外部排序总结(考研向)
外部排序
- 外部排序
- 原理(归并排序)
- 时间开销分析(如何优化)
- 优化1:多路归并
- 优化2:减少初始归并段的个数
- 在这里插入图片描述
- 败者树
- 作用
- 实现思路
- 置换-选择排序(归并段 pro)
- 基本思想
- 最佳归并树(哈夫曼树&WPL相关)
- 二路最佳归并树
- 多路最佳归并树
- 遇到的问题(节点数不满足要求)
- 结语
外部排序
-
外部排序的由来
-
在计算机处理数据的过程中,排序是一项常见操作。传统的内部排序是在内存中进行的,即整个排序过程不需要访问外存便能完成。
-
然而,在许多实际应用中,经常需要对大文件进行排序,这些文件中的记录数量众多、信息量庞大,无法将整个文件复制进内存中进行排序。
-
因此,需要将待排序的记录存储在外存中,排序时再把数据一部分一部分地调入内存进行排序,在排序过程中需要多次进行内存和外存之间的交换,这种排序方法就被称为外部排序。
-
经过操作系统的学习 我们知道在内存与外存(磁盘)之间的数据交换是以磁盘块为单位的
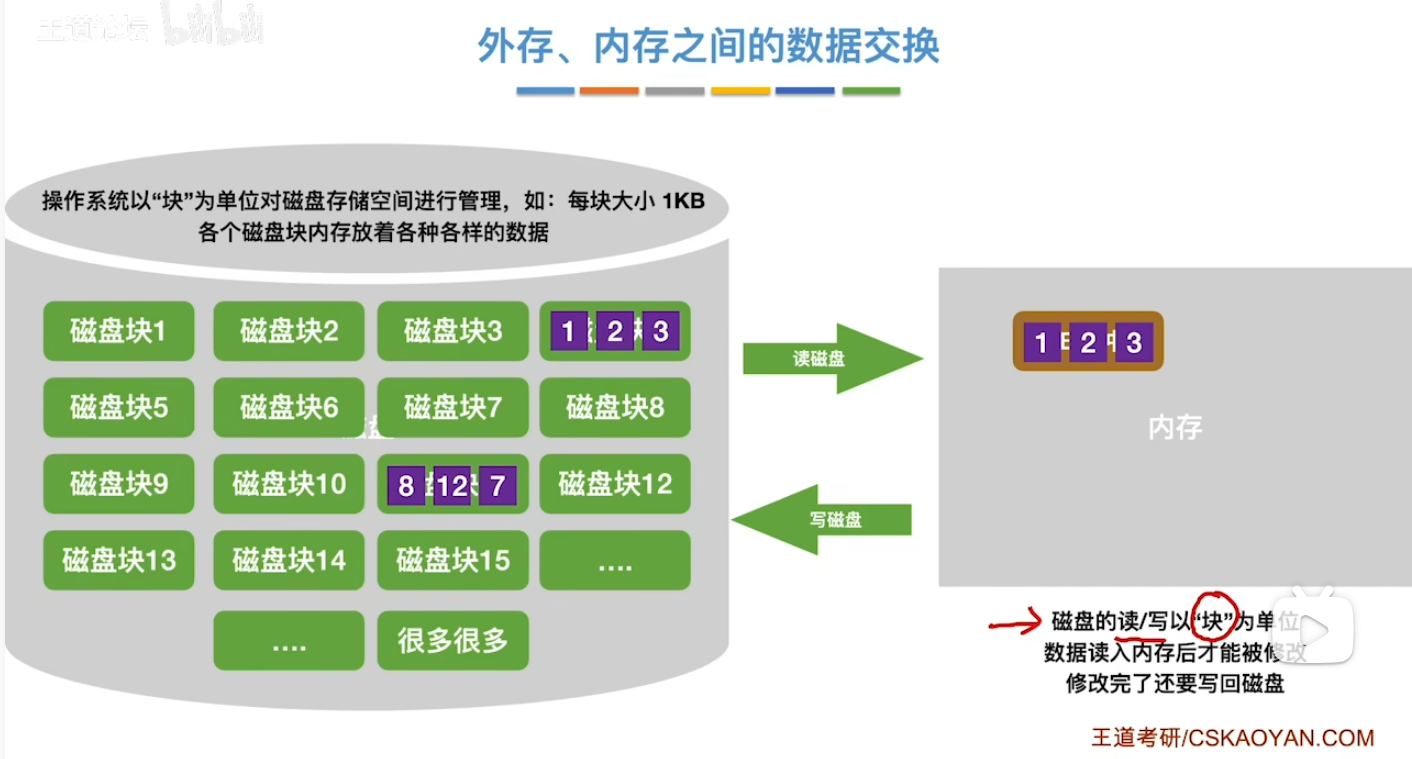
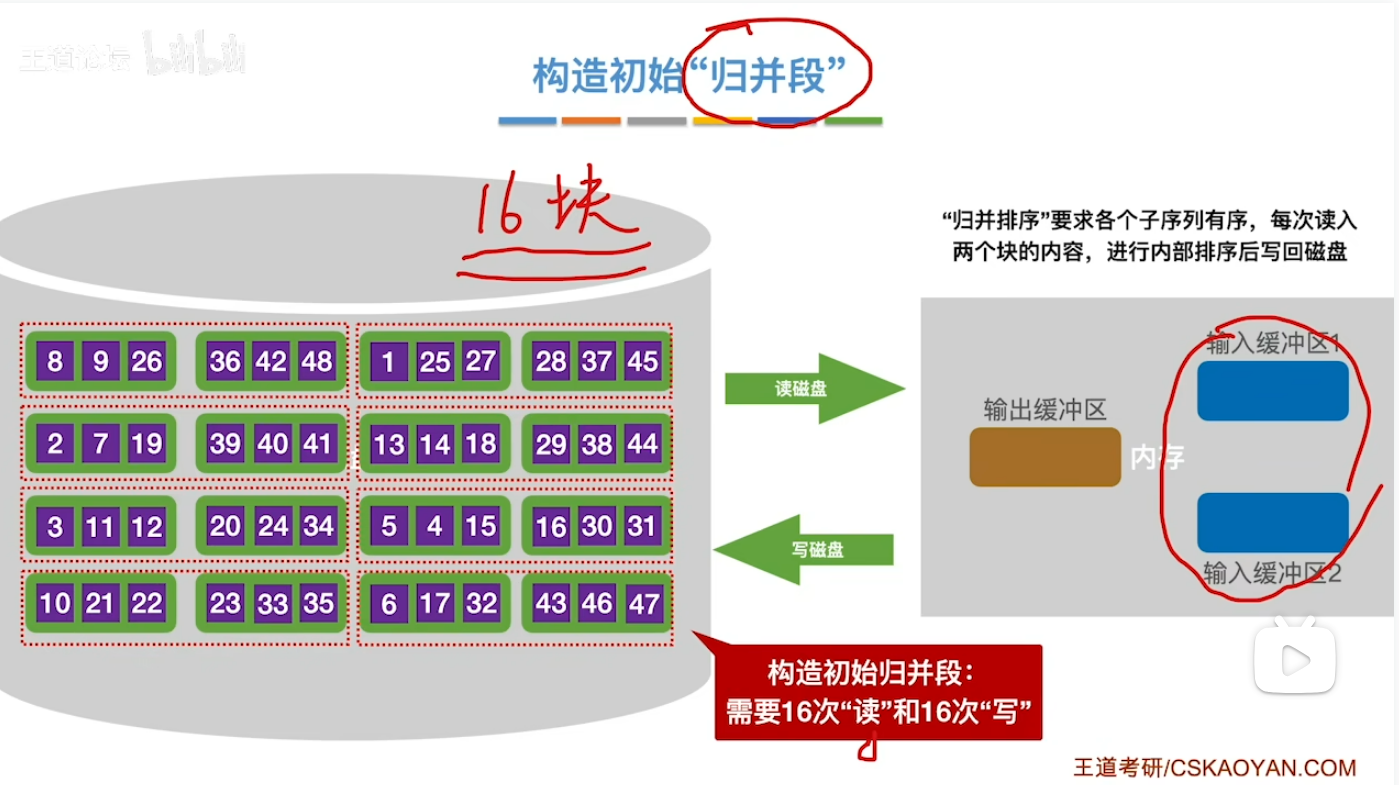
原理(归并排序)
- 1.如果你对于归并操作不清楚建议先去看看这个视频 对应链接
-
- 对于所有归并操作需要注意的是 一旦一个输入缓冲区为空时 一定是先将它填满再继续去归并排序而不是等到两个输入缓冲区都空了再去填充
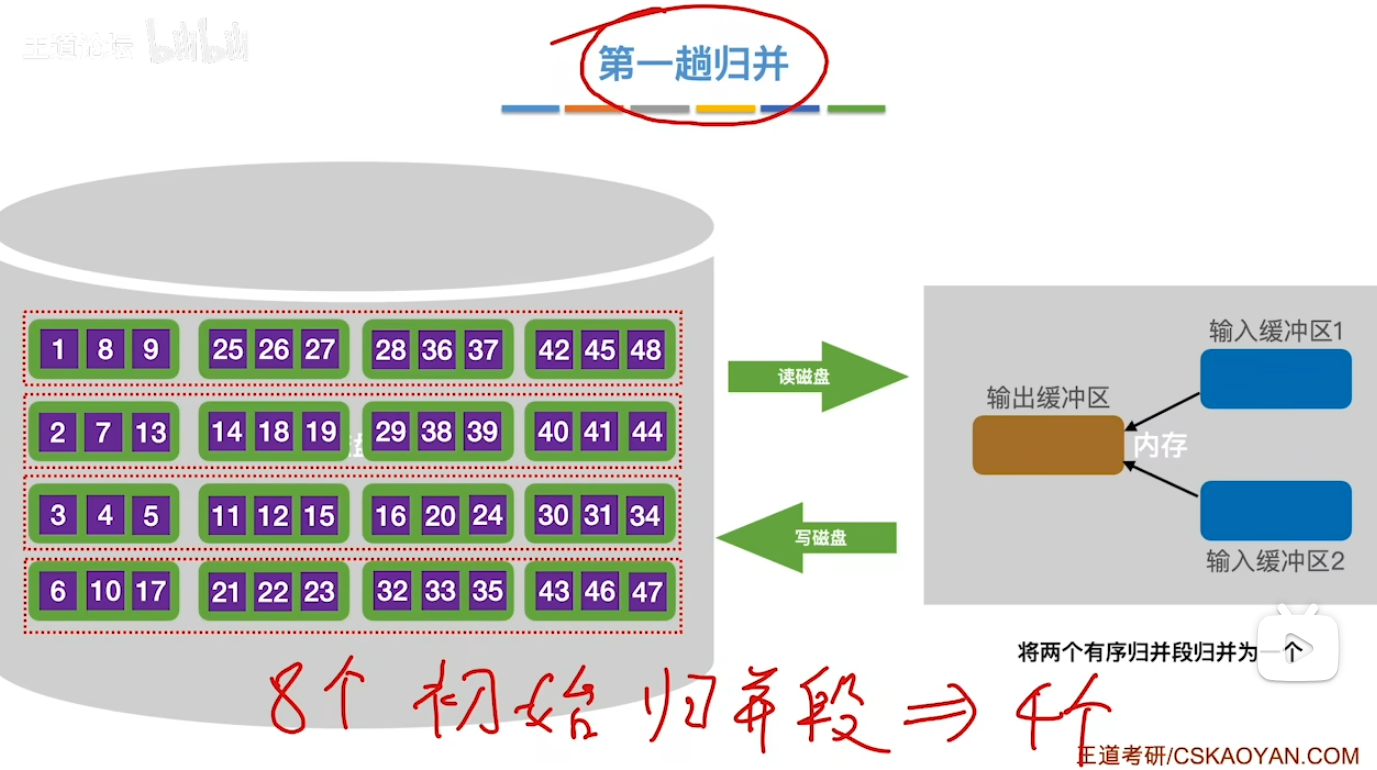 - 3.
- 3.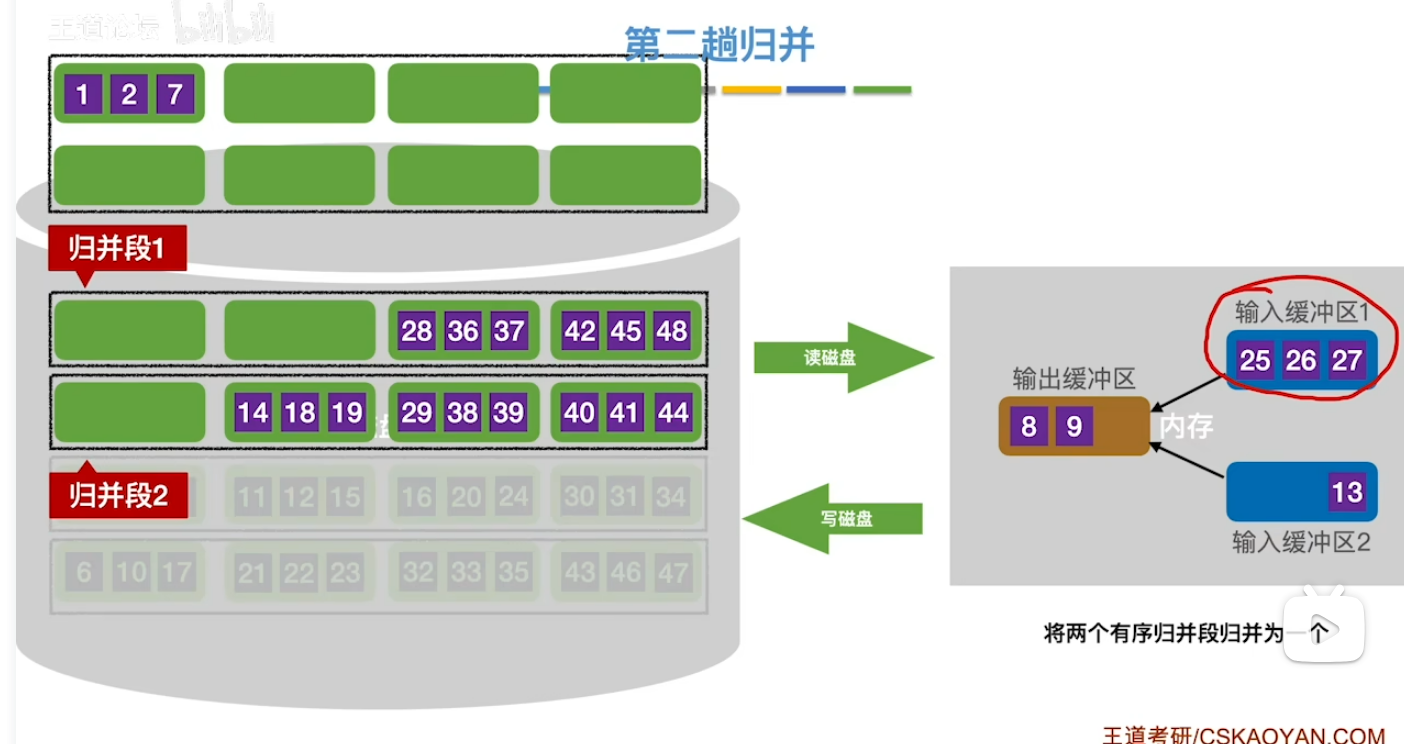
- 对于所有归并操作需要注意的是 一旦一个输入缓冲区为空时 一定是先将它填满再继续去归并排序而不是等到两个输入缓冲区都空了再去填充
-
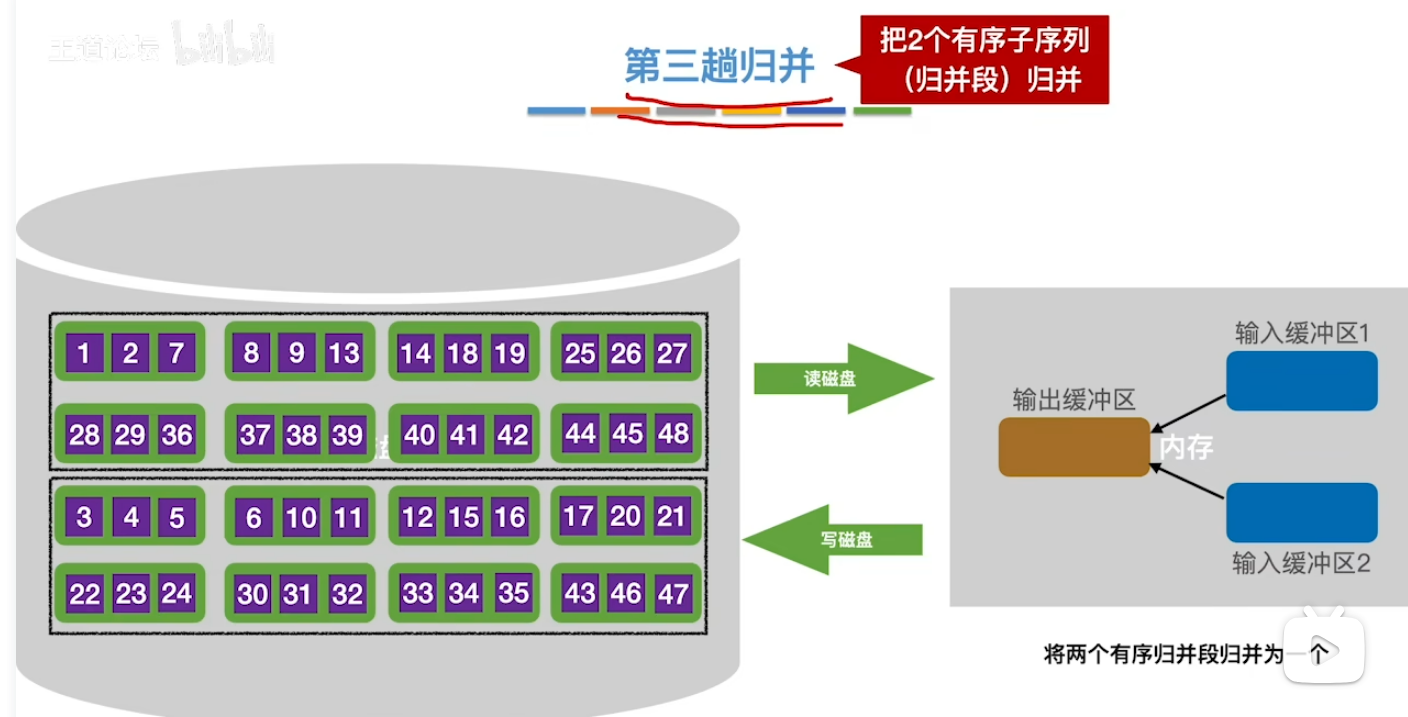
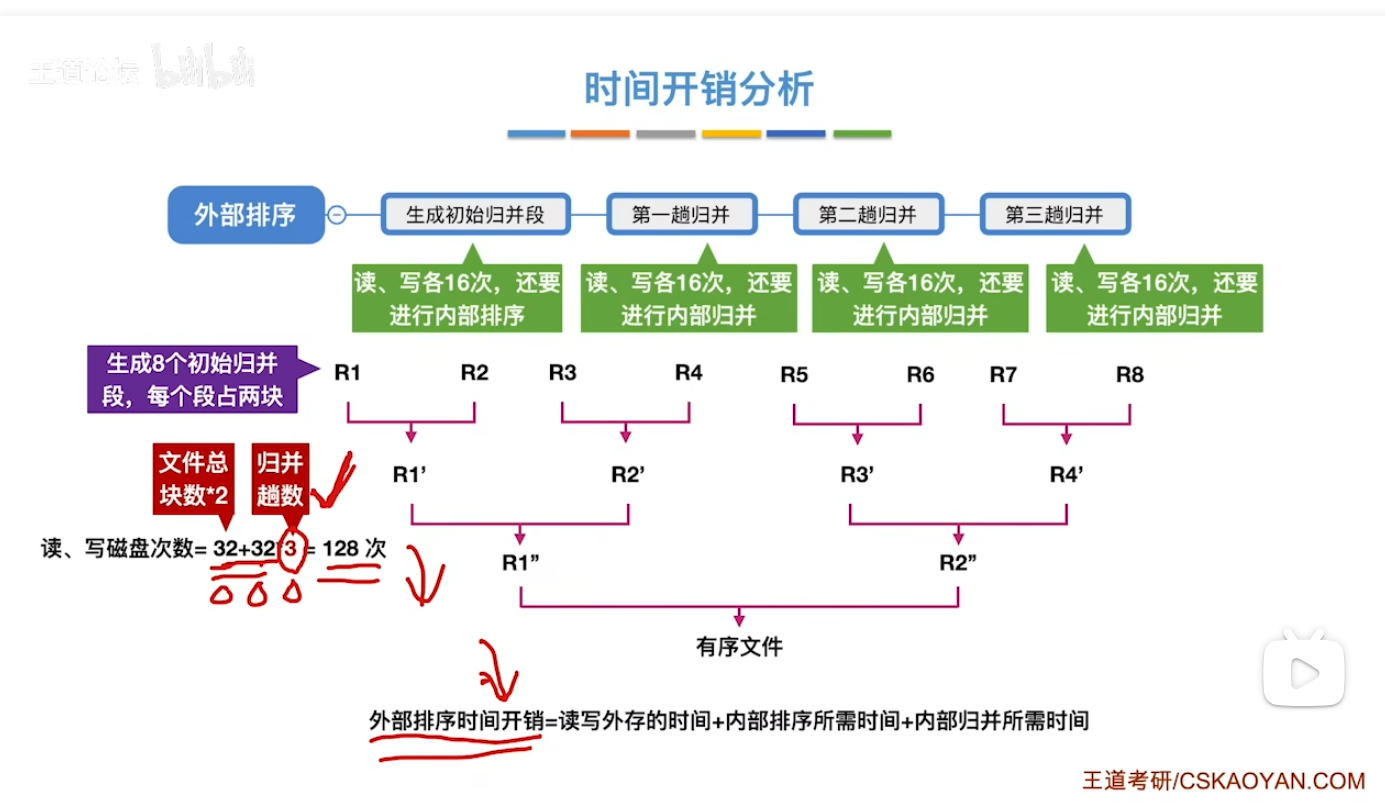
时间开销分析(如何优化)
- 对于外部排序的时间开销 我们主要利用抓大头的思想 因为内部归并和排序是在内存里交给CPU完成的 速度跟外存的I/O(读写)操作相比快太多太多 因此我们着重考虑读写外存的时间如何去优化
- 由于文件的总块数我们改变不了 我们只能通过减少归并趟数来优化
- 这就引出了我们的两种优化方式—— 多路归并 & 减少初始归并段的个数
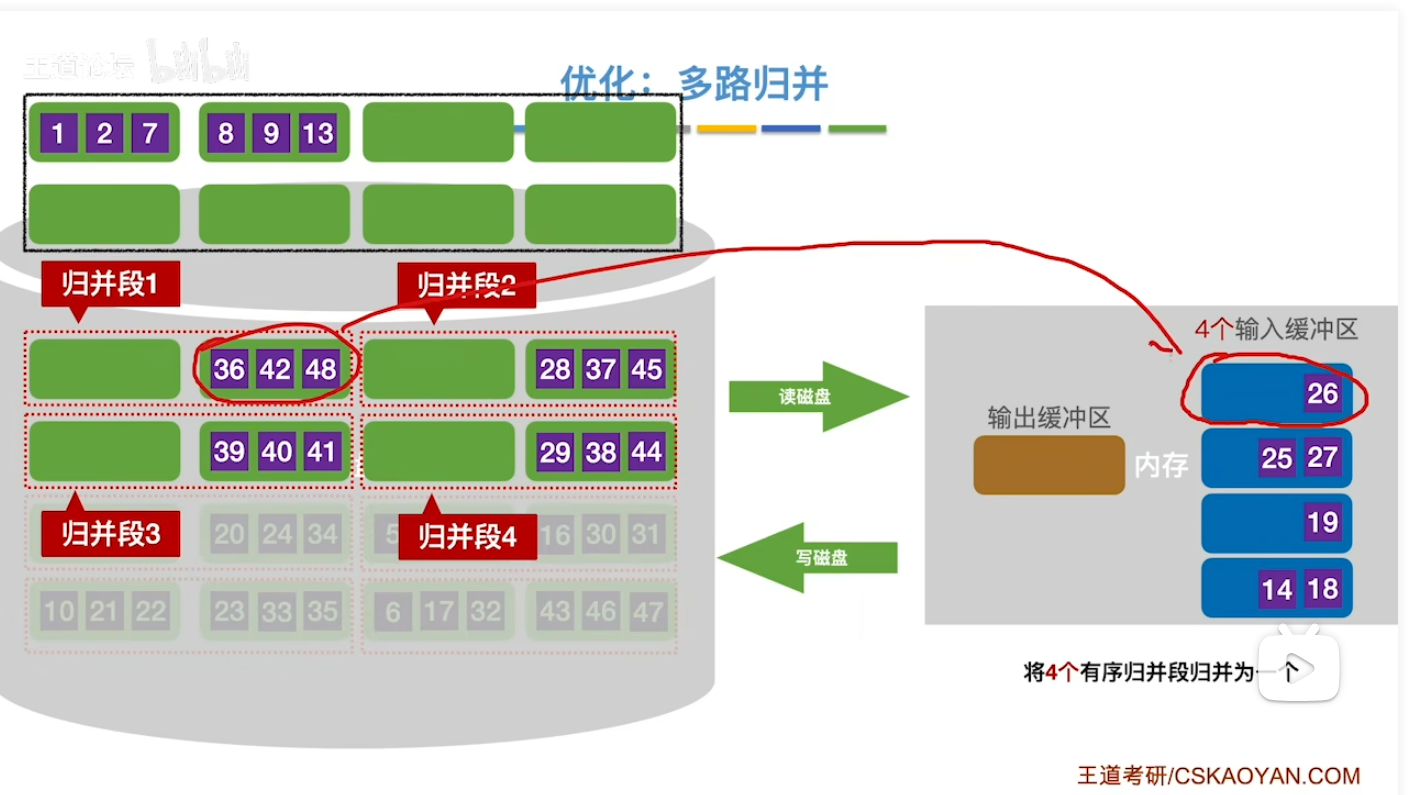
优化1:多路归并
其实说白了就是在内存里开四个输入缓冲区 还是按照归并操作的原则 对我们一开始建立好的归并段进行归并
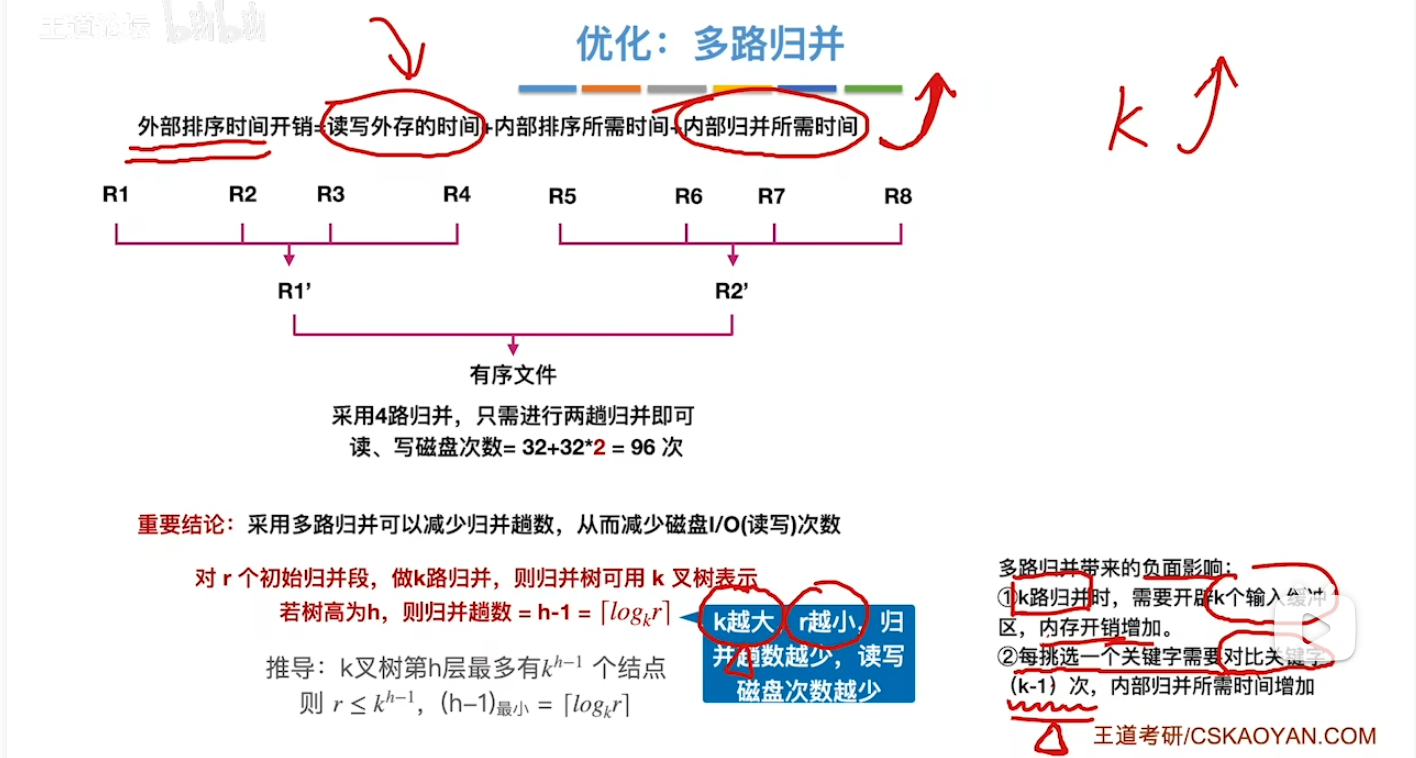
- 对应的一些性质
优化2:减少初始归并段的个数
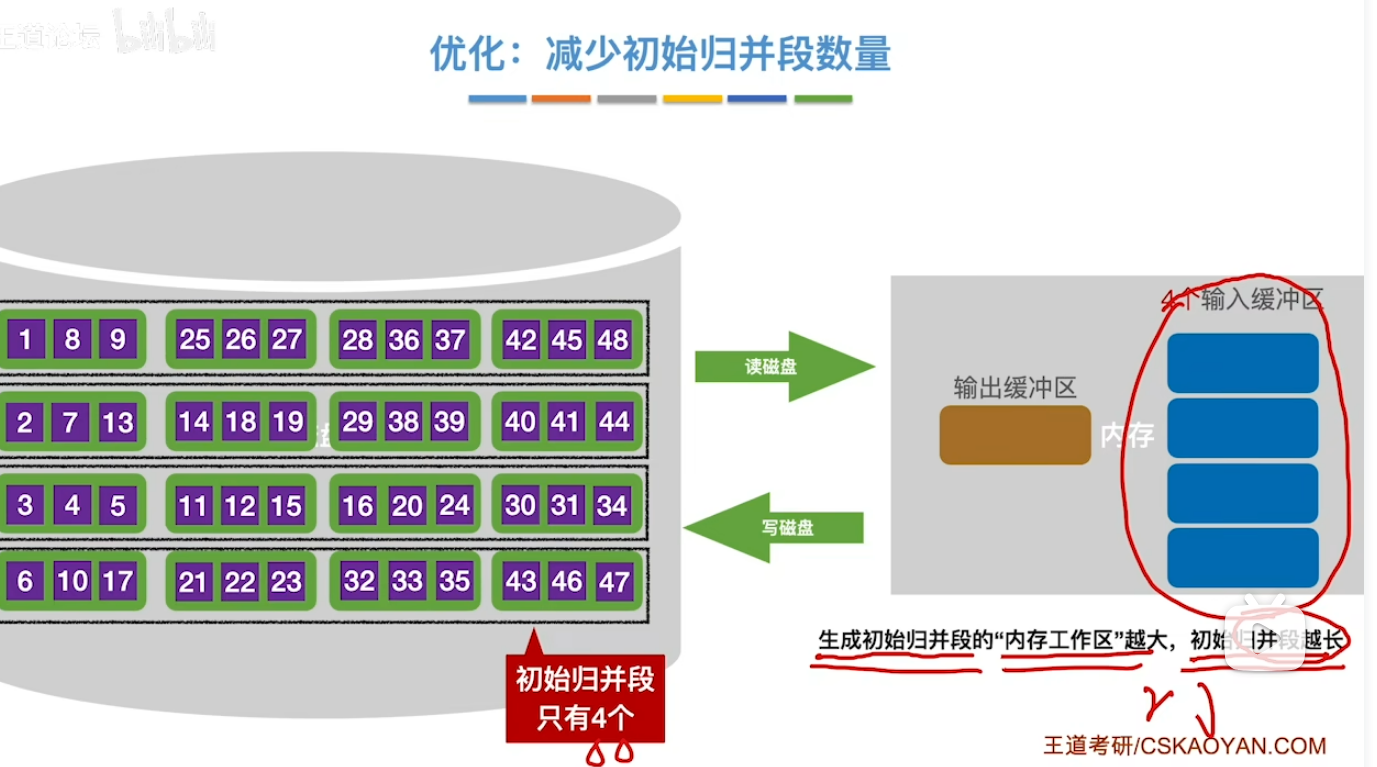
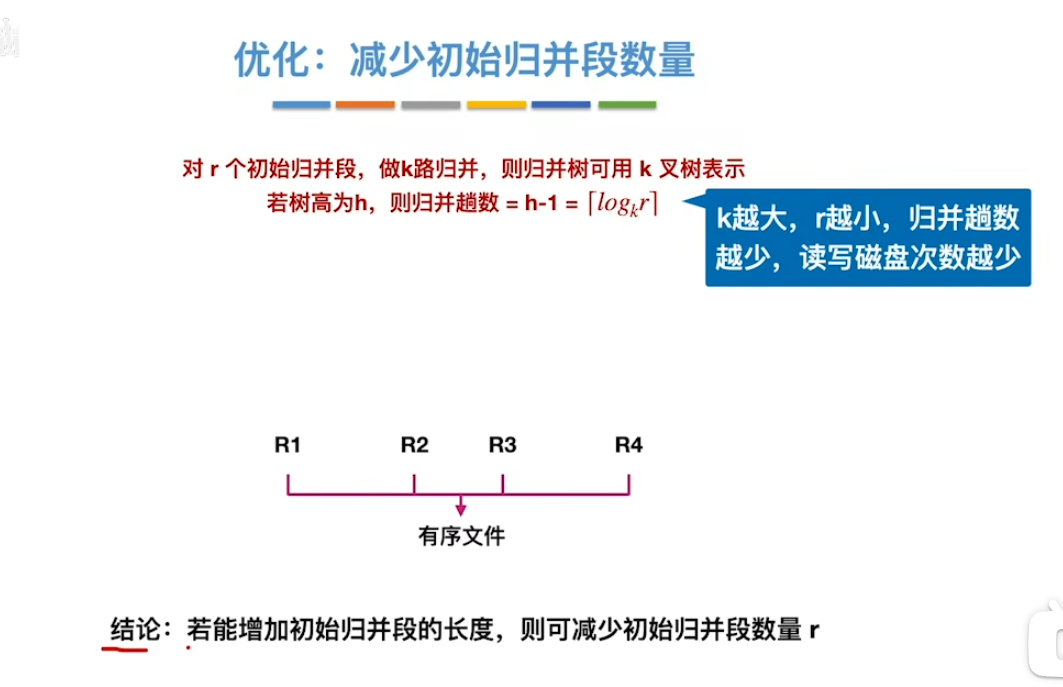
败者树
- 引入
-
- 咸鱼老师这例子太牛逼了
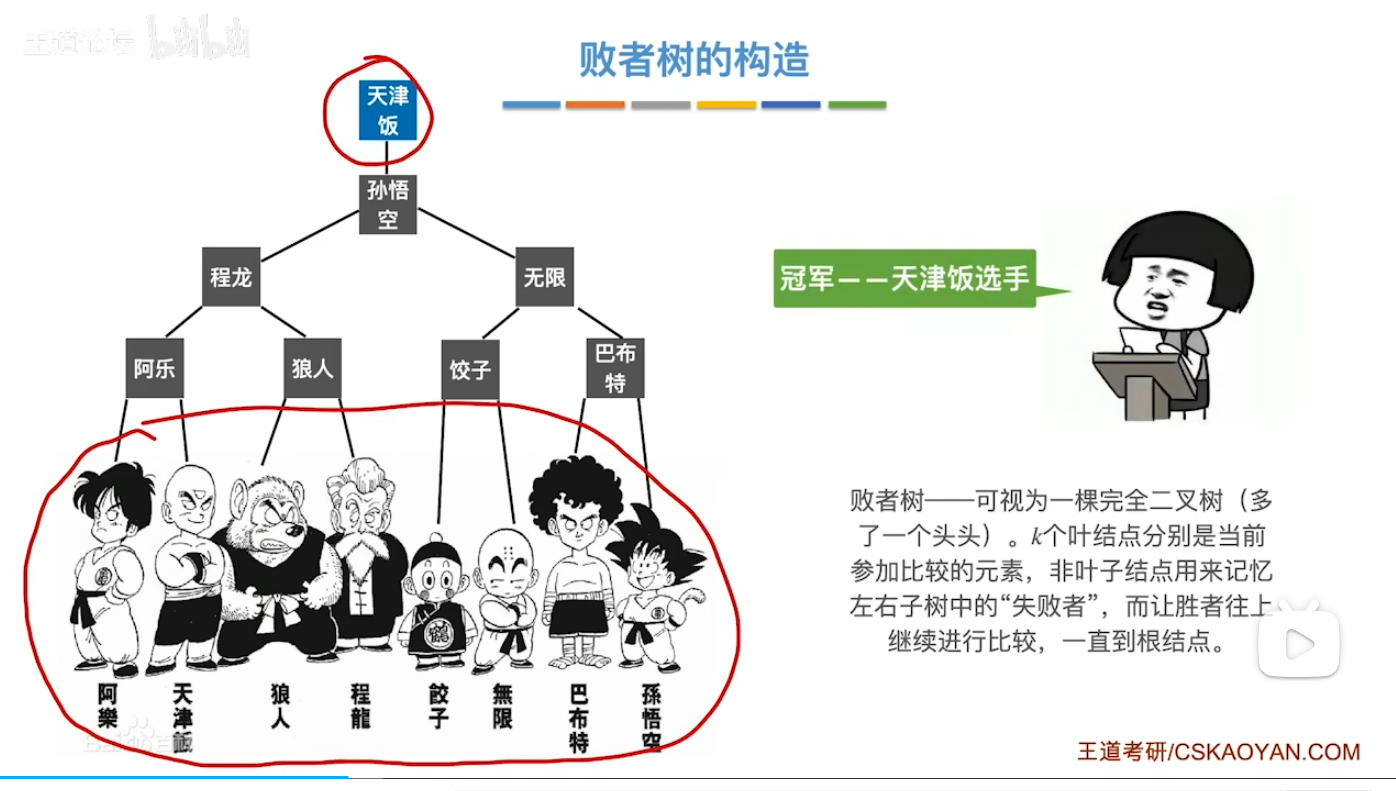
- 咸鱼老师这例子太牛逼了
-
- 冠军走了(最值被摘出去了)来了个派大星(归并段里面的数)看看什么实力
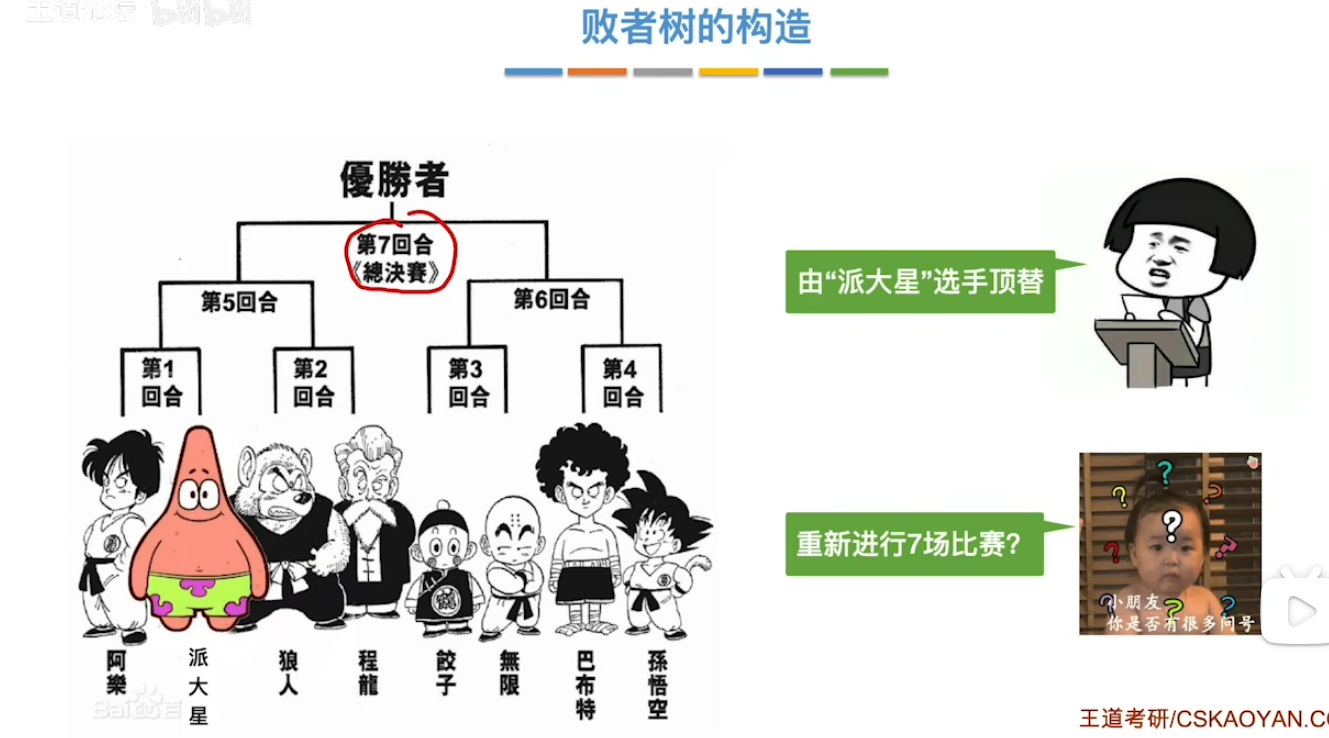
- 派大星只需要经过冠军的试炼就可以了 并不需要是个人就跟他打 说白了就是打一轮冠军打过的人来确定派大星的实力
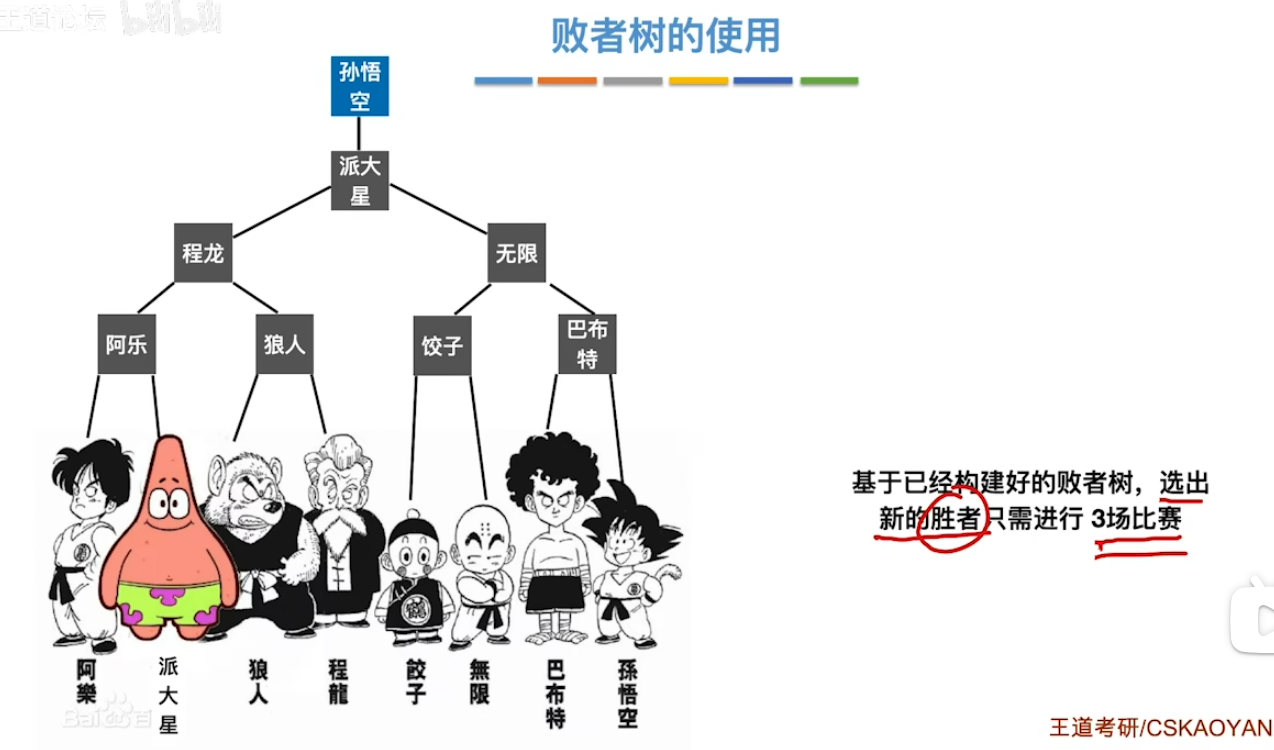
- 具体的样子(个人感觉有点像B+树 神似形也似)
- 比如 这时候我们要按从小到大排序 每次都要找最小元素 比较完了之后找到了最小元素是1 来自归并段3 这时候就在冠军位置上记录上3 然后元素1深藏功与名 直接让位
- 这个时候就让它的弟子(6)去继续挑战(比较)以此往复
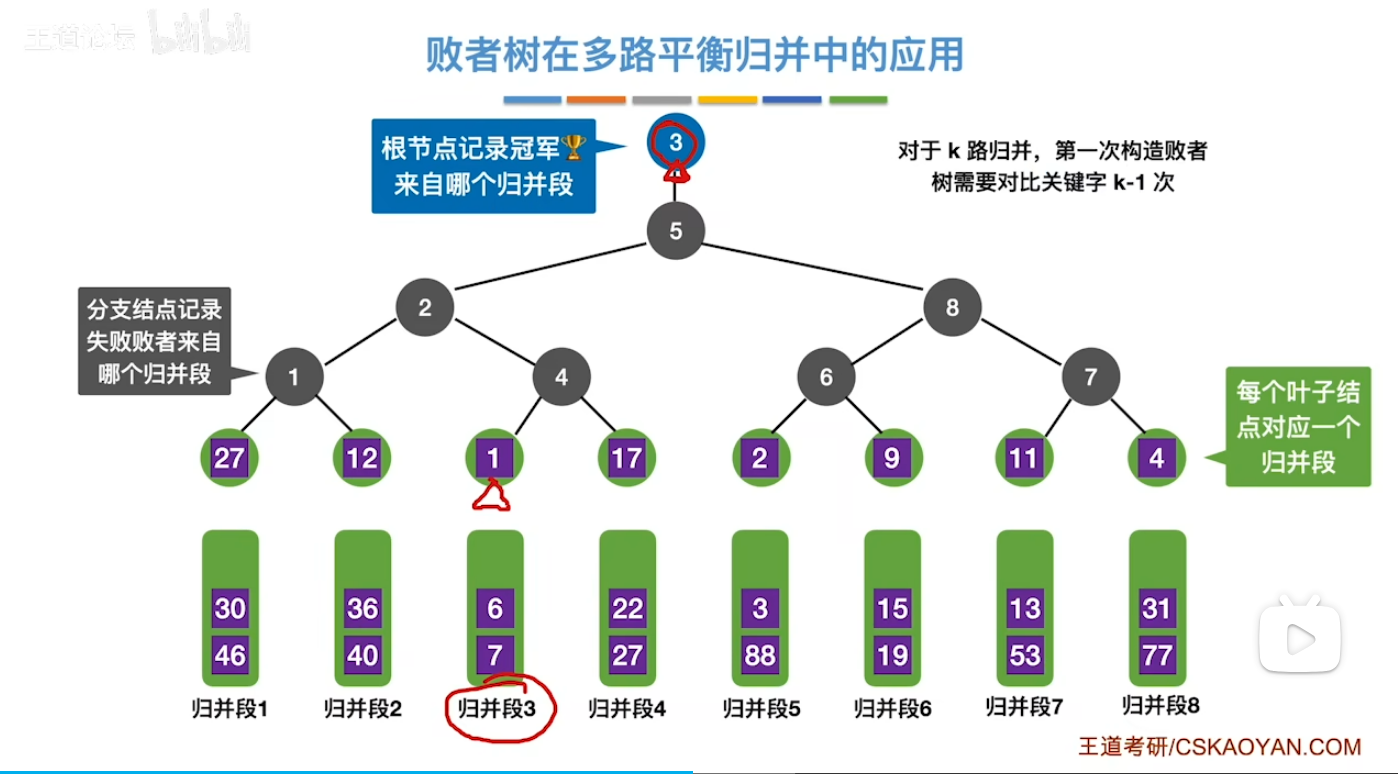
作用
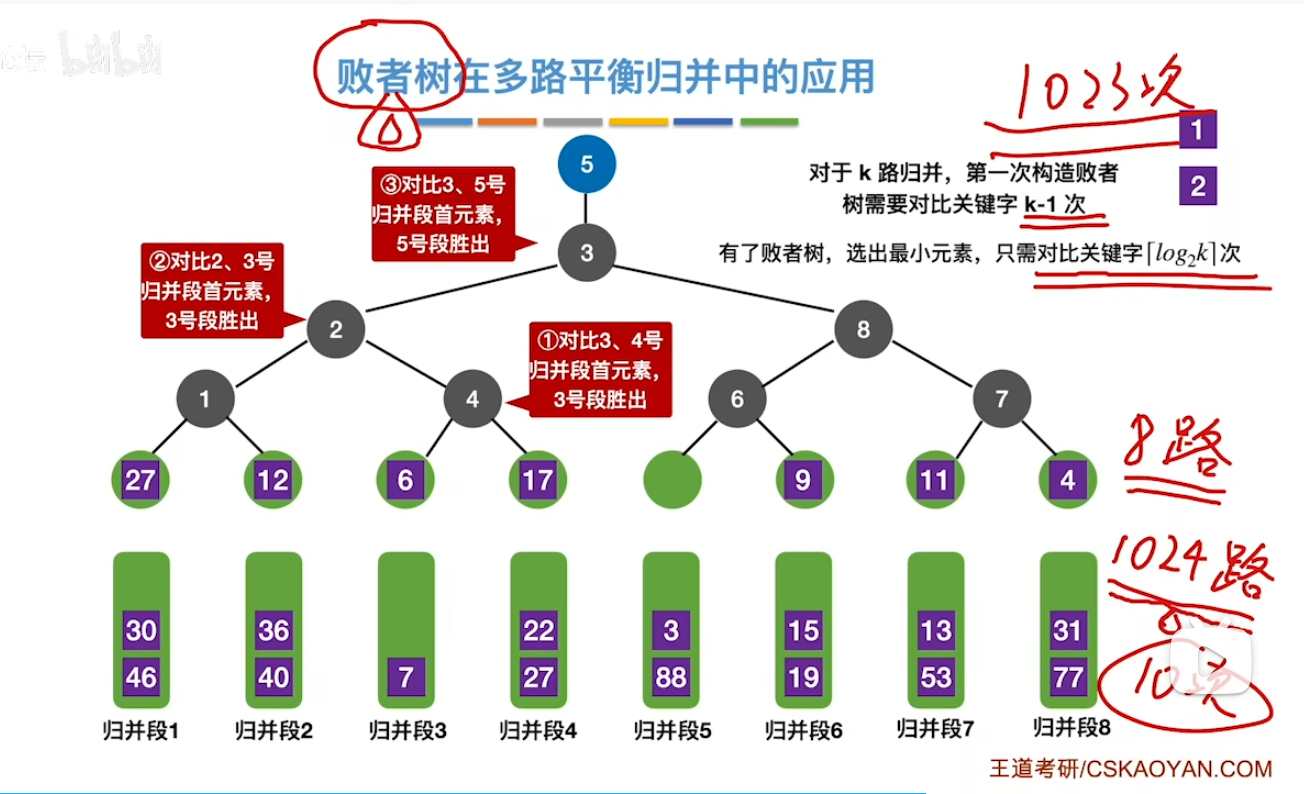
实现思路
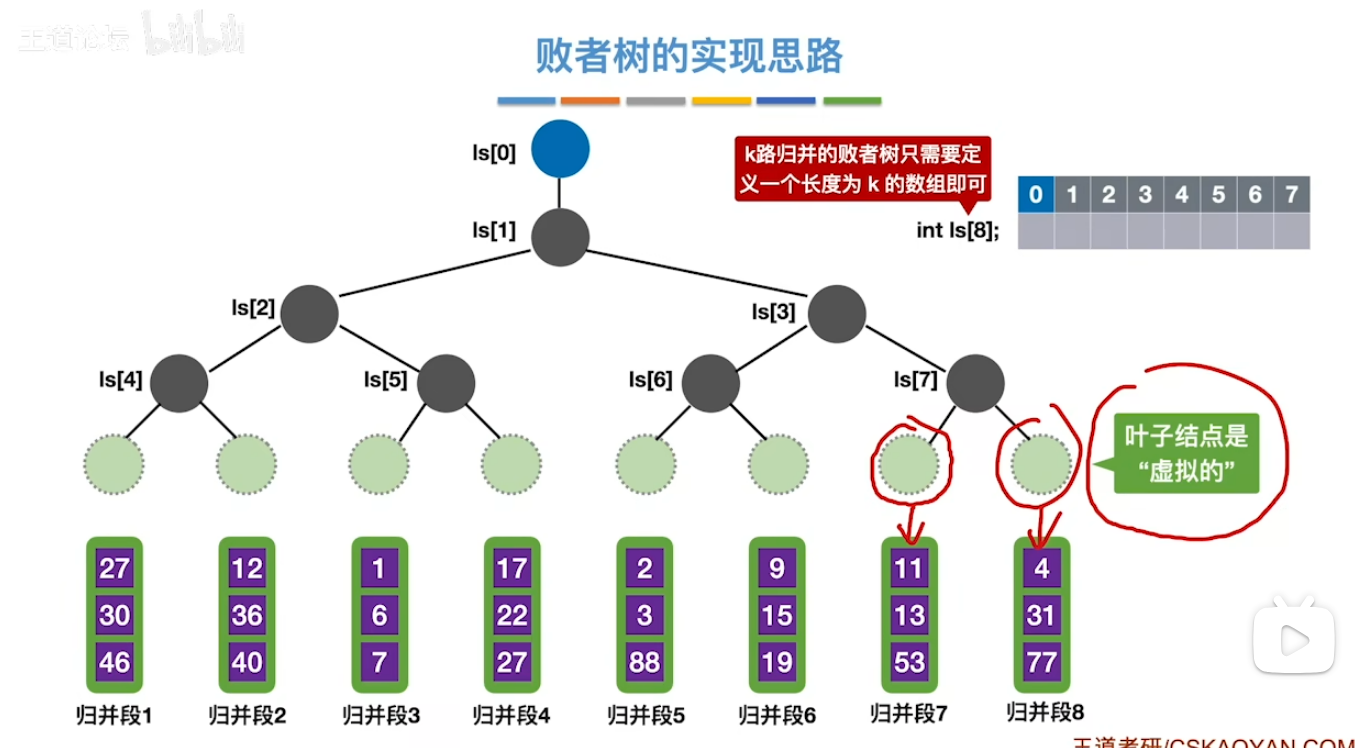
置换-选择排序(归并段 pro)
- 之前我们构造初始归并段的缺陷
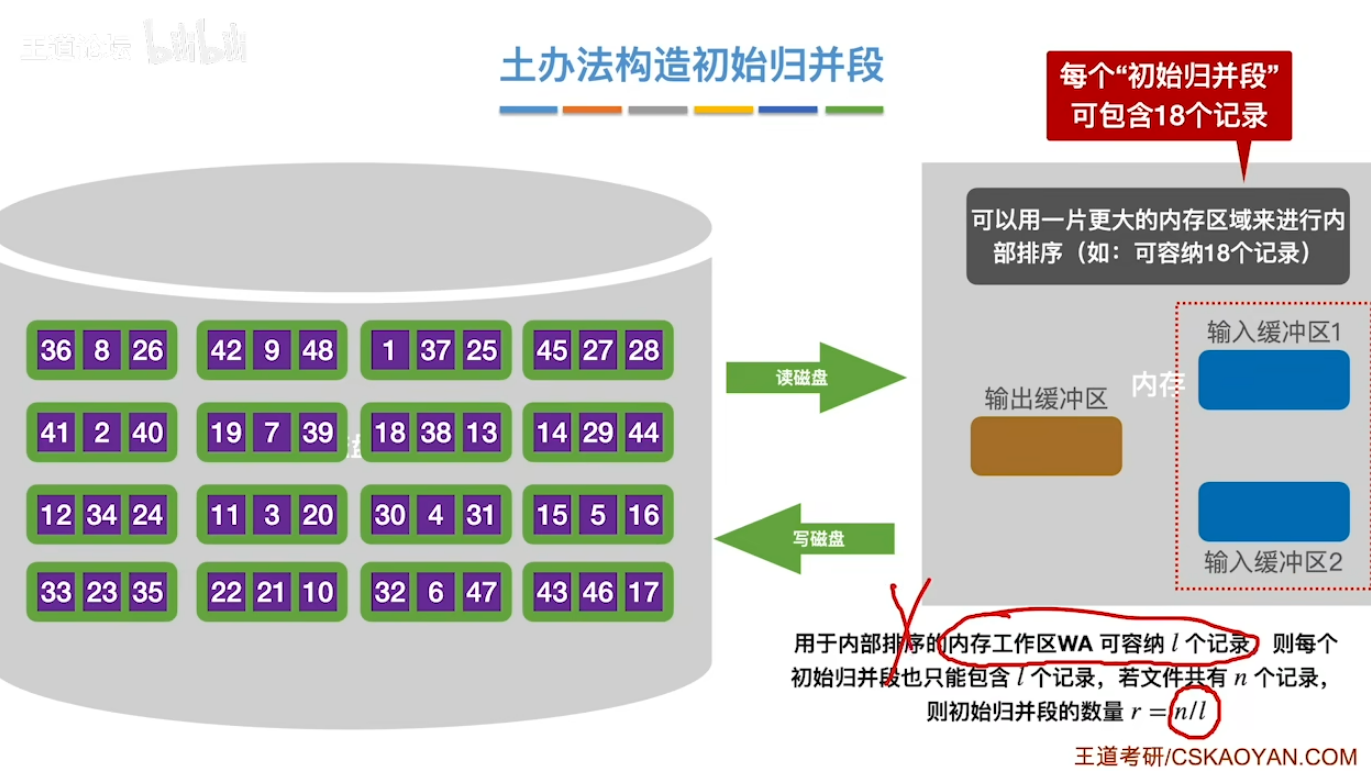
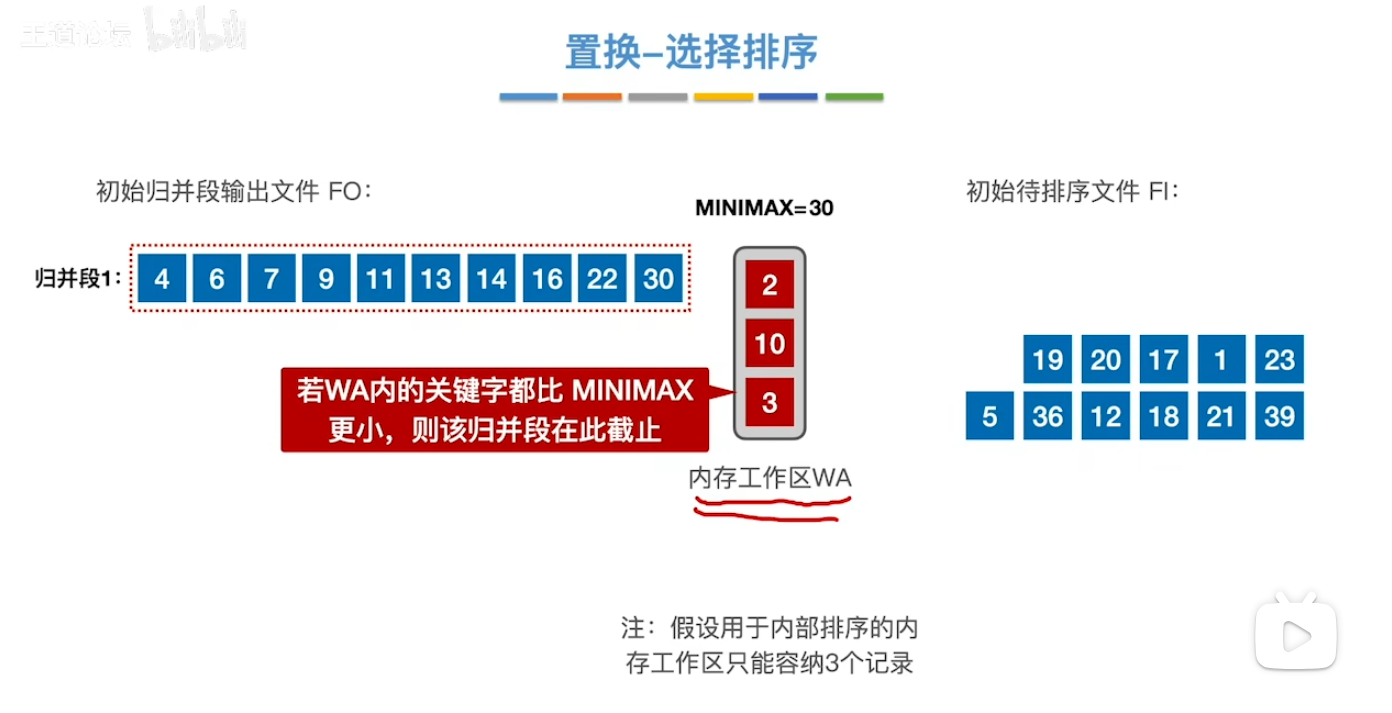
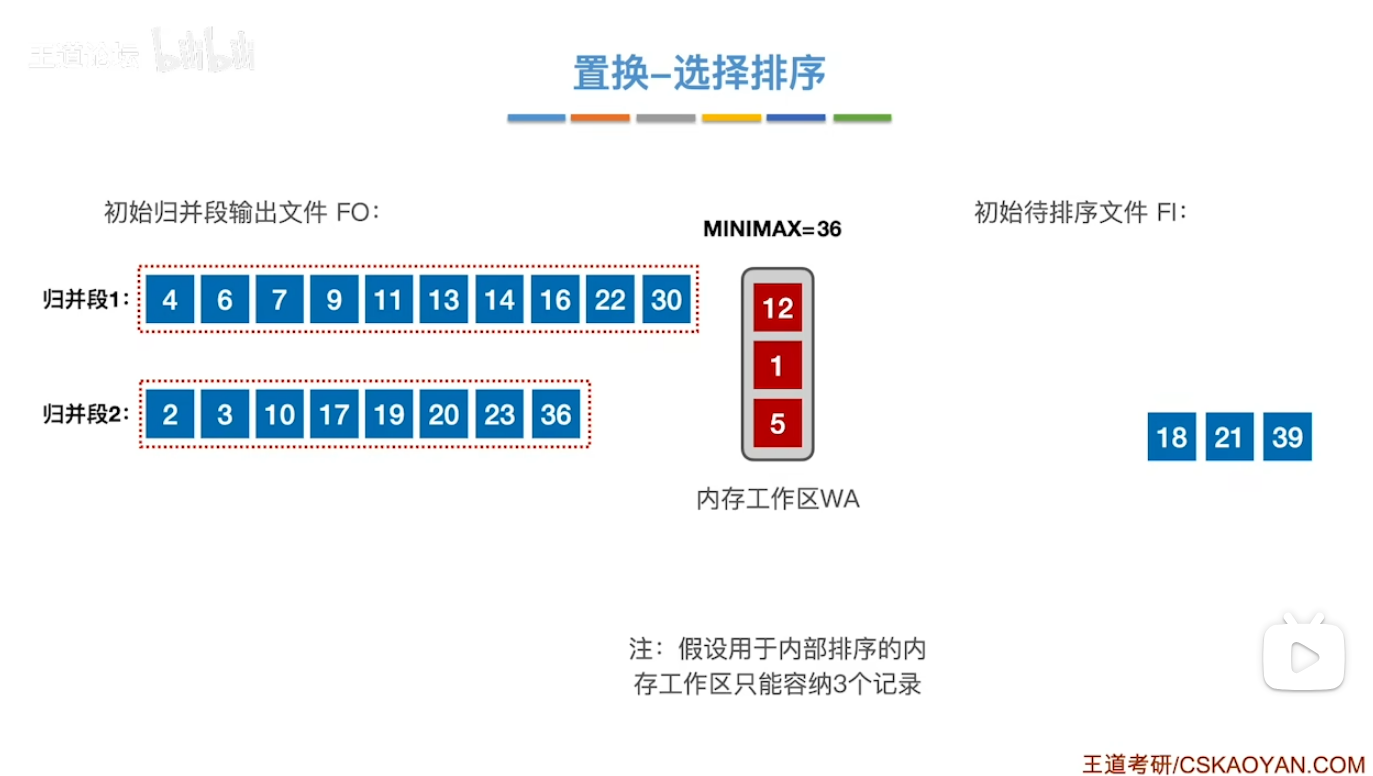
基本思想
- 用一句话来概括就是 我们每次都去选择待排序文件当中的最小值 并记录 保存在minimax中 不断地去更新直到接不上的时候(始终要保持归并段内部的有序) 这个归并段就终止了 并且我们的minimax也随之重置为了当前WA中的最小值 并将他作为我们下一个 新的 归并段的 第一个文件
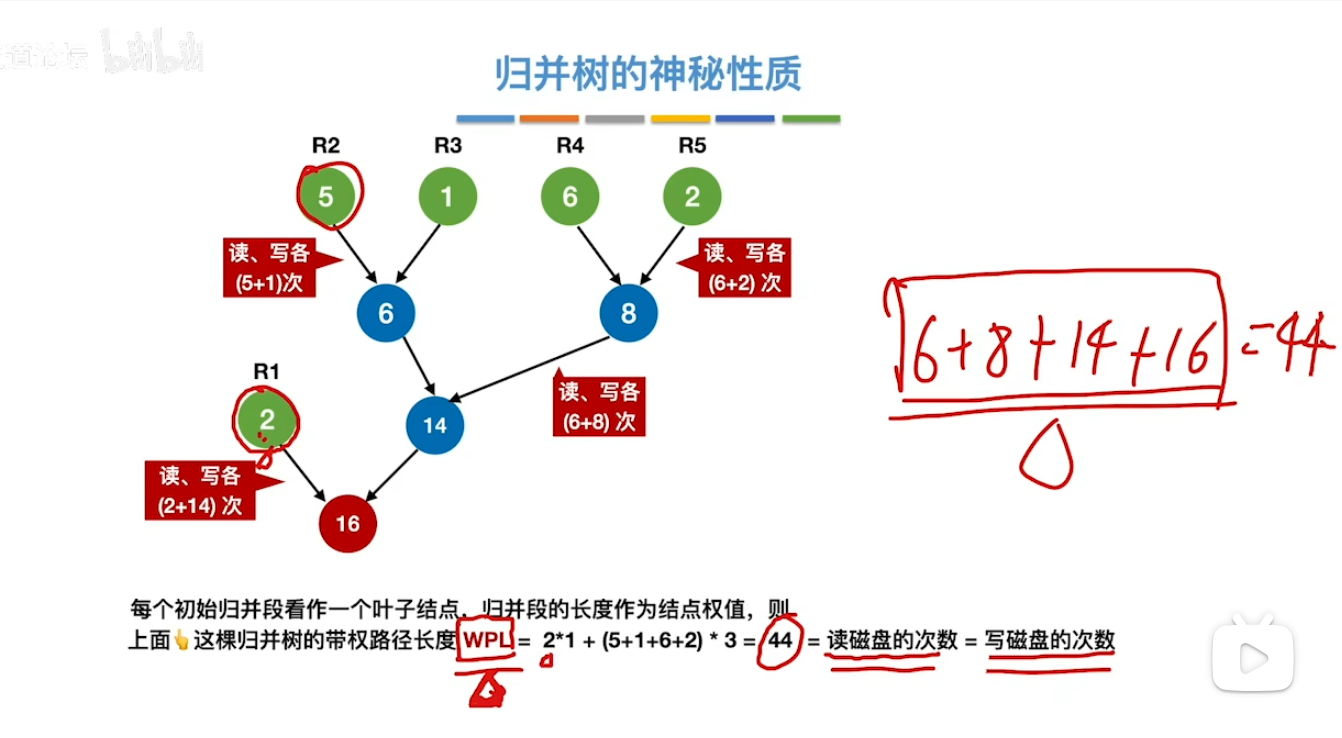
最佳归并树(哈夫曼树&WPL相关)
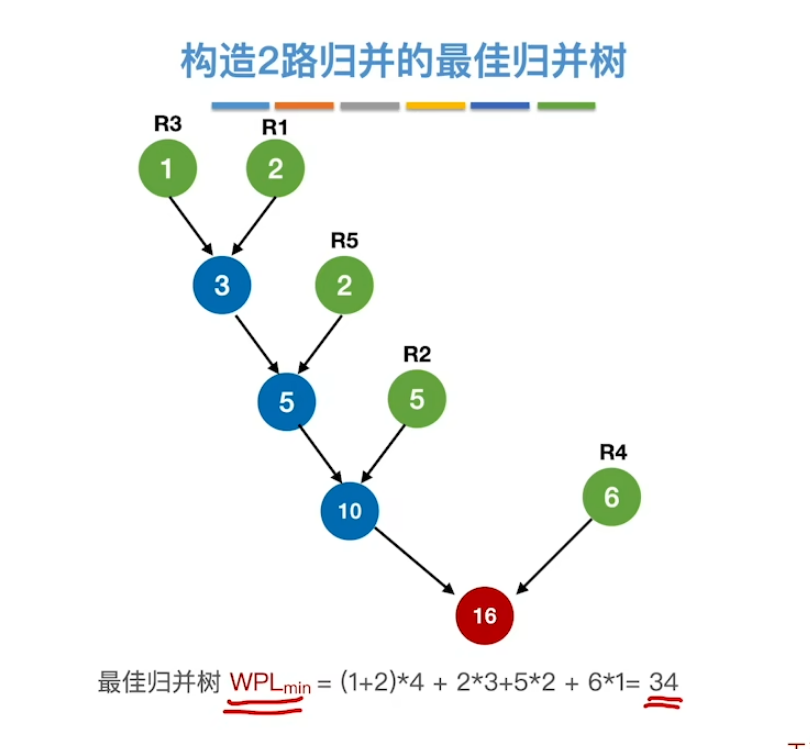
二路最佳归并树
- 构造的规则就是跟构造哈夫曼树是一样的 只不过这里每个节点上的权值代表的是我们归并段的长度
- 如果你不清楚什么是哈夫曼树及其哈夫曼编码 我强烈建议去看看懒猫老师的视频 对应链接
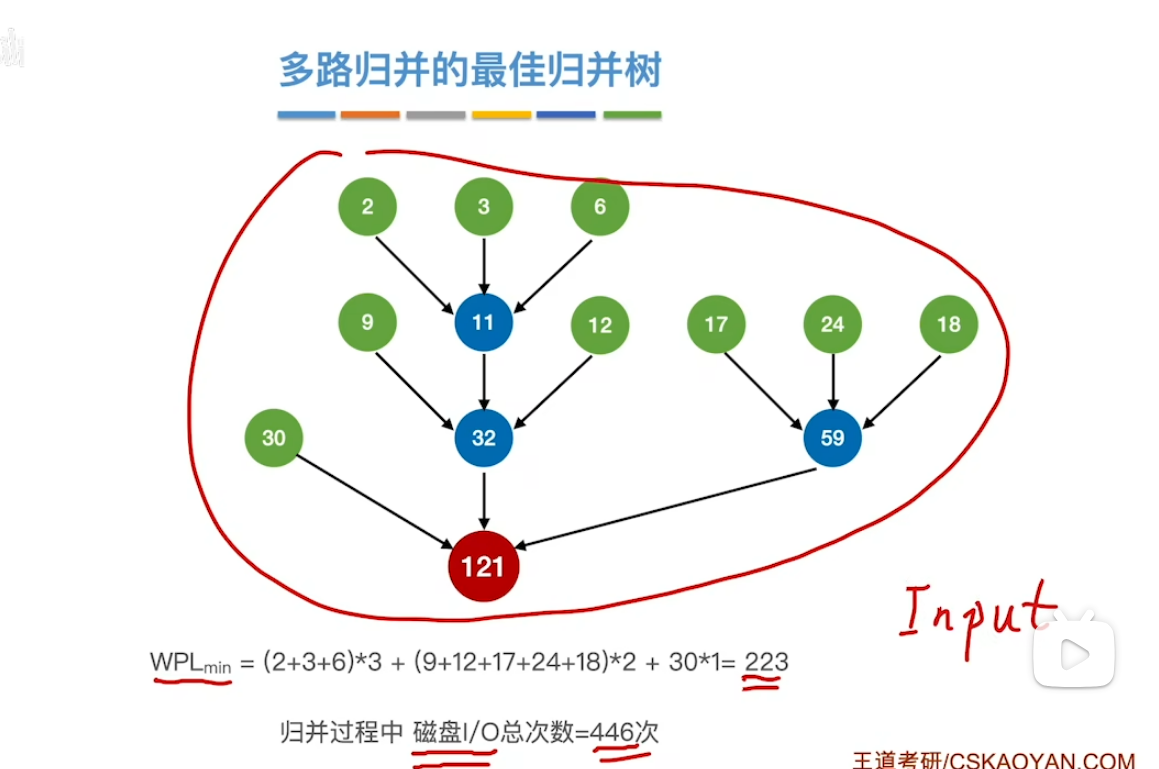
多路最佳归并树
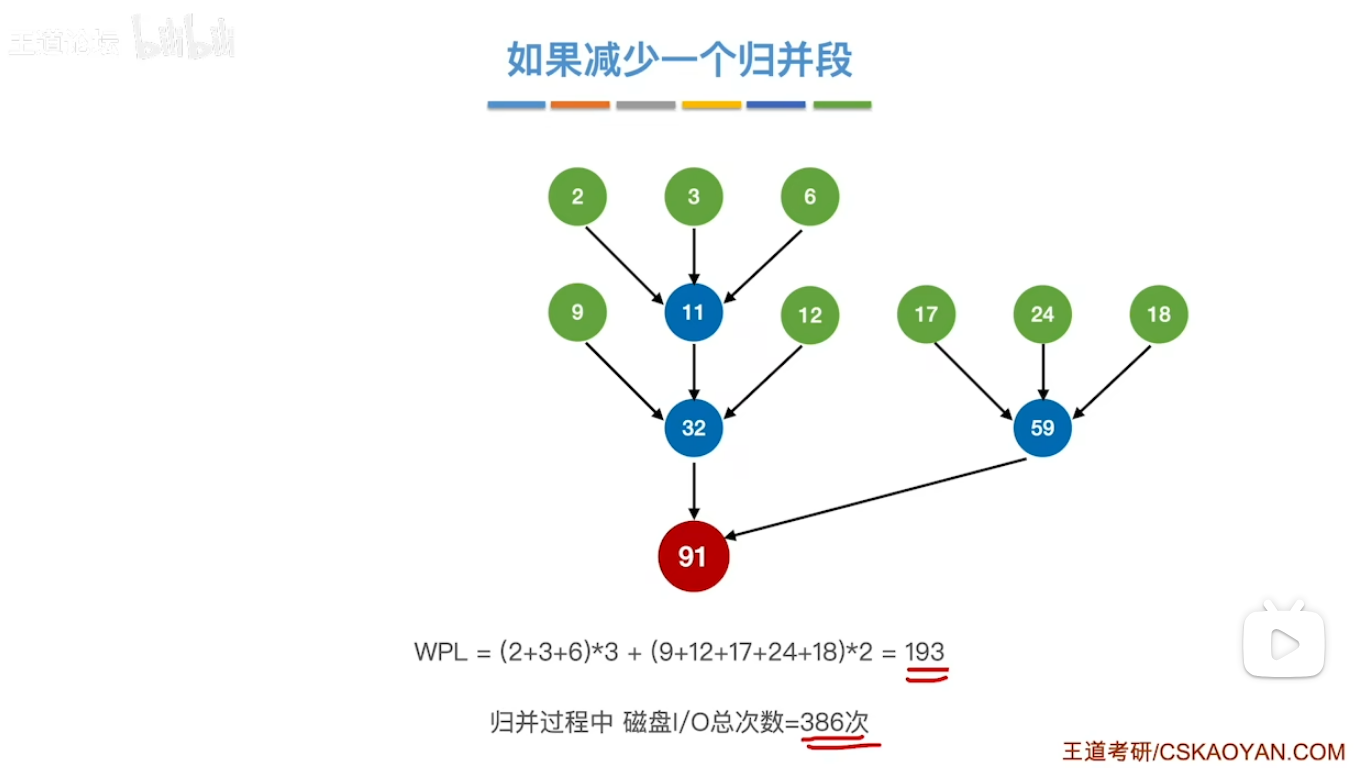
遇到的问题(节点数不满足要求)
-
如果节点数量不满足要求怎么办 比如我想构造一颗三叉树 但是现在只有8个节点 强行去构造是不行的
-
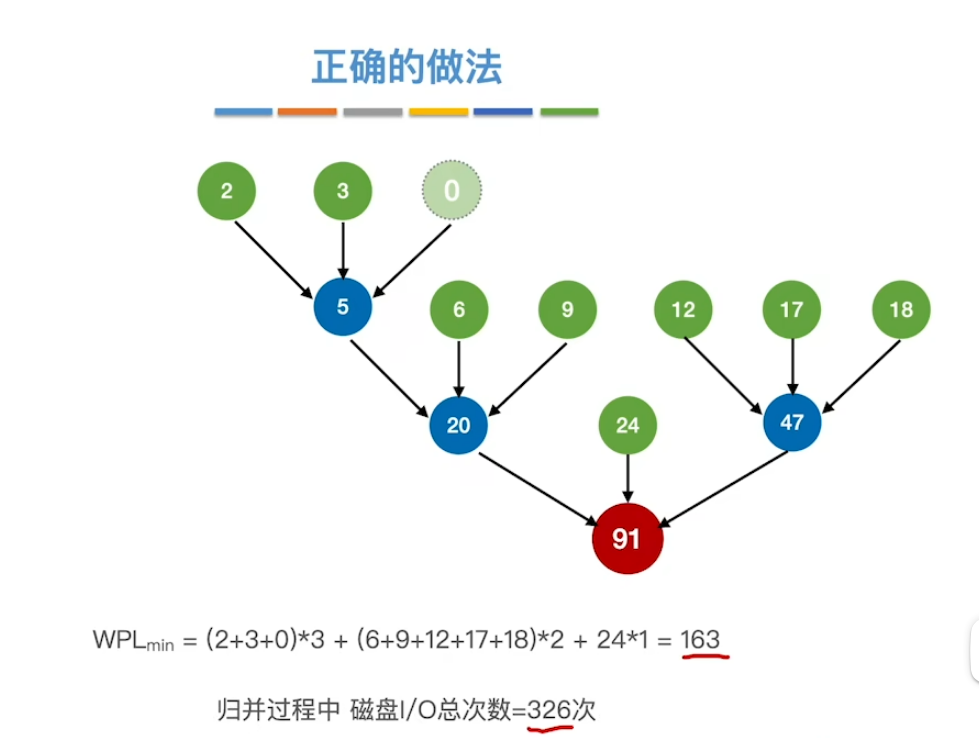
正确的做法:添加空节点(虚段)
-
如何快速确定添加虚段的数量

结语
这个确实好看
