哈希算法(摘要算法)
学习目标:
-
MD5算法
-
理解128位哈希值的生成原理
-
认识算法特性(不可逆、雪崩效应)
-
了解碰撞漏洞等安全局限性
-
-
SHA系列算法
-
掌握SHA-1/SHA-256/SHA-512的区别
-
理解不同位数的安全性差异
-
学习算法应用场景(如证书签名)
-
-
HMAC算法
-
理解密钥哈希的消息认证机制
-
掌握哈希+密钥的混合验证原理
-
在 JavaScript 中和 Python 中的基本实现方法,遇到 JS 加密的时候可以快速还原加密过程,有的网站在加密的过程中可能还经过了其他处理,但是大致的方法是一样的。
消息摘要算法/签名算法:MD5、SHA、HMAC
一、MD5
1.简介
MD5(Message-Digest Algorithm 5)是一种广泛使用的密码散列函数,由美国密码学家罗纳德·李维斯特(Ronald Rivest)设计,于1992年作为RFC 1321标准发布,用于替代其前身MD4算法。
核心特性:
- 单向加密性:作为摘要算法,MD5生成的哈希值不可逆向解密为原始数据
- 固定长度输出:无论输入数据大小,始终生成128位(16字节)的哈希值,通常表示为32位十六进制字符串
- 特征提取:通过对输入数据进行特征提取和压缩生成摘要
- 碰撞可能性:理论上不同输入可能产生相同哈希值(哈希碰撞),但概率极低
典型应用场景包括数据完整性校验、数字签名辅助等,但因其安全性缺陷,现已不推荐用于重要安全场景。
2.JavaScript实现md5
安装包:npm install crypto-js --save
案例:
var crypto_js=require('crypto-js')function get_md5(){var text="新年快乐"// toString 把数据转换成字符串console.log(crypto_js.MD5(text).toString())
}get_md5()3.Python实现md5
"""
MD5特点:加密的数据 是标准幻数长度32位数据16进制
"""
import hashlibdef get_md5():md5=hashlib.md5()md5.update('新年快乐'.encode('utf-8'))print(md5.hexdigest())get_md5()4.总结
MD5 哈希视为字符串,并且是将其视为十六进制数,MD5 哈希长度为128位,通常由32个十六进制数字表示。
二、SHA
1.简介
安全哈希算法(SHA) 由美国国家安全局(NSA)设计,是广泛应用于数据完整性验证和数字签名的密码学哈希函数家族。SHA 家族主要包括 SHA-1、SHA-224、SHA-256、SHA-384 和 SHA-512 等算法,其中数字后缀表示哈希输出的位数(如 SHA-256 输出 256 位)。
与 MD5(32 位哈希值)相比,SHA 更安全但计算速度较慢:
-
SHA-1 生成 40 位十六进制哈希值(160 位二进制),但因存在漏洞已逐步被弃用。
-
更高版本(如 SHA-256) 通过更长的哈希值和更强的抗碰撞性提升安全性,但性能开销更大。
SHA 是现行数字签名标准(如 DSS)的核心组件,推荐优先使用 SHA-2(如 SHA-256)或 SHA-3 替代 MD5 和 SHA-1。
2.JavaScript实现SHA
var crypto_js=require('crypto-js')function get_sha(){var text="新年快乐"console.log(crypto_js.SHA1(text).toString(),crypto_js.SHA1(text).toString().length)console.log(crypto_js.SHA224(text).toString(),crypto_js.SHA224(text).toString().length)console.log(crypto_js.SHA256(text).toString(),crypto_js.SHA256(text).toString().length)console.log(crypto_js.SHA384(text).toString(),crypto_js.SHA384(text).toString().length)console.log(crypto_js.SHA512(text).toString(),crypto_js.SHA512(text).toString().length)
}get_sha()3.Python实现SHA
import hashlibdef get_md5():md5 = hashlib.sha1()md5.update('新年快乐'.encode('utf-8'))print(md5.hexdigest())get_md5()三、HMAC
1.简介
全称:散列消息认证码(Hash-based Message Authentication Code)
提出时间:1996 年,1997 年作为 RFC 2104 标准发布。
核心原理
HMAC 是一种基于加密哈希函数(如 SHA-256、MD5)和共享密钥的消息认证协议,用于验证数据完整性和真实性。其核心流程如下:
-
共享密钥:通信双方预先协商一个密钥(
key)。 -
哈希算法:约定哈希算法(如 SHA-256)。
-
生成认证码:对消息进行哈希运算,结合密钥生成固定长度的认证码(MAC)。
-
校验合法性:接收方通过重新计算认证码,验证消息是否被篡改。
特点
-
安全性:依赖哈希算法的抗碰撞性,且密钥参与运算,防止伪造。
-
灵活性:支持任意哈希算法(如 HMAC-SHA256、HMAC-MD5)。
-
标准化:广泛应用于 TLS、IPSec、JWT 等协议。
与普通哈希的区别
-
普通哈希:仅验证数据完整性(如 SHA-256)。
-
HMAC:同时验证完整性和真实性(需密钥参与)。
2.JavaScript实现HMAC
var crypto_js=require("crypto-js")function get_hmac(){var text='新年快乐'var key='12345'// toString 把数据转换成字符串console.log(crypto_js.HmacMD5(text,key).toString())
}get_hmac()3.Python实现HMAC
import hmacdef get_md5():text='新年快乐'.encode('utf-8')key='12345'.encode('utf-8')md5=hmac.new(key,text,digestmod='MD5')print(md5.hexdigest())
get_md5()四、案例
1.md5 加密逆向案例
(1)逆向目标
网址:https://mytokencap.com/
接口:https://api.mytoken.info/ticker/currencyranklist?pages=2%2C1&sizes=100%2C100&subject=market_cap&language=en_US&legal_currency=USD&code=9e82a2d7d1c1f730e15ab1eab4109252×tamp=1752223590920&platform=web_pc&v=0.1.0&mytoken=
逆向参数: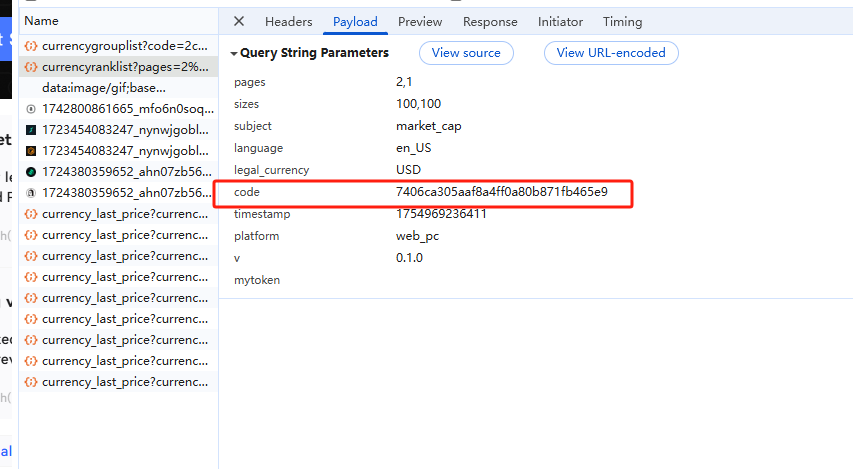
(2)逆向分析
用xhr进行定位,然后看栈的入参和返回值看是否数据已经加密:
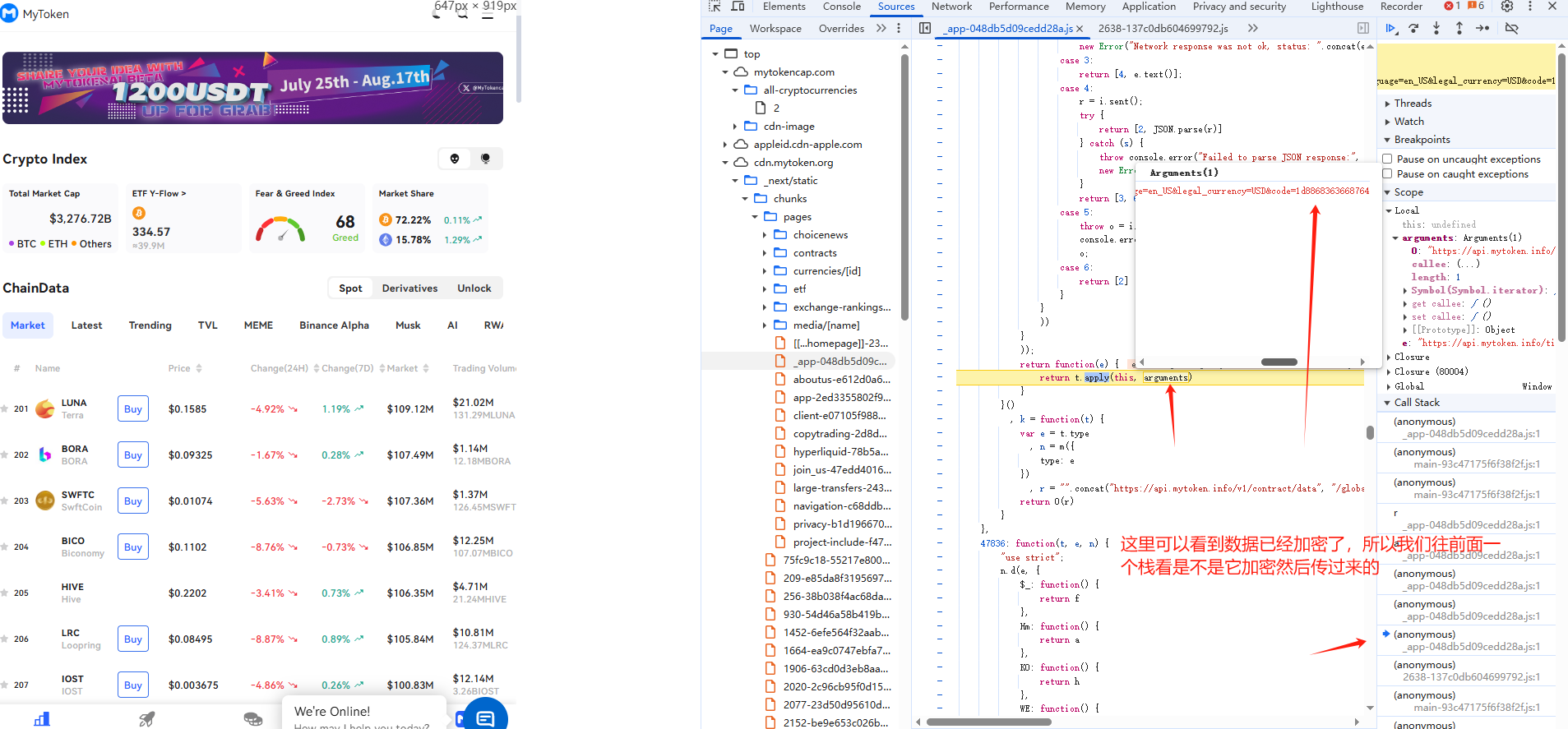
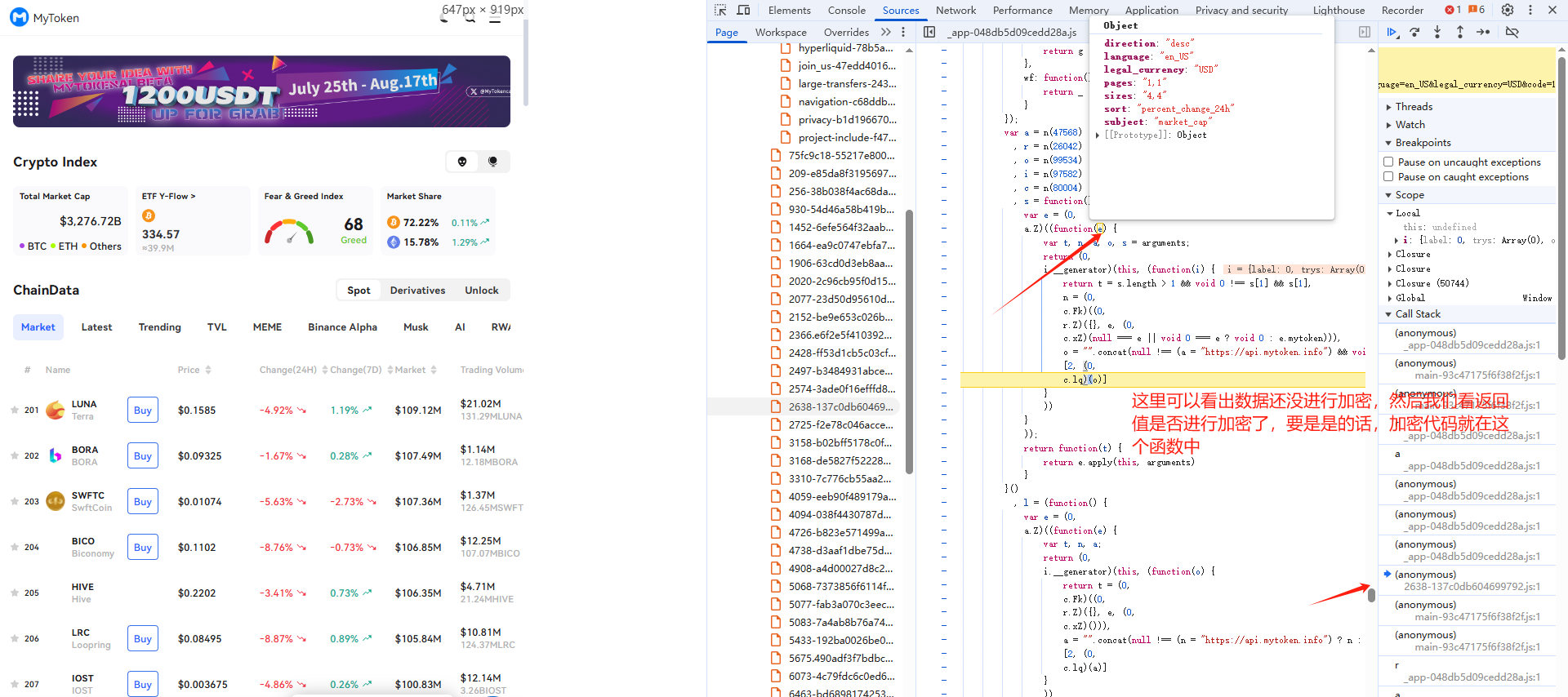
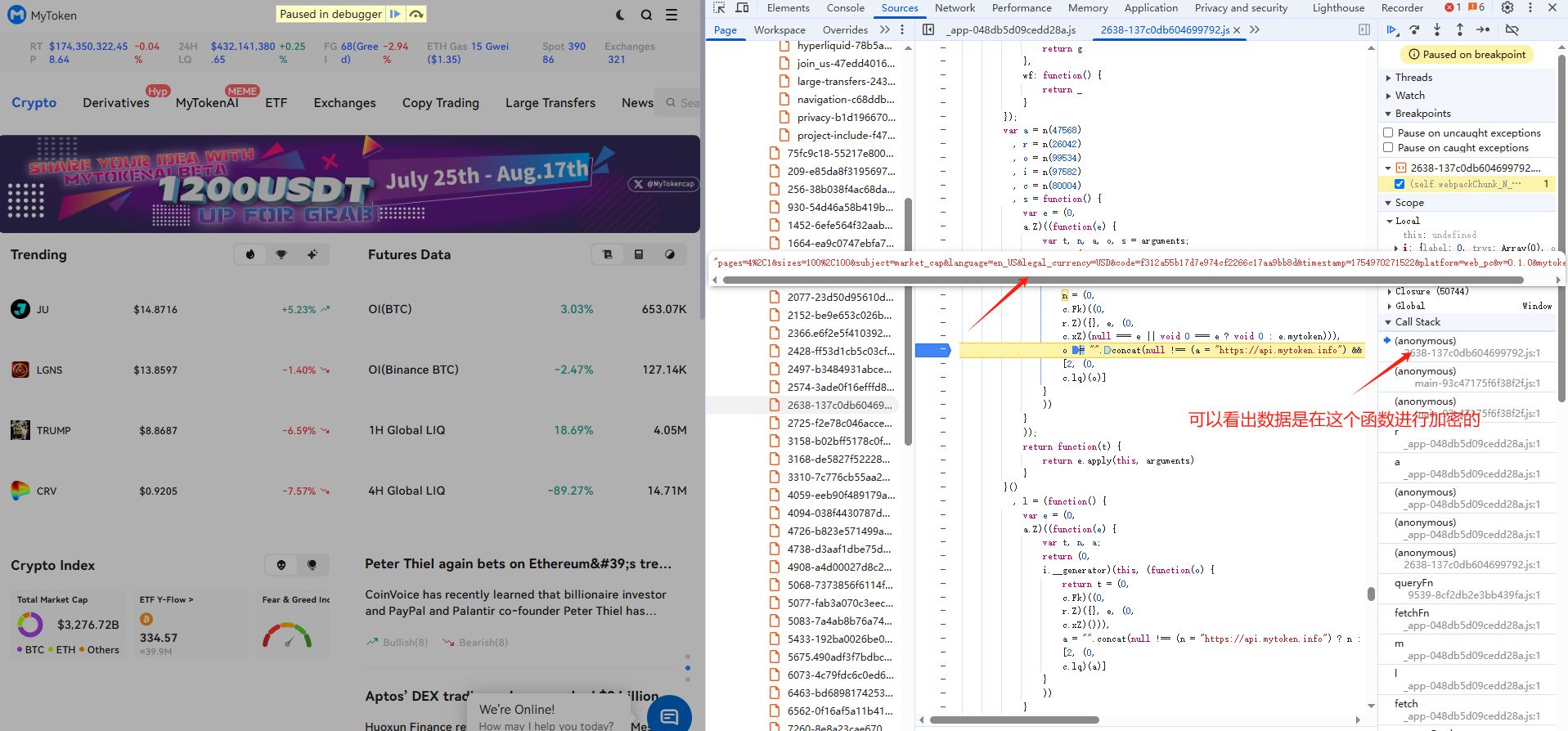
(3)代码实现
javascript代码:
var Crypto=require('crypto-js')function getMD5(text){return Crypto.MD5(text).toString()
}function get_code(){var e = Date.now().toString();code=getMD5(e + "9527" + e.substr(0, 6))var headers={}headers['timestamp']=eheaders['code']=codereturn headers
}
python代码:
import osimport requests
import execjs
import csvclass mytoken():def __init__(self):self.headers = {"accept": "*/*","accept-language": "zh-CN,zh;q=0.9","origin": "https://mytokencap.com","priority": "u=1, i","referer": "https://mytokencap.com/","sec-ch-ua": "\"Google Chrome\";v=\"137\", \"Chromium\";v=\"137\", \"Not/A)Brand\";v=\"24\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "cross-site","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36"}self.url = "https://api.mytoken.info/ticker/currencyranklist"self.filename='mytoken_data.csv'def get_info(self,data,page):params = {"pages": f"{page},1","sizes": "100,100","subject": "market_cap","language": "en_US","legal_currency": "USD","code": data['code'],"timestamp": data['timestamp'],"platform": "web_pc","v": "0.1.0","mytoken": ""}response = requests.get(self.url, headers=self.headers, params=params)return response.json()def parse_data(self,json_data):for i in json_data['data']['list']:result = {'name': i.get('name', 'N/A'),'rank': i.get('rank', 0),'market_name': i.get('market_name', ''),'latest_price': i.get('latest_price', 0), # 如果为空,默认 0'percent_change_24h': i.get('percent_change_24h', 0),'percent_change_7d': i.get('percent_change_7d', 0),'market_cap_usd': i.get('market_cap_usd', 0),'available_supply_ratio': i.get('available_supply_ratio', 0)}self.save(result)def save(self,item_dict):header = ['name', 'rank', 'market_name', 'latest_price', 'percent_change_24h', 'percent_change_7d', 'market_cap_usd', 'available_supply_ratio']file_exists=os.path.exists(self.filename)with open('mytoken_data.csv','a',encoding='utf-8',newline='')as f:f_csv=csv.DictWriter(f,fieldnames=header)if not file_exists:f_csv.writeheader()f_csv.writerow(item_dict)print(f'{item_dict['name']},保存成功')def main(self):with open('mytoken.js', 'r') as f:js_code = f.read()js = execjs.compile(js_code)data = js.call('get_code')for page in range(1,20):print(f'正在爬取第{page}页')json_data = self.get_info(data,page)self.parse_data(json_data)if __name__ == '__main__':m=mytoken()m.main()2.sha1 加密逆向案例
(1)逆向目标
网址:宝钢股份
接口:https://cmsauth.baowugroup.com/v1/web/api/content/list?domainId=12
逆向参数: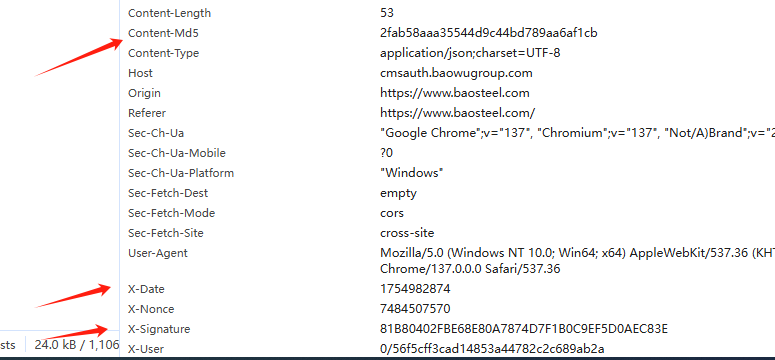
(2)逆向分析
定位:
方法一:关键字定位
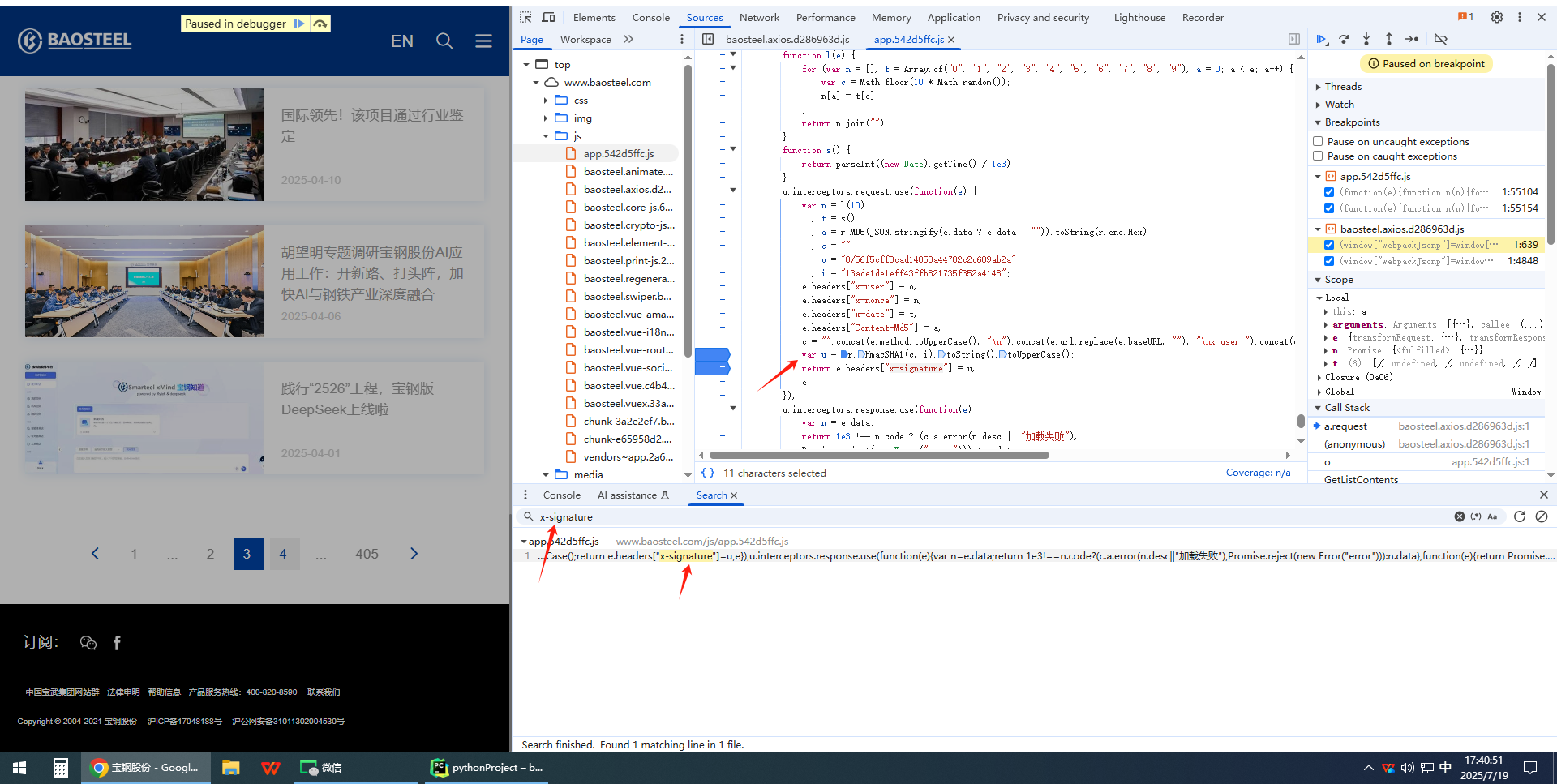
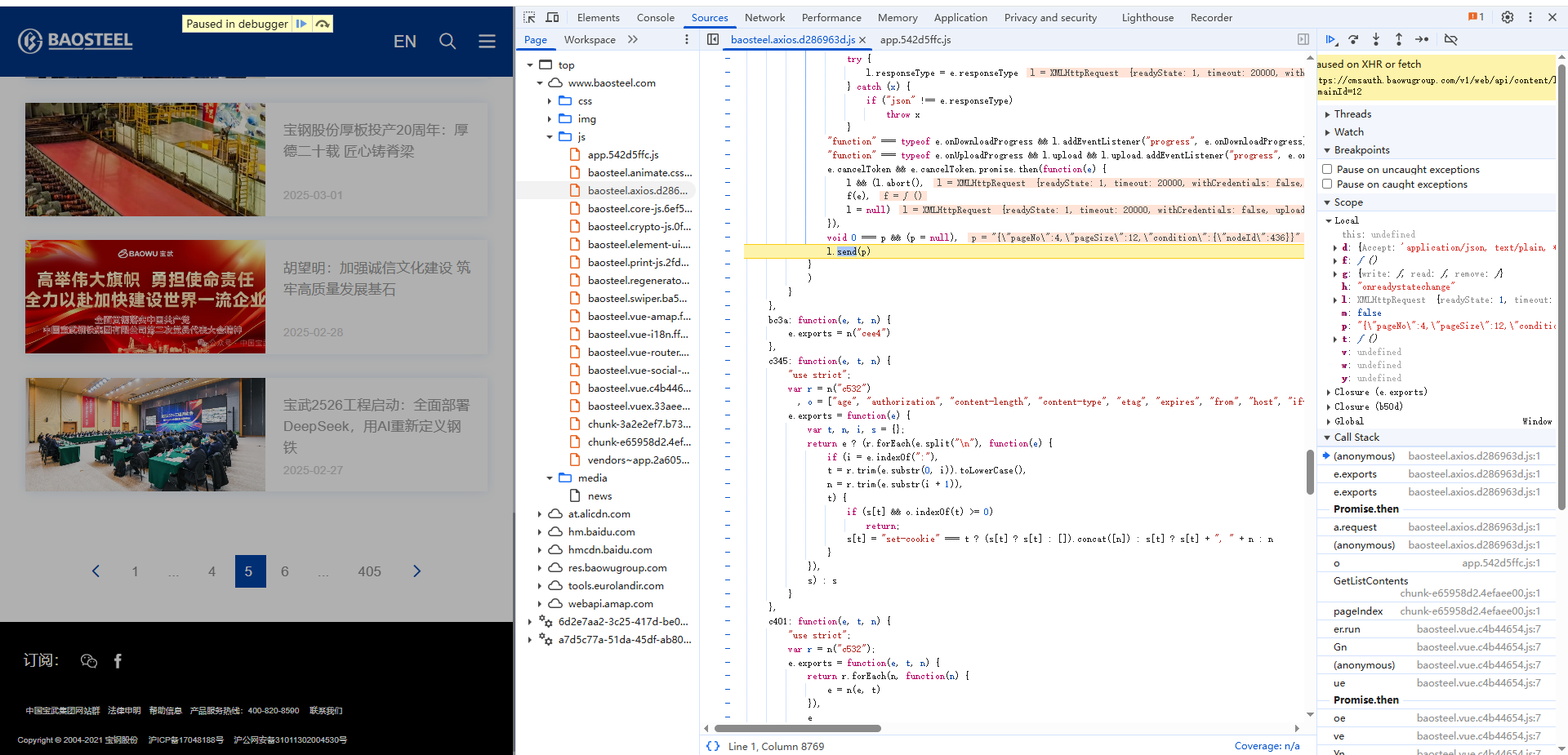
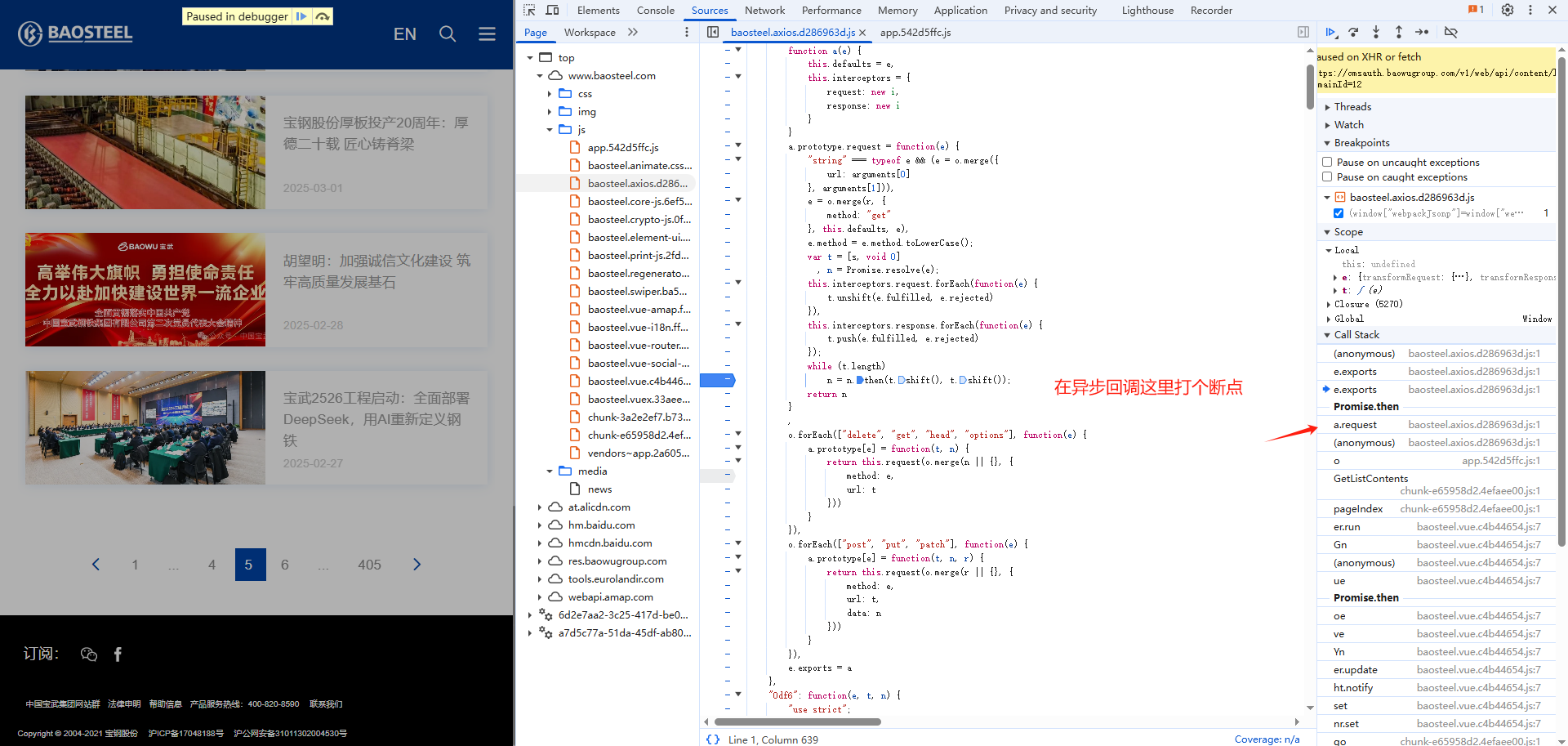
方法二:xhr定位

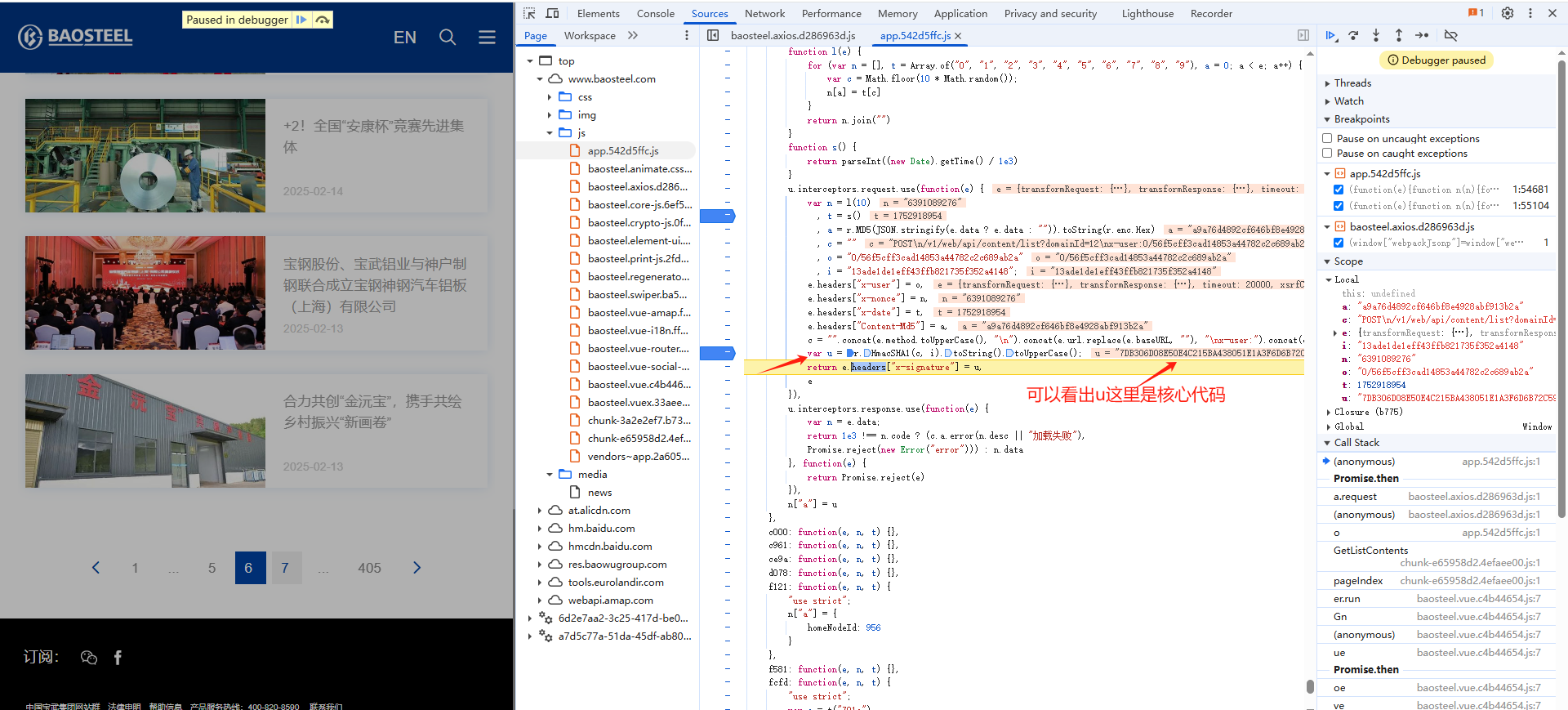
(3)代码实现
javascript代码:
var Crypto = require('crypto-js')function l(e) {for (var n = [], t = Array.of("0", "1", "2", "3", "4", "5", "6", "7", "8", "9"), a = 0; a < e; a++) {var c = Math.floor(10 * Math.random());n[a] = t[c]}return n.join("")
}function s() {return parseInt((new Date).getTime() / 1e3)
}function get_MD5(text) {return Crypto.MD5(text).toString()
}function get_header(page) {var n = l(10)var t = s()data = {"pageNo": page,"pageSize": 12,"condition": {"nodeId": 436}}var a = get_MD5(JSON.stringify(data ? data : ""))var o = "0/56f5cff3cad14853a44782c2c689ab2a"var i = "13ade1de1eff43ffb821735f352a4148";c = "".concat("POST", "\n").concat("/v1/web/api/content/list?domainId=12", "\nx-user:").concat(o, "\nx-nonce:").concat(n, "\nx-date:").concat(t, "\nContent-Md5:").concat(a, "\n");var u = Crypto.HmacSHA1(c, i).toString().toUpperCase();var headers = {}headers["x-nonce"] = nheaders["x-date"] = theaders["Content-Md5"] = aheaders["x-signature"] = ureturn headers
}
python代码:
import os.pathimport requests
import json
import execjs
import urllib3
import re
import csv
from urllib3.util.ssl_ import create_urllib3_context# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)class CustomHttpAdapter(requests.adapters.HTTPAdapter):def init_poolmanager(self, *args, **kwargs):context = create_urllib3_context()context.load_default_certs()context.set_ciphers("DEFAULT:@SECLEVEL=1")context.check_hostname = False # 禁用主机名检查context.verify_mode = False # 禁用证书验证kwargs["ssl_context"] = contextreturn super().init_poolmanager(*args, **kwargs)def get_headers(page):with open('baosteel.js', encoding='utf-8') as f:js_code = f.read()js = execjs.compile(js_code)return js.call('get_header', page)def make_request(page):headers_data = get_headers(page)headers = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9","Connection": "keep-alive","Content-Md5": headers_data["Content-Md5"],"Content-Type": "application/json;charset=UTF-8","Origin": "https://www.baosteel.com","Referer": "https://www.baosteel.com/","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "cross-site","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36","sec-ch-ua": "\"Google Chrome\";v=\"137\", \"Chromium\";v=\"137\", \"Not/A)Brand\";v=\"24\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","x-date": str(headers_data['x-date']),"x-nonce": headers_data['x-nonce'],"x-signature": headers_data['x-signature'],"x-user": "0/56f5cff3cad14853a44782c2c689ab2a"}params = {"domainId": "12"}payload = {"pageNo": page,"pageSize": 12,"condition": {"nodeId": 436}}session = requests.Session()session.mount("https://", CustomHttpAdapter())try:response = session.post(url="https://cmsauth.baowugroup.com/v1/web/api/content/list",headers=headers,params=params,data=json.dumps(payload, separators=(',', ':')),verify=False # 确保禁用验证)response.raise_for_status()return response.json()except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return Nonedef parse_data(page):json_data=make_request(page)for i in json_data['data']['data']:result={'title': i.get('listTitle', ''), # 如果不存在则返回空字符串'author': i.get('author', ''),'addDate': i.get('addDate', ''),'content': extract_text(i.get('content', '')) # 确保content存在再提取}save(result)print(f'{result['title']},保存成功')# 使用正则表达式提取文字内容
def extract_text(html):# 去除HTML标签text = re.sub(r'<[^>]+>', '', html)# 替换HTML实体text = text.replace('“', '"').replace('”', '"')# 去除多余的空格和换行text = re.sub(r'\s+', ' ', text).strip()return textdef save(result):file_exists=os.path.exists('output.csv')with open('output.csv', 'a', encoding='utf-8-sig', newline='') as f:writer = csv.DictWriter(f, fieldnames=['title', 'author', 'addDate', 'content'])if not file_exists:writer.writeheader()writer.writerow(result)if __name__ == "__main__":for page in range(0,14):print(f'正在爬取第{page}页')parse_data(page)3.hmac 加密逆向案例
(1)逆向目标
网址:https://www.qcc.com
接口:https://www.qcc.com/api/search/searchMulti
加密参数:
(2)逆向分析
xhr定位:
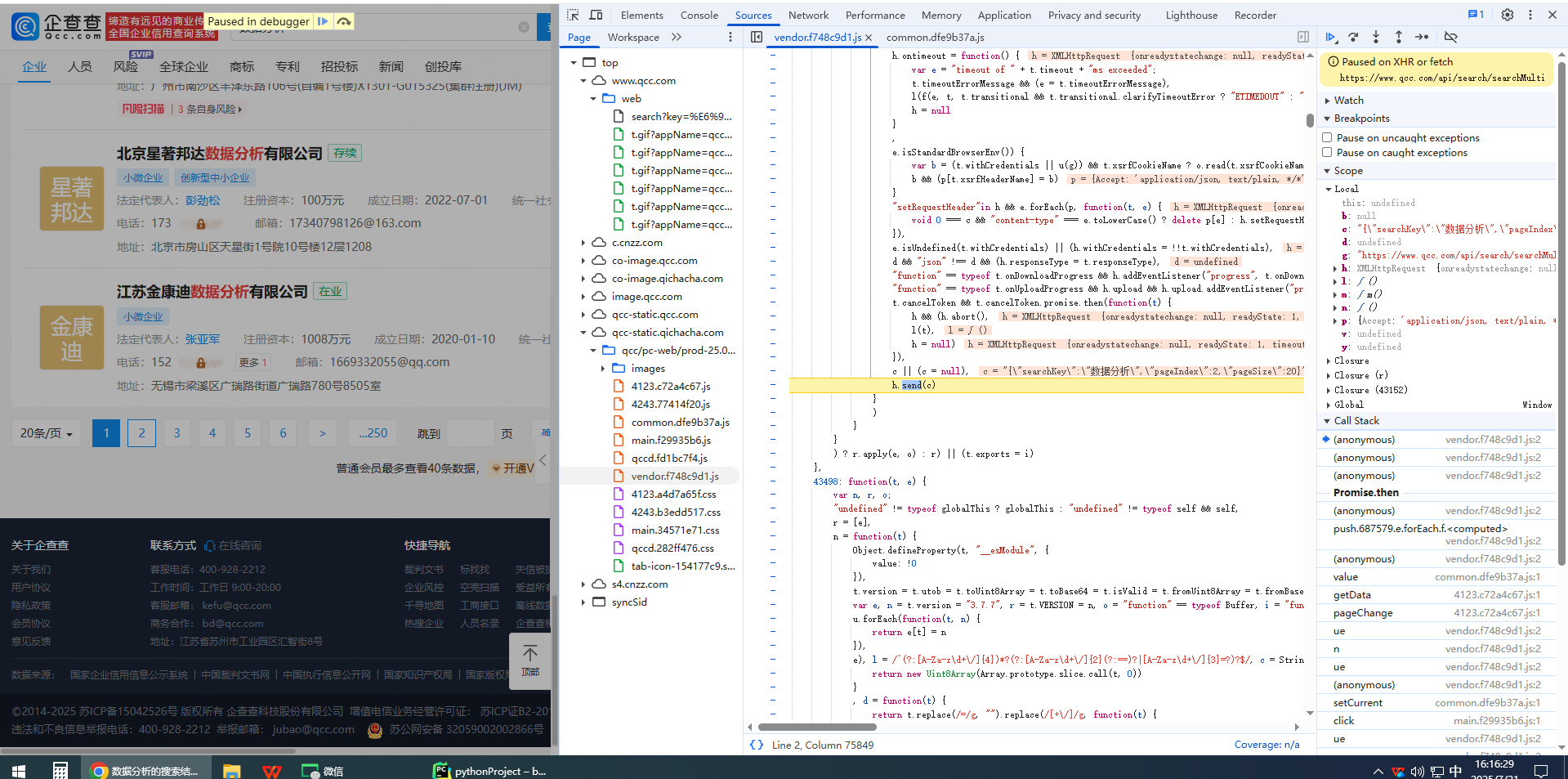
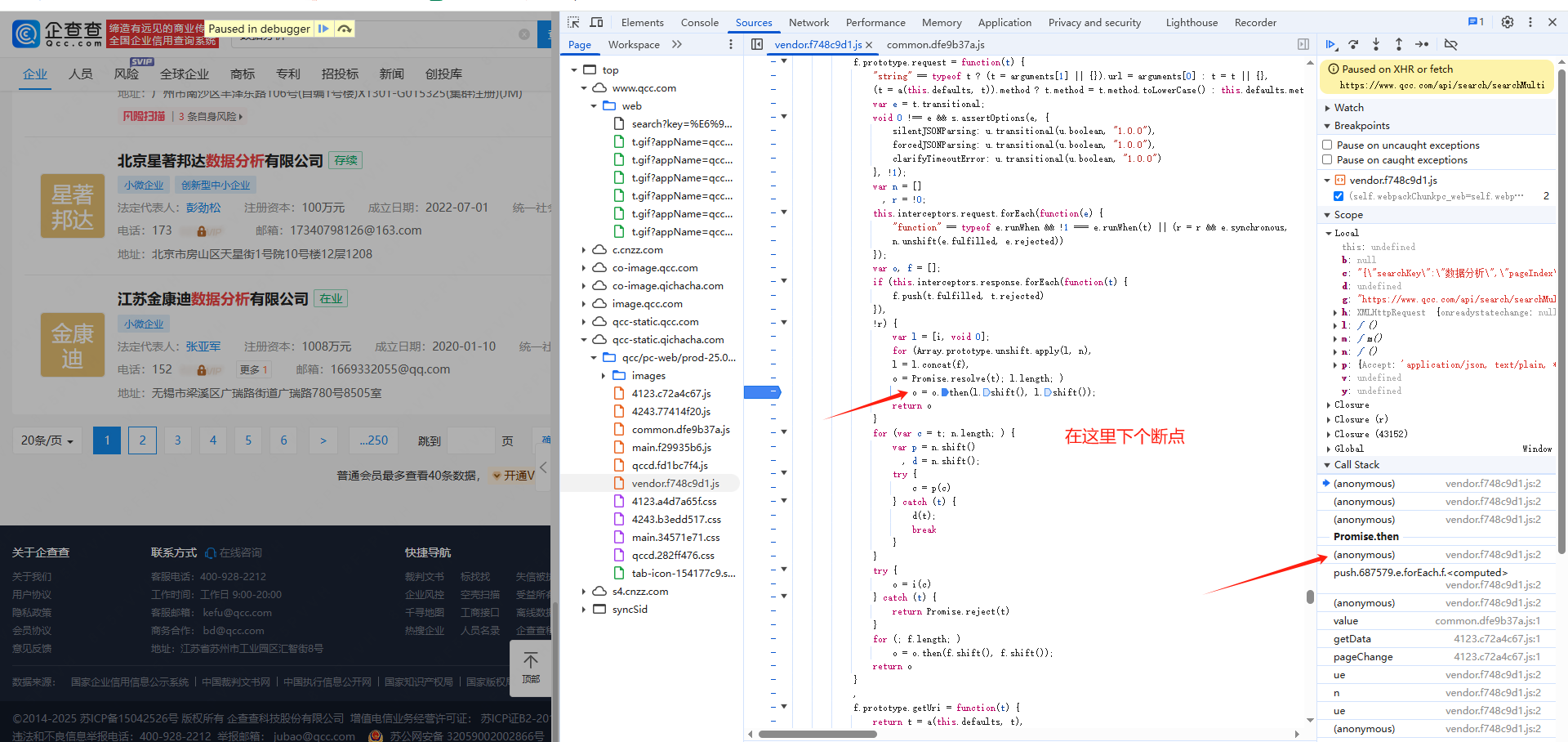
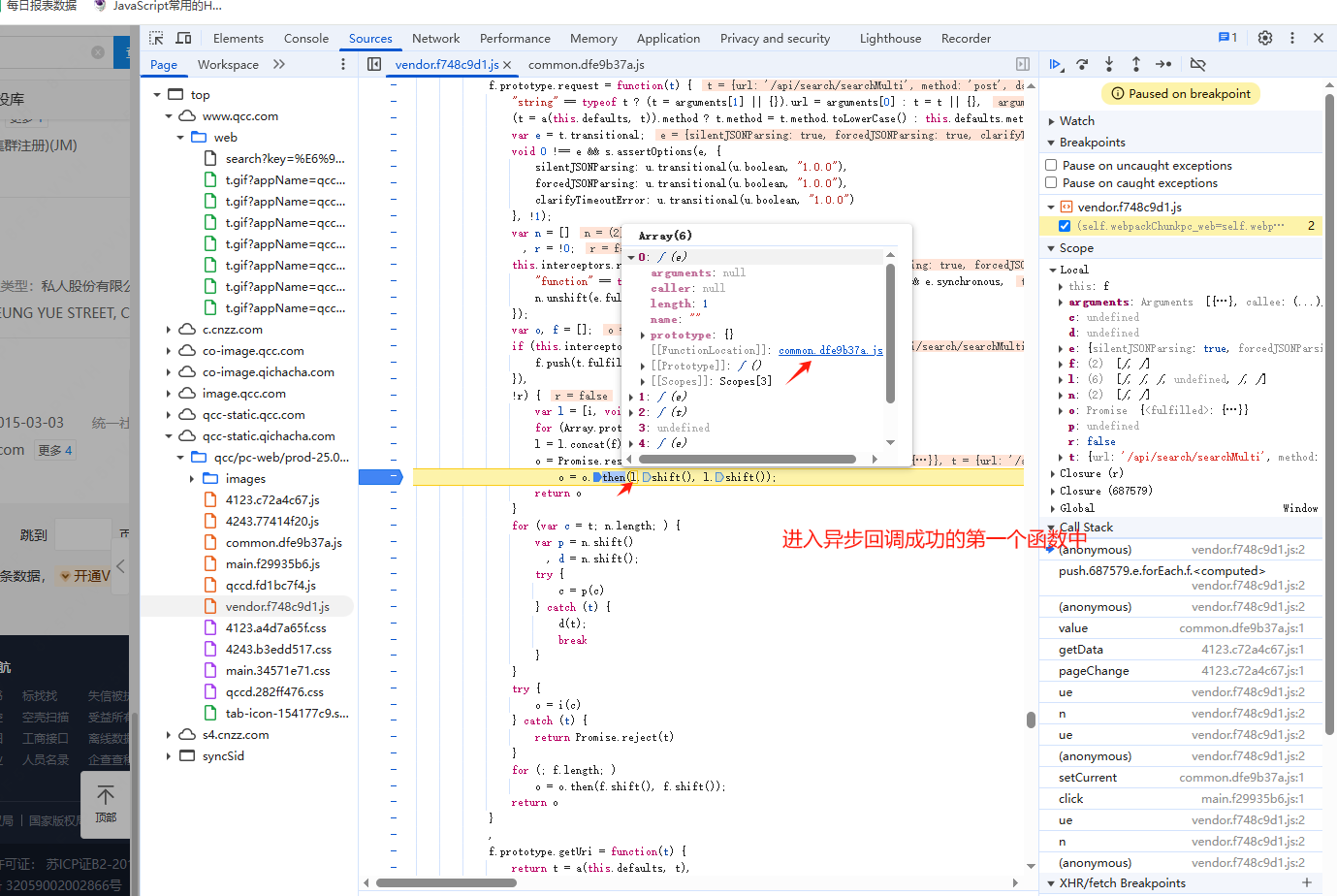

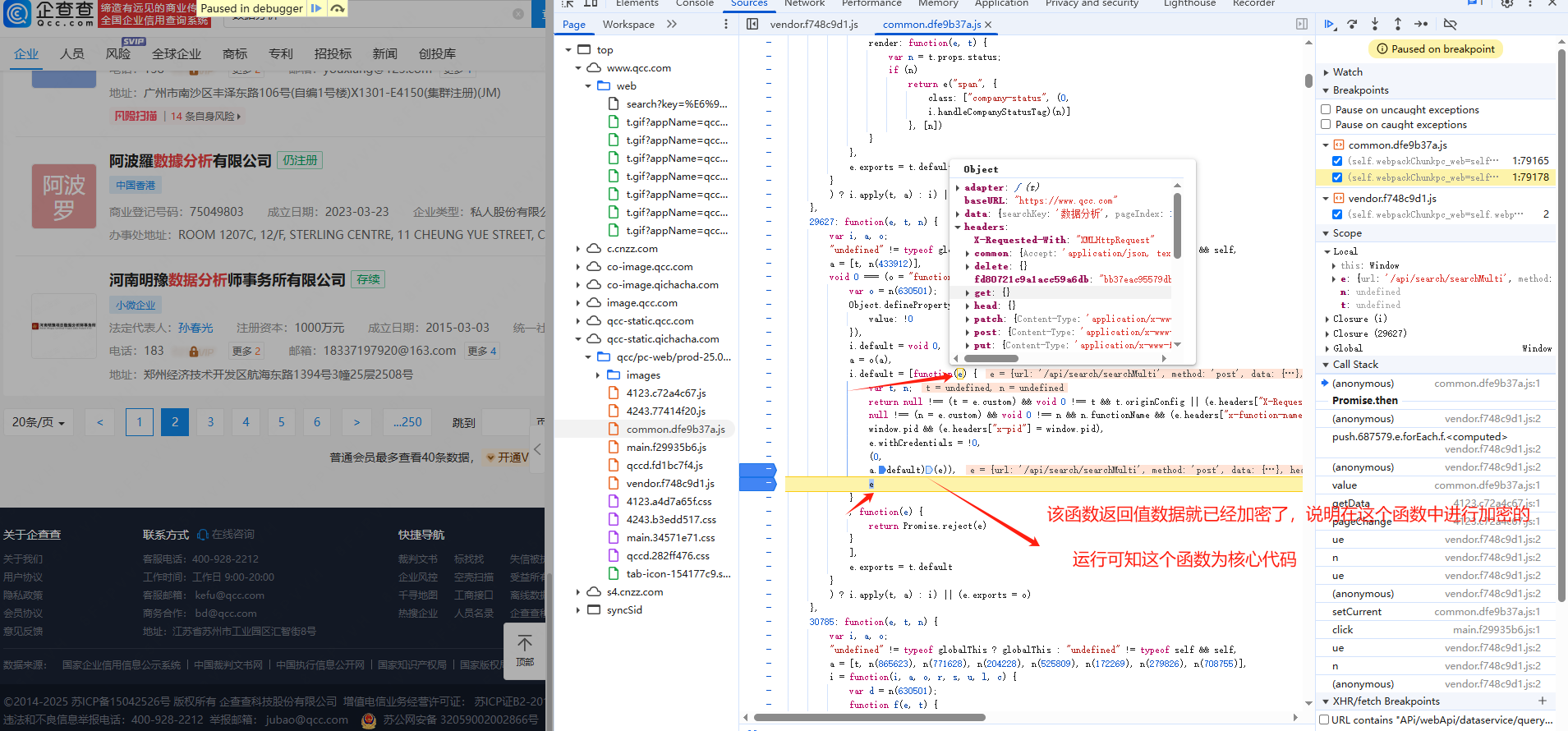
(3)代码实现
javascript代码:
var crypto_js = require("crypto-js");
var window = globalfunction get_hmac(e, t) {return crypto_js.HmacSHA512(e, t).toString()
}var dd = {"n": 20,"codes": {"0": "W","1": "l","2": "k","3": "B","4": "Q","5": "g","6": "f","7": "i","8": "i","9": "r","10": "v","11": "6","12": "A","13": "K","14": "N","15": "k","16": "4","17": "L","18": "1","19": "8"}
}function o1() {for (var e = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), t = e + e, n = "", i = 0; i < t.length; ++i) {var o = t[i].charCodeAt() % dd.n;n += dd.codes[o]}return n
}function get_key() {var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {}, t = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), n = JSON.stringify(e).toLowerCase();return get_hmac(t + n, o1(t)).toLowerCase().substr(8, 20)
}function get_val() {var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {}, t = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : "", n = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), i = JSON.stringify(e).toLowerCase();return get_hmac(n + "pathString" + i + t, o1(n))
}function get_head(page) {var t = "/api/search/searchmulti"var data = {"searchKey": "数据分析","pageIndex": page,"pageSize": 20}var i = get_key(t, data)var u = get_val(t, data, "3eafef687a41c14403d92bb27832ac2d");var headers = {}headers['key'] = iheaders['val']=ureturn headers
}
python代码:
import csv
import os.pathimport requests
import json
import execjs
import datetimeclass Qcc():def __init__(self):self.headers = {"accept": "application/json, text/plain, */*","accept-language": "zh-CN,zh;q=0.9","content-type": "application/json","origin": "https://www.qcc.com","priority": "u=1, i","referer": "https://www.qcc.com/web/search?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90","sec-ch-ua": "\"Google Chrome\";v=\"137\", \"Chromium\";v=\"137\", \"Not/A)Brand\";v=\"24\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","sec-fetch-dest": "empty","sec-fetch-mode": "cors","sec-fetch-site": "same-origin","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36","x-pid": "5bc82d14c7ba5674cb6adf46f34bc831","x-requested-with": "XMLHttpRequest"}self.cookies = {"qcc_did": "ffa1cee2-9a7c-45cd-9ac6-9acef982488b","UM_distinctid": "197e95e8a49571-0de7b7fc12e66e-26011e51-1fa400-197e95e8a4a493","_c_WBKFRo": "2gO8dngyOEHS0XTdB3u7rIfrkCIBkIpTq29UhbcS","QCCSESSID": "db7acd5a8a904fcf05cabf9562","CNZZDATA1254842228": "1887580038-1751966977-https%253A%252F%252Fcn.bing.com%252F%7C1755048341","acw_tc": "0a47308817550501936877347e94e8b3e925d636d8373691de3c9e9bd2fc3a"}self.url = "https://www.qcc.com/api/search/searchMulti"self.filename='qcc.csv'"""请求响应数据"""def get_info(self,page,header_data):data = {"searchKey": "数据分析","pageIndex": page,"pageSize": 20}self.headers[header_data["key"]] = header_data["val"]data = json.dumps(data, separators=(',', ':'))response = requests.post(self.url, headers=self.headers, cookies=self.cookies, data=data)return response.json()def format_timestamp(timestamp):"""将时间戳(毫秒)转为 YYYY-MM-DD 格式"""if not timestamp:return ""return datetime.datetime.fromtimestamp(timestamp / 1000).strftime("%Y-%m-%d")"""解析数据"""def parse_data(self,data):for i in data['Result']:result = {}# 基础信息result["公司名称"] = i.get("Name", "").replace("<em>", "").replace("</em>", "")result["统一社会信用代码"] = i.get("CreditCode", "")result["法定代表人"] = i.get("OperName", "")result["注册资本"] = i.get("RegistCapi", "")result["成立日期"] = (i.get("StartDate")) # 格式化时间戳result["经营状态"] = i.get("Status", "")# 行业信息industry = i.get("Industry", {})result["行业大类"] = industry.get("Industry", "")result["细分行业"] = industry.get("MiddleCategory", "") # 如"互联网数据服务"# 地址和联系方式result["注册地址"] = i.get("Address", "")result["联系电话"] = i.get("ContactNumber", "")result["邮箱"] = i.get("Email", "")# 其他关键信息result["企业类型"] = i.get("EconKind", "") # 如"有限责任公司"result["是否高新技术企业"] = any(tag.get("Type") == 108 for tag in i.get("TagsInfoV2", []))self.save(result)print(f'{result["公司名称"]},保存成功')"""保存数据"""def save(self,result):header = ["公司名称", "统一社会信用代码", "法定代表人", "注册资本", "成立日期", "经营状态", "行业大类", "细分行业", "注册地址", "联系电话", "邮箱", "企业类型", "是否高新技术企业"]file_exists=os.path.exists('qcc.csv')with open('qcc.csv', 'a', encoding='utf-8') as f:writer = csv.DictWriter(f, fieldnames=header)if not file_exists:writer.writeheader()writer.writerow(result)def main(self):with open('qcc.js', 'r', encoding='utf-8') as f:js_code=f.read()for page in range(1,3):print(f'正在爬取第{page}页')js=execjs.compile(js_code)header_data=js.call('get_head',page)data=self.get_info(page,header_data)self.parse_data(data)if __name__ == '__main__':q=Qcc()q.main()4.案例4
(1)逆向目标
网址:frame-shop-web
接口:https://wuhan.hbdzcg.com.cn/e-business/act/purchaseAnnouncement/listPage
加密参数: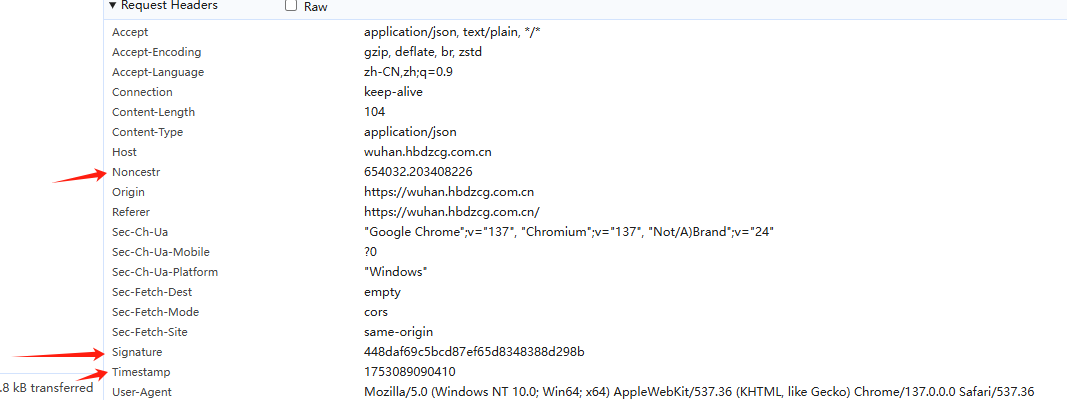
(2)逆向分析
关键字定位: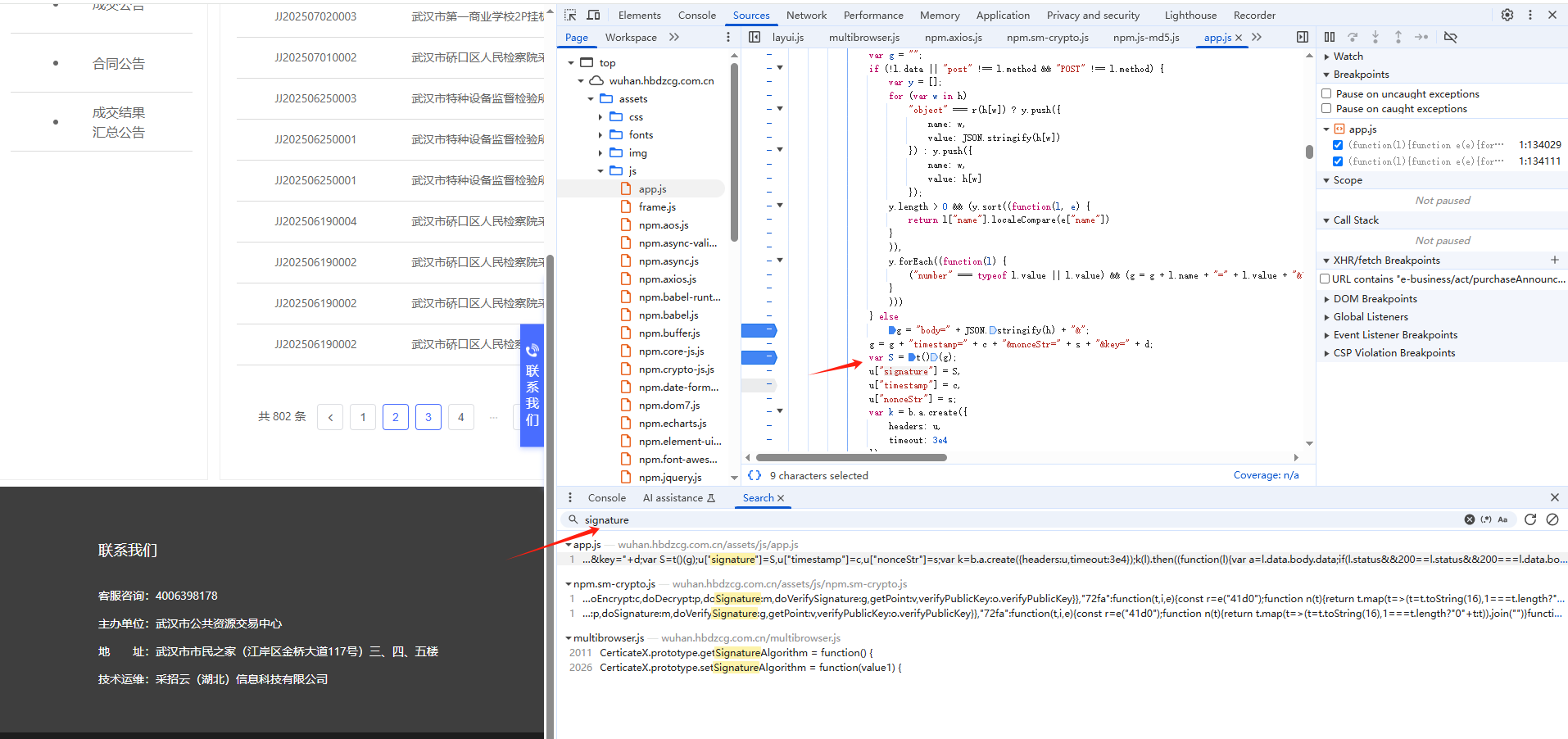
(3)代码实现
JS代码:
var Crypto = require('crypto-js')function get_md5(data) {return Crypto.MD5(data).toString()
}function wuhan(page) {var c = (new Date).getTime()var s = 1e6 * Math.random()var d = "MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAIQ3aWYA"var h = {"page": page,"pageSize": 10,"unitId": 1,"announcementTitle": "","announcementState": "","announcementType": "1"}var g = "body=" + JSON.stringify(h) + "&";g = g + "timestamp=" + c + "&nonceStr=" + s + "&key=" + dvar S = get_md5(g);var headers = {}headers["signature"] = S,headers["timestamp"] = c,headers["nonceStr"] = sreturn headers
}python代码:
"""
网址:https://wuhan.hbdzcg.com.cn/#/purchaseAnnouncement
接口:https://wuhan.hbdzcg.com.cn/e-business/act/purchaseAnnouncement/listPage
加密参数:signature
用搜索方法找加密地方
"""
import csvimport requests
import json
import execjs
import os
import timeclass Wu():def __init__(self):self.url = "https://wuhan.hbdzcg.com.cn/e-business/act/purchaseAnnouncement/listPage"def get_info(self,page):with open('wuhan_hbdzcg.js', encoding='utf-8') as f:js_code = f.read()js = execjs.compile(js_code)headers_data = js.call('wuhan', page)headers = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9","Connection": "keep-alive","Content-Type": "application/json","Origin": "https://wuhan.hbdzcg.com.cn","Referer": "https://wuhan.hbdzcg.com.cn/","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36","nonceStr": str(headers_data["nonceStr"]),"sec-ch-ua": "\"Google Chrome\";v=\"137\", \"Chromium\";v=\"137\", \"Not/A)Brand\";v=\"24\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","signature": headers_data["signature"],"timestamp": str(headers_data["timestamp"])}data = {"page": page,"pageSize": 10,"unitId": 1,"announcementTitle": "","announcementState": "","announcementType": "1"}data = json.dumps(data, separators=(',', ':'))response = requests.post(self.url, headers=headers, data=data)return response.json()def parse_data(self,data):item=dict()for i in data['body']['data']['list']:item['detail_url']=f'https://wuhan.hbdzcg.com.cn/#/purchaseAnnouncementDetail?id={i['announcementId']}'item['projectCode']=i['projectCode']item['announcementTitle']=i['announcementTitle']item['time']=i['bidTime']self.save(item)def save(self,item):file_exists = os.path.isfile('wuhan.csv') # 检查文件是否存在with open('wuhan.csv','a',newline='',encoding='utf-8') as f:header=['detail_url','projectCode','announcementTitle','time']f_csv=csv.DictWriter(f,fieldnames=header)if not file_exists:# 如果文件不存在,写入表头f_csv.writeheader()f_csv.writerow(item)print(f'{item['announcementTitle']}--保存成功')def main(self):for page in range(1,15):data=self.get_info(page)self.parse_data(data)time.sleep(3)if __name__ == '__main__':w=Wu()w.main()