Langchain入门:文本摘要
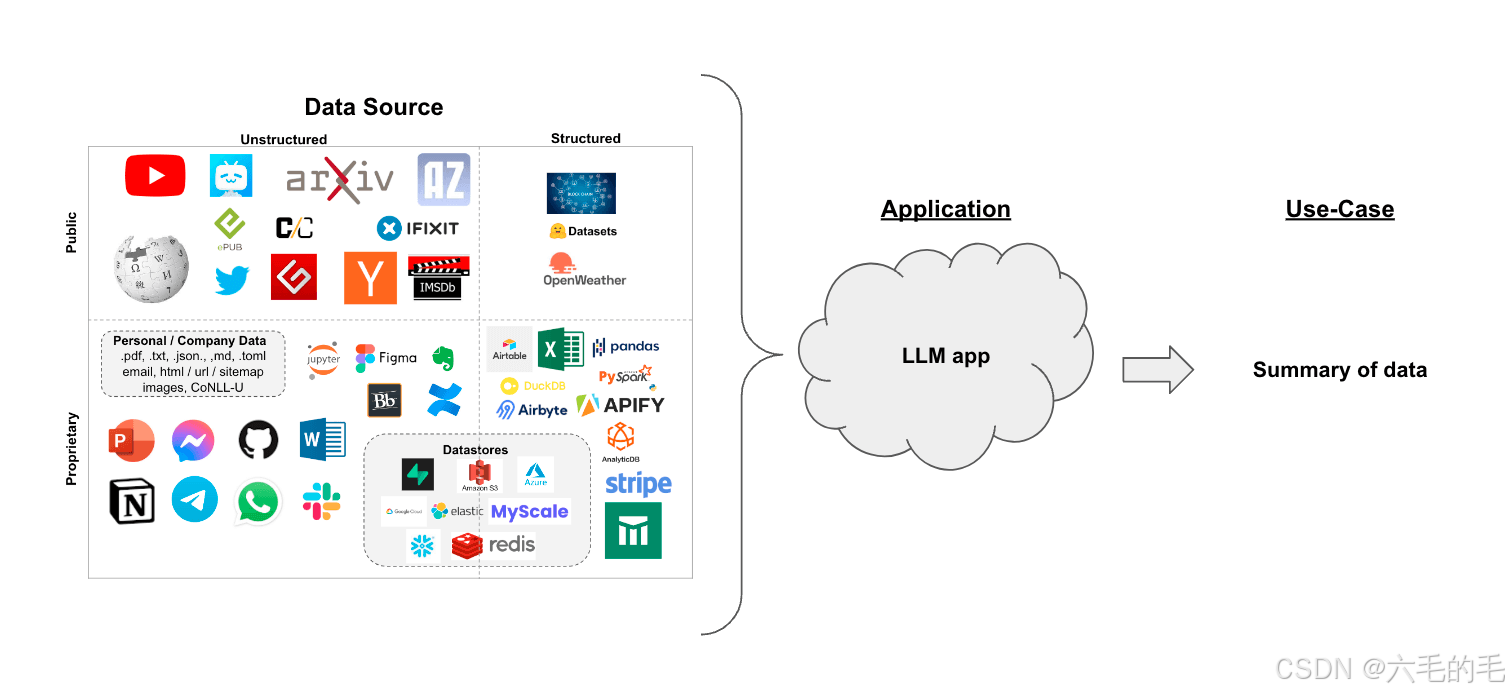
假设您有一组文档(PDF、Notion 页面、客户问题等),您想要总结内容。
大型语言模型(LLMs)在理解和综合文本方面非常出色,因此是一个很好的工具。
在 检索增强生成 的背景下,文本摘要可以帮助提炼大量检索文档中的信息,以为 LLM 提供上下文。
在本教程中,我们将介绍如何使用 LLM 从多个文档中总结内容。
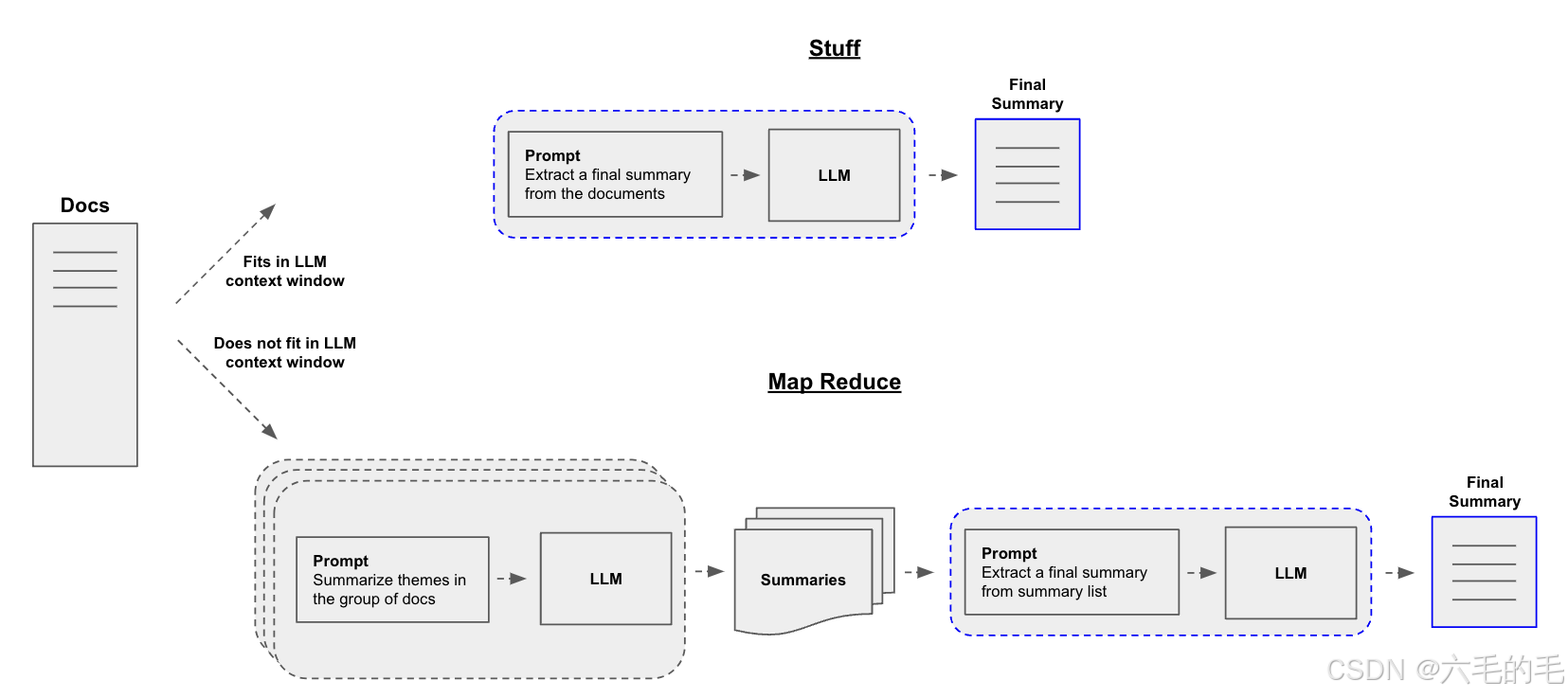
构建摘要生成器的一个核心问题是如何将您的文档传递到大型语言模型的上下文窗口中。常见的两种方法是:
-
Stuff:简单地将所有文档“填充”到一个提示中。这是最简单的方法
-
Map-reduce:在“映射”步骤中单独总结每个文档,然后将摘要“归约”成最终摘要。
请注意,当对子文档的理解不依赖于前面的上下文时,map-reduce 特别有效。例如,在总结许多较短文档的语料库时。在其他情况下,例如总结具有固有顺序的小说或文本,迭代细化 可能更有效。
首先我们加载文档。我们将使用 WebBaseLoader 来加载一篇博客文章:
from langchain.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
内容:在单个大型语言模型调用中总结
我们可以使用 create_stuff_documents_chain,特别是如果使用更大的上下文窗口模型,例如:
- 128k 令牌的 OpenAI gpt-4o
- 200k 令牌的 Anthropic claude-3-5-sonnet-20240620
该链将接受文档列表,将它们全部插入提示中,并将该提示传递给大型语言模型:
from langchain_openai import ChatOpenAIllm = ChatOpenAI(openai_api_base = "https://api.siliconflow.cn/v1/",openai_api_key = os.environ['siliconFlow'],model_name = "Qwen/Qwen3-8B", # 模型名称
)
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_messages([("system", "Write a concise summary of the following:\\n\\n{context}")]
)chain = create_stuff_documents_chain(llm, prompt)result = chain.invoke({"context": docs})
print(result)

请注意,我们还可以逐个令牌地流式传输结果:
for token in chain.stream({"context": docs}):print(token, end="|")
Map-Reduce: 通过并行化总结长文本
让我们来解析一下map-reduce方法。为此,我们将首先使用大型语言模型(LLM)将每个文档映射到一个单独的摘要。然后,我们将这些摘要减少或合并为一个单一的全局摘要。
请注意,map步骤通常是在输入文档上并行化的。
LangGraph,基于langchain-core构建,支持map-reduce工作流,非常适合这个问题:
- LangGraph允许单个步骤(例如连续摘要)进行流式处理,从而提供更大的执行控制;
- LangGraph的检查点支持错误恢复,扩展人机协作工作流,并更容易融入对话应用程序。
- LangGraph的实现易于修改和扩展,正如我们下面将看到的。
让我们首先定义与map步骤相关的提示,并通过链将其与LLM关联。我们可以使用与上面stuff方法相同的摘要提示:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplatemap_prompt = ChatPromptTemplate.from_messages([("system", "Write a concise summary of the following:\\n\\n{context}")]
)
map_chain = map_prompt | llm | StrOutputParser()
我们还定义了一个链,它将文档映射结果减少为单个输出。
reduce_template = """
The following is a set of summaries:
{docs}
Take these and distill it into a final, consolidated summary
of the main themes.
"""reduce_prompt = ChatPromptTemplate([("human", reduce_template)])
reduce_chain = reduce_prompt | llm | StrOutputParser()
通过 LangGraph 进行 orchestration
下面我们实现一个简单的应用程序,它在文档列表上映射摘要步骤,然后使用上述提示进行减少。
当文本相对于大型语言模型的上下文窗口较长时,Map-reduce 流特别有用。对于长文本,我们需要一种机制,以确保在减少步骤中要总结的上下文不超过模型的上下文窗口大小。在这里,我们实现了摘要的递归“折叠”:输入根据令牌限制进行分区,并生成分区的摘要。此步骤重复进行,直到摘要的总长度在所需限制内,从而允许对任意长度文本进行摘要。
首先,我们将博客文章分块为较小的“子文档”以进行映射:
from langchain_text_splitters import CharacterTextSplitter# from_tiktoken_encoder基于字符数分割
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000,chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
print(f"Generated {len(split_docs)} documents.")

接下来,我们定义我们的图。请注意,我们定义了一个人为较低的最大令牌长度为 1,000 个令牌,以说明“折叠”步骤。
TypedDict 是 Python 中用于为字典提供类型注解的工具,可以定义字典中每个键的类型,提供类型安全和IDE支持。
Send 用于创建动态的子任务:Send(节点名称, 传递给节点的状态)
collapse_docs 是 collapse_docs 的异步版本。 功能:将多个文档合并为一个文档
StateGraph 是 LangGraph 框架中的核心类,用于构建有状态的图形工作流。它允许你创建复杂的、多步骤的、可分支的处理流程
LangGraph 的核心原理:
- 每个节点函数返回一个字典
- 这个字典的键值对会自动合并到全局状态中
- 合并时会根据类型注解决定合并策略
import operator
from typing import Annotated, List, Literal, TypedDictfrom langchain.chains.combine_documents.reduce import (acollapse_docs,split_list_of_docs
)
from langchain_core.documents import Document
from langgraph.constants import Send
from langgraph.graph import END, START, StateGraphtoken_max = 1000def length_function(documents: List[Document]) -> int:# get_num_tokens函数计算文档的token数量return sum(llm.get_num_tokens(doc.page_content) for doc in documents)class OverallState(TypedDict):contents: List[str]summaries: Annotated[list, operator.add] # 定义一个会自动累积(追加)的列表类型collapsed_summaries: List[Document]final_summary: strclass SummaryState(TypedDict):content: strasync def generate_summary(state: SummaryState):response = await map_chain.ainvoke(state["content"]) # ainvoke可以异步执行return {"summaries": [response]}def map_summaries(state: OverallState):return [Send("generate_summary", {"content": content}) for content in state["contents"]]def collect_summaries(state: OverallState):return {"collapsed_summaries": [Document(summary) for summary in state["summaries"]]}async def collapse_summaries(state: OverallState):# split_list_of_docs# - docs: 文档列表# - length_function: 计算文档长度的函数 # - token_max: 每组的最大 token 限制doc_lists = split_list_of_docs(state["collapsed_summaries"], length_function, token_max)results = []for doc_list in doc_lists:results.append(await acollapse_docs(doc_list, reduce_chain.ainvoke))return {"collapsed_summaries": results}def should_collapse(state: OverallState,
) -> Literal["collapse_summaries", "generate_final_summary"]:num_tokens = length_function(state["collapsed_summaries"])if num_tokens > token_max:return "collapse_summaries"else:return "generate_final_summary"async def generate_final_summary(state: OverallState):response = await reduce_chain.ainvoke(state["collapsed_summaries"])return {"final_summary": response}graph = StateGraph(OverallState)
# Nodes:
graph.add_node("generate_summary", generate_summary)
graph.add_node("collect_summaries", collect_summaries)
graph.add_node("collapse_summaries", collapse_summaries)
graph.add_node("generate_final_summary", generate_final_summary)# Edges:
graph.add_conditional_edges(START, map_summaries, ["generate_summary"])
graph.add_edge("generate_summary", "collect_summaries")
graph.add_conditional_edges("collect_summaries", should_collapse)
graph.add_conditional_edges("collapse_summaries", should_collapse)
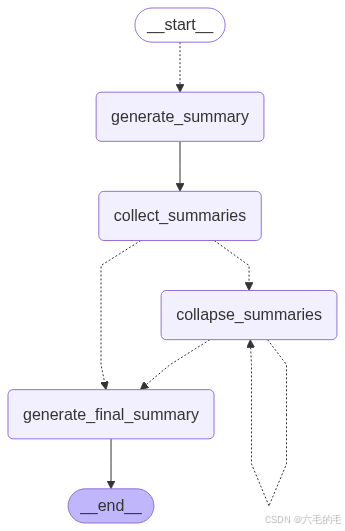
graph.add_edge("generate_final_summary", END)app = graph.compile()LangGraph 允许绘制图结构,以帮助可视化其功能:
from IPython.display import ImageImage(app.get_graph().draw_mermaid_png())
在运行应用程序时,我们可以流式传输图形以观察其步骤序列。下面,我们将简单地打印出步骤的名称。
请注意,由于图中存在循环,指定执行时的 recursion_limit 可能会很有帮助。当超过指定限制时,这将引发特定错误。
async for step in app.astream({"contents": [doc.page_content for doc in split_docs]},{"recursion_limit": 10},
):print(list(step.keys()))
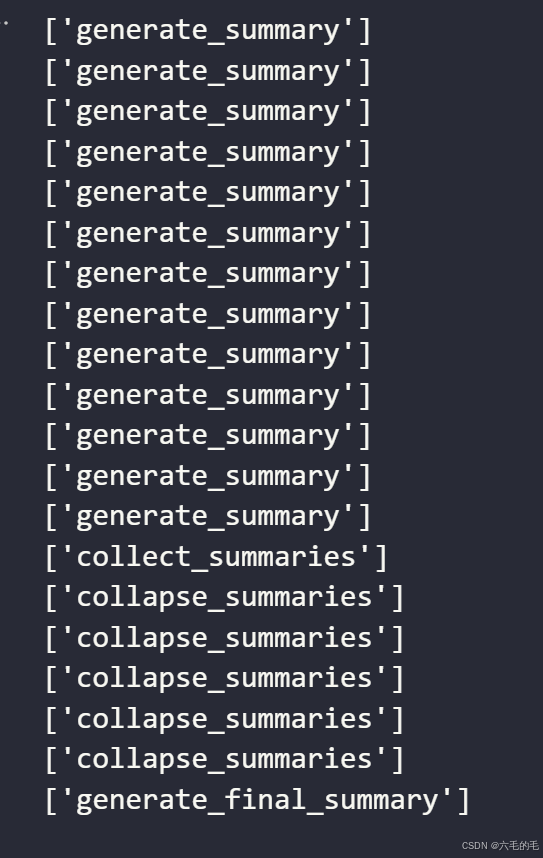
print(step)