Qwen系列模型
Qwen 1 / 1.5 系列模型技术解析
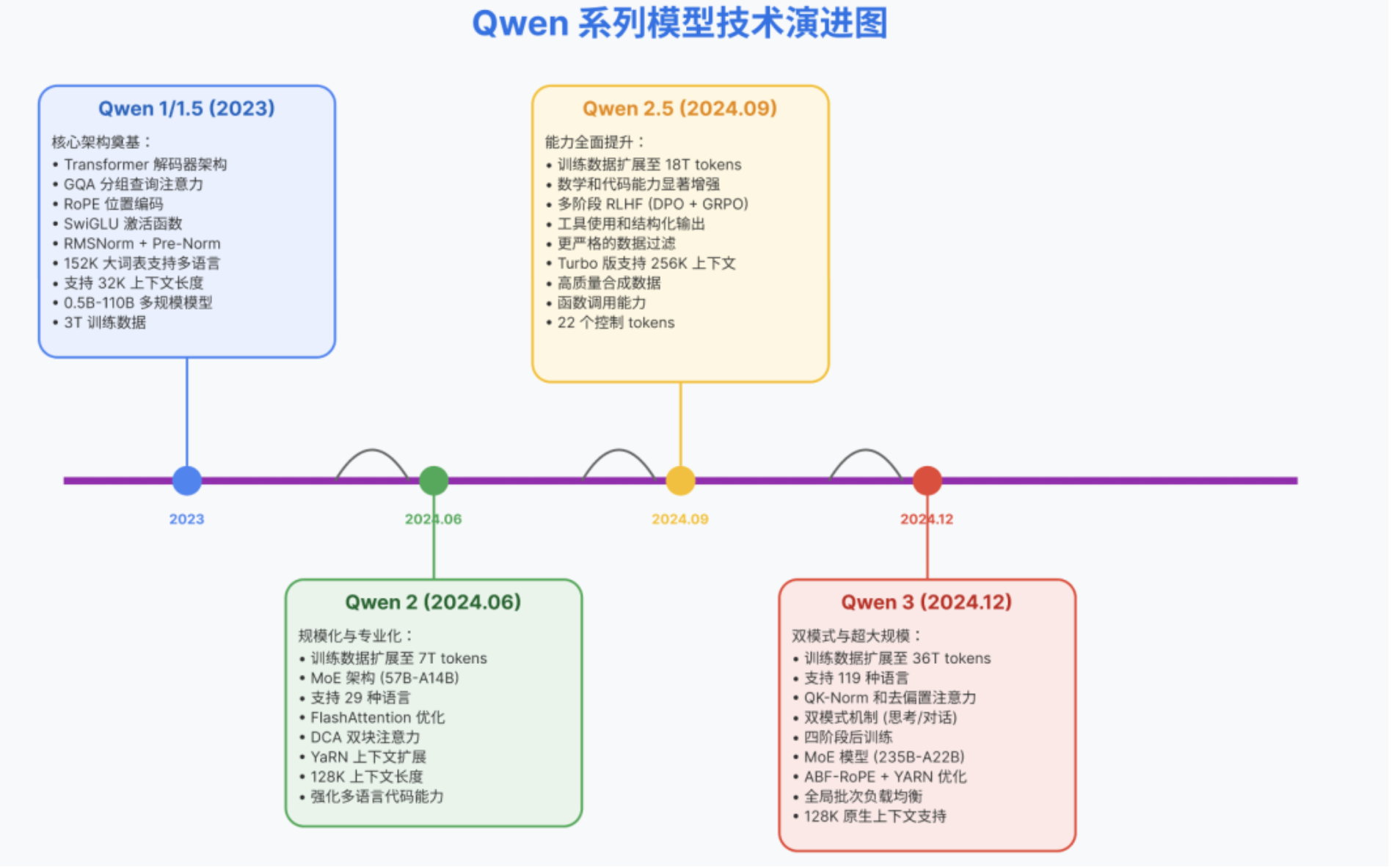
通义千问(Qwen)1 系列模型采用经典的 Transformer 解码器架构,是标准的自回归大语言模型框架。在此基础上,Qwen 引入了一些改进和定制设计:
- Transformer Decoder 架构
- 分组查询注意力(Grouped Query Attention, GQA)
- RoPE:
Qwen 在实现中使用了 FP32 精度 来计算 RoPE 的频率矩阵,以确保在长上下文情况下的数值稳定性和精度。这为后续扩展上下文长度打下基础。- 词典输入输出投影权重不共享参数:
实验发现这可以提升模型效果,但代价是略增内存消耗。- 去 Bias 处理:
以简化模型和提高训练稳定性。但在注意力层的 Q、K、V 投影中保留了偏置。研究表明,在 QKV 添加偏置有助于增强模型长上下文外推能力(即在上下文长度超出训练范围时保持稳定的注意力分布)。- Pre-Norm与 RMSNorm
- SwiGLU与FFN隐藏层从4倍到3倍:
以配合GLU的门控机制减少参数量,但性能无明显损失。- NTK 插值方法和窗口化注意力策略扩展上下文长度:
预训练时通常为2048(部分新版小模型已扩展至8192),推理阶段通过无需重新训练的技巧实现了长上下文扩展。
https://blog.csdn.net/weixin_59191169/article/details/148560050