python调研本地 DeepSeek API的例子
Python 示例代码
以下是一段调用本地 DeepSeek API 的 Python 示例代码,假设你的本地 DeepSeek 服务运行在 http://localhost:8000(请根据实际服务的端口调整),并包含基础的错误处理和参数配置:
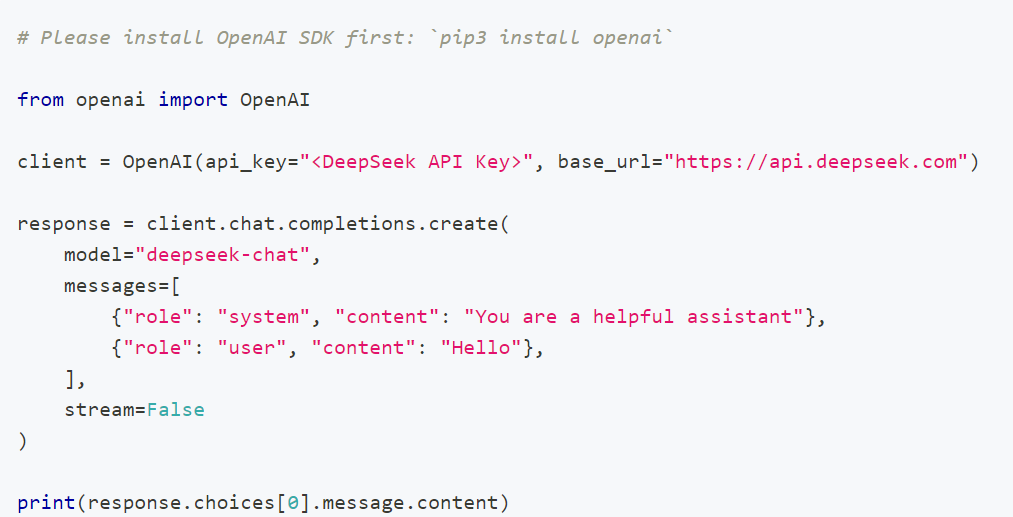
import requestsdef call_deepseek_api(prompt, api_key=None, max_tokens=512, temperature=0.7):"""调用本地 DeepSeek API 生成文本参数:prompt (str): 输入的提示词api_key (str): 可选,若本地服务需要 API Key 认证则填写max_tokens (int): 生成文本的最大长度(默认 512)temperature (float): 控制生成随机性的参数(0~1,越小越确定,默认 0.7)返回:str: 生成的文本内容(成功时)或错误信息(失败时)"""# 本地 API 地址(根据实际服务端口修改,常见如 8000/8080/5000)api_url = "http://localhost:8000/v1/chat/completions" # 假设接口路径为 /v1/chat/completions# 请求头(根据实际服务要求调整,可能需要添加 Authorization 或 Content-Type)headers = {"Content-Type": "application/json",}if api_key:headers["Authorization"] = f"Bearer {api_key}" # 若服务需要 Bearer Token 认证# 构造请求体(根据 DeepSeek API 文档调整参数,以下为通用示例)payload = {"model": "deepseek-chat", # 模型名称(根据本地部署的模型调整)"messages": [{"role": "user", "content": prompt} # 用户输入的提示],"max_tokens": max_tokens,"temperature": temperature,"stream": False # 是否流式输出(False 为一次性返回完整结果)}try:# 发送 POST 请求response = requests.post(api_url, json=payload, headers=headers, timeout=30)response.raise_for_status() # 若 HTTP 状态码非 200 则抛出异常# 解析响应(根据实际接口返回结构调整,以下为通用示例)result = response.json()# 假设返回结构包含 "choices" 列表,每个元素有 "message" 字段generated_text = result["choices"][0]["message"]["content"]return generated_textexcept requests.exceptions.RequestException as e:# 处理网络相关错误(连接失败、超时等)return f"请求失败: {str(e)}"except (KeyError, IndexError) as e:# 处理响应解析错误(如接口返回结构不符)return f"解析响应失败,可能接口返回格式变化: {str(e)}"except Exception as e:# 其他未知错误return f"未知错误: {str(e)}"# -------------------------- 示例用法 --------------------------
if __name__ == "__main__":# 你的输入提示user_prompt = "请用 Python 写一个计算斐波那契数列前 n 项的函数,并给出示例。"# 调用 API(若本地服务需要 API Key,替换为你的 key;否则留 None)output = call_deepseek_api(prompt=user_prompt,api_key=None, # 例如:"your-api-key-here"(如果需要)max_tokens=1024, # 根据需求调整生成长度temperature=0.5 # 调整生成随机性(0 更确定,1 更随机))# 打印结果print("生成的回复:")print(output)
使用说明:
-
安装依赖:需要先安装
requests库,若未安装可通过pip install requests安装。 -
调整参数:
api_url:根据本地 DeepSeek 服务的实际地址修改(例如若服务运行在8080端口,则改为http://localhost:8080/...)。model:根据本地部署的模型名称调整(例如可能是deepseek-7b-chat或其他)。headers:若本地服务需要认证(如 API Key),需按服务要求添加(例如Authorization: Bearer <key>)。payload:根据 DeepSeek API 文档调整请求体结构(例如部分服务可能需要prompt直接作为参数,而非messages列表)。
-
验证服务是否启动:确保本地 DeepSeek 服务已正确启动(例如通过
curl http://localhost:8000测试是否能返回有效响应)。
常见问题排查:
- 连接失败:检查服务是否启动、端口是否正确(可通过
netstat -tlnp查看端口占用)。 - 401 Unauthorized:可能是 API Key 错误或未正确配置认证。
- 400 Bad Request:可能是请求体参数格式错误(需对照 API 文档检查)。
- 500 Internal Error:可能是服务端内部错误(查看服务日志排查)。
如果你的本地 DeepSeek 服务是自定义接口(非通用 OpenAI 格式),请根据实际接口文档调整 api_url、headers 和 payload 的结构。
如何在本地部署 DeepSeek?
本地部署 DeepSeek 主要指部署其开源大模型(如 DeepSeek Chat 系列),支持通过 Hugging Face Transformers、vLLM 或 Docker 等方式实现。以下是详细步骤(以最常用的 DeepSeek Chat-7B 模型为例):
一、环境准备
1. 硬件要求(关键!)
- CPU:至少 8 核(推荐 16 核+)。
- 内存:至少 16GB(7B 模型建议 32GB+,13B 模型建议 64GB+)。
- GPU(可选但强推):
- NVIDIA 显卡(支持 CUDA),显存要求:
- 7B 模型(FP16):至少 14GB(推荐 24GB+,如 RTX 3090/4090)。
- 13B 模型(FP16):至少 28GB(推荐 A100 40GB/80GB)。
- 无 GPU 时可使用 CPU 推理(极慢,仅适合测试)。
- NVIDIA 显卡(支持 CUDA),显存要求:
2. 软件环境
- 操作系统:Linux(推荐 Ubuntu 20.04+)、macOS(Intel 芯片或 M1+)或 Windows(WSL2 更佳)。
- Python:3.8 ~ 3.11(推荐 3.10)。
- PyTorch:与 CUDA 版本匹配(GPU 用户需安装 CUDA 版,CPU 用户安装 CPU 版)。
- 依赖库:
transformers、accelerate、sentencepiece(部分模型需要)、vllm(可选,高效推理)。

二、部署方式 1:使用 Hugging Face Transformers(适合开发测试)
此方式直接通过开源库加载模型,适合小规模测试或自定义微调。
步骤 1:安装依赖
# 创建虚拟环境(推荐)
python -m venv deepseek-env
source deepseek-env/bin/activate # Linux/macOS
# deepseek-env\Scripts\activate # Windows# 安装核心库(GPU 用户需先装 PyTorch,参考 https://pytorch.org/)
pip install torch transformers accelerate sentencepiece
步骤 2:下载模型
DeepSeek Chat 模型开源在 Hugging Face Hub,可直接通过 transformers 加载(首次加载会自动下载,需耐心等待)。
from transformers import AutoTokenizer, AutoModelForCausalLM# 模型名称(Hugging Face Hub 地址)
model_name = "deepseek-ai/deepseek-chat"# 加载分词器和模型(GPU 用户添加 device_map="auto" 自动分配 GPU)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,device_map="auto", # GPU 自动分配(需安装 accelerate)torch_dtype=torch.float16 # FP16 量化(减少显存占用,仅 GPU 可用)
)
步骤 3:编写推理代码
def generate_response(prompt, max_tokens=512, temperature=0.7):# 构造输入(按模型要求的格式,添加 bos_token 等特殊标记)inputs = tokenizer(f"用户:{prompt}
助手:",return_tensors="pt",truncation=True,max_length=2048).to(model.device) # 输入移至 GPU(若有)# 生成文本outputs = model.generate(**inputs,max_new_tokens=max_tokens,temperature=temperature,do_sample=True, # 启用随机采样(更自然)eos_token_id=tokenizer.eos_token_id,pad_token_id=tokenizer.eos_token_id # 避免 padding 错误)# 解码输出(去除输入部分的提示)response = tokenizer.decode(outputs[0], skip_special_tokens=True)return response.split("助手:")[-1].strip() # 提取助手回复# 测试
prompt = "请用 Python 写一个快速排序函数,并解释其原理。"
response = generate_response(prompt, max_tokens=200, temperature=0.5)
print("助手回复:", response)

三、部署方式 2:使用 vLLM(适合高性能服务,推荐生产环境)
https://vllm.ai/ 是 UC Berkeley 开发的高效大模型推理引擎,支持高并发、低延迟,适合部署为 API 服务。
步骤 1:安装 vLLM
# GPU 用户(推荐 CUDA 11.8 或更高)
pip install vllm --pre --extra-index-url https://download.pytorch.org/whl/cu118# CPU 用户(仅测试用,性能差)
pip install vllm --pre --extra-index-url https://download.pytorch.org/whl/cpu
步骤 2:启动 vLLM 服务
通过命令行启动一个 HTTP 服务,暴露模型推理接口(支持多并发):
python -m vllm.entrypoints.api_server \--model deepseek-ai/deepseek-chat \--host 0.0.0.0 \ # 允许外部访问(本地测试用 127.0.0.1)--port 8000 \ # 服务端口(可自定义)--max-model-len 2048 \ # 最大输入长度(根据需求调整)--tensor-parallel-size 1 # 单卡用户保持 1(多卡用户调整为显卡数)
步骤 3:测试服务(用 curl 或 Python)
服务启动后,可通过 HTTP 请求调用:
# curl 测试
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "deepseek-ai/deepseek-chat","messages": [{"role": "user", "content": "请介绍一下你自己"}],"max_tokens": 200,"temperature": 0.7}'
Python 调用示例(同前问题中的代码)
只需将 api_url 改为 http://localhost:8000/v1/chat/completions,即可复用之前的 API 调用代码。

四、部署方式 3:使用 Docker(简化环境配置)
若不想手动配置环境,可通过 Docker 快速部署(需先安装 https://www.docker.com/)。
步骤 1:拉取 vLLM 官方镜像(推荐)
docker pull vllm/vllm:latest # 最新稳定版(需确认支持 DeepSeek 模型)
步骤 2:启动容器
docker run -d --gpus all \ # GPU 用户添加 --gpus all(需 NVIDIA Container Toolkit)-p 8000:8000 \-v /path/to/models:/models \ # 可选:挂载本地模型目录(若已提前下载)--name deepseek-server \vllm/vllm:latest \--model deepseek-ai/deepseek-chat \--host 0.0.0.0 \--port 8000
说明:
- 若模型未提前下载,容器会自动从 Hugging Face Hub 下载(需确保容器能访问互联网)。
- 本地已有模型时,可通过
-v挂载到/models/deepseek-chat,避免重复下载。

五、常见问题排查
-
模型下载慢:
- 使用国内镜像源(如 Hugging Face 镜像站):
# 在 transformers 中设置镜像源 from transformers import set_hf_hub_cache set_hf_hub_cache("/path/to/local/cache") # 本地缓存路径# 或通过环境变量指定镜像(需提前配置) # export HF_ENDPOINT=https://hf-mirror.com
- 使用国内镜像源(如 Hugging Face 镜像站):
-
显存不足:
- 尝试量化(如
load_in_8bit=True或load_in_4bit=True,仅 GPU 支持):model = AutoModelForCausalLM.from_pretrained(model_name,load_in_4bit=True, # 4bit 量化(大幅降低显存,可能损失精度)bnb_4bit_compute_dtype=torch.float16,device_map="auto" ) - 减少
max_new_tokens(生成长度)。
- 尝试量化(如
-
vLLM 启动失败:
- 检查 CUDA 版本(vLLM 要求 CUDA 11.7+):
nvcc --version # 查看 CUDA 版本 - 确保
vllm版本与模型兼容(最新版通常支持最新模型)。
- 检查 CUDA 版本(vLLM 要求 CUDA 11.7+):
总结
- 开发测试:推荐
Transformers方式,灵活易调试。 - 生产服务:推荐
vLLM+ Docker,高性能且易部署。 - 硬件限制:无 GPU 时可用 CPU 推理(仅测试),但需接受极慢速度。
根据需求选择合适的部署方式,若需更高性能(如多卡、高并发),可进一步调整 vLLM 的 tensor-parallel-size 或使用 Text Generation WebUI 等图形化工具(如 https://github.com/oobabooga/text-generation-webui)。