深度学习·基础知识
交叉熵损失CE
只关心正确类别的预测概率
- 先进行softmax得到logits
- 真实标签的概率分布:yyy,预测标签的概率分布:y^\hat{y}y^,NNN表示类别数,且yi∈{0,1}y_i\in\{0,1\}yi∈{0,1}
- 衡量两个概率分布的距离或者差别,类似KL散度
L(y,y^)=−1N∑i=1Nyilog(y^i) \mathcal{L}(y,\hat{y})=-\frac{1}{N}\sum_{i=1}^Ny_i log(\hat{y}_i) L(y,y^)=−N1i=1∑Nyilog(y^i)
二元交叉熵BCE
只需要记忆BCE就可,CE是其的一种推广
BCE确实强制每个类别的输出趋近0或1
- 先对每一个类别预测结果应用softmax得到logits
- 每一个类别的yiy_iyi允许为1,意味着可以存在多个分类结果。
- 真实标签的概率分布:yyy,预测标签的概率分布:y^\hat{y}y^,NNN表示样本数,且yi∈{0,1}y_i\in\{0,1\}yi∈{0,1}
L(y,y^)=−1N∑i=1Nyilog(y^i)+(1−yi)log(1−y^i) \mathcal{L}(y,\hat{y})=-\frac{1}{N}\sum_{i=1}^Ny_i log(\hat{y}_i)+(1-y_i)log(1-\hat{y}_i) L(y,y^)=−N1i=1∑Nyilog(y^i)+(1−yi)log(1−y^i)
Focal loss
- 用于解决数据集不平衡的问题
- 建立在BCE的基础之上
- ptp_tpt表明预测的置信度,与类别无关。(例如p=1表示对于类别1的预测概率为1,但是ptp_tpt表明了对正确标签的预测概率)
- αt\alpha_tαt定义与ptp_tpt类同,主要用平衡正负样本权衡。
- (1−pt)γ(1-p_t)^{\gamma}(1−pt)γ用于平衡难易的样本权衡。
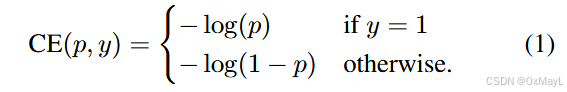
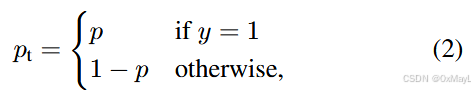
- 以下两种公式完全等价。就是展开来写的区别。
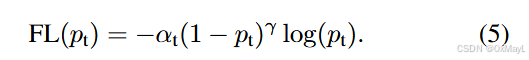
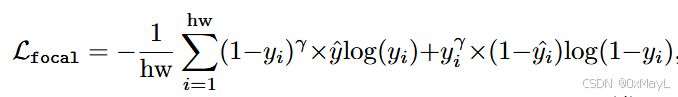
这里的yiy_iyi是预测结果,y^∈{0,1}\hat{y}\in\{0,1\}y^∈{0,1}是ground truth,αt\alpha_tαt一般不加,不考虑正负样本;γ=2\gamma=2γ=2时效果最好。
Dice loss
- 解决数据集不平衡的问题
标准公式:
Ldice=1−2∣X∩Y∣∣X∣+∣Y∣ \mathcal{L}_{dice}=1-\frac{2|X\cap Y|}{|X|+|Y|} Ldice=1−∣X∣+∣Y∣2∣X∩Y∣
很明显如果完全重合损失为0,所以这个loss适用于直接优化IOU指标
- 实际计算:
- 针对每一个类别计算loss损失
- 遍历每一个类别i,
(ground_truth==i)*pred*2得到上面的项,然后分别对掩码矩阵和预测矩阵求平方得到下面的项(技巧:转bool值)
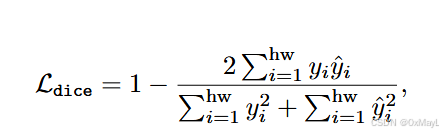
GZLSS/ZLSS和FLSS/FLSS
Zero-label=zero shot
few label=few shot
训练过程
- 预先设定某些类别为seen和unseen类
- 训练过程中对于unseen或者不涉及的类别,不计算损失
- 数据集的样本的划分细节等都不变

测试过程
- IOU指标取平均得到mIOU
- seen和unseen的类被分别计算
- 最终得到
harmonic mean (H)
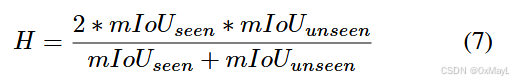
“inductive” zero-shot 和“transductive” zero-shot
Besides “inductive” zero-shot segmentation, there is a “transductive” zero-shot learning setting, which assumes that the names of unseen classes are known before the testing stage. They [17, 56] suppose that the training images include the unseen objects, and only ground truth masks for these regions are not available. Our method can easily be extended to both settings and achieve excellent performance.
“transductive” zero-shot在训练过程中,unseen类已知,图片中也包括unseen类,但是它们的注释信息是不知道的,所以需要CLIP生成伪标签,通过BCE来生成损失。