zookeeper因jute.maxbuffer启动异常问题排查处理
#作者:程宏斌
文章目录
- 一、前言
- 二、问题描述
- 三、定位过程
- 四、问题根因
- 五、解决方案
- 根本解决方案
- 应急处理方案
- 调大参数可能出现的问题
- 六、总结
- 为什么超出会报错
- 官方对于jute.maxbuffer的解释
- 注意事项
- 官方建议
一、前言
在分布式系统中,ZooKeeper作为关键的协调服务,承担着数据存储与状态同步的任务。然而,在实际运行过程中,可能会遇到由于jute.maxbuffer参数配置不当而导致的启动异常问题。本报告旨在分析jute.maxbuffer相关问题导致的启动异常,包括其产生的原因、具体错误表现及排查思路,并提供有效的解决方案,以确保ZooKeeper服务的稳定运行。
二、问题描述
问题描述:
Unable to load database on disk java.io.IOException: Unreasonable length=2429535
问题导致的zookeeper启动异常的问题。
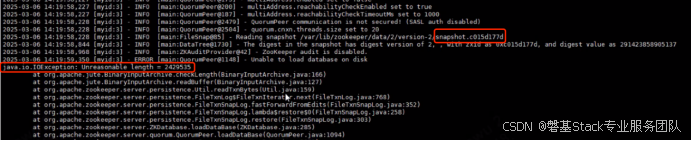
三、定位过程
通过排查日志可以发现Zookeeper在加载磁盘上的数据库时遇到异常。
具体的错误信息是Unreasonable length=2429535,ZooKeeper在加载数据库时遇到了jute.maxbuffer限制的问题。当前jute.maxbuffer的默认大小是1MB(1048575字节,官方指定),但日志中显示的长度2429535远超此值,出现Unreasonable length问题,导致zookeeper节点异常。
四、问题根因
在查看日志时,可以发现那个会话存在异常大量的ZNode节点(会有ID)。
然后查看具体的数据,看哪个节点数据异常,正常数据存放临时ZNode节点。当ZooKeeper关闭会话(CloseSession)时,会自动清理所有关联的临时ZNode,从而在事务日志中记录相应的删除操作。由于这些事务数据的总大小超过了1MB,导致无法同步至Follower节点,最终触发当前ZooKeeper节点的异常退出,进而引发集群重新选举Leader
五、解决方案
根本解决方案
1、需要排查ZNode节点数据过大的原因,并制定相应的处理方案。(需要研发确认)
2、规范zookeeper使用,严格按照官方要求使用。
3、将数据拆分到多个会话中,以避免单个会话关闭时触发大量临时节点删除,从而导致 ZooKeeper 产生过大的事务日志。(需要研发确认)
4、为不同业务分配独立的 ZNode,避免多个业务共享同一个大节点,从而降低数据量过大带来的风险。(需要研发确认)
应急处理方案
zookeeper的-DmaxBufferSize调大,具体调大到多少,需要看日志报错超出的大小。

调大参数可能出现的问题
可能会导致额外的延迟(LatencySpikes),降低吞吐量(Throughput)。
可能会使Leader与Follower之间的同步时间变得不可预测,并可能导致超时(Timeout),进而使选举仲裁节点变得不稳定。
六、总结
为什么超出会报错
1)zookeeper启动的时候会加载datalog(快照日志)进行内存数据恢复,zookeeper的快照日志是按照行记录的,在读取的时候会判断record的大小是否大于jute.maxbuffer(默认1M)。超过默认值1M,zookeeper将无法启动。
2)在closeSession写入数据的时候也是会判断节点数据大小是否大于jute.maxbuffer。
3)当一个客户端建立了很多的临时节点时,在进行closeSession的时候会把所有的临时节点的path集中在一起写到快照日志的record(因为closeSession时是需要删除所有临时节点的)。这时候record很大,超过1MB,就会超过jute.maxbuffer。造成zookeeper服务端报错。
官方对于jute.maxbuffer的解释
https://zookeeper.apache.org/doc/r3.6.3/zookeeperAdmin.html

官方翻译如下:
非安全选项
以下选项在特定情况下可能会有所帮助,但使用时需谨慎。每个选项的潜在风险将在说明其功能的同时进行解析。
jute.maxbuffer(Java系统属性:jute.maxbuffer)
此选项仅能通过Java系统属性进行配置,且无zookeeper前缀。它用于指定ZNode数据存储的最大大小,单位为字节。默认值为0xfffff(1,048,575字节,即接近1MB)。
注意事项
该属性必须在所有ZooKeeper服务器端和客户端上保持一致,否则可能会导致异常问题。
客户端jute.maxbuffer > 服务器端jute.maxbuffer:
当客户端尝试写入的数据大小超出服务器端的jute.maxbuffer限制时,服务器会报错 java.io.IOException: Len error。
客户端jute.maxbuffer < 服务器端jute.maxbuffer:
当客户端尝试读取的数据大小超出自身的jute.maxbuffer限制时,客户端会报错 java.io.IOException: Unreasonable length 或Packet len is out of range!
官方建议
ZooKeeper设计初衷是存储KB级别的数据,因此不建议在生产环境中将jute.maxbuffer调整为超过默认值,原因如下:
大体积ZNode会导致意外的延迟波动,影响吞吐量,降低整体性能。
大体积ZNode使Leader与Follower之间的同步时间变得不可预测,可能出现不同步或超时问题,进而导致集群不稳定。