h5bench(3)
3.1.21OpenPMD访问模式
OpenPMD 是一个开放的元数据模式,为科学和工程领域的数据集提供含义和自我描述。openPMD-API 库 提供了一个参考 API 来处理 OpenPMD 中的数据。在 h5bench 套件中,我们提供对使用 HDF5 后端的写入和读取并行基准测试的支持。
对于写入操作,该基准测试的输入包括维度数量、是否应模拟均衡负载、粒子与网格的比率、迭代次数、微型块的数量(块网格表示为微型块的网格)以及网格的大小。对于读取操作,该基准测试的输入包括维度数量、微型块的数量、网格的大小以及读取访问模式。读取模式可以是仅元数据,也可以是p网格在x、y或z轴上的切片,或者是3D磁场在x、y或z轴上的切片。
这大概是那种三维数组模拟的东西,模拟一个空间,1每个位置有一个值,物理上一般是这么干的。
3.1.31AMReX访问模式
AMReX 是一个用于大规模并行块结构自适应网格细化 (AMR) 应用的框架,这些应用用于燃烧、加速器物理、碳捕获与封存、宇宙学和天体物理学。块结构 AMR 能够在计算过程中实现时空感兴趣区域的不同分辨率。
AMReX 接受以下输入:域大小、每个子域的最大大小(用于并行分解)、层数、multifab 类中的组件、每个单元的粒子数、要写入的绘图和粒子文件、每次写入前的休眠时间,以及是否检查检查点/重启的正确性。此外,它允许 AMReX 从文件中读取网格,并指定细化比率和 HDF5 压缩算法。绘图文件和粒子输出都按 AMR 层组织数据,并将它们存储在单独的 HDF5 组中。在每个级别的组中,来自各个 AMR 块的数据被展平并连接成每个数据类型的单个一维数组(例如,整数和双精度浮点值)。访问模式可以归类为“连续-连续”。描述模拟参数和存储布局的附加元数据存储在每个组中。当使用压缩时,使用 HDF5 分块,默认块大小为 16 MB。
3.1.41E3SM访问模式
能源百亿亿次地球系统模型(E3SM)是地球气候的一个完全耦合模型,包括重要的生物地球化学和冰冻圈过程。32.3 E3SM使用希尔伯特空间曲线算法来划分线性化的20网格,该网格覆盖了所研究问题域的表面。分配给每个MPI进程的数据由一个很长的非连续子数组列表组成。在标准分辨率的E3SM生产运行中,每个进程的数量可以达到数十万个,这使得I/O任务在并行计算机上获得良好的性能非常具有挑战性。E3SM-lOl是一个基准程序,它捕获了E3SM的I/O内核,它已被用于评估使用各种I/O库时的I/O成本,并帮助改进E3SM的I/O实现。
h5bench套件目前支持三个E3SM模块的I/O模式——大气分量(F case)、海洋分量(G case)和陆地分量(l case)。F case包含387个2D和3D变量共享的三种独特的数据分解模式(一个共享分解1,323个共享分解2,63个共享分解3)。在F case中,每个进程写入文件中许多(每个进程最多174,953个)小的、非连续的区域。G case包含52个变量共享的六种数据分解(六个共享分解1,两个共享分解2,25个共享分解3,两个共享分解4,两个共享分解5,四个共享分解6)。因此,与F case相比,G case中进程写入的区域更少(每个进程最多20,888个),但区域更大。I case包含538个变量共享的五种数据分解(465个共享分解1,69个共享分解2,两个共享分解3,一个共享分解4,一个共享分解5,四个共享分解6)。I case的I/O模式与F case类似,只是文件中存在空洞(未写入的区域),并且数据在多个(240个)时间步长中写入。由于存在大量的碎片请求和一个几乎随机的I/O模式,E3sM-iO是I/O库最具挑战性的应用程序之一。
41结果
本节中呈现的结果被重复多次,跨越不同的日子,以考虑到共享文件系统的并发运行作业的可变性。在本文中,我们关注性能,特别是观察到的I/O速率,它表示写入或读取的数据量与执行所有写入或读取操作所花费的总挂钟时间之比。由于我们考虑的是总挂钟时间,因此该指标也将隐式地考虑花费在元数据相关操作上的时间。第4.1节总结了我们在生产机器上的初步观察,而以下各节探讨了在Perlmutter(第4.5节)、Theta(第4.6节)和Polaris(第4.7节)预百亿亿次机器上的初始性能。
为确保实验数据的可靠性,测试结果被多次重复执行,并跨越了不同的日期,以此来规避由于文件系统并发作业共享所带来的潜在变异性。在评估性能时,关键指标是I/O速率,该速率被定义为传输数据量与完成所有读写操作所耗费的总挂钟时间之比。通过关注总挂钟时间,该指标间接包含了元数据操作所占用的时间。文章的后续部分将按照特定顺序展开,首先在第4.1节呈现生产环境下的初步观察,随后在第4.5、4.6和4.7节分别深入探讨Perlmutter、Theta和Polaris这几款预超算平台上的初始性能表现。
4.1 | 超算上的HDF5性能
我们在2021年于 NERSC 的 Cori 和橡树岭领导计算设施 (OLCF) 的 Summit 上评估了 hsbench。我们将这些结果作为基线,并研究了三种新的前百亿亿次平台上的不同 HDF5 特性的性能:Perlmutter(第 4.5 节)。Theta(第 4.6 节)和 Polaris(第 4.7 节)。
4.1.1 1 Cori
Cori是一个Cray XC40系统,其峰值性能为30 PFlops。它包含两个主要的计算分区:Haswell和KNL。在本文的所有测试中,我们使用了具有2388个计算节点的Haswell分区。每个Haswell节点有两个插槽,每个插槽都有一个16核Haswell处理器。每个核心支持两个超线程,并且每个节点都有128 GB的DDR4内存,由两个插槽共享。
有点像所里的节点(笑
Cori提供了一个30 PB的Lustre文件系统作为文件的临时暂存空间。该文件系统的峰值性能为700 GB/s的I/O带宽。Lustre文件系统配备了248个对象存储目标(OST),默认条带化设置为1 MB条带大小和1个OST作为条带宽度。
用户可以使用1fs setstripe命令以及条带大小和条带宽度选项来更改Lustre上的条带化。NERSC提供了一个基于SSD的突发缓冲区,它使用Cray DataWarp.34。突发缓冲区的峰值带宽为1.7 TB/s,其中每个突发缓冲区节点(服务器)具有6.5 GB/s。
要请求突发缓冲区,用户必须请求所需的容量。每20 GB的容量请求提供一个突发缓冲区服务器。例如,请求100 GB的突发缓冲区会分配10个突发缓冲区服务器。
这个就是显式双目录的使用方式
4.1.2 Summit
Summit超级计算机基于IBM AC922系统。它包含4608个计算节点,每个节点配备2个IBM POWER9 (P9) 处理器和6个NVIDIA Tesla V100 (Volta) GPU。此外,每个节点有512 GB的DDR4 CPU内存,每个GPU有16 GB的HBM2内存。NVLink 2.0总线将每个P9 CPU连接到3个V100 GPU。
一个具有fat-tree拓扑的InfiniBand EDR网络连接这些节点。每个计算节点上都有一个1.6 TB NVMe设备,用于节点本地存储。
Summit的计算节点连接到中央范围的Alpine并行文件系统,这是一个250 PB的IBM Spectrum Scale (GPFS)部署。Summit的文件系统为顺序l/O提供2.5 TB/s的峰值性能。
4.1.3 | 实验设置
我们测试了表3中所示的h5bench配置,以展示基准测试套件的功能示例。我们至少运行了每个配置三次,并报告了每次运行的最佳性能。在Cori上,我们每个节点使用16个MPl等级;在Summit上,这些运行每个节点使用32个MPI等级。
在Cori Lustre上,我们使用了244的条带计数和16 MB的条带大小。在Cori的爆发缓冲区上,我们请求了8 TB,这分配了所有可用的270个爆发缓冲区服务器。在Summit的GPFS上,我们设置了16 MB的HDF5对齐,这等于GPFS的块大小。
在HDF5中,H5 Pset _al ignment调用设置文件访问的属性,以允许任何大于给定阈值的文件对象在文件系统上的偏移地址上对齐,该偏移地址是设置的对齐大小的倍数。
由于Summit中GPFS的块大小为16 MB,因此我们为大于4 KB的文件对象设置了16 MB的对齐属性。
在HDF5库中,H5Pset_alignment函数用于配置文件访问属性,其核心功能是确保大于特定阈值的文件对象在文件系统中以指定的对齐大小为基准进行偏移地址的对齐。此举旨在减少因数据块跨越文件系统块边界而产生的额外读写操作,从而提升I/O效率。
也就少了一块
每个基准测试运行还使用五个计算和 I/O 阶段的迭代,其中计算阶段通过睡眠函数模拟。我们使用了最多 15 秒的模拟计算阶段。我们改变了这个模拟计算时间,以有效地重叠 I/O 延迟。与每个阶段相关的数据组织在 sarme 文件中的不同 HDF5 组中。
对于异步 I/O 模式,我们使用了“显式”I/O 模式,其中基准测试使用 HDF5 事件集,当使用后台线程执行 I/O 操作时,这为用户提供了更多的控制。人们可以为基准测试套件尝试更多配置组合。
4.1.4 T HDF5性能、可扩展性和异步I/O
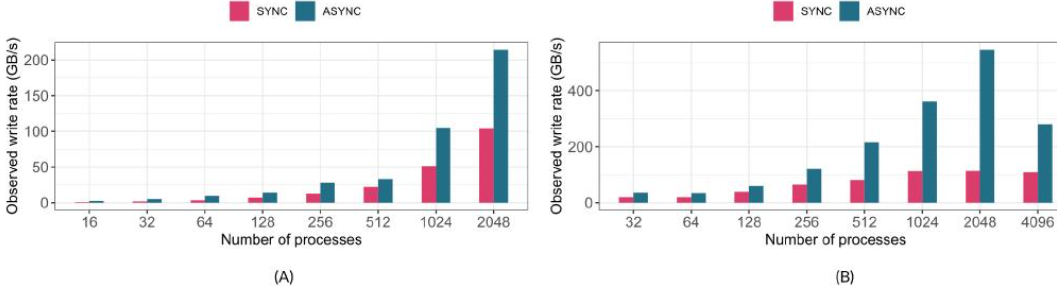
图 4:h5bench 在同步和异步模式下的写入性能,MPI 秩的数量不同。(A) Cori(每个节点 16 个秩),(B) Summit(每个节点 32 个秩)。
在图4A中,我们比较了在Cori上以异步和同步I/O模式写入数据时观察到的I/O速率;在图4B中,比较了在Summit上相同操作的速率。我们使用了内存和文件中的连续模式,其中八个一维数组被写入为八个HDF5数据集。
等待时间:在同步模式下,每个进程发出写入请求后都要等待写入完成,这就会造成大量的时间浪费在等待 I/O 操作完成上。而进程数量越多,这种等待的时间累计起来就越长。比如有 100 个进程依次进行同步写入,第一个进程写入完第二个进程才能开始,那这 100 个进程的总时间就等于每个进程写入时间的总和 。而异步模式下,进程不需要等待,可以马上进行下一个操作,这样多个进程可以同时进行其他任务,充分利用了 CPU 时间,提高了整体效率。
系统资源利用:异步模式能够更好地利用系统资源。存储设备(比如硬盘)的读写速度相对 CPU 的处理速度是比较慢的。同步模式下,CPU 大部分时间都处于空闲等待状态。而异步模式下,CPU 可以在发出写入请求后,去处理其他任务,当存储设备准备好时再进行数据传输,使得 CPU 和存储设备的工作更加并行化,提升了整体性能 。
可以看出,异步I/O模式的观察写入速率明显高于同步I/O模式。这是通过在基准测试的计算阶段(通过应用sleep()函数来模拟计算时间)重叠写入操作来实现的。
随着MPI等级数量的增加,基准测试实现了更高的写入速率。在2K MPI等级的规模下,在Cori上观察到的异步I/O速率为x 220 GB/s,在Summit上约为560 GB/s。我们观察到Summit在4K核心规模下出现了一个异常,I/O速率降至约290 GB/s。
这可能是由于这些作业运行时文件系统中的干扰造成的
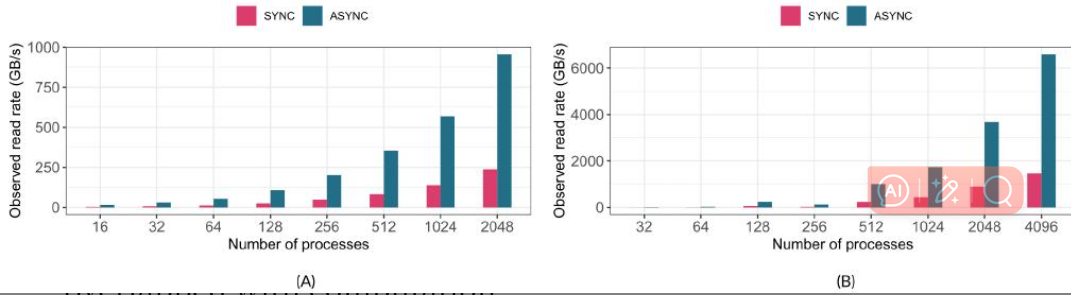
在图 5A.B 中,我们分别比较了在 Cori 和 Summit 上运行的读取基准测试的性能,使用了同步和异步 I/O 模式。我们使用了写入基准测试写入的相同数据,这些数据是来自 HDF5 数据集的连续 1D 数组。
为了避免读取的缓存效应,读取基准测试也在写入基准测试生成文件后的不同日期运行。我们还使用了aScale 详细描述了实验中使用的以 2 的幂为单位的过程范围。
在这些运行中,连续时间步之间有 15 秒的模拟计算时间,以便将读取时间与(模拟的)计算阶段完全重叠。使用异步 I/O,在 2K 核心上,观察到的 I/O 速率在 Cori 上为 1TB/s,在 Summit 上为 700 GB/s。
在 Cori 上,尽管峰值 I/O 带宽为 700GB/s,但观察到的 I/O 速率要高得多,因为计算阶段与基准测试所用的时间重叠。在理想情况下,要写入文件的最后一个时间步的数据没有后续的计算阶段。因此,文件写入阶段与计算不重叠。类似地,读取测试中的第一个读取阶段之前没有计算阶段,因此没有重叠。由于这些非重叠的 I/O 阶段,观察到的 I/O 速率很高。另一个观察结果是,在读取情况下,我们没有看到 Summit 上从 2K 到 4K MPl 等级的性能下降。(说的是右边这张图)
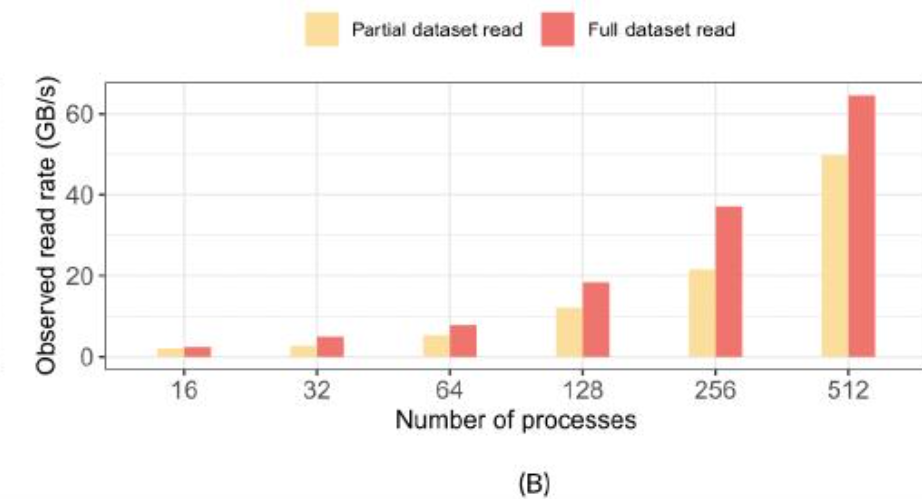
当数据分析应用程序读取数据时,一种常见的做法是读取由h5bench写入基准测试写入的1D数组数据的前10%,并将其与读取整个数据进行比较。在“完整读取”和“部分读取”的情况下,我们都将整个1D数组跨所有MPI等级进行分区。
在“完整读取”情况下,每个MPI等级读取其整个分区。在“部分读取”情况下,每个等级读取其分区的10%。
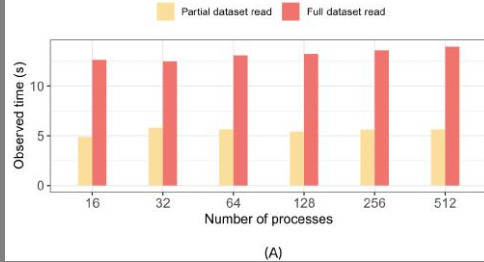
在图 6A 中,我们比较了使用不同数量的 MPI 进程读取部分数据和读取整个数据集时观察到的 I/O 时间。请注意,这是一个弱扩展测试,其中对于图中每组条形(x 轴上从 16 到 512 个进程),一维数组的大小都会增加。这在两种情况下都很常见。
弱扩展是资源变多任务也变多,强扩展是资源变多但是任务数目不变
在“部分读取”的情况下,时间仅在读取数据时减少,而元数据读取时间没有减少。需要进一步分析此时间,分别分析元数据和数据读取时间,以识别任何其他低效率。我们还在图 6B 中比较了这两种情况下的观察到的读取速率,可以理解的是,读取完整数据的速率更高,因为传输的数据量比“部分读取”情况下多 90%。
对比x+y和x+0.1y 可以全都解出来
4.1.5 1带有log VOL连接器的HDF5性能
图7显示了使用log VOL连接器、ADIOS和PnetCDF时E3SM-lO的写入性能。与log VOL连接器类似,ADIOS方法也将数据以日志布局存储在文件中。相反,PnetCDF方法以规范顺序存储数据,这需要进程间通信来交换MPI集体写入操作中的写入请求。
将此PnetCDF方法与另外两种使用日志布局的方法进行直接比较是不公平的,因为PnetCDF库也可以用于以日志布局存储数据。感兴趣的读者可以参考E3SM-lO的GitHub存储库以获取更多性能结果。
然而,我们将PnetCDF的结果添加到同一图表中,所以大于其他两种情况。三种情况下的时间步数(数据检查点)在F情况下为25,在G情况下为1,在清楚地表明在log VOL连接器和ADlOs中使用log布局存储数据优于PnetCDF方法中使用的规范布局的情况下为240pounddatatypes.
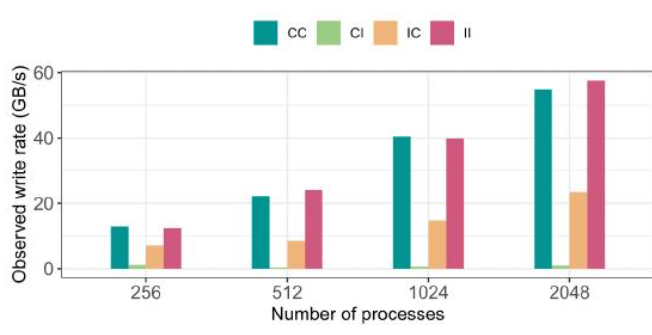
此图表明,当文件中的HDF5数据集的内存布局(CC)和内存中写入为HDF5数据类型(ll)的复合数据类型时,观察到的写入速率更高。由于在映射上没有差异,并且没有将内存缓冲区转换为文件布局的开销,因此在1024个MPl等级的规模下,写入速率高达400 GB/s,在2048个MPl等级的规模下,写入速率超过550 GB/s。
TheE3sM-lObenchmark的配置与高分辨率E3SM模拟的生产运行相匹配。F、G和I显著地影响了我们的实验,我们在使用IBM Spectrum Scale GPFS并行文件系统的wel ndSi节点上进行了实验。
在另外两种情况下,即必须将单个1D数组转换为HDF5复合数据类型(Cl),并将内存中的结构数组转换为单个HDF5数据集(IC),转换开销会影响性能,导致低于写入连续数据。
一个有趣的观察结果是,从单个1D数组(Cl)在文件中形成HDF5复合数据类型布局会导致显著的开销,并且在所有这四种模式中表现最差。通过从结构数组中提取数据来写入单个HDF5 1D数据集,在2048个MPl等级下实现了超过200GB/s的可观写入速率。
4.1.6I在Summit上使用节点本地存储进行缓存的HDF5性能
哦,是burst buffer欸
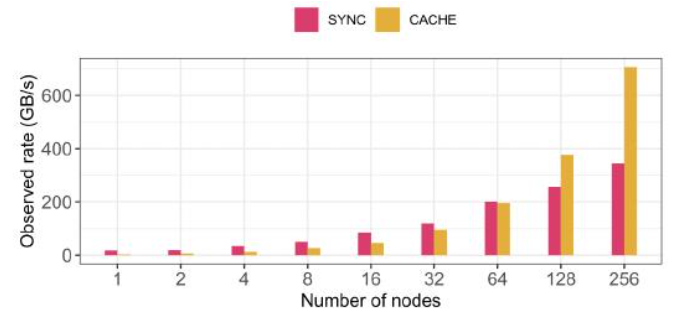
在图8中,我们展示了HDF5与Cache VOL在Summit上对于具有8百万个粒子的1D连续(内存中)连续(文件中)模式的性能。实验在1到256个节点上运行,每个节点16个进程。NVMe SSD用于在Cache VOL中缓存数据。
数据被同步写入NVMe SSD,并异步移动到GPFS并行文件系统。模拟计算时间为100秒。
观察到的缓存卷写入速率随节点数量线性增长,最终超过基准HDF5(SYNC),因为使用了越来越多的NVMe SSD,它们的总写入带宽高于相同规模下GPFS的带宽。
太有道理了,BB的带宽越来越大
4.1.7I Cori中局部性的影响
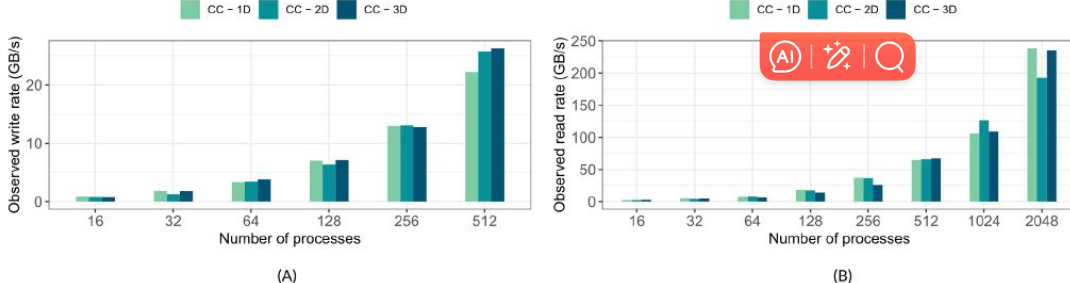
图 10 h5bench 在 Cori 共享 Lustre 文件系统上,针对不同 MPI 进程数,观测到的不同维度数组(1D、2D 和 3D)的写入和读取速率。(a) 写入,(b) 读取。
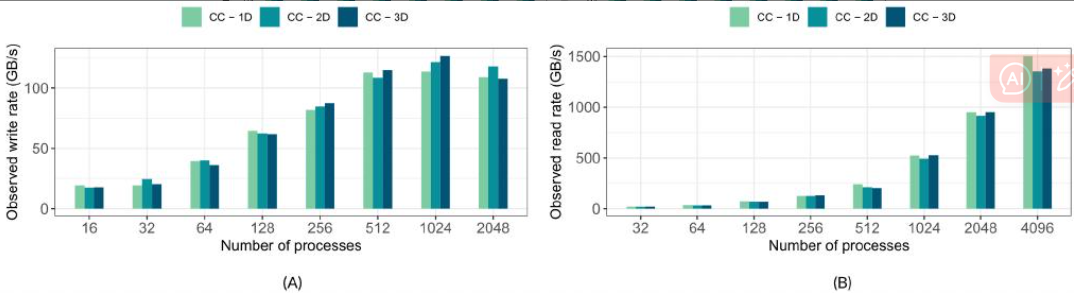
图 111 h5bench 在 Summit 上使用不同数量的 MPI 秩写入到共享 GPFS 文件系统时,观察到的不同维度数组(一维、二维和三维)的写入和读取速率。(A) 写入,(B) 读取。
Cori和Summit中阵列维度的影响
在图10和图11中,我们分别展示了在Cori和Summit上写入不同数组维度数据时的性能。在图10A.B中,我们描述了不同数组维度数据的观测速率,表明以不同维度写入或读取相同数量的数据获得了相对相似的性能。早期的研究表明,3D分解实现了较差的I/O性能,3 然而,除了通常的性能差异外,我们观察到不同维度下的写入和读取性能相似。
看来差不多
我们进一步研究了参考文献35 *中使用的代码,我们确认NetCDF4中初始化填充值的开销是导致性能不佳的真正原因,而不是实际的l/O延迟37。在Surmmit上,如图11A所示。
11A,我们观察到写入速率在4K核心的规模上有所下降,这需要进一步调查。
Lustre过载,性能开始下降,我也有点好奇
4.3 3 | Subfiling在Summit上的影响
第一个子文件研究(第2.3节)是在Summit上使用h5bench进行的,针对数组I/O模式的1D和3D维度。不同数组秩情况下的总文件大小相同,并随秩的数量而缩放(表4)。对于内存中和文件中的情况,数据集都是连续的。
啊就是那个这种算法,搞了个文件局部锁,然后merge起来。
使用了每个节点一个子文件的默认子文件VFD参数,并将其与通过五个运行对单个共享文件(SSF)的集体和独立I/O进行了比较,如图12所示。
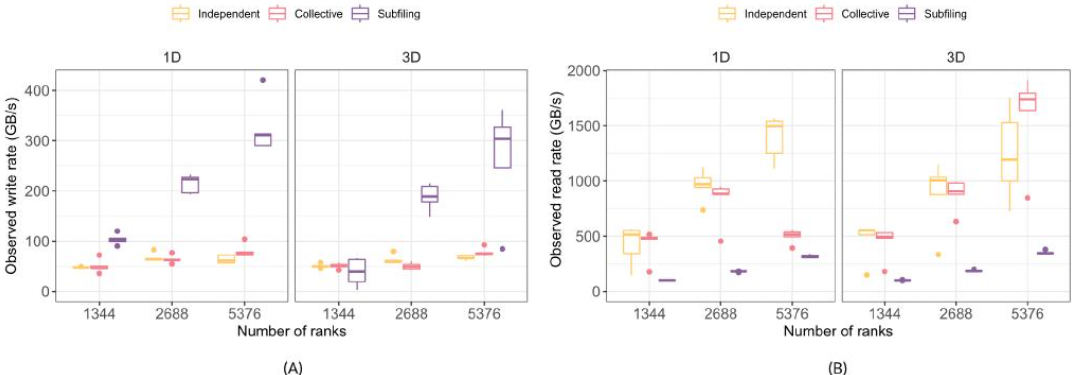
图12:h5bench在Summit的GPFS文件系统上,使用集体和独立I/O,以及每个节点一个子文件,针对单个共享分层数据格式版本5所观察到的写入和读取速率,具有不同的MPI秩。(A)写入,(B)读取。
写的好,读的差
对于写入,随着等级数量的增加,子文件提高了两种数组维度模式的速率,而SSF的速率保持相对恒定。子文件读取的性能不如SSF,并且仍然是改进其性能方法的开放性研究。第二个实验研究了每个节点使用多个子文件的影响,如图13所示。
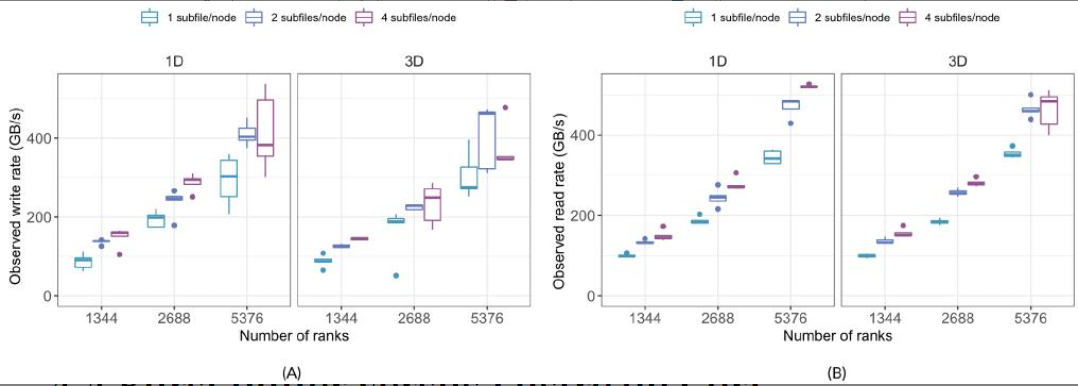
图13:在Summit上,使用不同数量的MPI,hsbench观察到的每个节点上不同子文件对GPFS的写入和读取速率
没啥大区区别,2好一点
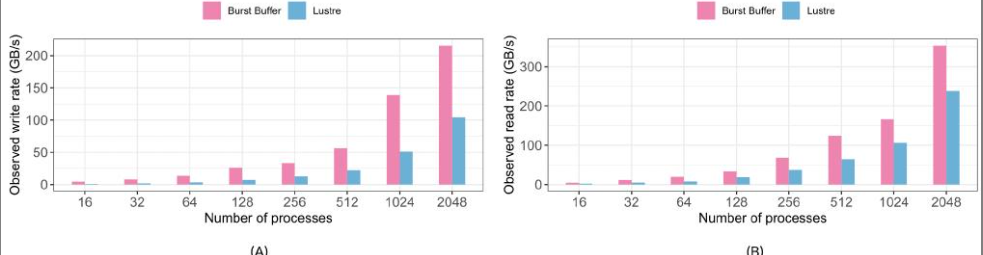
4.4 Cori上Burst buffer与Lustre的比较
在图 14A.B 中,我们比较了将数据写入 Lustre 文件系统和 Cori 上的 DataWarp Burst Buffer 的写入和读取性能。在这些测试中,我们配置了基准测试,以将一维数组写入文件中的各个 HDF5 数据集。
正如预期的那样,我们观察到使用 Burst Buffer 的 I/O 速率高于 Lustre。然而,当考虑超过 64 MPl ranks 的性能时,Burst Buffer 的写入性能平均比 Lustre 快 2.45 倍。Burst Buffer 的读取性能比 Lustre 快 1.7 倍。
4.5 I HDF5在permutter (NERSC)中的性能
开始看更大的新平台了
Perlmutteri 是部署在 NERSC 的一个异构系统,基于 HPE Cray Shasta 平台,包含纯 CPU 节点和 GPU 加速节点。该系统分两个阶段构建:第一阶段,包含 12 个 GPU 加速机柜,容纳超过 1500 个节点和 35PB 的全闪存存储,于 2021 年初交付;第二阶段,包含 12 个 CPU 机柜,目前正在组装。
Perlmutter 的纯 CPU 节点每个节点有两个 AMD EPYC 7763 (Milan) 处理器插槽,每个插槽 64 个内核,每个代码两个线程。每个节点有 512 GiB 的可用内存。每个节点一个 Cassini NIC,通过 PCle 4.0 和 Slingshot 11 互连结构连接。
Perlmutter 拥有一个全闪存 Lustre 文件系统,专为大型文件的高性能存储而设计。它具有 35 PB 的磁盘空间,超过 5 TB/s 的聚合带宽,以及 400 万 IOPS(4 KiB 随机)。其 Lustre 部署具有 16 个 MDS(元数据服务器)、274 个称为 OSS 的 I/O 服务器和 3792 个双端口 NVMe SSD。
默认情况下,Perlmutter 上的所有文件都以 1 MB 的条带大小跨单个 OST 进行条带化。在Perlmutter中,h5bench使用PrgEnv-gnu/8.3.3、cray-mpich/8.1.22、gcc/11.2.0系统模块和HDF5 1.13.2编译。我们在Perlmutter中运行了基准h5bench访问模式,使用集体数据和元数据调用,每个时间步模拟计算时间为10秒,总共五个时间步。
表5总结了我们在实验中使用的基准模式。我们将Lustre设置为将共享文件条带化为1 MB的条带,分布在256个OST上。实验采用弱扩展方法进行,使用1024、2048和4096个rank,每个节点64个rank。
