AI绘图-Stable Diffusion-WebUI的基本用法
前言
WebUI中的功能十分多无法一一说明,个人多进行尝试和探索才能更加熟练工具的应用;在本章中将会介绍Stable Diffusion中WebUI的安装、常见模块介绍以及文生图、图生图的常用方法
1 WebUI安装和介绍:
1.1 安装
- B站搜索秋叶,通过夸克网盘进行安装
- 视频中自带Stable Diffusion安装教程,安装完成后启动Stable Diffusion
| 名称 | 功能 |
|---|---|
| 高级选项 | 调整生成引擎、显存优化等,一般来说是默认设置 |
| 疑难解答 | 在生成图片出现错误的时候,这里进行扫描并生成错误报告 |
| 版本管理 | 对SD、扩展插件的版本进行升级以及管理 |
| 模型管理 | 对生成图像时使用到的各种模型进行管理 |
- 简易的一图流教程:
- 点击一键启动后打开浏览器
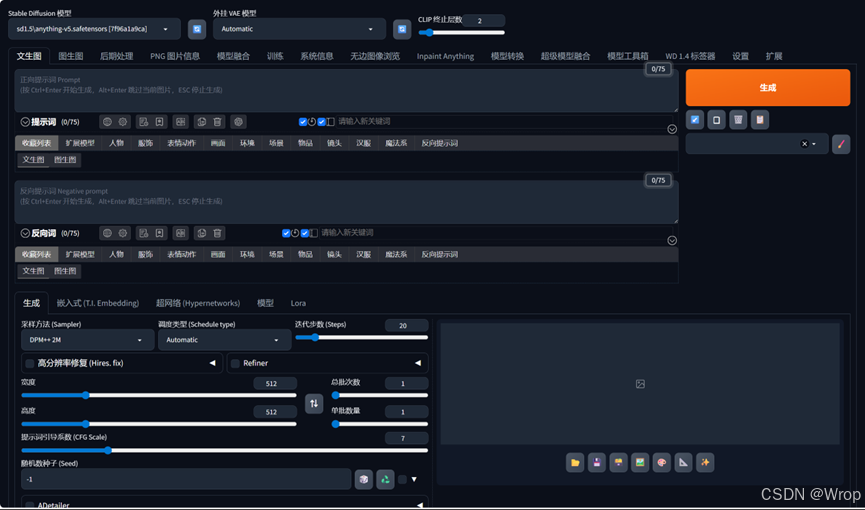
1.2 介绍
1.2.1 Stable Diffusion模型
选择之前下载过的模型,大模型是生成图片的基础,一般分为真实类型、3D类型、动漫类型
模型下载网站可以选择Civitai、liblib
大模型下载可以在网站的筛选器中选择checkpoint
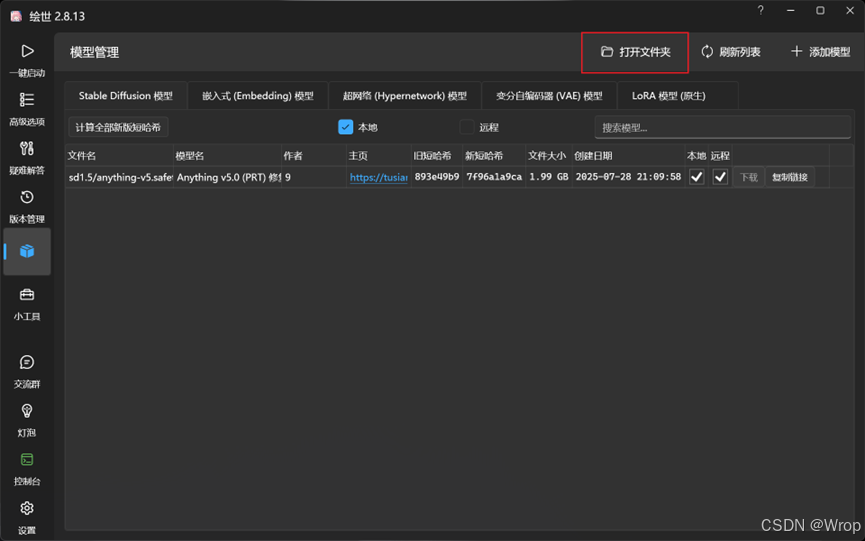
选择好下载的模型之后,可以在模型管理中打开大模型所在的文件夹
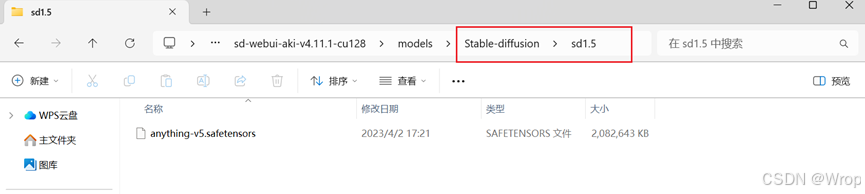
进入文件夹后将下载好的大模型文件放入

1.2.2 VAE模型和CLIP终止层数
VAE模型:个人理解上来看与添加滤镜比较相似,一般默认选择自动
CLIP终止层数:目的是跳过一些不必要的图像生成步骤,减少设备生成时间和负担,CLIP值越低,生成的图片越符合提示词的描述

1.2.3 文生图
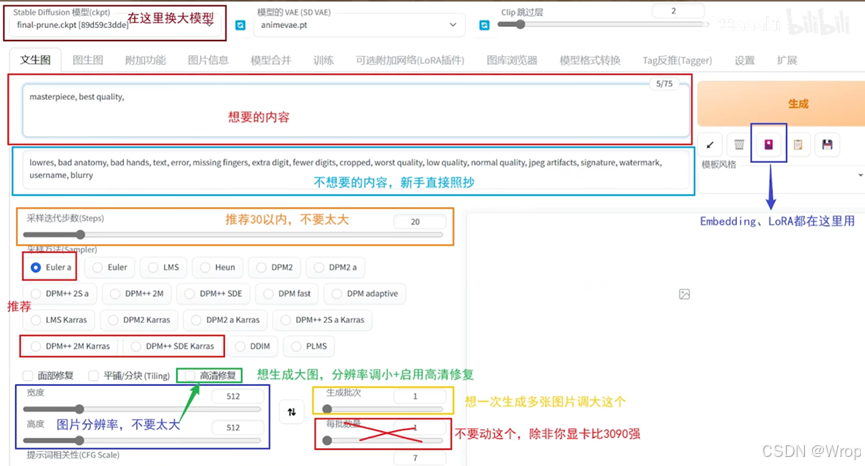
- 正向提示词框:希望在画面中出现的元素
可以在小框中输入中文,会直接翻译到正向提示词框中
提示词一栏可以提供思路以及加载扩展模型
正向提示词建议书写结构
提示词的分隔与权重:一般使用英文‘,’进行分隔,权重有两种写法:写法一:(1 girl:1.5):表示增强提示词的权重到1.5倍写法二:(((1 gril))):每套一层括号,提示词权重增强1.1倍,表示1.331倍权重
提示词的其他语法:[girl|cat]:表示猫女,女孩与猫融合[cat:dog:20]:表示前20步渲染猫,之后开始被替代开始渲染狗[dog:10]:狗在10步之后开始渲染\


- 反向提示词框:不希望在画面中出现的元素
- 生成模块:
从左到右,功能依次为:
按钮 功能 第一个 读取上次生成的参数 第二个 与第一个功能类似 第三个 删除所有正反向提示词 第四个 将预设里的反向提示词记载到提示词框中,预设需要在下方的画笔处进行设置

- 采样方法:指从随机噪声生成最终图像时所采用的计算步骤和数学策略,它决定了图像生成的路径、速度和质量;使用其他大模型时根据模型作者推荐进行设置,日常一般使用DPM++2M或者Euler a
- 调度类型:指控制噪声随时间步长衰减方式的数学策略,它决定了采样过程中每一步噪声的调整节奏和强度;同样需要根据模型作者推荐的进行设置,一般使用Karras;采样器负责执行生成步骤的算法,而调度类型则定义这些步骤中噪声的衰减规则,两者配合完成图像生成
- 迭代步数:指AI从随机噪声生成最终图像所经历的降噪计算次数,它直接影响图像细节的精细度和生成所需时间;一般选择20-50区间,过少精度不够,过多容易出现伪影
- 提示词引导数:指控制AI对输入提示词的服从强度的参数,数值越高则生成结果越严格贴合提示词,但可能丧失创意性;数值越低则AI自由度越高,但易偏离主题;一般设置为7
- 总批次数和单批次量:前者适合电脑性能不高,一批次一张图片,生成多批次;后者适合电脑性能高,只生成一批次,一批次多张图片
- 随机种子值:指生成图像时使用的初始噪声图的唯一数字标识,它决定了AI绘画的起点噪声状态,直接影响图像的构图、细节和风格;相同的种子值在相同参数下会生成完全一致的图像

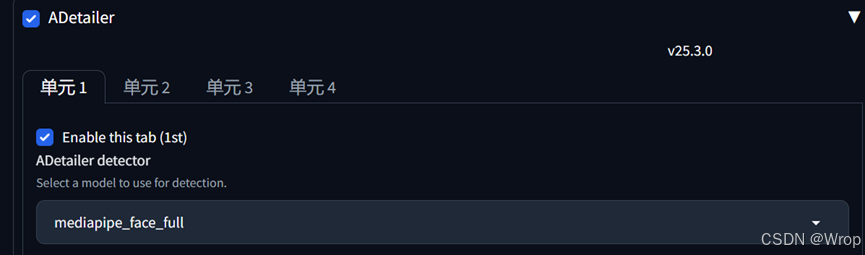
- ADetailer:是一个后处理插件,用于自动检测并增强图像中的细节,通过局部重绘修复模糊或畸变问题,可以用于人脸的修复
一般选用mediapipe_face_full,保证随机种子值与想要重绘的图片一致,在重绘模块中调整局部重绘幅度重新生成局部
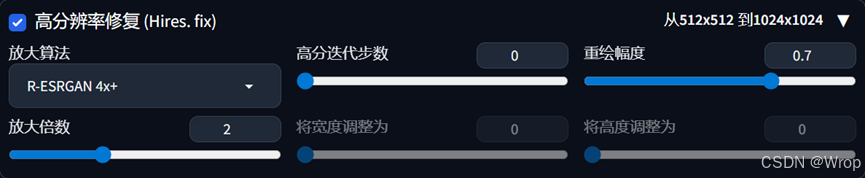
- 高分辨率修复:指通过分阶段生成策略(先快速生成低分辨率图像,再基于其细节智能放大至高清)来平衡效率与画质的核心功能,不能和ADetailer同时使用
放大算法:一般使用R-ESRGAN 4x+和R-ESRGAN 4x+ Anime6B,前者适合发大真实性的图片,后者适合放大动漫类型的图片
高分迭代步数:再次参考关键词进行生成,一般设置为0或10
放大倍数:将图像原来的大小扩大几倍
1.2.4 图生图
- 相比于文生图,图生图多出了两个按钮:
CLIP反推:使用CLIP神经网络创建图像的文本描述,并且将其填入到提示词框中
DeepBooru:使用DeepBooru神经网络创建图像的文字描述,并且将其填入到提示词框中
前者一般用于真实场景,输出语言风格是自然语言描述;后者一般用于动漫场景,输出风格是短标签组合

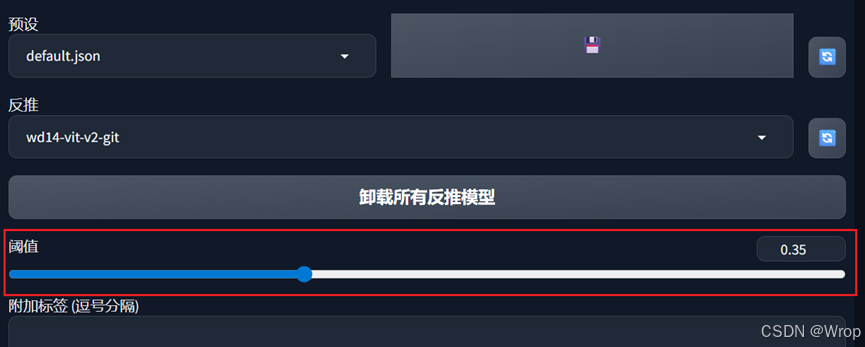
- 不过一般对于反推提示词,通常会使用WD1.4标签器,第一次使用可能会下载反推模型,时间会比较长

阈值越低,反推的越仔细,获得到的提示词就越多,一般默认即可
- 原图像素比较小的时候,可以使用三角形按钮自动检测尺寸
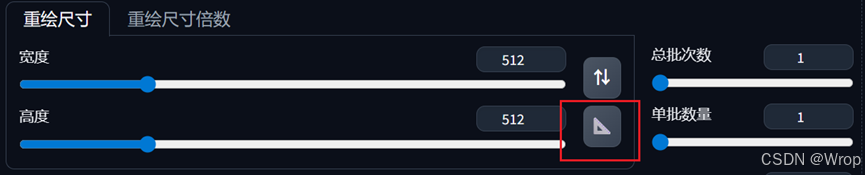
- 如果原图像素值过大,可以尝试重绘尺寸倍数,将尺度调小,其中1是原来比例

- 重绘幅度越大,图生图后的图像改变就越大,与提示词的关联度就越高

- 涂鸦:指用户通过手绘线条或色块覆盖原图局部区域,直接引导AI在指定位置进行定向重绘的交互式创作方式

- 局部重绘:手绘蒙版区进行针对局部的重新生成

- 涂鸦重绘:指用户通过手动绘制色块或线条覆盖图像局部区域,直接以视觉方式引导AI在该区域进行定向内容生成与替换的过程;例如画一个棕色区域胡,结合指导词“房子”,即可局部重绘出棕色的房子

- 上传重绘蒙版:根据已有的蒙版图片,对原图像进行重绘
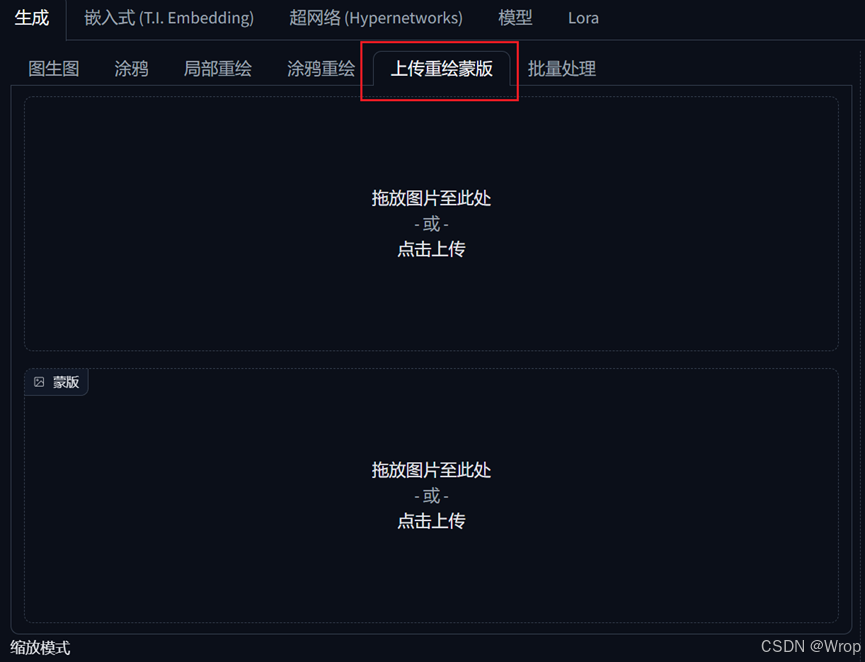
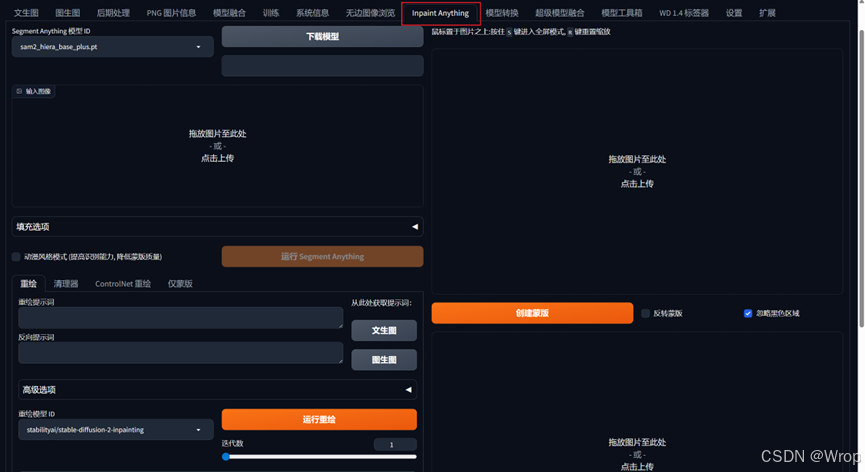
蒙版图片可以从Inpaint Anything模块进行获取
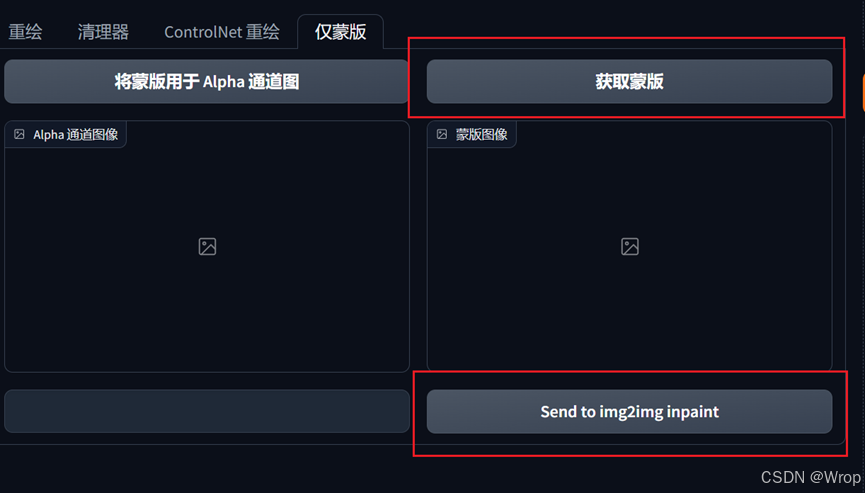
第一次使用需要先下载模型,模型一般使用默认;上传图像之后点击运行Segment Anything,之后根据需要导出蒙版的部位用画笔进行点画
最后在仅蒙版模块下点击获取蒙版,并Send to img2img inpaint
- PNG图片信息:还原使用SD生成的图片信息,包括正反向提示词、使用的模型以及参数等
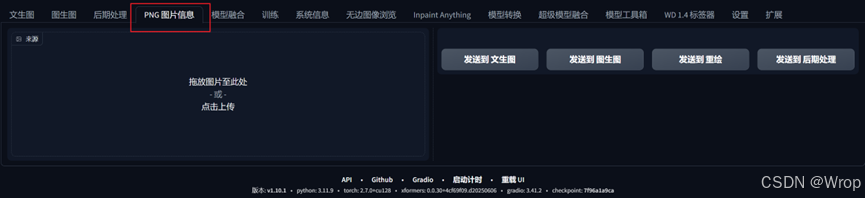
1.2.5 脚本
- 在下方可以选择脚本xyz图表,可以根据自己的需求进行设定,一般用来对比在不同模型以及不同参数下,步数有什么不同
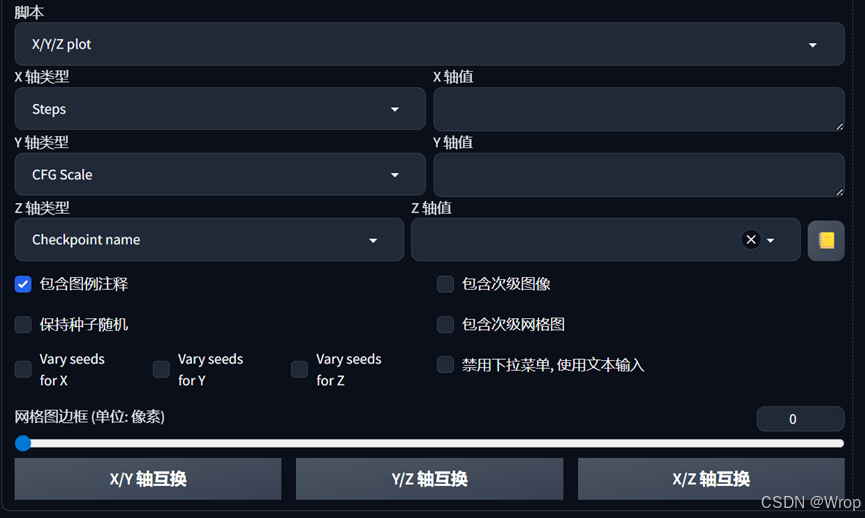
- 除此之外还有提示词矩阵,直接在正向引导词处使用’|’代替’,’即可使用,例如’1cat|playing with oranges|playing with apples’,一般可以用于模特更换不同的衣服
1.2.6 Lora模型
- 基本概念:指通过微调少量关键层参数生成的轻量级适配器,用于在基础大模型上叠加特定风格、角色或概念,实现定制化效果而不改变原模型结构;比如将普通人物转成迪士尼画风或固定生成某个原创角色
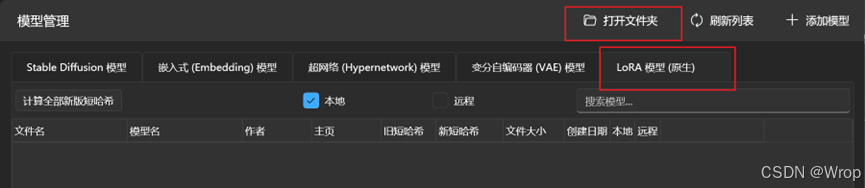
- 下载安装:可以在模型网站上筛选出LORA标签,选择需要的进行下载,下载完成后将文件安装在下面的位置:
- 使用Lora模型的顺序:
加载基础大模型->加载Lora插件->触发词激活->使用成功
在Lora模块中选择想要加载的插件,加载Lora插件: