避不开的数据拷贝(2)
接着上周未完的话题 避不开的数据拷贝。
既然处理器是通用机器,就没有专属数据,所以数据都要从别处调来,这就涉及到了数据搬运,就有了外设的概念。由于不同外设和处理器一起共享数据存储,时间会花在两方面:
- 时间会花在检索自己需要的数据上,这是算法和数据结构的领域;
- 时间会花在数据搬运上,这是拓扑,总线,网络,协议的领域;
“尽量不拷贝” 和 “尽量不传输数据” 都是尽量不移动数据的实例,而不是醉心于让拷贝和传输变得更快。为了不移动数据却又能使用数据,要将思路转换为传递控制信号或直接传递结果,让数据保持在 “原地”。 这需要更多的通路组织更智能的网络。
近年来如日中天的零拷贝,设备内存,片商存储等概念值得一提,但在软件领域,其实人们一直在恪守这些信念。不外乎两个观点:
- 内存观点,固定 buffer,比如统一往一个 buffer-ring 里送;
- 程序观点,离散 buffer,比如将离散的 buffer 串成一个 queue;
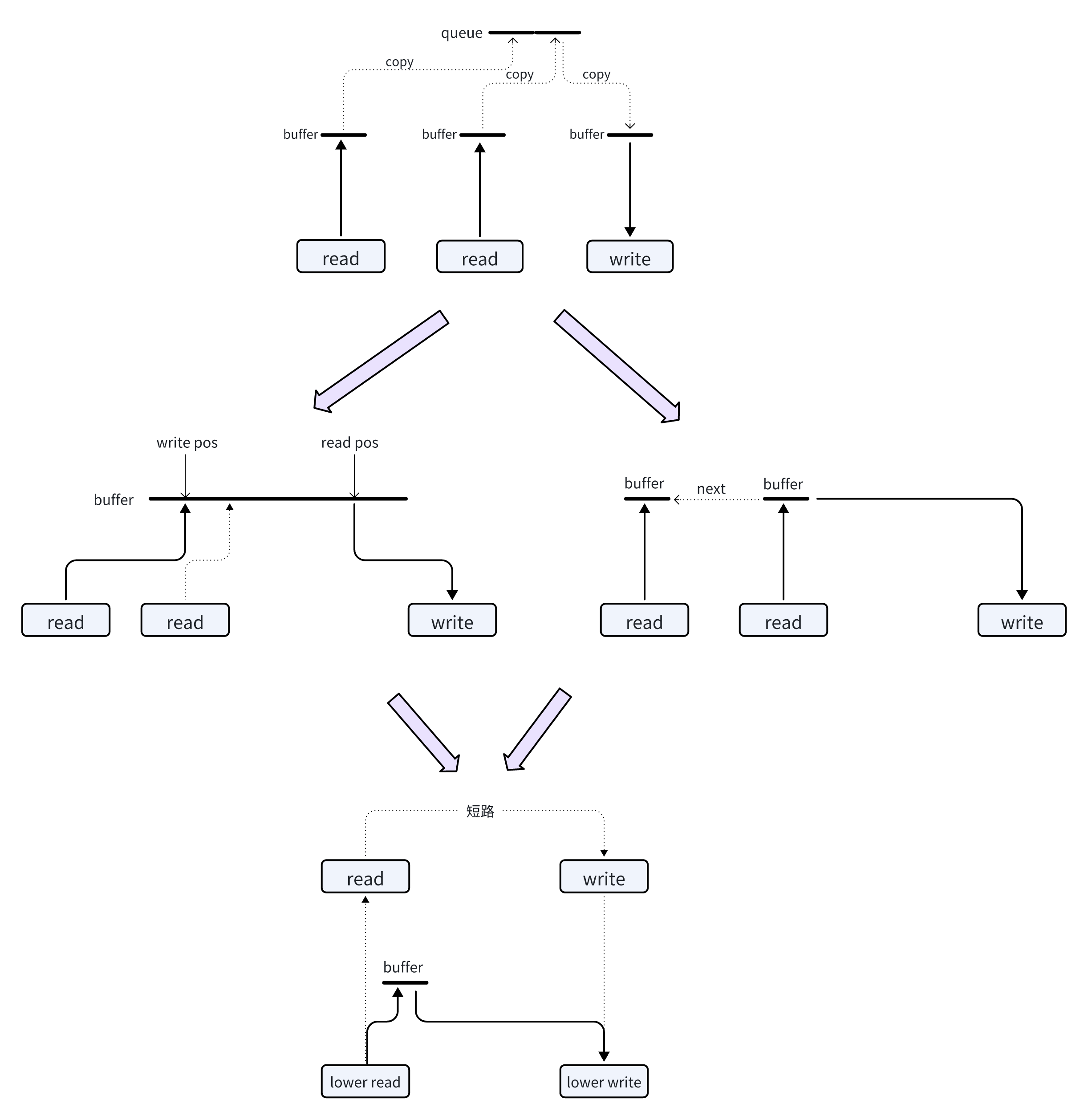
总之都是数据能不动就不动,实在要动就少动,如果有谁写了一个程序,频繁做 memcpy,势必要被优化掉,不管是针对程序,还是针对人。
可以审视从初学编程到使用 Linux 内核的 splice/tee,基本就是上图的过程,从一开始果真把 queue 当成一个实体 queue,copy 内存往里排队,到最后直接在两个 fd 之间非 copy 传递数据,见证了逐渐让数据不移动的过程。
同理,当外设能力反超 CPU,而软件成为瓶颈后,外设硬件当然要走一遍同样的路,近年来的 Device Memory TCP 就是其中一例:

其它实例几乎同理。
还有一个问题,如果必须要搬运,数据搬运过程中为什么需要 buffer,为什么不能一镜到底,推而广之,为什么要接力,转介。这就要说到通用计算机处理数据的两类方式:
- 流水线提高吞吐;
- 并行化提高吞吐;
总之要有资源,且要资源全部动起来,这是一种通用资源组织理念,无论对硬件还是软件。
本质上还是因为通用机器以数据为中心,通用机器的数据都从别处搬来,效率高低取决于搬运的方式,如果有搬运和处理部件闲置,就一定要想办法将它用起来。
定量讲,如果增加一倍的通用处理资源,理论上应该增加一倍的吞吐。举例说明,将数据从 A 搬到 B:
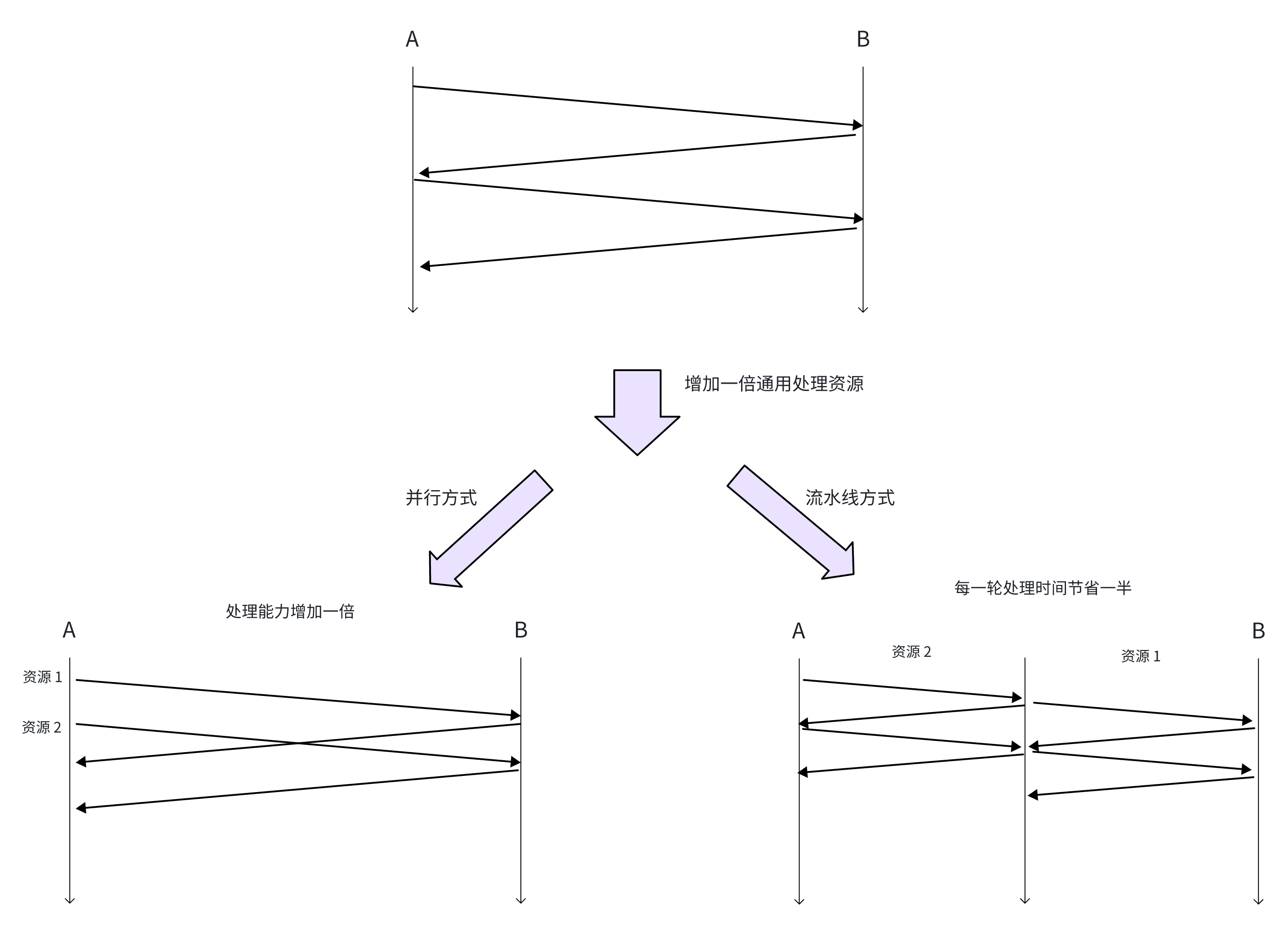
可见并行方式就是一镜到底,这并不是问题的核心所在。问题的核心在于分割时间还是分割空间,本质上还是如何在时空展开的问题,这就涉及到数据的语义。
如果数据是严格保序的,通用机器需无条件满足该约束,典型例子是通用处理器,即 CPU,它的处理资源必须在时间维度分割成流水线,作为数据的串行指令在其中接力通过。另一个对面的例子,内存数据是不保序的地址映射,因此它是并行结构,每一个 bit 都有一条地址线和数据线传输该 bit,这些线在空间维度并在一起。
这样看来,串行指令通过流水线执行,而数据则通过并行通道映射到目的地,似乎一想就通,但当真正传输数据而不仅仅是内存和 CPU 交互时,却纷纷拒绝并行,接受 stream 抽象,分层模型下 “纵然在 byte 级别存在 byte stream,但在 bit 级别依然并行传输” 的内存操作,等价为 “纵然在 byte 级别存在 byte stream,但在 packet 级别依然并行传输” 被忽视,也许是 packet 出现在 byte stream 之后,IP 从 TCP 分离而来之故,但 PCIe,USB 也是串行。
否则,若信道不识 stream,像内存地址般映射,并行传输就是自然而然的选择。
现如今,除了内存,芯片内部总线采用并行策略外,几乎都选择了串行,从大尺度的 TCP/IP,到微尺度的 PCIe,明确的理由似乎又要回到早期串行,并行之争里去寻址,不外乎:
- 并行信号时钟同步困难,时钟偏移,线路干扰,布线成本高;
- 串行时钟精准同步,抗干扰强,线路少,成本低,适合长距离;
把这些往大尺度 TCP/IP 延申,也能解释 MPTCP 的实现粒度为什么做不细,本质上是一回事。所以,最终的通用策略是:
- 传输网络以并行的方式构建,业务数据在其特定的某条路径上串行传输。
但这只是通用策略,值得注意的是例外,若并行劣势均克服,串行就没优势了,这也是我认可数据中心网络并行多路径传输的原因:
- 拓扑规则,ECMP 路径一致,RTT 短,同步存储开销小,负载分担,拥塞均衡。
总之,数据中心传输可像内存和内部总线那般并行,但其它场景不具备这特征,不管是广域网,USB,PCIe,还是 nvlink。更微观意义上,串行并行依然保持着嵌套,PCIe,nvlink 虽串行,但它们均采用多通道并行捆绑实现更高的带宽,整个数据搬运结构在全局看来依然维持着规整。
尽量不搬运数据,非要少量搬运,上面介绍了如何高效搬运。进一步优化思路就很明确,像以往专用设备那样独占数据,让数据和处理一体化,就滑向跷跷板的另一端了。
浙江温州皮鞋湿,下雨进水不会胖。