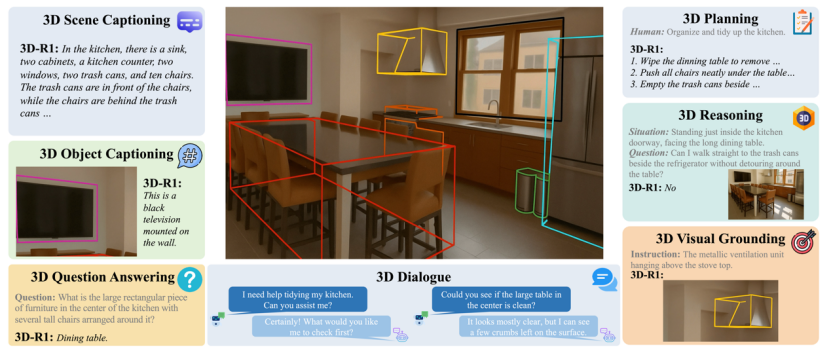
首个!3D空间推理框架3D-R1:融合强化学习、推理链、动态视角,实现7大任务SOTA!
摘要
在AI已经能“看图说话”“对话交流”的今天,一个关键问题逐渐浮出水面:
当AI进入真实世界的三维场景,它真的“理解”了吗? 从服务机器人、自动驾驶,到元宇宙交互、工业检测,3D场景理解已成为通向通用人工智能的关键突破口。 本期介绍的3D-R1模型,或许正是破题之作!
论文题目:3D-R1: Enhancing Reasoning in 3D VLMs for Unified Scene Understanding
论文作者:Ting Huang, Zeyu Zhang, Hao Tang
论文链接:https://arxiv.org/abs/2507.23478
项目主页:https://aigeeksgroup.github.io/3D-R1/
代码链接:https://github.com/AIGeeksGroup/3D-R1

受OpenAI-o1、Gemini-2.5-Pro和DeepSeek-R1等多模态推理模型的启发,本文提出了首个面向三维场景理解的空间推理框架——3D-R1。该框架首次将Chain-of-Thought推理范式、强化学习优化机制与多视角感知策略统一于一个3D视觉语言模型中。
在构建规模达3万条的高质量推理数据集Scene-30K后,3D-R1进一步引入基于GRPO的多重奖励强化学习算法,仅通过小规模调优,即可实现对复杂3D任务的精确理解与逻辑推理,性能可媲美SOTA多模态模型如OpenAI-o1与Gemini-2.5。
本文还系统探讨了推理数据生成、奖励函数设计、动态视角学习与RL-SFT模型的泛化差异,为构建通用三维空间智能体提供了新的思路与实践路径。

具身智能场景下,AI需要在真实、连续、多变的3D视觉输入中进行精准推理与决策,但这面临三大挑战:
挑战一:感知与推理高度耦合
推理的前提是准确的感知。具身任务中,视觉输入连续但不完美(遮挡、模糊、错检),一旦感知偏差,推理容易“跑偏”。
挑战二:空间结构复杂
真实3D环境中包含复杂的物体布局与时序变化。模型需整合多帧信息,识别关键目标并进行跨帧关联。
挑战三:视角有限且冗余
具身观察来自第一人称视角,帧间存在大量冗余信息,如何选择最关键视角,是模型面临的另一挑战。

为解决上述挑战,研究团队提出了3D-R1。它不仅聚焦于对3D场景的精准感知,还专门设计了增强“推理能力”的训练机制,使模型能像人一样“思考”和“判断”。
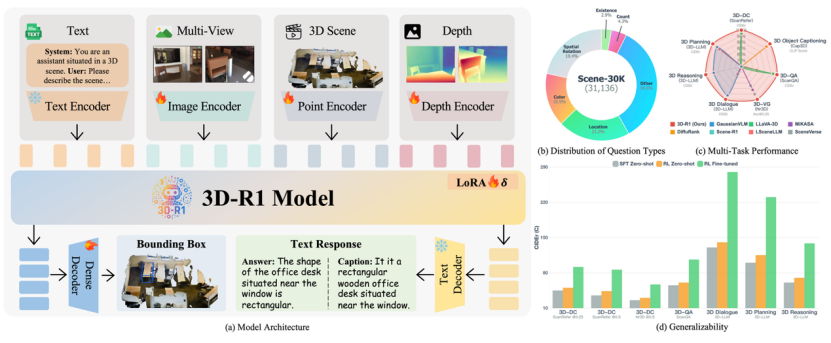
我们从三个关键方面对现有方法进行了创新:
(1). 构建高质量推理数据集:Scene-30K
大多数3D数据集中,只包含简单的描述或问答,而缺乏真正多步逻辑的训练样本。为此,我们基于多个3D数据集(如ScanQA、SceneVerse等)合成了一个具有逻辑链条的高质量数据集——Scene-30K。
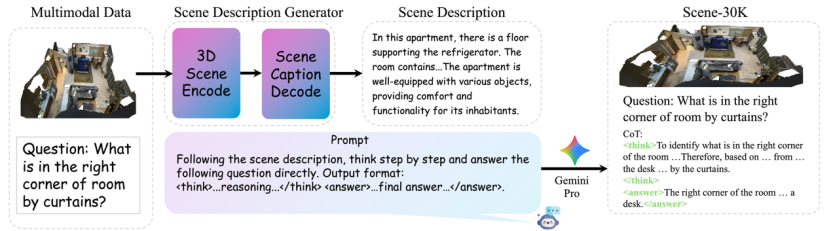
这个数据集的构造流程如下:
1.场景描述生成:利用预训练3D模型对点云生成简洁的场景描述;
2.推理链生成:将场景描述输入 Gemini2.5 Pro等大语言模型生成结构化的推理过程(Chain-of-Thought);
3.规则过滤:对输出进行格式、逻辑一致性、答案正确性等过滤,确保质量。 最终,我们获得了3万条结构规范、逻辑清晰的训练样本,为模型提供“冷启动”训练支持。
(2). 结合强化学习:让模型学会“思考”
在冷启动训练之后,我们引入了基于GRPO(Group Relative Policy Optimization)的强化学习机制,让模型在生成回答的过程中不断自我优化。
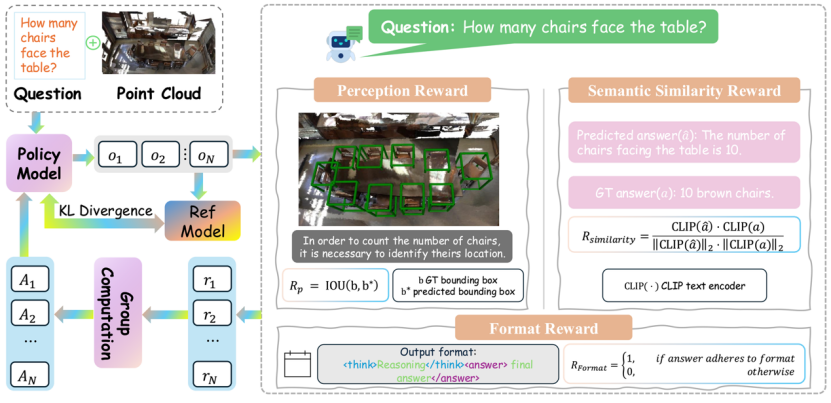
我们设计了三种奖励信号:
格式奖励:确保输出结构规范,例如必须包含推理和答案格式;
感知奖励:通过预测框与真实框的 IoU 计算定位准确性;
语义奖励:使用CLIP编码器计算预测答案与真实答案的语义相似度。
这种方式使得模型不仅回答正确,而且过程清晰、结构合规、语义贴合,具备更强的泛化推理能力。
(3). 动态视角选择:看到更关键的信息
在三维场景中,不同视角包含的信息差异巨大。如果模型只能从固定角度看世界,往往会错过关键细节。为此,我们提出了一种动态视角选择策略,帮助模型自动选择6张最具代表性的视图。
这一策略结合三种评分指标:
文本相关性(Text-to-3D):视角是否与问题文本高度相关;
空间覆盖度(Image-to-3D):该视角是否补充其他视角遗漏的信息;
多模态对齐(CLIP相似度):该视角与语言描述是否匹配。
最终,我们通过可学习的权重融合机制自动优化这些指标组合,选择对任务最关键的观察视角。

3D-R1在7个3D任务上进行了全面评估,包括:3D问答(3D-QA)、密集描述(3D Dense Captioning)、物体描述(3D Object Captioning)、多轮对话(3D Dialogue)、场景推理(3D Reasoning)、动作规划(3D Planning)、视觉定位(3D Visual Grounding)。
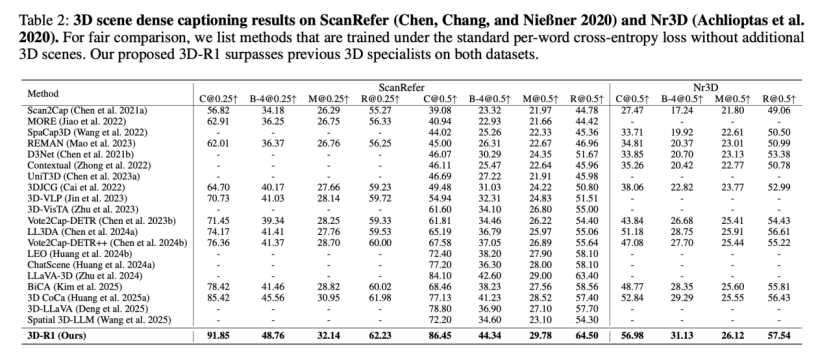
在3D场景密集描述任务中,3D-R1在ScanRefer和Nr3D两个数据集上均超越了之前的专业模型。
在最具挑战性的3D问答任务上,3D-R1在ScanQA基准的验证集和两个测试集上都取得了最优成绩。
在更复杂的3D对话、规划和空间推理任务上,3D-R1同样展现了其强大的综合能力。
这些结果证明了:无论是感知还是推理,3D-R1都展现了更强的泛化能力和任务表现。

3D-R1不仅在学术指标上领先,更具备实际应用价值。未来,它可以应用于:
家用机器人中:理解屋内物体位置并作出决策;
元宇宙/VR:根据场景进行对话式引导和互动;
自动驾驶:理解复杂街景并实时应答;
工业检查:根据场景自动识别潜在风险区域。

3D-R1不仅是一项模型技术创新,更是我们走向更强三维智能体的关键一步。未来,我们计划将其拓展至机器人控制、交互式问答、甚至自动家居整理等现实应用场景中。