Linux中进程地址空间
目录
- 程序地址空间
- 进程地址空间
程序地址空间
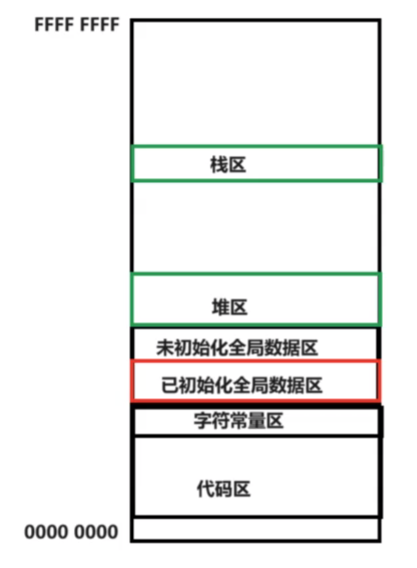
我们在学习时,通常会以这样一张表来表示程序布局,我们写的变量,对象,代码数据等就可以和这张图对应,从而区分不同数据的位置。
那么程序加载到内存后的内存布局是这个程序分布图吗?
int un_gval;
int init_gval=100;int main(int argc, char *argv[], char *env[])
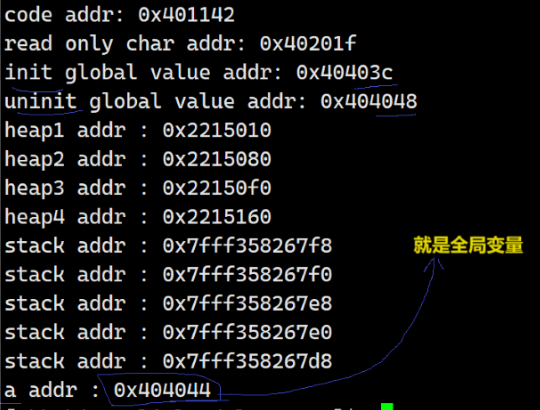
{printf("code addr: %p\n", main);//代码区const char *str = "hello Linux";printf("read only char addr: %p\n", str);//字符常量区printf("init global value addr: %p\n", &init_gval);//已初始化全局数据区printf("uninit global value addr: %p\n", &un_gval);//未初始化全局数据区char *heap1 = (char*)malloc(100); printf("heap addr : %p\n", heap1);//堆区printf("stack addr : %p\n", &str);//栈区return 0;
}
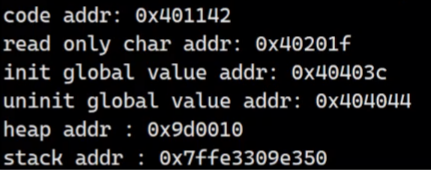
可以看到结果的确是按照程序分布图划分区域的
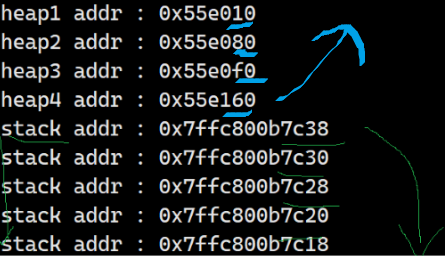
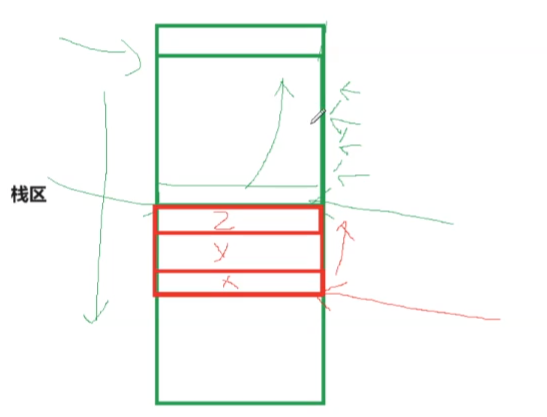
更细分的话可以看到堆向上增长,栈向下增长
复习一个概念,栈整体向下增长,但局部是向上使用的,就像数组
int a[10] , 遍历数组时通常需要++
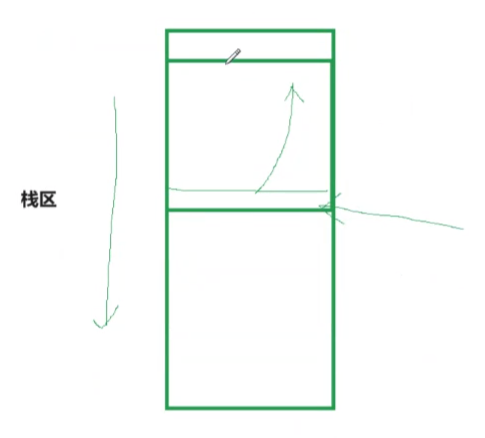
对于struct b{x,y,z} ,struct b obj 中的 &obj.x 、&obj.y 、&obj.z也是遵循这样的规则
对于一个变量a,用static修饰局部变量之后,其实是把它作为全局变量了,所以函数调用结束不会被释放
用fork演示一下
int g_val = 100;int main()
{pid_t id = fork();if (id == 0){//childint cnt = 5;while (1){printf("child, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val);sleep(1);if (cnt == 0){g_val = 200;printf("child change g_val: 100->200\n");}cnt--;}}else{//fatherwhile (1){printf("father, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val);sleep(1);}}sleep(100);return 0;
}
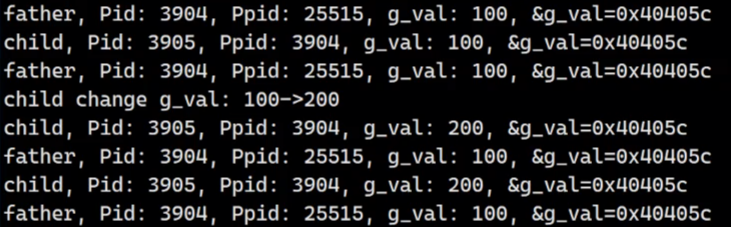
发现对于同一个g_val,同样的地址去读取,父子进程读出了不同的内容,那么我们在C/C++看到的地址,肯定不是物理地址。
我们平时遇到的地址,都是虚拟地址/线性地址
进程地址空间
物理地址,用户一概看不到,由OS统一管理
OS必须负责将 虚拟地址 转化成 物理地址
我们之前说的程序布局表准确来说是叫 进程地址空间
每一个进程运行之后,都会有一个进程地址空间的存在。
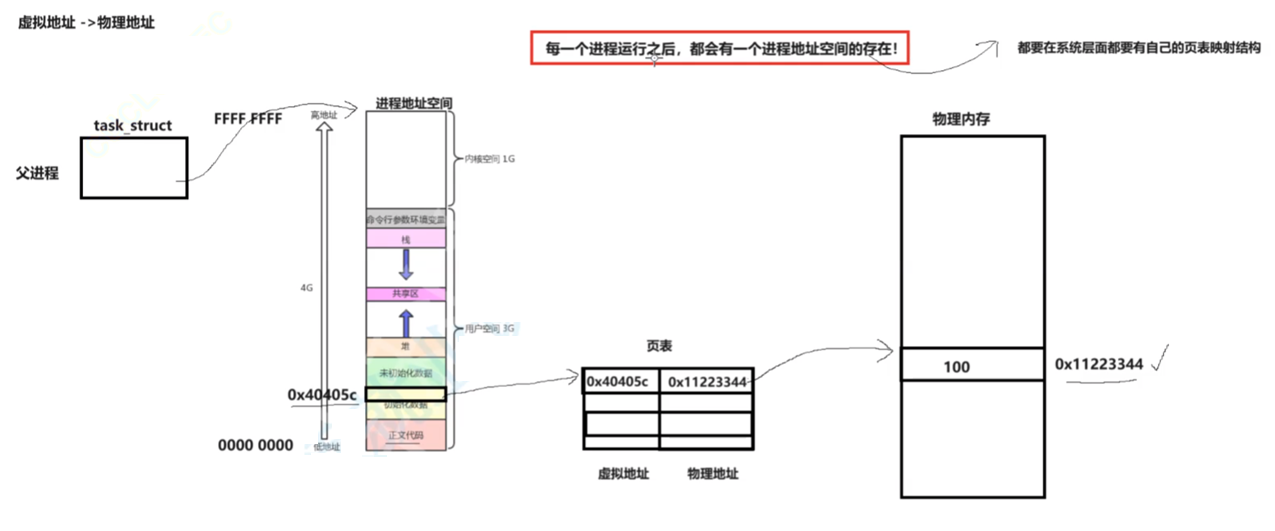
对于每一个进程,只要通过页表,就能用虚拟地址找到,定位到映射的物理地址,从而找到变量数据
创建出子进程之后,子进程要以父进程为模版拷贝PCB,除了自身pid,ppid,优先级等。然后拷贝进程地址空间,让自己的PCB指向自己的进程地址空间,再拷贝页表。
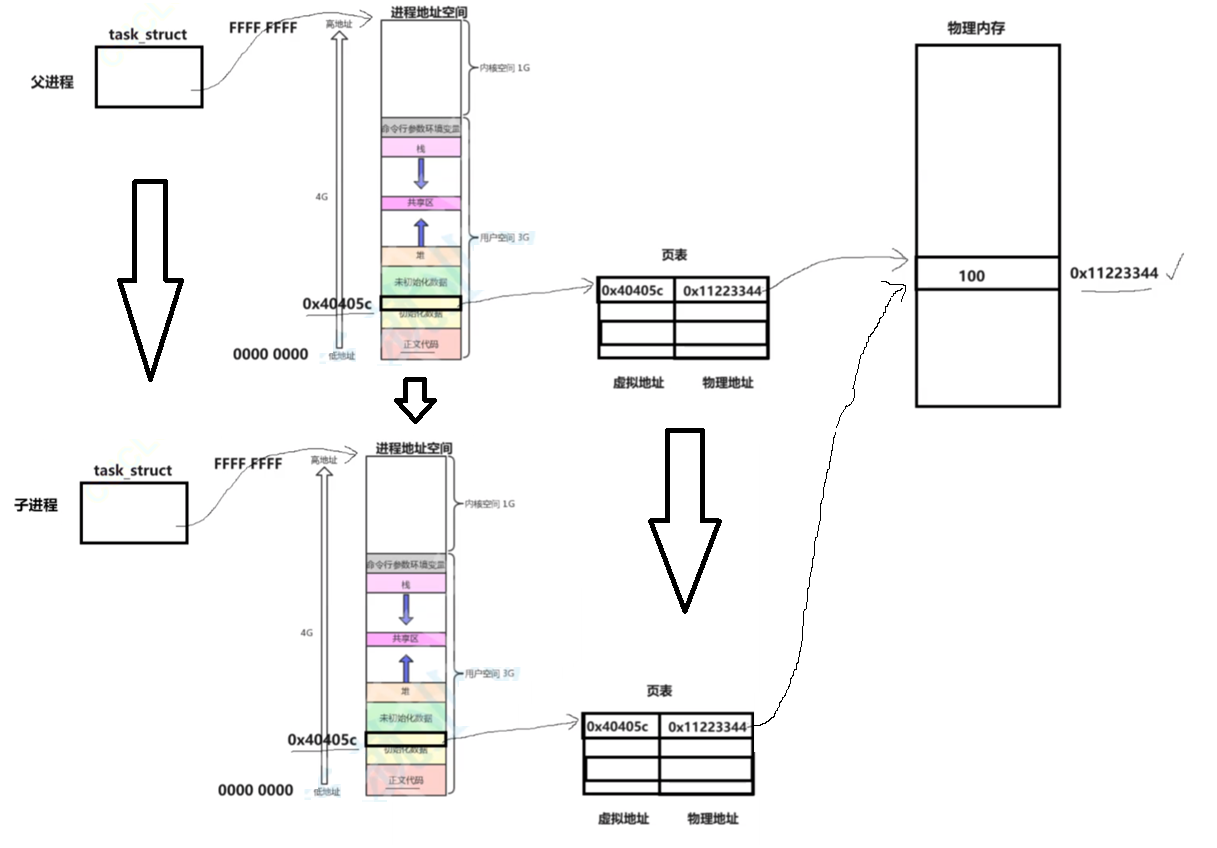
如果这个时候,子进程想修改g_val的值
每一个进程具有独立性,子进程读取之前会由操作系统 在物理内存中进行写时拷贝

这个进程地址空间,本质和进程的task_struct一样,是一个结构体

进程地址空间中的对不同区域划分,代码区、栈区,本质就是赋不同的值:long code_end = 40 ,long data_start =40