Java 8 特性
目录
一、Java 8中Interface接口
二、Lambda表达式
三、函数式接口 Functional Interface
1.常见的内置函数式接口介绍
1.1 Supplier接口--供给型接口
1.2 Consumer接口--消费型接口
1.3 Function接口--转换型接口
1.4 Predicate接口--断言型接口
四、Stream流
1.集合处理数据的弊端
2.获取Stream流的两种方式
(1)Collection集合提供了 default Streamstream()获取流;
(2)Stream接口的静态方法 of 可以获取对应的流。
3.Stream流常用方法
Stream注意事项
1.Stream只能操作一次
2.Stream方法返回的是新的流
3.Stream不调用终结方法,中间的操作不会执行
3.1 forEach():用来遍历流中的数据,void forEach(Consumeraction); 该方法接收一个 Consumer接口函数,会将每一个流元素交给该函数进行处理。
3.2 count():用来统计其中的元素个数,long count(); 该方法返回一个long值代表元素个数。
3.4 limit():可以对流进行截取,指取用前n个。参数是一个long型,如果集合当前长度大于参数则进行截取。否则不进行操作。Streamlimit(long maxSize);
3.7 sorted():如果需要将数据排序,可以使用 sorted方法。方法签名:
Streamsorted(Comparatorcomparator);
3.8 distinct():如果需要去除重复数据,可以使用 distinct方法。方法签名:Streamdistinct();
3.9 match():如果需要判断数据是否匹配指定的条件,可以使用 Match相关方法。方法签名:
3.10 collect():
collect() 收集是一个 最终操作,返回Stream中元素集合,返回值类型是集合(List、Set、Map)或 字符串。
将Stream中的元素,收集至新集合
Collectors.toList()
Collectors.toSet()
Collectors.toMap()
对Stream中的每个元素进行分组统计到一个新的集合:Collectors.groupingBy()
将Stream中的元素,映射至新集合:Collectors.mapping()
3.11 Parallel Streams并行流
Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
一、Java 8中Interface接口
interface接口的设计目的是面向接口编程,提高扩展性。
Java8中,接口中除了抽象方法外,还可以定义default默认方法和static静态方法。
default修饰的默认方法,属于实例方法,可以被实现类调用或重写。
调用:实现类必须implements接口,才能调用该接口的default默认方法。
重写:实现类implements不同接口时,接口中存在相同签名的方法(名称、参数、类型完全一致),则实现类必须重写该方法,明确方法定义;
static修饰的静态方法,属于类的静态方法。但它不能被子类继承,只能用interface接口名称调用。
二、Lambda表达式
Lambda 表达式本质是一个匿名函数,用于把函数作为参数,传入方法中,实现函数式编程风格。
使用Lambda 表达式可以使代码变的更加简洁紧凑。
语法格式:(parameters)-> expression 或 (parameters)->{ statements;}
public class Demo01 {public static void main(String[] args) {//使用匿名内部类//1.定义了一个没有名字的类//2.这个类实现了Runnable接口//3.重写了run方法,实例化了这个匿名内部类的对象//冗余//其实最关注的时run方法里面要执行的代码//lambda表达式体现的是函数式编程思想,只需要将需要去执行的代码放到函数中//lambds表达式是一个匿名函数Thread t1=new Thread(new Runnable() {@Overridepublic void run() {System.out.println("子线程1开始执行任务啦");}});t1.start();//体验lamdba表达式写法Thread t2=new Thread(()-> System.out.println("子线程2开始执行任务啦"));t2.start();}
}
/**
* lambda可以创建函数式接口对象
* 函数式接口:@FunctionalInterface
* 接口中的有且仅有一个抽象方法的接口,称为函数式接口(静态方法,默认方法,抽象方法只有一个)
* 语法格式:
* 接口名 对象名=(参数类型1 参数名1,...参数类型n 参数名n)->{方法体;}
* 参数类型n 参数名n:接口中抽象方法的参数项
* ->:表示连接操作
* {}:存放重写的方法体内容,可以理解为对抽象方法的覆盖。
*
* 简写:
* 1.参数类型可以简写
* 2.小括号,当参数只有1个时,可以省略
* 3.{}、return、; 同时进行省略
*/
//无参无返回值的类型
public class Demo02 {public static void main(String[] args) {swim(new ISwim() {@Overridepublic void swimming() {System.out.println("Forg蛙泳");}});//lambda相当于对接口抽象方法的重写swim(()-> System.out.println("Duck游泳"));}private static void swim(ISwim s1) {System.out.println("进入swim方法中了");s1.swimming();System.out.println("结束swim方法了");}
}
interface ISwim{void swimming();
}
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
//有参有返回值的的练习
public class Demo03 {public static void main(String[] args) {List<Integer> list = Arrays.asList(2, 1, 3, 9, 4, 5, 0);System.out.println(list);//匿名内部类排序list.sort(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return 01 - 02;}});// list.sort((Integer o1, Integer o2)->{return o1-o2;});//删除全部的参数类型
// list.sort((o1, o2) -> {return o1 - o2;});//删除{}、return、;list.sort((o1, o2) -> o1 - o2);System.out.println(list);}
}
public class Demo04 {public static void main(String[] args) {//单参,省略()写法Flyable f1=name-> System.out.println(name+"正在努力的飞");flying(f1,"小鸟");}public static void flying(Flyable f1,String str){System.out.println("进入到flying方法中");f1.fly(str);System.out.println("结束flying方法中");}
}interface Flyable{void fly(String name);//void eat();//接口中只能有一个抽象方法
}
三、函数式接口 Functional Interface
只有一个抽象方法的接口(可以定义多个非抽象方法)。可以使用@FunctionalInterface接口定义,强化语义规范。
函数式接口,也被称为SAM 接口(Single Abstract Method Interfaces)
作用:
基于函数式接口,可以使用Lambda表达式进行实现,实现函数式编程。
1.常见的内置函数式接口介绍
在 Java 8 中专门有一个包放函数式接口java.util.function,该包下的所有接口都有 @FunctionalInterface 注解,提供函数式编程方式。下面是最常用的几个接口。
1.1 Supplier接口--供给型接口
java.util.function.Supplier<T> 接口 - 方法没有参数,有返回值--供给型接口。
它意味着"供给" , 对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象数据。
供给型接口,通过Supplier接口中的get方法可以得到一个值,无参有返回的接口。
@FunctionalInterface
public interface Supplier<T> {public abstract T get();
}案例1:使用Lambda表达式返回数组元素最大值
练习1:返回一个11-20之间的随机偶数
import java.util.Arrays;
import java.util.Collections;
import java.util.Random;
import java.util.function.Supplier;//Supplier接口
public class Demo01 {public static void main(String[] args) {System.out.println("进入到main方法");printMax(()->{System.out.println("进入到get方法中了");Integer[] array={1,2,3,4};Integer number= Collections.max(Arrays.asList(array));System.out.println("在get中找到最大值了:"+number);return number;});Integer num=number(()->{Random random=new Random();
// Integer i1=random.nextInt(10)+11;
// System.out.println("在number方法中获取的随机数:"+i1);
// return i1;while ( true){int number=random.nextInt(10)+11;if ((number&1)==0){return number;}}});System.out.println(num);}public static void printMax(Supplier<Integer> sup){System.out.println("进入到printMax方法中了");Integer number=sup.get();System.out.println("printMax要打印sup获取的最大值:"+number);}//练习1:希望此方法返回一个随机11,20整数值,这个整数是由sup提供public static Integer number(Supplier<Integer> sup){return sup.get();}
}
1.2 Consumer接口--消费型接口
java.util.function.Consumer<T> 接口则正好相反 --方法有参数,没有返回值,它不是生产一个数据,而是消费一个数据,其数据类型由泛型参数决定。 --消费型接口
Consumer消费型接口,可以拿到accept方法参数传递过来的数据进行处理, 有参无返回的接口。
@FunctionalInterface
public interface Consumer<T> { public abstract void accept(T t);
} 案例1:accept() 使用Lambda表达式将一个字符串转成大写和小写的字符串
默认方法:andThen
如果一个方法的参数和返回值全都是 Consumer 类型,那么就可以实现效果:消费一个数据的时候,首先做一个操作,然后再做一个操作,实现组合。而这个方法就是 Consumer 接口中的default方法 andThen 。下面是JDK的源代码:
default Consumer<T> andThen(Consumer<? super T> after) {Objects.requireNonNull(after);return (T t) -> { accept(t); after.accept(t); };//箭头后的为返回Consumer对象中重写的方法体
}
//此时需要注意,我们返回的是一个Lambda表达式,就相当于返回了一个被重写了抽象方法的Consumer<T>类对象
// 即该类对象中,重写了accept()抽象方法,方法体为{ s -> System.out.println(s); s -> System.out.println(new StringBuilder(s).reverse().toString();}
// 即con1.andThen(con2).accept(name);,就变为 Consumer<T>.accept(name);
// Consumer<T>调用本身的accept()方法,并传入字符串参数 “林青霞 ”,所以会输出林青霞,霞青林
// 返回的是一个Consumer类型的对象,而不是直接去对此对象及性能调用备注: java.util.Objects 的 requireNonNull 静态方法将会在参数为null时主动抛出
NullPointerException 异常。这省去了重复编写if语句和抛出空指针异常的麻烦。
要想实现组合,需要两个或多个Lambda表达式即可,而 andThen 的语义正是“一步接一步”操作。例如两个步骤组合的情况
//Consumer接口
public class Demo02 {public static void main(String[] args) {//转小写caseLetter(t-> System.out.println(t.toLowerCase()),"HelloWorld");//转大写caseLetter(t-> System.out.println(t.toUpperCase()),"HelloWorld");//先转大写再转小写caseLetters(t-> System.out.println(t.toLowerCase()),t-> System.out.println(t.toUpperCase()),"HelloWorld");}public static void caseLetter(Consumer<String> con,String str){con.accept(str);}public static void caseLetters(Consumer<String> con1,Consumer<String> con2,String str){
// con1.accept(str);
// con2.accept(str);//先执行con1再执行con2con1.andThen(con2).accept(str);}
}
1.3 Function接口--转换型接口
java.util.function.Function<T,R>接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件, 后者称为后置条件。有参数有返回值。----- 此方法接收一个参数,加工处理成另一种,称为转换型接口。
Function转换型接口,对apply方法传入的T类型数据进行处理,返回R类型的结果,有参有返回的接口。使用的场景 例如:将 String类型转换为 Integer类型。
@FunctionalInterface
public interface Function<T, R> { public abstract R apply(T t);
} 案例1:截取字符串的前3位,转成数字
import java.util.Arrays;
import java.util.function.Function;public class Demo03 {public static void main(String[] args) {//1.获取字符串的长度Function<String,Integer> f1=s1->s1.length();test(f1,"1234abc");//2.截取字符串的前3位,将其转换成数字test(s1->Integer.parseInt(s1.substring(0,3)),"123xnasj");test(s1->s1.length(),len->new int[len],"abc");}public static void test(Function<String,Integer> function,String str){Integer number=function.apply(str);System.out.println(number);}//f1:获取字符串的长度//f2:获取指定长度的int类型的数组public static void test(Function<String,Integer> f1,Function<Integer,int[]> f2,String str){
// Integer number=f1.apply(str);
// int[] arr=f2.apply(number);
// System.out.println(Arrays.toString(arr));int[] arr=f1.andThen(f2).apply(str);System.out.println(Arrays.toString(arr));}
}默认方法: andThen:该方法同样用于“先做什么,再做什么”的场景,和 Consumer 中的 andThen差不多:
function中有一个默认方法,对应的代码的源码为如下
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {Objects.requireNonNull(after);return (T t) -> after.apply(apply(t));}1.4 Predicate接口--断言型接口
有时候我们需要对某种类型的数据进行判断,从而得到一个boolean值结果。这时可以使用
java.util.function.Predicate<T> 接口。------接收一个参数,返回一个boolean类型的值,称为判断型接口。
@FunctionalInterface
public interface Predicate<T> { public abstract boolean test(T t);
}
Predicate接口用于做判断,返回boolean类型的值案例1:判断数字是否大于等于100和判断是否为偶数
import java.util.Random;
import java.util.function.Predicate;public class Demo04 {public static void main(String[] args) {//1.判断此数字是否大于等于100int number=new Random().nextInt(200);method(num->num>=100,number);//2.判断此数字是否是偶数method(num->(num&1)==0,number);methods(num->num>=100,num->(num&1)==0,number);}public static void method(Predicate<Integer> p,Integer num){boolean b=p.test(num);System.out.println("数字num:"+num+"是否大于等于100判断后的结果为:"+b);}public static void methods(Predicate<Integer> p1,Predicate<Integer> p2,Integer num){boolean b=p1.and(p2).test(num);System.out.println("数字num:"+num+"是否大于100并且为偶数:"+b);boolean b1=p1.or(p2).test(num);System.out.println("数字num:"+num+"是否大于100或者为偶数:"+b1);boolean b2=p1.negate().test(num);System.out.println("数字num:"+num+"是否小于100:"+b2);boolean b3=p2.negate().test(num);System.out.println("数字num:"+num+"是否不为偶数:"+b3);}
}
默认方法: and or
既然是条件判断,就会存在与、或、非三种常见的逻辑关系。其中将两个 Predicate条件使用“与”逻辑连接起来实 现“并且”的效果时,可以使用default方法 and 。其JDK源码为:
default Predicate<T> and(Predicate<? super T> other) {Objects.requireNonNull(other);return (t) -> test(t) && other.test(t);}四、Stream流
java.util.Stream 表示能应用在一组元素上一次执行的操作序列。
Stream操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,可以连续完成多个操作。
1.集合处理数据的弊端
当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。我们来体验集合操作数据的弊端,需求如下:
public class Demo01 {public static void main(String[] args) {// 一个ArrayList集合中存储有以下数据:张无忌,周芷若,赵敏,张强,张三丰// 需求:1.拿到所有姓张的 2.拿到名字长度为3个字的 3.打印这些数据ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "张无忌", "周芷若", "赵敏", "张强", "张三丰");// 1.拿到所有姓张的ArrayList<String> zhanglist = new ArrayList<String>();for (String string : list) {if (string.startsWith("张")) {zhanglist.add(string);}}ArrayList<String> threeList = new ArrayList<String>();// 2.拿到名字长度为3的字for (String string : zhanglist) {if (string.length() == 3) {threeList.add(string);}}// 3.进行便利打印操作for (String str : threeList) {System.out.println(str);}// 这段代码中含有三个循环,每一个作用不同:
// 1. 首先筛选所有姓张的人;
// 2. 然后筛选名字有三个字的人;
// 3. 最后进行对结果进行打印输出。
// 每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。// 这是理所当然的么? 不是。循环 是做事情的方式,而不是目的。// 每个需求都要循环一次,还要搞一个新集合来装数据,如果希望再次遍历,// 只能再使 用另一个循环从头开始。
// 那Stream能给我们带来怎样更加优雅的写法呢?System.out.println("==========================");// 使用Stream流的方式来完成此处的任务list.stream().filter(str -> str.startsWith("张")).filter(str -> str.length() == 3).forEach(System.out::println);}}
// 直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:
// 获取流、过滤姓张、过滤长度为3、逐一打印。
// 我们真 正要做的事情内容被更好地体现在代码中。Stream流式思想概述
注意: Stream和IO流(InputStream/OutputStream)没有任何关系,请暂时忘记对传统IO流的固有印象!
Stream流式思想类似于工厂车间的“生产流水线” ,Stream流不是一种数据结构,不保存数据,而是对数据进行加工 处理。 Stream可以看作是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商品。
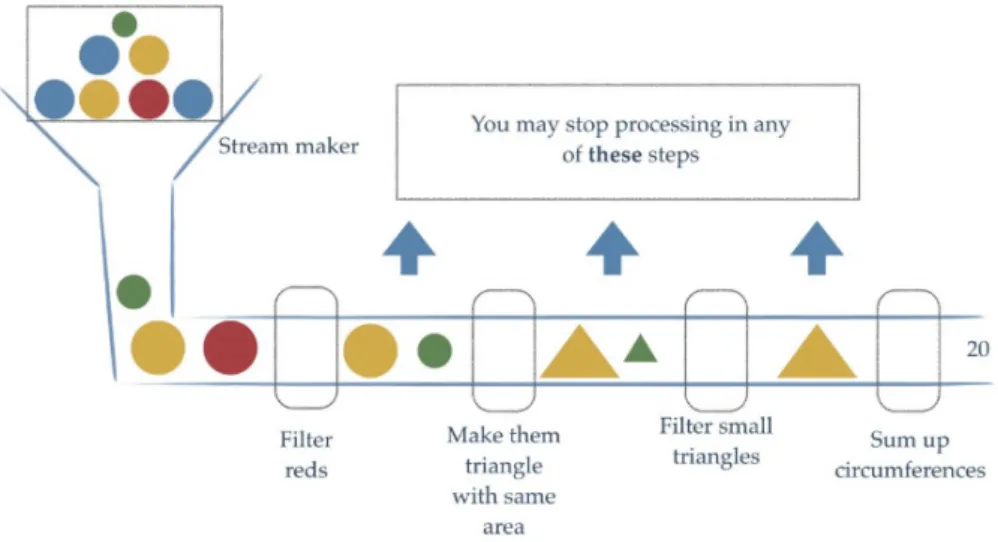
2.获取Stream流的两种方式
java.util.stream.Stream<T>是JDK 8新加入的流接口。 获取一个流非常简单,有以下几种常用的方式:
(1)Collection集合提供了 default Stream<E> stream()获取流;
(2)Stream接口的静态方法 of 可以获取对应的流。
import java.util.*;
import java.util.stream.Stream;public class Demo01 {public static void main(String[] args) {//方式1:Stream的静态方法of进行Stream对象的获取Stream<String> s1=Stream.of("aa","bb","cc");System.out.println(s1);String[] arr={"aa","bb","cc"};Stream<String> s2=Stream.of(arr);System.out.println(s2);int[] numbers={1,2,33,4,5};Stream<int[]> s3=Stream.of(numbers);System.out.println(s3);//方式2:集合Collection接口中的Stream方法List<String> list=Arrays.asList("aa","bb","cc");Stream<String> s4=list.stream();System.out.println(s4);HashSet<String> set=new HashSet<>(list);Stream<String> s5=set.stream();System.out.println(s5);Map<String,Integer> map=new HashMap<>();System.out.println(map.entrySet().stream());}
}3.Stream流常用方法
Stream流模型的操作很丰富,这里介绍一些常用的API。
这些方法可以被分成两种:
终结方法:返回值类型不再是 Stream类型的方法,不再支持链式调用。本小节中,终结方法包括 count和 forEach 方法。
非终结方法:返回值类型仍然是 Stream类型的方法,支持链式调用。(除了终结方法外,其余方法均为非终结 方法。)
Stream注意事项
1.Stream只能操作一次
2.Stream方法返回的是新的流
3.Stream不调用终结方法,中间的操作不会执行
import java.util.stream.Stream;public class Demo02 {public static void main(String[] args) {//1.同一个stream流只能使用一次,不能多次使用Stream<String> s1=Stream.of("aa","bb","cc");System.out.println(s1);
// long number1=s1.count();
// System.out.println(number1);
// long number2=s1.count();
// System.out.println(number2);//2.只要对流做操作,返回的就不是原来的流,永远是一个新流Stream<String> s2=s1.limit(3);s2.forEach(System.out::println);System.out.println(s2);//3.Stream不调用终结方法,中间的操作不会执行s2.filter((str)->{System.out.println(str);return true;}).count();}
}
3.1 forEach():用来遍历流中的数据,void forEach(Consumer<? super T> action); 该方法接收一个 Consumer接口函数,会将每一个流元素交给该函数进行处理。
3.2 count():用来统计其中的元素个数,long count(); 该方法返回一个long值代表元素个数。
3.3 filter():用于过滤数据,返回符合过滤条件的数据,可以通过filter方法将一个流转换成另一个子集流。该方法接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。方法声明:Stream<T> filter(Predicate<? super T> predicate);
3.4 limit():可以对流进行截取,指取用前n个。参数是一个long型,如果集合当前长度大于参数则进行截取。否则不进行操作。Stream<T> limit(long maxSize);
3.5 skip():如果希望跳过前几个元素,可以使用 skip方法获取一个截取之后的新流。如果流的当前长度大于n ,则跳过前n个;否则将会得到一个长度为0的空流。Stream<T> skip(long n);
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;public class Demo03 {public static void main(String[] args) {List<String> list=new ArrayList<>();Collections.addAll(list,"迪丽热巴","陶白白","吴磊","易烊千玺","刘亦菲");//1.获取流list 遍历集合中的元素Stream<String> s1=list.stream();s1.forEach(str-> System.out.println(str));//2.Stream流提供count方法来统计其中的元素个数Stream<String> s2=list.stream();long count=s2.count();System.out.println("元素个数为:"+count);//3.filter用于过滤数据,返回符合过滤条件的数据list.stream().filter(str->str.length()==3).forEach(str-> System.out.println(str));System.out.println("=============");//4.limit方法可以对流进行截取,只取用前n个list.stream().limit(2).forEach(str-> System.out.print(str+" "));System.out.println();System.out.println("============");//5.skip 如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的list.stream().skip(0).forEach(str-> System.out.print(str+" "));}
}3.6 map():Map可以将一种类型的流转换成另一种类型的流。该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。方法签名:<R> Stream<R> map(Function<? super T, ? extends R> mapper);
3.7 sorted():如果需要将数据排序,可以使用 sorted方法。方法签名:
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
3.8 distinct():如果需要去除重复数据,可以使用 distinct方法。方法签名:Stream<T> distinct();
3.9 match():如果需要判断数据是否匹配指定的条件,可以使用 Match相关方法。方法签名:
boolean allMatch(Predicate<? super T> predicate); :元素是否全部满足条件
boolean anyMatch(Predicate<? super T> predicate); :元素是否任意有一个满足条件
boolean noneMatch(Predicate<? super T> predicate);:元素是否全部不满足条件
public class Demo04 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>(Arrays.asList("32", "33", "22", "11", "66"));Stream<String> s1 = list.stream();//map可以将一种类型的流转换成另一种类型的流Stream<Integer> s2 = s1.map(str -> Integer.parseInt(str));//s2.forEach(number-> System.out.println(number));System.out.println("=================");//如果需要将数据排序,可以使用sorted方法//使用泛型类型的默认排序规则排序//s2.sorted().forEach(number-> System.out.println(number));//使用自定义的Comparator比较规则排序s2.sorted((a, b) -> b - a).forEach(number -> System.out.println(number));System.out.println("========distinct=========");//去重Stream.of(1, 3, 2, 1, 3, 4, 5, 6).distinct().forEach(number -> System.out.println(number));System.out.println("========match=========");//如果需要判断数据是否匹配指定的条件,可以使用Match相关方法//所有的元素匹配条件,则返回trueboolean b1 = Stream.of(1, 3, 2, 1, 3, 4, 5, 6).allMatch(number -> number > 100);System.out.println("allmatch:"+b1);//只要有一个匹配条件,则返回trueboolean b2 = Stream.of(1, 3, 2, 1, 3, 4, 5, 6).anyMatch(number -> number > 5);System.out.println("anymatch:"+b2);//所有元素都不匹配,则返回trueboolean b3 = Stream.of(1, 3, 2, 1, 3, 4, 5, 6).noneMatch(number -> number > 100);System.out.println("nonematch:"+b3);}
}
3.10 collect():收集是一个最终操作,返回Stream中元素集合,返回值类型是集合(List、Set、Map)或 字符串。
将Stream中的元素,收集至新集合
Collectors.toList()
Collectors.toSet()
Collectors.toMap()
对Stream中的每个元素进行分组统计到一个新的集合:Collectors.groupingBy()
将Stream中的元素,映射至新集合:Collectors.mapping()
public class Demo05 {public static void main(String[] args) {List<String> langList = Arrays.asList("abc", "deft", "gbkh", "bac", "fgh");//将过滤结果,收集至List集合List<String> list = langList.stream().filter(s -> s.toUpperCase().contains("B")).collect(Collectors.toList());System.out.println(list);//将过滤结果,收集至Set集合Set<String> set = langList.stream().filter(s -> s.toUpperCase().contains("B")).collect(Collectors.toSet());System.out.println(set);//将过滤结果,收集至Map集合Map<String, Integer> map = langList.stream().distinct().filter(s -> s.toUpperCase().contains("B")).collect(Collectors.toMap(str -> str, str -> str.length()));System.out.println(map);//按照字符串长度统计Map<Integer, List<String>> goupMap = langList.stream().distinct().collect(Collectors.groupingBy(str -> str.length()));System.out.println(goupMap);//按照字符串的长度转成集合List<Integer> mappingList = langList.stream().collect(Collectors.mapping(str -> str.length(), Collectors.toList()));System.out.println(mappingList);}
}
3.11 Parallel Streams并行流
Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
public class Demo06 {public static void main(String[] args) {int max=1000000;List<Integer> values=new ArrayList<>(max);Random r1=new Random();for (int i = max; i >=0 ; i--) {values.add(r1.nextInt());}//串行
// long t0=System.nanoTime();
// values.stream().sorted().count();
// long t1=System.nanoTime();
// long millis= TimeUnit.NANOSECONDS.toMillis(t1-t0);
// System.out.println("串行排序完成排序需要的时间是:"+millis);//并行long t0=System.nanoTime();values.parallelStream().sorted().count();long t1=System.nanoTime();long millis= TimeUnit.NANOSECONDS.toMillis(t1-t0);System.out.println("并行排序完成排序需要时间是:"+millis);}
}
public class Demo07 {public static void main(String[] args) {int max=100000;List<String> values=new ArrayList<>(max);for (int i = 0; i < max; i++) {UUID uuid= UUID.randomUUID();values.add(uuid.toString());}List<String> newlist=new Vector<>(max);long t0=System.nanoTime();//返回毫微秒values.stream().parallel().forEach(s->newlist.add(s));long t1=System.nanoTime();System.out.println(newlist.size());System.out.println("并行流运行的时间:"+(t1-t0));}
}