postgresql运维问题解决:PG集群备节点状态异常告警处理
小亦平台会持续给大家科普一些运维过程中常见的问题解决案例,运维朋友们可以在厂家问题及解决方案专栏查看更多案例
问题概述:
- 故障: pg数据库备节点状态异常
- 现象: 一般为集群间心跳超时导致,现象为集群有fail-count失败数告警,备节点状态为stop或alone。
问题分析:
- 直接原因: 集群间心跳超时。
- 故障表现:
- 集群有fail-count失败数告警。
- 备节点状态为stop或alone。
解决方案:
1. 用root用户登录数据库集群任一节点;
2. 检查集群状态: cls_status;
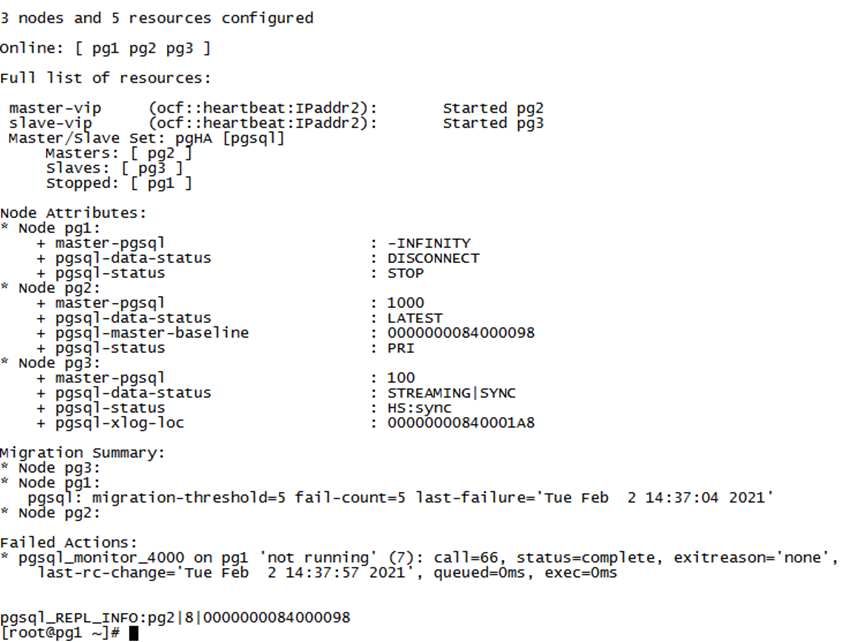
3.一般情况下会有fail-count告警,可以尝试通过resource cleanup 恢复异常节点的集群状态:
pcs resource cleanup pgsql --node 节点名;
4. 如果异常节点集群状态未恢复,可能为集群主备发生切换,需要清理异常节点的锁文件,可 以尝试删除锁文件后再执行第3步的命令:
rm -f /var/lib/pgsql/tmp/PGSQL.lock;
pcs resource cleanup pgsql --node 节点名;
5. 如果还是不成功,则可能是数据库的baseline发生变化,或主节点的wal日志文件以及归档,备节点启动时无法找到文件,可以查看数据库日志分析具体原因,
数据库日志目录:
pg10.5:/pgdb/pgdata/log
pg11.6:/pglog
则需要重构异常备节点:
rm -rf /pgdb/pgdata
cls_rebuild_slave
立即查看更多postgresql的相关内容
运维工作中遇到难题?立即提交工单。小亦平台工程师火速响应,助您快速修复故障!