AMO:超灵巧人形机器人全身控制的自适应运动优化
25年5月来自UCSD的论文“AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control”。
人形机器人的灵活性很大程度上源于其超灵巧的全身运动,从而能够完成需要较大操作空间的任务,例如从地面拾取物体。然而,由于人形机器人的高自由度 (DoF) 和非线性动力学,在真实人形机器人上实现这些能力仍然具有挑战性。本文提出了自适应运动优化 (AMO) 框架,该框架将模拟-到-真实的强化学习 (RL) 与轨迹优化相结合,以实现实时、自适应的全身控制。为了缓解运动模仿强化学习中的分布偏差,构建一个混合 AMO 数据集,并训练一个能够对潜 O.O.D. 命令进行鲁棒且按需调整的网络。在模拟环境中以及 29 自由度的 Unitree G1 人形机器人上验证 AMO,结果表明,与强大的基准模型相比,AMO 具有更出色的稳定性和更大的工作空间。最后证明 AMO 的稳定性能够通过模仿学习支持自主执行任务,从而凸显了该系统的多功能性和鲁棒性。
人形机器人全身控制。由于人形机器人自由度高且非线性,其全身控制仍然是一个具有挑战性的问题。此前,这主要通过动态建模和基于模型的控制来实现 [14, 16, 18, 19, 31, 32, 34, 35, 51, 52, 56, 72, 75]。最近,深度强化学习方法已显示出在实现腿式机器人稳健运动性能方面的潜力 [3, 7, 8, 20, 21, 22, 23, 26, 37, 38, 39, 40, 46, 47, 61, 67, 73, 74, 79]。研究人员已经研究基于高维输入的四足机器人 [7, 8, 22, 27] 和人形机器人 [9, 24, 29, 33] 的全身控制。 [24] 训练一个 Transformer 用于控制,另一个 Transformer 用于模仿学习。[9] 只鼓励上半身模仿动作,而下半身控制则被解耦。[29] 训练下游任务的目标条件策略。所有 [9, 24, 29] 都只表现出有限的全身控制能力,这迫使人形机器人的躯干和骨盆保持静止。[33] 展示人形机器人富有表现力的全身动作,但并没有强调利用全身控制来扩展机器人的操控任务空间。
人形机器人的遥操作。人形机器人的遥操作对于实时控制和机器人数据收集至关重要。先前在人形机器人遥操作方面的研究包括 [11, 24, 28, 29, 42, 64]。例如,[24, 29] 使用第三人称 RGB 摄像机来获取人类遥操作员的关键点。一些研究利用虚拟现实 (VR) 为远程操作员提供以自我为中心的观察。[11] 使用 Apple VisionPro 通过灵巧的双手控制头部和上半身的活动。[42] 使用 VisionPro 控制头部和上半身,同时使用踏板进行运动控制。人形全身控制需要远程操作员为机器人提供物理上可实现的全身坐标。
运动-操控模仿学习。模仿学习已被研究用于帮助机器人自主完成任务。根据演示来源识别现有工作,可将模仿学习分为从真实机器人专家数据中学习 [4, 5, 12, 13, 25, 36, 54, 55, 65, 66, 76, 78]、从游戏数据中学习 [15, 50, 70] 以及从人类演示中学习 [9, 21, 24, 26, 29, 57, 58, 59, 69, 71, 73]。这些模仿学习研究仅限于操作技能,而针对运动-操作的模仿学习研究非常少。[25] 使用轮式机器人研究运动-操作的模仿学习。本文利用模仿学习使人形机器人能够自主完成运动-操作任务。
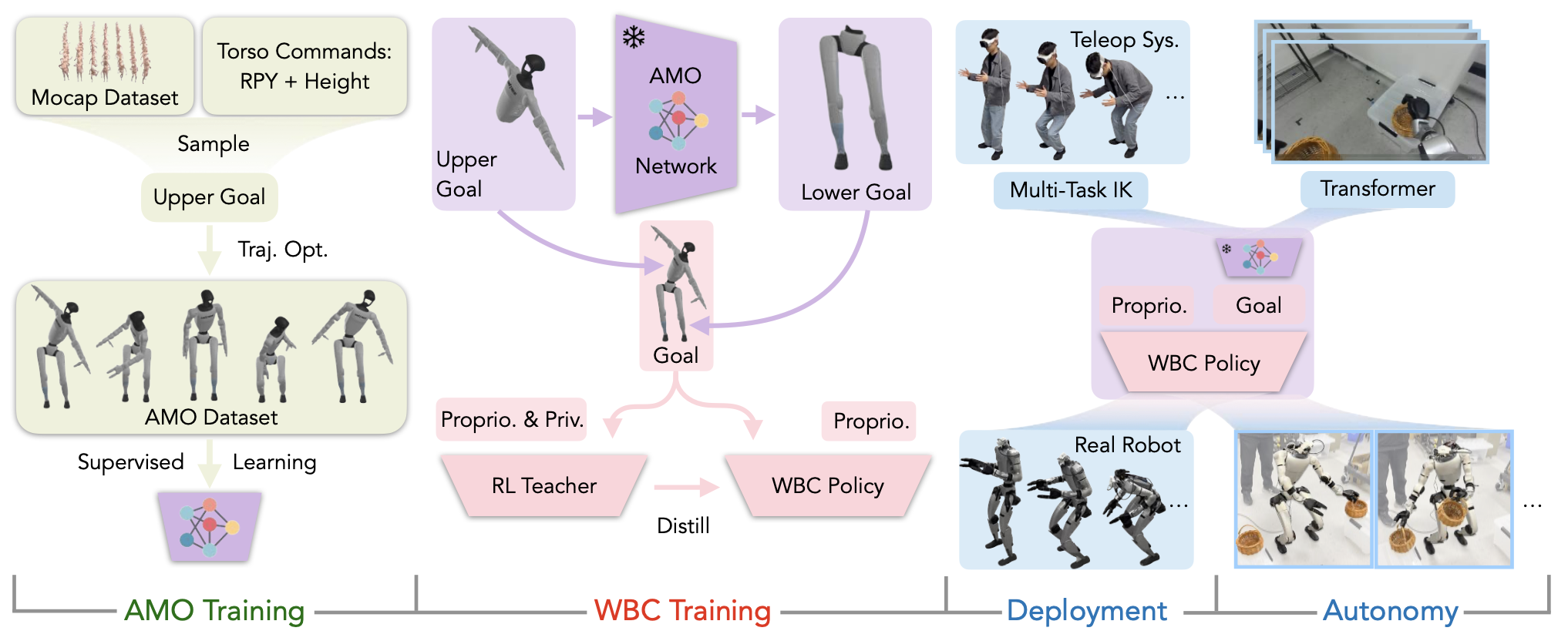
自适应运动优化 (AMO)是一种通过两项协同创新实现人形机器人全身实时控制的分层框架:(i) 混合运动合成:通过将运动捕捉数据中的手臂轨迹与概率采样的躯干方向融合来制定混合上身命令集,系统地消除训练分布中的运动偏差。这些命令驱动动态-觉察轨迹优化器产生满足运动可行性和动力学约束的全身参考运动,从而构建 AMO 数据集——第一个明确为灵巧操作设计的人形运动存储库。(ii) 可泛化的策略训练:虽然一种简单的解决方案是通过离散查找表将命令映射到运动,但此类方法仍然从根本上局限于离散的、分布内的场景。AMO 网络,学习连续映射,从而能够在连续输入空间和分布外 (O.O.D.) 远程操作命令之间进行稳健插值,同时保持实时响应能力。
如图所示:AMO 使人形机器人能够进行超灵巧的全身运动。(a):机器人在不同高度的平台上拾取和放置罐子。(b):机器人从左侧较高的架子上拿起一个瓶子,并将其放在右侧较低的桌子上。(c):机器人伸展腿部将瓶子放在高架子上。(d-g):机器人演示各种躯干俯仰、滚动、偏航和高度调整。(e):机器人利用臀部电机来补偿腰关节的限制,以实现更大的滚动旋转。

在下表中列出一个简短的比较,以展示该方法与最近两项代表性作品的主要优势:

如图所示 AMO 框架,可实现无缝全身控制。其系统分解为四个不同的组件:1. 通过使用轨迹优化收集 AMO 数据集进行 AMO 模块训练;2. 通过在模拟中进行师-生蒸馏进行 RL 策略训练;3. 通过逆运动学(IK) 和重定向进行真实的机器人遥操作;4. 通过使用 Transformer 的模仿学习 (IL) 进行真实的机器人自主策略训练。
问题表述与符号
在此研究类人机器人的全身控制问题,并重点关注两种不同的场景:远程操作和自主操作。
在远程操作场景中,全身控制问题被表述为学习一个目标条件策略 π′: G×S→A,其中G表示目标空间,S表示观测空间,A表示动作空间。在自主操作场景中,学习到的策略 π: S→A 仅基于观测生成动作,无需人工输入。
目标条件远程操作策略从远程操作员接收控制信号g ∈ G,其中 g = [p_head,p_left,p_right,v] p_head, p_left, p_right 表示操作员头部和手部关键点姿态,v = [v_x, v_y, v_yaw] 表示基准速度。观测值 s∈S 包括视觉和本体感受数据:s=[img_left, img_right, s_proprio]。动作 a ∈ A 由上半身和下半身的关节角度命令组成:a = [q_upper, q_lower]。
a) 目标条件遥操作:目标条件策略采用以下策略:分层设计:π′ = [π′_upper ,π′_lower]。上层策略 π_u′pper(p_head,p_left,p_right) = [q_upper, g′] 输出上半身动作和中间控制信号 g′ = [rpy,h],其中 rpy 控制躯干方向,h 控制基座高度。下层策略 π′_lower (v, g′, s_proprio) = q_lower 使用中间控制信号、速度指令和本体感受观测,生成下半身动作。
b) 自主策略:自主策略 π = [π_upper,π_lower] 与遥操作策略采用相同的层级设计。下层策略完全相同:
π_lower = π′_lower,而上层策略独立于人类输入,生成下层和中层控制动作:π_upper(img_left, img_right, s_proprio) = [q_upper, v, g′]。
自适应模块预训练
在系统规范中,底层策略遵循 [v_x,v_y,v_yaw,rpy,h] 形式的命令。遵循速度命令 [v_x,v_y,v_yaw] 的运动能力可以在模拟环境中随机采样有向向量,轻松学习,策略与 [8, 9] 相同。然而,学习躯干和高度跟踪技能并非易事,因为它们需要全身协调。与运动任务不同,可以基于 Raibert 启发式 [62] 设计足部跟踪奖励来促进技能学习,但目前缺乏这样的启发式方法来指导机器人完成全身控制。一些研究 [28, 33] 通过跟踪人类参考来训练此类策略。然而,他们的策略并没有在人体姿势和全身控制指令之间建立联系。
为了解决这个问题,提出一个自适应运动优化 (AMO) 模块。 AMO 模块表示为 φ(q_upper, rpy, h) = qref_lower。在从上肢接收到全身控制命令 rpy,h 后,该模块将这些命令转换为所有下肢执行器的关节角度参考,以便下肢策略进行显式跟踪。为了训练这个自适应模块,首先,通过随机采样上肢命令并执行基于模型的轨迹优化来收集 AMO 数据集,以获取下肢关节角度。轨迹优化可以表述为一个成本函数如下的多-接触最优控制问题 (MCOP):
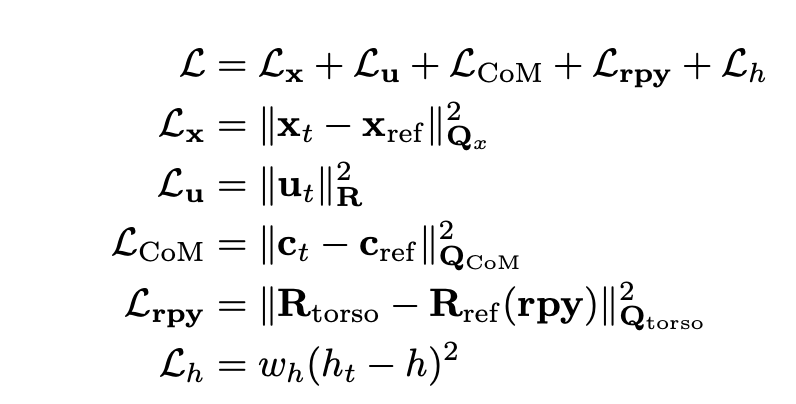
其中包括状态 x 和控制 u 的正则化、目标跟踪项 L_rpy 和 L_h,以及确保全身控制时保持平衡质心 (CoM) 的正则化项。收集数据集后,首先从 AMASS 数据集 [43] 中随机选择上半身运动,并采样随机躯干命令。然后,执行轨迹优化以跟踪躯干目标,同时保持稳定的 CoM 并遵守扳手锥(wrench cone)约束,以生成动态可行的参考关节角度。由于没有考虑步行场景,因此认为机器人的双脚都与地面接触。使用控制-有限可行性-驱动的差分动态规划 (BoxFDDP) 通过 Crocoddyl [48, 49] 生成参考。收集这些数据用于训练 AMO 模块,该模块将躯干命令转换为参考较低的姿势。AMO 模块是一个三层多层感知器 (MLP),在较低策略训练的后期阶段冻结。
底层策略训练
用大规模并行模拟来训练 IsaacGym[44] 的底层策略。底层策略旨在追踪 g′ 和 v,同时利用本体感受观测 s_proprio,包含基准方向 θ_t、基准角速度 ω_t、当前位置、速度和上一个位置目标。值得注意的是,底层策略的观测值包含上肢执行器的状态,以实现更好的上下肢协调。φ_t 是步态循环信号,其定义方式与 [45, 77] 类似。qref_lower 是由 AMO 模块生成的参考下肢下关节角度。底层动作空间 q_lower 是一个维度为 15 的向量,包含双腿的 2∗6 个目标关节位置和腰部电机的 3 个目标关节位置。
选择使用师-生框架来训练底层策略。首先使用现成的 PPO[63] 训练一个可以在模拟中观察到特别信息的教师策略。然后,利用监督学习将教师策略蒸馏为学生策略。学生政策仅观察现实中可用的信息,并且可以部署用于远程操作和自主任务。
教师策略可以是 π_teacher(v, g′, s_proprio, s_priv) = q_lower。附加的特权观察 s_priv 包括以下基本真实值:基准速度 vgt_t、躯干方向 rpygt_t 和基准高度 hgt_t,这些值在现实世界中跟踪其对应目标时不易获取。c_t 是脚与地面之间的接触信号。
教师训练课程:用精心设计的课程来规范强化学习训练中的不同任务。最初,底层策略被视为纯运动策略,目标高度随机化。然后,添加延迟以缩小模拟与现实之间的差距。之后,随机化目标躯干的滚动、俯仰和偏航,并激活相关奖励。最后,从 AMASS 数据集中采样手臂动作,并直接在环境中设置手臂关节的目标位置。按照训练计划,教师策略逐渐掌握复杂的全身控制设置,并能够监督现实世界中的学生操作。
学生策略可以写成π_student(v, g′, s_proprio, s_hist) = q_lower。为了用现实世界中可获得的观察结果来补偿s_proprio,学生策略利用25-步本体感受观察历史作为额外的输入信号:s_hist,t = s_proprio,t−1∼t−25。
远程操作上层策略实现
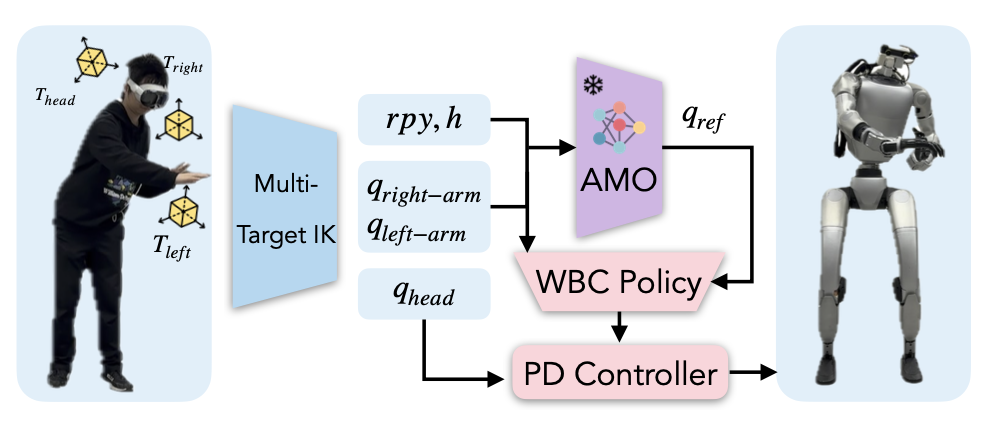
远程操作上层策略生成一系列全身控制命令,包括手臂和手部运动、躯干方向和基座高度。选择使用基于优化的技术来实现该策略,以达到操作任务所需的精度。具体而言,手部运动通过重定向生成,而其他控制信号则使用逆运动学 (IK) 计算。手部重定向实现基于 dex-retargeting [60]。
在全身控制框架中,将传统的 IK 扩展为多目标加权 IK,最小化与三个关键目标(头部、左腕和右腕)的 6D 距离。机器人调动所有上身执行器同时匹配这三个目标。正式而言,其目标是:

如图所示。优化变量 q 包括机器人上半身的所有驱动自由度 (DoF):q_head、q_left-arm 和 q_right-arm。除了电机命令之外,它还求解中间命令以实现全身协调:rpy 和 h 用于躯干方向和高度控制。为确保平稳的上半身控制,姿势成本在优化变量 q 的不同组成部分上权重不同:W_q_head、q_left-arm、q_right-arm < W_rpy,h。这鼓励策略优先考虑上半身执行器以执行较简单的任务。但是,对于需要全身运动的任务,例如弯腰拾取或够到远处的目标,会生成额外的控制信号 [rpy,h] 并发送到底层策略。底层策略协调其电机角度以满足上层策略的要求,从而实现全身目标的达成。IK 的实现采用 Levenberg-Marquardt (LM) 算法[68],并且基于 Pink [6]。
自主上层策略训练
通过模仿学习来学习自主上层策略。首先,人类操作员使用目标条件策略与机器人进行远程操作,记录观察结果和动作作为演示。然后,用 ACT [78] 和 DinoV2 [17, 53] 视觉编码器作为策略主干。视觉观察包括两幅立体图像 imgleft 和 imgright。DinoV2 将每幅图像分成 16 × 22 的块,并为每个块生成一个 384 维的视觉 token,从而产生一个形状为 2×16×22×384 的组合视觉token。该视觉 token 与通过投影 o_t = [supper_proprio,t, v_t−1, rpy_t−1, h_t−1] 获得的状态 token 连接在一起。这里,supper_proprio,t 是上肢本体感受的观测值,[v_t−1, rpy_t−1, h_t−1] 是发送给下层策略的最后一个命令。由于采用解耦系统设计,上层策略会观察这些下层策略的命令,而不是直接观察下肢本体感受。该策略的输出表示为:
[qhead_t, qdual−arm_t, qdual−hand_t, v_t, rpy_t, h_t ]
其包含所有上肢关节角度以及下层策略的中间控制信号。
在 IsaacGym 模拟器 [44] 中进行模拟实验。真实机器人配置如上图所示,它由 Unitree G1 [1] 改装而成,配备了两只 Dex3-1 灵巧手。该平台拥有 29 个全身自由度,每只手有 7 个自由度。定制一个带有三个驱动自由度的主动头部,用于映射人类操作员的头部运动,并安装一台 ZED Mini [2] 摄像头用于立体视觉。
部分实验使用外部 PC 进行,以便使用 RTX 4090 GPU 进行调试。尽管如此,整个遥操作系统和强化学习策略可以部署在具有 50Hz 推理频率的 Jetson Orin NX 上,如图所示。用 OpenTelevision[11] 在 VR 设备和机器人之间传输图像和人体姿势。
