3D感知多模态(图像、雷达感知)
一.BEVFusion
1.简要介绍
BEV是一个俯视空间,Fusion做的就是融合,这里指的就是图像和点云的融合。那如何把图像和点云融合在一起?认为融合方法有三种:
- a.point level fusion:点集的融合,从点云中采样一些点,再根据相机的内外参讲这些点投影到图像上,采样出图像特征,然后再拼接到点位上,利用这个融合后的特征去做3D目标检测
- b.feature level:将两种模态的中间特征通过内外参矩阵拼接投影,融合出完整特征去做的。具体啦说就是,对于输入点云,通过点云网络得到初始位置,初始位置去图像上采样特征,这是一个从点云到图像的过程,采样玩特征之后,再拿回到原始的点云空间中,拼接到原始的特征之上(蓝色部分是从图像上采样过来的特征,橙色部分是原始的初始点云特征),两种类型特征拼接到一起,去做3D检测任务
从流程上来看,a和b的方式都离不开一个映射的过程,也就是利用相机内外参,将3D点换算到2D图像上。但是如果外参计算不好,这也许会导致最终出现问题,同时,如何采样出来的点对应到图像上的特定像素,这个像素是模糊的,这都会导致最终效果不好。
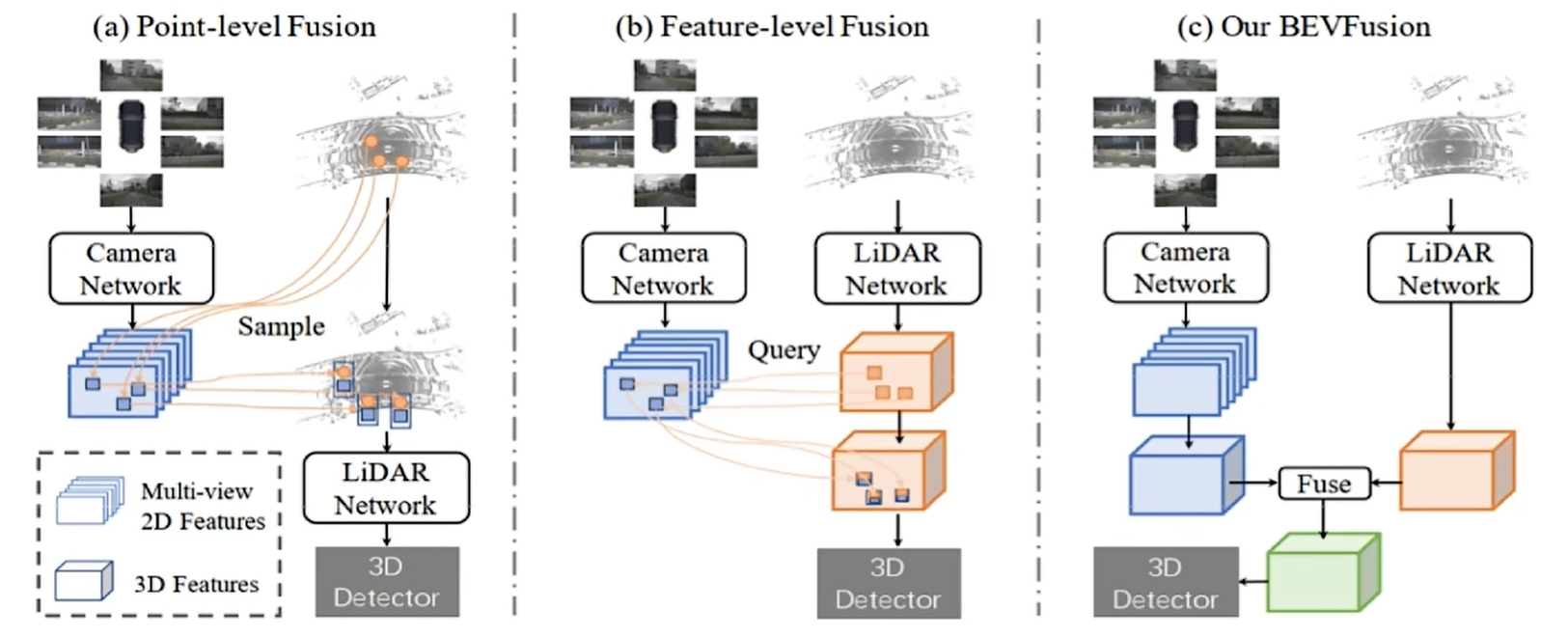
因此,以前的方式,无论是a还是b,都存在一个主次依赖的关系,都从点云出发,但如果点云不准、外参不准,那么后续的检测也就不会准。因此BEVFusion就希望尽可能降低这个主次依赖关系,对点云和图像做一个分别处理,然后再在BEV空间去做融合,
2.主体结构
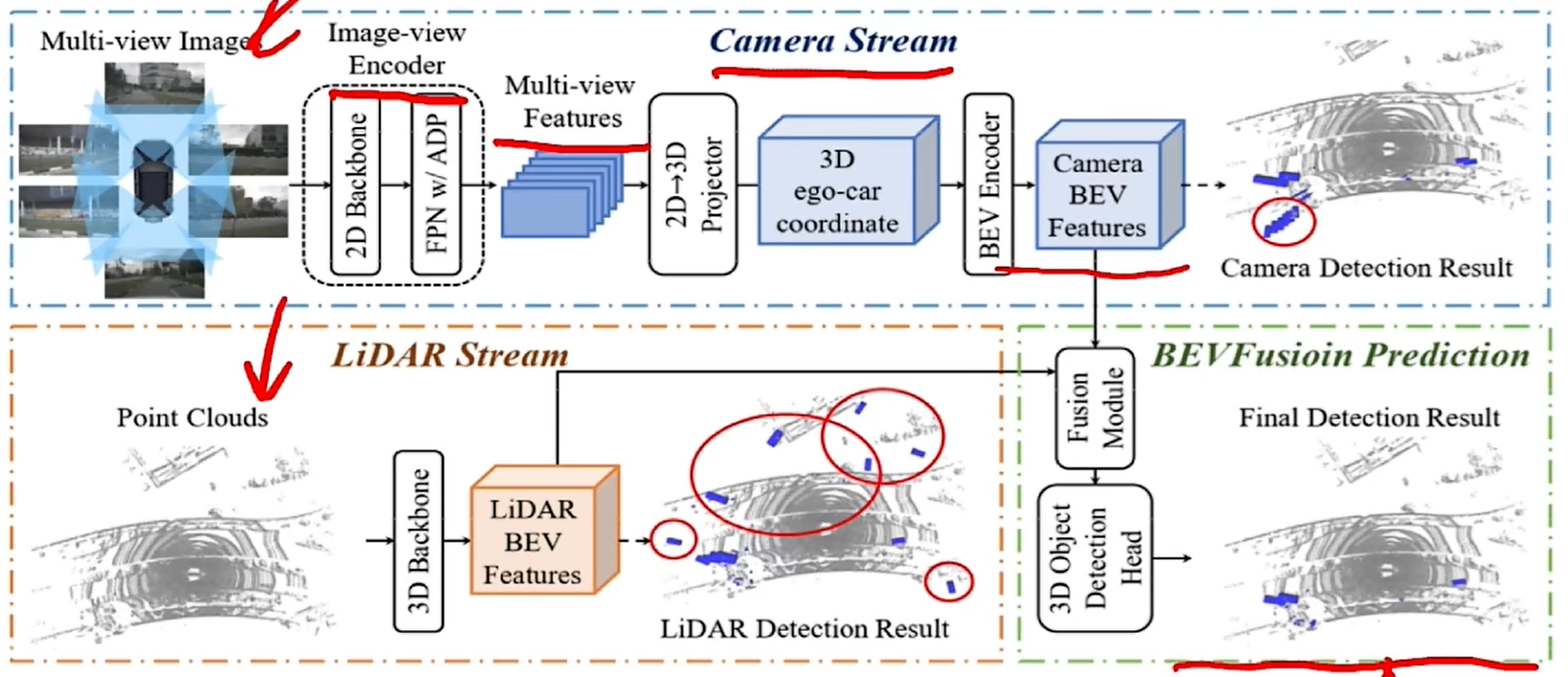
图像经过编码器得到图像特征,再通过一个转换器将2D变换到3D,再投影到BEV空间上,就得到了图像特征在BEV空间上的表征(Camera BEV Features)。而雷达点云通过一个3D Backbone 得到点云的BEV特征。接下来就需要去做融合了(Fusion Model),利用得到的混合特征去做预测。
Camera Stream

图像流的输入是多视角图像,相同一个2D Backbone提取基础的图像特征,再经过FPN+ADP模块(ADP模块包括上采样、池化、卷积)对多尺度特征做一个融合,得到多尺度图像特征;再通过一个2D->3D转换模块做一个转换,这个转换的过程其实就是对每一个像素位置做一个 深度分布的预测,会预测一系列的离散的深度概率,这个概率会作为一个权重去乘上像素的图像特征,然后每个像素点按照射线去进行特征投影,组成了所谓的3D空间;然后再投影,就可以得到Camera BEV Features了。
Lidar Stream
雷达流的输入是3D雷达点云,经过一个3D Backobone提取点云特征,这里主要使用Point pillar进行点云特征提取,由于点云本身就是3D的,所以只需要做投影或者直接拍扁,就可以将其转换到BEV空间了。
Fusion Model
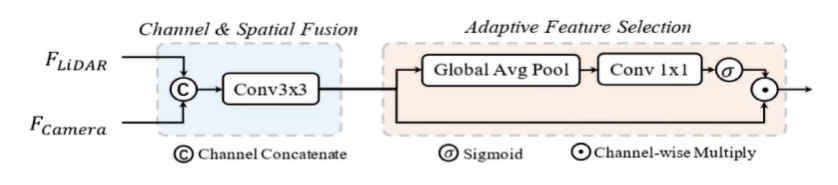
融合模块输入前面两个得到的BEV空间的图像特征和点云特征,接着按通道级联点云和图像BEV特征,再通过卷积网络提取级联后的特征,之后引入一个Adaptive Feature Selection模块,这其实一种通道注意力,去对通道维度进行了加权,考虑的是哪个通道更重要,是点云上的通道呢还是图象上的通道呢,通过这样一个权重的预测,对通道维度进行一个重新的加权;之后就得到了一个融合后的特征,自然也就可以用来做预测。
二.BEVFusio4D
三.BEVFormer
1.简要介绍
BEV是一个俯视空间,Former做的就是Transformer,这里指的就是使用transformer去做BEV的图像处理,完成后续检测目标。
2.主体结构
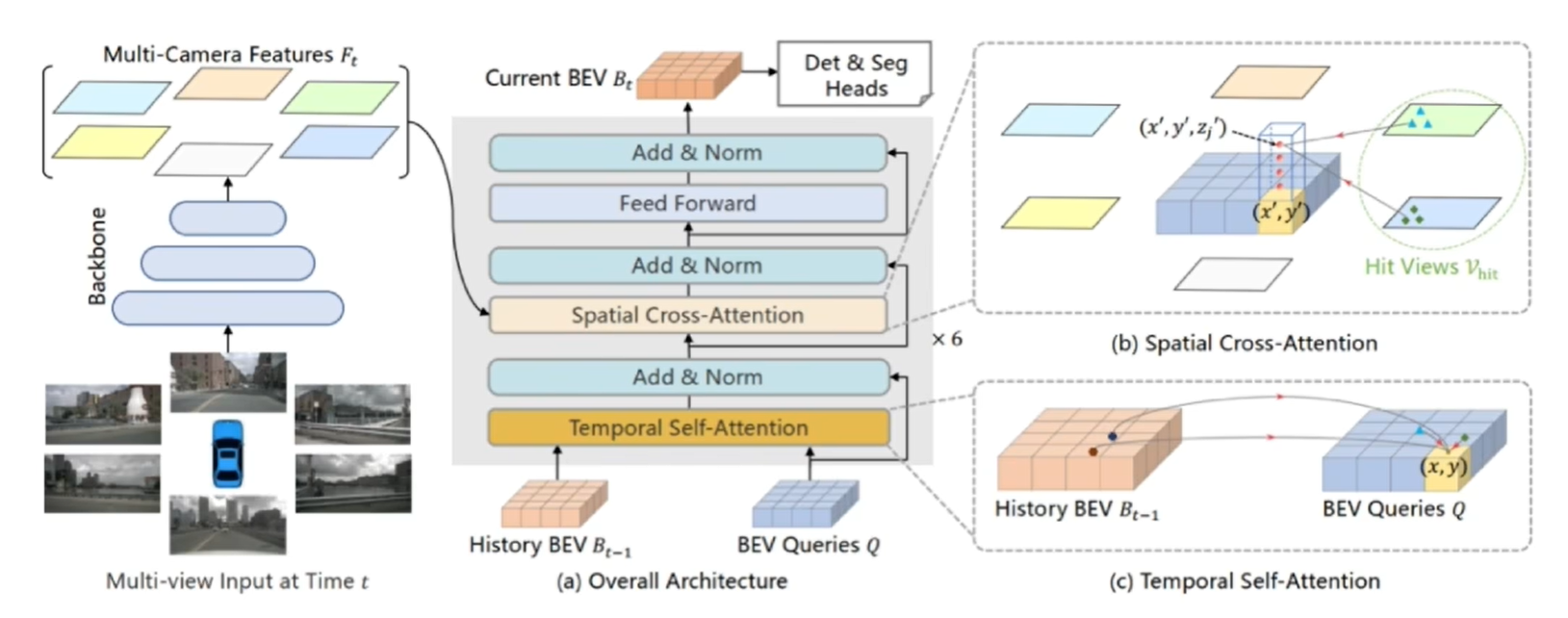
首先,输入的图像经过Backbone得到图像特征,将图像特征、History BEV、BEV Queries一起输入到一个结构当中,会得到Current BEV,就可以作为检测头的输入完成后续的检测分割任务。
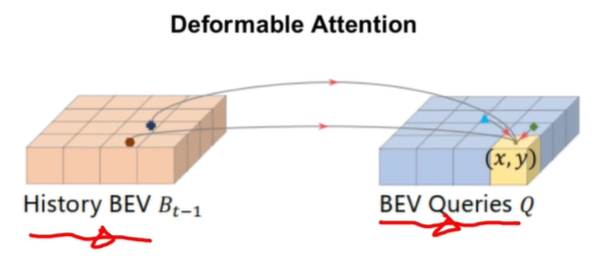
Temporal Self-attention
时序注意力是考虑到前一帧和当前帧的一个关联,那如何将前一帧的特征引入到当前帧的EBV空间中呢。这里使用的就是一个Deformable Attention,History BEV可以自适应选择哪一个BEV Queries对当前点是有增益的。有了History BEV的引导之后,BEV Queries查询的先验也就会更好。后续,再结合当前提取到的空间特征和已经有很强的BEV先验的Queries,就可以生成更好的BEV Feature。
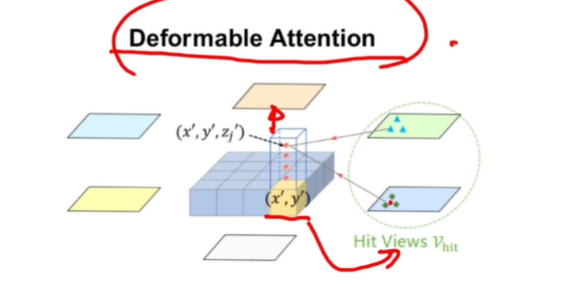
Spatial Attention
那已经有了提取好的multi-camera feature之后,怎么样生成想要的当前的BEV feature呢。使用空间注意力,利用BEV Queries对multi-camera feature做一个查询,去问一问“你有我这个位置的特征吗”;具体就是将XY先映射到他这个视角下所对应的位置上,通过去找这个位置临近的相邻点的一个特征,去进行一个融合,然后生成他当前视角下需要被融合的特征。后续他把这个多视角全都查询完之后,会生成X'Y'位置上通过multi-camera feature融合好的特征
四.PETR
从名字可以知道,主要就是Position Emebedding Transformer。那么核心设计思路就是位置编码(position emebedding)的设计上。
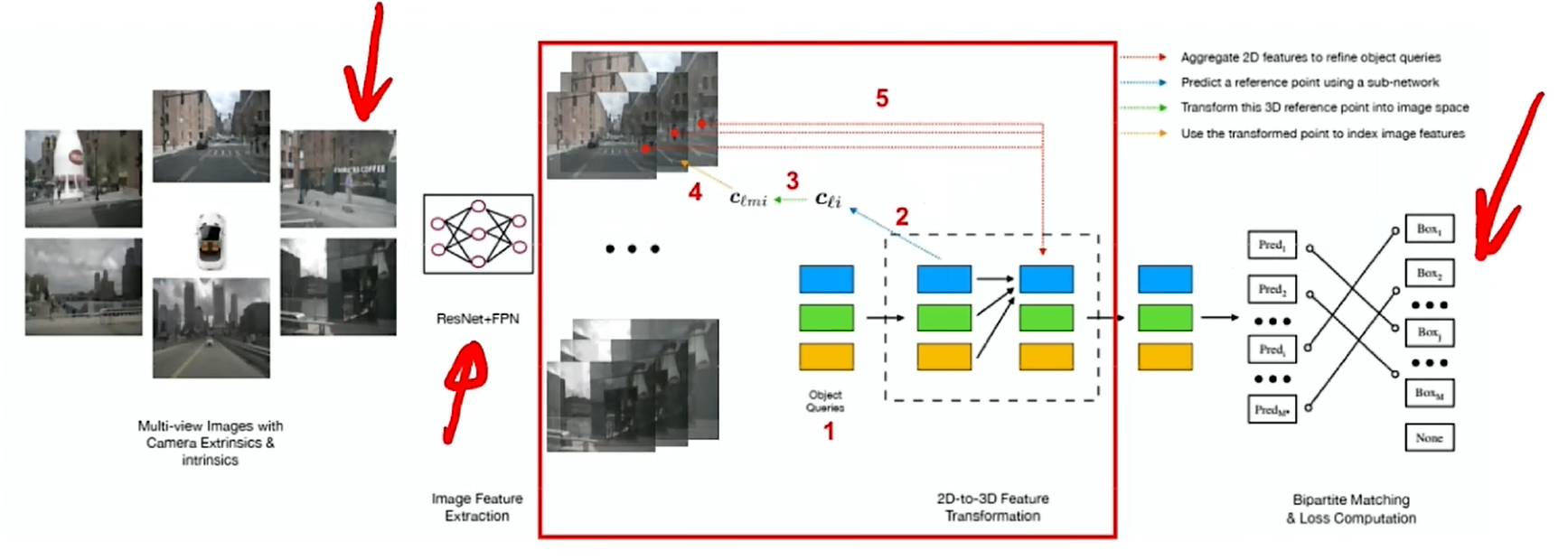
DETR3D
PETR是一个根据DETR3D改进的一个工作,因此先回顾一下DETR3D。对于输入的多视角图像,采用ResNet+FPN来提取图像特征,得到多尺度图像融合特征;再初始化一系列的Object query,query的主要作用就是随机初始化一些查询向量,用于查询空间中哪里有物体,query通过transformer结构来预测生成3D reference point,有了参考点之后就可以根据相机内外参,将参考点逆投影回图像空间,找到参考点在图象上的位置,进而找到该像素位置对应的特征。通过3种尺度的融合,得到最终的图像特征,进而可以进行预测;而这个过程其实是一个迭代预测的过程,是多次refine的过程,可以不断地得到新的object query,不断地更新预测。DETR3D通过这样一个过程去做3D目标检测任务。
PETR
动机
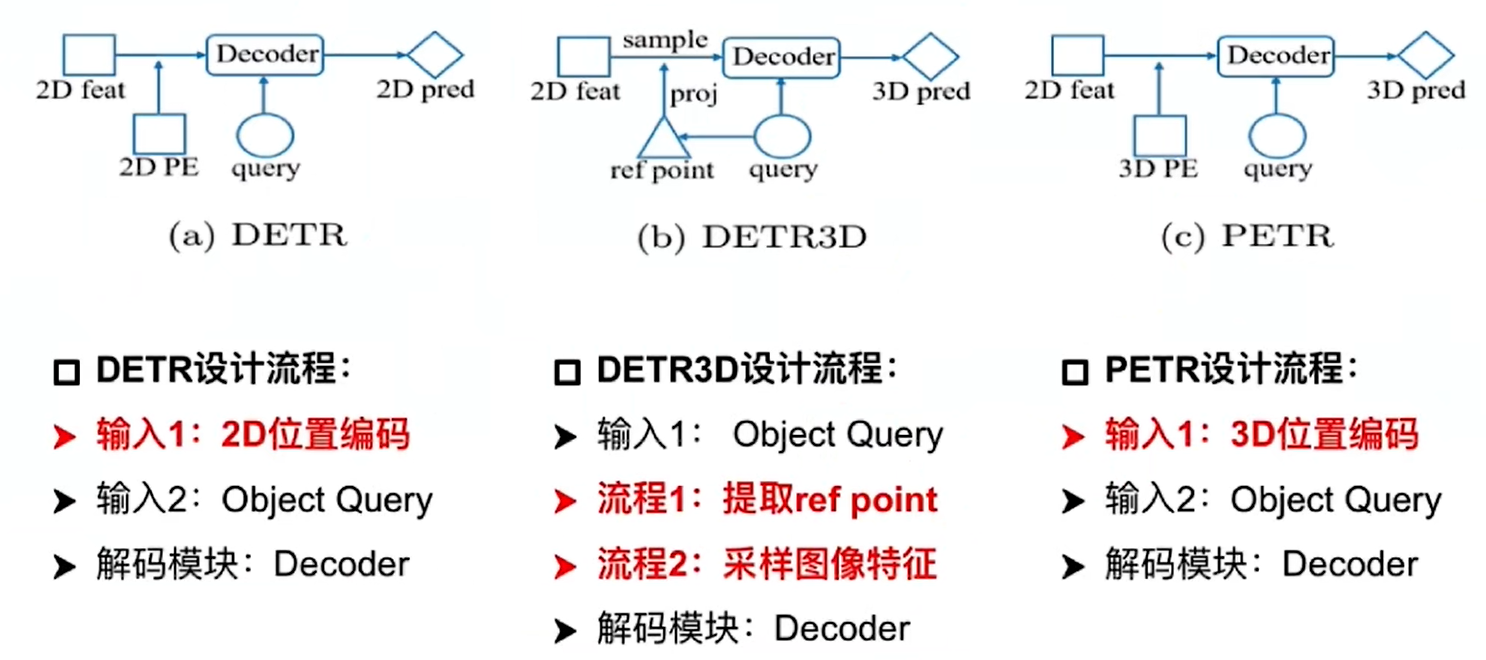
PETR认为DETR3D中的利用3D参考点来索引图像特征是不合理的,因为如果参考点位置出错了,那么图像特征也就错了,从而导致采样到的图像特征是无效的,同时认为,如果只采用参考点的投影位置得到图像特征来更新query是不够充分的,可能导致模型对于全局特征学习的不够充分。
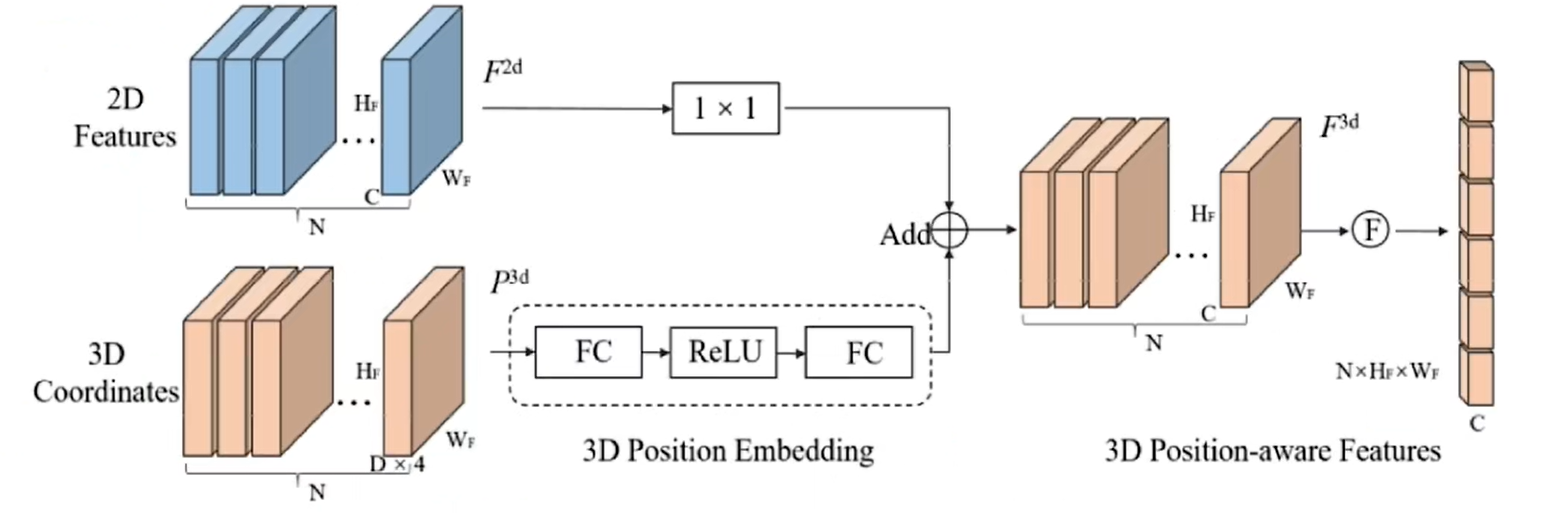
因此PETR使用3D PE(position emebedding)将多视角的2D图像特征转化为3D感知特征,也就是将2D feature和3D PE结合得到3D感知特征,这也使得query可以在3D语义环境下进行更新,从而省略了来回投影的过程,简化了DETR3D的流程。
主体结构
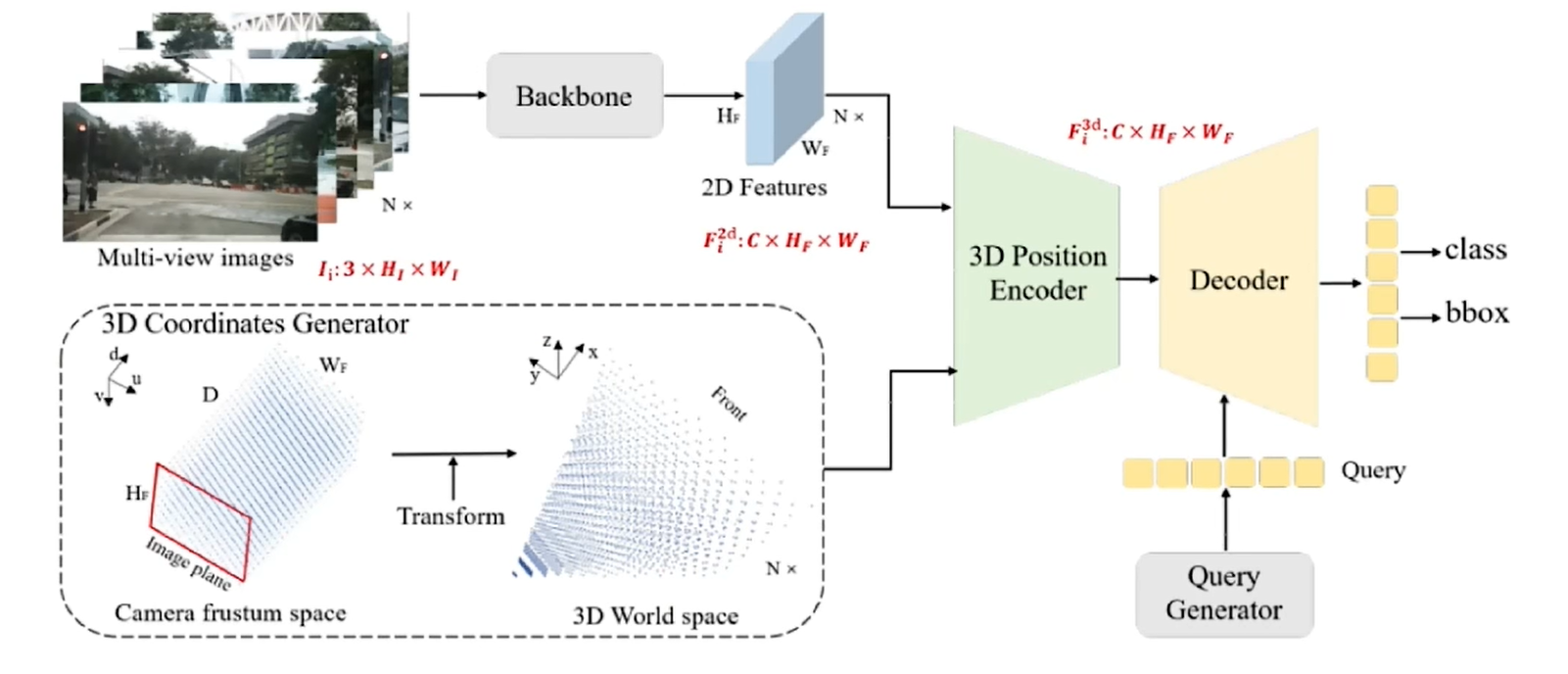
对于输入的多视角图像,经过Backbone可以得到图像特征,同时3D坐标生成器(3D Coordinates Generator)经过一系列的坐标变换将图像坐标转化为3D空间中的坐标,然后2D图像特征和3D位置坐标同时送到3D位置编码(3D Position Encoder),将3D位置信息融入到2D特征里面,生成一系列的object query,与得到的特征一起去得到预测结果。
3D Coordinates Generator:
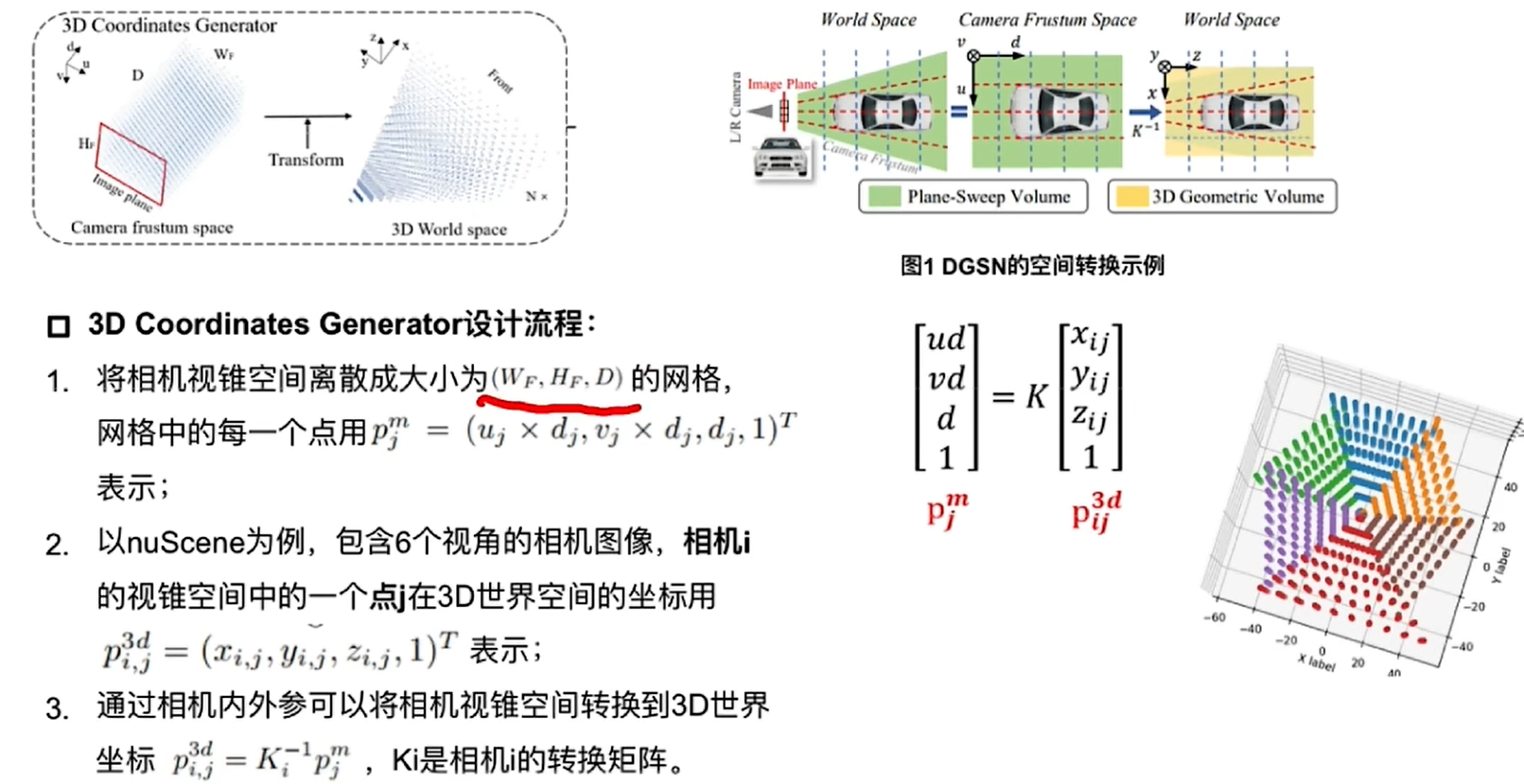
3D Position Encoder: