Datawhale AI夏令营第三期,多模态RAG方向 Task2
1.基础知识
1.1什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。
一文彻底搞懂大模型 - RAG(检索、增强、生成)
1.2什么是向量数据库?
定义
向量数据库也叫矢量数据库,是一种以数学向量的形式存储数据集合的数据库。更通俗的说法,向量就是一个数字列表,例如:[12, 13, 19, 8, 9]。这些数字表示维度空间中的一个位置,代表在这个维度上的特征。就像行和列号表示电子表格中特定单元格一样(例如,“A10”表示 A 列 10 行)。向量数据库的应用是使机器学习模型更容易记住先前的输入,从而使机器学习能够用于支持搜索、推荐和内容生成等应用场景。向量数据可以基于相似性搜索进行识别,而不是精确匹配,使计算模型能够在上下文中理解数据。
什么是向量?
向量是一组有序的数值,表示在多维空间中的位置或方向。向量通常用一个列或行的数字集合来表示,这些数字按顺序排列。在机器学习中,向量可以表示诸如单词、图像、视频和音频之类的复杂对象,由机器学习(ML)模型生成。高维度的向量数据对于机器学习、自然语言处理(NLP)和其他人工智能任务至关重要。一些向量数据的例子包括:
- 文本:想象一下你上次与聊天机器人互动的情景。它们是如何理解自然语言的呢?它们依赖于可以表示单词、段落和整个文档的向量,这些向量是通过机器学习算法转换而来的。
- 图像:图像的像素可以用数字数据描述,并组合成构成该图像的高维向量。
- 语音/音频:与图像类似,声波也可以分解为数字数据,并表示为向量,从而实现声音识别等人工智能应用。
向量数据库的兴起
向量数据库的兴起主要源于大模型 embedding 的应用。Transformer作为当今大模型的基础架构,在数据输入时需要对输入做 embedding, 由于当时主要是处理文本,所以这个 embedding 要做的就是词嵌入(word embedding),把文本转化为向量。由于大模型使用海量数据,数据的维度一般大于 1000 以上,所以临时或永久存储和计算(检索)这些高维向量数据就成了一个难题,这也是向量数据库崛起的一个主要原因。另一个方面,将人的输入以向量的方式临时存储起来,也可以提高类 chatgpt 应用的性能,让人觉得 ai 是有记忆的,可以检索历史问过的相关问题。想要自己试一试 embedding 的应用吗?可以试试 openai 的embedding api, 通过这个 api, 你的一个文本输入将会转化为多维向量。
(53 封私信) 什么是向量数据库 Vector Database? - 知乎
2.理解赛题
2.1任务背景
目前多模态信息(财报PDF)的AI利用率较低
近年来,大语言模型(LLM)的崛起为自然语言理解带来了革命。然而,它们也面临两大挑战:
-
知识局限性 :LLM的知识是预训练好的,对于私有的、最新的或特定领域的文档(比如本次比赛的财报)一无所知,并且可能产生幻觉。
-
模态单一性 :大多数LLM本身只能处理文本,无法直接“看到”和理解图像。
检索增强生成(RAG) 技术的出现,通过从外部知识库中检索信息来喂给LLM,有效地解决了第一个挑战。而本次比赛的核心—— 多模态检索增强生成(Multimodal RAG) ,则是应对这两大挑战的前沿方案。它赋予了AI系统一双“眼睛”,让他不仅能阅读文字,还能看懂图片,并将两者结合起来进行思考和回答。
2.2四大核心要素
- 数据源:财报数据库.zip 这个压缩包里的PDF文件
- 可溯源:必须明确指出答案的出处
- 多模态:问题可能需要理解文本,也可能需要理解图表(图像)
- 问答:根据检索的信息生成一个回答
3.任务要求和重难点
3.1输入与输出
输入
| 财报数据库.zip | 一个包含了多个PDF文件的压缩包。这些PDF是真实世界的公司财报,内容上是典型的 图文混排 格式,包含了大量段落、数据表格以及各种图表(如条形图、饼图、折线图等)。这是我们系统的 唯一信息来源 。所有问题的答案都必须从这些PDF文档中寻找,并且不能依赖任何外部知识。 |
|
| 一个JSON格式的文件,为我们提供了一系列“问题-答案”的范例。这是我们用来开发、训练和验证我们系统模型的主要依据。我们可以通过它来调试我们的算法,看看对于给定的问题,我们的系统能否找到正确的答案和出处。 [ |
| test.json | 另一个JSON格式的文件,包含了比赛最终用来评测我们系统性能的所有问题。 这是我们需要完成的任务。文件里 只包含 [ |
输出
我们的最终任务是为 test.json 中的每一个问题,预测出三个信息: 答案 ( answer ) 、 来源文件名 ( filename ) 和 来源页码 ( page ) 。
| 提交文件格式 | 官方要求我们将所有预测结果整理成一个 JSON 文件 进行提交。官方提供了 这个文件应该包含以下一个列表(列名以
|
| 提交文件示例 ( | [ { "filename": "xx.pdf", "page": 1, "question": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?", "answer": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?" }, …… ] |
3.2分析赛题数据
我们需要思考如何提取PDF里面的数据,主要可以考虑两个工具——
-
pymupdf:基于规则的方式提取pdf里面的数据, -
mineru:基于深度学习模型通过把PDF内的页面看成是图片进行各种检测,识别的方式提取。
3.3四大难点
- 多模态信息的有效融合
- 检索的准确性与召回率平衡
- 答案生成的可控性与溯源精确性
- 针对性评估指标的优化
3.4思考过程
第一步:从“终点”反推“起点”——快速明确核心任务
为每一个 question ,都精准地提供 answer 、 filename 和 page
为了生成这样的提交结果,我的系统内部就必须构建并维护一个大概包含以下元素的核心数据结构:
{ "content": "内容文本或描述", "metadata": { "filename": "来源文件名.pdf", "page": 页码 } }
这个结构是后续所有工作的基础。
同时, content 字段需要被转换成机器能够理解和搜索的形式,为了方便后续召回, 向量化(Embedding)字段选择的是content 。
第二步:技术方案的权衡与选择
多模态方案选择
为了优先保证能跑通一个完整的流程,我选择了 第一种方案:基于图片描述 。它的优点是实现简单、逻辑清晰,能让我快速验证整个RAG(检索增强生成)链路。
具体工具栈调研 :
-
PDF解析 :这个环节我们选择的mineru,但是task1里面为了降低大家的学习门槛,使用的是pymupdf作为平替方案。
-
Embedding实现 :我最初考虑使用
sentence-transformer库。但在进一步查阅资料时,我发现了Xinference,它能将模型部署为服务,并通过兼容OpenAI的API来调用。我立即决定采用这种方式,因为 服务化能让我的Embedding模块与主应用逻辑解耦,更利于调试和未来的扩展。
第三步:构建Baseline执行流程
-
预处理(离线完成) :
-
使用pymupdf批量解析所有PDF文档,得到结构化的JSON数据。
-
将原始的文本块,以及图片的描述文本,附带上它们的元数据(
filename,page),构造成我们第一步设计的核心数据结构。 -
调用
Xinference部署的Embedding模型服务,将所有内容的文本部分转换为向量。 -
将最终的
{ "id":"……","content": "...", "vector": [...], "metadata": ... }存入向量数据库,完成知识库构建。
-
-
在线推理 :
-
接收测试集的json文件中的一个
question。 -
调用
Xinference服务,将question向量化。 -
在向量数据库中进行相似度搜索,召回Top-K个最相关的内容块。
-
将召回的内容块及其元数据,与
question一同填入设计好的Prompt模板中。 -
将完整的Prompt交给一个大语言模型(LLM),生成最终的答案和来源信息。
-
4.baseline详解
4.1文件概况
| 文件名 | 作用简介 |
| fitz_parse_pdf.py | 一键式数据处理主脚本,自动完成 PDF 解析、内容结构化、分块合并 |
| rag_from_page_chunks.py | RAG 检索与问答主脚本,支持向量检索与大模型生成式问答 |
| get_text_embedding.py | 文本向量化,支持批量处理 |
| extract_json_array.py | 从大模型输出中提取 JSON 结构,保证结果可解析 |
| all_pdf_page_chunks.json | 所有 PDF 分页内容的合并结果,供 RAG 检索 |
| .env | 环境变量配置文件,存放 API 密钥、模型等参数 |
| caches/ | 预留目录(可选) |
| datas/ | 原始 PDF 文件及测试集存放目录 |
| data_base_json_content/ | PDF 解析后的内容列表(中间结果) |
| data_base_json_page_content/ | 分页后的内容(中间结果) |
| output/ | 其他输出文件目录 |
4.2方案思路
| 阶段一:离线预处理 (构建知识库)
|
|
|
|
| |
| 阶段二:在线推理 (生成答案)
|
|
|
|
| |
|
|
4.3核心逻辑
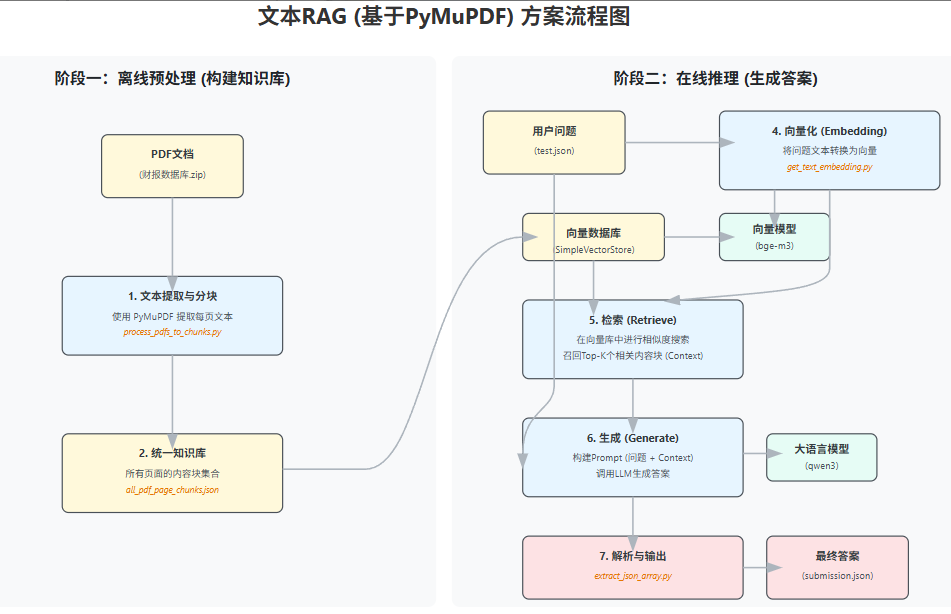
阶段一:离线预处理 (构建知识库) - fitz_pipeline_all.py
这个脚本是整个数据流水线的核心,用来提取pdf里面的数据成纯文本的内容, process_pdfs_to_chunks() :
-
作用 : 汇总所有PDF的按页内容,整合成一个统一的知识库文件。
-
数据结构 : 每个页面被构造成一个 "chunk"(知识块),包含ID、内容和元数据。
{
"id": "广联达2022年年度报告_page_34",
"content": "# 第三节 管理层讨论与分析...", // 该页的Markdown内容
"metadata": {
"page": "34",
"file_name": "广联达2022年年度报告.pdf"
}
}
项目根目录下的 all_pdf_page_chunks.json ,这是我们RAG系统的最终知识库。
阶段二:在线推理 (生成答案) - rag_from_page_chunks.py
这个脚本负责实现RAG的检索和生成两大核心功能,主要通过 SimpleRAG 类完成。
-
SimpleRAG.setup():-
作用 : RAG系统的初始化。
-
步骤 :
-
加载
all_pdf_page_chunks.json里的所有知识块。 -
调用
EmbeddingModel(其核心是get_text_embedding.py),将每个知识块的content文本批量转换为向量。 -
将知识块和它们对应的向量存入
SimpleVectorStore(一个简单的内存向量数据库) 中。
-
-
-
SimpleRAG.generate_answer():-
作用 : 针对一个问题,执行完整的“检索-生成”流程。
-
步骤 :
-
查询向量化 : 将输入的问题
question同样转换为向量。 -
信息检索 : 在
SimpleVectorStore中进行相似度搜索,找出与问题向量最相似的 Top-K 个知识块。 -
构建Prompt : 这是最关键的环节之一。脚本将用户的原始问题和检索到的Top-K个知识块(包含内容和元数据)一同填入一个Prompt模板中。这个模板会明确指示LLM:
-
扮演一个专业角色(金融分析助手)。
-
必须依据提供的上下文(检索到的知识块)来回答。
-
必须严格按照指定的JSON格式输出
{"answer": "...", "filename": "...", "page": "..."}。
-
-
调用LLM生成 : 将构建好的Prompt发送给大语言模型(如Qwen)。
-
解析与格式化 : 调用
extract_json_array.py工具,从LLM返回的可能混杂着其他文本的输出中,稳定地提取出JSON对象,并整理成最终的答案格式。
-
-
5.上分思路
- 分块策略 (Chunking Strategy):目前是按“页”分块,这样做简单但粗糙。是否可以尝试更细粒度的分块
- 检索优化 (Retrieval Optimization):可以引入重排(Re-ranking)模型吗?即在初步检索(召回)出20个候选块后,用一个更强的模型对这20个块进行重新排序,选出最相关的5个。
- Prompt工程 (Prompt Engineering):如何更清晰地指示LLM在多个来源中选择最精确的那一个?如何让它在信息不足时回答“根据现有信息无法回答”,而不是产生幻觉?
- 多模态融合 (Multimodal Fusion):多路召回,即文本问题同时去检索文本库和图片库(使用CLIP等多模态向量模型),将检索到的文本和图片信息都提供给一个多模态大模型(如Qwen-VL),让它自己去融合信息并作答。
- 升级数据解析方案:从
fitz到MinerU。MinerU可以对PDF进行深度的版面分析,除了能更精准地提取文本块外,还具备以下功能:识别表格 :将表格转化为结构化的Markdown或JSON格式。提取图片 :对文档中的图片进行识别。图片描述 :(可选)调用多模态模型为提取出的图片生成文字说明。
6.总结与心得
首先是理解了题目中的要点,怎么处理pdf,怎么读里面的文字和图片,图片有三种方法,一个是生成文字描述,一个文字和图片分别向量化,还有一个是直接用多模态的模型,然后要做一个问答的模型,输出的数据是给一个问题的答案,然后要溯源,给出页码还有文件名。大概是知道了什么是rag,什么是向量数据库,这是最近看面经存下的疑问,带着问题找答案,对rag的整个流程,检索增强生成,就是生成一个自己的数据库,然后问题在里面检索,获取到的信息加入prompt里,生成内容。知道了baseline的流程,是先构建知识库,然后检索生成。上分思路是,提取图片用mineru;更细的分块;检索过来怎么判断有没有噪音,要不要重排;优化提示词;融合文字和图片库,用多模态llm进行生成。
总结与心得(优化版)
通过这次赛题学习,我对任务要求和核心技术有了更清晰的理解。
首先,题目要求我们从财报 PDF(图文混排)中,针对给定问题生成答案,并且做到可溯源——不仅要回答问题,还要提供答案所在的文件名和页码。这意味着我们必须同时处理文本和图像信息。
在处理 PDF 时,文本部分可以直接解析提取,而图片则有三种处理思路:
-
OCR 转文字(例如表格、图表中的文字说明);
-
图像内容解析(通过视觉模型理解图表或图片信息,并转为描述性文本);
-
直接使用多模态大模型(例如 Qwen-VL、BLIP-2 等),在模型内部同时处理文字和图片。
在实现问答功能之前,我先补充学习了两个重要概念:
-
RAG(Retrieval-Augmented Generation):通过构建一个知识库,将外部检索到的相关信息作为提示,增强大模型的生成能力。流程大致是构建知识库 → 向量化存储 → 检索相关内容 → 将内容放入 Prompt → 生成答案。
-
向量数据库:将文本或图片描述转换成高维向量,存储在支持相似度检索的数据库中,以实现基于“语义相似度”的检索,而不是仅依赖关键词匹配。
Baseline 的实现流程主要分为两个阶段:
-
离线预处理(构建知识库)
-
解析 PDF,将每一页或每个内容块提取为文本(或文本+图片描述);
-
对内容进行向量化(embedding),并与元数据(文件名、页码)一起存储到向量库中。
-
-
在线推理(检索 + 生成)
-
将用户问题向量化,与知识库进行相似度检索;
-
从候选内容中选取最相关的若干段落,构建 Prompt 提供给 LLM;
-
生成答案,并输出对应的文件名与页码。
-
上分优化思路:
-
分块策略优化:当前是按页分块,可以改为更细粒度(按段落、表格、图表区域),减少无关信息干扰。
-
检索优化:初步检索后引入 Re-ranking 模型,重排候选段落,提高相关性;
-
Prompt 工程:优化提示词,让 LLM 在信息不足时能明确回复“无法回答”,避免幻觉;
-
多模态融合:文本检索和图片检索同时进行,再将两类信息输入多模态 LLM 融合生成答案;
-
升级数据解析:从
fitz转为 MinerU 等更强的 PDF 解析工具,提高图片和表格的处理能力。
个人收获:
这次学习让我从宏观上理解了 RAG 系统的工作机制——不仅是“调用大模型”,而是要先把数据处理成可检索的结构,再把检索到的知识作为生成的输入。同时,也认识到多模态信息处理在实际任务中很重要,尤其是涉及图表理解和跨模态信息融合时,检索与生成之间的协作至关重要。