scikit-learn工具介绍
scikit-learn
-
Python语言机器学习工具
-
Scikit-learn包括许多智能的机器学习算法的实现
-
Scikit-learn文档完善,容易上手,丰富的API接口函数
-
Scikit-learn官网:scikit-learn: machine learning in Python — scikit-learn 1.7.1 documentation
-
Scikit-learn中文文档:sklearn
-
scikit-learn中文社区
1 scikit-learn安装
使用 conda 安装
推荐用 conda 安装(自动处理依赖):
- 打开 Anaconda Prompt(或终端)。
- 进入当前所使用环境
conda activate 当前环境- 输入命令:
bash
conda install scikit-learn
2 Scikit-learn包含的内容
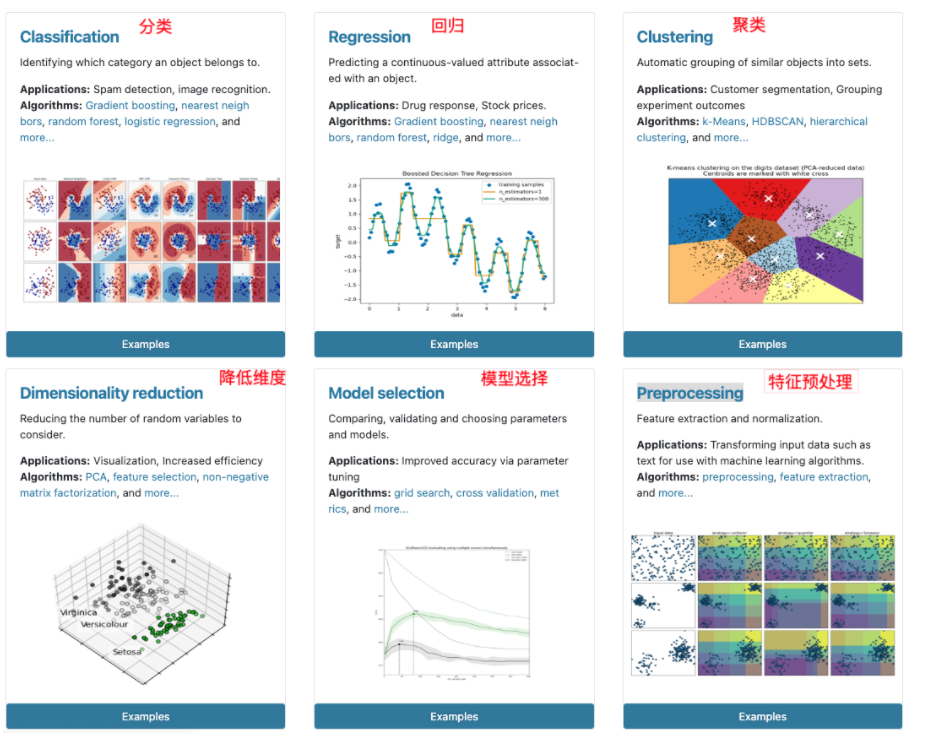
3 数据集
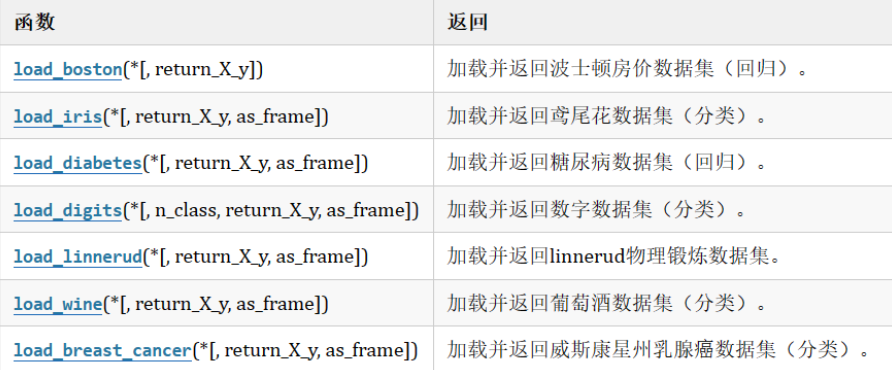
3.1 sklearn玩具数据集介绍
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取
3.2 sklearn现实世界数据集介绍
数据量大,数据只能通过网络获取

3.3 加载玩具数据集
示例1:鸢尾花数据(不了解可以在网上搜一下相关资料)
鸢尾花数据集介绍
特征有:
花萼长 sepal length
花萼宽sepal width
花瓣长 petal length
花瓣宽 petal width
三分类:
0-Setosa山鸢尾
1-versicolor变色鸢尾
2-Virginica维吉尼亚鸢尾
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data)#得到特征
print(iris.feature_names) #特征描述
print(iris.target) #目标形状
print(iris.target_names)#目标描述
print(iris.filename) #iris.csv 保存后的文件名
print(iris.DESCR)#数据集的描述试着输出观察数据(也可以试着观察糖尿病等数据集)
3.4 sklearn获取现实世界数据集
示例:获取20分类新闻数据
(1)使用函数: sklearn.datasets.fetch_20newsgroups(data_home,subset)
(2)函数参数说明:
(2.1) data_home
None这是默认值,下载的文件路径为 “C:/Users/ADMIN/scikit_learn_data/20news-bydate_py3.pkz” 自定义路径例如 “./src”, 下载的文件路径为“./20news-bydate_py3.pkz”
(2.2) subset
“train”,只下载训练集 “test”,只下载测试集 “all”, 下载的数据包含了训练集和测试集
(2.3) return_X_y,决定着返回值的情况
False,这是默认值 True,
(3) 函数返值说明:
当参数return_X_y值为False时, 函数返回Bunch对象,Bunch对象中有以下属性*data:特征数据集, 长度为18846的列表list, 每一个元素就是一篇新闻内容, 共有18846篇*target:目标数据集,长度为18846的数组ndarray, 第一个元素是一个整数,整数值为[0,20)*target_names:目标描述,长度为20的list*filenames:长度为18846的ndarray, 元素为字符串,代表新闻的数据位置的路径 当参数return_X_y值为True时,函数返回值为元组,元组长度为2, 第一个元素值为特征数据集,第二个元素值为目标数据集
from sklearn.datasets import fetch_20newsgroups #这是一个20分类的数据
news = fetch_20newsgroups(data_home=None,subset='all')
print(len(news.data)) #18846
print(news.target.shape) #(18846,)
print(len(news.target_names)) #20
print(len(news.filenames)) #188463.5本地csv数据
(1) 创建csv文件
方式1:打开计事本,写出如下数据,数据之间使用英文下的逗号, 保存文件后把后缀名改为csv
csv文件可以使用excel打开
方式2:创建excel 文件, 填写数据,以csv为后缀保存文件
(2) pandas加载csv
使用pandas的read_csv(“文件路径”)函数可以加载csv文件,得到的结果为数据的DataFrame形式
pd.read_csv("路径/ss.csv")
import pandas as pd
data_frame = pd.read_csv('.\src\\ss.csv')
data = data_frame.to_numpy()
x = data[:, :2]
y = data[:, 2]
print('x:\n', x)
print('y:\n', y)data_frame = pd.read_excel(".\src\\test.xlsx")
print(data_frame)4.数据集划分
sklearn.model_selection.train_test_split(*arrays,**options)#拿大部分数据去测试少部分去考试
参数
(1) *array
这里用于接收1到多个"列表、numpy数组、稀疏矩阵或padas中的DataFrame"。
(2) **options, 重要的关键字参数有:
train_szie值为0.0到1.0的小数,表示划分后训练集占的比例,整数表示个数,一般用小数
test_size 值为0.0到1.0的小数,表示划分后测试集占的比例,整数表示个数,一般用小数
random_state 值为任意整数,表示随机种子,使用相同的随机种子对相同的数据集多次划分结果是相同的。否则多半不同
strxxxx 分层划分,填y
2 返回值说明
返回值为列表list, 列表长度与形参array接收到的参数数量相关联, 形参array接收到的是什么类型,list中对应被划分出来的两部分就是什么类型
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
x, y = load_iris(return_X_y=True)
print(x[0], y[0])# 数据集划分
# train_test_split拿大部分数据去测试少部分去考试,并且数据是随机的
a = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
a_train, a_test = train_test_split(a)
print(a_train, a_test)# 数据集划分2
a = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
b = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# a b取的训练和测试数据数量和下标一致
a_train, a_test, b_train, b_test = train_test_split(a, b)
print(a_train, a_test, b_train, b_test)# 数据集划分3
a = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
b = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# train_size设置训练数据个数
# a_train, a_test, b_train, b_test = train_test_split(a, b, train_size=7)# train_size=0.8 设置训练数据为(比例)0.8 * 总数个数
# a_train, a_test, b_train, b_test = train_test_split(a, b, train_size=0.8)# train_size=0.8, test_size=0.1 分别设置训练数据与测试数据,可少不能超
# a_train, a_test, b_train, b_test = train_test_split(a, b, train_size=0.8, test_size=0.1)# shuffle=False控制是否打乱顺序,当为false时random_state无效
a_train,a_test,b_train,b_test=train_test_split(a,b,train_size=0.8,shuffle=False,random_state=42)print(a_train, a_test, b_train, b_test)
# 数据集划分的函数可以允许传入 data_frame list ndarray tuple 等等能取下标的都可以
4.1鸢尾花数据集划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据集
iris = load_iris()
x = iris.data
y = iris.target
# print(x, y)# 数据划分训练集(x,y)和测试集(x,y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
print(x_train.shape, x_test.shape)
print(y_train.shape, y_test.shape)4.2字典和数据集划分
from sklearn.feature_extraction import DictVectorizer
data = [{"city": "成都", "temperature": 30, "age": 118, "gdp": 100},{"city": "武汉", "temperature": 36, "age": 128, "gdp": 200},{"city": "北京", "temperature": 28, "age": 223, "gdp": 300}
]# 模型研究x与y的关系之前 必须保证x,y中全是数字# 创建转换器
# sparse=False表示生成的矩阵为稠密矩阵,True为稀疏矩阵
transfer = DictVectorizer(sparse=False)
# 先适配数据,再立即转换该数据,返回转换后的特征矩阵 data_new。
data = transfer.fit_transform(data)
print(data)# 转换后数据的特征名称
print(transfer.get_feature_names_out())
5.总结
-
先完成安装:推荐用 conda,激活目标环境后执行
conda install scikit-learn,自动处理依赖,省时省心。 -
从数据集入手:
- 先熟悉玩具数据集(如鸢尾花),用
load_iris()加载,查看data(特征)、target(标签)、feature_names(特征名)等属性,理解数据结构; - 尝试现实世界数据集(如 20 类新闻),用
fetch_20newsgroups()获取,注意参数subset(训练 / 测试集)和data_home(保存路径); - 掌握本地数据加载:用 pandas 的
read_csv()/read_excel()处理 CSV/Excel 文件,转为 numpy 数组提取特征(x)和标签(y)。
- 先熟悉玩具数据集(如鸢尾花),用
-
掌握数据集划分:
用train_test_split()划分训练集和测试集,重点理解参数:train_size/test_size(比例 / 数量)、random_state(固定划分结果)、stratify(分层抽样),通过鸢尾花等示例练习,确保划分后特征与标签对应。
关键是多动手:跑通示例代码,调整参数观察结果,逐步熟悉 scikit-learn 的数据处理逻辑,为后续模型训练打基础。