Redis宝典
Redis是什么
Redis是开源的,使用C语言编写的,支持网络交互,可基于内存也可持久化到本地磁盘的Key-Value数据库。
优点:
- 因为Redis是基于内存的,所以数据的读取速度很快
- Redis支持多种数据结构,包括字符串String、列表List、字典Hash、集合Set、有序集合Zset、位图、地理空间等
- Redis支持事务,且所有的操作都是原子性的,要么都执行,要不都不执行
- Redis支持持久化存储,提供RDB快照和AOF日志追加的两种持久化方式,解决了Redis宕机后数据丢失问题
- 支持高可用,内置了Redis Sentinel哨兵机制,提供高可用方案,实现故障转移。内置了Redis Cluster,提供集群方案,实现基于槽的分片方案,从而支持更大的Redis规模
- Redis还由其它丰富的功能,比如Key过期、计数、分布式锁、消息队列等
缺点:
- 由于Redis是基于内存的,所以单台机器存储的数据量受限于机器本身的内存大小。虽然Redis也支持了多种数据淘汰策略,但还是需要提前预估和节约内存。如果内存增长过快,还需要定期删除数据
- 修改配置文件进行重启后,将磁盘中的数据加载到内存,这个时间比较久。在这个过程中,Redis不能对外提供服务
Redis为什么执行这么快
- 首先Redis是C语言实现的,效率高
- Redis是基于内存操作的,不受磁盘IO瓶颈限制
- Redis是单线程模型可以避免因上下文切换及资源竞争导致耗时问题,也不用考虑各种锁竞争问题
- Redis采用了非阻塞IO多路复用机制提高了网络IO的传输性能
Redis的线程模型
Redis内部使用了文件事件处理器(file event handler),这个文件事件处理器是单线程的,所以Redis才叫做单线程模型。另外还采用了非阻塞的IO多路复用机制同时监听多个socket,根据socket上的事件来选择对应的事件处理器进行处理。
文件事件处理器包含4个部分:
- 多个socket
- IO多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个socket可能会产生不用的操作,每个操作对应不同的文件事件,IO多路复用程序监听多个socket,会将socket上的事件放入等待队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
Redis的数据类型及底层实现
Redis中有5中基础的数据结构,分别是:String字符串、List列表、Hash、Set集合、Zset有序集合,此外还支持4种不常用的数据结构:BitMap位图、HyperLogLog基数统计、Geo地理位置、Stream流
String
字符串是最常用的数据类型,在Redis中一个字符串的最大容量是512MB,但是一般建议Key的大小不要超过1KB,这样既节省空间又有利于检索。
应用场景:
- 缓存结构信心
- 分布式锁
- 计数器
LIst
List的底层实现是一个双向链表,支持两端插入和弹出,并且里面存放的元素是有序的,可以通过索引获取元素。
应用场景:
- 比如Twitter的关注列表和粉丝列表等都可以用List列表实现,另外还可以通过lrange命令,做分页功能
- 可以基于rpush和lpop指令,实现消息队列
Hash
哈希的底层实现是数组+链表,通过链地址法来解决哈希冲突,没有用到红黑树。
应用场景:
- Hash特别适合存储对象信息,比如存储用户对象信息,用户id可以作为Key,Value是一个map,map中存放了所有的属性信息
Set
内部实现是一个Value为null的HashMap,通过hash值去重
应用场景:
- 主要用于存储不希望又重复数据的场景
Zset
内部使用HashMap和跳跃表来保证数据的不重复且有序。通过提供一个优先级Score参数来保证元素有序。
应用场景:
- 排行榜,比如百度热搜排行榜
- 也可以用来实现延时队列,把想要执行时间的时间戳作为score,消息内容作为key,调用zadd来生产消
息,消费者zrangebyscore指令来获取N秒之前的消息轮询进行处理
为啥Zset用跳跃表而不用红黑树实现?
- skiplist的复杂度和红黑树一样O(log n),而且实现起来更简单
- 在并发场景下红黑树在插入和删除是都需要rebalance,性能不如跳跃表
跳跃表
在一般的链表中,如果我们需要查询一个元素,可能需要遍历链表,这样的时间复杂度是O(n)。而跳
跃表通过维护一个多层的链表,为链表查询提供了“快速通道”。在跳跃表中,每一个节点包含多个
“层”,每一层都有一个前进指针指向下一个节点,通过这种方式,跳跃表能够在横向和纵向上进行查
询,大大提高了查询效率。
跳跃表的查询、插入和删除操作都能够在O(log n)的时间复杂度内完成,这是因为跳跃表中的每一个节
点都包含了多个层,这些层通过前进指针和后退指针,实现了在不同层之间的快速跳转。
每个跳跃表节点包含以下信息:
- 层(level):每个节点包含多个层,每一层都包含一个前进指针(forward)和一个跨度
(span)。 - 前进指针(forward):指向同一层中的下一个节点。通过前进指针,跳跃表可以在同一层中快速
地定位目标节点。 - 跨度(span):记录前进指针所跨越的节点个数。跨度的作用是在跳跃表中快速定位目标节点。
后退指针(backward):指向同一层中的前一个节点。通过后退指针,跳跃表可以在同一层中快
速地定位前一个节点。
Redis事务
REdis事务时一组有序命令的集合,是Redis的最小执行单位。可以保证一次执行多个命令,每个事务是一个单独的隔离操作,事务中的命令按顺序执行。不支持回滚。
Redis事务涉及的4个指令:
- Multi 开启事务
- Exec 执行事务内的命令
- Discard 取消事务
- Watch 监听一个或多个Key,如果事务执行前Key被改动,事务被打断
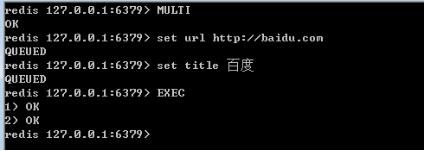
在项目中不使用Redis事务的原因:
- Redids是集群部署的,有16个节点,项目中不同的Key可能分布在不同的节点上,Redis事务对不同节点上的数据操作会失效
- Redis单条命令保证原子性,但事务不保证原子性。
- Redis事务不支持回滚,所以一般不用
Redis的同步机制
Redis支持个主从同步、从从同步,如果第一次进行主从同步,主节点需要使用bgsave命令,再将后续的修改操作记录保存到内存的缓冲区,等RDB快照文件全部同步到从节点,且从节点加载到内存后,从节点再通知主节点把复制期间修改的操作记录再次同步到从节点,即可完成同步过程
pipeline 有什么好处,为什么要用 pipeline?
使用pipeline管道的好处在于可以将多次IO往返的事件缩短为一次,但要求管道中执行的命令没有先后因果关系。
使用pipeline的原因在于客户端不用每次等待服务器响应后才能处理后续请求,可以将多个请求发送到服务器,只需在最后一步读取回复即可
Redis的持久化方式
Redis提供两种持久化方式 RDB快照 和 AOF日志追加:
RDB持久化方式:
RDB 持久化方式能够在指定的时间间隔对缓存中的数据进行快照存储。Redis 会段都创建(fork)一个子进程来进行持久化,会先将数据写入到临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO 操作的,这就确保了极高得性能,如果需要进行大规模数据的恢复,且对数据恢复得完整性不是非常敏感,那么RDB 方式要比 AOF 方式更加高效。
保存策略:
save 900 1 900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10 300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 1 0000 60 秒内如果至 10000 个 key 的值变化,则保存
优点:
- 只有一个dump.rdb文件,方便持久化
- 容灾性好,一个文件可以保存到安全的磁盘
- 高性能,fork子进程来完成写操作,让主进程继续处理命令,IO最大化
- 当数据量比较大时,比AOF的启动效率更高
缺点:
- 数据安全性低,因为RDB时间隔一段时间进行持久化,如果持久化之间发生故障,那么就会导致数据丢失。所以这种方式更适合数据要求不严谨的业务场景。
AOF=Append-only file 持久化方式:
将所有执行的命令以追加的方式记录到AOF日志文件中。Redis 重新启动时读取这个文件,重新执行日志文件中的命令达到恢复数据目的。
保存策略:
appendfsync always:每次产生一条新的修改数据的命令都执行保存操作;会影响性能,但是安全!
appendfsync everysec:每秒执行一次保存操作。如果在未保存当前秒内操作时发生了断电,仍然会导致一部分数据丢失(即 1 秒钟的数据)。
appendfsync no:命令仅写入 AOF 缓冲区,由操作系统决定何时同步到磁盘(通常依赖操作系统的页缓存机制,可能每 30 秒左右同步一次)。性能影响最小,也更不安全的选择。推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
优点:
- 数据安全,可以在配置文件中配置命令写入的频次,避免数据丢失
- 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据
一致性问题 - AOF机制的rewrite模式。AOF文件没被rewrite之前,可以对文件中的命令调整。
缺点:
- AOF文件比RDB文件大,且恢复速度慢
- 数据集大的时候,比RDB启动效率低。
两种持久化方式,要搭配使用:
- 不要仅仅使用 RDB ,因为那样会导致你丢失很多数据。
- 也不要仅仅使用 AOF ,因为那样有两个问题,第一,你通过 AOF 做冷备没有 RDB 做冷备的恢
复速度更快; 第二, RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备
份和恢复机制的 bug 。 - Redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,
用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF
文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。 - 如果同时使用 RDB 和 AOF 两种持久化机制,那么在 Redis 重启的时候,会使用 AOF 来重新
构建数据,因为 AOF 中的数据更加完整。
假如Redis中有1亿个key,找出其中所有指定前缀的key
使用keys指令可以扫出指定模式的key列表,但使用keys指令会阻塞正在提供服务,因为Redis时单线程的,直到keys指令执行完毕,服务才能恢复。也可以使用scan指令,scan指令可以无阻塞提取指定模式的key列表,但是会有一定的重复概率,需要在客户端做去重处理,另外耗时较长。
怎么使用 Redis 实现消息队列?
一般使用 list 结构作为队列, rpush 生产消息, lpop 消费消息。当 lpop 没有消息的时候,要适当
sleep 一会儿再重试。
- 面试官可能会问可不可以不用 sleep 呢?list 还有个指令叫 blpop ,在没有消息的时候,它会
阻塞住直到消息到来。 - 面试官可能还问能不能生产一次消费多次呢?使用 pub / sub 主题订阅者模式,可以实现 1:N
的消息队列。 - 面试官可能还问 pub / sub 有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用
专业的消息队列如 rabbitmq 等。 - 面试官可能还问 Redis 如何实现延时队列?使用sortedset ,拿时间戳作为 score ,消息内容作为
key 调用 zadd 来生产消息,消费者用zrangebyscore 指令获取 N 秒之前的数据轮询进行处理
什么是 bigkey?会存在什么影响?
bigkey 是指键值占用内存空间非常大的 key。例如一个字符串 a 存储了 200M 的数据。
bigkey 的主要影响有:
- 网络阻塞;获取 bigkey 时,传输的数据量比较大,会增加带宽的压力。
- 超时阻塞;因为 bigkey 占用的空间比较大,所以操作起来效率会比较低,导致出现阻塞的可能
性增加。
为什么Redis操作是原子性的,怎么保证原子性?
Redis中,命令的原子性是指:一个操作不可再分,要么执行,要么不执行。
Redis的操作之所以是原子性的,是因为Redis是单线程的。单个命令都是原子性的,若要保证多个命令具有原子性,可以通过Redis+Lua脚本的方式实现。
缓存雪崩、缓存穿透、缓存击穿、缓存更新、缓存降级等问题
缓存雪崩
缓存中的Key在同一时间大面积到期,导致大量请求都直接访问数据库,对数据库CPU和内存造成巨大压力,甚至宕机。
解决方案:
- 将缓存的失效时间分散开
- 访问数据库时上锁,避免同一时间大量请求发到数据库
缓存穿透
查询的数据在数据库中也没有,在缓存中自然也没有,每次首先查缓存查不到,都会再次查询数据库。若存在大量的这种请求,就会对数据库造成巨大压力。
解决方案:
- 使用布隆过滤器:对所有的key都做哈希放到一个足够大的bitmap中,bitmap中存放的都是0,1,在查询时若经过hash计算后,在bitmap中对应位置是0,那么数据肯定就不存在,可以直接返回空。为避免hash冲突,可以考虑多次hash。存在误判的情况。
- 若查询数据库为空,那么仍然缓存一个空置,并且设置一个很短的过期时间,比如1分钟。这样在短时间内,就避免了查询数据库。
缓存击穿
热点Key在缓存中失效的瞬间,大量并发请求直接穿透缓存访问数据库,导致数据库压力骤增甚至崩溃的现象。
解决方案:
- 热点Key永不过期,但牺牲了一致性,可以通过定时任务定期更新缓存
- 互斥锁:在缓存失效时,通过锁确保只有一个请求可以访问数据,其他请求等待锁释放后从缓存读取数据。
如何保证缓存和数据库的一致性
核心策略:先更新数据库,再删除缓存
- 优势
- 逻辑简单,避免复杂缓存更新逻辑
- 窗口期短(仅 DB 更新成功 → 缓存删除之间可能不一致)
- 存在的问题及解决方案
- 缓存删除失败:引入异步重试机制,写数据库后,将
删除缓存操作发到 消息队列 (Kafka/RabbitMQ),消费者自动重试直到成功。 - 短暂不一致窗口期:
- 设置 合理的缓存过期时间 (如 30s),作为兜底策略。
- 对一致性要求高的数据,在读取时采用 互斥锁(降低并发读旧数据概率)。
- 缓存删除失败:引入异步重试机制,写数据库后,将
终极一致性方案:订阅数据库变更日志 (Binlog)
✅ 工作流程:
- 使用 Canal 或 Debezium 监听 MySQL Binlog。
- 将数据变更事件发到消息队列。
- 消费者根据事件 删除/更新 Redis 缓存。
💡 优势:
- 彻底解耦:应用无需关注缓存删除逻辑
- 强顺序保证:Binlog 天然有序,避免并发导致的数据错乱
- 高可靠性:即使应用重启,也能从断点继续处理
应对高并发写:延迟双删
✅ 使用场景:
- 在"先删缓存再更新DB"策略中,防止旧数据在更新期间被重新加载到缓存
- 第二次删除用于清理可能存在的脏数据
⚠️ 注意:
- 延迟时间需根据业务读写耗时调整(通常 200ms~1s)
- 需配合消息队列实现可靠延迟
延时双删(解决并发读问题)
-
流程
- 先删除缓存
- 更新数据库
- 延迟 N 秒(通常 1-3 秒)再次删除缓存
-
作用:
处理 “删除缓存后,有读请求在数据库更新前读取旧值并重建缓存” 的问题。
Redis哈希槽
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通
过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
Redis集群模式
Redis 集群(Redis Cluster)是 Redis 官方提供的分布式解决方案,用于解决单机 Redis 的性能瓶颈(内存、QPS)和单点故障问题。它通过 数据分片(Sharding)、高可用(HA) 和 自动故障转移 三大核心能力,实现大规模数据存储与高性能访问
一、核心特性
| 特性 | 说明 |
|---|---|
| 数据分片 | 将数据自动拆分到 16384 个 Slot 中,分散在多个节点(分片)存储 |
| 去中心化架构 | 节点间使用 Gossip 协议 通信,无需代理层(如 Twemproxy/Codis) |
| 高可用 | 每个分片包含 主节点(Master) + 从节点(Replica),支持自动故障转移 |
| 客户端路由 | 客户端直接连接集群,通过 CRC16(key) mod 16384 计算 Slot 并路由到正确节点 |
| 线性扩展 | 支持动态增删节点,数据自动重平衡(Resharding) |
二、集群架构
- 最小集群规模:3 个主节点 + 3 个从节点(生产环境推荐至少 6 节点)
- Slot 分配:每个主节点负责一部分 Slot(如节点 A 管理 Slot 0-5500,节点 B 管理 5501-11000 等)
- 故障转移:主节点宕机时,从节点自动升主(由其他主节点投票选举)
集群方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 官方集群 | 原生支持、去中心化、自动故障转移 | 客户端需支持集群协议、跨Slot操作复杂 | 大规模数据、高可用要求 |
| Codis | 兼容旧客户端、Proxy 层透明 | 引入代理层(性能损耗)、依赖 ZooKeeper | 平滑迁移、多语言生态 |
| Redis Sentinel | 简单、主从自动切换 | 不分片(单机内存受限) | 中小规模、高可 |
Redis常见的性能问题和解决方案
- Master最好不要做任何持久化工作,避免因负载导致服务崩溃
- 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
- 为了主从复制的速度和连接的稳定性,Master 和 Slave最好在同一个局域网内
- 尽量避免在压力很大的主库上增加从库
- 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2…;这样的结构方便解决单点故障问题,实现Slave对Master的替换
什么情况下可能会导致 Redis 阻塞?
Redis 产生阻塞的原因主要有内部和外部两个原因导致:
内部原因:
- 如果 Redis 主机的 CPU 负载过高,也会导致系统崩溃;
数据持久化占用资源过多; - 对 Redis 的 API 或指令使用不合理,导致 Redis 出现问题。
外部原因:
外部原因主要是服务器的原因,例如服务器的 CPU 线程在切换过程中竞争过大,内存出现问题、网
络问题等。
Redis中的数据淘汰策略
Redis中的内存淘汰策略时当内存使用达到预设值maxmemory限制时,删除部分数据释放空间。
-
noeviction(默认策略)
- 行为:内存满时,不再支持写入操作(OOM错误),仅支持读/删除命令
- 场景:需要保证数据的完整性(如金融交易数据)
-
volatile-ttl
- 行为:从所有设置有过期时间key中,找出剩余生存时间最短的数据删除
- 场景:需要优先清理即将过期的数据(如限时优惠券)
-
volatile-random
- 行为:随机淘汰有过期时间的键
- 场景:数据不重要且无访问规律(如临时会话数据)
-
volatile-lru
- 行为:基于LRU(Least Recently Used),淘汰设置了过期时间的键中最近最少使用的键
- 场景:区分冷热数据且需要持久化部分关键数据(如用户登录会话)
-
volatile-lfu
- 行为:基于LFU(Least Frequently Used),淘汰设置了过期时间中使用频率最低的键
- 场景:适用于缓存短时高频访问数据(如突发热点新闻数据)
-
allkeys-random
- 行为:从所有键中随机淘汰键,无论是否设置过期时间
- 场景:数据无冷热区分或访问均匀(如静态资源缓存)
-
allkeys-lru
- 行为:基于LRU(Least Recently Used),淘汰所有键中最近最少使用的键
- 场景:缓存场景需保留高频访问数据(如电商热点数据)
-
allkeys-lfu
- 行为:基于LFU(Least Frequently Used),淘汰所有键中使用频率最低的键
- 场景:需要长期保留高频访问数据(如用户行为画像数据)
Redis实现分布式锁
核心设计原则
分布式锁五大特性
| 特性 | 说明 | 实现方案 |
|---|---|---|
| 互斥性 | 同一时刻只能有一个客户端持有锁 | Redis的原子操作 |
| 防死锁 | 锁必须支持自动释放 | key设置过期时间 |
| 容错性 | Redis节点故障时仍可用 | 多节点部署 |
| 身份安全 | 只能由锁持有者释放锁 | 唯一标识校验 |
| 可重入性 | 同一客户端可多次获取锁 | 计数器实现 |
基础实现方案
单节点Redis锁(SETNX方案)
// 加锁
String lockKey = "order_lock_123";
String clientId = UUID.randomUUID().toString();
boolean locked = jedis.set(lockKey, clientId, "NX", "PX", 30000) != null;// 解锁(Lua脚本保证原子性)
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +" return redis.call('del', KEYS[1]) " +"else " +" return 0 " +"end";
jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(clientId));
| 参数 | 值 | 作用 |
|---|---|---|
| NX | 不存在才设置 | 保证互斥性 |
| PX | 3000ms | 30s自动过期防止死锁 |
| clientId | UUID | 唯一标识持有者,保证身份安全 |
分布式高可用方案(RedLock算法)
Java实现(Redisson库)
Config config = new Config();
config.useClusterServers().addNodeAddress("redis://node1:6379").addNodeAddress("redis://node2:6379").addNodeAddress("redis://node3:6379");RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("orderLock");try {// 尝试加锁,最多等待10秒,锁自动释放时间30秒if (lock.tryLock(10, 30, TimeUnit.SECONDS)) {// 执行业务逻辑}
} finally {lock.unlock();
}
锁续期(Watchdog机制)
// Redisson的看门狗实现(默认每10秒续期)
private void scheduleExpirationRenewal(String threadId) {Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) {// 异步续期操作renewExpirationAsync(threadId);}}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
}
可重入锁实现
-- 加锁Lua脚本(支持可重入)
local counter = redis.call('hget', KEYS[1], ARGV[1])
if counter thenredis.call('hincrby', KEYS[1], ARGV[1], 1)redis.call('pexpire', KEYS[1], ARGV[2])return 1
elseif redis.call('exists', KEYS[1]) == 0 thenredis.call('hset', KEYS[1], ARGV[1], 1)redis.call('pexpire', KEYS[1], ARGV[2])return 1endreturn 0
end
性能优化策略
锁分段优化(提升并发)
// 将大锁拆分为多个小锁
String[] segmentLocks = new String[16];
for (int i = 0; i < 16; i++) {segmentLocks[i] = "order_lock_" + i;RLock lock = redisson.getLock(segmentLocks[i]);// 分别加锁
}
容灾处理方案
Redis节点故障处理
| 场景 | 解决方案 |
|---|---|
| 主节点宕机 | 启用哨兵自动切换 |
| 网络分区 | 使用NTP时间同步 |
| 持久化丢失 | 启用AOF+RDB备份 |
锁状态监控
# Redis监控命令
redis-cli info stats | grep sync_full # 检查主从同步
redis-cli slowlog get # 分析慢查询
最佳实践
-
TTL设置原则
- 业务最大执行时间 < TTL < Redis主从切换时间
- 推荐值:30s-120s
-
集群部署建议
-
压测指标参考
指标 单节点 三节点集群 加锁QPS 15,000 45,000 解锁延迟 <2ms <5ms 锁续期间隔 10秒 10秒
多种分布式锁对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Redis锁 | 高性能、易扩展 | 需要处理时钟漂移 | 高并发业务 |
| Zookeeper | 强一致性 | 性能较低 | 金融交易 |
| Etcd | 高可用、租约机制 | 部署复杂 | 云原生系统 |
| DB锁 | 简单直接 | 性能瓶颈 | 低频操作 |
推荐选择:对于大多数业务场景,使用Redis分布式锁(配合Redisson库)是最佳平衡方案
典型问题解决方案
问题1:锁提前过期
- 方案:实现锁续期机制(Watchdog)
- 代码:
lock.tryLock(0, 30, SECONDS) // 自动续期
问题2:主从切换丢锁
- 方案:使用RedLock算法
- 配置:至少3个独立Redis实例
问题3:客户端阻塞导致超时
- 方案:设置合理的等待时间
- 代码:
lock.tryLock(100, TimeUnit.MILLISECONDS)
问题4:锁重入需求
- 方案:使用可重入锁(RLock)
- 代码:
redisson.getLock().lock() // 可多次调用
watch dog 自动延期机制
客户端 1 加锁的锁 key 默认生存时间才 30 秒,如果超过了 30 秒,客户端 1 还想一直持有这把
锁,怎么办呢?
简单!只要客户端 1 一旦加锁成功,就会启动一个 watch dog 看门狗, 他是一个后台线程,会
每隔 10 秒检查一下,如果客户端 1 还持有锁 key,那么就会不断的延长锁 key 的生存时间。
Redis 在项目中的应用
Redis 一般来说在项目中有几方面的应用
-
作为缓存,将热点数据进行缓存,减少和数据库的交互,提高系统的效率
-
作为分布式锁的解决方案,解决缓存击穿等问题
-
作为消息队列,使用 Redis 的发布订阅功能进行消息的发布和订阅
Redis 服务器的的内存是多大
可以在配置文件中设置 redis得内存。如果不设置或者设置为0,则redis得默认内存为:32位下默认是 3G,64位下不受限制。一般推荐 Redis设置内存位最大物理内存的四分之三,也就是0.75。也可以通过命令 config set maxmemory <内存大小,单位字节> 来配置内存大小,但服务器重启后失效。config get maxmemory 获取当前内存大小
哨兵模式
在主从模式下,如果Master 节点异常,则会进行 主从切换,将其中一个 Slave 从节点作为 Master节点,将之前的Master节点作为Salve节点
判断主节点下线:
- 主观下线:指的是某个Sentinel哨兵节点 对某个 redis 服务器节点做出下线判断
- 客观下线:指的是某个Sentinel哨兵节点对 Master节点做出了主观下线判断,并且通过 sentinel is-master-down-by-addr 命令互相交流后,得出master主节点下线判断,然后开启failover 失败转移
工作原理:
- 每个 Sentinel 哨兵以每秒一次的频率向它所知得master、slave以及其它sentinel 实例发送一个 PING命令;
- 如果某个实例距离最后一次有效回复 PING命令得时间超过 down-after-milliseconds 选项设定的值,则这个实例就会被标记为主观下线
- 如果一个Master被标记为主观下线,则正在监视这个Master 得所有 Sentinel 要以每秒一次得频率确认 Master 的确进如了主观下线状态
- 当有足够数量的 Sentinel(大于等于配置文件中指定的值)在指定时间范围内确认 Master 的确进入了主观下线状态,则Master 会被标记为客观下线
- 一般情况下,每个Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave 发送INFO命令
- 当Master 被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave 发送 INFO 命令的频率会从10秒一次改为每秒一次
- 若没有足够数量的 Sentinel统一 Master已经下线,Master的客观下线状态就会被移除
entinel哨兵节点 对某个 redis 服务器节点做出下线判断 - 客观下线:指的是某个Sentinel哨兵节点对 Master节点做出了主观下线判断,并且通过 sentinel is-master-down-by-addr 命令互相交流后,得出master主节点下线判断,然后开启failover 失败转移
工作原理:
- 每个 Sentinel 哨兵以每秒一次的频率向它所知得master、slave以及其它sentinel 实例发送一个 PING命令;
- 如果某个实例距离最后一次有效回复 PING命令得时间超过 down-after-milliseconds 选项设定的值,则这个实例就会被标记为主观下线
- 如果一个Master被标记为主观下线,则正在监视这个Master 得所有 Sentinel 要以每秒一次得频率确认 Master 的确进如了主观下线状态
- 当有足够数量的 Sentinel(大于等于配置文件中指定的值)在指定时间范围内确认 Master 的确进入了主观下线状态,则Master 会被标记为客观下线
- 一般情况下,每个Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave 发送INFO命令
- 当Master 被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave 发送 INFO 命令的频率会从10秒一次改为每秒一次
- 若没有足够数量的 Sentinel统一 Master已经下线,Master的客观下线状态就会被移除
- 若 Master 重新向 Sentinel 的PING 命令返回有效恢复,Master 的主观下线状态就会被移除;