ECCV 2024 论文解读丨具身智能、机器人研究最新突破创先点分享合集
关注gongzhonghao【计算机sci论文精选】
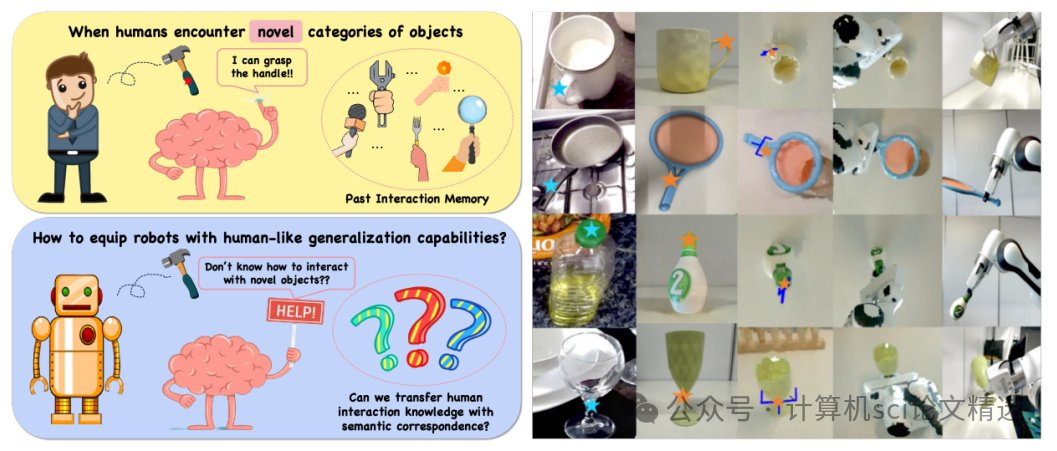
ECCV 机器人研究是当下智能装备领域的颠覆性进展,它整合了计算机视觉与自主控制的精髓,攻克了传统机器人在复杂环境中感知滞后、决策僵化的难题,达成了精度与适应性的同步飞跃
机器人这一领域不仅在工业制造、服务医疗等诸多场景中大显身手,在各大顶会顶刊的录用率也居高不下,简直是学术圈的 “热门焦点”!特别适合想产出高水平论文、推动技术落地的研究者。今天小图给大家精选3篇ECCV有关机器人模型方向的论文,请注意查收!
论文一:Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
方法:
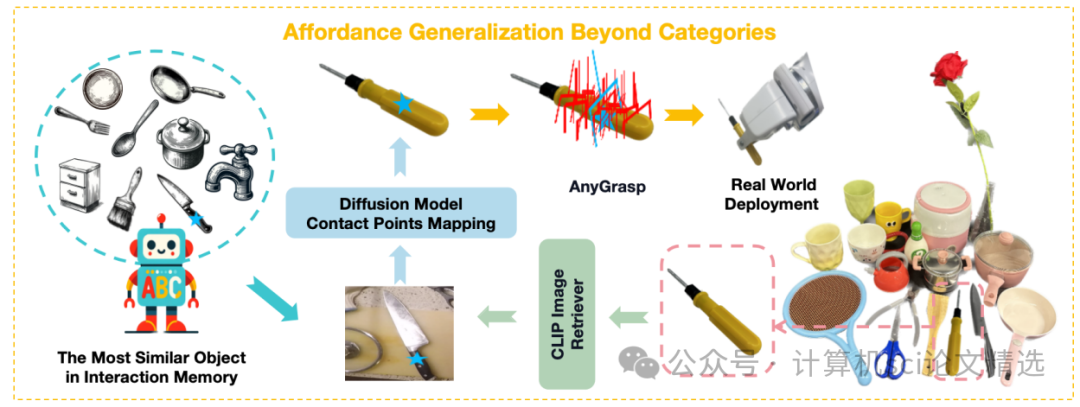
文章首先从人类视频中提取物体的交互经验并存储在操作记忆中,当面对新物体时,基于视觉和语义相似性从记忆中检索相似物体,然后利用扩散模型的语义对应能力将检索到的接触点映射到新物体上,最后结合AnyGrasp生成的抓取候选姿势,选择最接近的抓取姿势来指导机器人完成操作任务。
创新点:
提出了Robo-ABC框架,能够从人类视频中提取物体交互经验,无需额外标注、训练或先验知识。
在零样本泛化和跨类别泛化设置中,显著提高了与现有端到端方法相比的视觉操作检索成功率,提升了31.6%。
利用预训练扩散模型中的语义对应能力,实现了即使在不同类别物体之间也能进行操作映射,增强了机器人的泛化能力。
论文链接:
https://arxiv.org/abs/2401.07487
图灵学术论文辅导
论文二:Adapt2 Reward: Adapting Video-Language Models to Generalizable Robotic Rewards via Failure Prompts
方法:
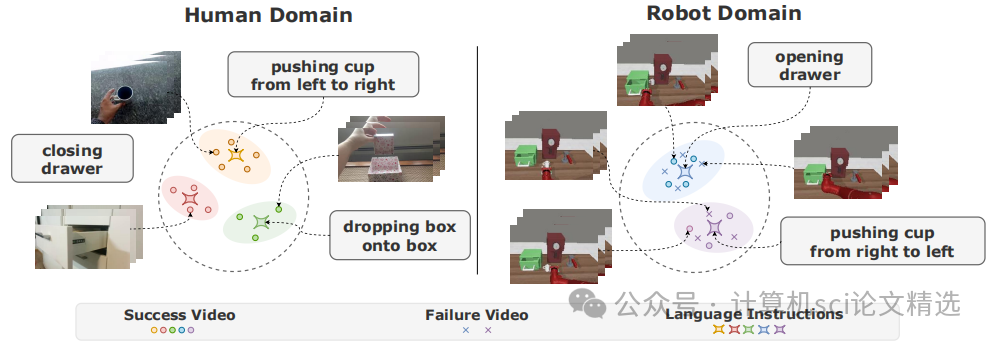
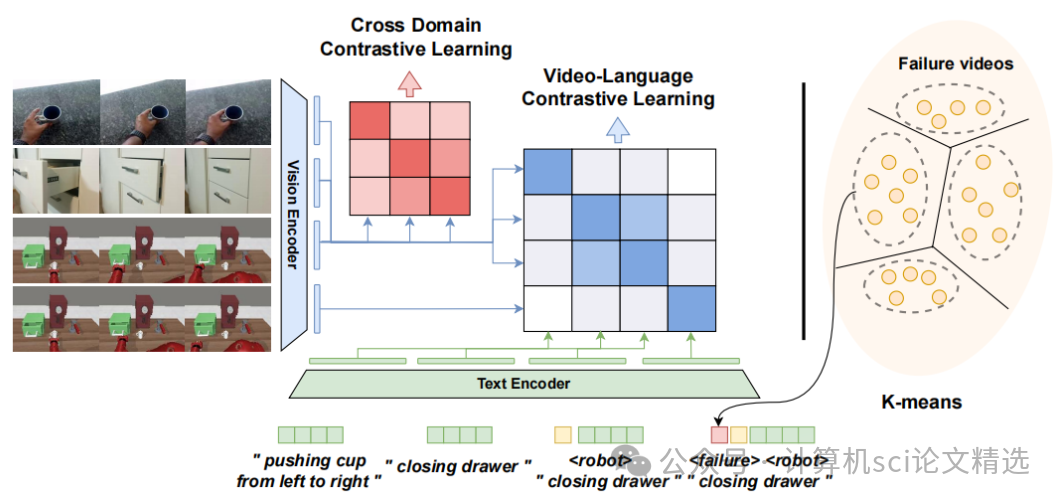
文章首先通过聚类失败视频来识别不同的失败模式,并为每个模式设计独特的失败提示,以增强模型对失败情况的理解。接着,利用跨域对比学习和视频-语言对比学习,对齐人类和机器人数据中的文本与视频表示,确保模型能够跨领域泛化。最后,结合视觉模型预测控制,将学习到的奖励函数应用于机器人任务规划和强化学习,实现了在新环境和新任务中的有效泛化。
创新点:
引入可学习的失败提示,通过聚类失败视频特征来识别失败模式,显著增强了模型对成功与失败执行的区分能力。
提出跨域对比学习方法,通过人类和机器人数据对齐文本和视频表示,有效弥合了两者之间的领域差异,提升了模型的泛化能力。
在多种模拟环境中验证了该方法的优越性,包括在MetaWorld和Concept2Robot环境中的任务泛化和环境泛化能力,证明了其在未见任务和环境中的高效适应性。
论文链接:
https://arxiv.org/abs/2401.07487
图灵学术论文辅导
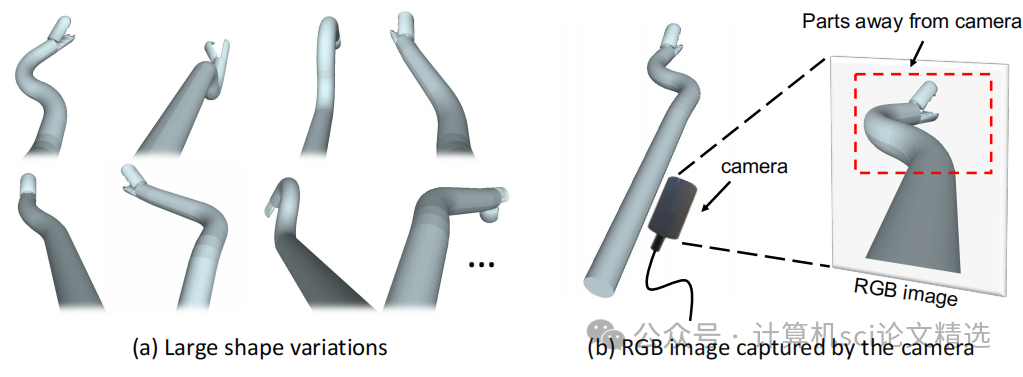
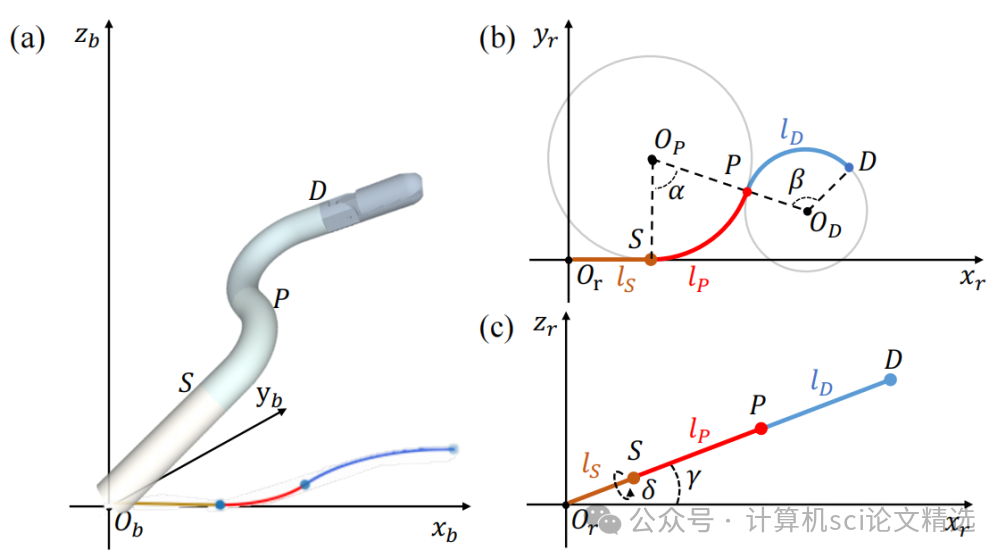
论文三:Shape-guided Configuration-aware Learning for Endoscopic-image-based Pose Estimation of Flexible Robotic Instruments
方法:
文章首先利用三维形状先验提取部分级别的几何表示,并通过查询图像特征来增强基于图像的机器人表示。然后,提出了一种有效的机制,根据初始柔性机器人姿态动态调整三维形状先验,以减少形状先验与图像中柔性机器人之间的差异。最后,通过矩阵费舍尔分布对柔性机器人姿态进行参数化,不仅实现了连续的学习空间,还能够恢复姿态不确定性。
创新点:
设计出形状引导的配置感知学习框架,利用柔性机器人的三维形状先验增强其基于图像的形状表示,显著提高了基于图像的姿态估计精度。
作者引入一种配置感知的形状变形机制,使用初始柔性机器人姿态将静态形状先验转换为动态形状先验,可用于柔性机器人姿态的精细化。
在内窥镜手术环境中对柔性机器人原型进行了广泛的实验,证明了该方法优于传统的基于关键点、骨架和直接回归的方法。
论文链接:
https://poseflex.github.io/
本文选自gongzhonghao【计算机sci论文精选】