nlp-句法分析
目录
一、句法概述
1、成分语法理论概述
(1)分析过程
(2)缺点
2、依存语法理论概述
(1)依存关系、配价模式
(2)分类
(3)优势:
二、成分句法分析
1、基于上下文无关文法(CFG)的成分句法分析
(1)经典分析算法:
(2)核心挑战
2、基于概率上下文无关文法(PCFG)的成分句法分析
(1)经典算法
(2) PCFG的模型参数学习过程
3、成分句法分析评价标准
三、依存句法分析
1、基于图
(1) 基本思想
(2)经典算法
非投射性依存句法分析:朱-刘/埃德蒙兹算法
投射性依存句法分析--基于动态规划的算法
2、基于神经网络的图依存句法分析
3、基于转移
4、基于神经网络的转移依存句法分析
5、依存句法分析评价方法
四、句法分析语料库
句法分析是指对输入的单词序列(一般为句子)判断其构成是否合乎给定的语法,分析合乎语法的句子的句法结构。
句法分析句法分析是句子结构和语义之间的桥梁,具有非常重要的作用,很多自然语言处理算法需要依赖句法分析结果,因此句法分析效果也直接影响到很多自然语言处理应用。句法分析是自然语言处理中长期关注的核心问题之一。
本章中,句法分析任务限定在得到完整的句法分析树,重点介绍了基于有监督机器学习算法的句法分析方法。对成分句法分析和依存句法分析分别介绍了各类型的评价方法。
一、句法概述
句法(Syntax)就是研究自然语言中不同成分组成句子的方式以及支配句子结构并决定句子是否成立的规则。
1、成分语法理论概述
成分(Constituent)又称短语结构,是指一个句子内部的结构成分,成分可以独立存在,或者可以用代词替代,又或者可以在句子中的不同位置移动。
根据不同成分之间是否可以进行相互替代而不会影响句子语法正确性可以进一步地将成分进行分类,某一类短语就属于一个句法范畴:比如“一本小说”“”一所大学”等都属于一个句法范畴:名词短语(None Phrase,NP)
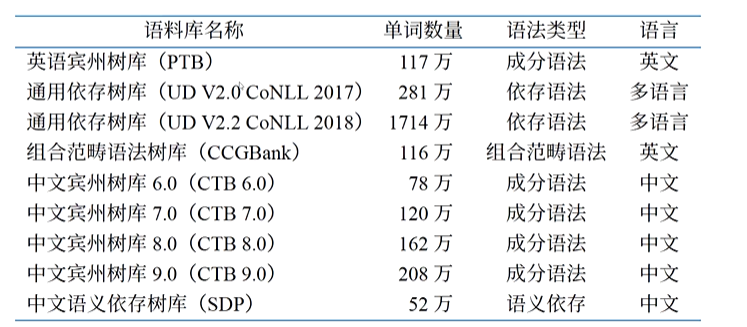
(1)分析过程
成分语法就是由句法范畴以及短语结构规则定义的语法。由于短语结构规则具有递归性,可以使短语和句子无限循环组合。
(2)缺点
由于成分语法局限于表层结构分析,不能彻底解决句法和语义问题,因比存在非连续成分、结构歧义等问题。如:
2、依存语法理论概述
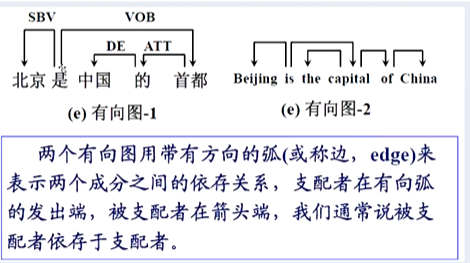
在依存语法理论中,“依存”就是指词与词之间支配与被支配的关系,这种关系不是对等的,而是有方向的。处于支配地位的成分称为支配者(governol,regent,head),而处于被支配地位的成分
称为从属者(modifier,subordinate,dependency)。
(1)依存关系、配价模式


(2)分类
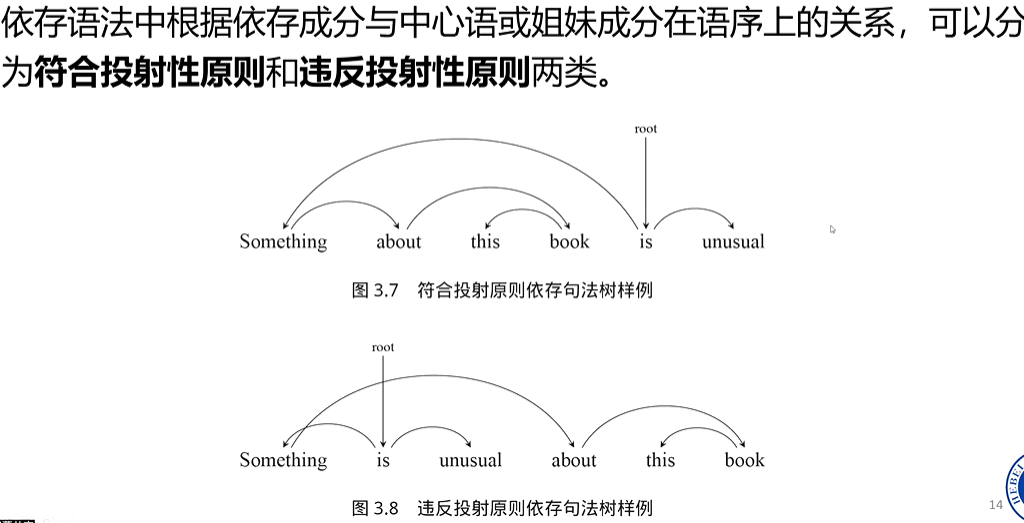
在图 3.7 “Something about this book is unusual” 中,句子里词语之间的依存关系在平面上不会出现交叉 ,就像从根节点向其他节点投射射线一样,各射线互不干扰,所以符合投射性原则。图 3.8 “Something is unusual about this book” 里,从依存关系来看,成分之间的依存连线在平面上会出现交叉 ,导致依存连线在图中出现了交叉的情况,不再是有序的投射状,所以违反了投射性原则。
(3)优势:
- 简单,直接按照词语之间的依存关系工作,是天然
- 词汇化的;不过多强调句子中的固定词序,对自由语序的语言分析更有优势;
- 受深层语义结构的驱动,词汇的依存本质是语义的:
- 形式化程度较短语结构语法浅,对句法结构的表述更为灵活。
二、成分句法分析
因句法结构歧义,句法分析需消除歧义,成分语法里结构歧义主要有两种。
- 附着歧义(Attachment ambiguity):示例为句子 “The boy saw the man with the telescope” ,即短语等成分在句法结构中 “附着” 位置不确定产生的歧义 。
- 并列连接歧义(Coordination ambiguity):示例是 “重要政策和措施” ,因并列成分的连接关系、范围等不确定,导致句法结构理解有歧义 ,比如 “(重要政策)和(措施)” 与 “重要(政策和措施)” 两种可能理解。
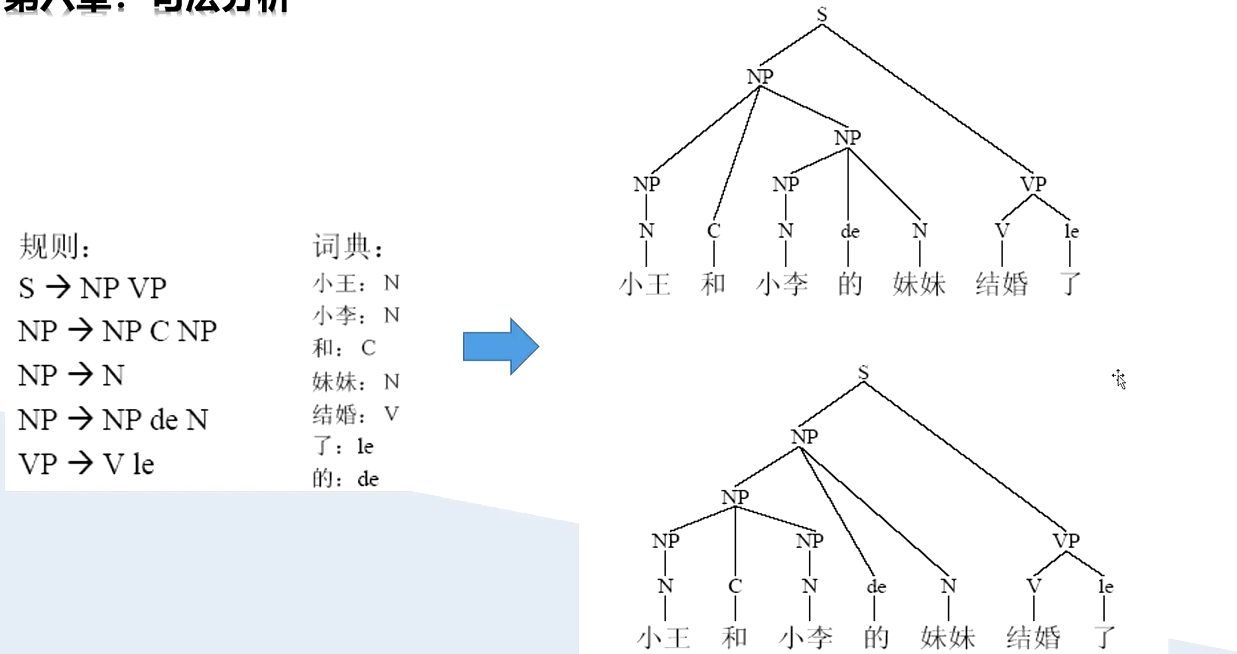
1、基于上下文无关文法(CFG)的成分句法分析
核心是通过 CFG 规则解析句子的层次化成分结构(如短语、子句等),最终生成句法树(短语结构树)来表示句子的句法组织方式。
- 成分(Constituent):指句子中具有独立句法功能的子序列(如 “名词短语 NP”“动词短语 VP”),例如 “一只黑猫” 是 NP,“在树上跳” 是 VP。
- 短语结构树:以树状结构直观展示成分的层次关系,树根为起始符号 S,叶节点为句子中的词语(终结符),中间节点为非终结符(句法范畴)

(1)经典分析算法:

 示例:【自顶向下】
示例:【自顶向下】
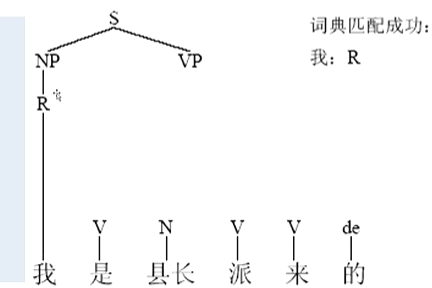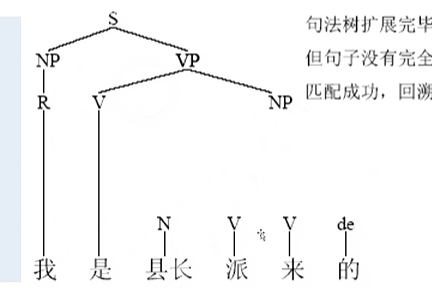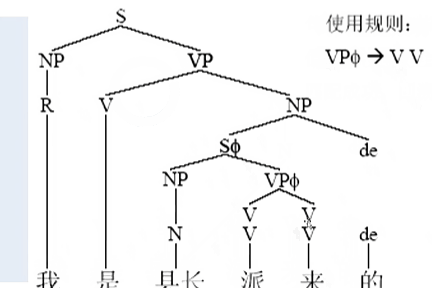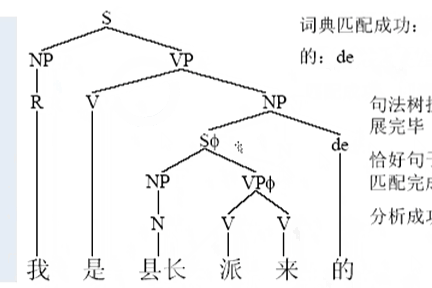
把所有的字符都吃进来的时候。这个时候就完成最终的句法的结构的生成
CYK算法【自底向上】



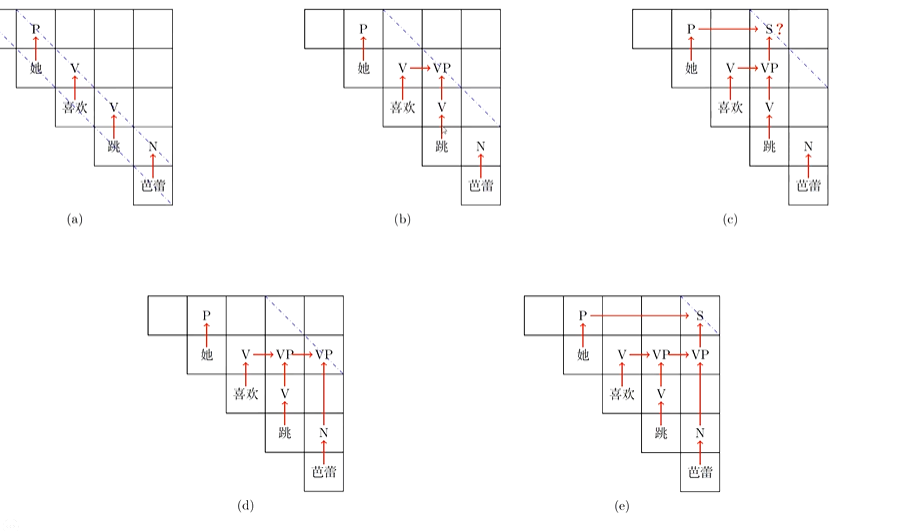
(2)核心挑战
基于 CFG 的成分分析面临的最大问题是句法歧义:同一个句子可能对应多个符合 CFG 规则的句法树。例如,句子 “咬死了猎人的狗” 存在两种歧义:
- (咬死了)(猎人的狗)——“狗” 是 “咬死了” 的宾语;
- (咬死了猎人的)狗 ——“狗” 是主语,“咬死了猎人的” 修饰 “狗”。
2、基于概率上下文无关文法(PCFG)的成分句法分析
CFG的扩展 ,为 CFG 的产生式添加概率(如 P (A→α) 表示规则 A→α 的使用概率),通过计算句法树的总概率,选择概率最高的树【Viterbi 树】作为最优解,解决了 CFG 中句法歧义问题



(1)经典算法
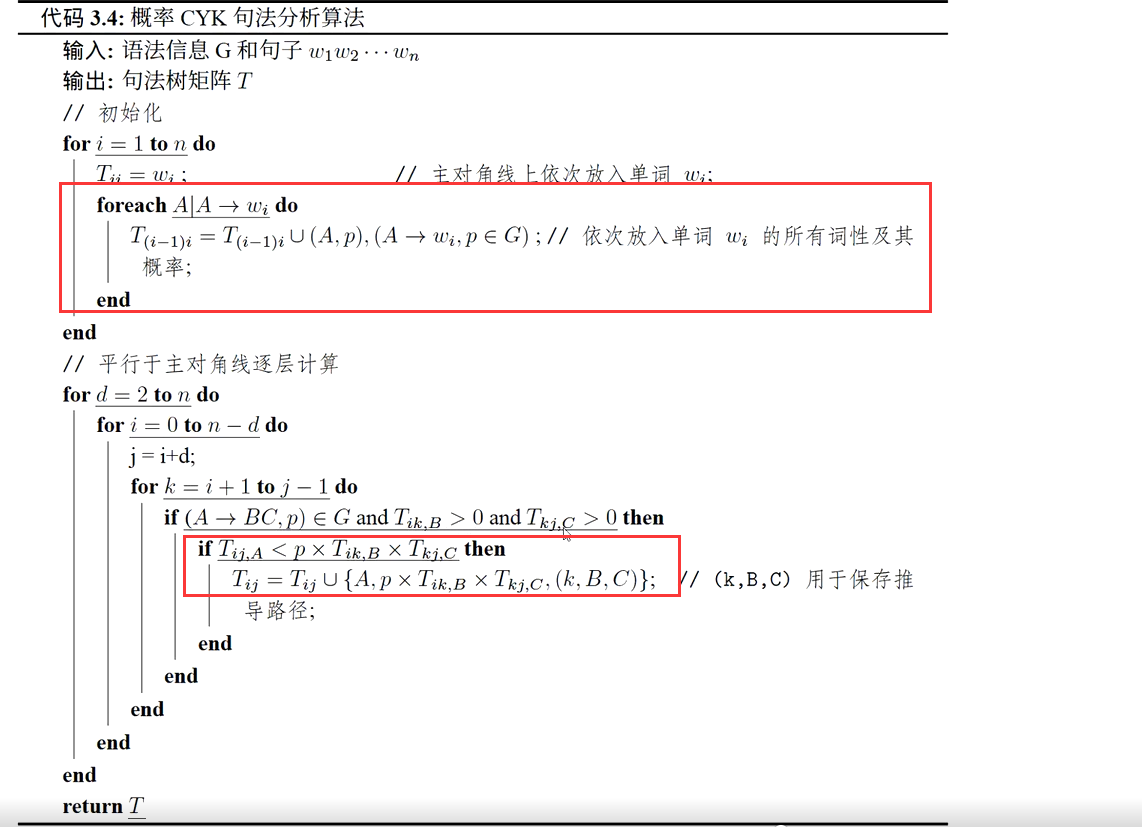
(2) PCFG的模型参数学习过程

3、成分句法分析评价标准
衡量句法分析结果与标准句法树(参考树)的契合程度

三、依存句法分析
依存句法分析(Dependency Parsing)任务目标是依据依存语法理论分析输入句子得到其依存句法结构树。

1、基于图
基于图的依存句法分析主要包含边评分模型和旬法树生成算法两个部分组成。其中边评分模型对于分析效果具有决定性的影响。核心是构造评分函数,为 “词与词之间的依存关系” 打分,最终选择分数最高的合法依存树。
(1) 基本思想
将句子中的每个词视为图的节点,词与词之间的可能依存关系视为有向边(边的方向从依存词指向中心词),通过定义 “边的打分函数” 计算每个可能依存关系的权重,最终从所有可能的依存树中选择总权重最高的树。

(2)经典算法
利用最大生成树算法得到的依存句法树不具备投射性。
针对具有投射性要求的依存句法树,可以利用其与上下文无关语法之间的强相关性,利用基于CYK 算法等上下文无关语法分析算法进行依存句法树分析。
非投射性依存句法分析:朱-刘/埃德蒙兹算法
一种带权有向图的最小/大生成树寻找算法。
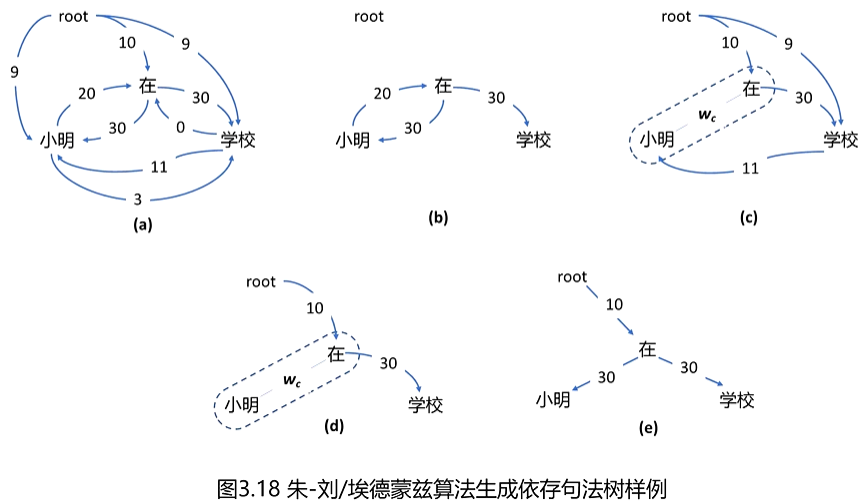
投射性依存句法分析--基于动态规划的算法

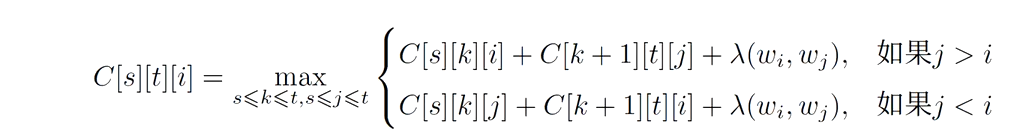
2、基于神经网络的图依存句法分析
将句子视为一个 “词节点构成的完全图”,用神经网络预测 “词与词之间的依存弧概率”,再通过图论算法(如最大生成树算法)从全图中选出最优依存树(满足无环、单根等句法约束)

3、基于转移
模拟人类 “逐步构建依存树” 的过程,通过有限状态转移(如Shift/Reduce/Arc操作)增量式生成依存树。

4、基于神经网络的转移依存句法分析
用神经网络替代转移系统中的 “手工特征 + 分类器”,学习状态到动作的映射。

5、依存句法分析评价方法
(1)无标签依存准确率

(2)有标签依存准确率