机器学习之随机森林(Random Forest)实战案例
一、算法基础
首先,来介绍一下算法的基础语法
class sklearn.ensemble.RandomForestClassifier(\
n_estimators=’warn’,\
criterion=’gini’,\max_depth=None, \
min_samples_split=2,\
min_samples_leaf=1, \
min_weight_fraction_leaf=0.0, \
max_features=’auto’, \
max_leaf_nodes=None, \
min_impurity_decrease=0.0, \
min_impurity_split=None, \
bootstrap=True, \
oob_score=False, \
n_jobs=None, \
random_state=None, \
verbose=0, \
warm_start=False, \
class_weight=None)随机森林重要的一些参数:
1.n_estimators :(随机森林独有)
随机森林中决策树的个数。
在0.20版本中默认是10个决策树;
在0.22版本中默认是100个决策树;
2. criterion :(同决策树)
节点分割依据,默认为基尼系数。
可选【entropy:信息增益】
3.max_depth:(同决策树)【重要】
default=(None)设置决策树的最大深度,默认为None。
【(1)数据少或者特征少的时候,可以不用管这个参数,按照默认的不限制生长即可
(2)如果数据比较多特征也比较多的情况下,可以限制这个参数,范围在10~100之间比较好】
4.min_samples_split : (同决策树)【重要】
这个值限制了子树继续划分的条件,如果某节点的样本数少于设定值,则不会再继续分裂。默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则建议增大这个值。
5.min_samples_leaf :(同决策树)【重要】
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
【叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。】
【比如,设定为50,此时,上一个节点(100个样本)进行分裂,分裂为两个节点,其中一个节点的样本数小于50个,那么这两个节点都会被剪枝】
6.min_weight_fraction_leaf : (同决策树)
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。【一般不需要注意】
7.max_features : (随机森林独有)【重要】
随机森林允许单个决策树使用特征的最大数量。选择最适属性时划分的特征不能超过此值。
当为整数时,即最大特征数;当为小数时,训练集特征数*小数;
if “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features.
【增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。】
8.max_leaf_nodes:(同决策树)
通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
【比如,一颗决策树,如果不加限制的话,可以分裂100个叶子节点,如果设置此参数等于50,那么最多可以分裂50个叶子节点】
9.min_impurity_split:(同决策树)
这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。一般不推荐改动默认值1e-7。
10.bootstrap=True(随机森林独有)
是否有放回的采样,按默认,有放回采样
11. n_jobs=1:
并行job个数。这个在是bagging训练过程中有重要作用,可以并行从而提高性能。1=不并行;
n:n个并行;
-1:CPU有多少core,就启动多少job。
二 、垃圾邮件的分析
数据附在该博客上,可自行下载
现在有几十个特征的数据,用该带标签数据训练摩西分析一个邮件是否为垃圾邮件
代码实现:
1. 导入必要的库
首先导入数据分析、机器学习模型、评估指标和可视化所需的库:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix2. 设置中文显示
确保 matplotlib 能够正常显示中文:
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False3. 定义混淆矩阵可视化函数
创建一个专门用于绘制混淆矩阵的函数,方便后续调用:
def cm_plot(y, yp):"""绘制混淆矩阵"""cm = confusion_matrix(y, yp)plt.matshow(cm, cmap=plt.cm.Blues) # 绘制混淆矩阵plt.colorbar() # 颜色条# 在矩阵中标记数值for x in range(len(cm)):for y in range(len(cm)):plt.text(x, y, cm[x, y], ha='center', va='center')plt.xlabel('预测值')plt.ylabel('真实值')plt.title('混淆矩阵')plt.show()4. 数据加载与预处理
读取数据集并进行基本的数据准备工作:
# 读取数据
data = pd.read_csv('spambase.csv')
x = data.iloc[:, :-1] # 特征(取所有行,除最后一列外的所有列)
y = data['label'] # 目标变量(假设最后一列名为'label')# 划分训练集和测试集
xtr, xte, ytr, yte = train_test_split(x, y, test_size=0.3, random_state=49)5. 数据平衡处理(未实际使用)
这段代码实现了数据平衡处理,但后续模型训练并未使用平衡后的数据:
# 数据平衡处理示例(未在后续模型中使用)
new_date = xtr.copy()
new_date['label'] = ytr
positive_eg = new_date[new_date['label']==0] # 正例(非垃圾邮件)
negative_eg = new_date[new_date['label']==1] # 负例(垃圾邮件)
positive_eg = positive_eg.sample(len(negative_eg)) # 下采样正例以平衡数据
date_c = pd.concat([positive_eg, negative_eg]) # 合并平衡后的数据集6. 构建与训练随机森林模型
使用随机森林算法构建分类模型并进行训练:
# 构建随机森林模型
rf = RandomForestClassifier(n_estimators=100, # 树的数量max_features=0.8, # 每棵树使用的特征比例random_state=0, # 随机种子,保证结果可复现
)
rf.fit(xtr, ytr) # 使用训练集训练模型7. 模型评估
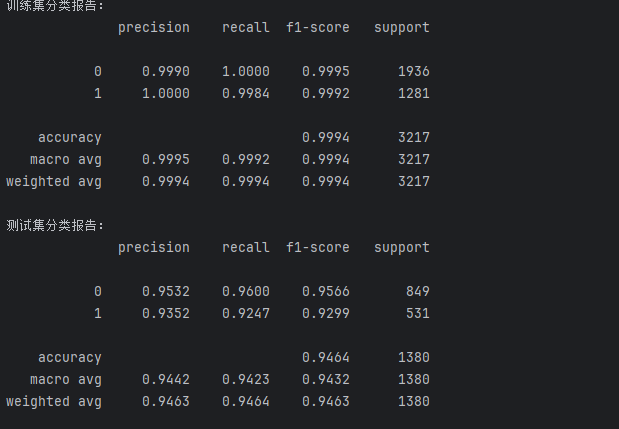
分别在训练集和测试集上评估模型性能:
# 训练集预测与评估
train_predicted = rf.predict(xtr)
print("训练集分类报告:")
print(metrics.classification_report(ytr, train_predicted, digits=4))# 测试集预测与评估
test_predicted = rf.predict(xte)
print("测试集分类报告:")
print(metrics.classification_report(yte, test_predicted, digits=4))# 绘制测试集的混淆矩阵
cm_plot(yte, test_predicted)8. 特征重要性分析
分析并可视化模型中最重要的特征:
# 特征重要性分析
importances = rf.feature_importances_
# 创建特征重要性DataFrame
importance_df = pd.DataFrame({'特征名称': x.columns, # 使用特征列名'重要性': importances
})# 按重要性降序排序并取前10
top10_features = importance_df.sort_values(by='重要性', ascending=False).head(10)# 绘制特征重要性条形图
plt.figure(figsize=(10, 6))
index = range(len(top10_features))
plt.yticks(index, top10_features['特征名称'])
plt.barh(index, top10_features['重要性'], color='skyblue')
plt.xlabel('特征重要性')
plt.title('随机森林模型特征重要性(前10)')
plt.gca().invert_yaxis() # 让最重要的特征显示在顶部
plt.show()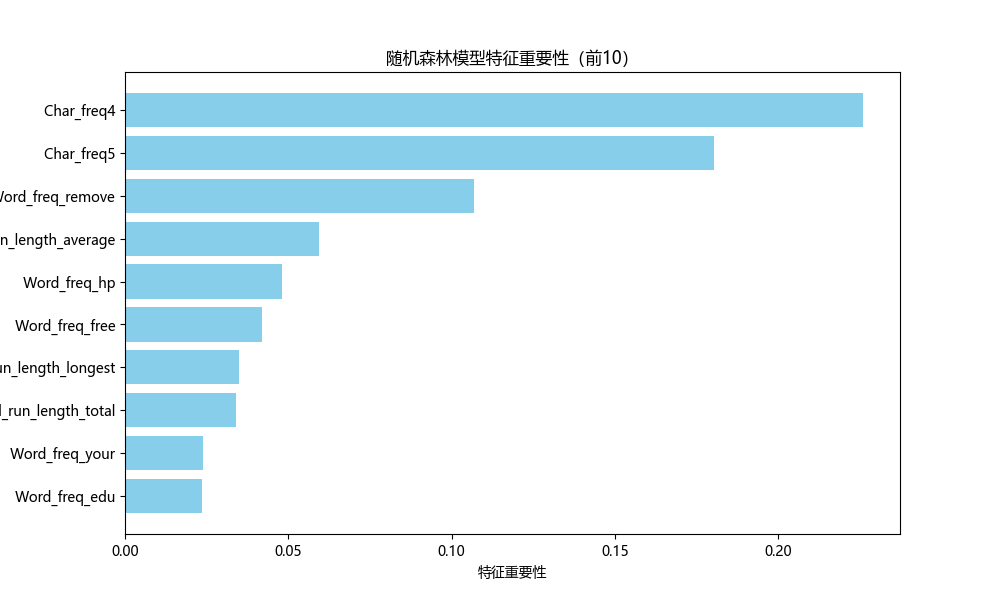
随机森林不仅将训练模型的准确率高,还能将重要的特征提取出来
三、尝试之前的银行案例
这里就不做解释了,具体实现去我的博客机械学习中的一些优化算法(以逻辑回归实现案例来讲解)里面看详情
from sklearn.preprocessing import StandardScaler
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import matplotlib.pyplot as plt# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = Falsedef cm_plot(y, yp):"""绘制混淆矩阵"""from sklearn.metrics import confusion_matriximport matplotlib.pyplot as pltcm = confusion_matrix(y, yp)plt.matshow(cm, cmap=plt.cm.Blues) # 绘制混淆矩阵plt.colorbar() # 颜色条# 在矩阵中标记数值for x in range(len(cm)):for y in range(len(cm)):plt.text(x, y, cm[x, y], ha='center', va='center')plt.xlabel('预测值')plt.ylabel('真实值')plt.title('混淆矩阵')plt.show()# 读取数据
date = pd.read_csv('creditcard.csv')
sal = StandardScaler()
date['Amount'] = sal.fit_transform(date[['Amount']])
date = date.drop(['Time'],axis = 1)x = date.iloc[:,:-1]
y = date['Class']xtr,xte,ytr,yte=train_test_split(x,y,test_size=0.3,random_state=42)new_date = xtr.copy()
new_date['label'] = ytr
positive_eg = new_date[new_date['label']==0]
negative_eg = new_date[new_date['label']==1]
positive_eg = positive_eg.sample(len(negative_eg))
date_c = pd.concat([positive_eg,negative_eg])xtr = date_c.iloc[:,:-1]
ytr = date_c['label']
# 构建随机森林模型
rf = RandomForestClassifier(n_estimators=100,max_features=0.8,random_state=0
)
rf.fit(xtr, ytr)# 训练集预测与评估
train_predicted = rf.predict(xtr)
print("训练集分类报告:")
print(metrics.classification_report(ytr, train_predicted, digits=4))# 测试集预测与评估
test_predicted = rf.predict(xte)
print("测试集分类报告:")
print(metrics.classification_report(yte, test_predicted, digits=4))cm_plot(yte, test_predicted)# 特征重要性分析
importances = rf.feature_importances_
# 创建特征重要性DataFrame
importance_df = pd.DataFrame({'特征名称': x.columns, # 直接使用特征列名'重要性': importances
})# 按重要性降序排序并取前10
top10_features = importance_df.sort_values(by='重要性', ascending=False).head(10)# 绘制特征重要性条形图
plt.figure(figsize=(10, 6))
index = range(len(top10_features))
plt.yticks(index, top10_features['特征名称'])
plt.barh(index, top10_features['重要性'], color='skyblue')
plt.xlabel('特征重要性')
plt.title('随机森林模型特征重要性(前10)')
plt.gca().invert_yaxis() # 让最重要的特征显示在顶部
plt.show()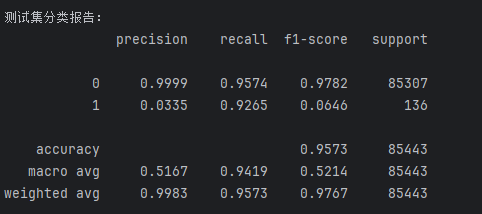
看结果可以发现,随机森林直接训练就和之前又是调参,又是交叉验证的出来的结果差不多了,我们后面学习的算法一般都比前面的效果好,但前面是打基础的,防止后面看不懂
你们也可以试试随机森林训练后再调参和交叉验证,这里就不示例代码了
最后模型召回率能达到99%