使用Pytest进行接口自动化测试(三)
(一)YAML
之前在项目中,我们也是用过YAML来做配置文件,他用于以人类可读的形式存储信息,
特点: 一种简易的可读语言,用于人和计算机交换数据
通常用来存储配置信息
跟python类似,有着严格的缩进
跟其他配置文件不一样,没有多余的符号("",{})等
注: 上篇博客我们还说了.ini文件,与他不同的是,YAML是区分大小写的,且严格遵循缩进
他的文件后缀名.yaml或者.yml YAML支持多种数据类型,具体有点多这里不详细列出
我们有很多工具可以帮我们把各种格式的文件转为yml格式的文件
JSON 转 YAML 工具 | 简化数据格式转换 - 嘉澍工具
YAML的使用
我们需要先下载YAML
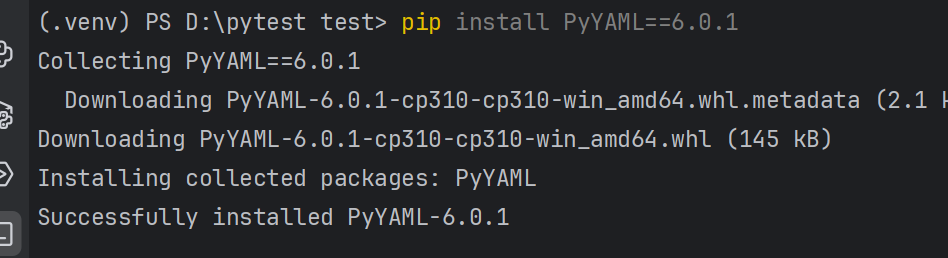 下载完成后,我们就可以手动写yml文件,或者使用命令来写yml文件了
下载完成后,我们就可以手动写yml文件,或者使用命令来写yml文件了
import yaml
#追加写入文件(f即为打开的文件)
def wirte_yaml(filename,data):with open(filename,encoding="utf-8",mode="a")as f:yaml.safe_dump(data,stream=f)
#读文件
def read_yaml(filename,key):with open(filename,encoding="utf-8",mode="r")as f:data=yaml.safe_load(f)return data[key]
#清空
def clear_yaml(filename):with open(filename,encoding="utf-8",mode="w")as f:f.truncate()
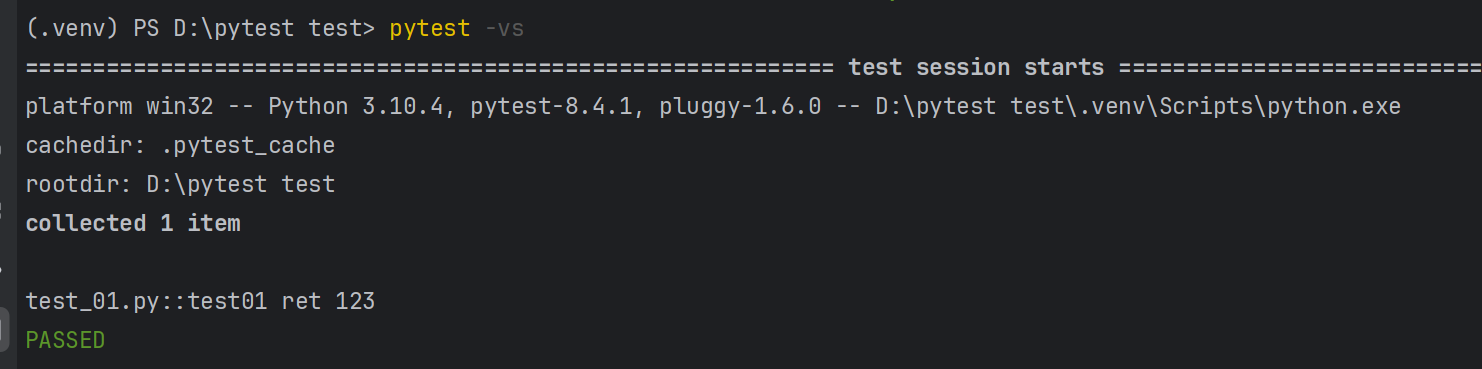
def test01():data={"string":"123"}wirte_yaml("pytest.yml",data)ret=read_yaml("pytest.yml","string")print("ret",ret)clear_yaml("pytest.yml")
yaml.safe_dump:这个函数会将python对象转为yml格式再给写入到yml文件中
yml.safe_load:这个函数会将yml格式对象转换为python对象
文件名.truncate:这个函数用来清空文件中数据
结果如下
(二)JSON Schema
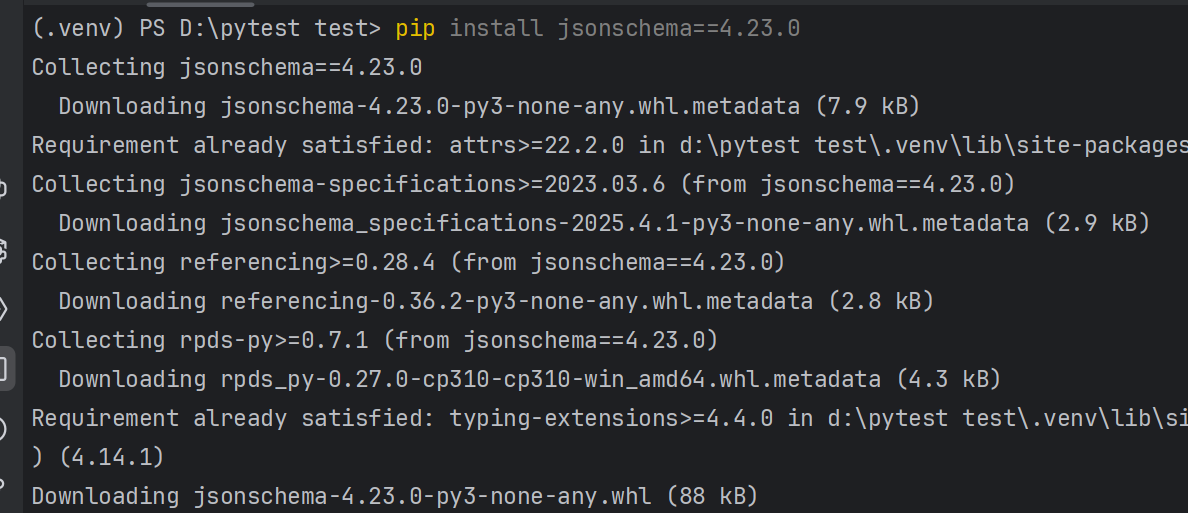
用来校验json是否符合我们的预期
还是需要我们手动安装
那具体是如何帮我们验证json格式是否符合预期?
这是我们JSON的一个代码块
 我们来看他对应的jsonSchema代码块
我们来看他对应的jsonSchema代码块
 我们分别再来看一下Json Schema的属性都是什么
我们分别再来看一下Json Schema的属性都是什么
首先就是type,这个用来指定json传输的类型
-
可以是字符串(string)、数字(number)、整数(integer)、对象(object)、数组(array)、布尔值(boolean)或null。
-
也可以是一个数组,表示允许多种类型。例如:
"type": ["string", "null"]表示可以是字符串或null
再来看required,(用于object类型)这个里面表示我们下面的properties哪些是必须要有的
properties 同样用于object类型,这里面表示object里面的键和对应值的数据类型
我们可以使用工具,将JSON转为Json Schema
但是这个工具可能会出错(容易把布尔类型,转成字符串),所以需要我们再校验一遍
在线JSON转Schema工具 - ToolTT在线工具箱
我们自己写个代码,来看一下
from jsonschema.validators import validate
#不要忘记导入jsonschema
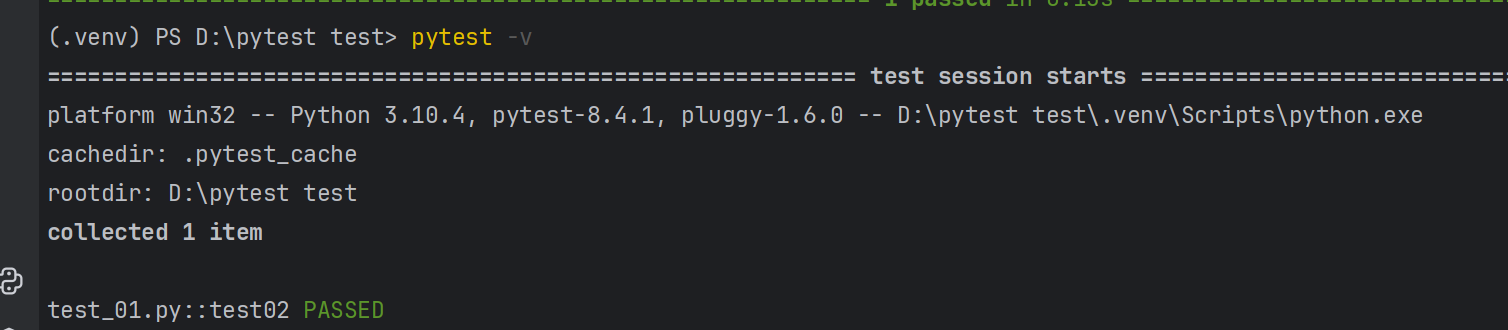
def test02():json01={"code":"SUCCESS","error":"","data":False}jsonschema={"type": "object","required": [],"properties": {"code": {"type": "string"},"msg": {"type": "string"},"data": {"type": "boolean"}}
}validate(json01,jsonschema)然后我们来看结果
我们properties是一个验证关键字,除了要写json对应的键和值的类型外,我们也可以指定一些其他的值,比如
最大最小值
:minimum 和 maximum:指定数值的最小值和最大值
exclusiveMinimum 和 exclusiveMaximum:指定数值必须严格大于或在小于某个值
这里举一个简单的例子
def test02():json01={"code":"SUCCESS","num":-1,"data":False}jsonschema={"type": "object","required": [],"properties": {"code": {"type": "string"},"num": {"type": "number","minimum": 0},"data": {"type": "boolean"}}
}比如我把num设定为-1,但在jsonschema中,我把num最小数值设定为0,这样就会报错

这里来说一下minimum和exclusiveMinimum的区别(maximum同理)
在Draft6之后
minimum就是我们常说的<=,exclusiceMinimum是<,且值都可以为数字
在Draft4之前
exclusiveMinimum必须是布尔值
需要与 minimum配合使用
pattrern字符串特殊校验
pattern使用正则表达是来验证字符串是否符合特定的模式
具体正则表达式怎么写,我们同样可以使用生成器
正则表达式生成器,常用正则表达式在线生成
数组约束
minItems和maxItems:指定数组的最小和最大长度
uniqueItems:确保数组中的元素是唯一的
true代表数组中不可以有重复元素
items:定义数组中每个元素的类型和约束
{"type": "array","items": {"type": "number","minimum": 0}
}这里定义数组中所有的元素都为number
{"type": "array","items": [{"type": "string"}, // 第一个元素必须是字符串{"type": "number"}, // 第二个元素必须是数字{"type": "boolean"} // 第三个元素必须是布尔值],"additionalItems": false // 禁止额外元素
}也可以使用元组模式定义每个位置元素
contains:必须包含特定元素
{"type": "array","contains": {"type": "string","pattern": "^admin$"}
}对象约束
minProperties和maxProperties:指定对象的最小和最大属性数量
additionalProperties:控制是否允许对象中出现在在properties中未定义的额外属性,默认为True
propertyNames- 约束属性名:通过正则表达式约束properties中属性名称
{"type": "object","propertyNames": {"pattern": "^[a-z][a-z0-9_]*$","maxLength": 20}
}必需属性
通过required关键字,Json Schema指定哪些属性是必须的,如果JSON实例中缺少这些必要属性,验证就会失败
{"type": "object","properties": {"name": { "type": "string" },"email": { "type": "string" }
},"required": ["name", "email"]
}依赖关系
dependentRequired可以定义属性之间的依赖关系 如果一个属性存在,则必须存在另一个属性
{"type": "object","properties": {"creditCard": { "type": "string" },"billingAddress": { "type": "string" }},"dependentRequired": {"creditCard": ["billingAddress"]}
}这就表示我们的creditCard依赖billingAddress当有creditCard时,就一定要有billingAddress
logging日志模块
logging是Python库中的一个模块,提供了灵活的日志功能
接下来我们看一下logging是怎样使用的
import logging# 配置日志:设置级别和格式
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 创建日志记录器
logger = logging.getLogger(__name__)# 记录不同级别的日志
logger.debug('这是一条调试信息')
logger.info('这是一条普通信息')
logger.warning('这是一条警告信息')
logger.error('这是一条错误信息')
logger.critical('这是一条严重错误信息'设置日志文件格式我们也可以这样写

handler.setFormatter(formatter)将创建的格式器对象设置到处理器上,这样处理器在接受到日志信息时,就会用这个格式器来格式化日志信息

获取日志记录器:logging.getlogger(__name__)获取一个日志记录器对象,name为当前模块的名称,通过不同文件名称来区分日志,有助于在大型项目中区分不同模块日志
设置日志级别:logger.setlevel()将日志记录器设置级别,当高于或者等于这个级别的日志就会记录
![]()
创建文件处理器:logging.fileHandler(filename="文件名")创建文件处理器,把日志信息写入到这个文件中
添加文件处理器:logger.addHandler(handler)将文件处理器添加到日志记录器中
生成测试报告allure
Allure Report由一个框架适配器和allure命令行工具组成,是一个开源工具,用于可视化的查看运行结果(测试报告)
还是需要我们手动的去下载
下载链接: https://github.com/allure-framework/allure2/releases/download/2.30.0/allure-2.30.0.zip
下载后 我们如果想在pycharm中使用,我们需要配置环境变量
找到对应bin文件,然后找到电脑的环境变量
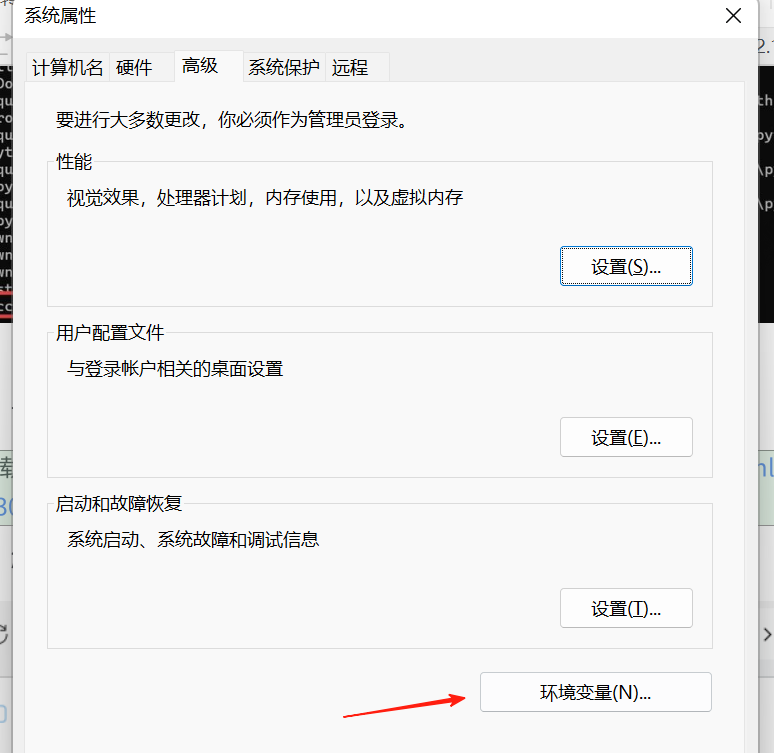
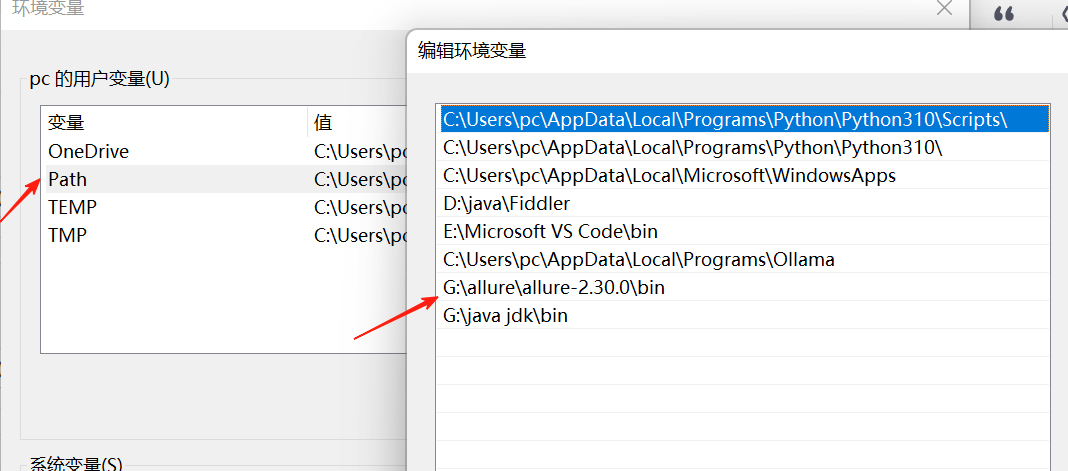
注:allure是一个基于Java的工具,所以我们需要先配置java环境变量,步骤一样的
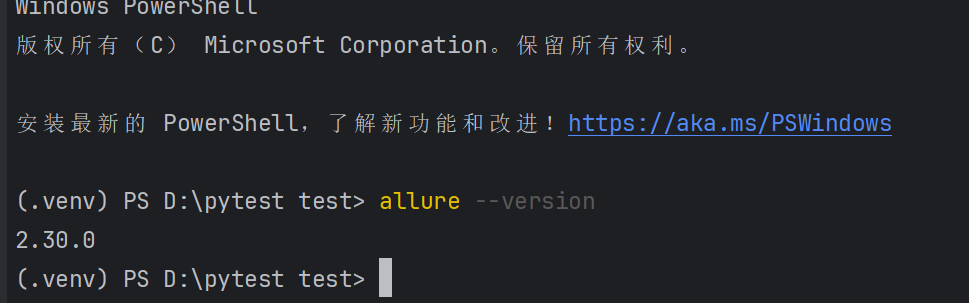
配置好后,如果我们想验证一下,我们可以使用allure --version

若出现我们在cmd中可以用上述命令打印版本,但是pycharm控制台提示找不到,则需要我们手动修改pycharm命令环境
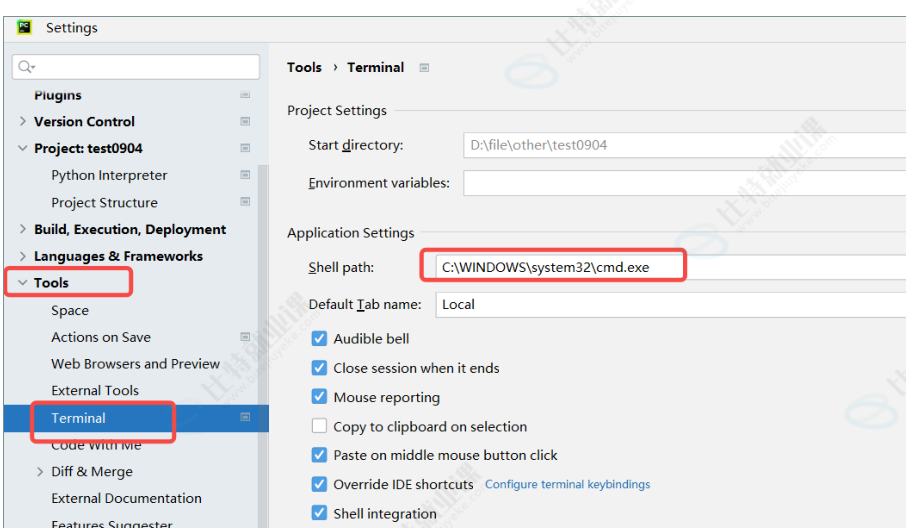
保存后重启pycharm即可
安装好后,我们来看他的使用
首先我们要运行自动化,并指定测试报告的放置路径
pytest --alluredir=results_dir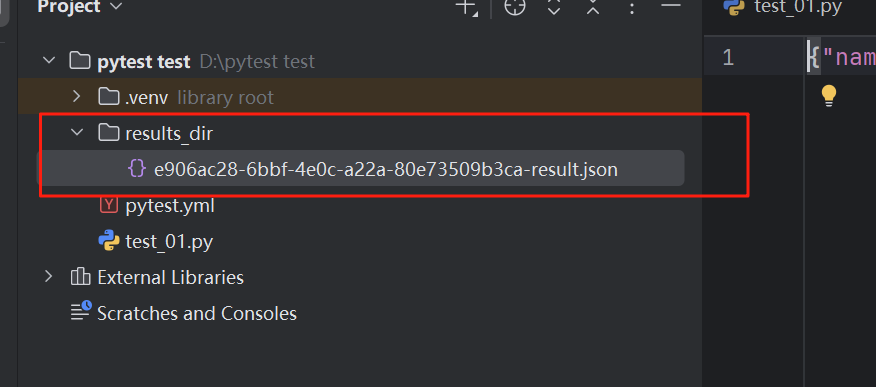
此时我们测试报告就已经生成了。那么如何查看测试报告呢?
方法1:
allure serve 生成的测试文件地址这个测试文件地址,可以是相对地址也可以是绝对地址(绝对地址要加“”,相对不用加)这边建议写绝对地址,不容易错
我们也可以指定端口号
allure serve --port 8787 .\allure-results\还有清除上一次生成的测试报告
allure serve .\allure-results\ --clean-alluredir执行后,就会给我们跳出Web版的测试报告
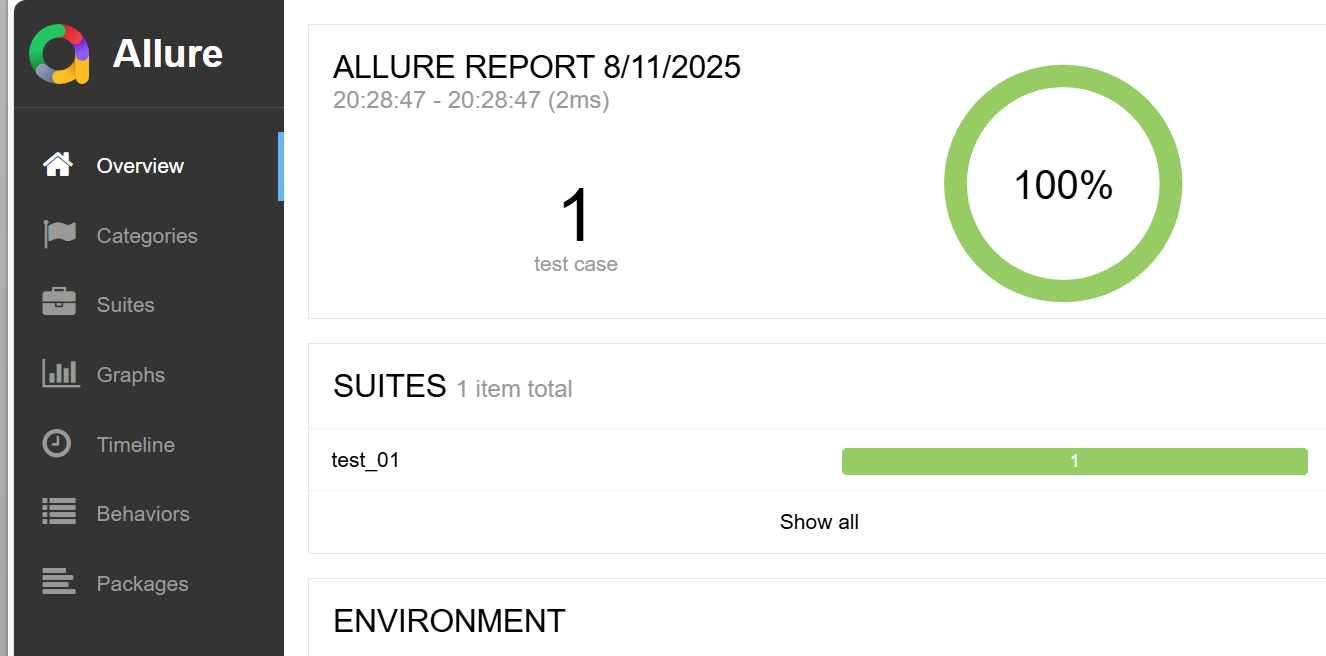
但是通过这样生成的测试报告,当我们关闭网站 ctrl+c后就会关闭无法再次打开,所以我们可以选择使用持续集成(CI)工具,或者本地持续运行的服务器或者我们生成静态的测试报告
通过
allure generate .\allure-results\ -o .\allure-report
--cleanallure generate是用来生成我们的测试报告
.\allure-results\`:这是测试结果所在的目录。
-o --clean:这个选项表示在生成新报告之前,先清理输出目录(即.\allure-report)。.\allure-report:-o是--output的缩写,用于指定生成的HTML报告的输出目录。