《汇编语言:基于X86处理器》第13章 高级语言接口(1)
与C、c++,Java等高级语言相比,汇编开发的效率偏低和维护成本偏高。大型的项目已经很少用汇编语言了,但并不是说汇编语言就完全没有用处了,在某些特定的领域,汇编语言还是很有用处的,比如配置硬件驱动器,芯片接口开发等。并且可以与C和c++混合使用。本章讲解高级语言接口,汇编语言与高级语言的混合编程,库调用。
13.1 引言
大多数程序员不会用汇编语言编写大型程序,因为这将花费相当多的时间。反之,高级语言则隐藏了会减缓项目开发进度的细节。但是汇编语言仍然广泛用于配置硬件驱动器,以及优化程序速度和代码量。
本章将重点关注汇编语言和高级编程语言之间的接口或连接。第二节将展示如何在C++中编写内联汇编代码。第三节将把 32 位汇编语言模块链接到 C++程序。最后,将说明如何在汇编程序中调用C库函数。
13.1.1 通用规范
从高级语言中调用汇编过程时,需要解决一些常见的问题。
首先,一种语言使用的命名规范(namingconvention)是指与变量和过程命名相关的规则和特性。比如,一个需要回答的重要问题是:汇编器或编译器会修改目标文件中的标识符名称吗?如果是,如何修改?
其次,段名称必须与高级语言使用的名称兼容。
第三,程序使用的内存模式(微模式、小描述、紧凑模式、中模式、大模式、巨模式,或平坦模式)决定了段大小(16或32位),以及调用或引用是近(同一段内)还是远(不同段之间)。
调用规范 调用规范(calling convention)是指调用过程的底层细节。下面列出了需要考虑的细节信息:
●调用过程需要保存哪些寄存器。
●传递参数的方法:用寄存器、用堆栈、共享内存,或者其他方法。
●主调程序调用过程时,参数传递的顺序
●参数传递方法是传值还是传引用。
●过程调用后,如何恢复堆栈指针
●函数如何向主调程序返回结果
命名规范与外部标识符 当从其他语言程序中调用汇编过程时,外部标识符必须与命名规范(命名规则)兼容。外部标识符(external identifier)是放在模块目标文件中的名称,链接器使得这些名称能够被其他程序模块使用。链接器解析对外部标识符的引用,但是仅适用于命名规范一致的情况。
例如,假设C程序Main.c 调用外部过程ArraySum。如下图所示,C 编译器自动保留大小写,并为外部名称添加前导下划线,将其修改为_ArraySum:

Array.asm 模块用汇编语言编写,由于其.MODEL 伪指令使用的选项为 Pascal 语言,因此输出 ArraySum 过程的名称就是ARRAYSUM。由于两个输出的名称不同,因此链接器无法生成可执行程序。
早期编程语言,如 COBOL 和PASCAL,其编译器一般将标识符全部转换为大写字母。近期的语言,如 C、C++ 和 Java 则保留了标识符的大小写。此外,支持函数重载的语言(如C++)还使用名称修饰(name decoration)的技术为函数名添加更多字符。比如,若函数名为MySub(int n,double b),则其输出可能为MySub#int#double。
在汇编语言模块中,通过MODEL伪指令选择语言说明符来控制大小写。
段名称 汇编语言过程与高级语言程序链接时,段名称必须是兼容的。本章使用Microsoft 简化段伪指令.CODE、.STACK 和.DATA,它们与Microsoft C++编译器生成的段名称兼容。
内存模式 主调程序与被调过程使用的内存模式必须相同。比如,实地址模式下可选择小模式、中模式、紧凑模式、大模式和巨模式。保护模式下必须使用平坦模式。本章将会给出两种模式的例子。
13.1.2 MODEL伪指令
16 位和 32 位模式中,MASM 使用.MODEL 伪指令确定若干重要的程序特性:内存模式类型、过程命名模式以及参数传递规则。若汇编代码被其他编程语言程序调用,那么后两者就尤其重要。.MODEL 伪指令的语法如下:
.MODEL memorymodel [,modeloptions]
MemoryModel 表13-1列出了memorymodel字段可选择的模式。除了平坦模式之外其他所有模式都可以用于16位实地址编程。
表13-1内存模式 | |
模式 | 说明 |
微模式 | 一个既包含代码又包含数据的段。文件扩展名为.com的程序使用该模式 |
小模式 | 一个代码段和一个数据段。默认情况下,所有代码和数据都为近属性 |
中模式 | 多个代码段,一个数据段 |
紧凑模式 | 一个代码段,多个数据段 |
大模式 | 多个代码段和数据段 |
巨模式 | 与大模式相同,但是各个数据项可以大于单个段 |
平坦模式 | 保护模式。代码与数据使用32位偏移量。所有的数据和代码(包括系统资源)都在一个32位段内 |
32位程序使用平坦内存模式,其偏移量为32位,代码和数据最大可达4GB。比如Iryine32.inc 文件包含了如下.MODEL伪指令:
.model flat, stdcall
ModelOptions .MODEL伪指令中的ModelOptions字段可以包含一个语言说明符和一个栈距离。语言说明符指定过程与公共符号的调用和命名规范。栈距离可以是NEARSTACK(默认值)或者FARSTACK。
1.语言说明符
伪指令.MODEL 有几种不同的可选语言说明符,其中的一些很少使用(比如BASICFORTRAN 和 PASCAL)。反之,C 和 STDCALL 则十分常见。结合平坦内存模式,示例如下:
.model flat, C
.model flat, STDCALL
语言说明符 STDCALL 用于 Windows 系统函数调用。本章在链接汇编代码和 C 与 C++程序时,使用C语言说明符。
2.STDCALL
STDCALL 语言说明符将子程序参数按逆序(从后往前)压入堆栈。为了便于说明,首先用高级语言编写如下函数调用:
AddTwo( 5:6);
STDCALL被选为语言说明符,则等效的汇编语言代码如下:
push 6
push 5
call AddTwo另一个重要的考虑是,过程调用后如何从堆栈中移除参数。STDCALL 要求在 RET 指令中带一个常量操作数。返回地址从堆栈中弹出后,该常数为 RET 执行与 ESP 相加的数值:
AddTwo PROCpush ebpmov ebp, espmov eax,[ebp+12] ;第二个参数add eax,[ebp+8] ;第一个参数pop ebpret 8 ;清除堆栈
AddTwo ENDP堆栈指针加上8后,就指回了主调程序参数人栈之前指针的位置。最后,STDCALL通过将输出(公共)过程名保存为如下格式来修改这些名称:
_name@nn
前导下划线添加到过程名,@符号后面的整数指定了过程参数的字节数(向上舍人到4的倍数)。例如,假设过程 AddTwo 带有两个双字参数,那么汇编器传递给链接器的名称就为_AddTwo@8。
Microsoft链接器是区分大小写的,因此MYSUB@8和MySub@8是两个不同的名称。要查看OBJ文件中所有的过程名,使用VisuaStudio中的DUMPBIN工具,选项为/SYMBOLS。
3.C说明符
和 STDCALL 一样,C语言说明符也要求将过程参数按从后往前的顺序压人堆。对于过程调用后从堆栈中移除参数的问题,C语言说明符将这个责任留给了主调方。在主调程序中,ESP与一个常数相加,将其再次设置为参数入栈之前的位置:
push 6 ;第二个参数
push 5 ;第一个参数
call AddTwo
add esp, 8 ;清除堆栈C语言说明符在外部过程名的前面添加前导下划线。示例如下:
_AddTwo
13.1.3 检查编译器生成的代码
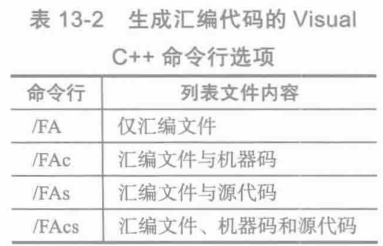
长久以来,C和C++编译器都会生成汇编语言源代码,但是程序员通常看不到。这是因为,汇编语言代码只是产生可执行文件过程的一个中间步骤。幸运的是,大多数编译器都可以应要求生成汇编语言源代码文件。例如,表13-2列出了Visual Studio 控制汇编源代码输出的命令行选项。
检查编译器生成的代码文件有助于理解底层信息,比如堆栈帧结构、循环和逻辑编码,并且还有可能找到低级编程错误。另一个好处是更加便于发现不同编译器生成代码的差异。
现在来看看C++编译器生成优化代码的一种方法。由于是第一个例子,因此先编写一个简单的C方法 ArraySum,并在 Visual Studio 2012 中进行编译,其设置如下:
●Optimization=Disabled(使用调试器时需要)
●Favor Size or Speed=Favor fast code
●Assembler Output=Assembly With Source Code
下面是用ANSIC编写的arraysum源代码:
int arraySum(int array[], int count)
{int i;int sum = 0;for(i = 0; i < count; i++)sum += array[i];return sum;
}现在来查看由编译器生成的arraysum的汇编代码,如图13-1所示。

图13-1Visual Studio生成的 ArraySum 汇编代码

1~4行定义了两个局部变量(sum和i)的负数偏移量,以及输人参数array和count的正数偏移量:
1: _sum$ = -8 ;size = 4
2: _i$ = -4 ;size = 4
3: _array$ = 8 ;size = 4
4: _count$ = 12 ;size = 4
9~10行设置 ESP为帧指针:
9: push ebp
10: mov ebp, esp
之后,11~14行从ESP中减去72,为局部变量预留栈空间。同时,把将会被函数修改的三个寄存器保存到堆栈。
11: sub esp, 72
12: push ebx
13: push esi
14: push edi
19行把局部变量sum定位到堆栈帧,并将其初始化为0。由于符号_sum$定义为数值-8,因此它就位于当前EBP下面8个字节的位置:
19: mov DWORD PTR_sum$[ebp], 0
24 和 25 行将变量 i初始化为 0,再转移到 30 行,跳过后面循环计数器递增的语句:
24: mov DWORD PTR_i$[ebp],0
25: imp SHORT $LN3@arraySum
26~29行标记循环开端以及循环计数器递增的位置。从C源代码来看,递增操作(i++)是在循环末尾执行,但是编译器却将这部分代码移到了循环顶部:
26: $LN2@arraySum:
27: mov eax,DWORD PTR _i$[ebp]
28: add eax,1
29: mov DWORD PTR _i$[ebp],eax
30~33行比较变量i和count,如果i大于或等于count,则跳出循环:
30:$LN3@arraySum:
31: mov eax, DWORD PTR _i$[ebp]
32: cmp eax, DWORD PTR _count$[ebp]
33: jge SHORT $LN1@arraySum
37~41行计算表达式sum+=array[]。Array[1]复制到 ECX,sum 复制到 EDX,执行加法运算后,EDX 的内容再复制回sum:
37: mov eax, DWORD PTR _i$[ebp]
38: mov ecx, DWORD PTR _array$[ebp]
39: mov edx, DWORD PTR _sum$[ebp]
40: add edx, DWORD PTR[ecx+eax*4]
41: mov DWORD PTR _sum$[ebp], edx
42 行将控制转回循环顶部:
42: jmp SHORT SLN2@arraySum
43 行的标号正好位于循环之外,该位置便于作为循环结束时进行跳转的目标地址:
43: $LN1@arraySum:
48 行将变量sum 送人 EAX,准备返回主调程序。
52~56 行恢复之前被保存的寄存器,其中,ESP 必须指向主调程序在堆栈中的返回地址。
48: mov eax, DWORD PTR _sum$[ebp]
49:
50: ; 12: }
51:
52: pop edi
53: pop esi
54: pop ebx
55: mov esp, ebp
56: pop ebp
57: ret 0
58: _arraySum ENDP
可以写出比上例更快的代码,这种想法不无道理。上例中的代码是为了进行交互式调试,因此为了可读性而牺牲了速度。如果针对确定目标编译同样的程序,并选择完全优化,那么结果代码的执行速度将会非常快,但同时,程序对人类而言基本上是无法阅读和理解的。
调试器设置 用Visual Studio调试C 和 C++程序时,若想查看汇编语言源代码,就在Tools 菜单中选择 Options 以显示如图 13-2 的对话框窗口,再选择箭头所指的选项。上述设置要在启动调试器之前完成。接着,在调试会话开始后,右键点击源代码窗口,从弹出菜单中选择 Go to Disassembly。
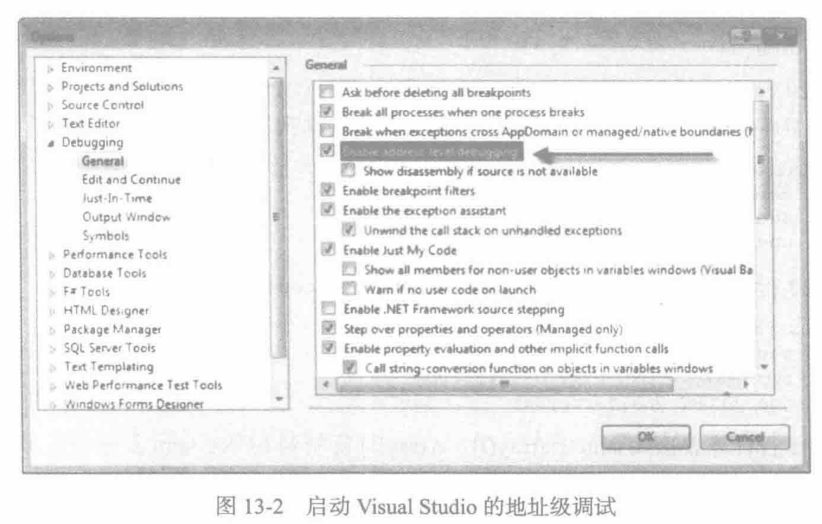
图13-2启动VisualStudio的地址级调试
本章目标是熟悉由C和C++编译器产生的最直接和简单的代码生成例子。此外,认识到编译器有多种方法生成代码也是很重要的。比如,它们可以将代码优化为尽可能少的机器代码字节。或者,可以尝试生成尽可能快的代码,即使要用大量机器代码字节来输出结果(常见的情况)。最后,编译器还可以在代码量和速度的优化间进行折中。为速度进行优化的代码可能包含更多指令,其原因是,为了追求更快的执行速度会展开循环。机器代码还可以拆分为两部分以便利用双核处理器,这些处理器能同时执行两条并行代码。
13.1.4 本节回顾
1.什么是编程语言使用的命名规范?
答:语言的命名规范是指变量或过程命名的相关规则和特性。
2.实地址模式可以选择哪些内存模式?
答:微模式、小模式、紧凑模式、中模式、大模式、巨模式
3.使用STDCALL语言说明符的汇编语言过程可以与C++程序链接吗?
答:不可以,因为链接器无法找到过程名。
13.2 内嵌汇编代码
13.2.1 Visual C++中的_asm伪指令
内嵌汇编代码(inline assembly code)是指直接插入高级语言程序中的汇编源代码。大多数C和C++编译器都支持这一功能。
本节将展示如何在运行于32位保护模式,并采用平坦内存模式的MicrosoftVisual C++中编写内嵌汇编代码。其他高级语言编译器也支持内嵌汇编代码,但其语法会发生变化。
内嵌汇编代码是把汇编代码编写为外部模块的一种直接替换方式。编写内嵌代码最突出的优点就是简单性,因为不用考虑外部链接,命名以及参数传递协议等问题。
但使用内嵌汇编代码最大的缺点是缺少兼容性。高级语言程序针对不同目的平台进行编译时,这就成了一个问题。比如,在IntelPentium处理器上运行的内嵌汇编代码就不能在RISC处理器上运行。一定程度上,在程序源代码中插入条件定义可以解决这个问题,插入的定义针对不同目标系统可以启用函数的不同版本。不过,容易看出,维护仍然是个问题另一方面,外部汇编过程的链接库容易被为不同目标机器设计的相似链接库所代替。
__asm伪指令 在VisualC++中,伪指令__asm可以放在一条语句之前,也可以放在一个汇编语句块(称为asm块)之前。语法如下:
__asm statement
__asm {statement-1statement-2....statement-n
}(在“asm”的前面有两个下划线。)
注释 注释可以放在 asm块内任何语句的后面,使用汇编语法或C/C++语法。VisualC++手册建议不要使用汇编风格的注释,以防与C宏混淆,因为C宏会在单个逻辑行上进行扩展。下面是可用注释的例子:
mov esi,buf :initialize index register
mov esi,buf /* initialize index register*/
mov esi,buf //initialize index register特点 编写内嵌汇编代码时允许:
●使用 x86 指令集内的大多数指令。
●使用寄存器名作为操作数。
●通过名字引用函数参数。
●引用在asm 块之外定义的代码标号和变量。(这点很重要,因为局部函数变量必须在asm块的外面定义。)
●使用包含在汇编风格或C风格基数表示法中的数字常数。比如,0A26h 和 0xA26 是等价的,且都能使用。
●在语句中使用PTR 运算符,比如 inc BYTE PTR[esi]。
●使用 EVEN 和ALIGN伪指令。
限制 编写内嵌汇编代码时不允许:
●使用数据定义伪指令,如DB(BYTE)和DW(WORD)。
●使用汇编运算符(除了PTR之外)。
●使用 STRUCT、RECORD、WIDTH 和MASK。
●使用宏伪指令,包括MACRO、REPTIRCIRP和ENDM,以及宏运算符(!&、%和.TYPE)。
●通过名字引用段。(但是,可以用段寄存器名作为操作数。)
寄存器值 不能在一个asm块开始的时候对寄存器值进行任何假设。寄存器有可能被asm 块前面的执行代码修改。Microsoft Visual C++的关键字_fastcall 会使编译器用寄存器来传递参数,为了避免寄存器冲突,不要同时使用_fastcall和_asm。
一般情况下,可以在内嵌代码中修改 EAX、EBX、ECX和EDX,因为编译器并不期望在语句之间保留这些寄存器值。但是,如果修改的寄存器太多,那么编译器就无法对同一过程中的 C++代码进行完全优化,因为优化要用到寄存器。
虽然不能使用OFFSET运算符,但是用LEA指令也可以得到变量的偏移地址。比如,下面的指令将buffer 的偏移地址送人 ESI
lea esi,buffer
长度、类型和大小 内嵌汇编代码还可以使用LENGTHSIZE和TYPE运算符。LENGTH 运算符返回数组内元素的个数。按照不同的对象,TYPE 运算符返回值如下:
●对C或C++类型以及标量变量,返回其字节数。
●对结构,返回其字节数。
●对数组,返回其单个元素的大小。
SIZE运算符返回LENGTH*TYPE的值。下面的程序片段演示了内嵌汇编程序对各种C++类型的返回值。
Microsoft Visual C++内嵌汇编程序不支持 SIZEOF 和LENGHTOF 运算符。
使用 LENGTH、TYPE和 SIZE 运算符
下面程序包含的内嵌汇编代码使用LENGTH、TYPE 和SIZE 运算符对 C++变量求值。每个表达式的返回值都在同一行的注释中给出:
struct Package {long originZip //4long destinationZip //4float shippingPrice; //4
};
char myChar;
bool myBool;
short myShort;
int myInt;
long myLong;
float myFloat;
double myDouble;
Package myPackage;
long double myLongDouble;
long myLongArray[10];
__asm {mov eax, myPackage.destinationZipmov eax, LENGTH myInt; //1mov eax, LeNGTH myLongArray; //10mov eax, TYPE myChar; //1mov eax, TYPE myBool; //1mov eax, TYPE myShort; //2mov eax, TYPE myInt; //4mov eax, TYPE myLong; //4mov eax, TYPE myFloat; //4mov eax, TYPE myDouble; //8mov eax, TYPE myPackage; //12mov eax, TYPE myLongDouble; //8mov eax, TYPE myLongArray; //4mov eax, SIZE myLong; //4mov eax, SIZE myPackage; //12mov eax, SIZE myLongArray; //40
}13.2.2 文件加密示例
现在查看的简短程序实现如下操作:读取一个文件,对其进行加密,再将其输出到另一个文件。函数TranslateBuffer 用一个__asm 块定义语句,在一个字符数组内进行循环,并把每个字符与预定义值进行XOR 运算。内嵌语言可以使用函数形参、局部变量和代码标号。由于本例是由Microsoft Visual C++编译的 Win32控制台应用,因此其无符号整数类型为32 位;
void TranslateBuffer(char *buf, unsigned count, unsigned char eChar)
{__asm {mov esi, bufmov ecx, countmov al, eCharL1:xor [esi], alinc esiloop L1} //asm
}C++模块 C++启动程序从命令行读取输入和输出文件名。在循环内调用 TranslateBuffer从文件读取数据块,加密,再将转换后的缓冲区写入新文件:
头文件:
#pragma once // 防止头文件被重复包含, 非标准(但广泛支持)
//translat.h
void TranslateBuffer(char* buf, unsigned count,unsigned char eChar);调用源文件
//13.2.2 文件加密示例
//现在查看的简短程序实现如下操作:读取一个文件,对其进行加密,再将其输出到另一个文件。
#include <iostream>
#include <fstream>
#include "translat.h"
using namespace std;int main(int argcount, char *args[])
{//从命令行读取输入和输出文件if (argcount < 3) {cout << "Usage: encode infile outfile" << endl;return -1;}const int BUFSIZE = 2000;char buffer[BUFSIZE];unsigned int count; //字符计数unsigned char encryptCode;cout << "Encryption code [0-255]?";cin >> encryptCode;ifstream infile(args[1], ios::binary);ofstream outfile(args[2], ios::binary);cout << "Reading " << args[1] << " and creating "<< args[2] << endl;while(!infile.eof()) {infile.read(buffer, BUFSIZE);count = infile.gcount();TranslateBuffer(buffer, count, encryptCode);outfile.write(buffer, count);}return 0;
}用命令提示符运行该程序,并传递输入和输出文件名是最容易的。比如,下面的命令行读取infile.txt,生成encoded.txt:
encode infile.txt encoded.txt
在VS2019中设置命令行参数
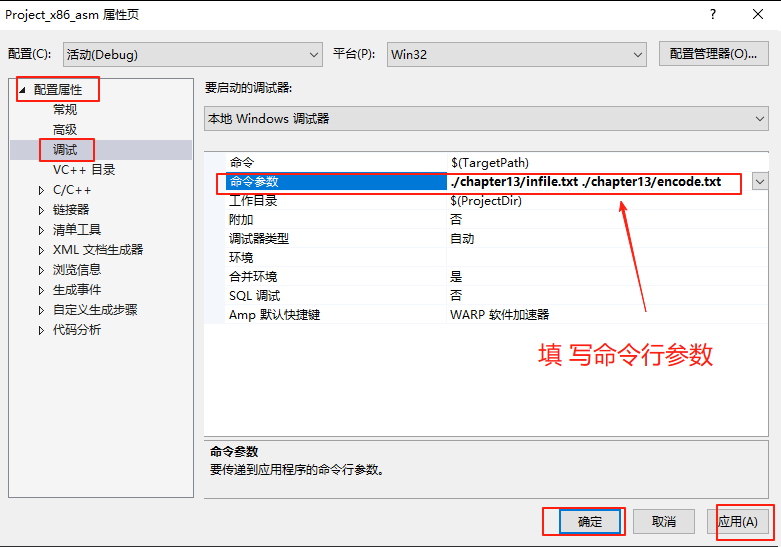
运行调试:

查看加密文件:

头文件 头文件translat.h包含了TanslateBuffer 的一个函数原型;
void TranslateBuffer(char* buf, unsigned count,unsigned char echar);
此程序位于本书\Examples\ch13\VisualCPP\Encode文件夹。
过程调用的开销
如果在调试器调试程序时查看Disassembly窗口,那么,看到函数调用和返回究竟有多少开销是很有趣的。下面的语句将三个实参送人堆栈,并调用 TranslateBuffer。在VisualC++的Disassembly 窗口,激活 Show Source Code和 Show Symbol Names 选项:
;TranslateBuffer(buffer, count, encryptCode)
movzx eax, byte ptr[encryptCode]
push eax
mov ecx, dword ptr [count]
push ecx
lea edx, [buffer]
push edx
call TranslateBuffer(0411834h)
add esp,0Ch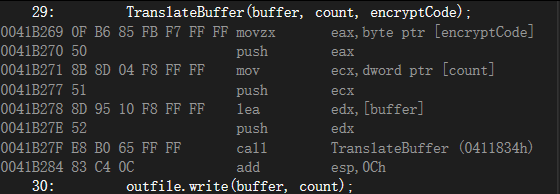
下面的代码对TranslateBuffer进行反汇编。编译器自动插人了一些语句用于设置EBP,以及保存标准寄存器集合,集合内的寄存器不论是否真的会被过程修改,总是被保存。
push ebp
mov ebp,esp
sub esp,0C0h
push ebx
push esi
push edi
mov edi,ebp
xor ecx,ecx
mov eax,0CCCCCCCCh
rep stos dword ptr es:[edi]
//代码内嵌从这里开始
mov esi,dword ptr [buf]
mov ecx,dword ptr [count]
mov al,byte ptr [eChar]
xor byte ptr [esi],al
L1:
xor [esi], al;
inc esi
loop L1 (041B460h)
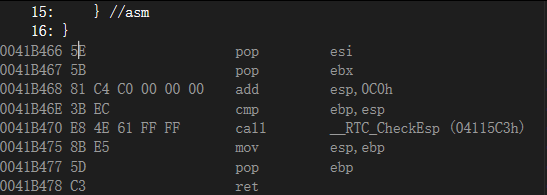
pop edi
//代码内嵌结束
pop esi
pop ebx
add esp,0C0h
cmp ebp,esp
call __RTC_CheckEsp (04115C3h)
mov esp,ebp
pop ebp
ret 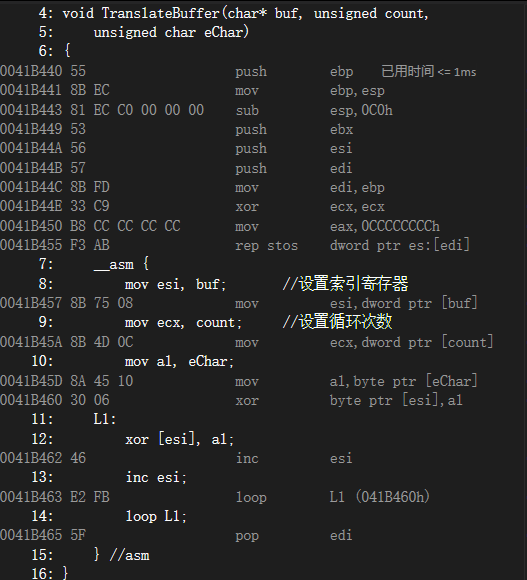
若关闭了调试器Disassembly窗口的Display Symbol Names 选项,则将参数送人寄存器的三条语句如下:
mov esi, dword ptr[ebp+8]
mov ecx, dword ptr [ebp+0ch]
mov al, byte ptr[ebp+10h]编译器按要求生成Debug目标代码,这是非优化代码,适合于交互式调试。如果选择Release 目标代码,那么编译器生成的代码就会更加有效(但易读性更差)。
忽略过程调用本小节开始时给出的TranslateBuffer中有6条内嵌指令,其执行总共需要8条指令。如果函数被调用几千次,那么其执行时间就比较可观了。为了消除这种开销,把内嵌代码插入调用TranslateBuffer的循环,得到更为有效的程序:
while(!infile.eof())
{infile.read(buffer, BUFFSIZE);count = infile.gcount();__asm {lea esi, buffer;mov ecx, count;mov al, encryptCode;L1:xor [esi],al;inc esi;loop L1;}//asmoutfile.write(buffer, count);}程序位于本书\Examples\ch13\VisualCPP\Encode Inline 文件夹。
13.2.3 本节回顾
1.内嵌汇编代码与内嵌C++过程有什么不同之处?
答:内嵌汇编代码是将汇编语言源代码直接插入高级语言程序。反之,c++中的内嵌限定符则要求c++编译器直接把函数体插入程序的编译代码,以便消除函数调用和返回所耗费的额外执行时间。(注意:回答这个问题需要用到本书并未涉及的一些c++语言知识。)
2.与使用外部汇编过程相比,内嵌汇编代码有什么优势?
答:编写内嵌代码的最大优点就是简单,因为它没有外部链接问题,命名哽,也不用考虑参数传递协议。其次,内嵌代码执行速度更快,因为它避免了汇编语言过程和返回通常所需要的额外执行时间。
3.给出至少两种在内嵌汇编代码中添加注释的方法。
答:注释示例:
mov esi, buf ;initialize index register
mov esi, buf //initialize index register
mov esi, buf /*initialize index register*/
4.(是/否):内嵌语言是否可以引用_asm块之外的代码标号?
答:是