云原生环境Prometheus企业级监控
目录
- 基于kubernetes的Prometheus 介绍
- 1:环境简介
- 2:监控流程
- 3:Kubernetes监控指标
- Prometheus安装
- 1:安装
- 2:修改grafana的service的类型
- 3:访问grafana
- 4:修改Prometheus的service类型
- 5:访问Prometheus
- 配置Grafana Dashbord
- 1:导入模板
- 监控Mysql数据库
- 1:安装一个mysql
- 2:配置mysql exporter采集mysql监控文件
- 3:配置ServiceMonitor
- 对钉钉报警
- 1:部署Dingtalk
- 2:启动服务
- 3:配置Alertmanager
- 4:访问Alertmanager页面
- 解决ServiceMonitor找不到主机问题
- 1:查看target
- 2:查看ServiceMonitor是否创建成功
- 3:解决kube-controller-manager不监控
基于kubernetes的Prometheus 介绍
1:环境简介
node-exporter + prometheus + grafana是一套非常流行的 Kubernetes 监控方案。它们的功能
如下:
node-exporter:节点级指标导出工具,可以监控节点的 CPU、内存、磁盘、网络等指标,并暴露Metrics 接口。
Prometheus:时间序列数据库和监控报警工具,可以抓取 Cadvisor 和 node-exporter 暴露的Metrics 接口,存储时序数据,并提供 PromQL 查询语言进行监控分析和报警。
Grafana:图表和 Dashboard 工具,可以査询 Prometheus 中的数据,并通过图表的方式直观展示Kubernetes 集群的运行指标和状态。
2:监控流程
(1)在 Kubernetes集群的每个节点安装 Cadvisor和node-exporter,用于采集容器和节点级指标数据。(2)部署 Prometheus,配置抓取 Cadvisor 和 node-exporter 的Metrics 接口,存储 containers 和nodes 的时序数据。
(3)使用 Grafana 构建监控仪表盘,选择 Prometheus 作为数据源,编写 PromQL 査询语句,展示 K8S 集群的 CPU 使用率、内存使用率、网络流量等监控指标。
根据监控结果,可以设置 Prometheus 的报警规则,当监控指标超过阈值时发送报警信息。这套方案能(4)够全面监控 Kubernetes 集群的容器和节点,通过 Metrics 指标和仪表盘直观反映集群状态,并实现自动报警,非常适合 K8S 环境下微服务应用的稳定运行。
具体实现方案如下:
node-exporter:在每个节点也作为 Daemonset 运行,采集节点 Metrics。
Prometheus:部署Prometheus operator 实现,作为 Deployment 运行,用于抓取 Metrics 和
报警。
Grafana:部署 Grafana Operator 实现,用于仪表盘展示。
3:Kubernetes监控指标
K8S 本身的监控指标:
CPU 利用率:包括节点 CPU 利用率、Pod CPU 利用率、容器 CPU 利用率等,用于监控 CPU 资源使用情况。
内存利用率:包括节点内存利用率、Pod 内存利用率、容器内存利用率等,用于监控内存资源使用情况。
网络流量:节点网络流量、Pod 网络流量、容器网络流量,用于监控网络收发包大小和带宽利用率磁盘使用率:节点磁盘使用率,用于监控节点磁盘空间使用情况。
Pod 状态:Pod 的 Running、waiting、succeeded、Failed 等状态数量,用于监控 Pod 运行状态。
节点状态:节点的 Ready、NotReady 和 Unreachable 状态数量,用于监控节点运行状态
容器重启次数:单个容器或 Pod 内所有容器的重启次数,用于监控容器稳定性。
API 服务指标:Kubernetes API Server 的请求 LATENCY、请求 OPS、错误码数量等,用于监控API Server 性能。
集群组件指标:etcd、kubelet、kube-proxy 等组件的运行指标,用于监控组件运行状态。
这些都是 Kubernetes 集群运行状态的关键指标,通过Prometheus 等工具可以进行收集和存储,然后在 Grafana 中设计相应的 Dashboard 进行可视化展示。当这些指标超出正常范围时,也可以根据阈值设置报警,保证 Kubernetes 集群和服务的稳定运行。
例如:
CPU 利用率超过 80%报警
内存利用率超过 90%报警
网络流量/磁盘空间突增报警
Pod/节点 NotReady 状态超过 10%报警
API Server 请求 LATENCY 超过 200ms 报警
etcd 节点 Down 报警等等
这些报警规则的设置需要根据集群大小和服务负载进行评估。
Prometheus安装
1:安装
Prometheus Operator 是 Core0s 开源的项目,它提供了一种 Kubernetes-native 的方式来运行和管理 Prometheus。Prometheus operator 可以自动创建、配置和管理 Prometheus 实例,并将其与Kubernetes 中的服务发现机制集成在一起,从而实现对 Kubernetes 集群的自动监控。
Prometheus 和Prometheus operator 的区别如下:Prometheus是一种开源的监控系统,用于记录各种指标,并提供査询接口和告警机制。而Prometheus0perator 则是一种用于在 Kubernetes 上运行和管理 Prometheus 的解决方案。相比于传统方式手动部署 Prometheus,Prometheus Operator 可以自动创建、配置和管理 Prometheus 实例,并将其与Kubernetes 中的服务发现机制集成在一起,大幅简化了我们的工作量。


备注:
–server-side
这个特性主要目标是把逻辑从 kubectl apply 移动到 kube-apiserver 中,这可以修复当前遇到的很多有关所有权冲突的问题。
可以直接通过 API 完成声明式配置的操作,而无需依赖于特定的 kubectl apply 命令
如果要删除Prometheus operator,可以使用下面的命令
kubectl delete -ignore-not-found=true -f manifests/setup
备注:
prometheus-operator 的作用主要是用来创建prometheus 的相关资源以及监视与管理它创建出来的资源对象。
安装Prpmetheus Stack

备注:
删除Prometheus stack
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
备注:
kube-prometheus-stack 是一个全家桶,提供监控告警组件alert-manager、grafana 等子组件。
查看容器状态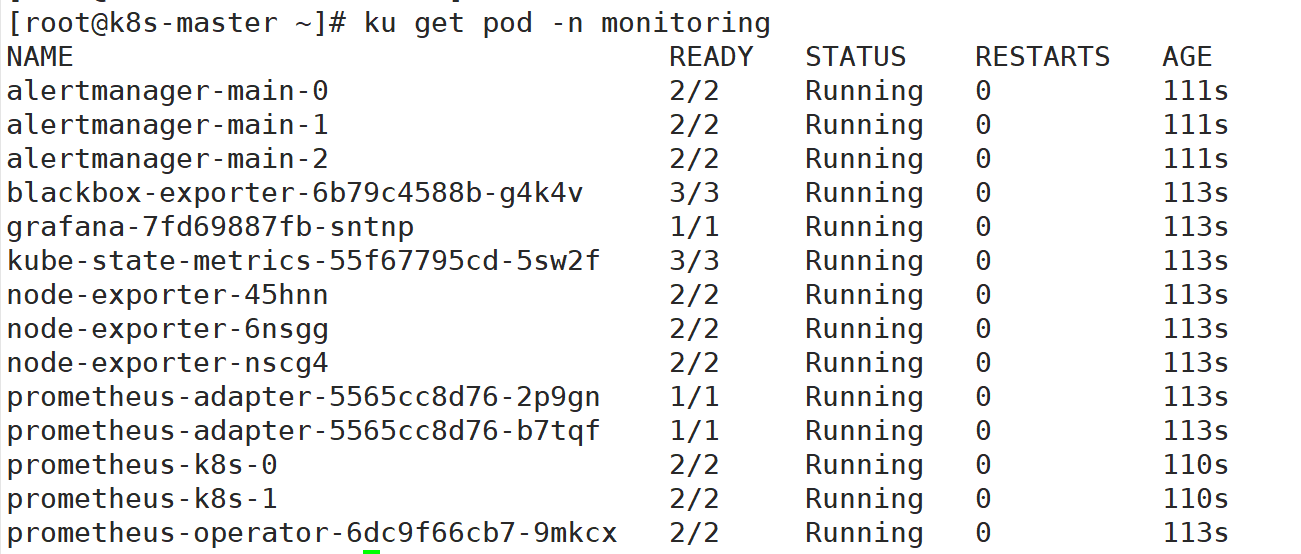
servicemonitors 定义了如何监控一组动态的服务,使用标签选择来定义哪些 Service 被选择进行监控。这可以让团队制定一个如何暴露监控指标的规范,然后按照这些规范自动发现新的服务,而无需重新配置。
为了让 Prometheus 监控 Kubernetes 内的任何应用,需要存在一个 Endpoints 对象,Endpoints对象本质上是 IP 地址的列表,通常 Endpoints 对象是由 Service 对象来自动填充的,Service 对象通过标签选择器匹配 Pod,并将其添加到 Endpoints 对象中。一个 Service 可以暴露一个或多个端口,这些端口由多个 Endpoints 列表支持,这些端点一般情况下都是指向一个 Pod。Prometheus operator 引入的这个 ServiceMonitor 对象就会发现这些 Endpoints 对象,并配置 Prometheus 监控这些 Pod.ServiceMonitorspec的endpoints部分就是用于配置这些 Endpoints的哪些端口将被 scrape 指标的。
Prometheus Operator 使用 ServiceMonitor 管理监控配置。
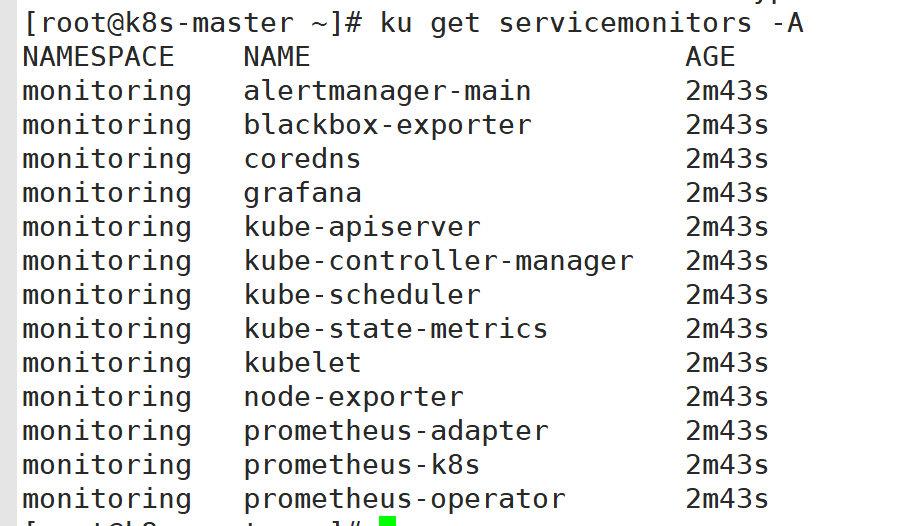
2:修改grafana的service的类型



3:访问grafana
任意集群内IP地址:30665
4:修改Prometheus的service类型


5:访问Prometheus
任意集群内ip+30420
查看监控目标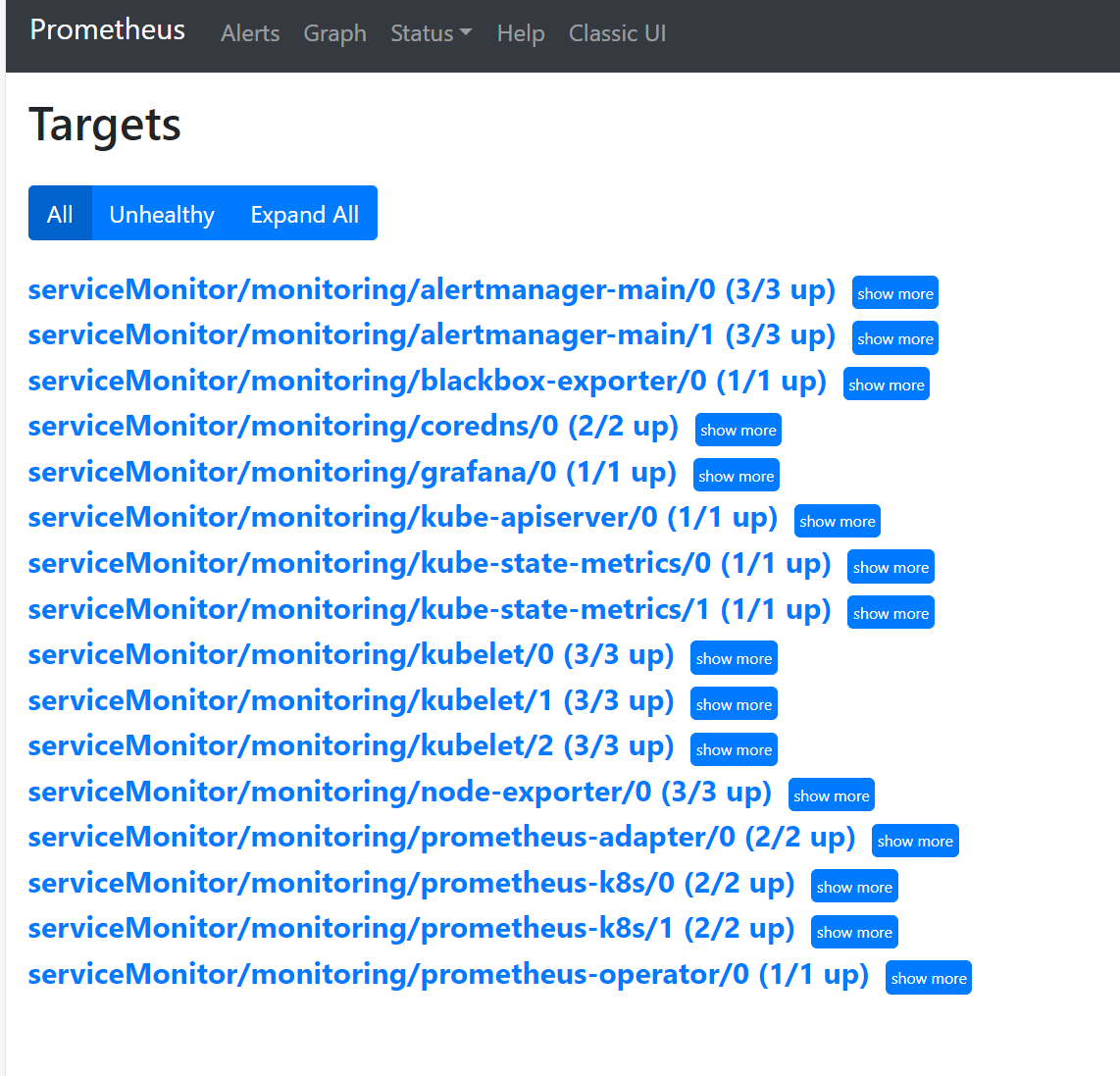
备注:
在 Prometheus 中一条告警规则有三个状态:
inactive:还未被触发;
pending:已经触发,但是还未达到 for 设定的时间;
firing:触发且达到设定时间
配置Grafana Dashbord
1:导入模板
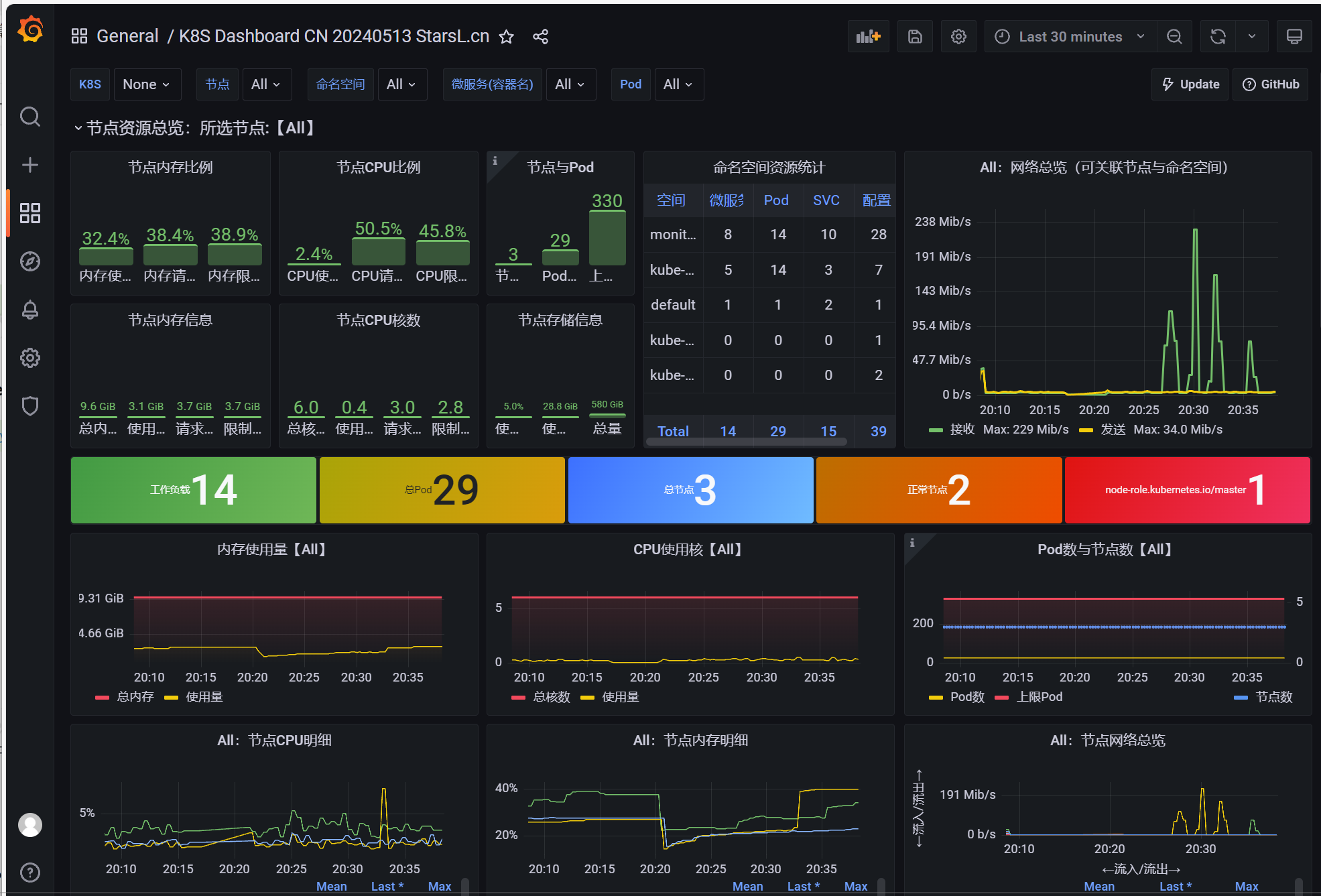
监控Mysql数据库
在 Prometheus 的监控体系中,符合云原生设计理念的应用通常自带一个 Metrics 接口,这使得Prometheus 能够直接抓取到应用的监控数据。然而,对于非云原生应用(如 MySQL、Redis、Kafka 等),由于它们并未原生暴露 Prometheus 所需的 Metrics 接口,因此我们需要借助 Exporter 来实现数据的采集和暴露。本案例将以 MySOL 为例,详细介绍如何通过 Exporter 实现对非云原生应用的监控,并将其集成到 Prometheus 监控体系中。
1:安装一个mysql
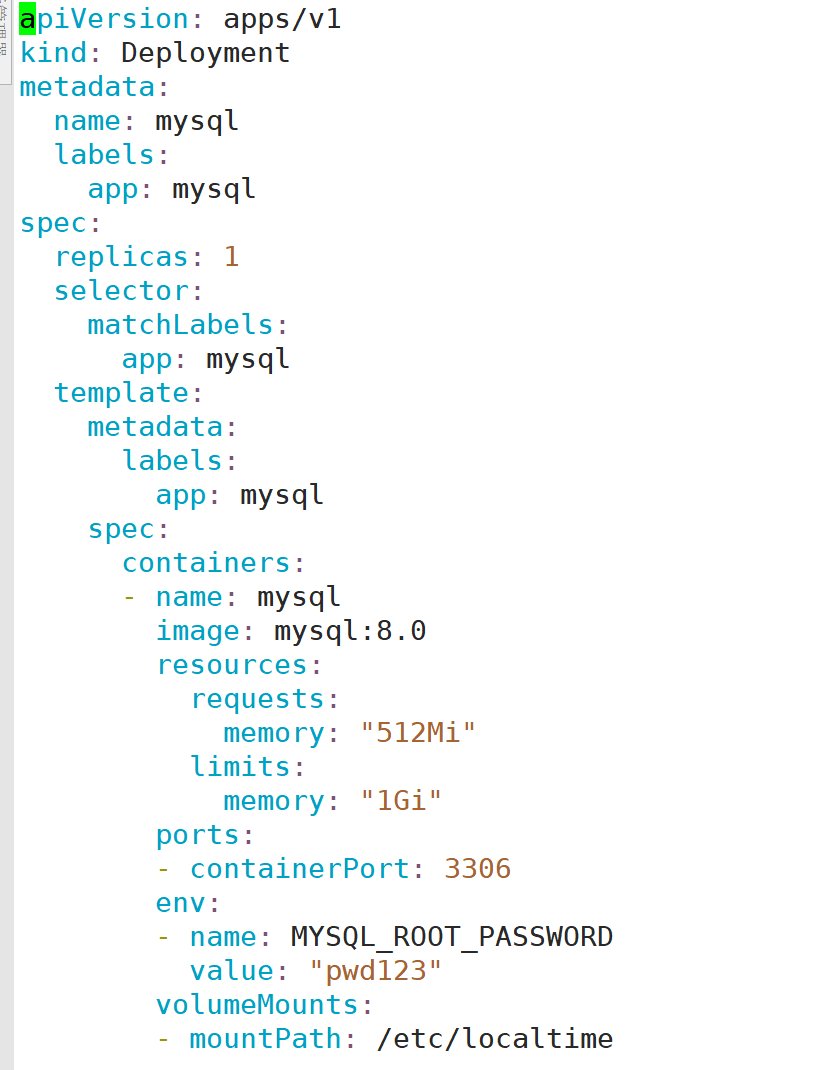



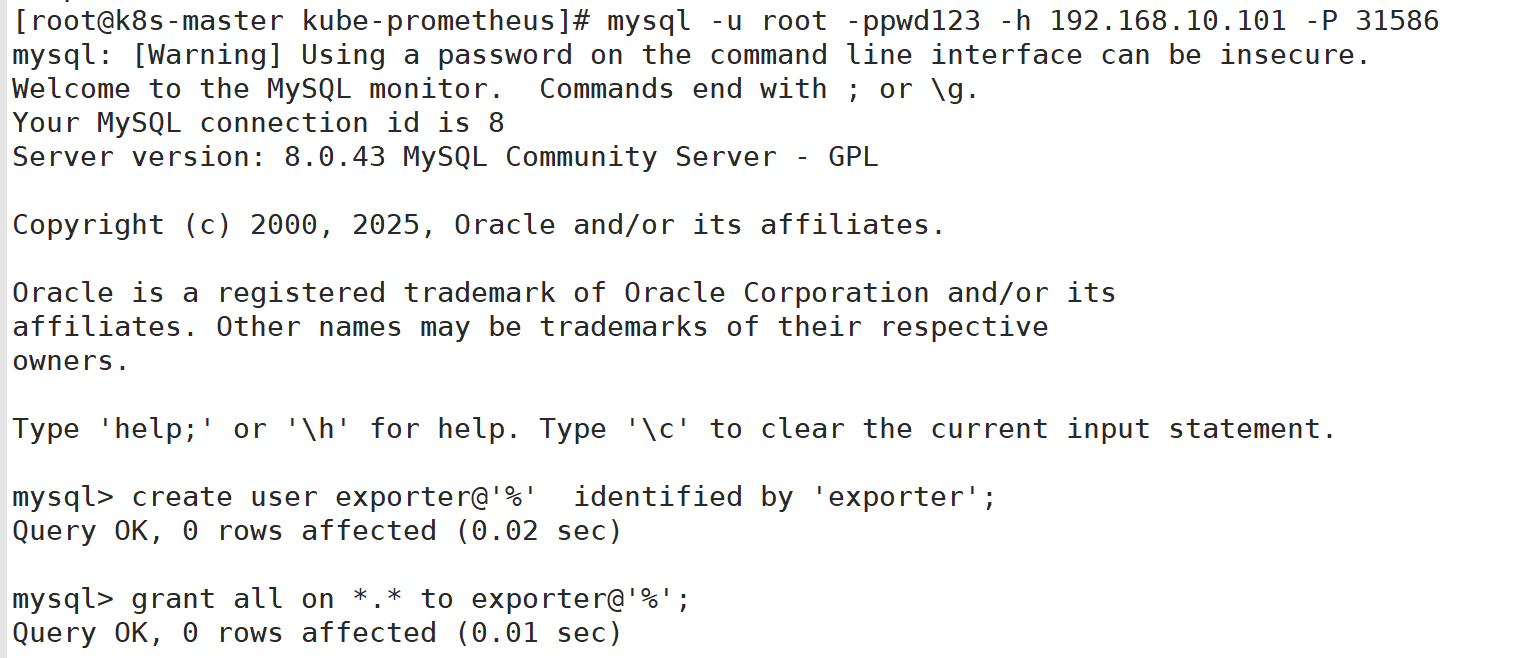
2:配置mysql exporter采集mysql监控文件

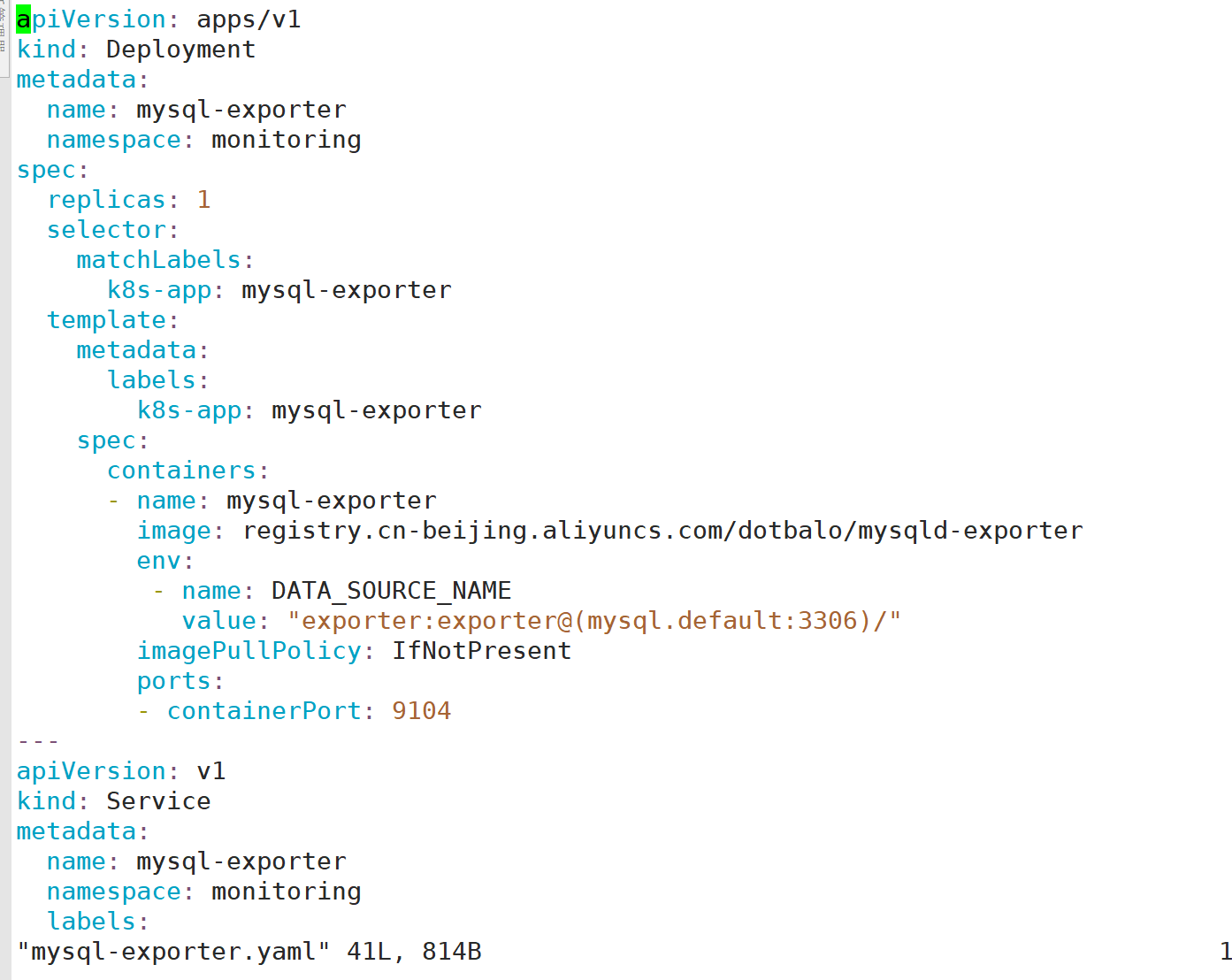
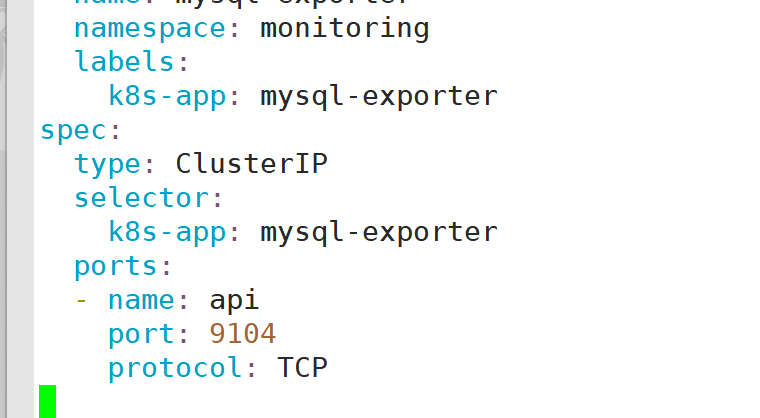
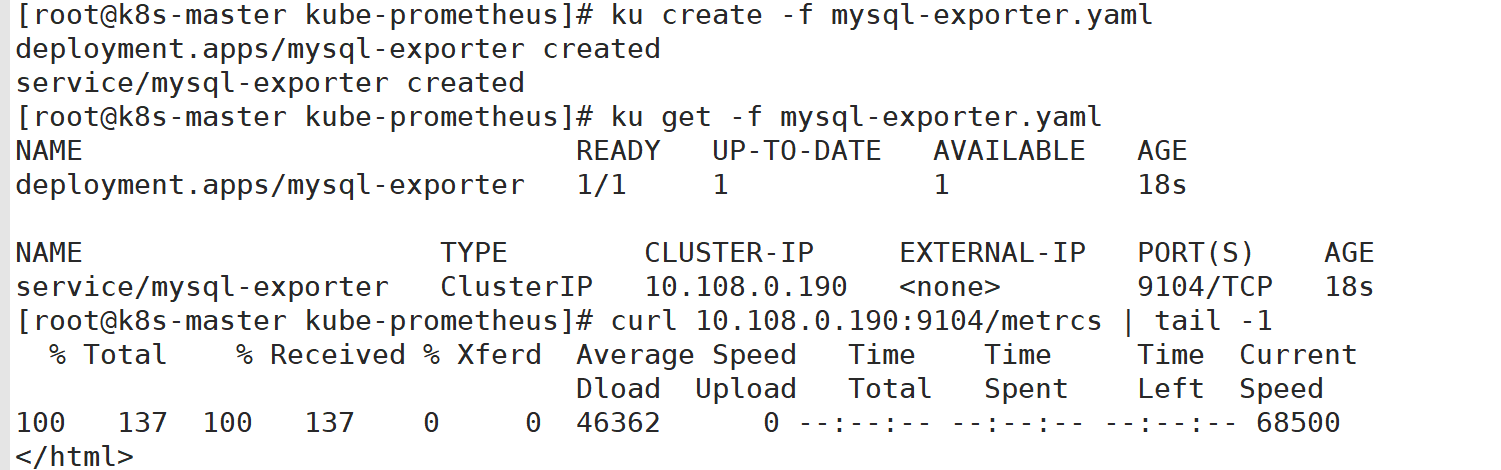
3:配置ServiceMonitor
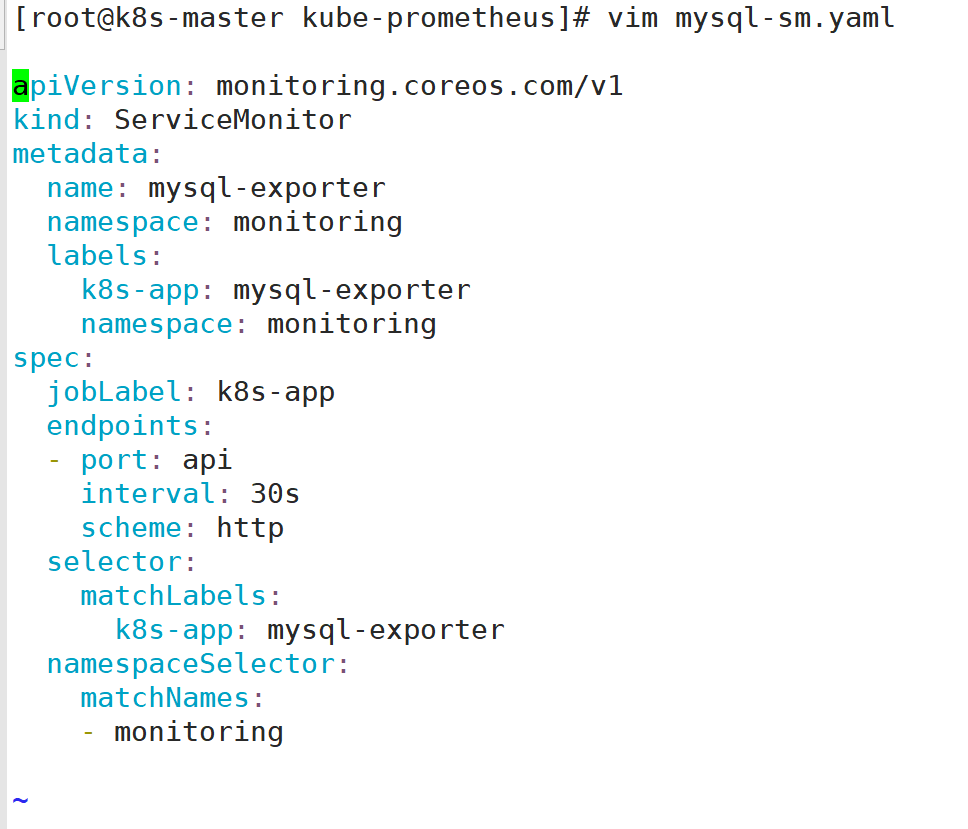

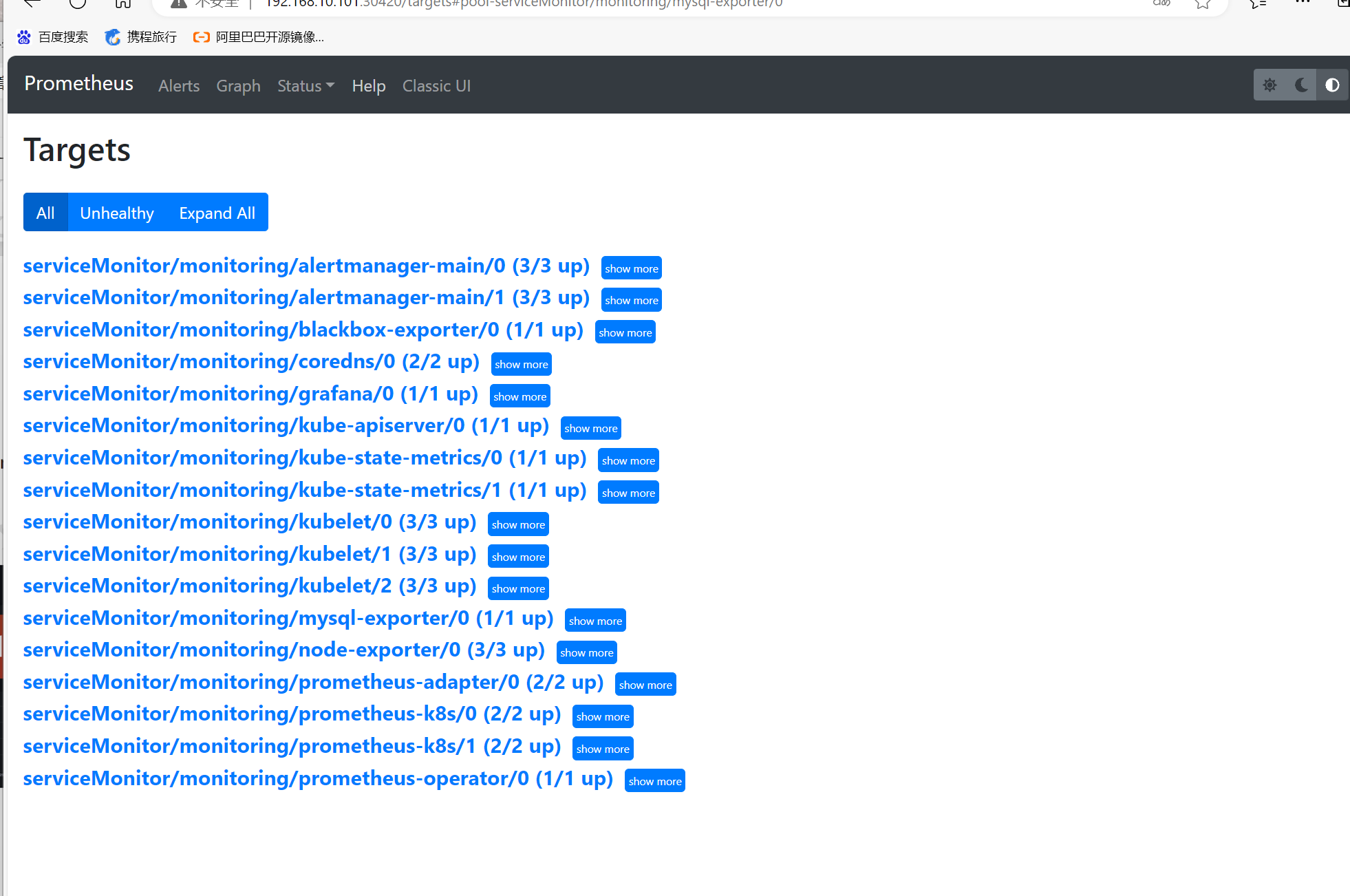
查看监控出现的mysql
对钉钉报警
首先在钉钉群里面添加一个自定义机器人为钉钉机器人添加关键字:
1:部署Dingtalk
DingTalk(钉钉)是阿里巴巴集团开发的一款企业级通讯和协作平台,旨在提升工作效率和团队协作能力。它集成了即时通讯、视频会议、任务管理、日程安排、文件共享等多种功能,适用于企业内部的沟通与协作。DingTalk 支持多平台使用,包括移动设备(i0s、Android)和桌面端(windows、macos),并且提供了丰富的 API 接口,方便与企业现有的系统进行集成。
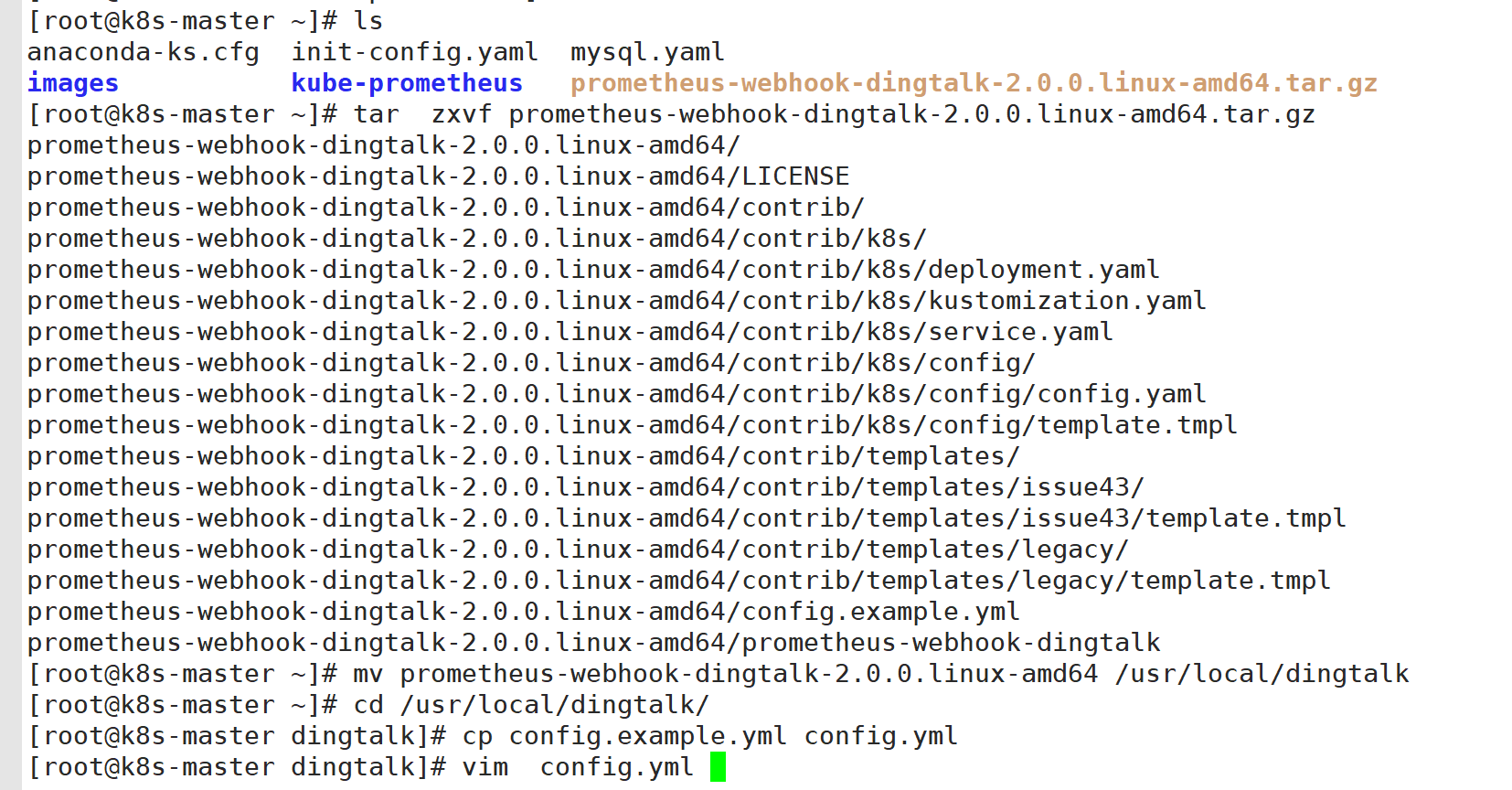
写机器人的webhook

2:启动服务
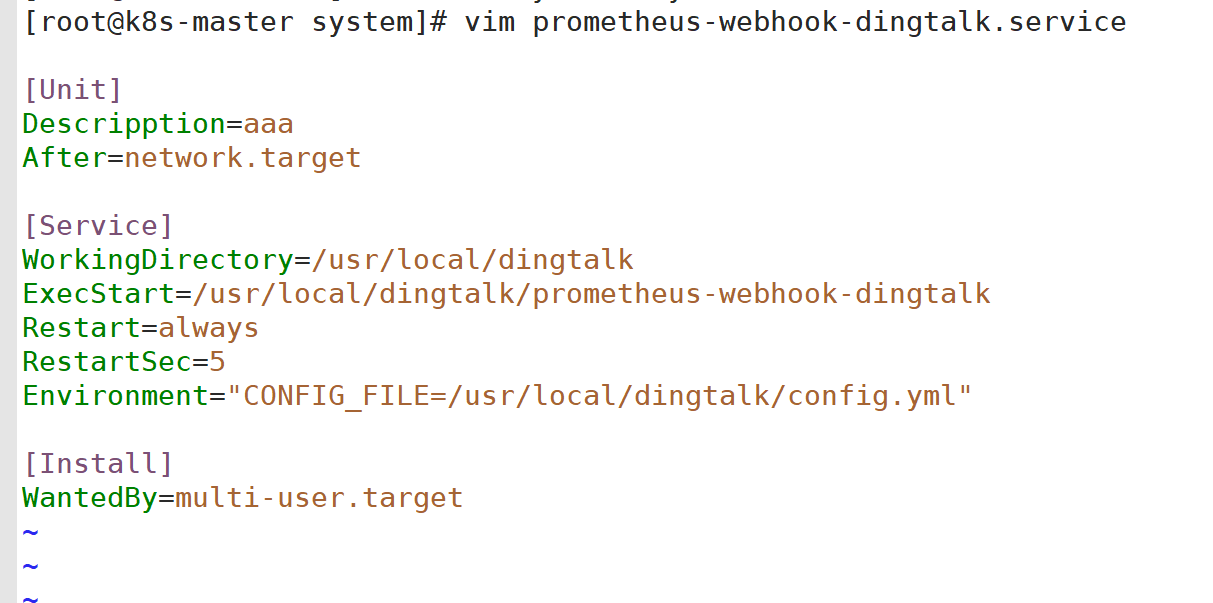


3:配置Alertmanager






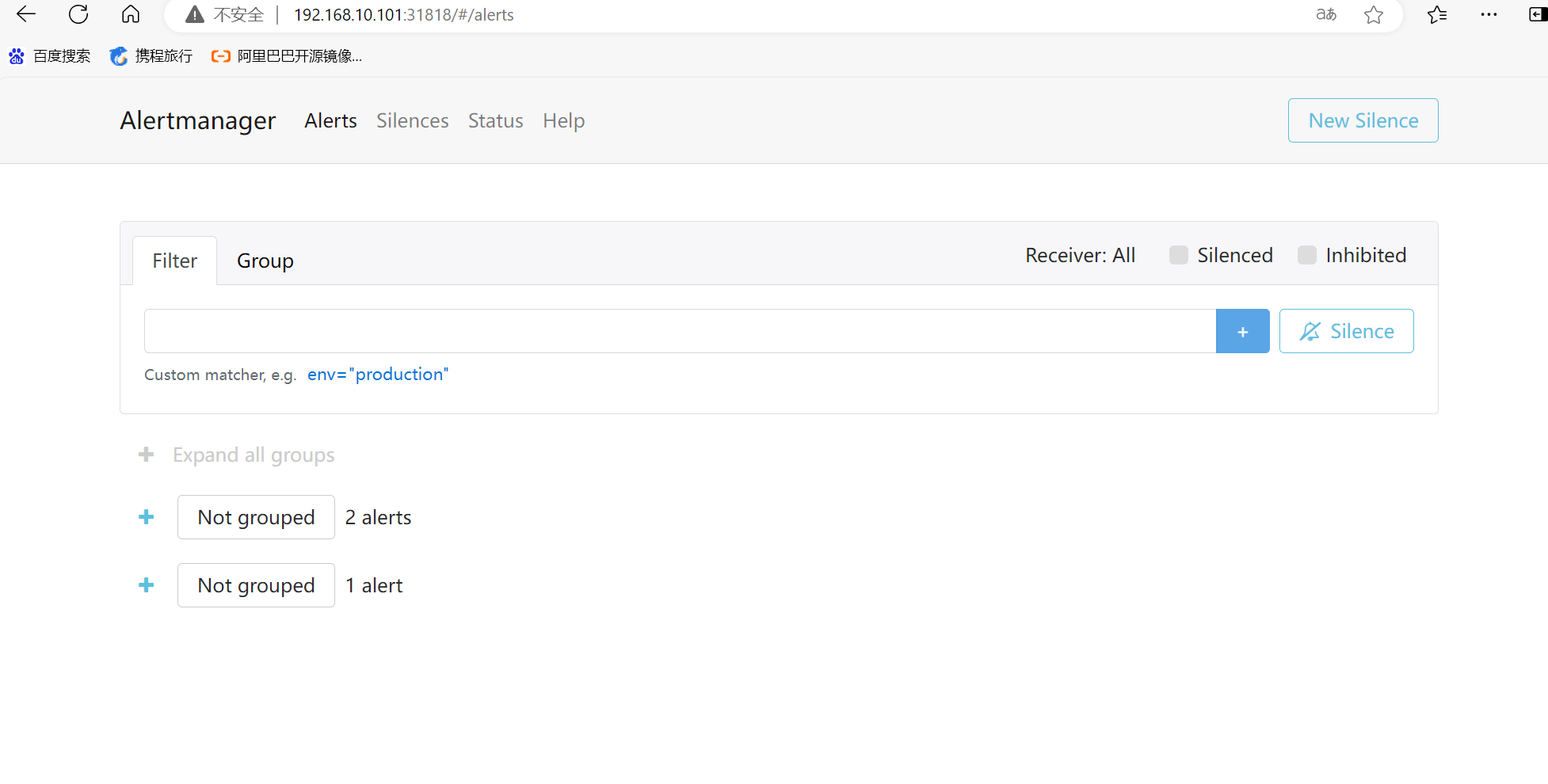
4:访问Alertmanager页面
任意集群内ip:31818
备注:
Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing.
1、Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。
2、Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态
3、Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到 Inactive,如此循环。
如果修改了 alertmanager-secret.yaml 文件,可以重建一下
kubectl delete -f alertmanager-secret.yaml
kubectl create -f alertmanager-secret.yaml
等待报警信息,可以自己制造问题
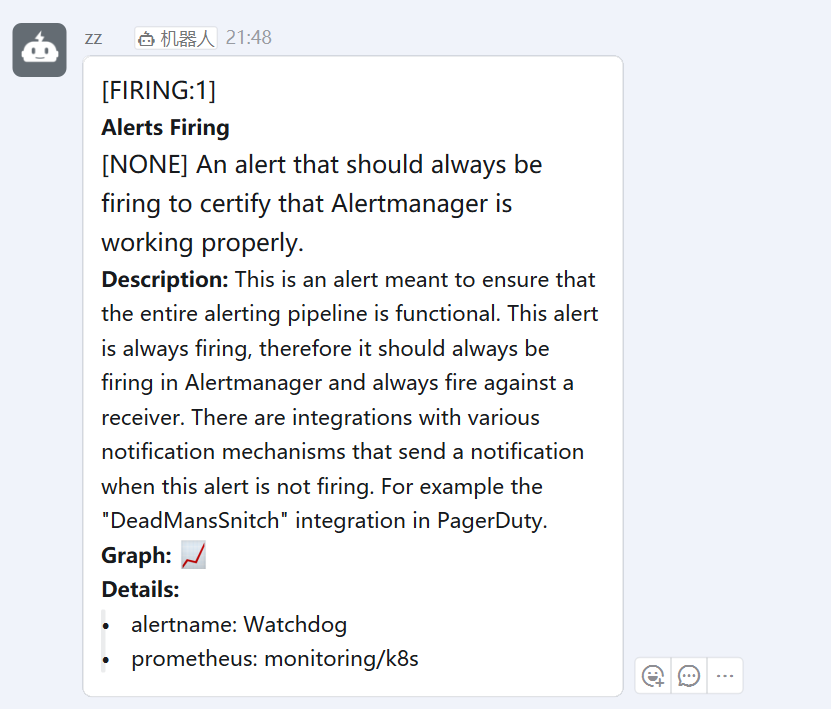
解决ServiceMonitor找不到主机问题
发现虽然在Alert中有KubeControllerManager和KubeScheduler的监控配置,但是没有发现可用的监控目标

1:查看target
Status–>Target(监控目标中没有kube-controller-manager和kube-scheduler)

备注:
在Prometheus中一条告警规则有三个状态:
inactive:还未被触发;
pending:已经触发,但是还未达到for设定的时间;
firing:触发且达到设定时间。
2:查看ServiceMonitor是否创建成功

3:解决kube-controller-manager不监控
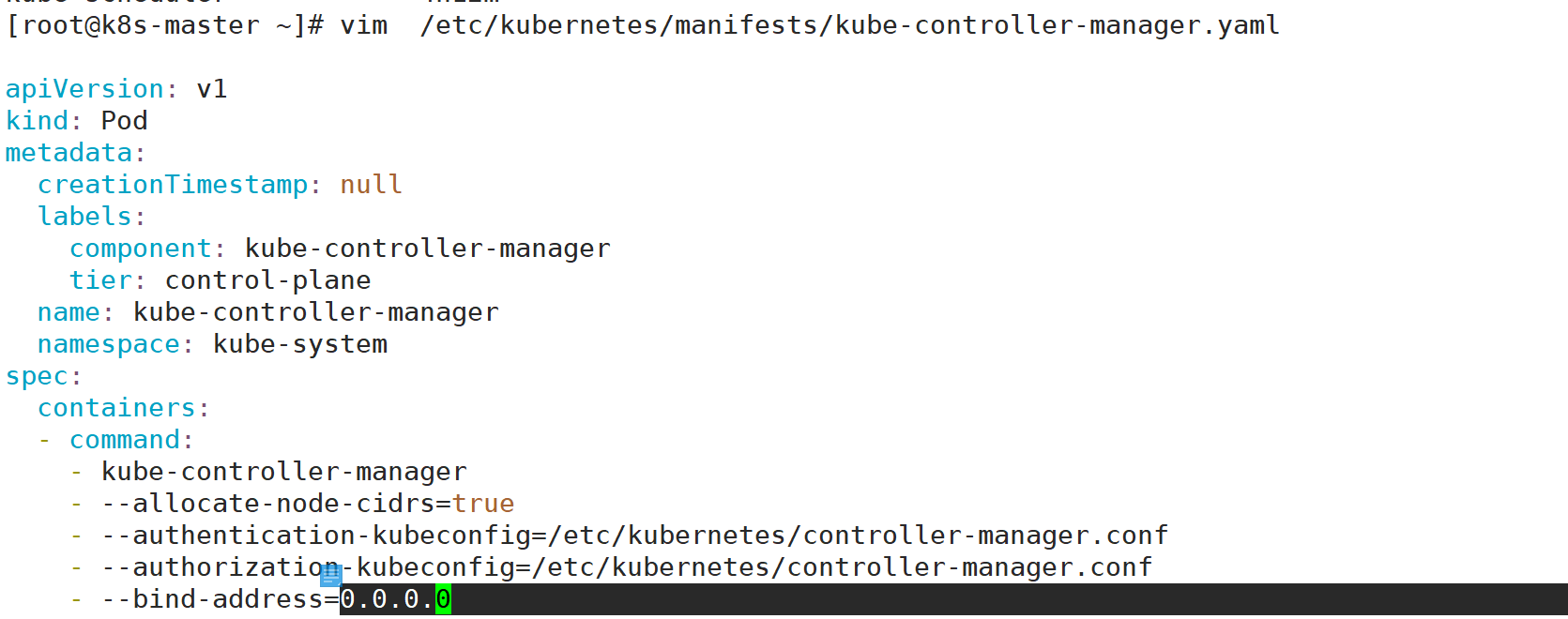
将kube-controller-manager的监听地址修改为0.0.0.0.原来是127.0.0.1
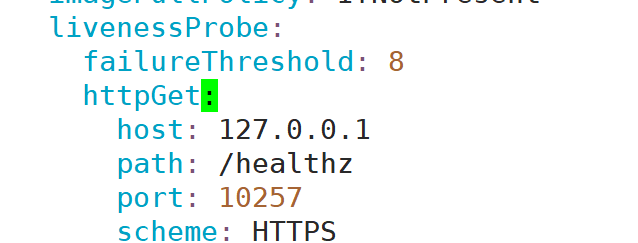
注意:
从此文件可以看出controller-manager的监听端口为10257,协议为HTTPS

注意:
如果无法看到kube-controll的进程需要等待一会,如果等一会也看不到,可以重建一下kube-controller-manager.yaml,重建一下也不行就重启master节点。
查看kube-controller-manager的ServiceMonitor的配置


注意:
此处的ServiceMonitor匹配的是kube-system命名空间下具有app.kubernetes.io/name=kube-controller-manager标签的Service。需要查看一下是否有这个service
查看标签

注意:
此处发现没有这个Service
创建一个EndPoint和servce,指向自己的Controller Manager

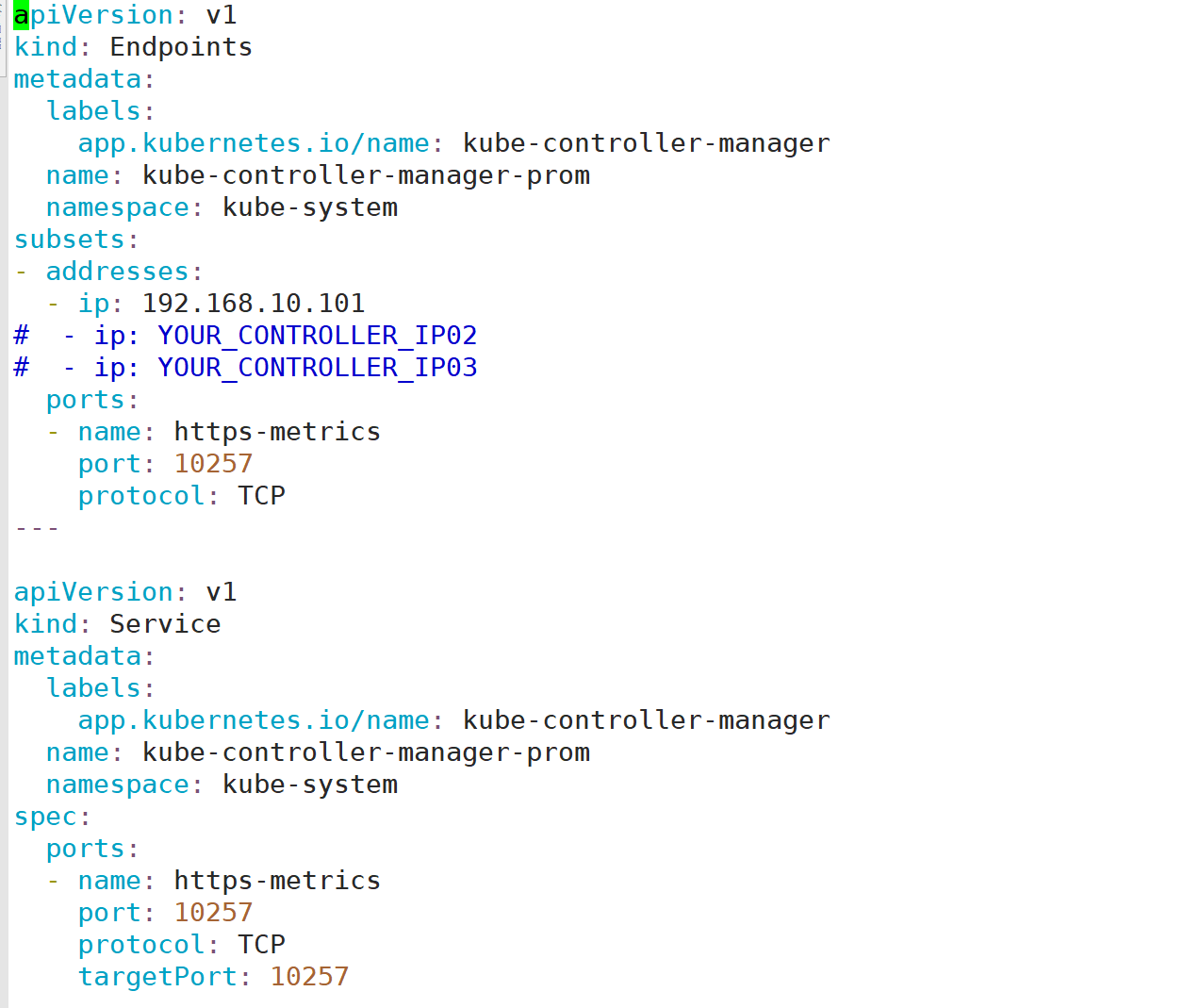
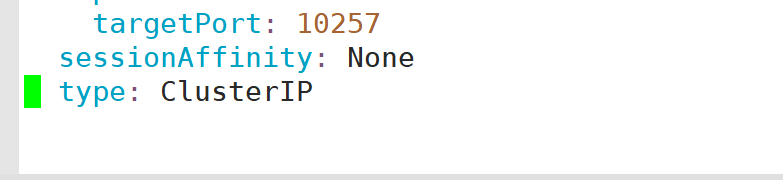

修改ServiceMonitor的配置和Service的一致(高于1.22版本的默认不用修改)

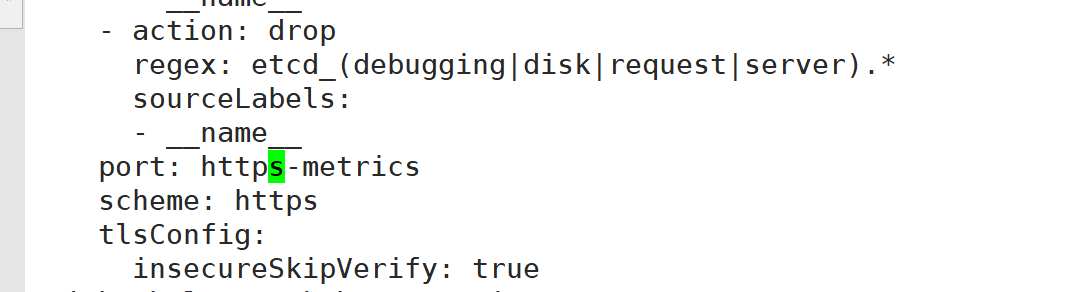
kube-scheduler不监控和controller-manager原因一样,对应修改即可