【CV 目标检测】①——目标检测概述
一、目标检测概述
1.目标检测
-
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标,并确定它们的类别(分类任务)和位置(回归任务)
-
目标检测中能检测出来的物体取决于当前任务(数据集)需要检测的物体有哪些
-
目标检测的位置信息一般有两种格式(以图片左上角为原点(0,0))
-
极坐标表示:xmin, ymin, xmax, ymax分别代表x, y坐标的最小值,最大值(左上角坐标<右下角坐标)
图像坐标系原点在左上角,把图像看作ndarray,行对应着y,列对应着x
-
中心点坐标:x_center, y_center, w, h分别表示目标检测框的中心点坐标和目标检测框的宽,高
-
2.开源数据集
经典的目标检测数据集有两种,PASCAL VOC数据集和MS COCO数据集
(1)PASCAL VOC数据集
PASCAL VOC是目标检测领域的经典数据集。PASCAL VOC包含约10000张带有边界框的图片用于训练和验证。PASCAL VOC数据集是目标检测问题的一个基准数据集,很多模型都是在此数据集上得到的,常用的是VOC2007和VOC2012两个版本的数据集,共20个类别,分别是:
- Person:person
- Animal:bird,cat,cow,horse,sheep
- Vehicle:aeroplane,bicycle,boat,bus,car,motorbike,train
- Indoor:bottle,chair,dining table,potted plant,soft,tv/monitor
下载地址:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
目标位置信息 解释:
- 0 不可用于分割
- Frontal 物体在图片中的位置是 前面
- Unspecified 正常拍摄 Right 物体位于右侧
- 1 物体是截断的
- 0 不是 难以识别的物体(若为1,则是人难以识别的物体)
(2)MS COCO数据集
- 全称是Microsoft Common Objects in Context。COCO数据集是一个大型的丰富的物体检测,分割和字幕数据集。这个数据集以场景理解为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定,图像包括91类目标,328000影像和2500000个label。目前为止目标检测的最大数据集,提供的类别有80类,超过33万张图片,其中20万张有标注,整个数据集中个体的数目超过150万个。
- COCO数据集的标签文件标记了每个segmentation+bounding box的精确坐标。其精度均为小数点后两位,一个目标的标签示意如下:

- COCO数据集的目标个数相对VOC数据集来说 要小一点
- COCO数据集使用json文件标注目标
- COCO数据集精细标注,即先 分割,然后再进行框选标注,总共标注了80个类别的目标
3.常用的评价指标
(1)IOU
在目标检测算法中,IOU(intersection over union,交并比)是目标检测算法中用来评价2个矩形框之间相似度的指标
IOU=两个矩形框相交的面积两个矩形框相并的面积IOU = \frac{两个矩形框相交的面积}{两个矩形框相并的面积}IOU=两个矩形框相并的面积两个矩形框相交的面积
- IOU—>1,两个矩形框越相似;IOU—>0,两个矩形框越不相似。
- 当IOU达到0.5,则检测效果还可以;当IOU达到0.7,则检测效果还不错。
实现方法:
def Iou(box1, box2, wh = False):if wh = False: # 使用极坐标表示xmin1, ymin1, xmax1, ymax1 = box1xmin2, ymin2, xmax2, ymax2 = box2else: # 使用中心点表示# 第一个框左上角坐标xmin1, ymin1 = int(box1[0] - box1[2]/2.0), int(box1[1] - box1[3]/2.0)# 第一个框右下角坐标xmax1, ymax1 = int(box1[0] + box1[2]/2.0), int(box1[1] + box1[3]/2.0)# 第二个框左上角坐标xmin2, ymin2 = int(box2[0] - box2[2]/2.0), int(box2[1] - box2[3]/2.0)# 第二个框右下角坐标xmax2, ymax2 = int(box2[0] + box2[2]/2.0), int(box2[1] + box2[3]/2.0)# 获取矩形框交集对应的左上角和右下角的坐标(intersection)xx1 = np.max([xmin1, xmin2])yy1 = np.max([ymin1, ymax2])xx2 = np.min([xmax1, xmax2])yy2 = np.min([ymax1, ymax2])# 计算两个矩形框的面积area1 = (xmax1 - xmin1)*(ymax1 - ymin1)area2 = (xmax2 - xmin2)*(ymax2 - ymin2)# 计算交集面积inter_area = (np.max([0, xx2 - xx1]))*(np.max([0, yy2 - yy1])) # 若xx2 - xx1小于0,则使最终结果等于0# 计算交并比iou = inter_area / (area1 + area2 - inter_area + 1e-6)return iou
示例:
import matplotlib.pyplot as plt
import matplotlib.patches as patches # 绘制矩形框
# 真实框和预测框
True_bbox, predict_bbox = [100, 35, 398, 400], [40, 150, 355, 398]
# bbox是bounding box的缩写
img = plt.imread('dog.jepg')
fig = plt.imshow(img)
# 将边界框(左上x,左上y,右下x,右下y)格式转换成为matplotlib格式:((左上x,左上y),宽,高)
# 真实框绘制
fig.axes.add_patch(plt.Rectangle(xy = (True_bbox[0], True_bbox[1]), width = True_bbox[2] - True_bbox[0], height = True_bbox[3] - True_bbox[1], fill = False, edgecolor = 'blue',linewidth = 2)
)
# 预测框绘制
fig.axes.add_patch(plt.Rectangle(xy = (predict_bbox[0], predict_bbox[1]), width = predict_bbox[2] - predict_bbox[0], height = predict_bbox[3] - predict_bbox[1], fill = False, edgecolor = 'red',linewidth = 2)
)# 计算iou
Iou(True_bbox, predict_bbox)
(2)mAP(Mean Average Precision)
目标检测问题中的每个图片都可能包含一些不同类别的物体,需要评估模型的物体分类和定位性能(只有物体分类:准确率;只有定位性能:IOU)。因此,用于图像分类问题的标准指标precision不能直接应用于此
A、mAP计算方法
TP,FP,FN,TN
- True Positive(TP):IOUIOUIOU(IOUthresholdIOU_{threshold}IOUthreshold一般取0.5)的检测框数量(同一Ground Truth 只计算一次)
- False Positive(FP):IOU≤IOUthresholdIOU \le IOU_{threshold}IOU≤IOUthreshold的检测框的数量,或者检测到同一个GT的多余检测框的数量
- False Negative(FN):没有检测到的GT数量
- True Negative(TN):在MAP评价指标中不会使用到
查准率,查全率
- 查准率(
Precision):TPTP+FP\frac{TP}{TP+FP}TP+FPTP - 查全率(
Recall):TPTP+FN\frac{TP}{TP+FN}TP+FNTP
P-R曲线
查准率和查全率两者绘制的曲线即为P-R曲线
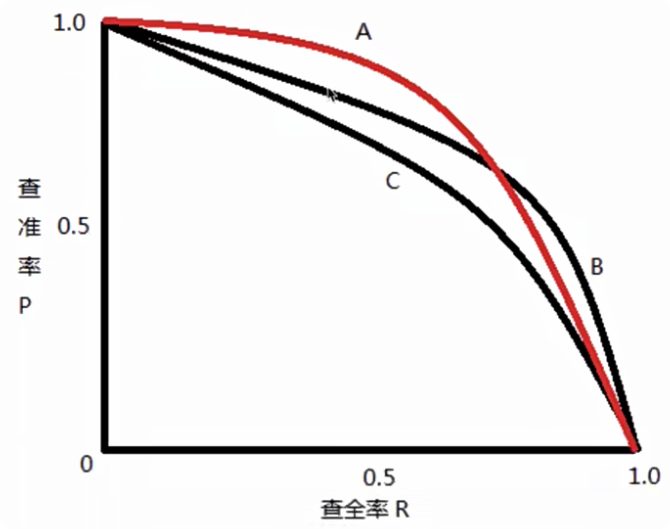
AP(average precision)
AP是PR曲线下的面积
mAP
mAP是多个分类任务的AP的平均值
B、mAP计算示例
其中all detections代表所有预测框的数量,all ground truths代表所有GT的数量
Precision=TPTP+FP=TPalldetectionsPrecision = \frac{TP}{TP+FP}=\frac{TP}{all\,detections}Precision=TP+FPTP=alldetectionsTP
Recall=TPTP+FN=TPallgroundtruthsRecall = \frac{TP}{TP+FN} = \frac{TP}{all\,ground\,truths}Recall=TP+FNTP=allgroundtruthsTP
AP是计算某一类P-R曲线下的面积,mAP则是计算所有类别P-R曲线下面积的平均值
解释:
- 当一个GT有多个预测边框时,则认为其中IOU最大的并且IOU≥0.3IOU \ge 0.3IOU≥0.3的标记为TP,其余的均标记为FP
- IOU—>1,则预测边框与GT越相似;反之,则越不相似
先计算出P-R曲线上各个点的坐标(注意:需要根据置信度从大到小排序所有的预测框)
- ACC TP:从第一个检测结果到当前行的所有 TP 的总和,用于计算累积的精确率(Precision)和召回率(Recall)
- ACC FP:从第一个检测结果到当前行的所有 FP 的总和,同样用于计算累积的精确率和召回率
然后就可以绘制出P-R曲线
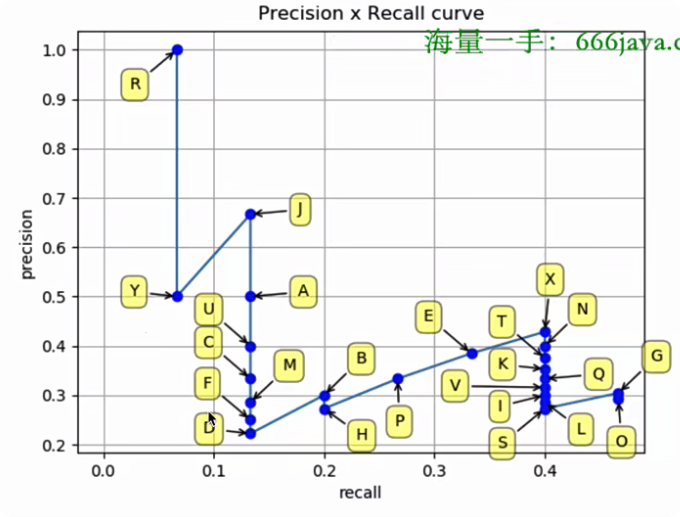
得到P-R曲线之后就可以计算AP(P-R曲线下的面积),有两种方法:
- 在VOC2010以前,只需要选取当Recall≥0,0.1,0.2,…,1Recall \ge 0, 0.1, 0.2,\dots,1Recall≥0,0.1,0.2,…,1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值,取11个点[0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1][0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1][0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1]的插值所得
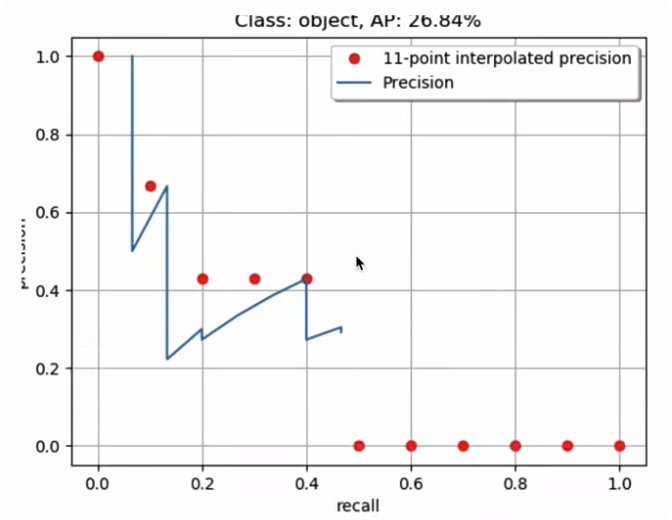
得到一个类别的AP结果如下:
AP=111∑r∈0,0.1,0.2,⋯,1ρinterp(r)AP = \frac{1}{11}\sum_{r \in 0, 0.1,0.2, \cdots, 1} \rho_{interp}(r)AP=111∑r∈0,0.1,0.2,⋯,1ρinterp(r)
AP=111(1+0.6666+0.4285+0.4285+0.4285+0+0+0+0+0+0)AP = \frac{1}{11}(1+0.6666+0.4285+0.4285+0.4285+0+0+0+0+0+0)AP=111(1+0.6666+0.4285+0.4285+0.4285+0+0+0+0+0+0)
AP=26.84%AP = 26.84\%AP=26.84%
要计算mAP,就把所有类别的mAP计算出来,然后取平均即可
- 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取大于等于这些Recall值时对应的Precision最大值,如下图所示:
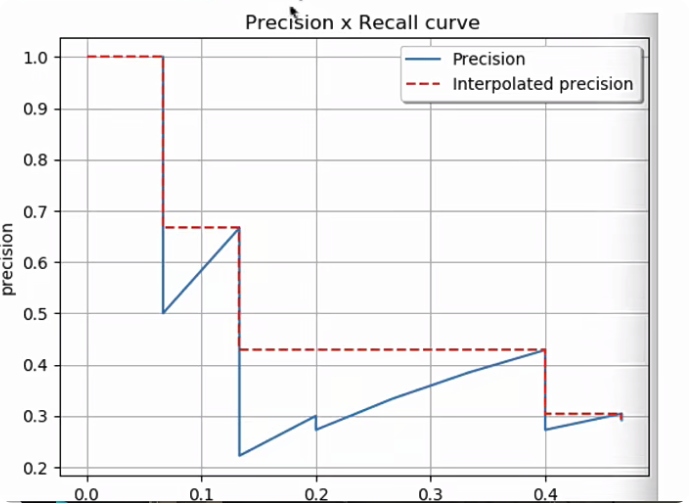
然后就可以计算PR曲线下面积作为AP值:
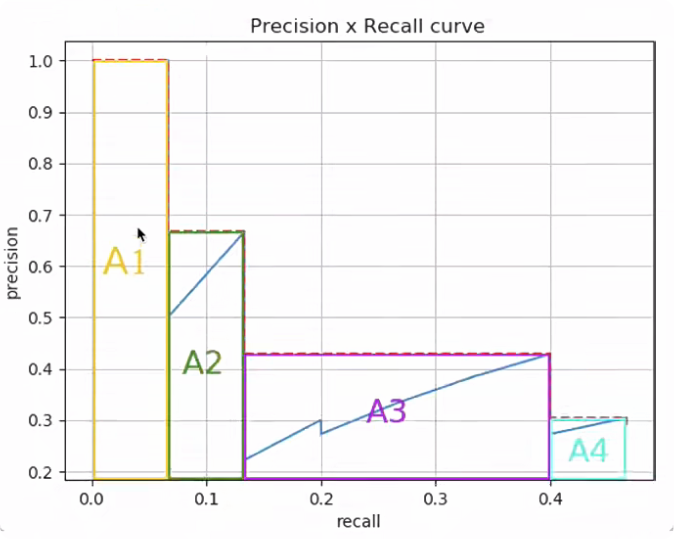
AP=A1+A2+A3+A4AP = A_1+A_2+A_3+A_4AP=A1+A2+A3+A4
A1=(0.0666−0)×1=0.0666A_1 = (0.0666-0)\times1= 0.0666A1=(0.0666−0)×1=0.0666
A2=(0.1333−0.0666)×0.6666=0.04446222A_2 =(0.1333-0.0666)\times0.6666 = 0.04446222A2=(0.1333−0.0666)×0.6666=0.04446222
A3=(0.4−0.1333)×0.4285=0.11428095A_3 = (0.4-0.1333)\times0.4285 = 0.11428095A3=(0.4−0.1333)×0.4285=0.11428095
A4=(0.4666−0.4)×0.3043=0.02026638A_4 = (0.4666-0.4)\times0.3043=0.02026638A4=(0.4666−0.4)×0.3043=0.02026638
AP=0.0666+0.04446222+0.11428095+0.02026638AP = 0.0666+0.04446222+0.11428095+0.02026638AP=0.0666+0.04446222+0.11428095+0.02026638
AP=0.24560955AP = 0.24560955AP=0.24560955
AP=24.56%AP = 24.56\%AP=24.56%