k8s中的控制器的使用
官方文档:
工作负载管理 | Kubernetes
控制器也是管理pod的一种手段
-
自主式pod:pod退出或意外关闭后不会被重新创建
-
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
负责整个集群中对于数量的监控的软件就是控制器,当有一台主机出现了错误,控制器会立刻,找一台新的主机来顶替它的工作
控制机常用类型
| 控制器名称 | 控制器用途 |
|---|---|
| Replication Controller | 比较原始的pod控制器,已经被废弃,由ReplicaSet替代 |
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行 |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力 |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象。 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs。 |
| HPA全称Horizontal Pod Autoscaler | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放 |
查看容器名称


名字不会一直叫这个
如果出现了故障退出,那每次启动时,名字都会变化,那这里就做不了主从复制,要解决就要把他的名字固定住,每次登录还是一样的名字
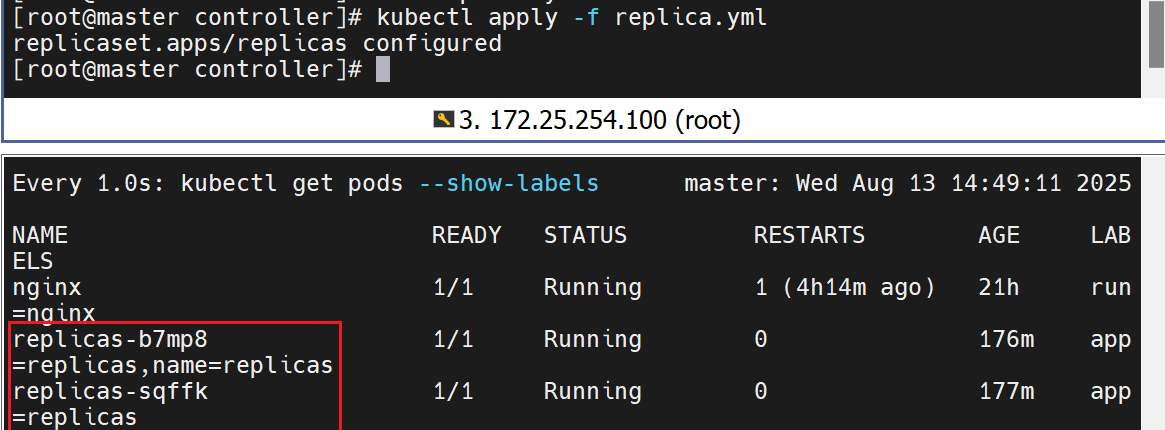
replicaset控制器
-
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
-
ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求
-
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
-
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
replicaset 示例

这里给控制器里做标签,是为了让微服务可以发现它
给容器写标签,是为了让控制器可以检测到它
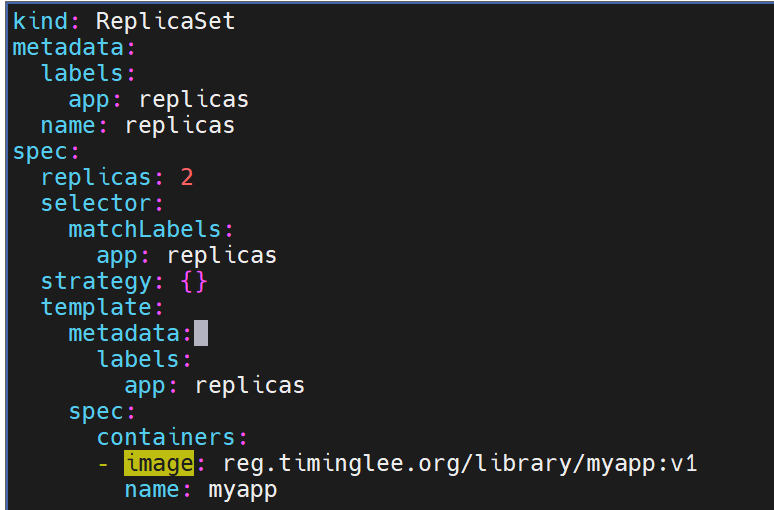

strategy(更新策略)是 Deployment 资源的字段,用于定义 Pod 滚动更新的策略(如RollingUpdate或Recreate)。而 ReplicaSet 作为更基础的控制器,并不支持strategy配置,因此在 ReplicaSet 的 YAML 中声明该字段会被 Kubernetes 拒绝
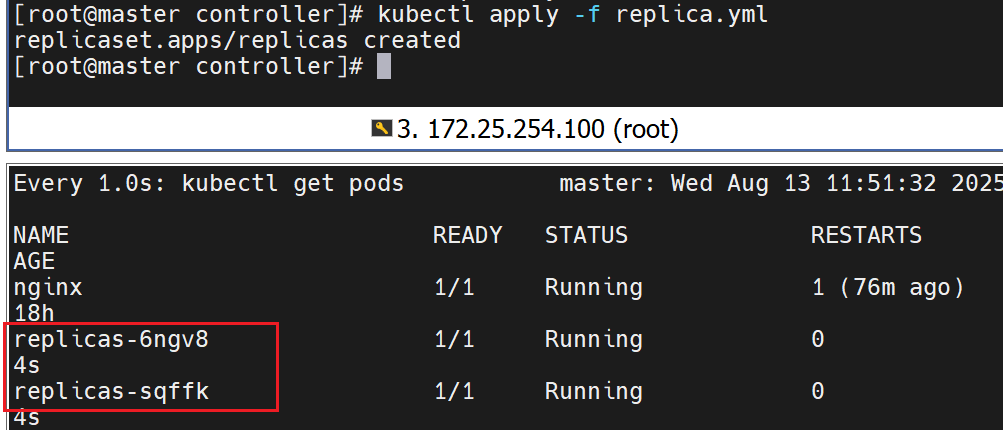
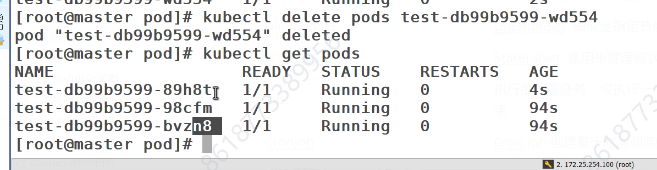
删除pods还会重新建一个
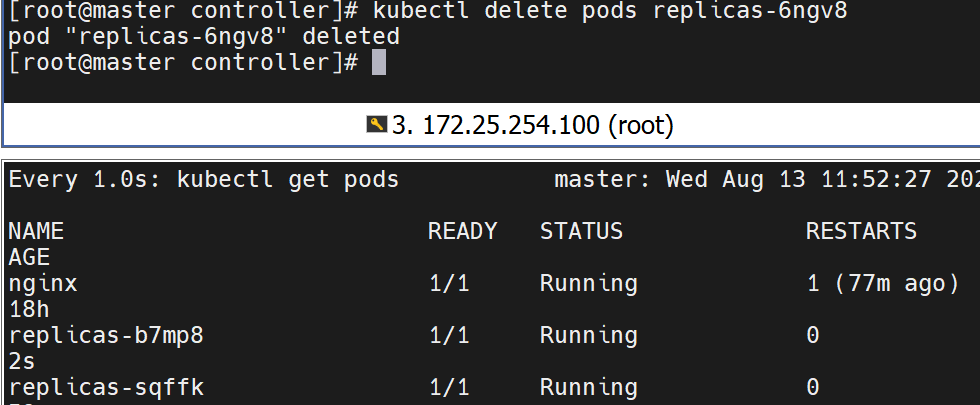
指定的标签不一致,就不算上这个不一致的了
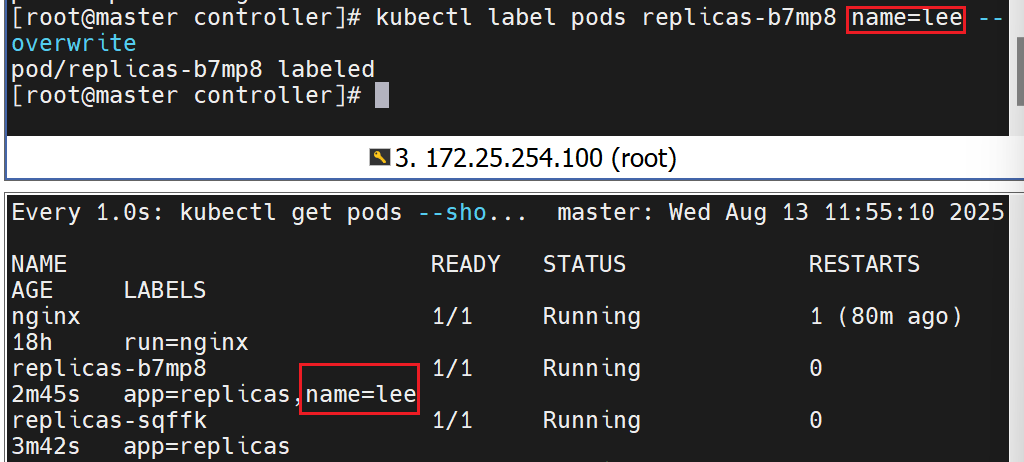
将其修改回去
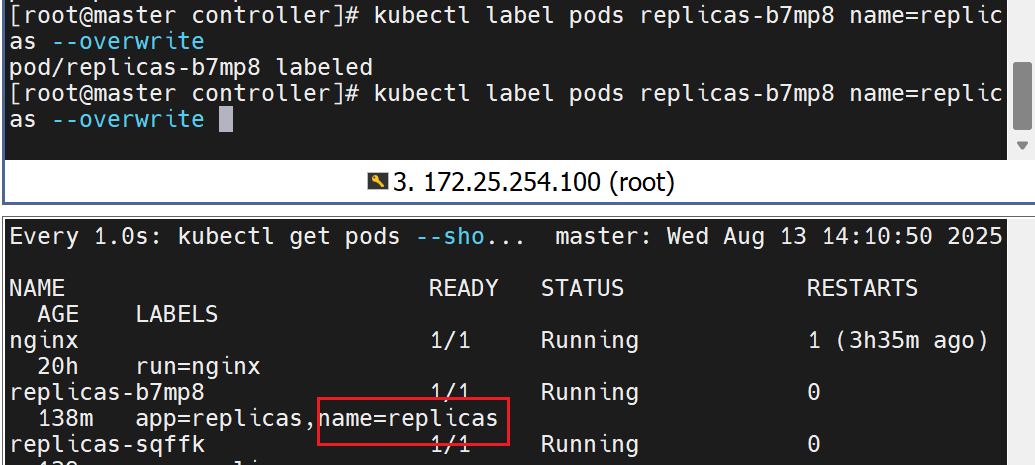
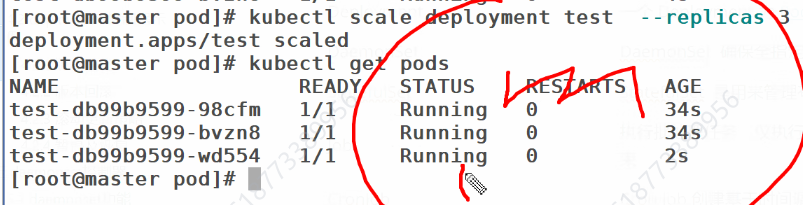
修改个数,可以拉伸也可以声明
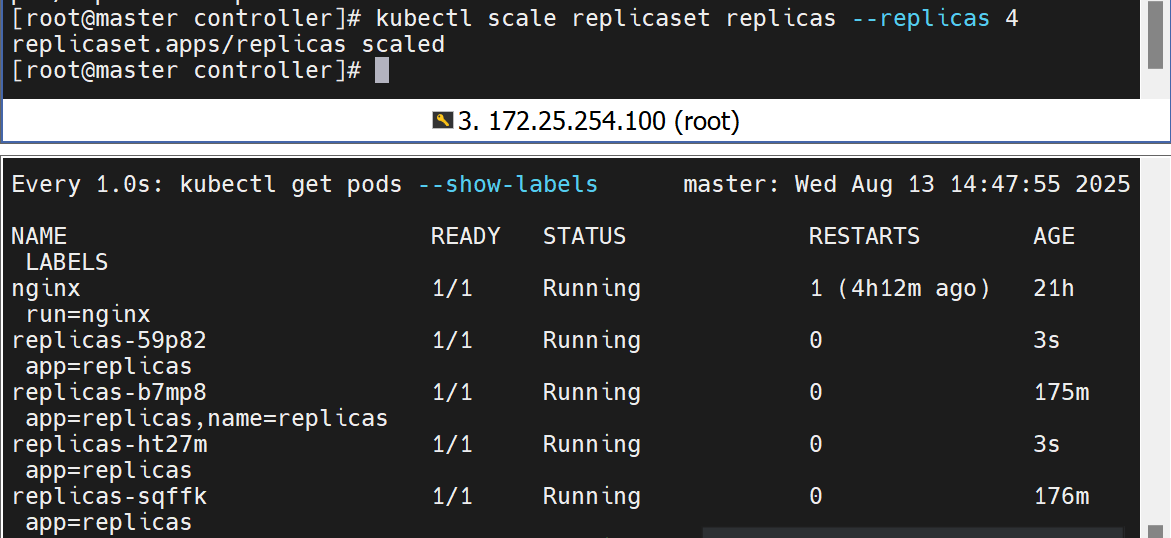
再次重启yml,会根据yml中的内容再次刷新个数
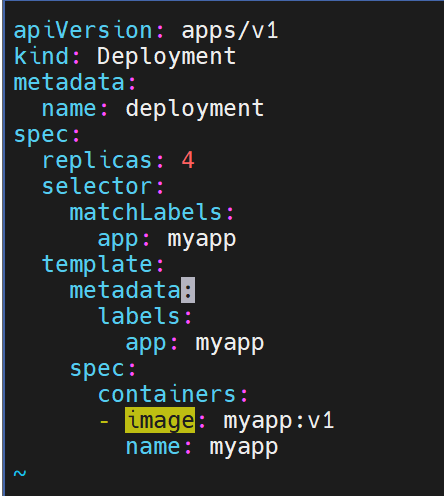
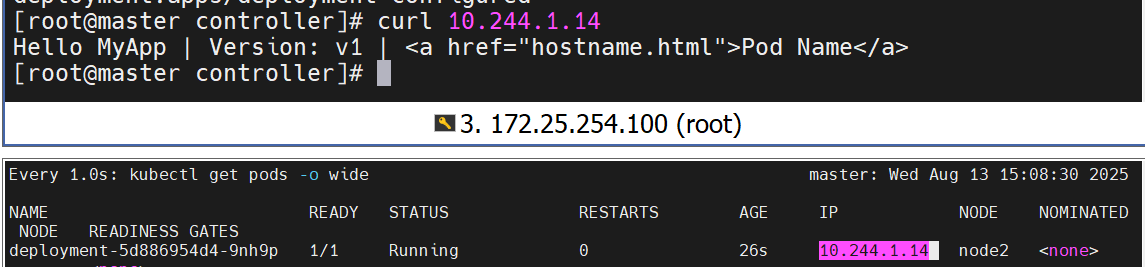
deployment 控制器


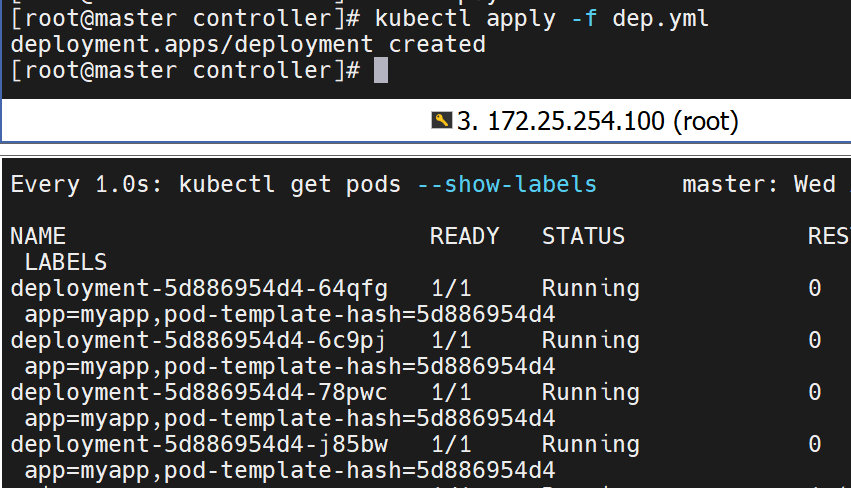

示例:版本更新
直接在编辑文件里声明就行
#pod运行容器版本为v1

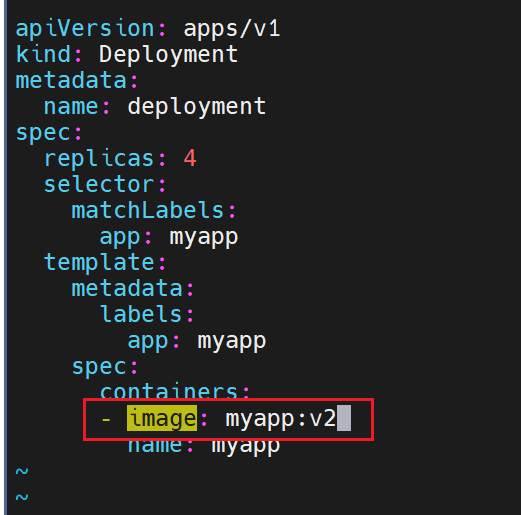
查看更新效果
更新的过程是重新建立一个版本的RS,新版本的RS会把pod 重建,然后把老版本的RS回收
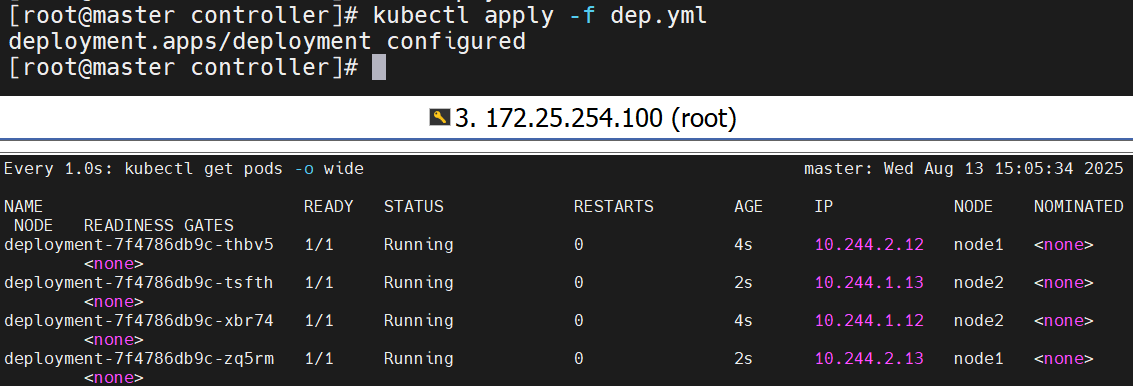
可以看到版本变化了
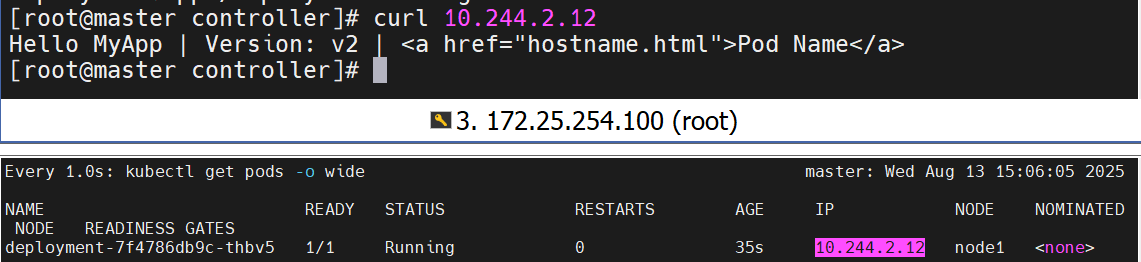
版本回滚
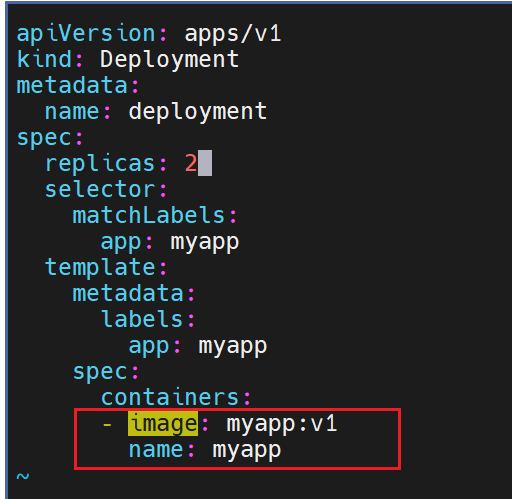
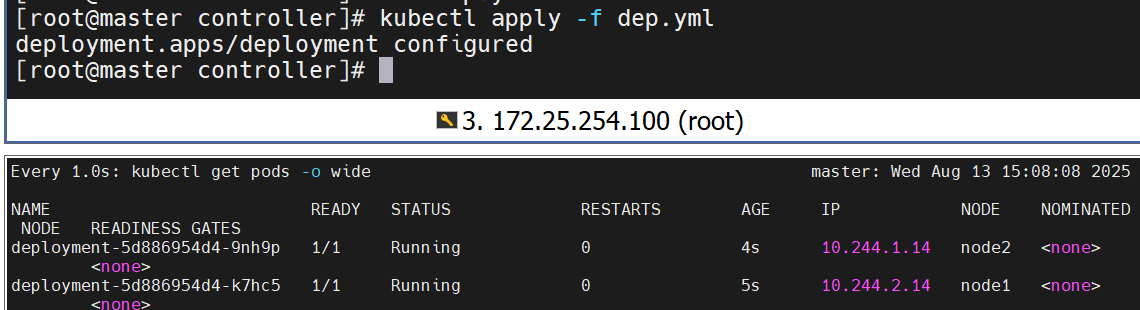
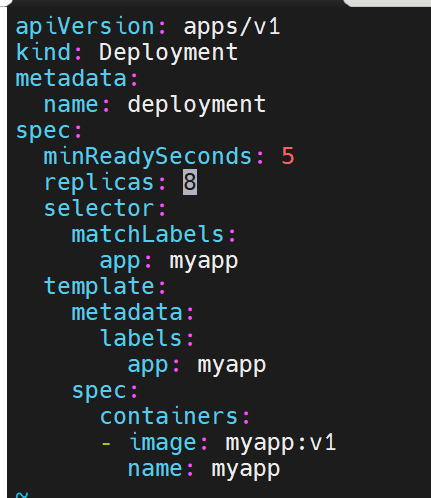
滚动更新策略
这次更新了一部分,下次更新就5秒一次,一共要更新8个

影响最小的,最丝滑的更新策略
更一个关一个
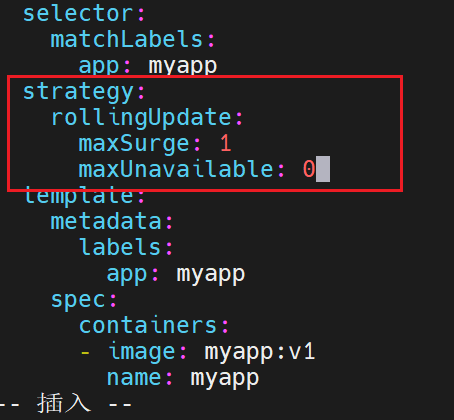
maxUn~~更新中不能用的是0个,这里就是不能有不能用的
暂停及恢复
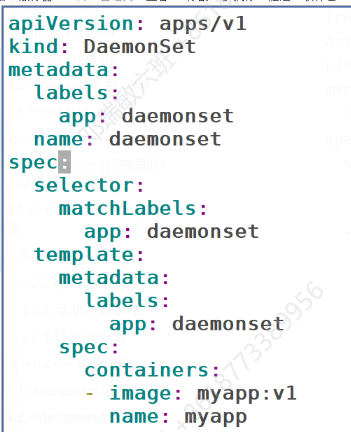
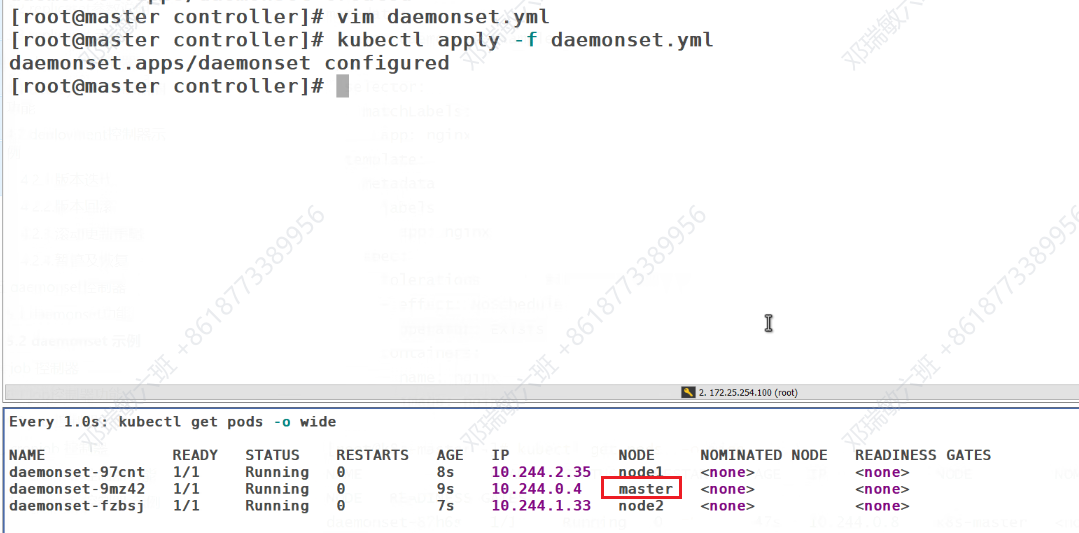
Deamonset控制器


过滤一下污点信息

现在只在master设定了污点,默认是不被调用的
我们的myapp是会在node1&2上都会有,但是master上是默认不会有的,因为是有污点的
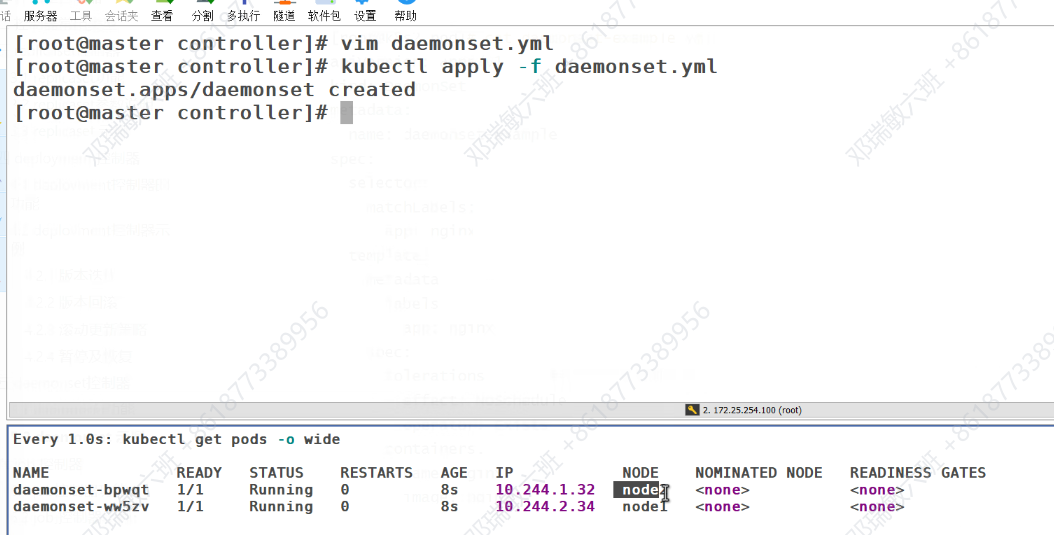
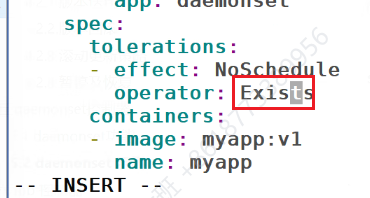
但是master上也不是不可以有,可以设置对污点的容忍度,就可以运行了
强容忍,即便有也不在乎
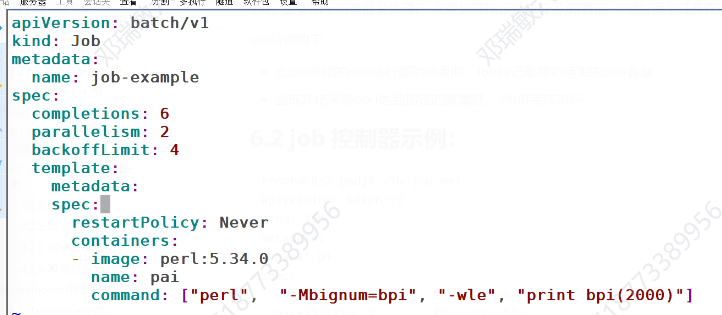
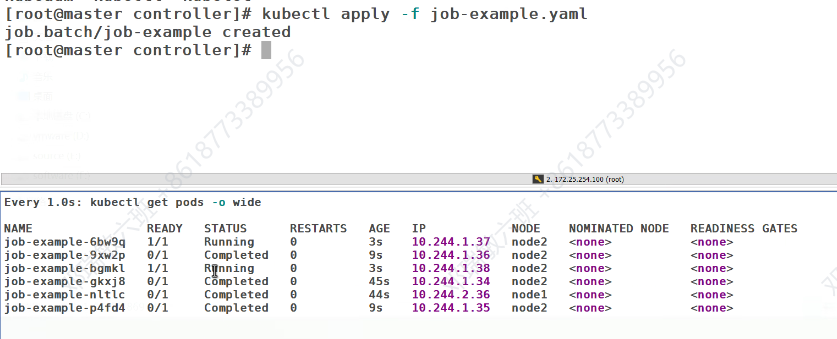
job 控制器

一共有几次任务,每次开机个pod,一共几轮完成,当pod运行了四次,都没成功就重新计数再来
退出了,做什么处理,如果停掉了,就什么都不做了
![]()

此时运行就是两个两个开始建立
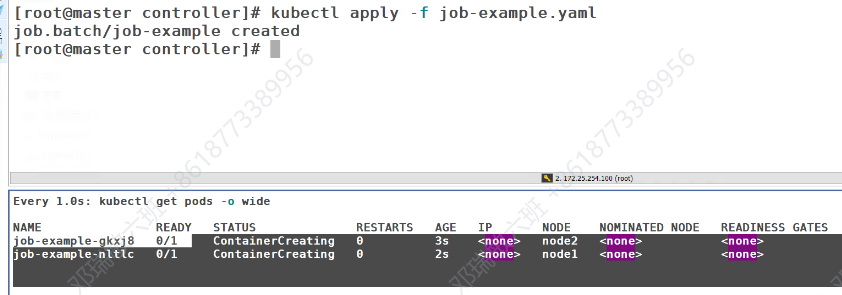
直到完成6个的创建
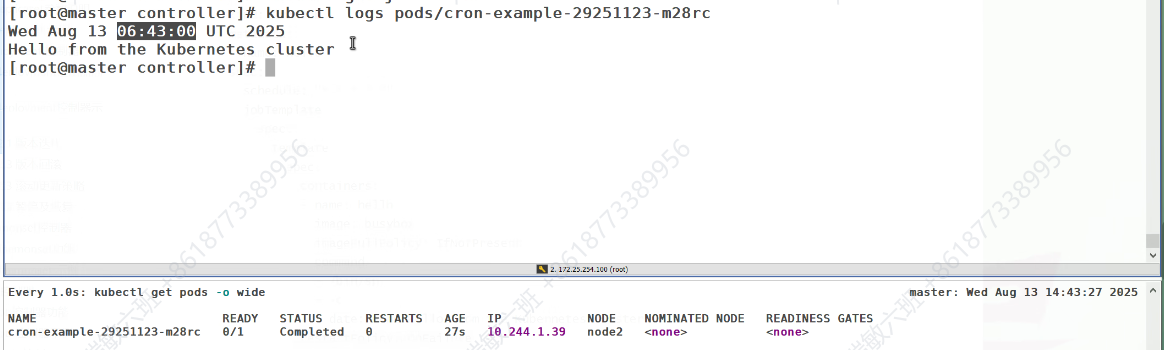
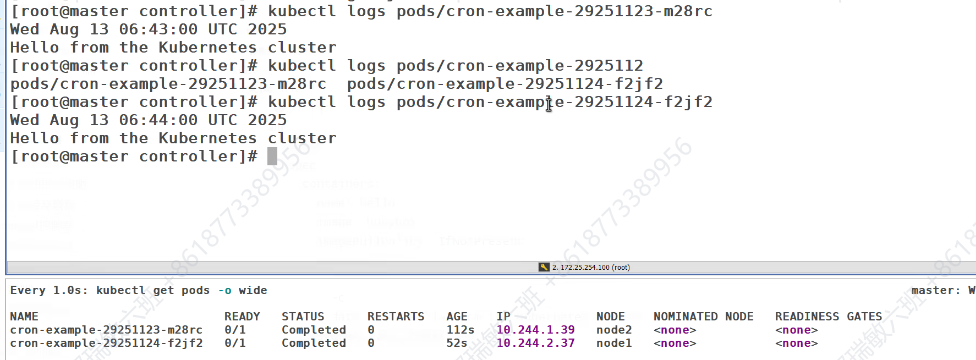
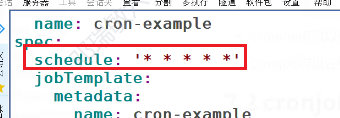
cronjob控制器
job是一次性的,需要周期进行的话,需要加上时间
示例
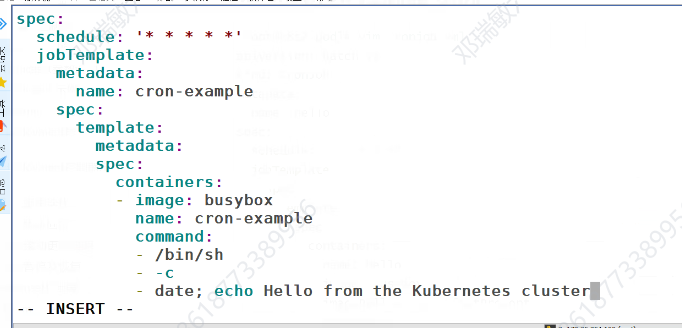
先显示系统时间
如果本地有镜像就不拉,没有就拉取
如果挂了,就重新开启·
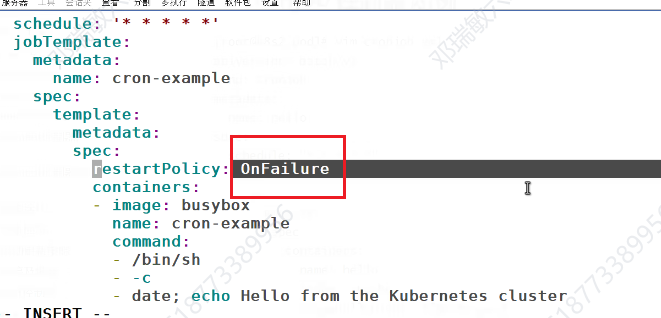

每隔一分钟,会新建一个