动手学深度学习13.11. 全卷积网络 -笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:全连接卷积神经网络 FCN【动手学深度学习v2】_哔哩哔哩_bilibili
本节教材地址:13.11. 全卷积网络 — 动手学深度学习 2.0.0 documentation
本节开源代码:…>d2l-zh>pytorch>chapter_optimization>fcn.ipynb
全卷积网络
如 13.9节 中所介绍的那样,语义分割是对图像中的每个像素分类。全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 (Long et al., 2015)。与我们之前在图像分类或目标检测部分介绍的卷积神经网络不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过在 13.10节 中引入的转置卷积(transposed convolution)实现的。因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
构造模型
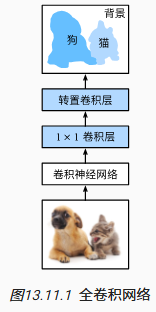
下面我们了解一下全卷积网络模型最基本的设计。如 图13.11.1 所示,全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1 × 1 1\times 1 1×1卷积层将通道数变换为类别个数,最后在 13.10节 中通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空间位置像素的类别预测。
下面,我们[使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征],并将该网络记为pretrained_net。ResNet-18模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]
/usr/local/lib/python3.11/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.warnings.warn(
/usr/local/lib/python3.11/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
100%|██████████| 44.7M/44.7M [00:00<00:00, 184MB/s][Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))),AdaptiveAvgPool2d(output_size=(1, 1)),Linear(in_features=512, out_features=1000, bias=True)]
接下来,我们[创建一个全卷积网络net]。它复制了ResNet-18中大部分的预训练层,除了最后的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
给定高度为320和宽度为480的输入,net的前向传播将输入的高和宽减小至原来的 1 / 32 1/32 1/32,即10和15。
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
torch.Size([1, 512, 10, 15])
接下来[使用 1 × 1 1\times1 1×1卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。]最后需要(将特征图的高度和宽度增加32倍),从而将其变回输入图像的高和宽。回想一下 6.3节 中卷积层输出形状的计算方法:由于 ( 320 − 64 + 16 × 2 + 32 ) / 32 = 10 (320-64+16\times2+32)/32=10 (320−64+16×2+32)/32=10且 ( 480 − 64 + 16 × 2 + 32 ) / 32 = 15 (480-64+16\times2+32)/32=15 (480−64+16×2+32)/32=15,我们构造一个步幅为 32 32 32的转置卷积层,并将卷积核的高和宽设为 64 64 64,填充为 16 16 16。我们可以看到如果步幅为 s s s,填充为 s / 2 s/2 s/2(假设 s / 2 s/2 s/2是整数)且卷积核的高和宽为 2 s 2s 2s,转置卷积核会将输入的高和宽分别放大 s s s倍。
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,kernel_size=64, padding=16, stride=32))
[初始化转置卷积层]
在图像处理中,我们有时需要将图像放大,即上采样(upsampling)。双线性插值(bilinear interpolation)是常用的上采样方法之一,它也经常用于初始化转置卷积层。
为了解释双线性插值,假设给定输入图像,我们想要计算上采样输出图像上的每个像素。
- 将输出图像的坐标 ( x , y ) (x,y) (x,y)映射到输入图像的坐标 ( x ′ , y ′ ) (x',y') (x′,y′)上。
例如,根据输入与输出的尺寸之比来映射。
请注意,映射后的 x ′ x′ x′和 y ′ y′ y′是实数。 - 在输入图像上找到离坐标 ( x ′ , y ′ ) (x',y') (x′,y′)最近的4个像素。
- 输出图像在坐标 ( x , y ) (x,y) (x,y)上的像素依据输入图像上这4个像素及其与 ( x ′ , y ′ ) (x',y') (x′,y′)的相对距离来计算。
双线性插值的上采样可以通过转置卷积层实现,内核由以下bilinear_kernel函数构造。限于篇幅,我们只给出bilinear_kernel函数的实现,不讨论算法的原理。
def bilinear_kernel(in_channels, out_channels, kernel_size):factor = (kernel_size + 1) // 2# 奇数核,中心在整数坐标if kernel_size % 2 == 1:center = factor - 1# 偶数核,中心在两个整数中间else:center = factor - 0.5# 生成两个张量,用于表示核中每个位置的坐标:# og[0]:形状为 (kernel_size, 1) 的列向量,代表行坐标(y 轴);# og[1]:形状为 (1, kernel_size) 的行向量,代表列坐标(x 轴)og = (torch.arange(kernel_size).reshape(-1, 1),torch.arange(kernel_size).reshape(1, -1