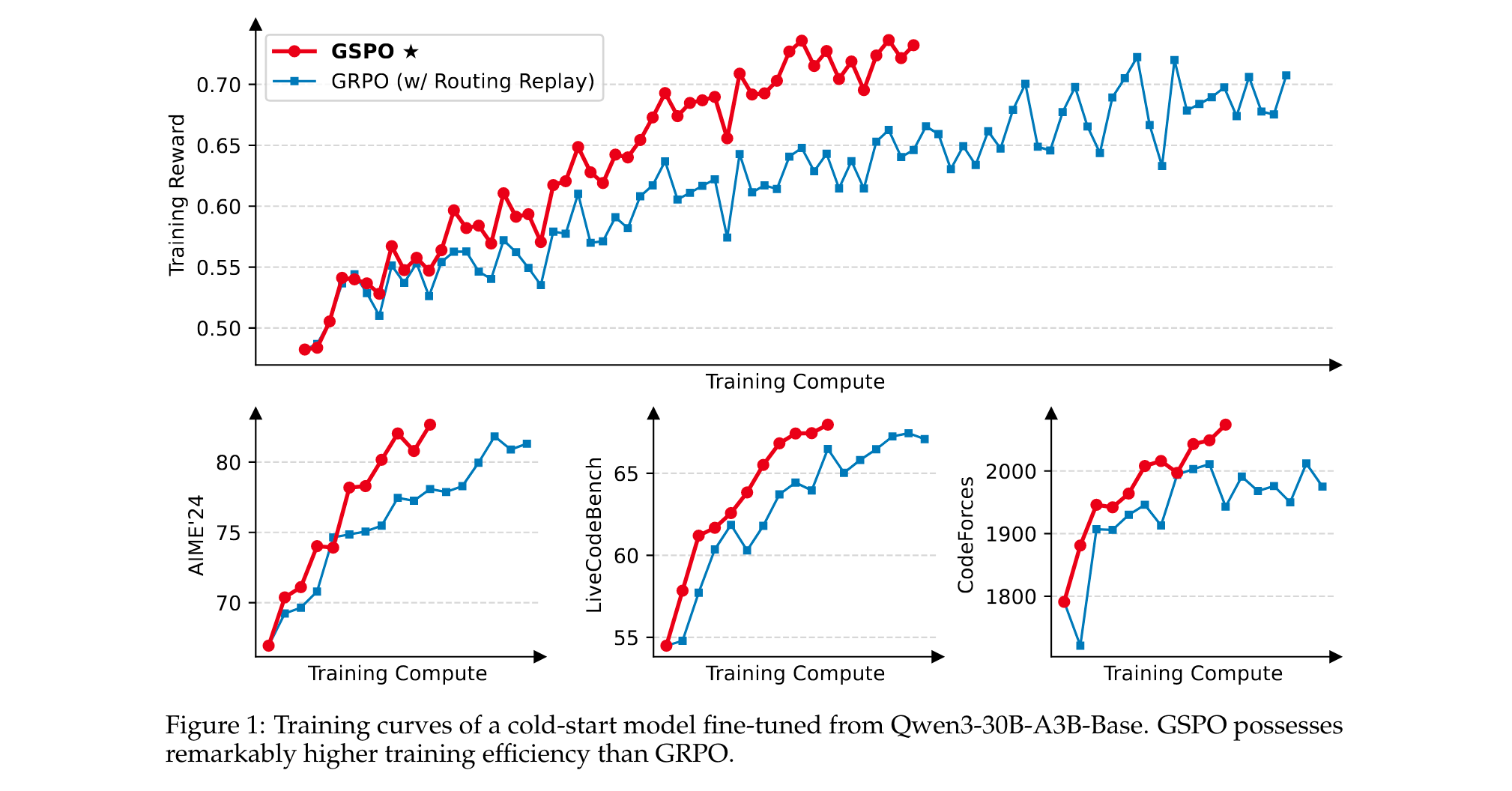
主要结果
实验结果表明:
- GSPO训练过程稳定,能够通过增加训练计算、定期更新查询集和延长生成长度来持续提升性能。
- GSPO在训练效率上显著优于GRPO,在相同训练计算和消耗查询下实现更好的训练准确性和基准性能。
- GSPO成功应用于最新Qwen3模型的RL训练,证明了其在释放大规模RL扩展能力方面的有效性。
关于裁剪比例的观察
尽管GSPO的序列级裁剪比GRPO的token级裁剪裁剪了更多token,但GSPO仍实现了更高的训练效率。这表明GRPO的token级梯度估计本质上是噪声大且低效的,而GSPO的序列级方法提供了更可靠和有效的学习信号。

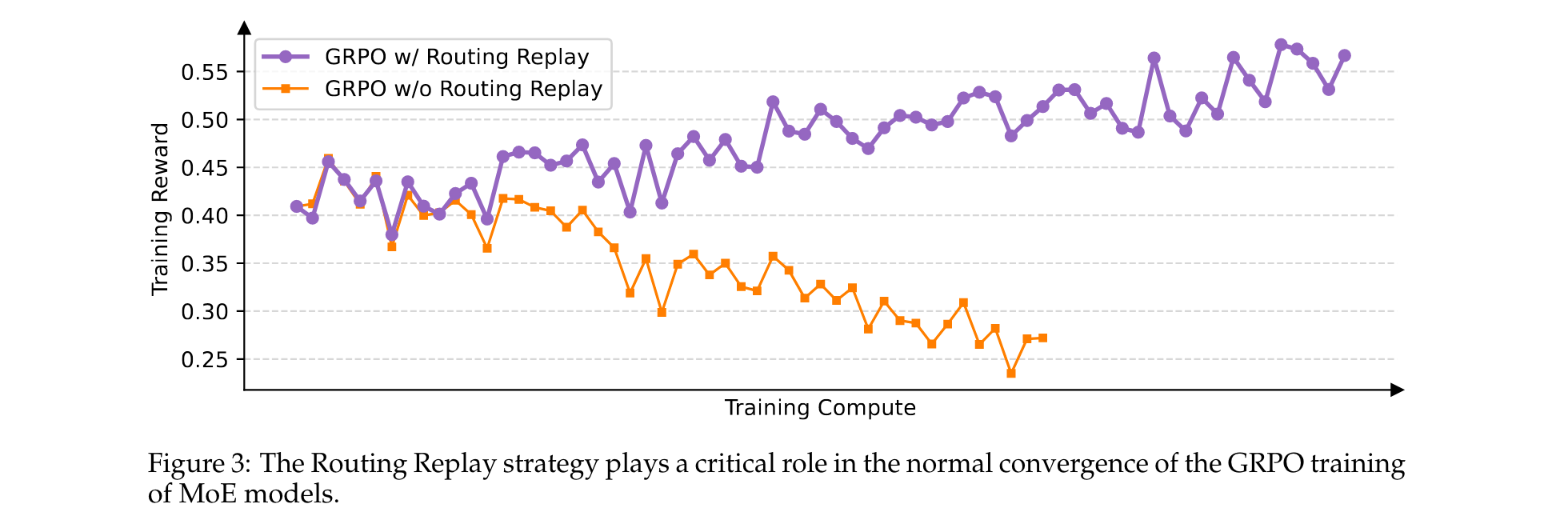
GSPO对MoE训练的益处
在MoE模型训练中,专家激活波动会导致token级重要性比率剧烈波动,进而影响RL训练的正常收敛。为解决这个问题,之前的方法采用了Routing Replay策略,但会带来额外的内存和通信开销。
GSPO通过关注序列似然而非单个token似然,从根本上解决了专家激活波动问题,消除了对Routing Replay策略的依赖。这不仅简化和稳定了训练过程,还允许模型充分利用其容量而无需人工约束。
GSPO对RL基础设施的益处
由于训练引擎(如Megatron)和推理引擎(如SGLang和vLLM)之间的精度差异,在实践中通常需要使用训练引擎重新计算旧策略下采样响应的似然。然而,GSPO只使用序列级而非token级似然进行优化,对精度差异更容忍,因此可以直接使用推理引擎返回的似然进行优化,从而避免了使用训练引擎重新计算的需求。这在部分rollout和多轮RL等场景以及训练-推理分离框架中特别有益。