CVPR 2025 | 北大团队SLAM3R:单目RGB长视频实时重建,精度效率双杀!
北京大学陈宝权团队联合香港大学等推出的实时三维重建系统SLAM3R,首次实现从单目RGB长视频中实时且高质量重建场景稠密点云。该系统通过前馈神经网络无缝集成局部3D重建与全局坐标配准,提供端到端解决方案,使用消费级显卡(如4090D)即可达20+ FPS性能,重建点云的准确度和完整度达当前最先进水平,兼顾运行效率与重建质量。该研究成果被 CVPR 2025 评为 Highlight 论文,并在第四届中国三维视觉大会(China3DV 2025)上被评选为年度最佳论文(TOP1)。
本篇论文的相关即插即用模块和代码论文,感兴趣的dd~
论文这里
2. 【论文基本信息】

- 论文标题:SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
- 作者:Yuzheng Liu、Siyan Dong、Shuzhe Wang、Yingda Yin、Yanchao Yang、Qingnan Fan、Baoquan Chen(其中Yuzheng Liu和Siyan Dong为共同第一作者)
- 论文链接:https://arxiv.org/pdf/2412.09401
- 项目链接:https://github.com/PKU-VCL-3DV/SLAM3R
3.【背景及相关工作】
3.1 研究背景
- 密集3D重建需解决场景几何结构捕捉问题,传统多阶段方法依赖离线处理,适用性受限。
- 现有密集SLAM方法在精度、完整性、效率中至少存在一项缺陷;单目SLAM系统常效率低下,如NICER-SLAM速度远低于1 FPS。
- 双视图几何方法(如DUSt3R)有潜力,但多视图扩展需全局优化,效率不足;Spann3R虽加速重建,却导致累积漂移和质量下降。
3.2 相关工作
- 传统离线方法:通过SfM和MVS实现重建,神经隐式等表示提升质量,但需离线处理,无法实时应用。
- 密集SLAM:早期方法侧重实时性但结构稀疏;现有方法虽融入几何信息,却存在重建不完整、依赖深度传感器等问题;单目系统运行慢,且依赖相机姿态与场景表示交替求解策略。
- 端到端密集3D重建:DUSt3R开创无相机参数的端到端流程,后续工作扩展至多领域,但多视图扩展效率低;Spann3R虽优化效率,却有累积漂移问题。
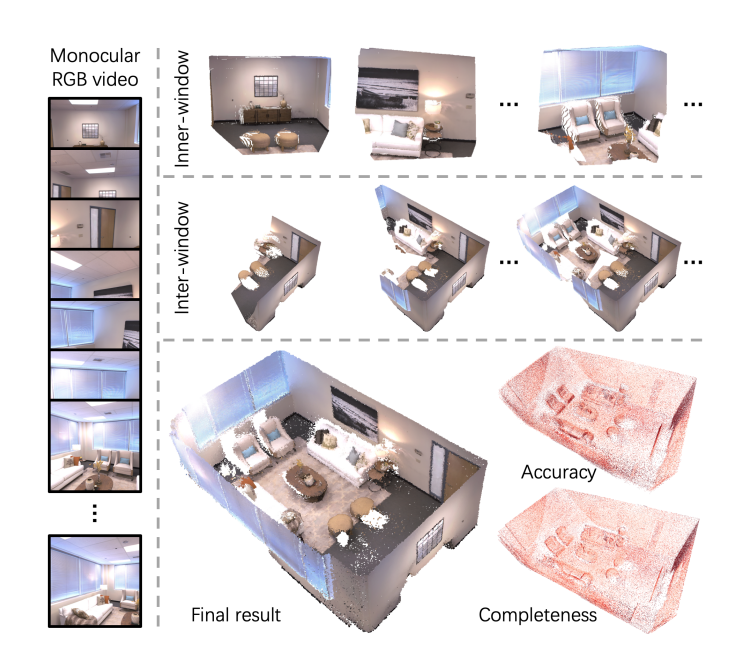
4. 【算法框架与核心模块】
4.1 算法框架
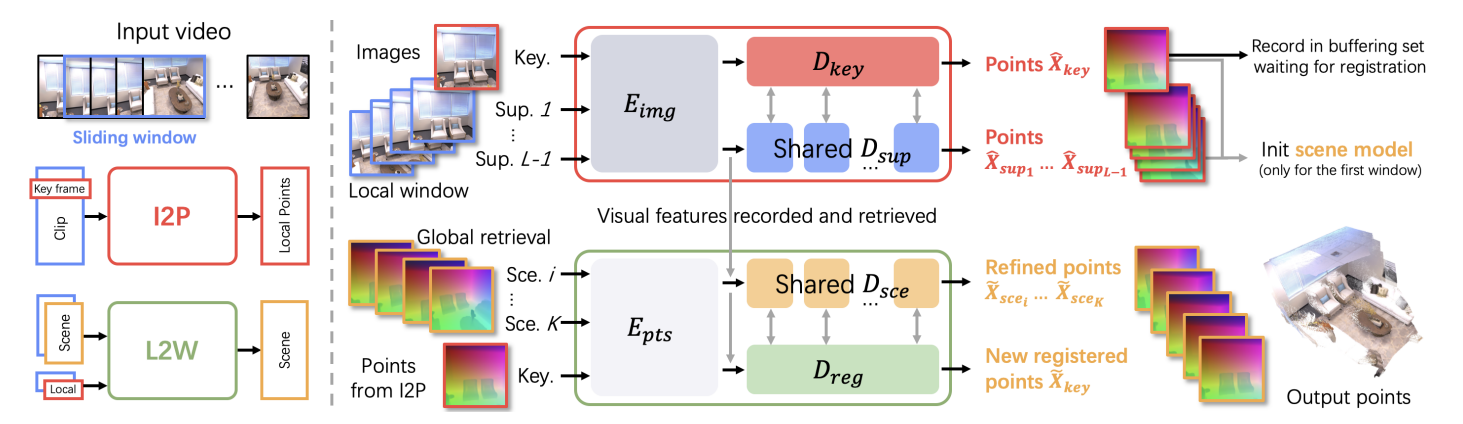
SLAM3R采用两级层次结构框架,通过滑动窗口机制将输入的单目RGB视频转换为重叠片段,先由Image-to-Points(I2P)网络从每个窗口中重建局部3D点云,再通过Local-to-World(L2W)网络将这些局部点云逐步配准到全局坐标系,形成一致的场景重建,全程无需显式求解相机参数。
4.2 核心模块
4.2.1 Image-to-Points(I2P)网络
- 功能:从视频片段中恢复局部3D点云,以窗口中的关键帧为参考坐标系。
- 结构:
-
图像编码器:采用多分支Vision Transformer(ViT),对窗口内的每个帧进行编码,得到特征令牌Fi(T×d)=Eimg(Ii(H×W×3)),i=1,...,LF_{i}^{(T × d)}=E_{i m g}\left(I_{i}^{(H × W × 3)}\right), i=1, ..., LFi(T×d)=Eimg(Ii(H×W×3)),i=1,...,L。
-
关键帧解码器:引入多视图交叉注意力机制,聚合支持帧信息,输出解码后的关键帧令牌Gkey=Dkey(Fkey,Fsup1,...,FsupL−1)G_{k e y}=D_{k e y}\left(F_{k e y}, F_{s u p_{1}}, ..., F_{s u p_{L-1}}\right)Gkey=Dkey(Fkey,Fsup1,...,FsupL−1)。
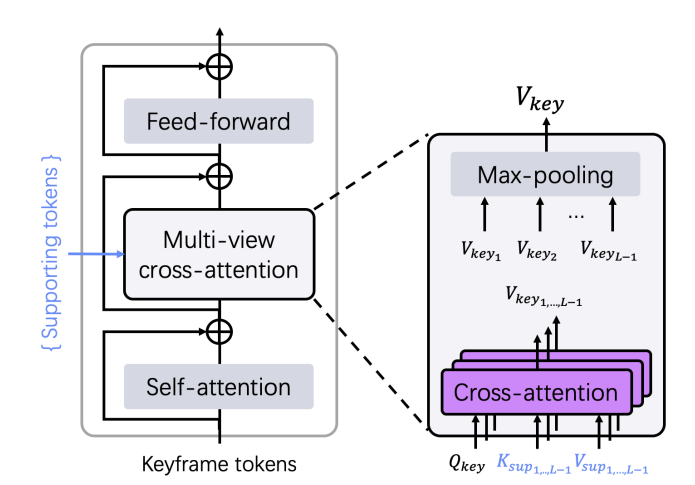
-
支持帧解码器:与关键帧交换信息,解码得到支持帧令牌Gsupi=Dsup(Fsupi,Fkey),i=1,...,L−1G_{sup _{i}}=D_{sup }\left(F_{sup _{i}}, F_{key }\right), i=1, ..., L-1Gsupi=Dsup(Fsupi,Fkey),i=1,...,L−1。
-
点云重建:通过线性头从解码令牌中回归3D点云和置信度图X^i(H×W×3),C^i(H×W×1)=H(Gi(T×d)),i=1,...,L\hat{X}_{i}^{(H × W × 3)}, \hat{C}_{i}^{(H × W × 1)}=H\left(G_{i}^{(T × d)}\right), i=1, ..., LX^i(H×W×3),C^i(H×W×1)=H(Gi(T×d)),i=1,...,L。
-
- 损失函数:置信度感知损失LI2P=∑i=1LMi⋅(C^i⋅L1(1z^X^i,1zXi)−αlogC^i)\mathcal{L}_{I 2 P}=\sum_{i=1}^{L} M_{i} \cdot\left(\hat{C}_{i} \cdot L 1\left(\frac{1}{\hat{z}} \hat{X}_{i}, \frac{1}{z} X_{i}\right)-\alpha log \hat{C}_{i}\right)LI2P=∑i=1LMi⋅(C^i⋅L1(z^1X^i,z1Xi)−αlogC^i)。
4.2.2 Local-to-World(L2W)网络
- 功能:将局部3D点云增量配准到全局坐标系,维持全局一致性。
- 结构:
- 点云嵌入:对I2P输出的点云进行编码,与视觉特征融合Fi(T×d)=Fi(T×d)+Pi(T×d),i=1,...,K+1\mathcal{F}_{i}^{(T × d)}=F_{i}^{(T × d)}+\mathcal{P}_{i}^{(T × d)}, i=1, ..., K+1Fi(T×d)=Fi(T×d)+Pi(T×d),i=1,...,K+1。
- 注册解码器:将关键帧局部点云转换到全局坐标系,Gkey=Dreg(Fkey,Fsce1,...,FsceK)\mathcal{G}_{key }=D_{reg }\left(\mathcal{F}_{key }, \mathcal{F}_{sce _{1}}, ..., \mathcal{F}_{sce _{K}}\right)Gkey=Dreg(Fkey,Fsce1,...,FsceK)。
- 场景解码器:优化场景几何,Gscei=Dsce(Fscei,Fkey),i=1,...,K\mathcal{G}_{sce _{i}}=D_{sce }\left(\mathcal{F}_{sce _{i}}, \mathcal{F}_{key }\right), i=1, ..., KGscei=Dsce(Fscei,Fkey),i=1,...,K。
- 全局点云重建:输出全局坐标系下的点云和置信度图X~i(H×W×3),C~i(H×W×1)=H(Gi(T×d)),i=1,...,K+1\tilde{X}_{i}^{(H × W × 3)}, \tilde{C}_{i}^{(H × W × 1)}=H\left(\mathcal{G}_{i}^{(T × d)}\right), i=1, ..., K+1X~i(H×W×3),C~i(H×W×1)=H(Gi(T×d)),i=1,...,K+1。
- 损失函数:无需尺度归一化的置信度损失LL2W=∑i=1LMi⋅(C~i⋅L1(X~i,Xi)−αlogC~i)\mathcal{L}_{L 2 W}=\sum_{i=1}^{L} M_{i} \cdot\left(\tilde{C}_{i} \cdot L 1\left(\tilde{X}_{i}, X_{i}\right)-\alpha log \tilde{C}_{i}\right)LL2W=∑i=1LMi⋅(C~i⋅L1(X~i,Xi)−αlogC~i)。
4.2.3 检索与缓冲机制
- 缓冲集:采用水库采样策略维持已注册的场景帧,最多保留B个帧,新帧插入概率为B/idB/idB/id。
- 检索模块:基于I2P解码器块,计算关键帧与场景帧的相关分数Retrieval(Fkey(T×d),{Fscei(T×d)})Retrieval \left(F_{k e y}^{(T × d)},\left\{F_{s c e_{i}}^{(T × d)}\right\}\right)Retrieval(Fkey(T×d),{Fscei(T×d)}),选择top-K场景帧作为参考。
4.3 模块配置
- I2P训练:输入长度为11的视频片段,中间帧为关键帧,训练100个epoch,初始化权重来自DUSt3R预训练模型。
- L2W训练:窗口大小设为13,训练200个epoch,使用无尺度归一化的损失函数。
- 检索模块:冻结其他模块,训练20个epoch,采用L1损失监督相关分数。
- 窗口与采样:滑动窗口步长为1,训练图像裁剪为224×224像素,使用8块NVIDIA 4090D GPU训练。
5.【实验结果】
5.1 数据集与实现细节
- 训练用ScanNet++、Aria Synthetic Environments、CO3D-v2混合数据,共约880K片段;在7 Scenes、Replica上定量评估,还测试了多种数据集和野外视频以验证泛化能力。
- 模型基于DUSt3R架构修改,用其预训练权重初始化。I2P训练100 epoch(约6小时),L2W训练200 epoch(约15小时),检索模块训练20 epoch;训练图像裁剪为224×224,用8块NVIDIA 4090D GPU。
5.2 对比实验
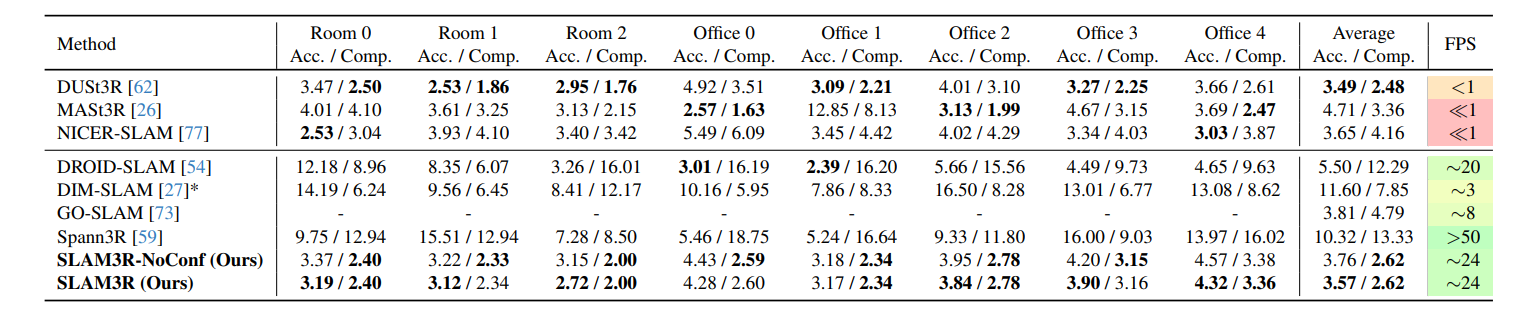
- 用精度、完整性、FPS评估,通过Umeyama算法和ICP对齐预测与真实点云。

- 7 Scenes数据集:SLAM3R在精度、完整性上优于DUSt3R、MASt3R、Spann3R,保持∼25 FPS,漂移更小。

- Replica数据集:SLAM3R超过DUSt3R、NICER-SLAM等方法,∼24 FPS,重建质量接近优化方法。
5.3 分析实验
-
I2P模型:支持视图增加,重建质量提升,窗口超11后效率下降,故用窗口大小11。
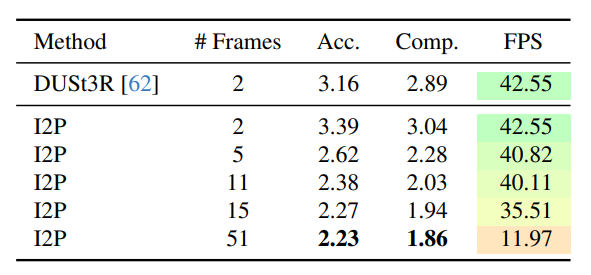
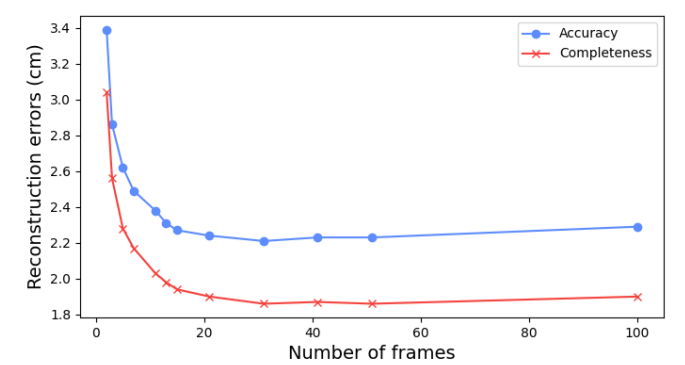
-
L2W模型:I2P+L2W+Re在对齐精度和效率上优于全局优化、传统方法。
-
检索模块:比仅选最近帧的方法性能更优。
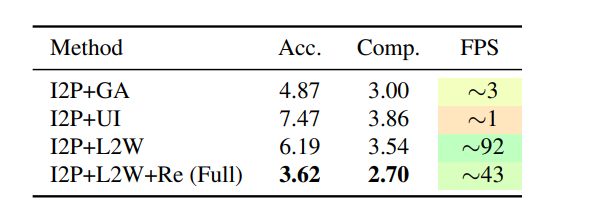
-
野外场景:在多种数据集上表现可靠,泛化能力强。

6.【总结展望】
6.1 总结
本文提出了SLAM3R,一种新颖高效的单目RGB SLAM系统,可实现实时高质量的密集3D重建。该系统采用双层级神经网络框架,通过高效的前馈过程实现端到端3D重建,无需显式求解相机参数。实验表明,SLAM3R在多个数据集上均达到了最先进的重建精度和完整性,同时保持20+ FPS的实时性能,弥合了RGB-only密集场景重建中质量与效率之间的差距。
6.2 展望
当前系统因未显式求解或优化相机参数,无法进行全局光束平差,在大规模户外场景中仍面临累积漂移的挑战。未来工作将重点解决这一局限性,进一步提升系统在复杂场景下的稳定性和准确性。
7.【快速上手指南】
7.1 安装
克隆仓库并进入目录:
git clone https://github.com/PKU-VCL-3DV/SLAM3R.git
cd SLAM3R
创建并激活环境:
conda create -n slam3r python=3.11 cmake=3.14.0
conda activate slam3r
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
可选加速配置:
pip install xformers==0.0.28.post2
cd slam3r/pos_embed/curope/
python setup.py build_ext --inplace
cd ../../../
7.2 演示
Replica数据集演示:
# 下载样本场景至./data/Replica_demo/
bash scripts/demo_replica.sh
自定义数据演示:
# 下载户外数据至./data/wild/
bash scripts/demo_wild.sh
# 可视化
bash scripts/demo_vis_wild.sh
Gradio界面:
python app.py
7.3 评估
在Replica数据集上评估:
cd data
wget https://cvg-data.inf.ethz.ch/nice-slam/data/Replica.zip
unzip Replica.zip && rm -rf Replica.zip
python evaluation/process_gt.py
bash ./scripts/eval_replica.sh
7.4 训练
准备数据集和预训练权重后:
mkdir checkpoints
wget https://download.europe.naverlabs.com/ComputerVision/DUSt3R/DUSt3R_ViTLarge_BaseDecoder_224_linear.pth -P checkpoints/
bash ./scripts/train_i2p.sh
bash ./scripts/train_l2w.sh