kubeadm搭建生产环境的双master节点k8s高可用集群
k8s环境规划:
podSubnet(pod 网段) 10.20.0.0/16
serviceSubnet(service 网段): 10.10.0.0/16
实验环境规划:
操作系统:centos7.9
配置: 4G 内存/4核CPU/40G 硬盘
网络:NAT
| K8s集群角色 | ip | 主机名 | 安装的组件 |
|---|---|---|---|
| 控制节点(master) | 192.168.121.101 | master1 | apiserver、controller-manager、scheduler、kubelet、etcd、docker、kube-proxy、keepalived、nginx、calico |
| 控制节点(master) | 192.168.121.102 | master2 | apiserver、controller-manager、scheduler、kubelet、etcd、docker、kube-proxy、keepalived、nginx、calico |
| 工作节点(node) | 192.168.121.103 | node1 | kubelet、kube-proxy、docker、calico、coredns |
| Vip(虚拟ip) | 192.168.121.100 | * |
1 初始化安装k8s集群的实验环境
1.1 修改虚拟机ip,固定静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens32 # 替换为自己实际网卡名称 ifcfg-ens**BOOTPROTO=static # static 表示静态ip地址
NAME=ens32 # 网卡名字
DEVICE=ens32 # 网络设备名
ONBOOT=yes # 开机自启动网络,必须要是yes
IPADDR=192.168.121.101 # ip地址
NETMASK=255.255.255.0 # 子网掩码
GATEWAY=192.168.121.2 # 网关
DNS1=223.5.5.5 # DNS
DNS2=8.8.8.8
systemctl restart network1.2 修改机器主机名
在master1节点上执行以下:
hostnamectl set-hostname master1在master2节点上执行以下:
hostnamectl set-hostname master2在node1节点上执行以下:
hostnamectl set-hostname node11.3 配置主机 hosts 文件,可以通过主机名互相访问
修改每一台机器的/etc/hosts文件,增加三行{ip 主机名}:
192.168.121.101 master1
192.168.121.102 master2
192.168.121.103 node1
1.4 配置主机之间免密登录
可以使用xshell工具发送键输入到所有会话,用于多台机器同时执行一样的命令
ssh-keygen:SSH 密钥生成工具 -t rsa:指定密钥类型为 RSA -b 4096:指定密钥长度为 4096 位, 一路回车不用输密码
ssh-keygen -t rsa -b 4096
# 出现表示成功
The key's randomart image is:
+---[RSA 4096]----+
| o.o o..o=+.|
| . + ....o*==O|
| o . o +ooOE|
| ... .o +. o|
| .oo S . = = .|
| .=.. . . = . |
| ...+ . . |
| o. . |
| .. |
+----[SHA256]-----+
使用xshell发送键输入到所有会话,把本地生成的密钥文件和私钥文件拷贝到远程主机
ssh-copy-id master1
ssh-copy-id master2
ssh-copy-id node1ssh-copy-id master1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'master1 (192.168.121.101)' can't be established.
ECDSA key fingerprint is SHA256:Kx5U2vn407nrPiAwpK1poBqjVqDpzBI0szutWmYEG4w.
ECDSA key fingerprint is MD5:e0:e7:75:80:e3:b1:41:16:fa:76:e9:0b:27:87:fb:c2.
Are you sure you want to continue connecting (yes/no)? yes # 输入yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@master1's password: # 输入登录密码Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'master1'"
and check to make sure that only the key(s) you wanted were added.
1.5 关闭交换分区 swap
#永久关闭:注释 swap 挂载,给 swap 这行开头加一下注释
vim /etc/fstab
#/dev/mapper/centos-swap swap swap defaults 0 0
为什么要关闭 swap 交换分区?
- 性能损耗大:swap 用磁盘模拟内存,速度比物理内存慢得多,会导致程序响应变慢
- 调度不可控:干扰系统对内存使用的判断,尤其在 Kubernetes 等集群中,会破坏资源调度的准确性
- 设计冲突:K8s 等系统依赖精确的内存状态进行调度,swap 会导致判断失真
1.6 修改机器内核参数
使用xshell发送键输入到所有会话
modprobe br_netfilter echo "modprobe br_netfilter" >> /etc/profile vim /etc/sysctl.d/k8s.confnet.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1 sysctl -p /etc/sysctl.d/k8s.conf
-
modprobe br_netfilter- 加载 br_netfilter 模块,该模块用于支持桥接网络与 iptables 规则的交互 -
echo "modprobe br_netfilter" >> /etc/profile- 将模块加载命令添加到 profile 文件,确保系统重启后自动加载 -
vim /etc/sysctl.d/k8s.conf- 编辑 sysctl 配置文件,用于设置内核参数 -
配置的三个内核参数含义:
-
net.bridge.bridge-nf-call-ip6tables = 1- 启用桥接网络对 IPv6 的 iptables 支持 -
net.bridge.bridge-nf-call-iptables = 1- 启用桥接网络对 IPv4 的 iptables 支持 -
net.ipv4.ip_forward = 1- 启用 IPv4 转发功能
-
-
sysctl -p /etc/sysctl.d/k8s.conf- 立即加载刚才配置的内核参数,无需重启系统
1.7 关闭 firewalld 防火墙
使用xshell发送键输入到所有会话
systemctl stop firewalld && systemctl disable firewalld
1.8 关闭 selinux
使用xshell发送键输入到所有会话
vim /etc/selinux/config# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disable # 修改成disable
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted

检查是否关闭
getenforceDisabled #显示disabled说明selinux已经关闭
1.9 配置 repo 源
使用xshell发送键输入到所有会话
安装 rzsz 命令
yum install lrzsz -y 安装 scp:
yum install openssh-clients -y#备份基础 repo 源
mkdir /root/repo.bak cd /etc/yum.repos.d/ mv * /root/repo.bak/#下载阿里云的 repo 源curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo

配置国内阿里云docker的repo源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo报错-bash: yum-config-manager: 未找到命令
安装依赖:
yum install -y yum-utils
1.10 配置安装 k8s 组件需要的阿里云的 repo 源
[root@master1 ~]#vim /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0 #将 master1 上 Kubernetes 的 repo 源复制给 master2 和 node1
[root@master1 ~]# scp /etc/yum.repos.d/kubernetes.repo master2:/etc/yum.repos.d/
[root@master1 ~]# scp /etc/yum.repos.d/kubernetes.repo node1:/etc/yum.repos.d/
1.11 配置时间同步
使用xshell发送键输入到所有会话,安装ntpdate命令
yum install ntpdate -y
#跟网络时间做同步
ntpdate cn.pool.ntp.org
#把时间同步做成计划任务
crontab -e
* */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
#重启 crond 服务
service crond restart
1.12 开启 ipvs
使用xshell发送键输入到所有会话
vim /etc/sysconfig/modules/ipvs.modules#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules}; do/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1if [ 0 -eq 0 ]; then/sbin/modprobe ${kernel_module}fi
donechmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs

-
vim /etc/sysconfig/modules/ipvs.modules- 创建一个模块加载脚本,用于加载 IPVS 相关内核模块 -
脚本内容解析:
-
定义了需要加载的 IPVS 相关内核模块列表
-
循环检查每个模块是否存在
-
如果模块存在则加载它
-
-
最后一行命令的作用:
-
chmod 755 ...- 赋予脚本可执行权限 -
bash ...- 立即执行脚本加载模块 -
lsmod | grep ip_vs- 验证 IPVS 模块是否成功加载
-
1.13 安装基础软件包
使用xshell发送键输入到所有会话
yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet通过 yum 包管理器一次性安装多个系统工具和开发依赖包,适用于服务器初始化或环境搭建,各软件包的主要用途如下:
-
基础工具:
yum-utils(yum 扩展工具)、wget(下载工具)、vim(文本编辑器)、net-tools(网络工具如 ifconfig)、telnet(远程连接测试)、socat(网络工具)、lrzsz(文件传输工具)。 -
存储相关:
device-mapper-persistent-data、lvm2(LVM 逻辑卷管理工具)、nfs-utils(NFS 文件共享支持)。 -
开发依赖:
gcc、gcc-c++(编译器)、make、cmake(编译工具)、libxml2-devel、openssl-devel、curl-devel等(各类库的开发文件,用于编译软件)。 -
系统相关:
ntp、ntpdate(时间同步)、sudo(权限管理)、openssh-server(SSH 服务)、epel-release(扩展软件源)。 -
容器 / K8s 相关:
ipvsadm(IPVS 负载均衡管理)、conntrack(连接跟踪工具,用于网络规则)。
1.14 安装 iptables
使用xshell发送键输入到所有会话
#安装 iptables
yum install iptables-services -y
#禁用 iptables
service iptables stop && systemctl disable iptables
#清空防火墙规则
iptables -F
2 安装 docker 服务
2.1 安装 docker-ce
使用xshell发送键输入到所有会话
yum install docker-ce-20.10.24 docker-ce-cli-20.10.24 containerd.io-1.6.24-3.1.el7 -y
systemctl start docker && systemctl enable docker && systemctl status docker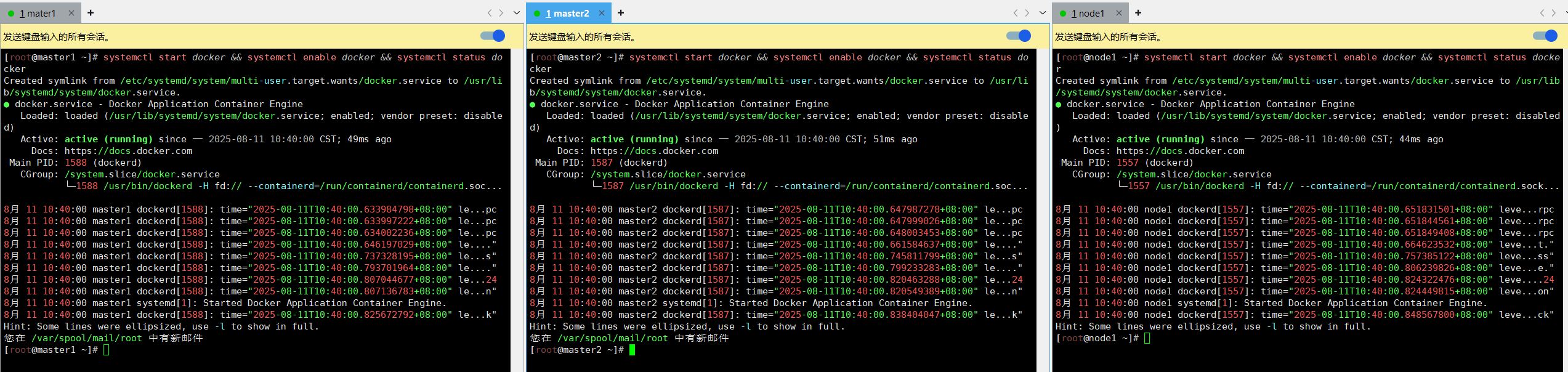
2.2 配置 docker 镜像加速器和驱动
使用xshell发送键输入到所有会话
Docker镜像极速下载服务 - 毫秒镜像
一键全局配置
一键解决镜像仓库拉取镜像慢的问题,国内专业的镜像仓库解决方案商
bash <(curl -sSL https://n3.ink/helper)[root@master1 ~]# bash <(curl -sSL https://n3.ink/helper)=======================================1ms Helper 引导助手
=======================================🔍 检测到系统: Linux x86_64
📦 下载包: 1ms-helper_Linux_x86_64.tar.gz
🚀 解压安装...
⚡ 启动程序 (参数: )...请选择要执行的命令:
------------------------------1. config - 一键配置毫秒镜像(推荐)2. check - 检查与毫秒镜像的连接状态和配置3. dns:check - 检查和修复Docker DNS配置问题4. config:account - 配置毫秒镜像账号5. remove:account - 移除毫秒镜像账号配置6. config:mirror - 快速配置毫秒镜像为您的镜像仓库首选7. remove:mirror - 移除毫秒镜像配置8. 退出请选择 (输入数字): 1
🚀 开始一键配置毫秒镜像...
此过程将依次配置镜像加速和账号认证📦 第1步: 配置镜像加速...
配置文件路径: /etc/docker/daemon.json
文件不存在,路径:/etc/docker/daemon.json[]
🔍 检查Docker DNS配置...
⚠️ Docker未配置DNS服务器,将使用系统默认DNS
❌ 系统DNS无法解析Docker镜像域名🔧 DNS问题修复建议:
推荐配置以下DNS服务器(按优先级排序):
1. 223.5.5.5
2. 114.114.114.114
3. 8.8.8.8
4. 1.1.1.1
是否自动配置推荐的DNS服务器?默认:y [y/n] y
测试推荐的DNS服务器...
⚠️ 223.5.5.5 不可用
⚠️ 114.114.114.114 不可用
⚠️ 8.8.8.8 不可用
⚠️ 1.1.1.1 不可用
❌ 所有推荐的DNS服务器都不可用,请检查网络连接
配置完成
是否重新加载Docker配置文件(重启Docker)以便生效配置?默认:y [y/n] y
即将重新加载Docker配置,并且重启Docker
使用systemctl管理Docker服务
执行:systemctl daemon-reload ...执行:systemctl restart docker ...验证Docker服务状态...
执行:docker info ...
✅ Docker服务重启成功🔐 第2步: 配置账号认证...
您确认已经在毫秒镜像注册账号? 默认:n [y/n] y
请输入您的账号: 130****5735(为保护您的隐私已脱敏)
请输入您的密码: *************正在验证账号信息,请稍候...
使用标准Docker配置路径: /root/.docker/config.json
未配置过 docker.io 的账号
是否将 docker.io 的账号位置配置成毫秒镜像的账号?
为什么这么做? 见: https://www.mliev.com/docs/1ms.run/docker-login/linux#%E8%BF%9B%E9%98%B6%E6%95%99%E7%A8%8B
能在无前缀时候走VIP加速通道!!!
强烈建议输入y,默认:n [y/n] y
是否加速 ghcr.io ?默认:y [y/n] y
使用方法:将【ghcr.io】替换成【ghcr.1ms.run】
是否加速 gcr.io ?默认:y [y/n] y
使用方法:将【gcr.io】替换成【gcr.1ms.run】
是否加速 nvcr.io ?默认:y [y/n] y
使用方法:将【nvcr.io】替换成【nvcr.1ms.run】
是否加速 quay.io ?默认:y [y/n] y
使用方法:将【quay.io】替换成【quay.1ms.run】
是否加速 docker.elastic.co ?默认:y [y/n] y
使用方法:将【docker.elastic.co】替换成【elastic.1ms.run】
是否加速 mcr.microsoft.com ?默认:y [y/n] y
使用方法:将【mcr.microsoft.com】替换成【mcr.1ms.run】
是否加速 registry.k8s.io ?默认:y [y/n] y
使用方法:将【registry.k8s.io】替换成【k8s.1ms.run】
使用标准Docker配置路径: /root/.docker/config.json
账号配置成功🎉 一键配置完成!
现在您可以享受毫秒级的Docker镜像下载体验了!
您在 /var/spool/mail/root 中有新邮件vim /etc/docker/daemon.json{"registry-mirrors": ["https://docker.1ms.run"],"exec-opts": ["native.cgroupdriver=systemd"] # 添加此行,指定 Docker 容器运行时使用的 cgroup 驱动程序 为 systemd。
}systemctl daemon-reload && systemctl restart docker && systemctl status docker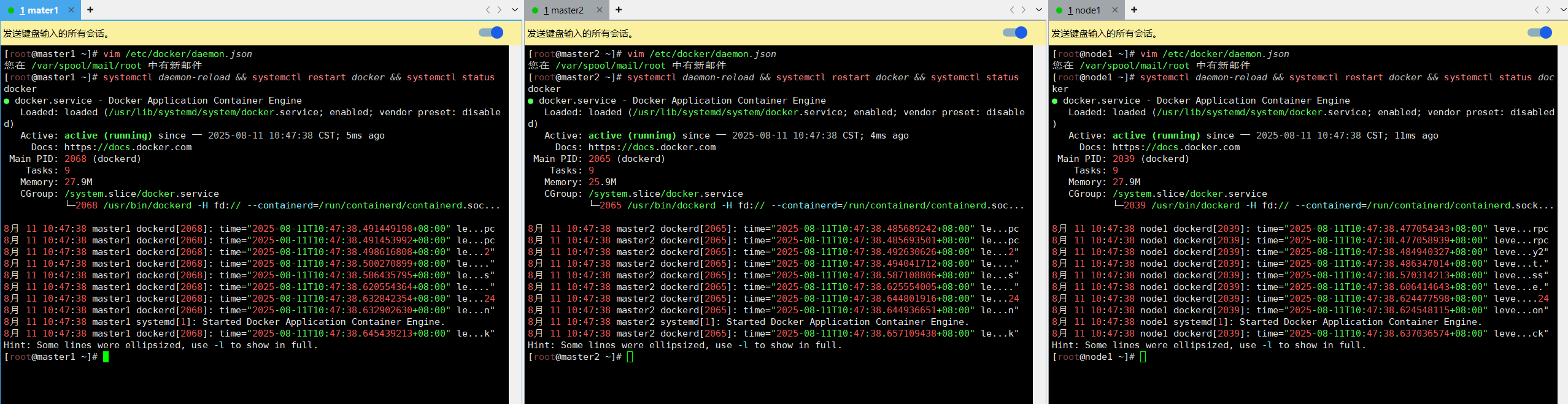
3 安装初始化 k8s 需要的软件包
使用xshell发送键输入到所有会话
yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet-
yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6-
使用 yum 包管理器安装指定版本 (1.20.6) 的 Kubernetes 核心组件
-
kubelet:在每个节点上运行的代理,负责管理容器
-
kubeadm:用于初始化和管理 Kubernetes 集群的工具
-
kubectl:Kubernetes 命令行客户端,用于与集群交互
-
-
服务管理命令:
-
systemctl enable kubelet:设置 kubelet 服务开机自启动 -
systemctl start kubelet:立即启动 kubelet 服务 -
systemctl status kubelet:查看 kubelet 服务的运行状态
-
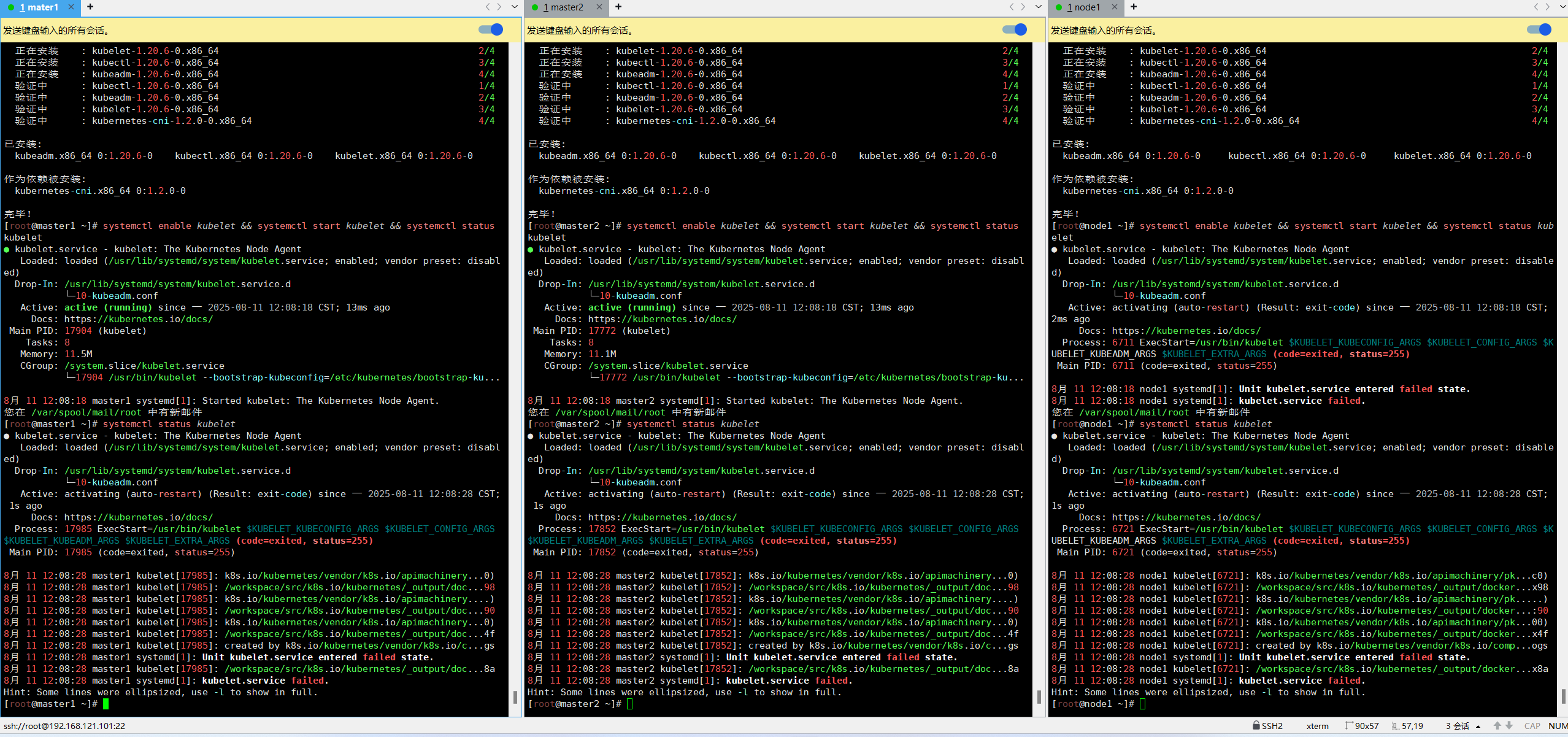
上面可以看到 kubelet 状态不是 running 状态,这个是正常的,不用管,等 k8s 组件起来这个
kubelet 就正常了。
4 通过 keepalive+nginx 实现 k8s apiserver 节点高可用
4.1 安装 nginx 主备:
在master1和master2上做nginx主备安装
yum install -y nginx nginx-mod-stream keepalived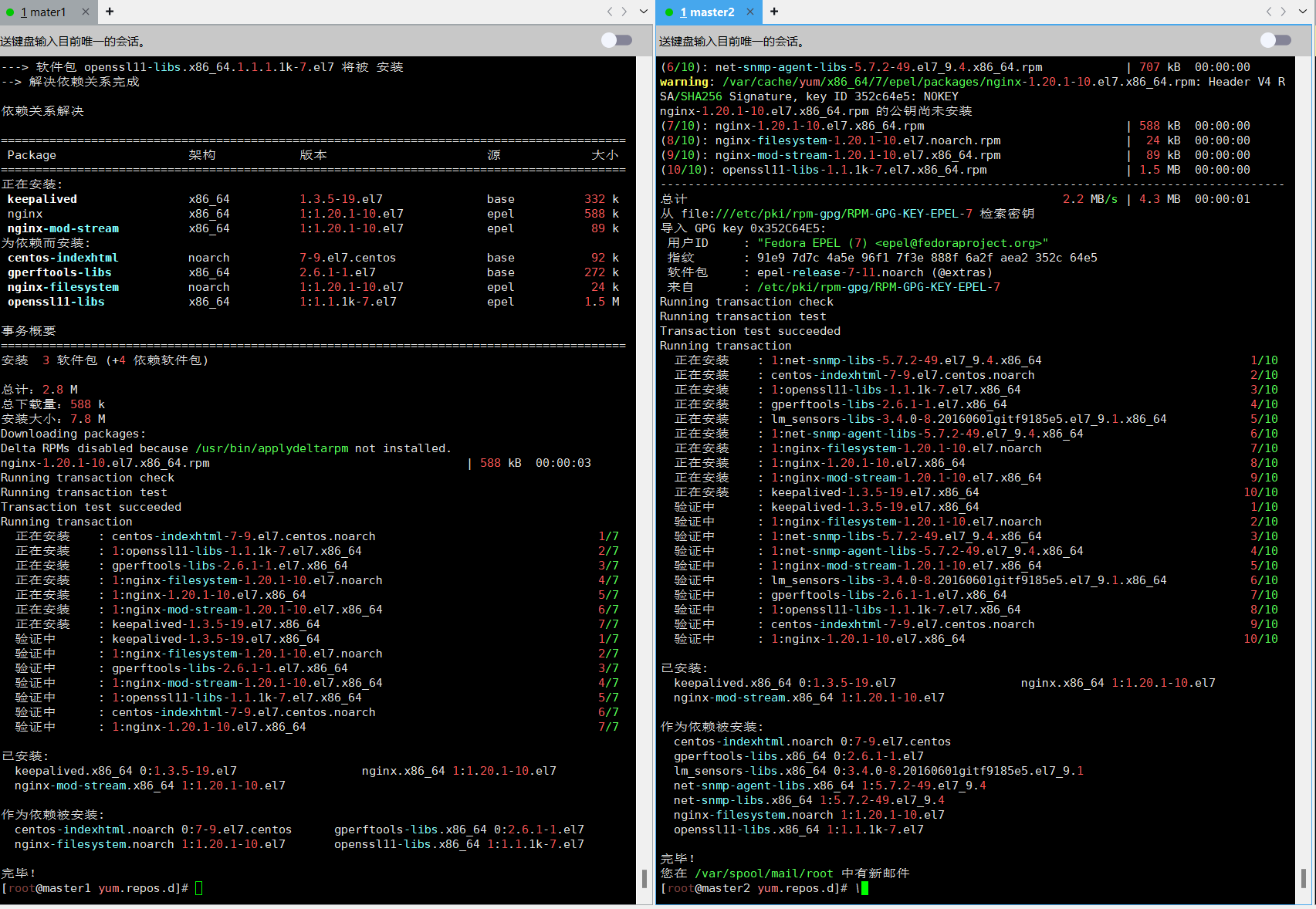
4.2 修改 nginx 配置文件,主备一样
vim /etc/nginx/nginx.conf#清空内容插入以下
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {worker_connections 1024;
}
stream {log_format main '$remote_addr $upstream_addr - [$time_local] $status
$upstream_bytes_sent'; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver {server 192.168.121.101:6443; # Master1 ip:port 替换为自己实际ipserver 192.168.121.102:6443; # Master2 ip:port 替换为自己实际ip}server {listen 16443; proxy_pass k8s-apiserver;}
}
http {log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 65;types_hash_max_size 2048;include /etc/nginx/mime.types;default_type application/octet-stream;server {listen 80 default_server;server_name _;location / {}}
}-
基础配置部分:
-
定义了运行用户、工作进程数、错误日志和 PID 文件位置
-
包含了 Nginx 模块配置
-
设置了事件处理的最大连接数
-
-
核心的四层负载均衡部分(stream 块):
-
定义了日志格式
-
创建了名为 k8s-apiserver 的上游服务器组,包含两个 Master 节点的 API Server 地址和端口 (6443)
-
配置了一个监听 16443 端口的服务器,将流量转发到上游服务器组
-
这样设计避免了与 Master 节点自身的 6443 端口冲突
-
-
常规 HTTP 配置部分:
-
定义了 HTTP 日志格式
-
设置了一些优化参数(sendfile、tcp_nopush 等)
-
包含了 MIME 类型配置
-
一个默认的 HTTP 服务器配置(监听 80 端口)
-
4.3 keepalive 配置
主master1配置
vim /etc/keepalived/keepalived.conf
# 清空全部内容插入以下
global_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_MASTER
}vrrp_script check_nginx {script "/etc/keepalived/check_nginx.sh"
}vrrp_instance VI_1 {
state MASTERinterface ens32 # 修改为实际网卡名virtual_router_id 51 priority 100 # 优先级,备服务器设置 90advert_int 1 # 指定 VRRP 心跳包通告间隔时间,默认 1 秒authentication {auth_type PASSauth_pass 1111}# 虚拟 IPvirtual_ipaddress {192.168.121.100/24}track_script {check_nginx}
}创建nginx工作状态检测脚本
vim /etc/keepalived/check_nginx.sh#!/bin/bash
count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];thensystemctl stop keepalived
fi
赋予可执行权限
chmod +x /etc/keepalived/check_nginx.sh备master2配置
vim /etc/keepalived/keepalived.confglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id NGINX_MASTER
}vrrp_script check_nginx {script "/etc/keepalived/check_nginx.sh"
}vrrp_instance VI_1 {
state MASTERinterface ens32 # 修改为实际网卡名virtual_router_id 51 priority 90 # 优先级,备服务器设置 90advert_int 1 # 指定 VRRP 心跳包通告间隔时间,默认 1 秒authentication {auth_type PASSauth_pass 1111}# 虚拟 IPvirtual_ipaddress {192.168.121.100/24}track_script {check_nginx}
}-
全局定义(global_defs):
-
配置了通知邮件相关信息(出现故障时发送警报)
-
设置了 SMTP 服务器和超时时间
-
定义了路由器 ID(NGINX_MASTER),用于标识当前节点
-
-
VRRP 脚本(vrrp_script):
-
定义了一个名为
check_nginx的健康检查脚本 -
脚本路径为
/etc/keepalived/check_nginx.sh(需要你另外创建这个脚本) -
作用是检查 Nginx 服务是否正常运行
-
-
VRRP 实例(vrrp_instance VI_1):
-
state MASTER:标识当前节点为主节点(备节点应设为 BACKUP) -
interface ens32:指定绑定的网卡(需根据实际环境修改) -
virtual_router_id 51:VRRP 路由 ID,同一集群内所有节点需保持一致 -
priority 100:优先级(备节点应设为较低值,如 90) -
advert_int 1:心跳检测间隔为 1 秒 -
认证配置:使用密码 "1111" 进行节点间认证
-
virtual_ipaddress:定义虚拟 IP(VIP)为 192.168.121.100/24 -
track_script:关联 Nginx 健康检查脚本
-
创建nginx工作状态检测脚本
vim /etc/keepalived/check_nginx.sh#!/bin/bash
count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];thensystemctl stop keepalived
fi
-
count=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$")-
这行命令用于统计正在运行的 Nginx 进程数量
-
ps -ef |grep nginx:查找包含 nginx 的进程 -
grep sbin:过滤出 nginx 主程序(通常位于 /sbin/nginx) -
egrep -cv "grep|$$":排除 grep 进程和当前脚本进程自身,-c统计数量,-v取反
-
-
if [ "$count" -eq 0 ];then systemctl stop keepalived;fi-
如果 Nginx 进程数量为 0(即 Nginx 已停止),则执行
systemctl stop keepalived -
停止当前节点的 Keepalived 服务,使 VIP 自动漂移到备用节点
-
使用前的必要操作:
赋予可执行权限
chmod +x /etc/keepalived/check_nginx.sh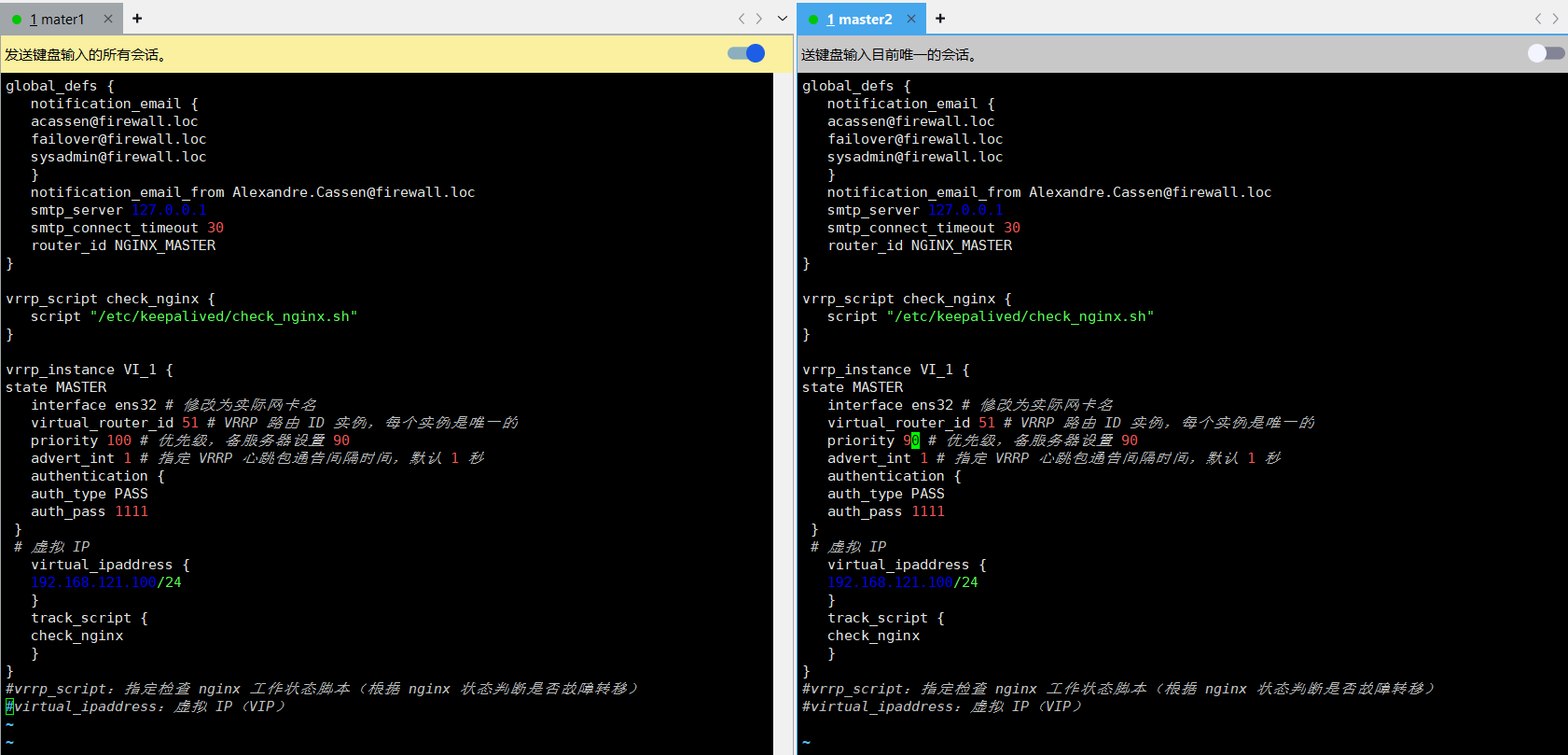
4.4 启动服务
master1 master2 依次执行
systemctl daemon-reloadsystemctl start nginxsystemctl start keepalivedsystemctl enable nginx keepalivedsystemctl status keepalived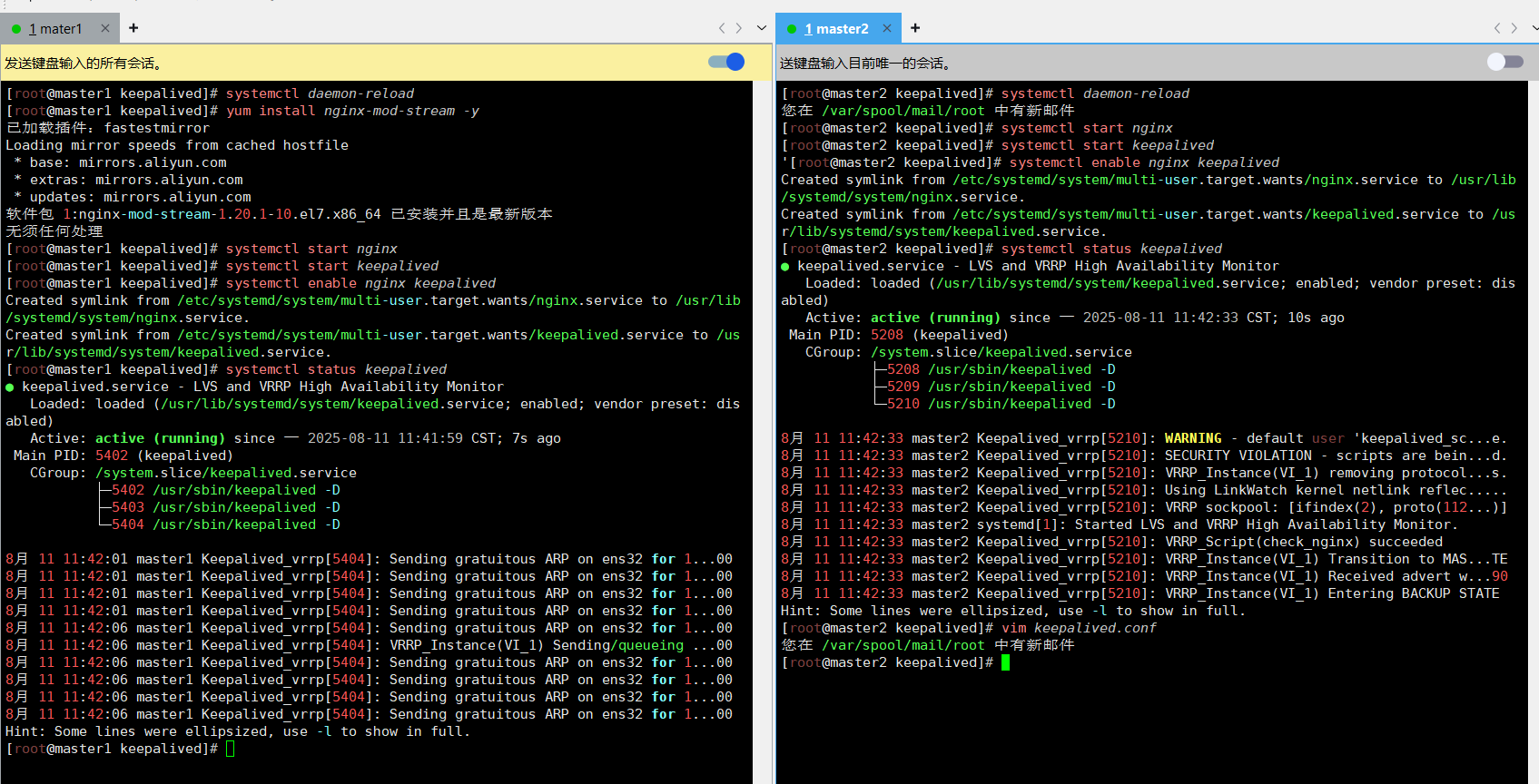
4.5 测试 vip 是否绑定成功
[root@master1 keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:0b:e0:0c brd ff:ff:ff:ff:ff:ffinet 192.168.121.101/24 brd 192.168.121.255 scope global noprefixroute ens32valid_lft forever preferred_lft foreverinet 192.168.121.100/24 scope global secondary ens32valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe0b:e00c/64 scope link valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:41:ef:90:7f brd ff:ff:ff:ff:ff:ffinet 172.17.0.1/16 brd 172.17.255.255 scope global docker0valid_lft forever preferred_lft forever4.6 测试 keepalived:
停掉 master1 上的 nginx,Vip 会漂移到 master2
systemctl stop nginx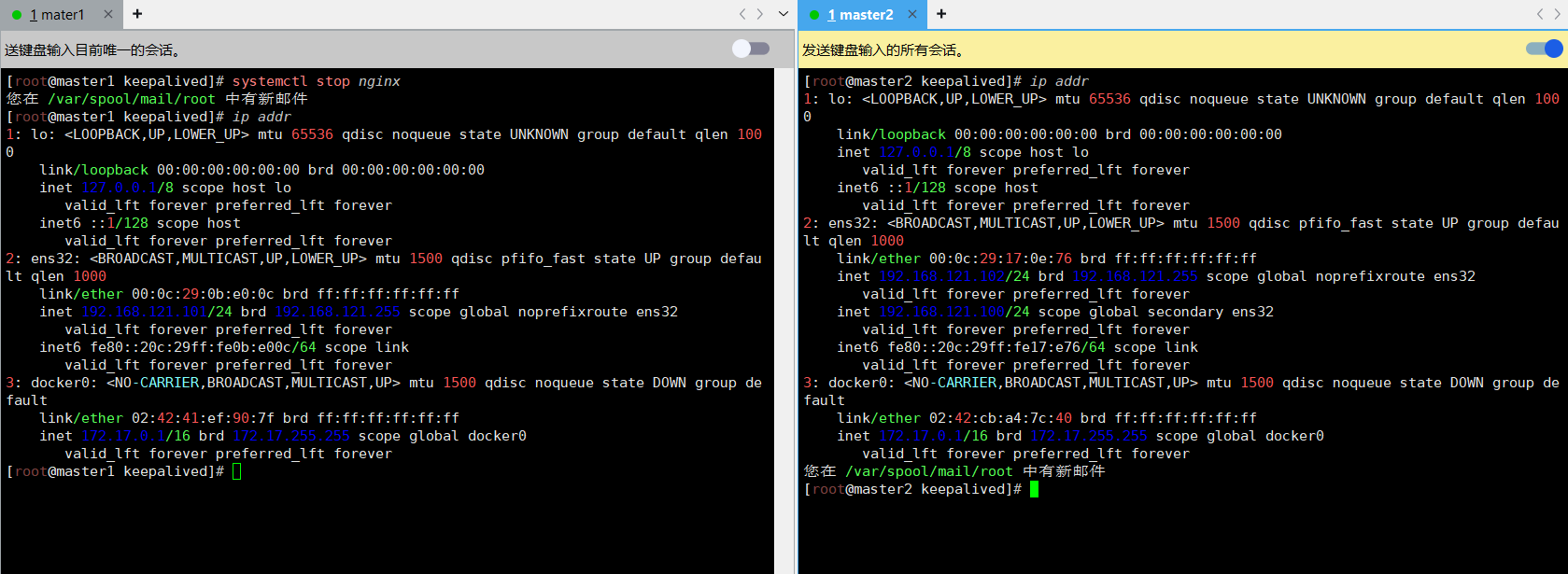
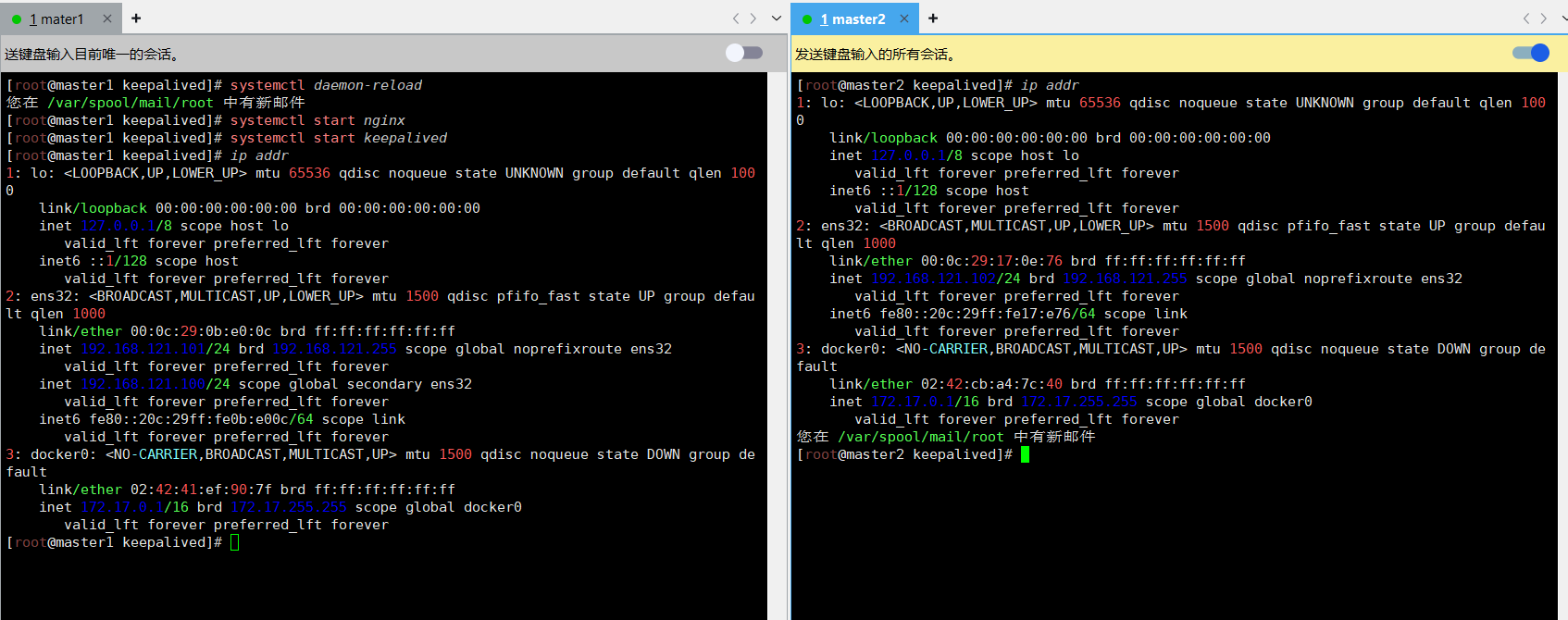
启动 master1 上的 nginx 和 keepalived,vip 又会漂移回来
[root@master1 keepalived]# systemctl daemon-reload
[root@master1 keepalived]# systemctl start nginx
[root@master1 keepalived]# systemctl start keepalived
[root@master1 keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:0b:e0:0c brd ff:ff:ff:ff:ff:ffinet 192.168.121.101/24 brd 192.168.121.255 scope global noprefixroute ens32valid_lft forever preferred_lft foreverinet 192.168.121.100/24 scope global secondary ens32valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe0b:e00c/64 scope link valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default link/ether 02:42:41:ef:90:7f brd ff:ff:ff:ff:ff:ffinet 172.17.0.1/16 brd 172.17.255.255 scope global docker0valid_lft forever preferred_lft forever
5 kubeadm 初始化 k8s 集群
[root@master1 keepalived]# cd /root/
[root@master1 ~]# vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.26.6
controlPlaneEndpoint: 192.168.121.100:16443 # 虚拟ip
imageRepository: registry.aliyuncs.com/google_containers
apiServer:certSANs:- 192.168.121.101 # master1- 192.168.121.102 # master2- 192.168.121.103 # node1- 192.168.121.100 # 虚拟ip
networking:podSubnet: 10.20.0.0/16serviceSubnet: 10.10.0.0/16
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
-
ClusterConfiguration 部分:
-
kubernetesVersion: v1.26.6:指定要部署的 Kubernetes 版本 -
controlPlaneEndpoint: 192.168.121.100:16443:设置控制平面的访问端点,这里使用了之前配置的虚拟 IP (VIP) 和 Nginx 监听的 16443 端口,实现高可用 -
imageRepository: registry.aliyuncs.com/google_containers:使用阿里云镜像仓库,解决国内访问 Google 镜像仓库的问题 -
certSANs:指定 API Server 证书中包含的 Subject Alternative Names,确保所有节点和 VIP 都能通过证书验证 -
networking:定义网络配置-
podSubnet: 10.20.0.0/16:Pod 网络的子网范围(需与你将使用的 CNI 插件配置一致) -
serviceSubnet: 10.10.0.0/16:Service 网络的子网范围
-
-
-
KubeProxyConfiguration 部分:
-
mode: ipvs:指定 kube-proxy 使用 IPVS 模式,相比默认的 iptables 模式,在大规模集群中有更好的性能
-
[root@master1 ~]# docker load -i k8simage-1-20-6.tar.gz
[root@master2 ~]# docker load -i k8simage-1-20-6.tar.gz
[root@node1 ~]# docker load -i k8simage-1-20-6.tar.gzk8simage-1-20-6.tar.gz
链接: https://pan.baidu.com/s/1tt-PHdrf3c1VVBiZ4fiRyg?pwd=cypb 提取码: cypb
kubeadm init --config kubeadm-config.yaml --ignore-prefligh-errors=SystemVerification显示如下,说明安装完成
[root@master1 ~]# kubeadm init --config kubeadm-config.yaml --ignore-preflight-errors=SystemVerification
[init] Using Kubernetes version: v1.20.6
[preflight] Running pre-flight checks
[preflight] The system verification failed. Printing the output from the verification:
KERNEL_VERSION: 3.10.0-1160.el7.x86_64
DOCKER_VERSION: 20.10.24
OS: Linux
CGROUPS_CPU: enabled
CGROUPS_CPUACCT: enabled
CGROUPS_CPUSET: enabled
CGROUPS_DEVICES: enabled
CGROUPS_FREEZER: enabled
CGROUPS_MEMORY: enabled
CGROUPS_PIDS: enabled
CGROUPS_HUGETLB: enabled[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.24. Latest validated version: 19.03[WARNING SystemVerification]: failed to parse kernel config: unable to load kernel module: "configs", output: "modprobe: FATAL: Module configs not found.\n", err: exit status 1
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master1] and IPs [10.10.0.1 192.168.121.101 192.168.121.100 192.168.121.102 192.168.121.103]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [192.168.121.101 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [192.168.121.101 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[apiclient] All control plane components are healthy after 56.024993 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master1 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)"
[mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: f4zpmb.m7wjllm4a375d7s2
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
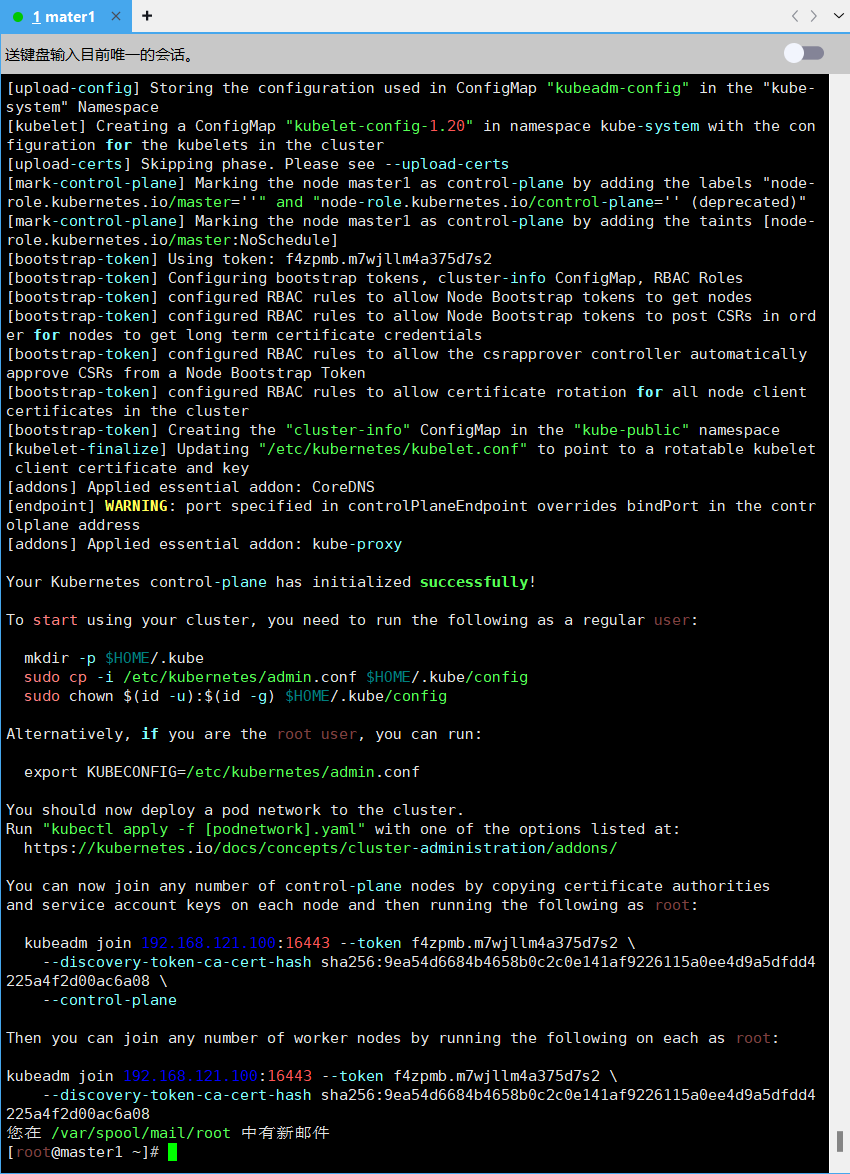
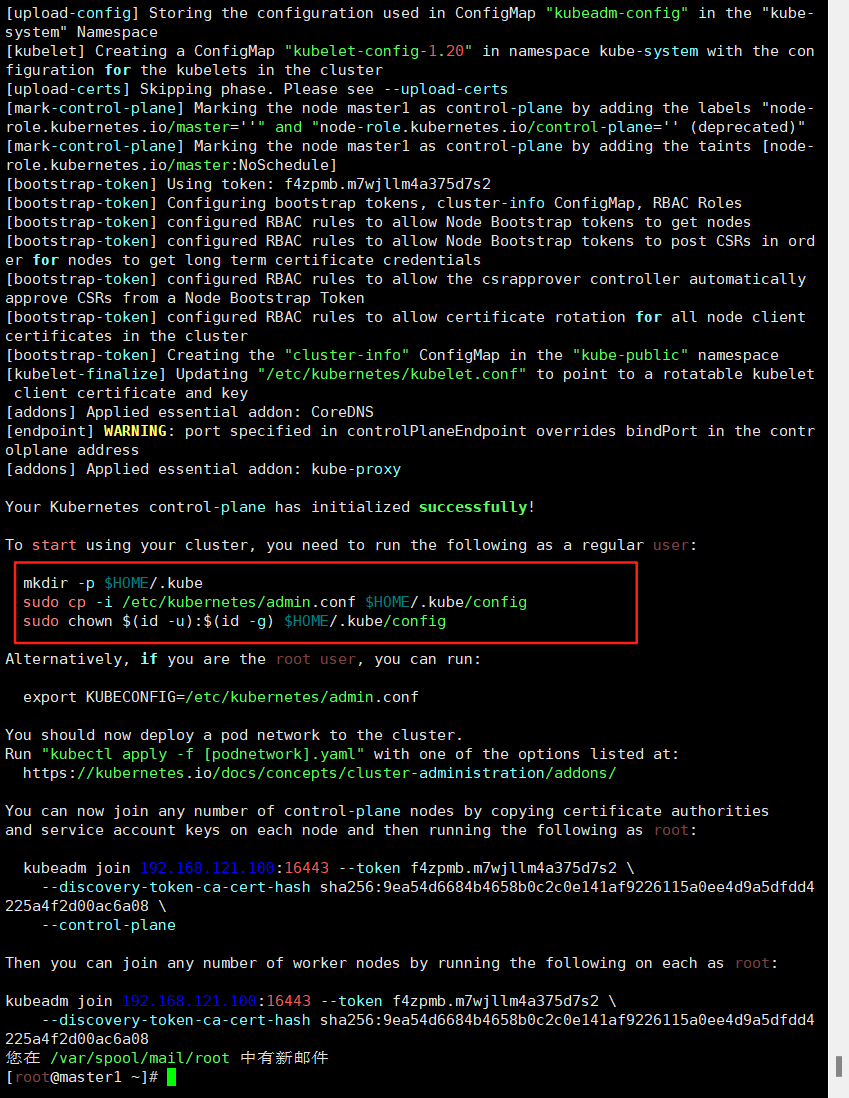
[addons] Applied essential addon: kube-proxyYour Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:kubeadm join 192.168.121.100:16443 --token f4zpmb.m7wjllm4a375d7s2 \--discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08 \--control-plane Then you can join any number of worker nodes by running the following on each as root:kubeadm join 192.168.121.100:16443 --token f4zpmb.m7wjllm4a375d7s2 \--discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08
倒数第二条命令是把master节点加入集群,需要保存下来,每个人的都不一样
kubeadm join 192.168.121.100:16443 --token f4zpmb.m7wjllm4a375d7s2 \--discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08 \--control-plane最后一条命令是把node工作节点加入集群
kubeadm join 192.168.121.100:16443 --token f4zpmb.m7wjllm4a375d7s2 \--discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08 配置 kubectl 的配置文件 config,相当于对 kubectl 进行授权,这样 kubectl 命令可以使用这个证书对 k8s 集群进行管理
[root@master1 ~]# mkdir -p $HOME/.kube
[root@master1 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master1 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 6m28s v1.20.6
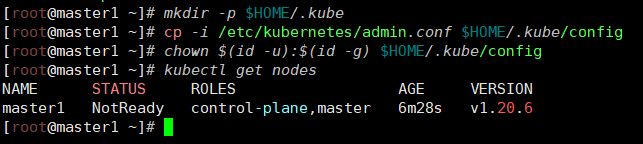
集群状态还是 NotReady 状态,因为没有安装网络插件
6 扩容 k8s 集群-添加 master 节点
在 master2 创建证书存放目录:
cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/把 master1 节点的证书拷贝到 master2 上
[root@master1 ~]# scp /etc/kubernetes/pki/ca.crt master2:/etc/kubernetes/pki/
ca.crt 100% 1066 1.4MB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/ca.key master2:/etc/kubernetes/pki/
ca.key 100% 1675 1.9MB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/sa.key master2:/etc/kubernetes/pki/
sa.key 100% 1675 2.1MB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/sa.pub master2:/etc/kubernetes/pki/
sa.pub 100% 451 516.4KB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/front-proxy-ca.crt master2:/etc/kubernetes/pki/
front-proxy-ca.crt 100% 1078 1.7MB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/front-proxy-ca.key master2:/etc/kubernetes/pki/
front-proxy-ca.key 100% 1679 2.2MB/s 00:00
[root@master1 ~]# scp /etc/kubernetes/pki/etcd/ca.crt master2:/etc/kubernetes/pki/etcd/
ca.crt 100% 1058 554.7KB/s 00:00
您在 /var/spool/mail/root 中有新邮件
[root@master1 ~]# scp /etc/kubernetes/pki/etcd/ca.key master2:/etc/kubernetes/pki/etcd/
ca.key 100% 1679 1.3MB/s 00:00 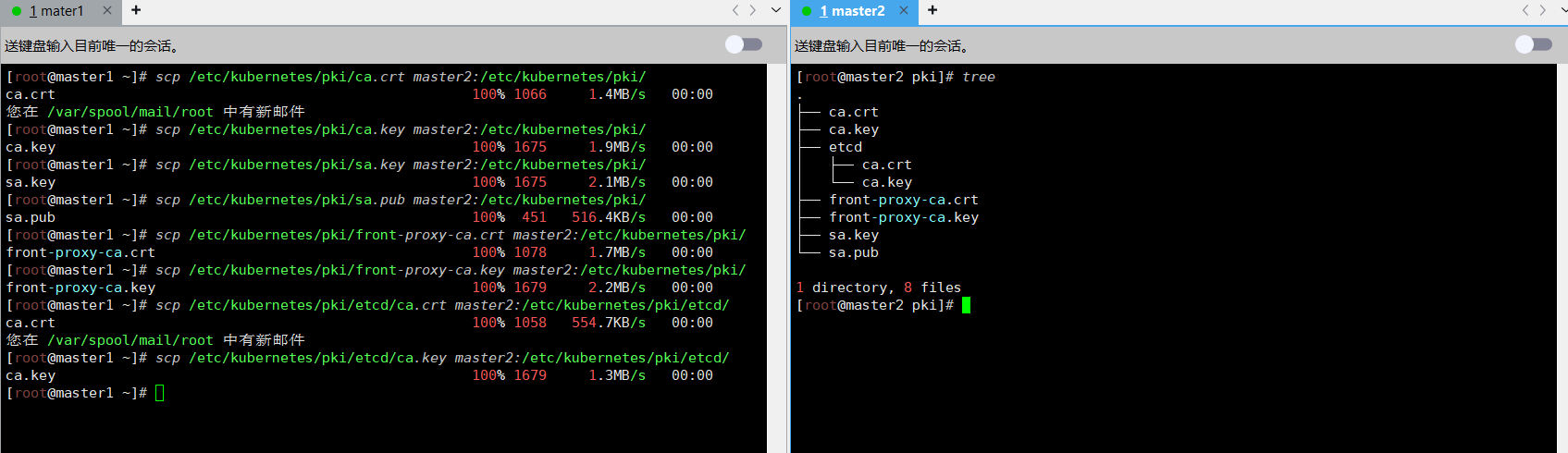
证书拷贝之后在 master2 上执行如下命令,复制自己的,这样就可以把master2 和加入到集群,成为控制节点:
[root@master1 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.121.100:16443 --token voxprz.tfhvb5cyjrgni1ir --discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08[root@master2 pki]# kubeadm join 192.168.121.100:16443 \
> --token voxprz.tfhvb5cyjrgni1ir \
> --discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08 \
> --control-plane \
> --ignore-preflight-errors=SystemVerification
[preflight] Running pre-flight checks
[preflight] The system verification failed. Printing the output from the verification:
KERNEL_VERSION: 3.10.0-1160.el7.x86_64
DOCKER_VERSION: 20.10.24
OS: Linux
CGROUPS_CPU: enabled
CGROUPS_CPUACCT: enabled
CGROUPS_CPUSET: enabled
CGROUPS_DEVICES: enabled
CGROUPS_FREEZER: enabled
CGROUPS_MEMORY: enabled
CGROUPS_PIDS: enabled
CGROUPS_HUGETLB: enabled[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.24. Latest validated version: 19.03[WARNING SystemVerification]: failed to parse kernel config: unable to load kernel module: "configs", output: "modprobe: FATAL: Module configs not found.\n", err: exit status 1
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master2] and IPs [192.168.121.102 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master2] and IPs [192.168.121.102 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master2] and IPs [10.10.0.1 192.168.121.102 192.168.121.100 192.168.121.101 192.168.121.103]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[mark-control-plane] Marking the node master2 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)"
[mark-control-plane] Marking the node master2 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]This node has joined the cluster and a new control plane instance was created:* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.To start administering your cluster from this node, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configRun 'kubectl get nodes' to see this node join the cluster.
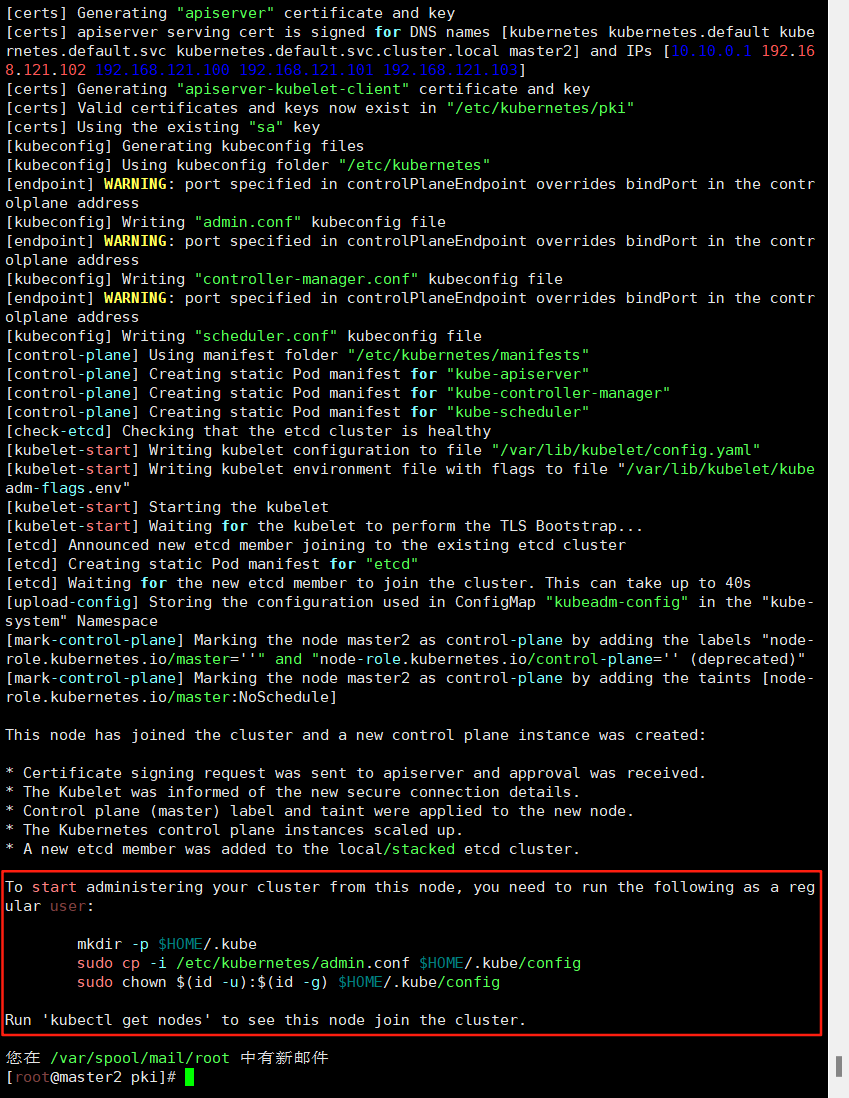
看到上面说明 master2 节点已经加入到集群了
在master1上查看集群状况:
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 16m v1.20.6
master2 NotReady control-plane,master 97s v1.20.6
上面可以看到 master2 已经加入到集群了
7 扩容 k8s 集群-添加 node 节点
在 master1 上查看加入节点的命令:
[root@master1 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.121.100:16443 --token 05jbt3.lffqtvwu6g7rxqg5 --discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08 把node1加入集群
[root@node1 ~]# kubeadm join 192.168.121.100:16443 --token 05jbt3.lffqtvwu6g7rxqg5 --discovery-token-ca-cert-hash sha256:9ea54d6684b4658b0c2c0e141af9226115a0ee4d9a5dfdd4225a4f2d00ac6a08 --ignore-preflight-errors=SystemVerification
[preflight] Running pre-flight checks
[preflight] The system verification failed. Printing the output from the verification:
KERNEL_VERSION: 3.10.0-1160.el7.x86_64
DOCKER_VERSION: 20.10.24
OS: Linux
CGROUPS_CPU: enabled
CGROUPS_CPUACCT: enabled
CGROUPS_CPUSET: enabled
CGROUPS_DEVICES: enabled
CGROUPS_FREEZER: enabled
CGROUPS_MEMORY: enabled
CGROUPS_PIDS: enabled
CGROUPS_HUGETLB: enabled[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.24. Latest validated version: 19.03[WARNING SystemVerification]: failed to parse kernel config: unable to load kernel module: "configs", output: "modprobe: FATAL: Module configs not found.\n", err: exit status 1
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
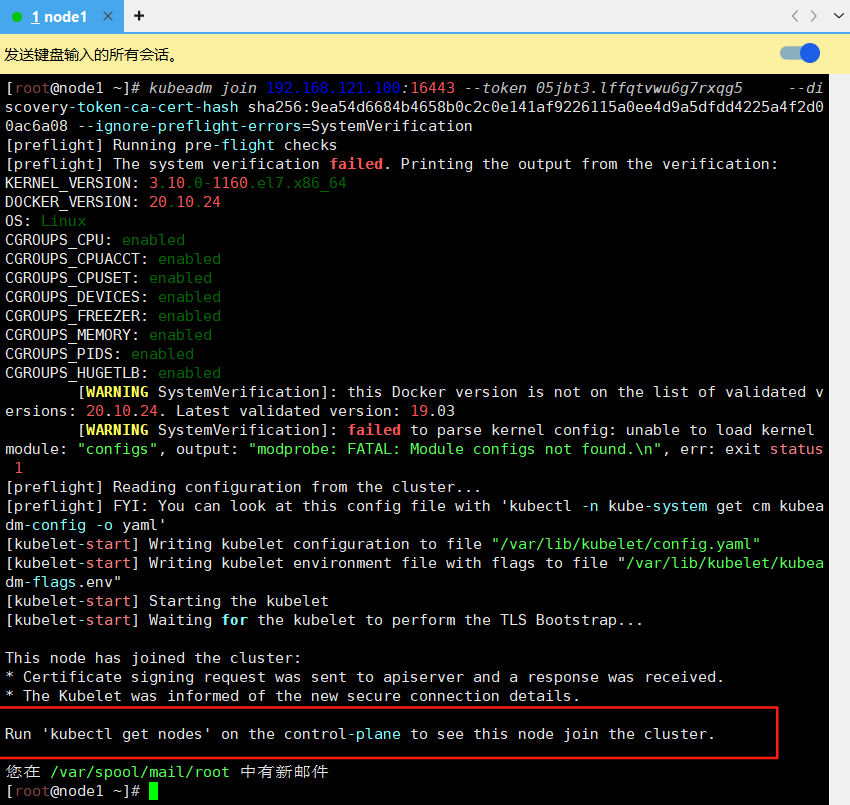 看到上面说明 node1 节点已经加入到集群了,充当工作节点
看到上面说明 node1 节点已经加入到集群了,充当工作节点
在 master1 上查看集群节点状况:
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 19m v1.20.6
master2 NotReady control-plane,master 4m42s v1.20.6
node1 NotReady <none> 71s v1.20.6

可以看到 node1 的 ROLES 角色为空,<none>就表示这个节点是工作节点。
可以把 node1 的 ROLES 变成 work,按照如下方法:
[root@master1 ~]# kubectl label node node1 node-role.kubernetes.io/worker=worker
node/node1 labeled
您在 /var/spool/mail/root 中有新邮件
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 20m v1.20.6
master2 NotReady control-plane,master 5m52s v1.20.6
node1 NotReady worker 2m21s v1.20.6
上面状态都是 NotReady 状态,说明没有安装网络插件
[root@master1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7f89b7bc75-9dz6q 0/1 Pending 0 20m
coredns-7f89b7bc75-gcdgm 0/1 Pending 0 20m
etcd-master1 1/1 Running 0 20m
etcd-master2 1/1 Running 0 6m7s
kube-apiserver-master1 1/1 Running 0 20m
kube-apiserver-master2 1/1 Running 1 6m28s
kube-controller-manager-master1 1/1 Running 1 20m
kube-controller-manager-master2 1/1 Running 0 6m28s
kube-proxy-4vs4k 1/1 Running 0 6m29s
kube-proxy-n996l 1/1 Running 0 20m
kube-proxy-r8ft5 1/1 Running 0 2m58s
kube-scheduler-master1 1/1 Running 1 20m
kube-scheduler-master2 1/1 Running 0 6m29s
是 pending 状态,这是因为还没有安装网络插件,等到下面安装好网络插件
之后这个 cordns 就会变成 running 了
8 安装 kubernetes 网络组件-Calico
上传 calico.yaml 到 master1 上,使用 yaml 文件安装 calico 网络插件 。
calico.yaml
链接: https://pan.baidu.com/s/15dOU4IN7GtBbueK-3Ro4Cw?pwd=3qrm 提取码: 3qrm
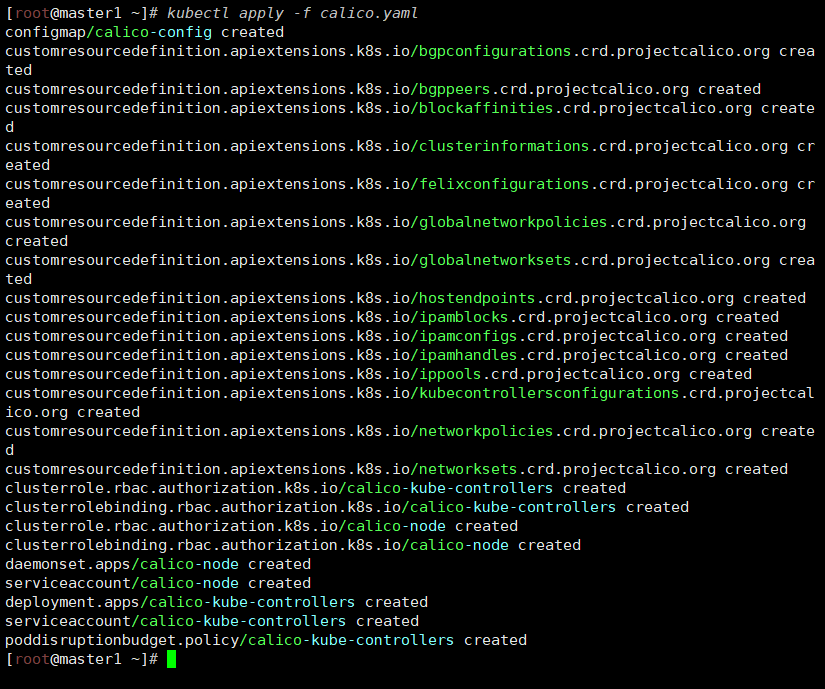
[root@master1 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6949477b58-w7knf 1/1 Running 0 33s
calico-node-5fs4d 1/1 Running 0 32s
calico-node-d4zqq 1/1 Running 0 32s
calico-node-x72kl 1/1 Running 0 32s
coredns-7f89b7bc75-9dz6q 1/1 Running 0 23m
coredns-7f89b7bc75-gcdgm 1/1 Running 0 23m
etcd-master1 1/1 Running 0 23m
etcd-master2 1/1 Running 0 9m12s
kube-apiserver-master1 1/1 Running 0 23m
kube-apiserver-master2 1/1 Running 1 9m33s
kube-controller-manager-master1 1/1 Running 1 23m
kube-controller-manager-master2 1/1 Running 0 9m33s
kube-proxy-4vs4k 1/1 Running 0 9m34s
kube-proxy-n996l 1/1 Running 0 23m
kube-proxy-r8ft5 1/1 Running 0 6m3s
kube-scheduler-master1 1/1 Running 1 23m
kube-scheduler-master2 1/1 Running 0 9m34s
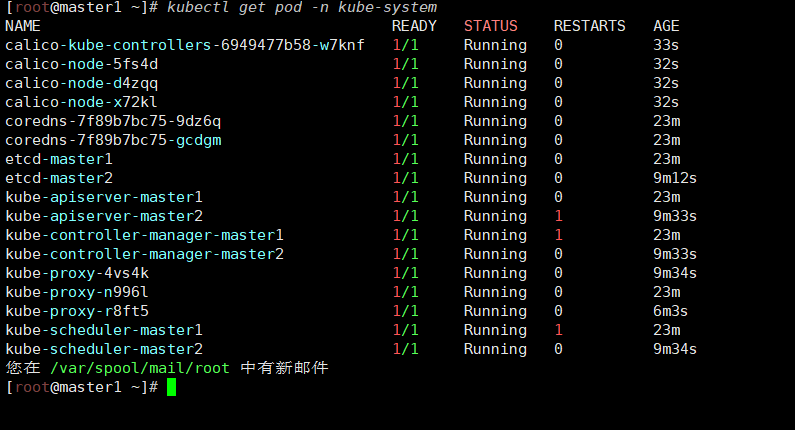
coredns-这个 pod 现在是 running 状态,运行正常
再次查看集群状态
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 24m v1.20.6
master2 Ready control-plane,master 10m v1.20.6
node1 Ready worker 6m53s v1.20.6
STATUS 状态是 Ready,说明 k8s 集群正常运行了
9 测试在 k8s 创建 pod 是否可以正常访问网络
把 busybox-1-28.tar.gz 上传到 node1 节点,手动解压
busybox-1-28.tar.gz
链接: https://pan.baidu.com/s/1cDZOkzfkYpbrwa5q_OmauA?pwd=bmi3 提取码: bmi3
[root@node1 ~]# docker load -i busybox-1-28.tar.gz
432b65032b94: Loading layer 1.36MB/1.36MB
Loaded image: busybox:1.28
[root@master1 ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
If you don't see a command prompt, try pressing enter.
/ # ping baidu.com
PING baidu.com (182.61.244.181): 56 data bytes
64 bytes from 182.61.244.181: seq=0 ttl=127 time=52.100 ms
64 bytes from 182.61.244.181: seq=1 ttl=127 time=52.229 ms
64 bytes from 182.61.244.181: seq=2 ttl=127 time=51.160 ms
通过上面可以看到能访问网络,说明 calico 网络插件已经被正常安装了
10 测试 k8s 集群中部署 tomcat 服务
把 tomcat.tar.gz 上传到 xianchaonode1,手动解压
tomcat.tar.gz等3个文件
链接: https://pan.baidu.com/s/1Ff6wFkDscJE_L49dqgDjSg?pwd=hcta 提取码: hcta
[root@node1 ~]# docker load -i tomcat.tar.gz
f1b5933fe4b5: Loading layer 5.796MB/5.796MB
9b9b7f3d56a0: Loading layer 3.584kB/3.584kB
edd61588d126: Loading layer 80.28MB/80.28MB
48988bb7b861: Loading layer 2.56kB/2.56kB
8e0feedfd296: Loading layer 24.06MB/24.06MB
aac21c2169ae: Loading layer 2.048kB/2.048kB
Loaded image: tomcat:8.5-jre8-alpine
[root@master1 ~]# kubectl apply -f tomcat.yaml
pod/demo-pod created
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-pod 1/1 Running 0 6s
[root@master1 ~]# kubectl apply -f tomcat-service.yaml
service/tomcat created
[root@master1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 30m
tomcat NodePort 10.10.46.17 <none> 8080:30080/TCP 6s
在浏览器访问 node1 节点的 ip:30080 即可请求到浏览器
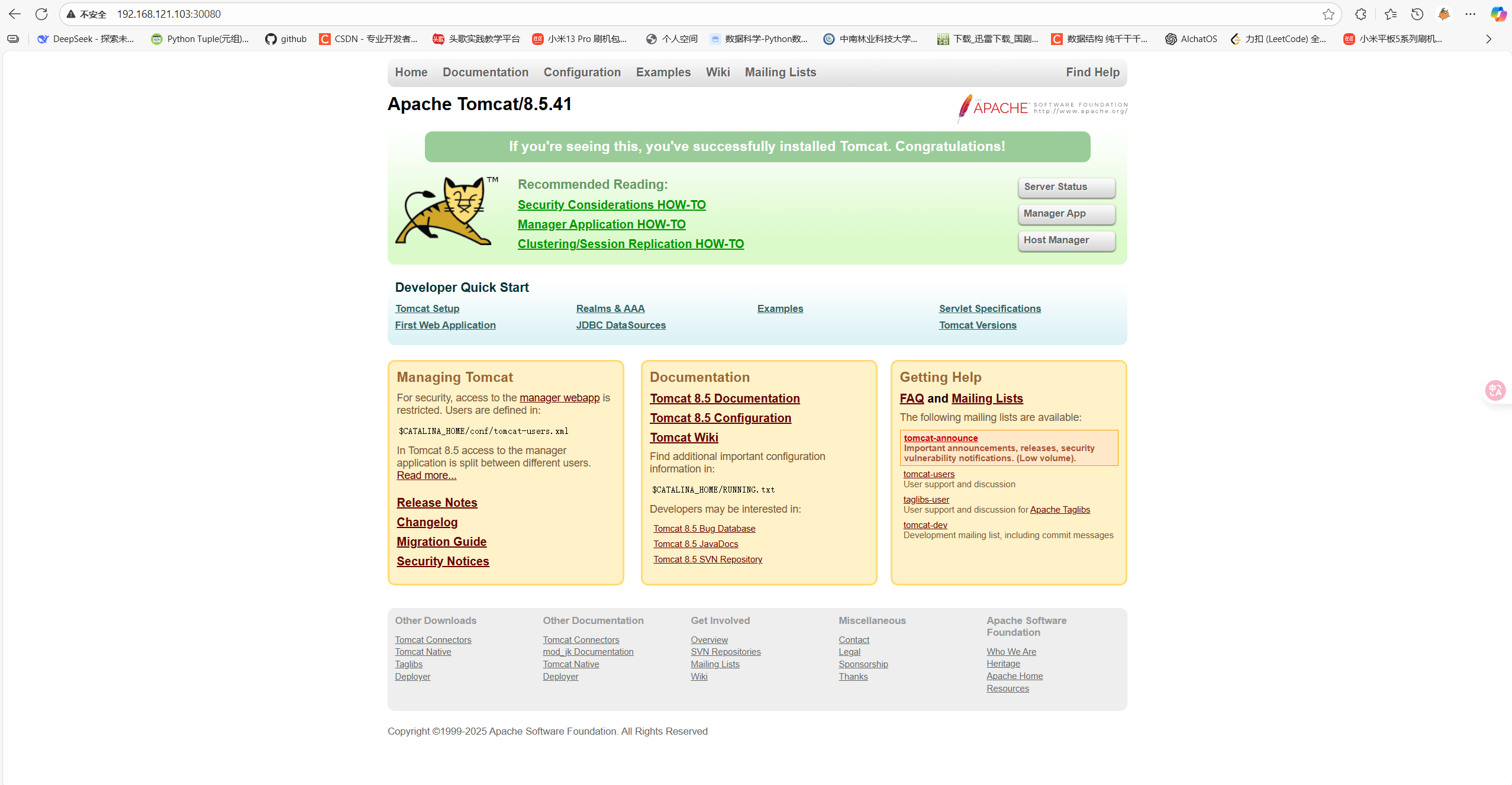
11 测试 coredns 是否正常
[root@master1 ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes.default.svc.cluster.local
Server: 10.10.0.10
Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.localName: kubernetes.default.svc.cluster.local
Address 1: 10.10.0.1 kubernetes.default.svc.cluster.local
/ # nslookup tomcat.default.svc.cluster.local
Server: 10.10.0.10
Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.localName: tomcat.default.svc.cluster.local
Address 1: 10.10.46.17 tomcat.default.svc.cluster.local