机器学习DBSCAN密度聚类
引言
在机器学习的聚类任务中,K-means因其简单高效广为人知,但它有一个致命缺陷——假设簇是球形且密度均匀,且需要预先指定簇数。当数据存在任意形状的簇、噪声点或密度差异较大时,K-means的表现往往不尽如人意。这时候,DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 作为基于密度的聚类算法,凭借其无需预设簇数、能识别噪声、处理任意形状簇的特性,成为工业界和学术界的神器
本文将从原理到代码,带你彻底搞懂DBSCAN,并通过实战案例掌握其核心技巧。
一、DBSCAN核心概念:用“密度”定义簇
要理解DBSCAN,首先需要明确5个核心概念:
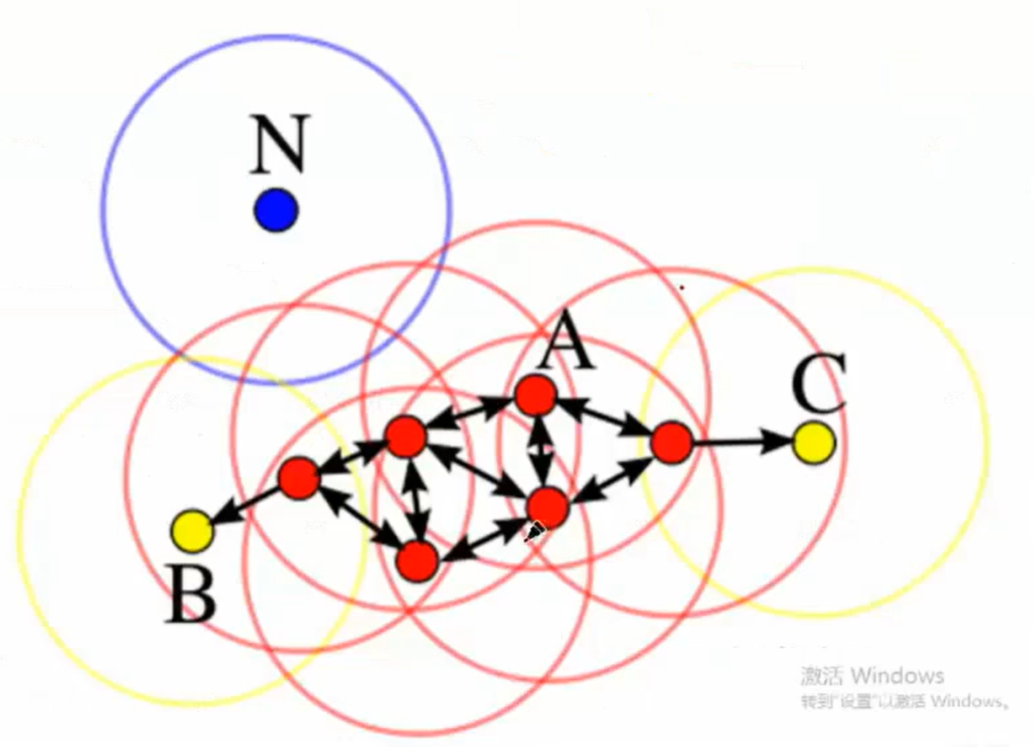
1. ε邻域(ε-Neighborhood)
对于数据点 ppp,其ε邻域是指所有与 ppp 的距离不超过 ε\varepsilonε 的点的集合,数学上表示为:
Nε(p)={q∈D∣distance(p,q)≤ε}N_\varepsilon(p) = \{ q \in D \mid \text{distance}(p, q) \leq \varepsilon \}Nε(p)={q∈D∣distance(p,q)≤ε}
其中 DDD 是数据集,distance\text{distance}distance 常用欧氏距离(连续数据)或曼哈顿距离(高维稀疏数据)。
2. 核心对象(Core Object)
如果数据点 ppp 的ε邻域内至少包含 min_samples\text{min\_samples}min_samples 个点(包括 ppp 自己),则 ppp 是一个核心对象。
换句话说,核心对象是“密度足够高”的点,是簇形成的基础。
3. 直接密度可达(Directly Density-Reachable)
如果点 qqq 位于核心对象 ppp 的ε邻域内(即 q∈Nε(p)q \in N_\varepsilon(p)q∈Nε(p)),则称 qqq 从 ppp 出发是直接密度可达的。
4. 密度可达(Density-Reachable)
如果存在一个点序列 p1,p2,...,pnp_1, p_2, ..., p_np1,p2,...,pn,其中 p1=pp_1 = pp1=p,pn=qp_n = qpn=q,且每个 pi+1p_{i+1}pi+1 从 pip_ipi 直接密度可达,则称 qqq 从 ppp 出发是密度可达的。
密度可达是直接密度可达的传递扩展,但不具备对称性(即 qqq 密度可达 ppp 不代表 ppp 密度可达 qqq)。
5. 密度相连(Density-Connected)
如果存在一个核心对象 ooo,使得 ppp 和 qqq 都从 ooo 密度可达,则称 ppp 和 qqq 是密度相连的。
密度相连的点属于同一个簇。
6. 簇与噪声
- 簇:数据集中最大的密度相连点集(即无法通过密度可达扩展更多点)。
- 噪声:不属于任何簇的点(不被任何核心对象密度可达)。
二、DBSCAN算法流程:从核心对象到簇的构建
DBSCAN的核心逻辑是“从核心对象出发,扩展密度可达的点形成簇”。具体步骤如下:
- 计算所有点的ε邻域:遍历数据集,为每个点计算其ε邻域内的点数量。
- 筛选核心对象:保留那些ε邻域内点数量 ≥ min_samples的点,标记为核心对象。
- 扩展簇:从任意一个未被访问的核心对象出发,递归地将其所有密度可达的点加入当前簇,并标记为已访问。
- 处理噪声:所有未被访问且不属于任何核心对象的点,标记为噪声。
三、代码实战:用Python实现DBSCAN
1. 环境准备与数据生成
我们使用 scikit-learn 提供的合成数据,并添加噪声。首先安装依赖:
pip install numpy pandas matplotlib scikit-learn
生成数据代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_noise
from sklearn.preprocessing import StandardScaler# 生成3个真实簇(含噪声)
X, y_true = make_blobs(n_samples=300, centers=3, cluster_std=[1.0, 2.0, 0.8], # 不同簇的密度差异random_state=42
)
X = StandardScaler().fit_transform(X) # 标准化数据# 添加5%的噪声点(偏离真实簇)
noise = make_noise(n_samples=int(0.05*len(X)), noise_scale=3.0, random_state=42)[0]
X = np.concatenate([X, noise])# 可视化原始数据
plt.scatter(X[:, 0], X[:, 1], c='gray', s=10, label='Unclustered Data')
plt.title("Raw Data with Noise")
plt.legend()
plt.show()
2. 使用scikit-learn的DBSCAN
sklearn.cluster.DBSCAN 已经封装了高效的DBSCAN实现,我们直接调用并调参:
from sklearn.cluster import DBSCAN# 初始化DBSCAN,关键参数:eps=ε,min_samples=min_samples
dbscan = DBSCAN(eps=0.8, min_samples=5)
clusters = dbscan.fit_predict(X) # 输出:-1表示噪声,其他为簇标签# 统计结果
n_clusters = len(set(clusters)) - (1 if -1 in clusters else 0) # 排除噪声标签-1
n_noise = np.sum(clusters == -1)
print(f"Estimated number of clusters: {n_clusters}")
print(f"Estimated number of noise points: {n_noise}")# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=clusters, s=10, cmap='viridis')
plt.title(f"DBSCAN Clustering (eps=0.8, min_samples=5)")
plt.colorbar(label='Cluster ID (-1=Noise)')
plt.show()
3. 关键参数调优:如何选择ε和min_samples?
DBSCAN的效果高度依赖两个参数:
eps(ε):邻域半径,太小会导致很多簇被分割,太大可能合并不同簇。min_samples:核心对象的最小邻域点数,通常设置为维度+1(如2维数据设为3-5)。
调参技巧:k-distance图
k-distance图通过计算每个点到其第k近邻的距离并排序,绘制折线图。曲线的“拐点”对应的距离即为合适的ε(通常k=min_samples-1)。
from sklearn.neighbors import NearestNeighbors
import numpy as np# 计算每个点的k近邻距离(k=min_samples-1=4)
min_samples = 5
k = min_samples - 1
neighbors = NearestNeighbors(n_neighbors=k)
neighbors_fit = neighbors.fit(X)
distances, indices = neighbors_fit.kneighbors(X)# 排序距离并绘制
distances = np.sort(distances, axis=0)[:, 1] # 取第k近邻的距离(排除自己)
plt.plot(distances)
plt.xlabel("Points sorted by distance")
plt.ylabel(f"{k}-th Nearest Neighbor Distance")
plt.title("k-distance Plot for ε Selection")
plt.grid(True)
plt.show()
解读k-distance图:
曲线从左下到右上逐渐上升,当出现一个明显的“跳跃”(拐点)时,对应的距离即为合适的ε。例如,若拐点在距离0.8处,则设置eps=0.8。
四、DBSCAN的优缺点与适用场景
优点:
- 无需预设簇数:自动根据数据密度划分簇。
- 抗噪声能力强:明确识别噪声点(标签-1)。
- 处理任意形状簇:不依赖簇的球形假设。
缺点:
- 参数敏感:ε和min_samples的选择对结果影响大。
- 高维数据效果下降:高维空间中距离度量失效(维度诅咒)。
- 密度不均匀时表现差:若簇间密度差异大,难以找到统一的ε。
适用场景:
- 数据分布有明显密度差异(如用户分群中的高价值/低活跃用户)。
- 存在噪声或离群点(如金融欺诈检测)。
- 簇形状不规则(如地理区域的用户分布)。
五、总结
DBSCAN是一种强大的密度聚类算法,核心是通过“核心对象”和“密度可达”定义簇,天然抗噪声且能处理任意形状的簇。实战中需重点调参ε和min_samples,推荐使用k-distance图辅助选择ε。下次遇到传统聚类算法无法解决的复杂数据时,不妨试试DBSCAN