java集合之单列集合
目录
一、集合概述
1、集合
①基础概念
②与数组的对比
③集合分类:
2、集合框架
①基础概念
②三要素
③集合框架继承体系图(重要部分,并非全部)
二、单列集合
1、概述
2、Collection接口
①Collection基础方法
②Collection泛型参数方法补充
3、List接口
①特点:
②常用方法:
③实现类:
1> ArrayList
2> LinkedList
3> Vector
4、Set接口
①特点:
②常用方法:
③实现类:
1> HashSet
2> TreeSet
排序规则
3> LinkedHashSet
大学生入门:引用数据类型——数组及其易踩坑的点-CSDN博客![]() https://blog.csdn.net/qq_73698057/article/details/149564809?spm=1001.2014.3001.5502
https://blog.csdn.net/qq_73698057/article/details/149564809?spm=1001.2014.3001.5502
数组特点:
长度固定:
创建时需要指定长度,并且长度在创建后不可改变
相同数据类型:
例如int数组只能存储int类型的数据
连续内存分配:
堆空间为数组开辟的内存是连续的
导致在插入和删除元素时需要元素整体移动,效率低下
随机访问:
由于数组中的元素在内存中是连续存储的
可以通过索引来访问,时间复杂度为O(1)
显而易见
如果我们要存储多个数据类型不一致
或者个数不固定时
数组就无法满足我们的需求了
这时就需要使用 java 提供的集合框架了
一、集合概述
1、集合
①基础概念
java中,集合是一种用于存储和操作一组对象的数据结构
它提供了一组接口和类,用于处理和操作对象的集合
②与数组的对比
为了更好地理解集合,我们把集合和数组放在一起来看:
首先他们都可以存储多个元素值
区别在于:
1. 数组的长度是固定的
集合的长度是可变的
2. 数组中存储的是同一类型的元素
集合中存储的数组可以是不同类型的
3. 数组可以存放基本类型数据或引用类型变量
集合中只能存放引用类型变量
4. 数组除了拥有 length属性 和 从Object中继承过来的方法之外,数组对象调用不了其他的属性和方法了
集合框架由 java.util 包下多个接口和实现类组成,定义并实现了很多方法,功能强大
只能存引用类型变量?
那下面这些情况是怎么回事?
collection.add(1);
int a = 1;
collection.add(a);
Integer integer = 1;
collection.add(integer);
实际情况是
前两种自动装箱
最后一种直接存储 Integer 对象
所以“集合只能存储引用类型”这个说法是正确的

③集合分类:
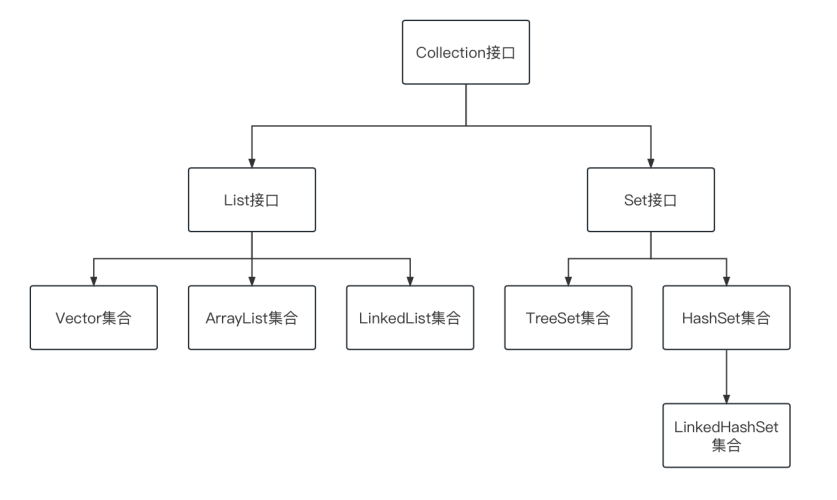
1.单列集合(Single Column Collection)
根接口: java.util.Collection
单列集合是指每个集合元素只包含一个单独的对象,它是集合框架中最简单的形式
Collection接口结构图(重要部分,并非全部):
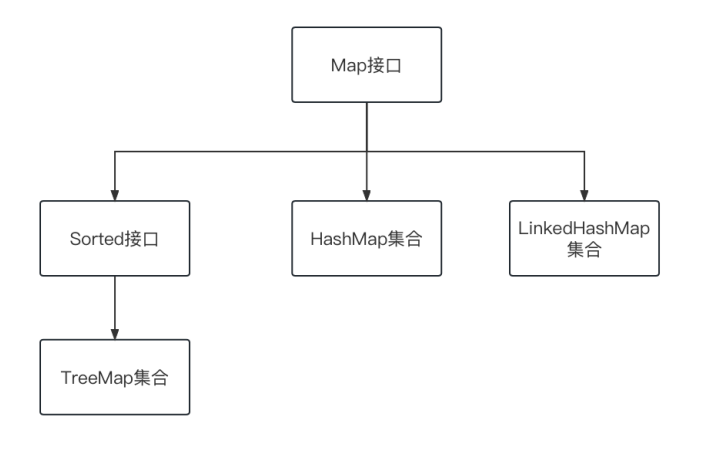
1.多列集合(Multiple Column Collection)
根接口: java.util.Map
多列集合是指每个集合元素由多个列(字段)组成,可以同时存储和操作多个相关的值
Map接口结构图如下(重要部分,并非全部):
2、集合框架
①基础概念
集合框架
java中用于表示和操作集合的一组类和接口
位于 java.util 包中
包括:
Collection 集合接口
List 列表接口
Map 映射接口
Set 类
... ...
目的:
提供一种通用的方式来存储和操作对象的集合
无论集合的具体实现方式如何
用户都可以使用统一的接口和方法来操作集合
怎么理解 集合 和 集合框架 呢 ?
如果把一个个集合看作一个个收纳盒
那么集合框架就是 收纳指南
上面记录了:
不同类型的收纳盒、
统一的操作标准、
还有现成的使用方法
②三要素
1.接口
整个集合框架的上层结构,都是用接口进行组织的
接口中定义了集合中必须要有的基本方法
通过接口还把集合划分成了几种不同的类型,每一种集合都有自己对应的接口
2、实现类
对于上层使用接口划分好的集合种类,每种集合接口都会有对应的实现类
每一种接口的实现类很可能有多个,每个的实现方式也各有不同
3、数据结构
每个实现类都实现了接口中所定义的最基本的方法
例如对数据的存储、检索、操作等方法
但是不同的实现类,它们存储数据的方式不同,也就是使用的数据结构不同
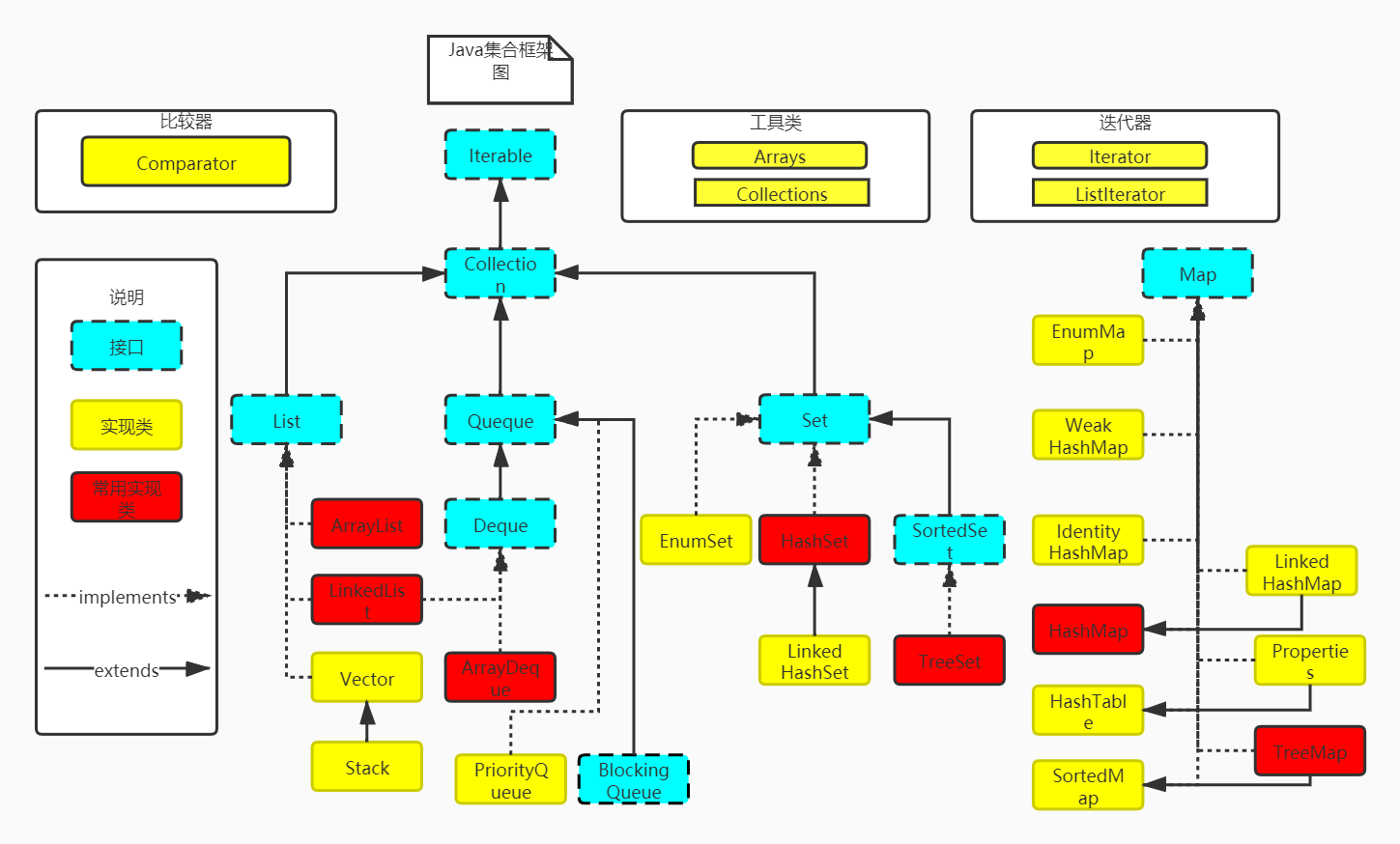
③集合框架继承体系图(重要部分,并非全部)
二、单列集合
1、概述
单列集合是指每个集合元素只包含一个单独的对象
单列集合的根接口是 java.util.Collection
根接口下面又有两个子接口:List 和 Set
如何理解这句话呢?
我们把单列和多列放一起比较
就好比有一个班级花名册
单列集合每一行只有单独的名字信息,而多列集合一行有多个信息:
单列 双列

再比如说有一列火车
单列火车是这样的:
[苹果车厢] [牛奶车厢] [面包车厢] [鸡蛋车厢] // 每节车厢只装一种商品双列火车是这样的:
[苹果-5元车厢] [牛奶-10元车厢] [面包-8元车厢] // 每节车厢装两种信息:商品名和价格
2、Collection接口
单列集合的父接口
其中定义了单列集合通用的一些方法
Collection接口的实现类都可以使用这些方法
①Collection基础方法
package java.util;
public interface Collection<E> extends Iterable<E> {//省略...//向集合中添加元素 boolean add(E e)//清空集合中所有的元素。 void clear()//判断当前集合中是否包含给定的对象。boolean contains(Object o)//判断当前集合是否为空。boolean isEmpty()//把给定的对象,在当前集合中删除。boolean remove(Object o)//返回集合中元素的个数。 int size()//把集合中的元素,存储到数组中。 Object[] toArray()
}示例:
import java.util.ArrayList;
import java.util.Collection;public class Test {// 集合中 一般 也放 同一种类型数据public static void main(String[] args) {// 1.接口 引用 = new 实现类(实参);Collection coll = new ArrayList();if (coll.isEmpty())System.out.println("coll is Empty!");// 2.任何引用类型都可以放入// 自动扩容coll.add("hello"); //StringInteger i = 12;coll.add(i);coll.add(2.3); // Doublecoll.add(1.2F); // Floatcoll.add('a'); // Characterint[] arr = { 1, 2, 3 };coll.add(arr); //int[]// coll.add(new Student());// 3.输出 coll.toString()System.out.println(coll);System.out.println("size: " + coll.size());System.out.println("--------------");// 4.清空 collcoll.clear();System.out.println(coll);// 5.判断是否为空if (coll.isEmpty())System.out.println("coll is Empty!");elseSystem.out.println("coll is not empty!");}
}此时动手实操的同学会发现代码爆黄线了
为什么呢?
其实是我们的格式有点小问题
区别于之前的书写格式,集合是这样的:
接口类型<存储的数据类型> 接口引用名 = new 实现类<>(构造方法实参);
例: Collection<String> coll = new ArrayList<>();
还可以写成:
Collection<String> coll = new ArrayList<String>();
Collection coll = new ArrayList();
需要注意的是,前两种明确了数据类型,就只能存储这一种
第三种可以存储多种,但是一般情况下存储一种数据类型
②Collection泛型参数方法补充
package java.util;
public interface Collection<E> extends Iterable<E> {//省略... //把一个指定集合中的所有数据,添加到当前集合中 boolean addAll(Collection<? extends E> c)//判断当前集合中是否包含给定的集合的所有元素。 boolean containsAll(Collection<?> c)//把给定的集合中的所有元素,在当前集合中删除。 boolean removeAll(Collection<?> c)//判断俩个集合中是否有相同的元素,如果有当前集合只保留相同元素,如果没有当前集合元素清空 boolean retainAll(Collection<?> c)//把集合中的元素,存储到数组中,并指定数组的类型 <T> T[] toArray(T[] a)//返回遍历这个集合的迭代器对象 Iterator<E> iterator()
}
示例:
import java.util.ArrayList;
import java.util.Collection;
//泛型方法测试
public class Test03_Element {public static void main(String[] args) {//1.实例化两个集合对象,专门存放String类型元素// 集合实例化对象 固定写法Collection<String> c1 = new ArrayList<>();Collection<String> c2 = new ArrayList<>();//2.分别往c1和c2集合中添加元素String s1 = "hello";String s2 = "world";c1.add(s1);c1.add(s2);String s3 = "nihao";String s4 = "hello";String s5 = "okok";c2.add(s3);c2.add(s4);c2.add(s5);System.out.println("c1: " + c1);System.out.println("c2: " + c2);System.out.println("-------------");//3.将c2集合整体添加到c1中c1.addAll(c2);System.out.println("c1.size: " + c1.size());System.out.println("after addAll(c2), c1: " + c1);System.out.println("-------------");//4.判断是否包含指定元素boolean f = c1.contains("hello");System.out.println("contains hello: " + f);//5.创建s6对象,判断集合中是否包含该对象// 注意: s6的地址 和 "world"地址不一样// s6是堆中临时new出来的,"world"存在堆中的字符串常量池中String s6 = new String("world");// 结果显示true,说明集合contains方法借助equals方法进行比较,而非 ==f = c1.contains(s6);System.out.println("contains(s6): " + f);System.out.println("-------------");//6.判断是否包含c2对象f = c1.containsAll(c2);System.out.println("containsAll(c2): " + f);System.out.println("-------------");//7.删除指定元素【底层借助equals比较,然后删除】f = c1.remove(s6);System.out.println("remove(s6): " + f);System.out.println("after remove, c1: " + c1);System.out.println("-------------"); //8.删除c2整个集合【底层实现:遍历c2,逐个元素equals比较,然后删除】f = c1.removeAll(c2);System.out.println("removeAll(c2): " + f);System.out.println("after remove, c1: " + c1);}
}
3、List接口
继承了 Collection 接口
①特点:
——有序集合
——带索引的集合,可以通过索引精确查找对应元素
——可以存放重复元素(包括null)
——默认尾部添加元素
②常用方法:
除了从 Collection 中继承过来的方法,除此之外还有:
//返回集合中指定位置的元素。
E get(int index);//用指定元素替换集合中指定位置的元素,并返回被替代的旧元素。
E set(int index, E element);//将指定的元素,添加到该集合中的指定位置上。
void add(int index, E element);//从指定位置开始,把另一个集合的所有元素添加进来
boolean addAll(int index, Collection<? extends E> c);//移除列表中指定位置的元素, 并返回被移除的元素。
E remove(int index);//查收指定元素在集合中的所有,从前往后查到的第一个元素(List集合可以重
复存放数据)
int indexOf(Object o);//查收指定元素在集合中的所有,从后往前查到的第一个元素(List集合可以重
复存放数据)
int lastIndexOf(Object o);//根据指定开始和结束位置,截取出集合中的一部分数据
List<E> subList(int fromIndex, int toIndex);示例:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class Test {public static void main(String[] args) {//1.创建List集合对象List<String> list = new ArrayList<>();//2.添加元素,默认尾部添加list.add("hello1");list.add("hello2");list.add("hello3");list.add("hello1");System.out.println(list);//3.指定位置添加元素// add(int index,String s) list.add(1, "world");System.out.println(list);//4.删除索引位置为2的元素boolean f = list.remove(2);System.out.println("remove(2): " + f);System.out.println("after remove: " + list);//5.修改指定位置元素list.set(0, "briup");System.out.println(list);//6.借助get方法遍历集合for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i)); }System.out.println("-----------------");//7.使用foreach遍历for(Object obj : list){System.out.println(obj);}System.out.println("-----------------");//8.使用迭代器遍历Iterator<String> it = list.iterator();while(it.hasNext()){String str = it.next();System.out.println(str);}}
}③实现类:
1> ArrayList
是 List 的一个实现类
是最常用的一种 List 类型集合
extends AbstractList<E> extends AbstractCollection<E>
特点:
1. ArrayList集合底层是数组,查询快,增删慢
适用业务场景:查询功能多,增删功能少
eg:学生管理系统
2. ArrayList集合线程不安全
代码示例与 LinkedList 放在一起对比
2> LinkedList
实现了List接口
extends AbstractSequentialList<E> extends AbstractList<E>
特点:
1. LinkedList 集合底层是双向链表,查询慢,增删快
适用业务场景:增删功能多,查询功能少
eg:浏览器的前进后退
2. LinkedList 集合线程也不安全
特点验证:
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;public class Test {public static void main(String[] args) {//操作集合的次数final int NUM = 100000;//1.实例化集合对象List<String> list = new ArrayList<>();//List<String> list = new LinkedList<>();//2.开启计时,往集合种放入 100000 个元素long start1 = System.currentTimeMillis();for (int i = 0; i < NUM; i++) {list.add(0,"hello"+i);}long end1 = System.currentTimeMillis();//3.输出时长System.out.println(list.getClass().getSimpleName()+"插入"+NUM+"条数据耗时"+(end1-start1)+"毫秒");//4.开启计时,从集合种取 100000 个元素long start2 = System.currentTimeMillis();for(int i = 0; i < list.size(); i++){list.get(i);}long end2 = System.currentTimeMillis();//5.输出时长System.out.println(list.getClass().getSimpleName()+"检索"+NUM+"条数据耗时"+(end2-start2)+"毫秒");}
}//运行效果:
//根据电脑的当前情况,每次运行的结果可能会有差异
//以下是我的电脑运行的实验结果ArrayList插入100000条数据耗时508毫秒
ArrayList检索100000条数据耗时2毫秒
LinkedList插入100000条数据耗时22毫秒
LinkedList检索100000条数据耗时17709毫秒System.currentTimeMillis();
//获取当前时刻的时间戳
3> Vector
实现了 List 接口
extends AbstractList<E> extends AbstractCollection<E>
特点:
1. Vector 集合底层是数组,查询快,增删慢
2. Vector 集合多线程安全,效率低
4、Set接口
继承了 Collection 接口
①特点:
——无序集合,不按 add 顺序添加元素
——不带下标(索引)
——元素不能重复
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;public class Test {public static void main(String[] args){//1.实例化Set集合,指向HashSet实现类对象Set<String> set = new HashSet<>();set.add("hello1");set.add("hello2");set.add("hello3");set.add("hello4");set.add("hello5"); //添加失败 重复元素set.add("hello5"); //添加失败 重复元素//加强for循环遍历for(String obj : set){System.out.println(obj);}System.out.println("-----------------");//迭代器遍历Iterator<String> it = set.iterator();while(it.hasNext()){Object obj = it.next();System.out.println(obj);}}
}//输出结果:
hello1
hello4
hello5
hello2
hello3
----------
省略...②常用方法:
基本都是Collection继承过来的,这里就不再赘述
③实现类:
1> HashSet
底层是哈希表
extends AbstractSet<E> implements Set<E>
特点:
1. 无序性:存储顺序和插入顺序无关
2. 唯一性:元素不重复,null也只能存一个
3. 高效性:哈希表的特点
需要注意的是,由于HashSet没有重写 equals方法 和 hashCode方法
所以存储 数据相同的自定义类的对象 时会认为它们是不同的
比如:
import java.util.*;class Student {private String name;private int age;public Student(String name, int age) {this.name = name;this.age = age;}// 注意:这里没有重写 equals 和 hashCode 方法@Overridepublic String toString() {return "Student{name='" + name + "', age=" + age + "}";}
}public class HashSetDuplicateExample {public static void main(String[] args) {Set<Student> set = new HashSet<>();// 添加四个"相同"的Student对象set.add(new Student("Alice", 20));set.add(new Student("Alice", 20));set.add(new Student("Alice", 20));set.add(new Student("Alice", 20));System.out.println("HashSet大小: " + set.size()); // 输出 4System.out.println("HashSet内容: " + set);}
}所以要往 HashSet 集合存储自定义类
一定要记得重写自定义类中的equals方法和hashCode方法
2> TreeSet
底层是二叉树
TreeSet是SortedSet(Set接口的子接口)的实现类
特点:
1. 有序性:插入的元素会自动排序
2. 唯一性:元素不重复,null也只有一个
3. 高效性:二叉树的特点
入门案例一:
import java.util.Set;
import java.util.TreeSet;public class Test{public static void main(String[] args){//1.实例化集合对象Set<Integer> set = new TreeSet<>();//2.添加元素set.add(3);set.add(5);set.add(1);set.add(7);//3.遍历for(Integer obj : set) {System.out.println(obj);} }
}//输出结果:
1
3
5
7截止这里一切都没有问题,我们继续往下看
入门案例二:
import java.util.Set;
import java.util.TreeSet;class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + "]";}
}public class Test_Person {public static void main(String[] args) {//1.实例化TreeSetSet<Person> set = new TreeSet<>();//2.添加元素set.add(new Person("zs",21));set.add(new Person("ls",20));set.add(new Person("tom",19));//3.遍历集合for (Person person : set) {System.out.println(person);}}
}//程序运行,提示异常,具体如下:
Exception in thread "main" java.lang.ClassCastException:
包名.Person cannot be cast to java.lang.Comparableat java.util.TreeMap.compare(TreeMap.java:1290)at java.util.TreeMap.put(TreeMap.java:538)at java.util.TreeSet.add(TreeSet.java:255)at
包名.Test_Person.main(Test_Person.java:41)看起来似乎没有问题啊
为什么会报错呢?
我们看一下报错原因:
ClassCastException:Person cannot be cast to java.lang.Comparable

原来是我们自定义的类没有实现 Comparable 接口
为什么会这样呢?
这就不得不引入新的知识点了:
排序规则
由于TreeSet是一个有序集合,那么想要有序必然要存在一定的规则
有两种方式:
1、自然排序
如果一个类实现了Comparable接口
并且重写了compareTo方法,那么这个类对象就可以进行排序了。
compareTo方法说明:
返回值:int
小于0:当前对象小,this.value < o.value
等于0:当前对象等于 this.value = o.value
大于0:当前对象大 this.value > o.value
调用者:当前对象的参数
实际参数:要比较的对象参数
调用方式:this.value.compareTo(o.value);
作用:
元素插入过程:先排序后去重
当TreeSet插入元素时会调用compareTo方法
如果方法返回-1,先插入this,o放后面
如果方法返回0,两个元素相等,只插入一个元素
如果方法返回1,先插入o,this放后面2、比较器排序
如果Student不是自定义类,而是第三方提供的类
我们不可以修改源码,就可以使用比较器排序
实现:
1、创建一个实现了 Comparator 接口的类
2、重写里面的 compare() 方法
3、创建一个 TreeSet 类对象时,将比较器对象作为参数传递给构造函数compare方法说明:
int result = compare(o1,o2);
——result的值大于0,表示升序
——result的值小于0,表示降序
——result的值等于0,表示元素相等,不能插入
注意:
如果自然排序和比较器排序同时存在
优先使用比较器排序
案例展示:
public class Teacher implements Comparable<Teacher>{private int id;private String name;private int age;public Teacher() {}public Teacher(int id, String name, int age) {this.id = id;this.name = name;this.age = age;}public int getId() {return id;}public String getName() {return name;}public int getAge() {return age;}@Overridepublic String toString() {return "Teacher [id=" + id + ", name=" + name + ", age=" + age + "]";}@Overridepublic int compareTo(Teacher o) {int num = this.name.compareTo(o.name);if(num == 0){num = this.age - o.age;}if(num == 0){num = this.id - o.id;}return num;}
}import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;public class TestTeacher {public static void main(String[] args) {//自然排序,Comparable接口Teacher t1 = new Teacher(001,"alan", 18);Teacher t2 = new Teacher(002,"tom", 19);Teacher t3 = new Teacher(003,"tom", 20);Teacher t4 = new Teacher(004,"alan", 18);Teacher t5 = new Teacher(005,"jack", 18);Set<Teacher> set = new TreeSet<>();System.out.println("自然排序:");set.add(t1);set.add(t2);set.add(t3);set.add(t4);set.add(t5);for(Teacher t : set){System.out.println(t);}//比较器排序,Comparator接口Comparator<Teacher> comparator = new Comparator<Teacher>() {@Overridepublic int compare(Teacher t1, Teacher t2){ int num = t1.getName().compareTo(t2.getName());if(num == 0){ num = t1.getAge() - t2.getAge();}if(num == 0){num = t1.getId() - t2.getId();}return num;}};Set<Teacher> set2 = new TreeSet<>(comparator);System.out.println("比较器排序:");set2.add(t1);set2.add(t2);set2.add(t3);set2.add(t4);set2.add(t5);for(Teacher t : set2){System.out.println(t);}}
}3> LinkedHashSet
底层是链表 + 哈希表
父类 HashSet 所以具有父类唯一、高效的优点
接口 Set 保持元素的插入顺序,不会自动排序
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;public class Test074_LinkedHashSet {public static void main(String[] args) {// 1.实例化LinkedHashSetSet<String> set = new LinkedHashSet<>();// 2.添加元素set.add("bbb");set.add("aaa");set.add("abc");set.add("bbc");set.add("abc");// 3.迭代器遍历Iterator<String> it = set.iterator();while (it.hasNext()) {System.out.println(it.next());}}
}//运行结果:
bbb
aaa
abc
bbc
