人工智能——自动微分
一、自动微分的基础概念—计算图
要理解自动微分,必须先理解计算图:它是用 “节点” 和 “边” 直观表示计算过程的图形。
- 节点:分为两种 ——
- 变量节点(如输入 x、参数 w、中间结果 a、输出 y);
- 操作节点(如加法 \(+\)、乘法 \(\times\)、激活函数 \(\sigma\) 等)。
- 边:表示变量与操作之间的依赖关系(“谁是谁的输入”)
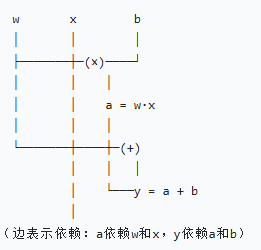
各个节点按照反向传播后,其梯度是否会被自动释放又可以分为:叶子节点和非叶子节点
1. 叶子节点(Leaf Nodes)
- 定义:用户直接创建的输入变量(如训练数据 x、模型参数 \(w, b\)),没有 “父节点”(不是任何操作的输出)。
- 特点:在反向传播中,它们的梯度会被保留(存储在
.grad属性中),因为模型训练需要用这些梯度更新参数
![]()
2. 非叶子节点(Non-leaf Nodes)
- 定义:由操作生成的中间结果(如 a = w * x、输出 y = a + b),有明确的 “父节点”(依赖其他变量)。
- 特点:反向传播后,它们的梯度会被自动释放(默认不保留),以节省内存(中间结果的梯度对参数更新没用)
![]()
有个概念:梯度的本质到底是什么,为什么x,b也有梯度?
一、先明确核心:所有梯度都是 “损失函数的偏导数”
梯度的本质是 “损失函数对某个变量的偏导数”
例如:
那么:
那上面概念中提到的梯度会被保留又是什么呢?在梯度计算过程中有什么用?
反向传播后,叶子节点的
.grad属性会存储对应的偏导数,而非叶子节点的.grad会被自动清空(节省内存)模型参数\(w, b\)的梯度的原因是:w 和 b 是模型的 “可学习参数”,训练的目标就是通过调整它们来减小损失 L。
用线性回归直观看各变量的梯度



二、自动微分的数学原理
在理解了计算图后其实就可以知道,神经网络的损失函数本质是 “多层函数嵌套的复合函数”,而链式法则正是求解复合函数导数的关键
1. 链式法则的基本形式
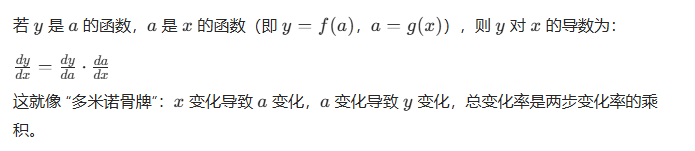
2. 多层复合函数的链式法则(对应神经网络的多层结构)
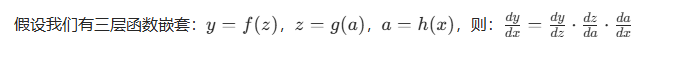
而整个反向传播的过程其实就是在进行链式求解的过程最终求出模型参数 w , b 的梯度(损失函数对其的导数)
三、自动微分的过程
自动微分在计算机中的实现,本质是通过 “追踪计算过程”+“存储梯度规则”+“反向链式计算” 三个核心步骤
第一步:判断哪些变量需要追踪计算,然后用requires_grad进行标记,后续所有涉及该变量的操作都会被记录
怎么判断一个值是否需要通过
requires_grad=True开启梯度追踪,核心原则是:该变量是否需要被 “优化”(即是否需要通过梯度来调整其值)
第二步:前向传播,从输入变量出发,按计算图的依赖关系,依次执行操作,得到输出结果(如损失函数值),同时记录每个操作的 “梯度函数”(即该操作的导数公式,用于后续反向传播)

第三步:反向传播,从输出节点(如损失函数 y)出发,按计算图反向遍历,用链式法则逐层计算每个叶子节点的梯度【其实就是链式求导】

四、总结
1、梳理一下自动微分整个过程的思路:
我们用 “学生做题” 来类比整个过:
- 模型就像 “学生”,参数 w, b是学生的 “知识储备”;
- 训练数据是 “练习题”,输入 x 是题干,真实标签 y_true 是标准答案;
- 前向传播是 “学生做题”,输出 y_pred 是学生的答案;
- 损失函数 L 是 “得分”(损失越小,得分越高);
- 反向传播是 “老师批改并分析错误”,梯度是 “错题解析”(告诉学生哪些知识错了、错多少);
- 最终目的是让学生(模型)通过修正知识(参数),下次做题(预测)更准
2、最终输出的是什么?——“错题解析”(梯度)和 “优化后的知识”(参数)
整个自动微分的过程实际上就是在求模型参数 w, b 的梯度。
但这只是中间结果,我们真正要的是通过梯度优化后的参数。就像学生拿到错题解析后,不是停在 “知道错了”,而是要 “改正错误”—— 通过梯度下降算法更新参数
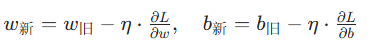
3、整个过程的思路:
我们用 “预测房价” 的例子,完整串起整个流程:
1. 准备阶段:明确 “学什么”
- 数据:已知的 “房子特征(面积、楼层)x” 和 “真实房价 y_true ;
- 模型:假设房价和特征是线性关系y_hat = w1 *{面积} + w2 * {楼层} + b 【w1, w2, b 是要学的参数】;
- 损失函数:用 “预测房价与真实房价的差距” 衡量,比如 L= (y_hat - y_true)**2。
2. 迭代训练:“尝试 - 分析 - 改进” 的循环(核心步骤)
先定义好学习率、训练轮次
第 1 步:前向传播(尝试预测)
- 输入一批房子特征 x,用当前参数计算预测房价 \(\hat{y}\)(比如初始参数随机,预测可能很离谱:面积 100㎡的房子预测成 10 万)
- 计算损失L(比如真实房价是 100 万,损失 L = (10-100)^2 = 8100
第 2 步:反向传播(分析错误)
- 从损失 L 出发,用自动微分算梯度:

第 3 步:参数更新(改进模型)
- 用梯度调整参数(比如 w1 = w1 - lr * (-1800),增大 w1;
- 此时模型的 “知识”(参数)变好了,下次预测会更准。
第 4 步:重复迭代
- 用新参数再做前向传播(预测下一批房子)、反向传播(算新梯度)、更新参数……
- 随着迭代次数增加,损失 L 越来越小(预测越来越准),直到模型能稳定预测未知房子的价格。
3. 最终结果:得到 “好用的模型”
训练结束后,我们得到优化好的参数 \(w_1, w_2, b\)。此时给一个新房子的特征(比如面积 120㎡、3 楼),模型能输出接近真实值的房价 —— 这就是整个过程的意义。
代码:
#通过自动微分求解函数参数
import torch
import matplotlib.pyplot as plt#定义数据
x = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float32)
y_true = torch.tensor([5, 7, 9, 11, 12], dtype=torch.float32)plt.scatter(x.numpy(), y_true.numpy())
plt.show()#定义参数
w = torch.tensor(2.0, dtype=torch.float32, requires_grad=True)
b = torch.tensor(3.0, dtype=torch.float32, requires_grad=True)#定义模型
def model(x):return w * x + b#定义损失函数
def loss(y_true, y_pred):return torch.mean((y_true - y_pred) ** 2)
#学习率,训练轮数
lr = 0.01
epochs = 100
loss_history = []
w_history = []
b_history = []
#训练模型
for epoch in range(epochs):#前向传播y_pred = model(x)#反向传播l = loss(y_true, y_pred)l.backward()#计算梯度#更新参数with torch.no_grad():#避免梯度更新时对梯度进行修改w -= lr * w.gradb -= lr * b.grad#梯度清零w.grad.zero_()b.grad.zero_()#记录轮次损失loss_history.append(l.item())#每10轮打印一次损失if (epoch+1) % 10 == 0:print(f'epoch/epochs {epoch+1}/{epochs}: loss {l.item():.4f}, w {w.item():.4f}, b {b.item():.4f}')
# print(loss_history)
#绘制损失曲线
plt.plot(loss_history)