【RocketMQ 生产者和消费者】- ConsumeMessageConcurrentlyService 并发消费消息
文章目录
- 1. 前言
- 2. submitConsumeRequest 提交消息消费请求
- 3. ConsumeRequest 消费请求
- 3.1 processConsumeResult 处理消费结果
- 3.2 removeMessage 将消息从本地缓存中删掉
- 4. 小结
本文章基于 RocketMQ 4.9.3
1. 前言
- 【RocketMQ】- 源码系列目录
- 【RocketMQ 生产者消费者】- 同步、异步、单向发送消费消息
- 【RocketMQ 生产者和消费者】- 消费者启动源码
- 【RocketMQ 生产者和消费者】- 消费者重平衡(1)
- 【RocketMQ 生产者和消费者】- 消费者重平衡(2)- 分配策略
- 【RocketMQ 生产者和消费者】- 消费者重平衡(3)- 消费者 ID 对负载均衡的影响
- 【RocketMQ 生产者和消费者】- 消费者的订阅关系一致性
- 【RocketMQ 生产者和消费者】- 消费者发起消息拉取请求 PullMessageService
- 【RocketMQ 生产者和消费者】- broker 是如何处理消费者消息拉取的 Netty 请求的
- 【RocketMQ 生产者和消费者】- broker 处理消息拉取请求
- 【RocketMQ 生产者和消费者】- 消费者处理消息拉取结果
前面讲了消费者如何处理消息返回结果,下面就是获取到消息的处理结果了,其中有一个步骤就是将消息提交给消费服务消费。
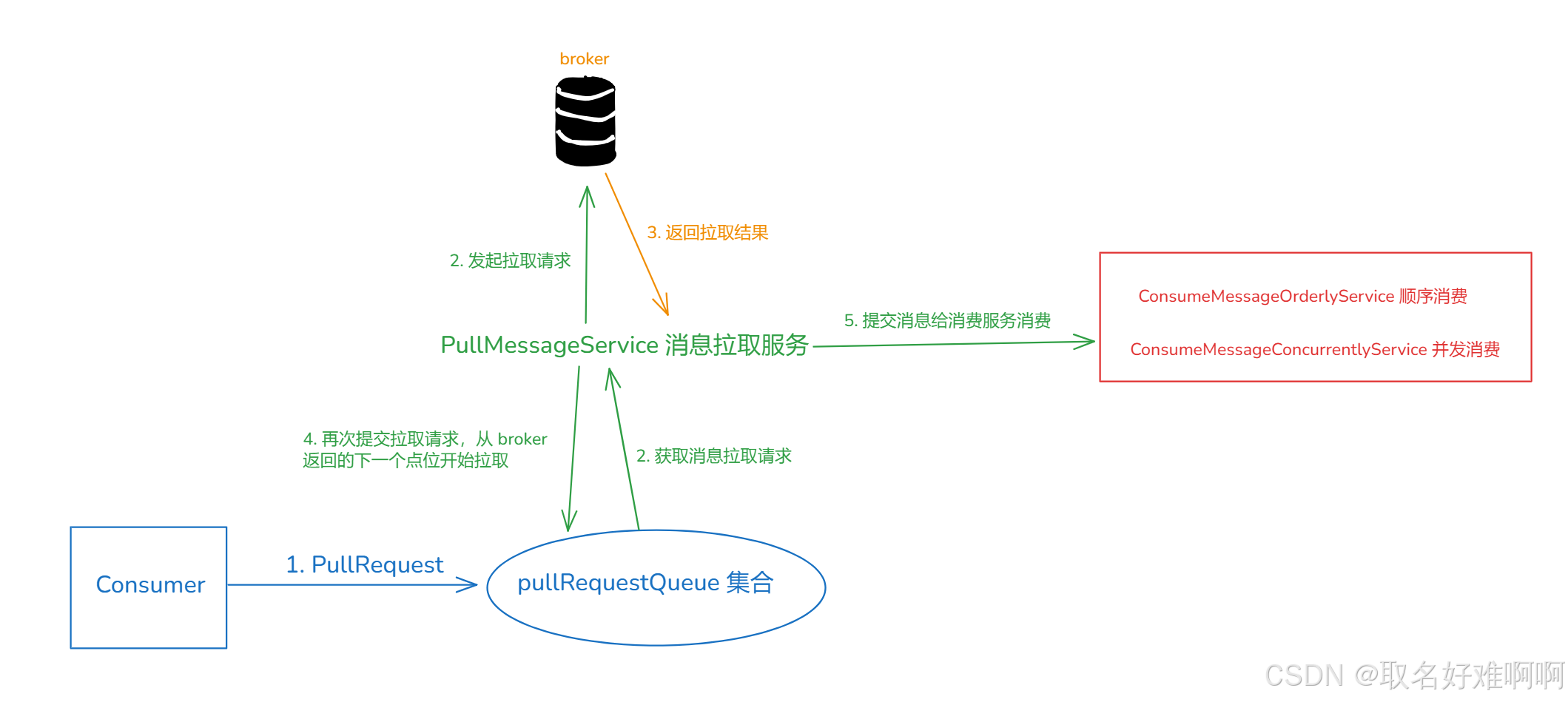
先来看下入口,就是下面这段代码。
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(pullResult.getMsgFoundList(),processQueue,pullRequest.getMessageQueue(),dispatchToConsume);
ConsumeMessageConcurrentlyService 用于处理并发消费,也就是不需要确保顺序性,因此在消息消费的时候是不需要加锁的。ConsumeMessageConcurrentlyService 也是通过线程池来处理消息,可以看到下面的代码,默认的并发消费线程池核心线程数和最大线程数都是 20,而 consumeRequestQueue 阻塞队列是无界的,没有限制大小。
// 并发消费的线程池, 核心线程数和最大线程数都是 20, 无界阻塞队列
this.consumeExecutor = new ThreadPoolExecutor(this.defaultMQPushConsumer.getConsumeThreadMin(),this.defaultMQPushConsumer.getConsumeThreadMax(),1000 * 60,TimeUnit.MILLISECONDS,this.consumeRequestQueue,new ThreadFactoryImpl(consumeThreadPrefix));
2. submitConsumeRequest 提交消息消费请求
下面具体进入到提交消息请求的入口方法,来看下是如何处理的,首先要明确一点就是消费者一次性消费的条数是有限的,可以通过消费者的 consumeMessageBatchMaxSize 参数设置,如果不设置,那么提交到线程池的消费请求一次只会消费一条消息。
如果拉取到的消息数量超过了 consumeMessageBatchMaxSize,就会分批添加到线程池里面去处理。
/*** 提交并发消费请求* @param msgs 消费者拉取到的消息* @param processQueue 处理队列* @param messageQueue 消息队列* @param dispatchToConsume 是否分发给消费者去消费, 并发消费没影响, 顺序消费下因为要考虑顺序性才需要考虑这个参数*/
@Override
public void submitConsumeRequest(final List<MessageExt> msgs,final ProcessQueue processQueue,final MessageQueue messageQueue,final boolean dispatchToConsume) {// 一次性可以批量消费多少条消息, 默认是 1final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();// 如果消息数比这小if (msgs.size() <= consumeBatchSize) {// 构建 ConsumeRequest 请求ConsumeRequest consumeRequest = new ConsumeRequest(msgs, processQueue, messageQueue);try {// 直接提交到线程池中去消费this.consumeExecutor.submit(consumeRequest);} catch (RejectedExecutionException e) {// 请求太多了就延迟 5s 再提交this.submitConsumeRequestLater(consumeRequest);}} else {// 消息数比较多, 由于一次性最多只能消费 consumeBatchSize 条, 所以按 consumeBatchSize 分批提交for (int total = 0; total < msgs.size(); ) {// 一批消息集合, 大小是 consumeBatchSizeList<MessageExt> msgThis = new ArrayList<MessageExt>(consumeBatchSize);// 按顺序添加 consumeBatchSize 条消息到 msgThis 中for (int i = 0; i < consumeBatchSize; i++, total++) {if (total < msgs.size()) {msgThis.add(msgs.get(total));} else {break;}}// 提交到线程池去执行消费ConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue);try {this.consumeExecutor.submit(consumeRequest);} catch (RejectedExecutionException e) {for (; total < msgs.size(); total++) {msgThis.add(msgs.get(total));}// 被线程池拒绝了就延迟 5s 再提交, 任务太多了this.submitConsumeRequestLater(consumeRequest);}}}
}
如果线程池满了,执行了拒绝策略,这种情况下会重新延迟添加,一般也不会,队列大小都是 Integer.MAX_VALUE。
3. ConsumeRequest 消费请求
最终消费的核心逻辑就是在 ConsumeRequest 完成的,这个类的属性就三个:msgs、processQueue、messageQueue,processQueue 就是消息队列对应的处理队列。
下面来看下里面的 run 方法,首先判断如果处理队列是 dropped, 也就是被丢弃的状态, 就不消费了,这就对应上一篇文章说的,如果 offset 不在消息队列的消息范围内,也就是返回 OFFSET_ILLEGAL 的时候,那么就会将这个消息队列对应的处理队列设置为 dropped,后续就不会再消费了。
// 如果处理队列是 dropped, 也就是被丢弃的状态, 就不消费了
if (this.processQueue.isDropped()) {log.info("the message queue not be able to consume, because it's dropped. group={} {}", ConsumeMessageConcurrentlyService.this.consumerGroup, this.messageQueue);return;
}
接下来获取并发消费的监听器,这个就是消费者消费的时候设置的,用户自定义。然后如果是重传 topic,就将这条消息的 topic 还原为原始的 topic。消费者消费失败会把消息添加到重传 topic 队列中,然后消费者消费重传消息时在这里还原回真实 topic ,后面继续往真实的 topic 队列里面添加。
// 1. 首先获取下并发消费的消息监听器, 这个监听器就是用户自己设置的, 在里面去设置消费的逻辑
MessageListenerConcurrently listener = ConsumeMessageConcurrentlyService.this.messageListener;
ConsumeConcurrentlyContext context = new ConsumeConcurrentlyContext(messageQueue);
ConsumeConcurrentlyStatus status = null;
// 如果消息是重传消息, 将这条消息的 topic 设置为原始 topic
defaultMQPushConsumerImpl.resetRetryAndNamespace(msgs, defaultMQPushConsumer.getConsumerGroup());
然后是消费前置钩子判断,做一些前置操作,也是可以在创建消费者的时候通过 registerConsumeMessageHook 方法去注册钩子。
// 2. 如果设置了消费钩子, 就调用 ConsumeMessageHook#consumeMessageBefore
ConsumeMessageContext consumeMessageContext = null;
if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {consumeMessageContext = new ConsumeMessageContext();consumeMessageContext.setNamespace(defaultMQPushConsumer.getNamespace()); // 命名空间consumeMessageContext.setConsumerGroup(defaultMQPushConsumer.getConsumerGroup()); // 消费者组consumeMessageContext.setProps(new HashMap<String, String>()); // 消息属性consumeMessageContext.setMq(messageQueue); // 消息队列consumeMessageContext.setMsgList(msgs); // 消息consumeMessageContext.setSuccess(false); // 是否消费成功ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.executeHookBefore(consumeMessageContext);
}
接下来消费所有消息,也就是在 for 循环里面去消费。
// 起始时间
long beginTimestamp = System.currentTimeMillis();
boolean hasException = false;
// 消费的结果类型, 默认是 SUCCESS, 就是消费成功
ConsumeReturnType returnType = ConsumeReturnType.SUCCESS;
try {if (msgs != null && !msgs.isEmpty()) {for (MessageExt msg : msgs) {// 遍历消息, 设置每一条消息的消费的起始时间MessageAccessor.setConsumeStartTimeStamp(msg, String.valueOf(System.currentTimeMillis()));}}// 3. 调用消费监听器的 consumeMessage 方法, 里面也是我们自定义的消费逻辑, 返回结果就是 ConsumeReturnType 类型status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {log.warn(String.format("consumeMessage exception: %s Group: %s Msgs: %s MQ: %s",RemotingHelper.exceptionSimpleDesc(e),ConsumeMessageConcurrentlyService.this.consumerGroup,msgs,messageQueue), e);// 出现异常, 设置异常标志位hasException = true;
}
// 消费时间
long consumeRT = System.currentTimeMillis() - beginTimestamp;
这个 consumeMessage 就是业务自己定义的消费逻辑,status 是返回结果,下面就是对这个返回结果做判断,分成了几种情况:没有结果、消费超时、业务返回消费失败、业务返回消费成功。
// 4. 处理消费的返回结果
if (null == status) {if (hasException) {// 异常标记returnType = ConsumeReturnType.EXCEPTION;} else {// 什么都没有返回returnType = ConsumeReturnType.RETURNNULL;}
} else if (consumeRT >= defaultMQPushConsumer.getConsumeTimeout() * 60 * 1000) {// 消费时间超过 15 分钟, 消费超时了returnType = ConsumeReturnType.TIME_OUT;
} else if (ConsumeConcurrentlyStatus.RECONSUME_LATER == status) {// 消费失败, 稍后尝试重新消费returnType = ConsumeReturnType.FAILED;
} else if (ConsumeConcurrentlyStatus.CONSUME_SUCCESS == status) {// 消费成功returnType = ConsumeReturnType.SUCCESS;
}
这个 returnType 是用来设置回消费钩子的属性的,至于后面是不是需要重试,最终还是判断 status。
// 设置了消费者钩子, 就将消费结果设置到钩子的 ConsumeContextType 属性中
if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {consumeMessageContext.getProps().put(MixAll.CONSUME_CONTEXT_TYPE, returnType.name());
}// 如果返回结果为空, 消费出异常了
if (null == status) {log.warn("consumeMessage return null, Group: {} Msgs: {} MQ: {}",ConsumeMessageConcurrentlyService.this.consumerGroup,msgs,messageQueue);// 消息消费失败, 稍后重新消费status = ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
最后如果设置了消费钩子,调用 consumeMessageAfter 方法,后置处理,然后统计消费时间,最后处理消费结果,也是消费重传的处理逻辑。
// 5. 如果设置了消费钩子, 就调用 ConsumeMessageHook#consumeMessageAfter
if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {// 因为已经消费了, 所以这里可以设置消费状态以及是否消费成功consumeMessageContext.setStatus(status.toString());consumeMessageContext.setSuccess(ConsumeConcurrentlyStatus.CONSUME_SUCCESS == status);ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.executeHookAfter(consumeMessageContext);
}// 6. 统计增加消费时间
ConsumeMessageConcurrentlyService.this.getConsumerStatsManager().incConsumeRT(ConsumeMessageConcurrentlyService.this.consumerGroup, messageQueue.getTopic(), consumeRT);// 7. 处理消费结果, 在里面会去重新消费
if (!processQueue.isDropped()) {ConsumeMessageConcurrentlyService.this.processConsumeResult(status, context, this);
} else {log.warn("processQueue is dropped without process consume result. messageQueue={}, msgs={}", messageQueue, msgs);
}
3.1 processConsumeResult 处理消费结果
/*** 处理消费结果* @param status 消费状态* @param context 上下文* @param consumeRequest 消费请求*/
public void processConsumeResult(final ConsumeConcurrentlyStatus status,final ConsumeConcurrentlyContext context,final ConsumeRequest consumeRequest
) {...}
首先处理消费成功的逻辑,先获取 ackIndex,这个属性意思是消费成功的消息的索引,由消费者业务逻辑设定,可以在消费成功一条消息之后就设置为对应的下标,比如下面的写法。
consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {for (int i = 0; i < msgs.size(); i++) {MessageExt msg = msgs.get(i);System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), new String(msg.getBody(), StandardCharsets.UTF_8));context.setAckIndex(i);}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}
});
这个参数用于统计有多少条消息是成功消费了的,当然你不设置默认是 Integer.MAX_VALUE,也就是默认全部消息都消费成功,不过这个应该是配合前面的 consumeMessageBatchMaxSize 来使用的,因为默认一个线程任务一次只会消费一条消息,所以这里设置不设置应该都没有问题,但是如果设置了 consumeMessageBatchMaxSize,那么一次性就会消费多条消息,这种情况下还是设置比较好。
消费成功的逻辑就是分别统计下消费成功的消息条数和消费失败的条数。
// 消费成功的消息在集合中的索引, 默认是 Integer.MAX_VALUE
int ackIndex = context.getAckIndex();// 如果消息为空就直接返回
if (consumeRequest.getMsgs().isEmpty())return;switch (status) {case CONSUME_SUCCESS:// 消费成功, ackIndex 设置成消息的最后一条的索引if (ackIndex >= consumeRequest.getMsgs().size()) {ackIndex = consumeRequest.getMsgs().size() - 1;}// ok 就是索引 + 1, 意思是消费成功的消息数int ok = ackIndex + 1;// 这里就是消费失败的数了, 就是 0int failed = consumeRequest.getMsgs().size() - ok;// 统计增加消费成功数this.getConsumerStatsManager().incConsumeOKTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), ok);// 统计增加消费失败数this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), failed);break;
然后就是消费失败,比如业务返回 ConsumeConcurrentlyStatus.RECONSUME_LATER,又或者业务处理的时候出异常了,这种情况在上面 run 方法也会设置为 ConsumeConcurrentlyStatus.RECONSUME_LATER,这时候就需要失败重试了,先设置 ackIndex = -1,然后统计下消费失败的条数,后面会从 ackIndex + 1 位置开始重复消费。
case RECONSUME_LATER:// 消费失败ackIndex = -1;// 统计消费失败的消息条数this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(),consumeRequest.getMsgs().size());break;
default:break;
下面开始处理消费失败的消息,首先是 广播模式,这种情况下由于每一条消息会发送给这个消费者组下面的所有消费者去消费,所以不需要重试,直接打印下日志就行了,说不定其他消费者就消费成功了呢,这种消费模式下对于幂等性应该没有太多要求。
// 判断消息的消费模式, 处理消费失败的情况, 为什么是消费失败的情况呢, 因为下面遍历的时候如果消费成功 ackIndex + 1 = consumeRequest.getMsgs().size()
// 只有消费失败才会从 0 开始遍历
switch (this.defaultMQPushConsumer.getMessageModel()) {case BROADCASTING:// 广播模式下打印消费失败的消息for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {MessageExt msg = consumeRequest.getMsgs().get(i);log.warn("BROADCASTING, the message consume failed, drop it, {}", msg.toString());}break;case CLUSTERING:// 集群模式下, 从 ackIndex + 1 开始遍历所有消息List<MessageExt> msgBackFailed = new ArrayList<MessageExt>(consumeRequest.getMsgs().size());for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {// 获取消费失败的消息MessageExt msg = consumeRequest.getMsgs().get(i);// 将消息重新发送到重试队列, 重试队列会有延时等级, 就是延时消息boolean result = this.sendMessageBack(msg, context);// 如果发送失败, 发送异常if (!result) {// 重试次数 + 1msg.setReconsumeTimes(msg.getReconsumeTimes() + 1);// 再次添加到发送失败的队列中msgBackFailed.add(msg);}}if (!msgBackFailed.isEmpty()) {// 将发送失败的消息从 msgs 中删掉consumeRequest.getMsgs().removeAll(msgBackFailed);// 延迟 5s 再次将发送失败的消息重新提交到线程池去消费this.submitConsumeRequestLater(msgBackFailed, consumeRequest.getProcessQueue(), consumeRequest.getMessageQueue());}break;default:break;
}
但是如果是 集群模式 下,消费失败就要从 ackIndex + 1 开始看看要不要重新消费了,如果需要重新消费,就调用 sendMessageBack 方法将消息重新发送到重试队列,重试队列会有延时等级, 就是延时消息,所以这里先看下发送过程,至于是怎么处理的,后面等写到延时消息那块再来细看里面的源码。
注意下上面的流程,如果说发送失败了,出异常,那么相当于本次重试失败了,重试次数会 + 1,然后继续延迟 5s 再次将发送失败的消息重新提交到线程池去消费。
最后当处理完这块的逻辑,从处理队列的 msgTreeMap 中将消费成功和消费失败但是已经成功发送到 broker 的重传 topic 的消息给删掉,同时返回结果是删掉这批消息之后的 msgTreeMap 的最小偏移量。
// 从处理队列的 msgTreeMap 中将消费成功和消费失败但是已经成功发送到 broker 的重传 topic 的消息给删掉
// 同时返回结果是删掉这批消息之后的 msgTreeMap 的最小偏移量
long offset = consumeRequest.getProcessQueue().removeMessage(consumeRequest.getMsgs());
然后更新本地 offsetTable,之前的文章也说了,offsetTable 存储的是这个队列下一条要处理的消息的偏移量,也就是在 ConsumeQueue 中的索引位置,msgTreeMap 用于存储没有消费的消息集合,是一个 TreeMap 类型的集合,key 是偏移量,所以直接返回最小偏移量就行。
// 更新内存中的 offsetTable 中的最新偏移量
if (offset >= 0 && !consumeRequest.getProcessQueue().isDropped()) {this.defaultMQPushConsumerImpl.getOffsetStore().updateOffset(consumeRequest.getMessageQueue(), offset, true);
}
3.2 removeMessage 将消息从本地缓存中删掉
/*** 将 msgs 从 msgTreeMap 中删掉, 并且返回第一条消息的偏移量* @param msgs* @return*/
public long removeMessage(final List<MessageExt> msgs) {long result = -1;final long now = System.currentTimeMillis();try {// 加写锁this.treeMapLock.writeLock().lockInterruptibly();// 更新上一次消费的时间this.lastConsumeTimestamp = now;try {if (!msgTreeMap.isEmpty()) {// 返回结果默认设置成最大偏移量 + 1result = this.queueOffsetMax + 1;int removedCnt = 0;// 遍历所有要移除的消息for (MessageExt msg : msgs) {MessageExt prev = msgTreeMap.remove(msg.getQueueOffset());// 移除成功if (prev != null) {// 移除的消息数 - 1removedCnt--;// 缓存中的消息大小减去移除的消息大小msgSize.addAndGet(0 - msg.getBody().length);}}// 减去移除的消息条数msgCount.addAndGet(removedCnt);if (!msgTreeMap.isEmpty()) {// 如果缓存里面还有消息, 就返回第一条消息的偏移量result = msgTreeMap.firstKey();}}} finally {// 解除写锁this.treeMapLock.writeLock().unlock();}} catch (Throwable t) {log.error("removeMessage exception", t);}// 返回结果return result;
}
为了避免并发写入删除出问题,先加个本地写锁,然后将消息从缓存中删掉,同时更新 msgSize 和 msgCount,分别表示本地存储的消息大小和消息条数。如果消息最后都删完了,表示这个集合里面的消息都是消费过的,这种情况下返回的偏移量就是原来的最大偏移量 + 1。而如果这个缓存里面没有消息,就返回 -1,外层就不会更新本地 offsetTable。
4. 小结
这篇文章讲述了 ConsumeMessageConcurrentlyService 是如何并发消费消息的,下一篇文章就再来看下 ConsumeMessageOrderlyService 如何消费顺序消息。
如有错误,欢迎指出!!!!