Datawhale AI夏令营第三期多模态RAG方向 Task3
1.baseline优化路径
- 升级数据解析核心 :放弃 PyMuPDF, 切换到 MinerU 。
-
优化分块与索引策略 :有了 MinerU 精细化的解析结果,我们可以进行对 图片进行进一步的内容解释,添加图片的描述信息。
-
引入重排(Re-ranking)
-
实施模型微调 :让模型更适应财报问答的场景。
-
微调Embedding模型 :利用
train.json中的问答对构造训练数据,让模型学习财报领域的语义关系,提升检索召回的准确率。
-
具体步骤可能包括:
- 数据预处理:
- 从 train.json 中提取问答对。
- 构造正样本(匹配的问答对)和负样本(不匹配的问答对)。
- 如果数据量不足,可能需要数据增强(比如同义句改写)。
- 选择损失函数:
- 常用的损失函数包括:
- 余弦相似度损失:让正样本的向量更接近,负样本的向量更远。
- 对比损失(Contrastive Loss):强化正负样本的区分。
- 三元组损失(Triplet Loss):使用锚点、正样本、负样本三元组,确保正样本比负样本更接近锚点。
- 微调模型:
- 使用预训练的 Embedding 模型(如 Sentence-BERT、MiniLM)。
- 在财报领域的问答对上进行微调,调整模型参数。
- 评估效果:
- 在验证集上测试模型的检索性能,比如计算召回率(Recall@K)、准确率(Precision@K)或平均倒数排名(MRR)。
- 应用到检索任务:将微调后的模型用于财报领域的语义搜索或问答系统,输入问题,输出与问题语义最匹配的答案。
2. 微调LLM :利用 train.json 构造“指令-上下文-回答”格式的数据,对LLM进行指令微调。主要目的是让LLM更“听话”,能更忠实地根据我们提供的上下文作答,并严格按照要求的格式输出答案和来源。
5.运行全量测试数据:修改rag_from_page_chunks.py文件里面的变量TEST_SAMPLE_NUM,将原来的10改成None
运行过程中遇到了遇到了 RateLimitError(错误代码 429),提示达到了 API 的速率限制(TPM limit reached,可能是每分钟 token 限制)
[515/806] 正在处理: 千味央厨公司在2022年的盈利预测与评级如何?...
[516/806] 正在处理: 广联达(002410)公司点评报告中,新成本平台的市场空间如...
[517/806] 正在处理: 根据《伊利专业乳品2022中国现制茶饮渠道消费者与行业趋势报...
[518/806] 正在处理: 根据《2022中国现制茶饮渠道消费者与行业趋势报告》中的内容...
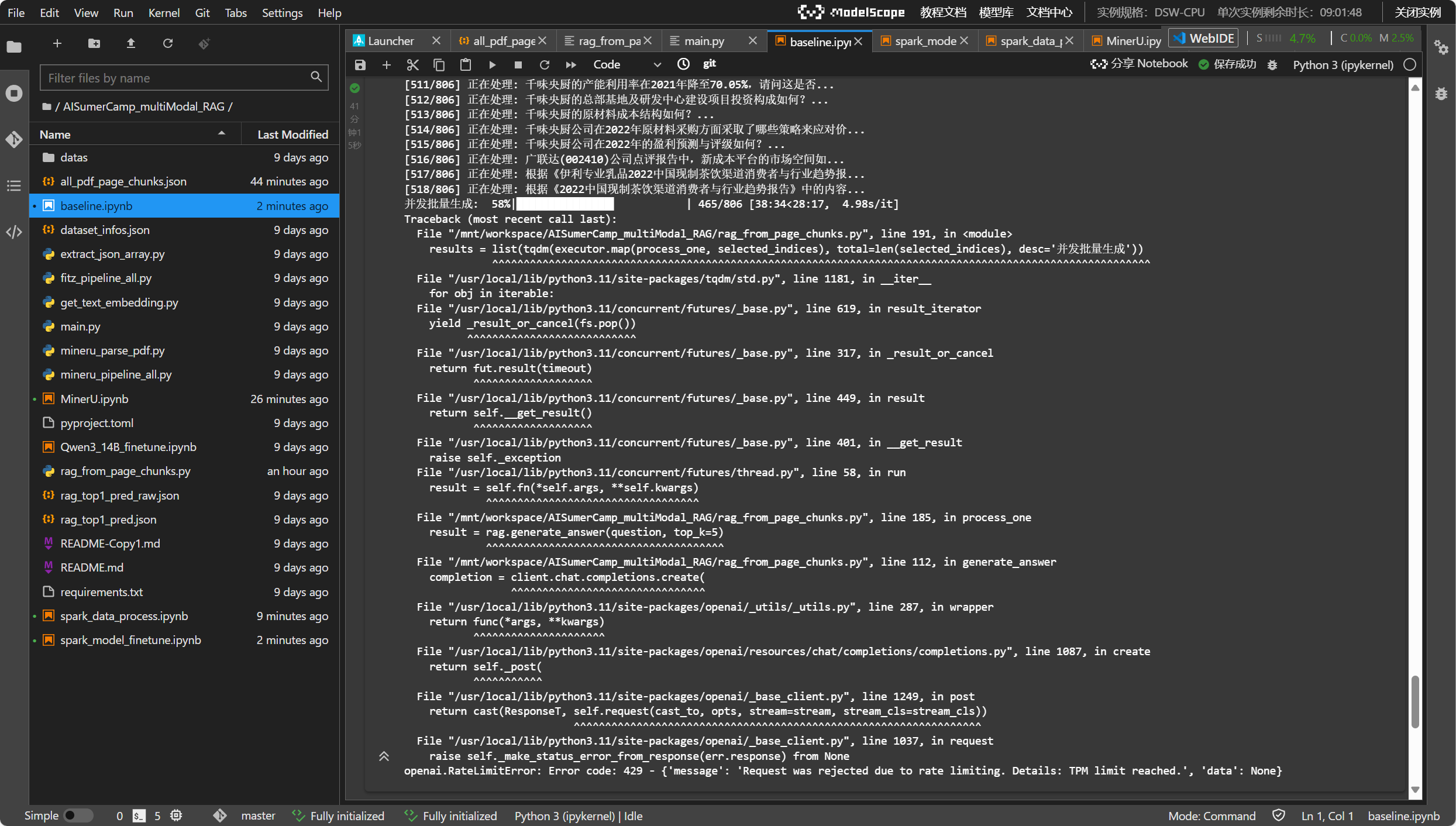
并发批量生成: 58%|███████████████▌ | 465/806 [38:34<28:17, 4.98s/it]
Traceback (most recent call last):File "/mnt/workspace/AISumerCamp_multiModal_RAG/rag_from_page_chunks.py", line 191, in <module>results = list(tqdm(executor.map(process_one, selected_indices), total=len(selected_indices), desc='并发批量生成'))^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/site-packages/tqdm/std.py", line 1181, in __iter__for obj in iterable:File "/usr/local/lib/python3.11/concurrent/futures/_base.py", line 619, in result_iteratoryield _result_or_cancel(fs.pop())^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/concurrent/futures/_base.py", line 317, in _result_or_cancelreturn fut.result(timeout)^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/concurrent/futures/_base.py", line 449, in resultreturn self.__get_result()^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/concurrent/futures/_base.py", line 401, in __get_resultraise self._exceptionFile "/usr/local/lib/python3.11/concurrent/futures/thread.py", line 58, in runresult = self.fn(*self.args, **self.kwargs)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/mnt/workspace/AISumerCamp_multiModal_RAG/rag_from_page_chunks.py", line 185, in process_oneresult = rag.generate_answer(question, top_k=5)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/mnt/workspace/AISumerCamp_multiModal_RAG/rag_from_page_chunks.py", line 112, in generate_answercompletion = client.chat.completions.create(^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/site-packages/openai/_utils/_utils.py", line 287, in wrapperreturn func(*args, **kwargs)^^^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/site-packages/openai/resources/chat/completions/completions.py", line 1087, in createreturn self._post(^^^^^^^^^^^File "/usr/local/lib/python3.11/site-packages/openai/_base_client.py", line 1249, in postreturn cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls))^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/usr/local/lib/python3.11/site-packages/openai/_base_client.py", line 1037, in requestraise self._make_status_error_from_response(err.response) from None
openai.RateLimitError: Error code: 429 - {'message': 'Request was rejected due to rate limiting. Details: TPM limit reached.', 'data': None}2.进阶要点
进阶要点1:提取文档的多模态内容
像 MinerU 这样的工具能帮助我们进行版面分析,区分出标题、段落、表格和图片,并且能把表格转换成 Markdown 这种结构化格式。
这样处理后,知识库的内容就比纯文本丰富多了。
对于解析出来的图片,我们可以用多模态大模型,比如 Qwen-VL,来生成文字描述,把图片信息也文本化,方便后续的检索。
其中使用mineru进行解析内容的版本在我们的github仓库内是有提供的,文件名字叫做mineru_pipeline_all.py
将 baseline 中运行 fitz_pipeline_all.py 的命令( !python fitz_pipeline_all.py)替换为 !python mineru_pipeline_all.py,可以切换到使用 MinerU 解析 PDF 并生成 all_pdf_page_chunks.json
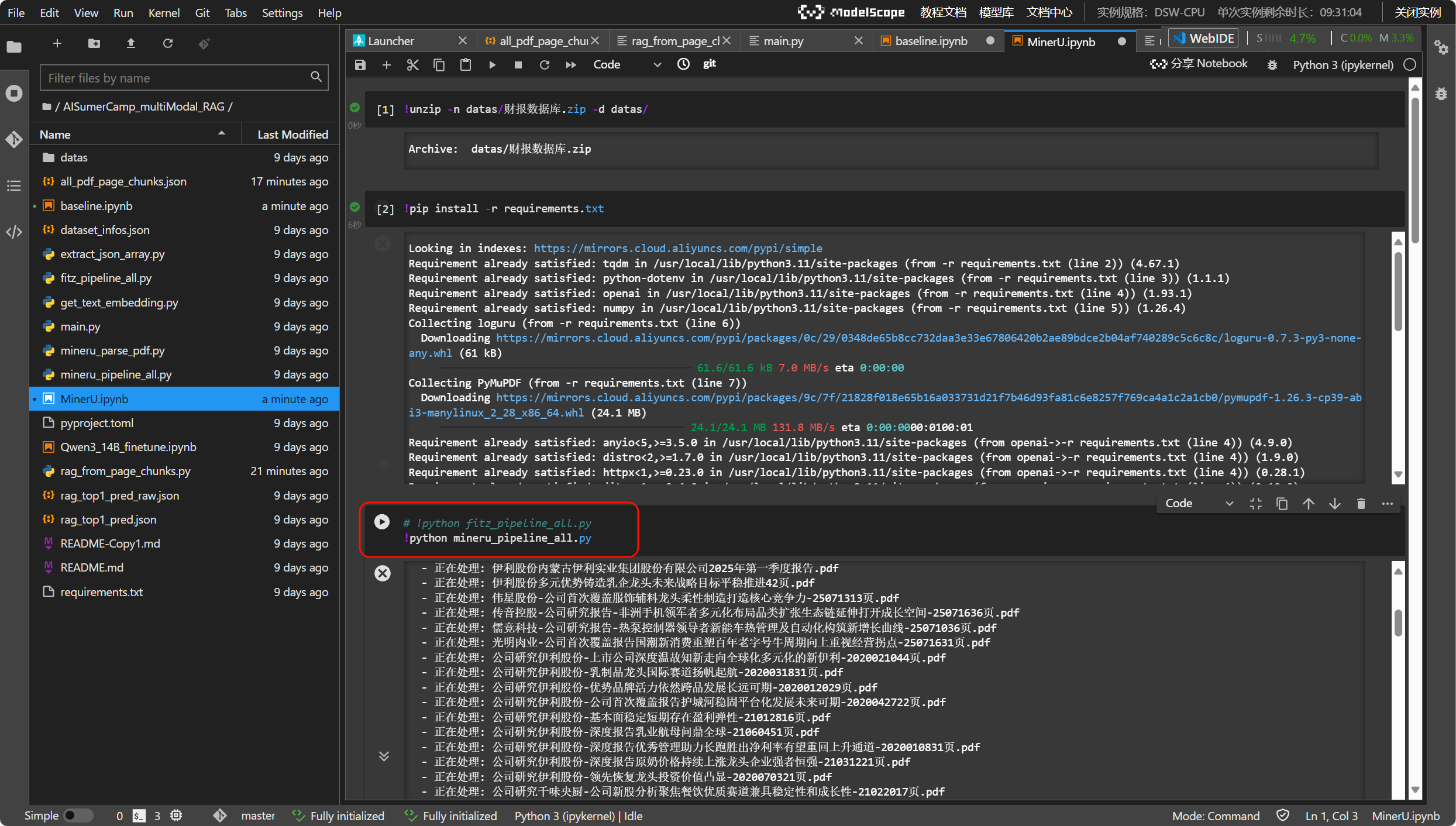
在requirement.txt中将mineru解除注释

在GPU环境下运行mineru_pipeline_all.py
运行时出现报错:
Traceback (most recent call last):File "/mnt/workspace/AISumerCamp_multiModal_RAG/mineru_pipeline_all.py", line 7, in <module>from image_utils.async_image_analysis import AsyncImageAnalysis ModuleNotFoundError: No module named 'image_utils'
在requirements.txt文件中加入image_utils
代码详解:
第一步:用 MinerU 解析 PDF (
parse_all_pdfs函数)这是所有工作的起点。这个函数会遍历指定的文件夹,找到所有 PDF 文件。
对于每一个 PDF,它会调用
mineru_parse_pdf.do_parse这个核心功能。
do_parse是 MinerU 发挥作用的地方,它会去分析 PDF 的版面布局,识别出里面的文本、标题、表格和图片,然后把这些识别出的所有内容元素,连同它们的类型、位置、层级等信息,都存进一个名为_content_list.json的文件里。可以把它看作是 MinerU 对整个 PDF 进行的一次精细化扫描和内容提取,产出的是最原始、最详细的结构化数据。
第二步:将解析结果整理成 Markdown 格式 (
process_all_pdfs_to_page_json函数)拿到第一步的原始数据后,这一步的目标是把它整理成对后续模型更友好的格式。它会读取
_content_list.json,先按页码把内容分好组,然后逐个处理每一页里的内容项。这里面最关键的逻辑在
item_to_markdown函数里。这个函数是一个转换器,它根据内容项的类型(type)来决定如何转换:
如果是
text,它会根据文本的层级(text_level)加上 Markdown 的标题符号,比如一级标题就变成# 标题。如果是
table,它会把表格的 HTML 代码直接拿过来用,并附上表格的标题。如果是
image,它会生成 Markdown 的图片语法。代码会检查图片本身有没有自带的文字描述(
caption)。如果没有,并且我们允许进行视觉分析(
enable_image_caption=True),它就会调用一个多模态大模型(代码里指定的是
Qwen/Qwen2.5-VL-32B-Instruct)来给这张图片生成一段描述。这就把图片这种非文本信息,也转化成了可以被检索的文本,极大地丰富了知识库的内容,当然,你也可以强制要求使用多模态模型直接生成图片的描述信息。
这一步完成之后,我们会为每个 PDF 生成一个
_page_content.json文件,里面记录了每一页转换成的完整 Markdown 文本。
第三步:汇总所有内容,生成最终的知识库文件 (
process_page_content_to_chunks函数)这是最后一步的整合工作。
它会遍历第二步生成的所有
_page_content.json文件,把每一页的内容都封装成一个标准的“知识块”(chunk)。每个 chunk 都是一个字典,包含三个关键信息:一个唯一的
id,页面转换后的content(也就是那段 Markdown 文本),以及包含来源页码和文件名的metadata。最后,它把所有 PDF 的所有页面对应的 chunk 合并到一个大的列表里,并存成
all_pdf_page_chunks.json文件。这个文件就是我们整个流程的最终产物,可以直接拿去给 Embedding 模型做向量化,然后构建我们的向量数据库了。
进阶要点2:“粗召回”与“精召回”的检索策略
我们可以采用一个两步走的检索策略,也就是先“召回”再“重排”。
-
第一步“召回”,用向量检索或者关键词检索(比如BM25算法),快速地找到一个比较大的候选范围,目的是把相关的都找出来。
-
第二步“重排”,用一个更精准的重排模型,比如 FlagEmbedding 仓库里的 BGE-ReRanker 模型,来给这些候选项和问题的相关性打分,然后选出分数最高的几个。
3.其他进阶方法和思路
进阶思路1:多路召回与融合
比如,我们可以并行运行两种检索:一种是基于关键词的检索,像 BM25 算法,它擅长匹配问题中出现的具体词语;另一种是基于向量的语义检索,使用 embedding 模型来查找意思相近但用词可能不同的内容。这样,两条通路可以形成优势互补。
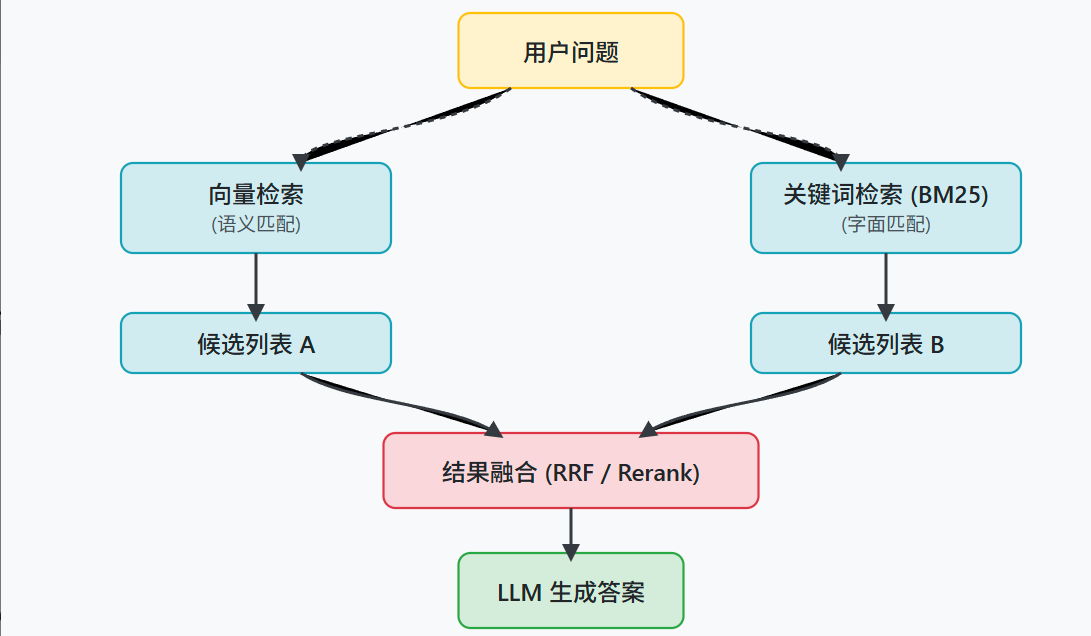
在从不同通路拿到各自的召回结果列表后,接下来的问题就是如何把它们融合成一个更高质量的排序。
这里通常有两种处理思路:
-
第一种是使用重排模型(Re-ranker)。
我们可以把所有通路召回的结果汇总到一起,然后用一个重排模型,比如基于 FlagEmbedding 的模型,来对这个大集合进行统一的、更精细的相关性打分,最后选出分数最高的几个结果。
-
第二种是使用无需训练模型的融合算法,
一个常见的例子是倒数排名融合(Reciprocal Rank Fusion, RRF)。
这种方法会根据每个文档在不同召回列表中的排名位置,来计算出一个综合分数,然后根据这个综合分数生成一个新的排序。
进阶思路2:构建知识图谱
什么是知识图谱?
知识图谱(Knowledge Graph)是一种结构化的知识表示形式,用于存储和组织复杂的关系数据。它以图的形式表示实体(Entity)、属性(Attribute)和它们之间的关系(Relation),通常以节点(表示实体)和边(表示关系)的形式构建。知识图谱的目标是将分散的知识整合成一个结构化的网络,便于机器理解、推理和查询。
还有一个方向是构建知识图谱。现在我们的知识库里的知识块是相互独立的,但原文中它们是有结构联系的。
我们可以把一份文档表示成一个知识图谱,里面的节点可以是段落、表格、图表、公司名等实体,边则表示它们之间的关系,比如“位于”、“描述”或者“属于”。
进阶思路3:让RAG系统拥有自我修正的能力
具体来说,就是让系统在检索一次之后,能自己判断一下找到的上下文够不够回答问题。
如果不够,它可以自己生成一个新的、更具体的查询语句,再次进行检索,把两次的结果合在一起再生成答案。
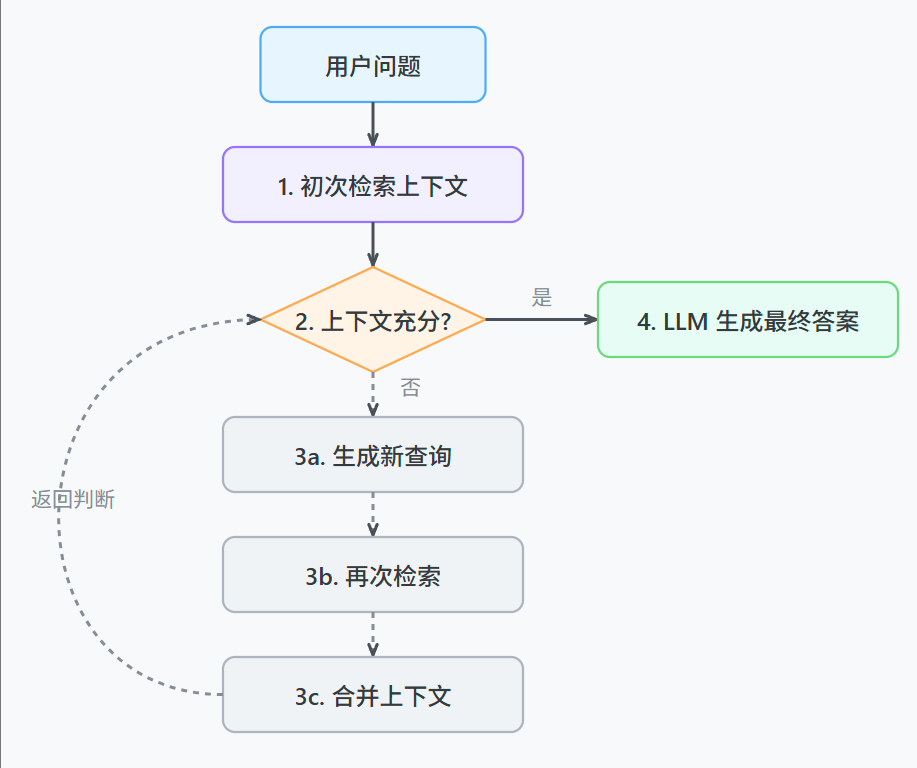
进阶思路4:模型微调
整个微调流程可以分为两大步: 数据准备 和 模型训练 。主要涉及到 spark_data_process.ipynb 和 spark_model_finetune.ipynb 两个文件。
4.1数据准备 (spark_data_process.ipynb)
我们的目标是利用官方提供的 train.json ,将其转换为模型能够理解的“指令-输入-输出”格式。
核心目标 :将原始的问答数据,转换为符合Alpaca指令格式的 qa_train.json 文件。
什么是Alpaca
Alpaca 数据集通常以 JSON 格式存储,每个样本包含以下三个字段:
- instruction:用户提供的指令或问题,描述任务或需要模型完成的工作。
- input:(可选)额外的上下文或输入信息,为指令提供更多背景。如果没有额外上下文,这个字段可以为空。
- output:模型应该生成的回答或结果。
spark_data_process.ipynb 的核心逻辑是将每个问答对(Q&A pair)包装成一个结构化的字典。
-
输入与输出 :
input字段对应原始问题,output 字段对应标准答案。模型在训练时会学习到,在收到这样的instruction和input后,应该生成类似 output 的回答。 -
最终产物 :执行该脚本后,我们会得到
qa_train.json文件,这是下一步模型训练的直接输入。
我们通过提供一个固定的
instruction(指令),作为学习材料,通过微调教会模型在我们这个财报任务下的“角色”和“任务”。这使得模型在面对新的问题时,能更好地按照我们期望的身份和方式来回答。
4.2 模型训练 (spark_model_finetune.ipynb)
有了标准格式的训练数据,我们就可以开始进行模型的有监督微调(Supervised Fine-Tuning, SFT)。
我们在参考代码中使用了 unsloth 框架高效微调 Qwen2.5-7B 。
1. 环境配置与模型加载
首先,我们加载必要的库和预训练模型。 unsloth 框架通过优化,可以显著降低显存占用并提升训练速度。
2. 添加LoRA适配器
我们不训练模型的全部参数,而是采用LoRA(Low-Rank Adaptation)技术,只插入并训练少量“适配器”参数。这极大地节约了计算资源。
LoRA(Low-Rank Adaptation)是一种高效的微调(Fine-tuning)技术,用于在不大幅修改预训练模型的情况下,适应特定任务或领域。它通过在模型的权重矩阵中引入低秩更新(low-rank updates),大幅减少需要训练的参数量,从而降低计算成本和内存需求,同时保持模型性能。LoRA 最初由微软研究院提出,广泛应用于大语言模型(如 LLaMA、BERT)和视觉模型的微调。
3. 加载并格式化数据
加载上一步生成的 qa_train.json ,并将其转换为训练所需的最终文本格式。
4. 配置并启动训练
使用HuggingFace的 trl 库中的 SFTTrainer 来配置训练参数并启动训练。
5. 推理验证与模型保存
训练完成后,我们可以立即进行一个简单的推理测试,看看模型是否学会了按照我们的要求回答问题。最后,将训练好的LoRA适配器保存下来,以便后续在RAG系统中使用。
通过以上步骤,我们就完成了一次完整的模型微调。得到的 lora_model 文件夹包含了微调后的模型权重,可以在RAG的生成环节加载它。
通过系统的模型微调,我们可以显著提升RAG系统在财报问答任务上的表现。