从原理到实践:一文掌握Kafka的消息生产与消费
什么是kafka
一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
kafka中基本术语
消息:kafka中的数据单元,也称为记录
批次:为了提高效率,消息分批次被消费,这一组消息就叫批次
主题:消息的种类叫主题,一个主题代表了一类消息
分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序。
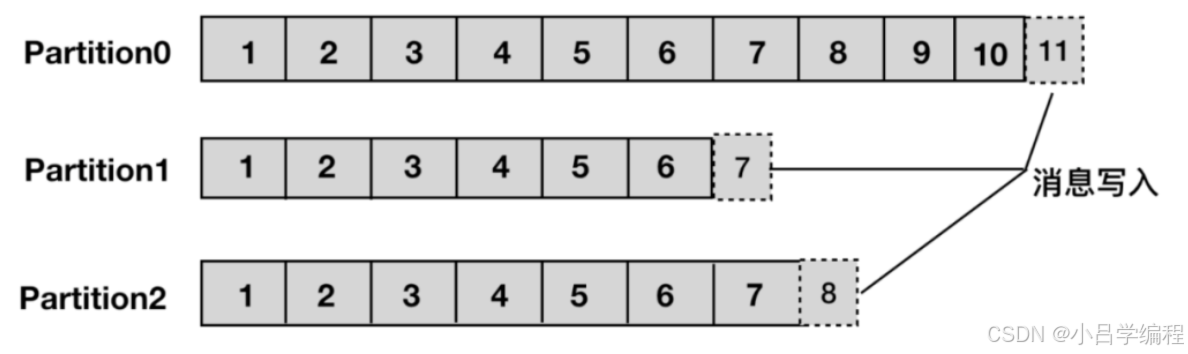
生产者:生产者用于持续不断的向某个主题发送消息
消费者:消费者用于处理生产者产生的消息
消费者群组:生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体
偏移量:它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据
Kafka Broker:在 Kafka 中,Broker(代理)是 Kafka 集群的基础工作单元,负责消息的存储、传输和处理。简单来说,Broker 就是运行 Kafka 服务的服务器节点。
Kafka 的特性
- 高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
- 高伸缩性:每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
- 持久性、可靠性:Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 的数据能够持久存储。
- 容错性:允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
- 高并发:支持数千个客户端同时读写
kafka常用参数配置
Produce关键配置
bootstrap.servers
Kafka集群地址(逗号分隔)
acks
acks是kafka生产者中最核心的可靠性配置,配置决定了生产者认为消息是否"成功写入",该配置有三种级别,分别是0、1(默认)、all
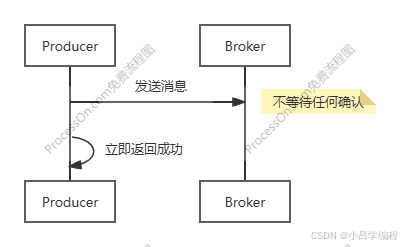
acks=0 无确认
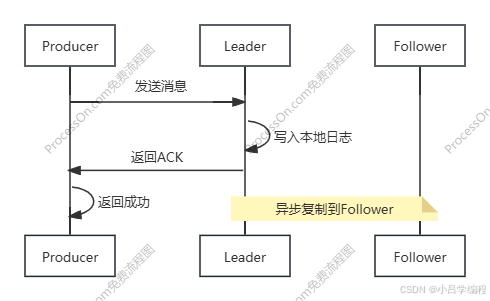
acks=1 Leader确认
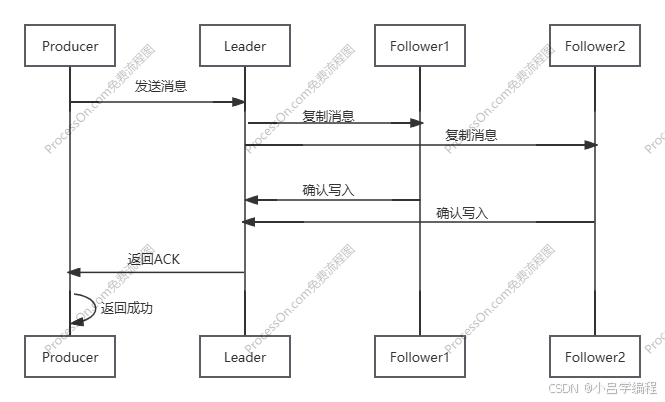
acks=all 全副本确认
| 配置值 | 可靠性 | 延迟 | 吞吐量 | 适用场景 | 数据丢失风险 |
|---|---|---|---|---|---|
acks=0 | 最低 | 最低 | 最高 | 监控日志、实时指标 | 极高:发送即视为成功 |
acks=1 | 中等 | 低 | 高 | 普通日志、非关键数据 | 中等:Leader 写入后崩溃可能丢失 |
acks=all | 最高 | 高 | 中等 | 金融交易、订单数据 | 极低:需配合 min.insync.replicas |
key.serializer、value.serializer
键序列化、值序列化类
interceptor.classes
允许为 Kafka 生产者或消费者插入自定义逻辑,在消息发送/消费的关键节点进行拦截处理
Consumer 关键配置
bootstrap.servers
Kafka集群地址
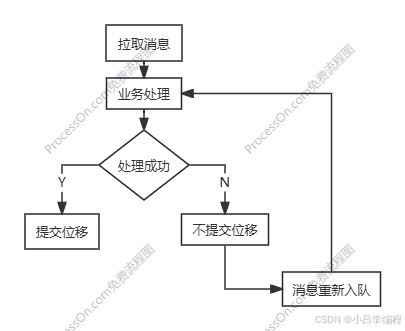
enable.auto.commit
消息的自动和手动提交,取决于该配置的设置
自动提交:
- 开发者无需关心位移管理逻辑
- 减少代码复杂度和出错可能
- 批量提交减少网络请求次数
- 无提交等待时间,连续消费不间断
手动提交:
- 确保业务操作与位移提交的原子性
- 避免"部分成功"导致的数据不一致
- 支持事务性操作
- 异常恢复能力
| 维度 | 自动提交 | 手动提交 |
|---|---|---|
| 开发复杂度 | 极简 | 复杂 |
| 吞吐量 | 最高 | 中等 |
| 可靠性 | 可能丢失 | 精确一次 |
| 资源消耗 | 较低 | 较高 |
| 适用场景 | 通知/日志 | 交易/订单 |
🌐 生活场景类比:报纸配送系统
自动提交模式:
送报员每天将报纸投入信箱即视为送达(自动提交),不等待住户确认。
优势:高效率覆盖整个社区,每天能送1000户。
风险:可能有人没收到报纸(消息丢失)。
手动提交模式:
快递员必须当面签收包裹(手动确认)。
优势:确保每个包裹送达(消息可靠)。
代价:每天只能送100户,效率低下。
key.serializer、value.serializer
键序列化、值序列化类
保持消费者活跃关键配置
| 参数 | 作用域 | 默认值 | 介绍 | 风险 |
|---|---|---|---|---|
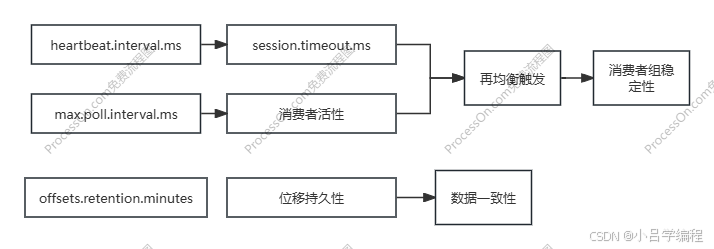
| session.timeout.ms | 消费者 | 45秒 | 消费者需要定期发送心跳给协调器证明自己存活,如果超时消费者被标记为死亡,触发再均衡分区重新分配给其他消费者 | 误判死亡 |
| heartbeat.interval.ms | 消费者 | 3秒 | 控制消费者发送心跳的频率 | 心跳风暴 |
| max.poll.interval.ms | 消费者 | 5分钟 | 控制两次poll()调用之间的最大允许间隔,也就是控制业务处理时长,如果处理时长超时,直接踢出消费组 | 被意外踢出 |
| offsets.retention.minutes | Broker | 7天 | 当消费者停止工作后,生产者依旧在生产数据,位移数据依旧在增多,但是到了位移保留时长后,位移数据将会被删除 | 位移丢失 |
| auto.offset.reset | 消费者 | latest | 当没有初始offset或offset已被删除时,消费者如何处理。可选值:latest(从最新消息开始),earliest(从头开始),none(报错) | 数据丢失或重复消费 |

位移数据删除后处理:
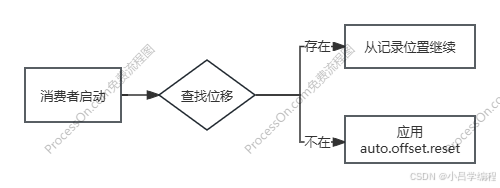
| 策略 | 消费起始位置 | 是否"归零" | 数据影响 | 风险 |
|---|---|---|---|---|
latest | 分区最新位移 (如12500) | 否 | 跳过11000-12500的所有订单 | 消息丢失 |
earliest | 分区当前起始位移 (如0或5000) | 是物理归零 | 重放所有可用历史订单 | 重复消费 |
none | 不启动 | N/A | 服务中断 | 抛异常 |
总结:
kafka发送消息
//示例:
private final KafkaTemplate<String, String> kafkaTemplate;
//参数很多可参考官网文档
kafkaTemplate.send(topic, message);方法参数详解
1. 基本发送:指定主题和消息内容
ListenableFuture<SendResult<K, V>> send(String topic, V data);参数:
topic:消息发送到的 Kafka 主题名称。data:消息内容(Value)。
kafkaTemplate.send("user-events", "{\"userId\": 1001, \"action\": \"login\"}");2. 指定分区:发送到特定分区
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, V data);参数:
partition:目标分区的编号(从 0 开始)。
示例:
// 发送到主题 "order-events" 的分区 2
kafkaTemplate.send("order-events", 2, "{\"orderId\": \"O20231001\"}");- 作用:明确将消息发送到指定分区,适用于需要控制消息物理存储位置的场景(如日志顺序性要求)。
3. 指定 Key 和 Value:控制分区策略
ListenableFuture<SendResult<K, V>> send(String topic, K key, V data);参数:
key:消息的键(Key),用于计算分区(默认Hash策略)。
示例:
// 使用用户ID作为Key,确保同一用户的消息进入同一分区
kafkaTemplate.send("user-actions", "user-1001", "{\"action\": \"purchase\"}");- 作用:通过 Key 控制分区分配,保证相同 Key 的消息总是进入同一分区,实现顺序性消费。
4. 指定分区、Key 和 Value
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, V data
);- 示例:
// 发送到分区 1,Key 为 "region-east",Value 为区域数据
kafkaTemplate.send("region-data", 1, "region-east", "{\"sales\": 5000}");作用:同时指定分区和 Key(以 Key 的分区计算结果优先,若分区已指定则忽略 Key)。
5. 包含时间戳
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key, V data
);参数:
timestamp:消息时间戳(毫秒),用于日志留存策略或流处理。
示例:
long eventTime = System.currentTimeMillis(); kafkaTemplate.send("sensor-data", 0, eventTime, "sensor-001", "{\"temp\": 25.5}" );作用:
显式设置消息时间戳,影响 Kafka 日志清理策略(如
LogAppendTime或CreateTime)。
6. 使用 ProducerRecord 对象
ListenableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record);示例:
ProducerRecord<String, String> record = new ProducerRecord<>("audit-logs", 0, "log-20231001", "{\"level\": \"INFO\", \"message\": \"User login\"}" ); kafkaTemplate.send(record);作用:直接使用 Kafka 原生
ProducerRecord对象,支持更底层配置(如 Headers)。
kafka接收消息
//示例: @KafkaListener(topics = PositionAnalyseMessage.TOPIC, groupId = "wetool-position-analyse")public void consume0(PositionAnalyseMessage message) {this.doConsume(message);}1.在同一个消费组中,同一条消息只被一个消费者消费
// 同组的消费者A
@KafkaListener(topics = "test-topic", groupId = "same-group")
public void consumeA(String message) { }// 同组的消费者B
@KafkaListener(topics = "test-topic", groupId = "same-group")
public void consumeB(String message) { }2.在不同消费组中,同一条消息会被不同组的消费者都会消费(类似发布订阅)
// 订单消息处理
@KafkaListener(topics = "order-topic", groupId = "order-process")
public void processOrder(Order order) {// 处理订单逻辑
}// 订单统计
@KafkaListener(topics = "order-topic", groupId = "order-statistics")
public void statisticsOrder(Order order) {// 统计订单数据
}// 订单通知
@KafkaListener(topics = "order-topic", groupId = "order-notification")
public void notifyOrder(Order order) {// 发送订单通知
}消费场景
消息手动提交
参数设置
enable.auto.commit=false
consumer.pause() 、consumer.resume()方法
consumer.pause():
暂停消费指定分区的消息,暂时不再从这些分区拉取新消息。consumer.resume():
恢复消费之前暂停的分区的消息,继续从这些分区拉取消息。
acknowledgment.acknowledge()
手动确认消息已被成功处理
分区解释
规则:
从 0 开始编号:所有 Kafka 分区的编号都是从 0 开始的整数
连续递增:分区编号是连续的(0, 1, 2, 3...)
格式:
<topic_name>-<partition_id>
配置:
num.partitions=1 未指定分区数 → 使用
num.partitions值(默认为 1)
单分区:
停止分区:
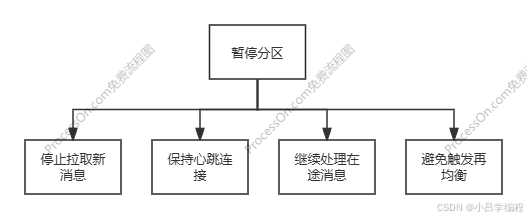
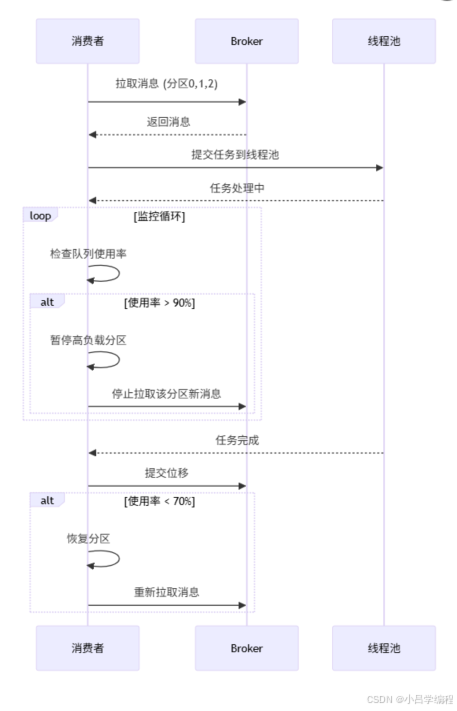
停止拉取新消息核心效果:
- 消费者不再从指定分区获取新消息
- 但已拉取到内存的消息仍会继续处理
- 分区积压消息会保留在Kafka broker上
暂停分区的意义:
- 流量控制:防止消费者过载的终极手段
- 稳定性保障:避免消费者崩溃和再均衡风暴
- 精准调控:分区粒度的流量管理
- 无缝恢复:负载下降后自动恢复消费
- 资源保护:防止内存溢出和线程耗尽
代码实现逻辑
批量消费消息场景
参数设置
containerFactory.setBatchListener(true);
max.poll.records:单次 poll() 调用返回的最大消息数(默认500)
fetch.max.wait.ms:等待多久拉取消息