5种缓存策略解析
在构建高并发系统时,缓存几乎是绕不开的技术组件。以 Redis 为代表的内存缓存可以显著降低后端数据库的访问压力,提升数据查询速度。但缓存的使用方式、与数据库的交互模式,以及更新时机,都会直接影响到系统的性能与一致性。这些行为模式,就形成了不同的 缓存策略(Cache Strategies)。下面是对几种常见缓存策略的介绍。
一、从系统读取数据
1. Cache Aside(旁路缓存)
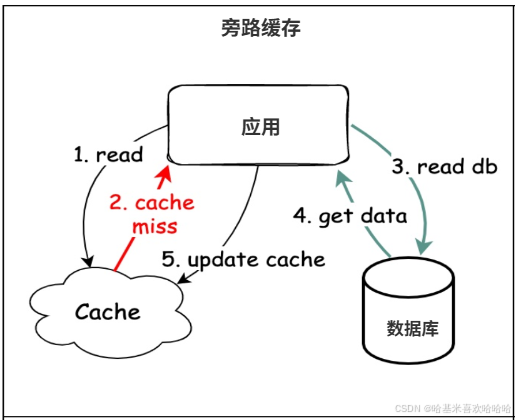
Cache Aside 也被称为 Lazy Loading(惰性加载),它的核心思想是应用代码自己决定何时从缓存读取、何时从数据库读取,并且在缓存缺失(Cache Miss)时,主动去数据库取数据,然后回填到缓存中。这种方式下,缓存并不直接参与数据库交互,而是由业务逻辑显式控制。
例如,应用请求某个商品详情时,会先访问 Redis,如果命中(Cache Hit),直接返回数据;如果未命中(Cache Miss),则去 MySQL 查询,再将查询结果写入 Redis 以便下次访问时直接命中。缓存的生命周期也由业务代码控制,比如可以设定 TTL 来自动过期。
Cache Aside 的优点是实现灵活,缓存只存热点数据,不会因为冷数据浪费内存。
高并发场景下的潜在风险:多个请求同时访问同一条不存在于缓存的数据,可能会同时打到数据库,也就是通常所说的 缓存击穿(Cache Stampede)。
解决方法:加互斥锁(例如 Redis 分布式锁)、提前预热数据,或使用异步刷新机制。
2. Read Through(读穿透)
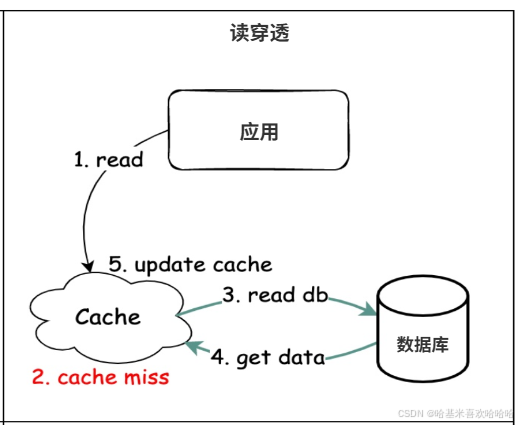
与 Cache Aside 不同,Read Through 模式将缓存的读逻辑交由缓存组件或中间件来完成,应用只需要向缓存请求数据,如果缓存不存在,由缓存层负责去加载数据库数据,并自动填充到缓存中。这种模式常见于支持自定义加载器的缓存中间件,比如 Guava Cache、Ehcache,或者在 Redis 前加一层代理服务(如自研的 Cache Service)。
从业务开发的角度,Read Through 隐藏了缓存与数据库的切换逻辑,使得代码更简洁。但这也意味着缓存层必须有直接访问数据库的能力。
二、向系统写入数据
1. Write Around(绕写缓存)
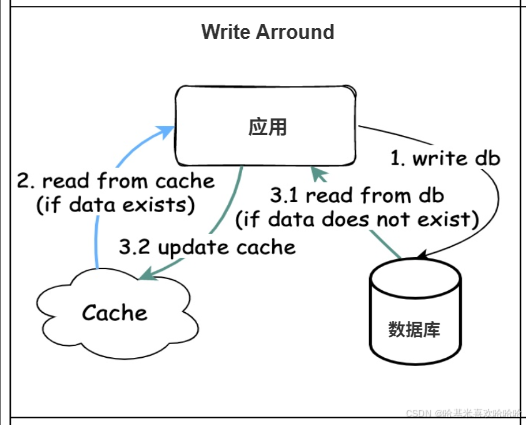
Write Around 是一种只写数据库、不直接写缓存的策略。更新数据时,应用只更新数据库,并不立即更新缓存;缓存中的旧数据会在下次访问时因为过期或被淘汰而失效,然后通过 Cache Aside 或 Read Through 再次加载最新数据。
这种方式的优点是减少缓存写操作,对于写多读少的数据尤其适用,比如日志型数据、历史数据等。但它的缺点同样明显:写完数据后,缓存中可能还存着旧值,直到缓存自然过期或被驱逐,读请求才会拿到最新数据。
2. Write Back(回写缓存)
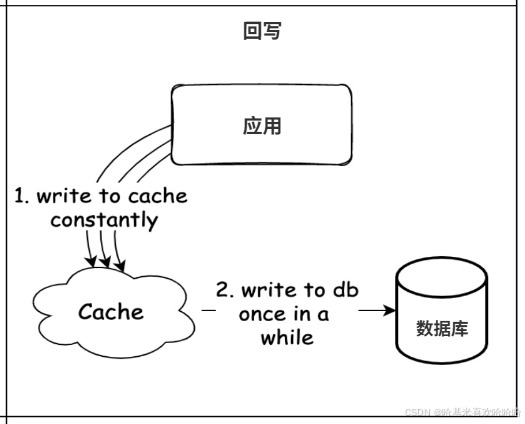
Write Back 也叫 Write Behind,其思路是先将数据写入缓存,由缓存异步地、批量地将更新同步到数据库。这样,写操作的延迟极低,因为请求返回时数据只写进了内存,不需要等待数据库落盘。这种方式在高写入吞吐的场景中非常高效,例如排行榜更新、实时统计等。
然而,Write Back 最大的风险在于数据一致性:一旦缓存节点在数据同步到数据库之前宕机,就会造成数据丢失。因此,使用 Write Back 时,必须配合持久化机制(比如 Redis 的 AOF 或 RDB)来降低丢失风险,并且要有补偿机制保证最终一致性。在分布式环境下,还需要考虑数据在多个缓存节点间的同步问题。
3. Write Through(直写缓存)
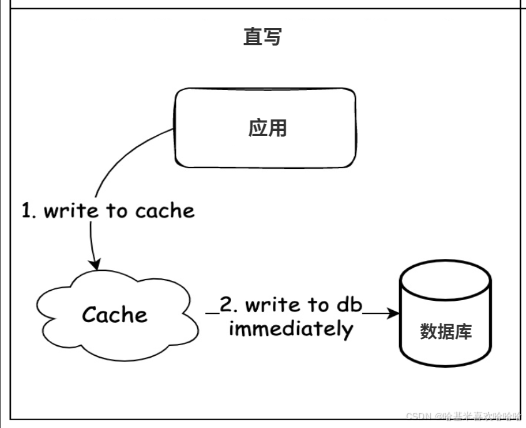
Write Through 是一种同步写策略,即应用更新数据时先写缓存,由缓存层负责同步写数据库。与 Write Back 最大的区别是,Write Through 必须等数据库写入成功后才返回客户端,因此它的延迟会比 Write Back 高,但数据一致性要好得多。
这种模式适合需要同时保证缓存与数据库一致性的场景,比如电商的库存扣减、账户余额更新等业务。缺点是写延迟会比直接写数据库更高,因为需要经过缓存和数据库两层写入。
三、总结
在实际系统设计中,这些策略往往会结合使用。
- 读多写少的商品详情查询服务,可以使用 Cache Aside + Write Around 组合,以降低缓存更新频率;
- 实时性要求高的排行榜,可以采用 Write Back,并通过 Redis 持久化机制保障数据安全;
任何缓存策略都离不开对缓存一致性问题的处理。无论是 Cache Aside 的缓存击穿、Write Around 的短期不一致,还是 Write Back 的数据丢失风险,都需要结合业务特点,设计 TTL、异步刷新、持久化等手段,确保系统的性能和可靠性。