Pytorch模型复现笔记-FPN特征金字塔讲解+架构搭建(可直接copy运行)+冒烟测试
文章目录
- 1. FPN的出现背景
- 2. FPN特征金字塔核心思路
- 3. 所以小尺寸,富有更多语义特征的特征图,要怎么和大尺寸,空间信息更多的特征图进行融合?
- 4. SO,FPN一般怎么用?
- 5. Pytorch实战部分 搭建FPN网络架构
- 5.1 Bottlenect搭建
- 5.2 FPN架构搭建
- 5.3 冒烟测试
1. FPN的出现背景
在FPN出现之前,多目标检测面临一个核心矛盾:
- 浅层网络包含丰富的空间信息,但是语义信息不足
- 深层网络包含丰富的语义信息(图片里有什么),但是空间信息不足(这东西在哪里?)

SSD类型的检测器就是该矛盾的经典受害者之一,其检测器在检测不同尺寸的物体的时候效果并不是很好,不是只能检测小物体,就是只能检测大物体。为了解决这个矛盾,研究人员提出了几种解决方案:
-
图像金字塔
如下图所示,其核心思想是将图像缩放到不同尺寸,然后分别送入不同的输入尺寸卷积网络提取对应尺寸的特征图,并且直接对该尺寸特征图进行预测。

这种方法效果上佳,什么尺寸的物体都能检测的很好,唯一比较难绷的地方就是计算量太尼玛大了。你要是四个网络能并行运行还好,四个网络要是串行那就够你等了。 -
利用CNN固有的金字塔结构(SSD-LIKE Pyramid feature hierarchy):
研究人员盯着SSD看来一会儿:欸,这中间的特征图们不也是形成了一个金字塔结构吗?把这些特征图也用来预测不就完事了?还只有一次前向传播!哇简直就是免费的午餐!然后就出现了如下的,称为SSD-LIKE Pyramid feature hierarchy的金字塔结构来提取多尺度信息:

想法很好,但是天下没有免费的午餐。你想让一个刚卷完几次,尺寸刚缩小一点,自己都还没搞清楚自己里面有美女还是豪车的特征图去找到美女和豪车在哪里,对网络是一件非常残忍的事情(更学术一点,就是语义信息不足产生的语义鸿沟让检测效果不会很好)
2. FPN特征金字塔核心思路
现在问题很明确了。FPN的作者既想利用SSD-LIke 金字塔的只需要一次前向传播的性能优势来解决图像金字塔速度太慢的问题,又要解决SSD-LIKE金字塔的语义鸿沟问题(浅层特征语义信息不足)。
几个研究哥们知道天下没有免费的午餐,但是哥几个也不想花太多精力去倒腾复杂的网络结构,于是几个天才脑瓜直接倒反天罡,把顶层有最强语义信息的特征图直接倒过来一层层往下与空间信息越来越强的特征图进行融合,然后再每一层融合之后的特征图分别进行融合,这样,网络就能 “既知道图片里面有美女和机车,也知道美女和机车再图片的哪里”了。

3. 所以小尺寸,富有更多语义特征的特征图,要怎么和大尺寸,空间信息更多的特征图进行融合?
这是一个关键的问题,FPN设计了如下手法将它两进行融合:
- 把小尺寸,但是有更多语义语义信息的特征图放大到和下一层特征图相同的尺寸
- 把上一层的特征图输出进行1x1卷积调整到与上一层相同的通道数
然后直接把这两玩意加起来,没错,就是+起来这么简单粗暴,然后就成功融合在一起了。

4. SO,FPN一般怎么用?
一般来说,你可以有两种方法来运用FPN:

一种是在每个层级的特征图都独立的接一个检测头进行预测,每个层级的检测头负责不同尺寸的物体。(如上图中下面的例子)
另一种则是指在最后的,融合和所有层级特征的特征图上,由一个统一的,功能强大的预测头来完成。
至于这两种方法有什么优劣式,等我真用它两来做实验了再说吧。
5. Pytorch实战部分 搭建FPN网络架构
光说不练假把式,现在我们直接搓一个FPN架构出来,以冒烟测试成功为目标。
先来把FPN的几个核心组件标上序号,并且说一下大概的作用:
| 组件 | 作用 | 对应代码部分 |
|---|---|---|
| 预卷积网络-生成C1特征图(不参与金字塔构造) | 提取底层特征(竖线,横线等) | self.stem |
| 骨干网络(类ResNet结构自底向上,生成C2->C5特征图) | 提取多尺度特征 | c2_stage-c5_stage |
| 自顶向下路径(P5->P2) | 通过上采样传递高层语义信息 | self._upsample_and_add 函数内部的 F.interpolate |
| 横向连接 | 将不同层级的特征对齐通道后融合 | self.p5_lat_conv, self.p4_lat_conv, self.p3_lat_conv, self.p2_lat_conv |
| 特征平滑层(图中黄色的框就是平滑之后的结果) | 消除上采样带来的混叠效应 | self.p4_smooth_conv, self.p3_smooth_conv, self.p2_smooth_conv |
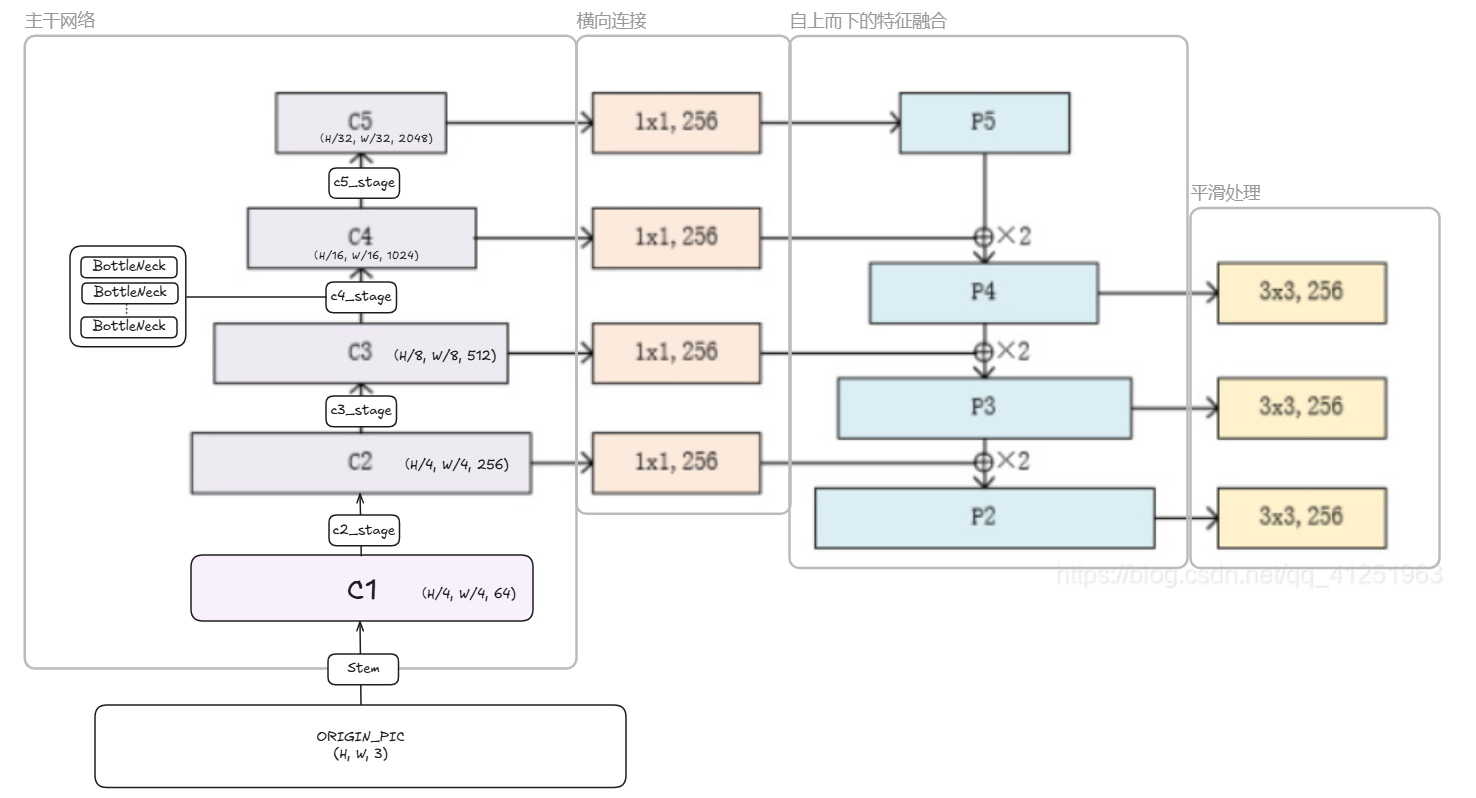
原图没有C1,我给它加上了,我一开始也还纳闷怎么直接从C2开始的。
5.1 Bottlenect搭建
什么?你不知道Bottlenect是什么?别担心,这很正常(我刚看到的时候也不懂)。先前我们说了主干网络是类Resnet结构,其负责输出c2-c5的基本砖块给FPN进行特征融合。而BottleNeck则这个类Resnet主干网络里面的 基本单元,具有残差结构设计,其结构长这样:

对应在图中,每一个产生c2-c5的 layer (比如 self.layer2) 都是由多个 Bottleneck 模块堆叠而成的。
OK,现在直接根据图写pytorch代码:
这个FPN类的设计思路是一体化,将主干网络Backbone和特征金字塔合起来实现了
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import math
import torch# resNet的基本BottleNect类
# 构建主干网络中输出c2-c5的基本砖块
# 每一个 layer (比如 self.layer2) 都是由多个 Bottleneck 模块堆叠而成的。
class BottleNeck(nn.Module):expansion = 4 # 定义输出通道相对于输出平面的倍增系数为4def __init__(self, in_channels, planes, stride=1, downsample=None):super().__init__()# 核心结构:1x1降维 -> 3x3卷积 -> 1x1升维self.bootlenect_convs = nn.Sequential(nn.Conv2d(in_channels, planes, kernel_size=1, bias=False), # 1x1吧维度降下来, 从in_channels降到planes通道数, (neck的实际通道数)nn.BatchNorm2d(planes)nn.ReLU(inplace=True), # 就地操作?nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False), # 在窄维度上卷积,节省计算量nn.BatchNorm2d(planes),nn.ReLU(inplace=True),nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False), # 把窄维度(脖子)升维到其x4的倍数的通道数nn.BatchNorm2d(self.expansion*planes,)self.relu = nn.ReLU(inplace=True)self.downsample = downsample # 用于处理残差连接输入和输入维度不匹配的情况(1x1卷积法)def forward(self, x):# 残差连接, Resnet里面的残差连接方式identity = xout = self.bottleneck_convs(x)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return out
5.2 FPN架构搭建
有了BottleNeck类,现在我们就可以来实现图中的整个网络了。其继承了ResNet主干网络和FPN头。
class FPN(nn.Module):"""一个集成了ResNet主干和FPN头的完整模型。初始化时需提供一个列表,定义ResNet每个阶段的Bottleneck数量。例如, ResNet-50 对应 [3, 4, 6, 3]。"""def __init__(self, blocks_per_layers):super().__init__()self.in_channels=64# ===================================================================# 1. ResNet 主干网络 (Backbone) - FPN的“自下而上”路径# ===================================================================# Stem层:处理初始输入图像self.stem = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False), # size / 2nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # size / 4)# 四个主要的stage, 用于提取不同层级的特征图 C2, C3, C4, C5self.c2_stage = self._make_stage(64, block_per_layer[0]) # 在这个 Stage 内部的所有 Bottleneck 模块中,那个起核心作用的 3x3 卷积层的输入和输出通道数 + 这个stage有多少bottlenect块self.c3_stage = self._make_stage(128, blocks_per_layer[1], stride=2) # 尺寸缩小一倍self.c4_stage = self._make_stage(256, blocks_per_layer[2], stride=2)self.c5_stage = self._make_stage(512, blocks_per_layer[3], stride=2)# ===================================================================# 2. FPN 头部 (Head) - FPN的“自上而下”路径和“横向连接”# ===================================================================# FPN统一输出通道数fpn_out_channels=256# 横向连接,使用1x1卷积统一主干网络各层输出的通道self.p5_lat_conv = nn.Conv2d(2048, fpn_out_channels, kernel_size=1)self.p4_lat_conv = nn.Conv2d(1024, fpn_out_channels, kernel_size=1)self.p3_lat_conv = nn.Conv2d(512, fpn_out_channels, kernel_size=1)self.p2_lat_conv = nn.Conv2d(256, fpn_out_channels, kernel_size=1)# 平滑层,使用3x3卷积处理融合后的特征,消除混叠效应self.p4_smooth_conv = nn.Conv2d(fpn_out_channels, fpn_out_channels, kernel_size=3, padding=1)self.p3_smooth_conv = nn.Conv2d(fpn_out_channels, fpn_out_channels, kernel_size=3, padding=1)self.p2_smooth_conv = nn.Conv2d(fpn_out_channels, fpn_out_channels, kernel_size=3, padding=1)def _make_stage(self, planes, num_blocks, stride=1):"""构建ResNet的一个Stage(多个BottleNect组成)"""# planes:在这个 Stage 内部的所有 Bottleneck 模块中,那个起核心作用的 3x3 卷积层的输入和输出通道数downsample=None# 当 stride!=1 (空间下采样) 或 输入通道数不匹配时,需要downsample来调整残差连接的维度(发生在第一个bottleneck块)if stride != 1 or self.in_channels != Bottleneck.expansion * planes:downsample = nn.Sequential(nn.Conv2d(self.in_channels, Bottlenect.expansion * planes, kernel_size=3, stride=stride, bias=False),nn.BatchNorm2d(BottleNeck.expansion * planes)layers = []layers.append(BottleNeck(self.in_channels. planes, stride, downsample))self.in_channels = planes * BottleNect.expansionfor _ in range(1, num_blocks):layers.append(BottleNeck(self.in_channels. planes)) # 只在第一个块进行通道调整return nn.Sequential(*layers)def _upsample_and_add(self, p, c_lat):"""核心融合操作:上采样 + 逐元素相加"""_, _, H, W = c_lat.shape# 将高层特征p上采样到与底层横向连接特征c_lat相同的尺寸,然后相加return F.interpolate(p, size=(H, W), mode='bilinear', align_corners=False) + c_latdef forward(self, x):# 1. 自下而上路径:通过主干网络提取特征c1_out = self.stem(x)c2_out = self.c2_stage(c1_out)c3_out = self.c3_stage(c2_out)c4_out = self.c4_stage(c3_out)c5_out = self.c5_stage(c4_out)# 2. 自上而下路径,特征融合# 横向链接统一通道p5_lat = self.p5_lat_conv(c5_out)p4_lat = self.p4_lat_conv(c4_out)p3_lat = self.p3_lat_conv(c3_out)p2_lat = self.p2_lat_conv(c2_out)# 自顶向下进行上采样和融合p5_out = p5_lat # P5直接由C5的横向连接得到p4_fused = self._upsample_and_add(p5_out, p4_lat)p3_fused = self._upsample_and_add(p4_fused, p3_lat)p2_fused = self._upsample_and_add(p3_fused, p2_lat)# 对融合后的特征进行平滑处理,得到最终的金字塔输出p4_out = self.p4_smooth_conv(p4_fused)p3_out = self.p3_smooth_conv(p3_fused)p2_out = self.p2_smooth_conv(p2_fused)# 以元组形式返回FPN各层输出,通常从最精细的P2到最粗糙的P5return p2_out, p3_out, p4_out, p5_out 5.3 冒烟测试
if __name__ == "__main__":device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"print(f"Using {device} device")# 冒烟测试net_fpn = FPN([3, 4, 6, 3]).to(device)print(net_fpn)input = torch.randn(1, 3, 224, 224, device=device)output = net_fpn(input)print(output[0].shape)
冒烟成功,运行结果如下:
Using cpu device
FPN((stem): Sequential((0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False))(c2_stage): Sequential((0): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(c3_stage): Sequential((0): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(3): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(c4_stage): Sequential((0): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(3): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(4): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(5): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(c5_stage): Sequential((0): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck_convs): Sequential((0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(p5_lat_conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))(p4_lat_conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(p3_lat_conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))(p2_lat_conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))(p4_smooth_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(p3_smooth_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(p2_smooth_conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
torch.Size([1, 256, 56, 56])