小杰python高级(six day)——pandas库
1.数据可视化
用于绘制 DataFrame 数据图形,它允许用户直接从 DataFrame 创建各种类型的图表,而不需要使用其他绘图库(底层实际上使用了 Matplotlib)。
(1)plot
DataFrame.plot(*args, **kwargs)
功能:绘制各种线图
参数:kind: 图表类型,可以是以下之一:
'line': 折线图(默认)
'bar': 柱状图
'barh': 水平柱状图
'hist': 直方图
'box': 箱线图
'kde': 核密度估计图
'area': 面积图
'pie': 饼图
'scatter': 散点图
'hexbin': 六边形箱图
x:指定X轴数据(列名或索引)
y:指定y轴数据(列名或列名列表)
ax: Matplotlib 子图对象
subplots:是否绘制子图,True绘制子图
figsize: 图表的尺寸,格式为 `(width, height)`,单位为英寸。
use_index: 是否使用 pandas 的索引作为 x 轴标签。默认为 `True`。
title: 图表的标题。
grid: 是否显示网格线。默认为 `False`。
legend: 是否显示图例。默认为 `True`。
xticks: x 轴的刻度位置。
yticks: y 轴的刻度位置。
xlim: x 轴的范围,格式为 `(min, max)`。
ylim: y 轴的范围,格式为 `(min, max)`。
color: 绘制颜色,可以是单个颜色或颜色列表。
label: 图例标签。
data = {'name':['zhangsan','lisi','wangwu', 'json'],'age':[12, 14, 20, 14],'height':[30, 14, 20, 14]}
df = pd.DataFrame(data)
print(df)# 绘制柱状图
# 将df的name作为x轴标签,只绘制age数据
df.plot(kind='bar', x='name', y='age')
plt.show()
2.文件的读写
pandas.read_csv(filepath, sep=',', header='infer', usecols=None,...)功能:读取csv类型的文件 参数:filepath:读取的文件名 sep:字段分隔符,默认为逗号 header:指定第一行作为列名,默认为0(第一行) usecols:返回一个数据子集,需要读取的列pandas.read_excel(filepath, sheet_name=0, header=0, usecols=None, ...)功能:读取execl类型文件 参数:sheet_name:工作表名称或索引,默认为0(第一个工作表) 其他同上DataFrame.to_csv(path=None, sep=',', columns=None, index=True, ...)功能:将DataFrame写入csv类型的文件 参数:columns:要写入的列名列表index:是否写行(索引)名称。默认为True。DataFrame.to_excel(excel_writer, sheet_name='Sheet1', ...)功能:将DataFrame写入excel类型的文件 参数:同上
# 读csv文件
# df = pd.read_csv('./learn_pandas.csv', usecols=['School','Height'])
# print(df)
# 读excel文件
df = pd.read_excel('./item.xlsx', usecols=['order-info','order-info 2'])
print(df)
# 写excel文件
df.to_excel('test.xlsx')
3.爬虫工具
1.简介
Instant Data Scraper插件是一款功能强大的数据抓取工具,主要用于从网页上自动提取数据。
Instant Data Scraper插件能够自动检测并提取网页上的数据,包括但不限于产品信息、评论、价格等,这些数据可以被导出为Excel或CSV文件,方便用户进行进一步的分析和处理。此外,该插件还支持动态数据检测,能够确保提取的数据是最新的。
2.使用步骤
1.安装插件
1. 使用谷歌浏览器安装插件
在线访问可能访问不了,使用本地插件进行加载。
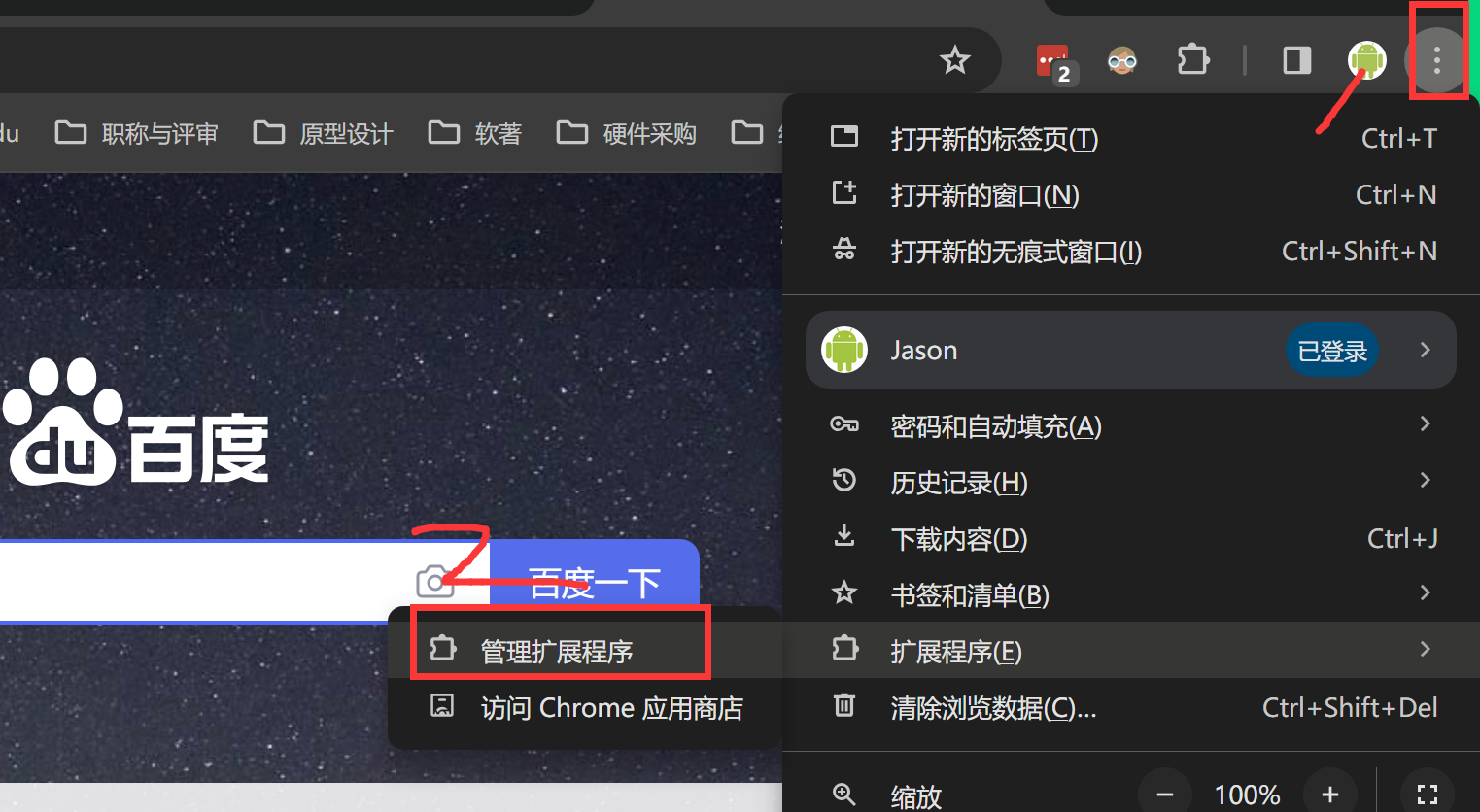
2.打开右上角
3.下载群里的 ,把插件的扩展名改为rar
,把插件的扩展名改为rar ,把文件夹解压缩。
,把文件夹解压缩。
4.回到Chrome浏览器中,点击下图,在弹出的窗口中选择刚才解压后的文件夹。
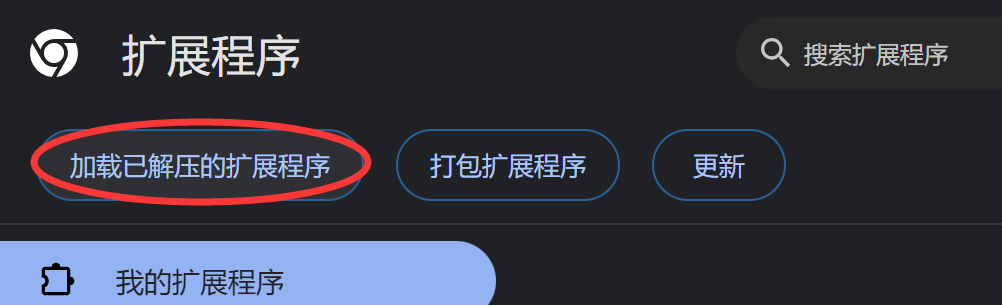 5.找到这个图标,将精灵球固定在任务栏
5.找到这个图标,将精灵球固定在任务栏
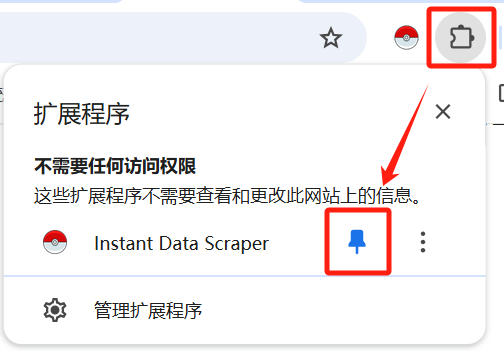
2.数据爬取
打开任意要爬取的网址
点击 告诉爬虫程序翻页键在哪里,再次点击
告诉爬虫程序翻页键在哪里,再次点击 。
。
点击 开始爬取,点击
开始爬取,点击 下载爬取数据。
下载爬取数据。
点击 可以停止爬取。
可以停止爬取。
4.三个库的总结
(1)numpy库
- 创建:ndarray = array
empty、zeros、ones、full、fill
arange、linspace、random(rand、random、randint、randn、normal、uniform、shuffle)
- 访问:下标、切片
- numpy数据类型:基本数据类型i4 S10、结构化数据类型[(键名,类型),()]
- 属性:ndim、shape、size、dtype
修改属性:astype类型、reshape形状、np.resize/arr.resize、flatten、T
- 运算:
算术运算:+ - * / **0.5 add\subtract/multiply/divide/powrer
广播机制:
矩阵运算:@ dot
逻辑运算:& | ~
关系运算:==
统计运算:sum、mean、max、min(argmax、argmin)、cumsum、cumprod、var、std
数学函数:sin/cos/tan、exp/exp2、log/log2
排序:sort()[::-1]
- 数组操作
添加删除:append/insert/delete
修改数组维度:expand_dims升维、squeeze降维
数组连接:concatenate、stack
数组分割:split
where函数:根据条件筛选数据
(2)matplotlib库
pyplot:绘图函数:plot、bar/barh、scatter、pie、hist、contour
设置属性:title、xlabel、ylabel、legend、subplot、tight_layout、subplots
操作函数:savefig、imread、imshow、imsave、close、pause
Line2D对象:set_data\get_label
Figure对象:创建:隐式、显示(figure())
操作:add_subplot\suptitle\add_axes\subplots_adjust\get_size_inches\clear
Axes对象:获取对象:plt.gca plt.gcf
操作:set_xlim/set_ylim、set_xlabel/set_ylabel、set_title、text
GridSpec对象:绘制子图网格 GridSpec
(3)pandas库
- 数据结构
Series:创建、访问(位置、标签、切片、函数get/head/tail/isin)、属性(value\index\dtype\shape\size\name\hasnans\is_unique\empty\axes)
DataFrame:创建、访问([列]、loc、iloc)、属性(index/columns/values/dtypes/ndim/T)
- 数据操作
数据清洗:dropna/fillna/isnull/drop_duplicates
数据转换:replace、transform
数据排序:sort_values、sort_index
数据筛选:根据关系运算结果或布尔数组进行筛选
数据拼接:concat
统计运算:sum、mean、count、max、min、var、std、quantile、describe、value_counts
分组聚合:gropby、agg
数据可视化:plot
文件读写:read_csv/read_excel/to_csv/to_excel