数据结构——并查集及C++实现
目录
一、前言
二、并查集
1、并查集结构
2、合并
2.1找根
三、代码实现
1、并查集类
2、找根
3、合并
4、判断两个单个元素是否在一个集合里
5、并查集中集合个数
四、并查集的优化
1、优化一 高度优化
2、优化二 压缩路径
五、源码
六、总结
一、前言
想象这样一个场景:你正在设计一个社交网络系统,用户之间可以添加好友。系统需要支持两个操作:
- 检查用户A和用户B是否是朋友(直接或间接)。
- 将用户A和用户B添加为好友。
面对上亿用户,如何高效地实现这两个操作?暴力搜索?DFS?还是有更好的方法?
这就是我们今天要介绍的主角——并查集(Union-Find set),一个专门用来处理这类“动态连通性”问题的高效数据结构。
在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-find set)。
二、并查集
并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的合并及查询问题。常常在使用中以森林来表示。
举个例子来说:假设某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
毕业后,学生们要去公司上班,每个地方的学生自发组织成小分队一起上路,于是:西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。
现在就已经分为了三个小团体,那我我们该怎么标识以区分这三个小团体呢?
那上面我们了解过了概念,并查集呢通常用森林来表示,一棵树就是一个集合。
为了将名字和编号一一对应起来,我们还需要在编号和姓名之间建立一个映射关系。
1、并查集结构
首先,对于上面的例子,我们拿到的是学生们的姓名,我们考虑如何对他们进行存储如何做到姓名和编号的一一映射呢?
使用一个数组来存储学生们的姓名,再使用一个map结构来存储学生们姓名和编号之间的映射关系。我们可以用vector存名字数组里面的数据,那下标就可以做它们的编号,那这样用编号找名字是很方便的,编号是几,就找下标为几的元素就行了。 但是名字找编号就有点麻烦,所以我们可以借助map给名字和编号建立一个映射关系。
#pragma once
#include <vector>
#include <map>template<class T>
class UnionFindSet
{
public:UnionFindSet(const T* a, size_t n){for (size_t i = 0; i < n; ++i){_a.push_back(a[i]);_indexMap[a[i]] = i;}}
private:vector<T> _a; // 编号找人map<T, int> _indexMap; // 人找编号};测试结果如下
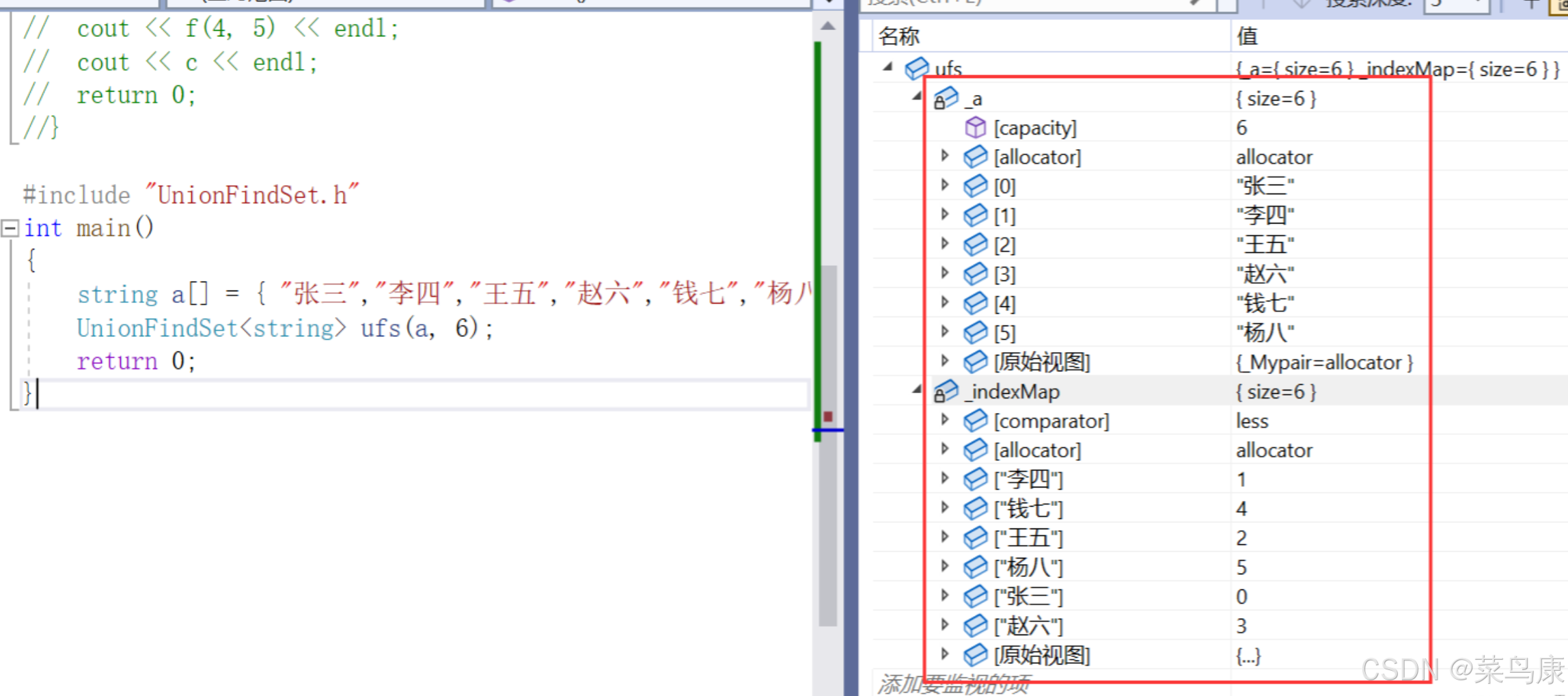
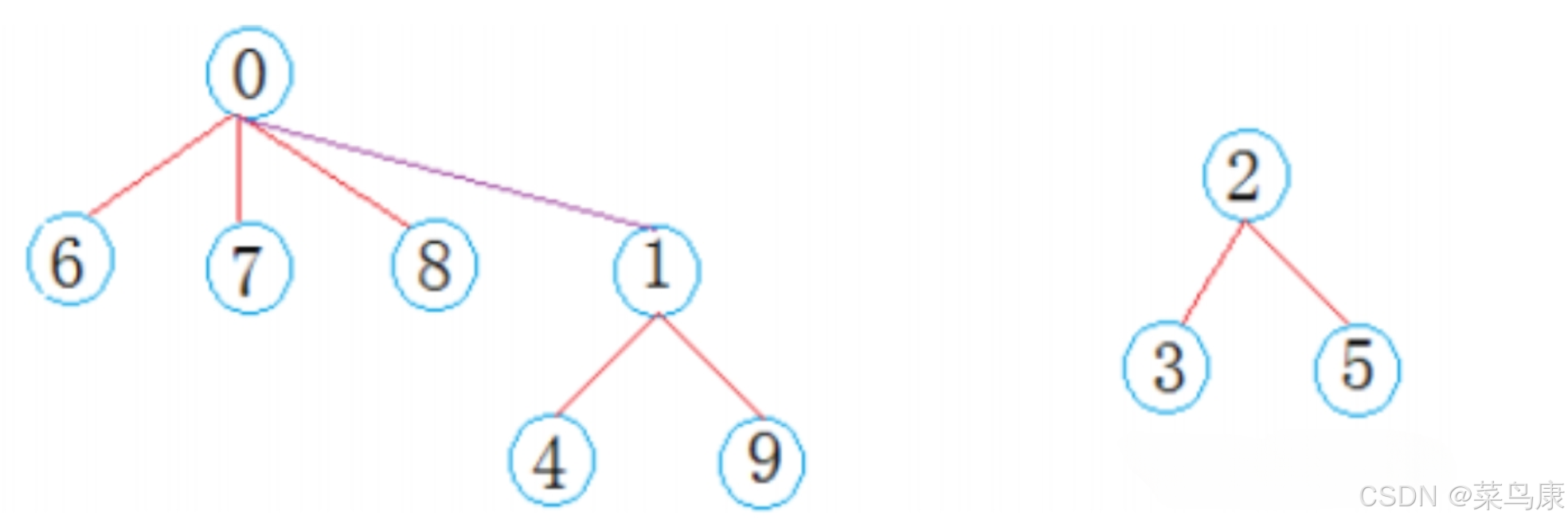
接着在上面的例子中,我们将集合分成了三部分,按并查集的概念来说,一棵树就代表一个集合。西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。 很简单,选一个做根,其它的做它的孩子就可以了。 假设选最小的做根(组长),负责大家的出行如下所示
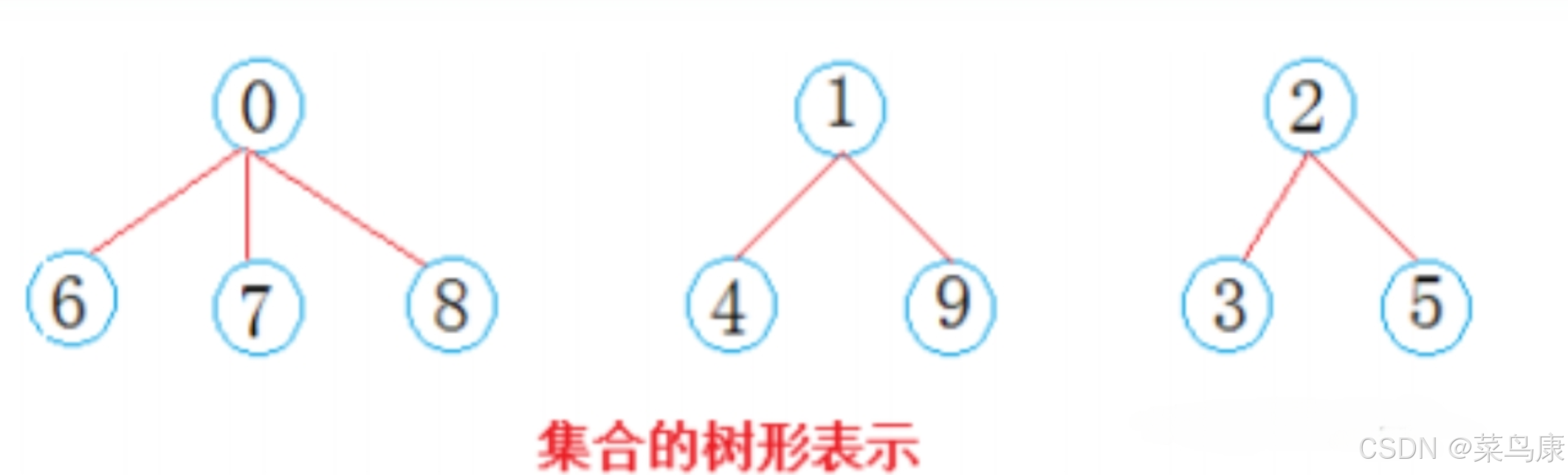
这里用的是双亲表示法,我们只需要使用一个数组就可以搞定。就跟我们之前学的堆有点类似,堆的逻辑结构是一棵完全二叉树,但底层的物理结构是一个数组。 那这里10个人,所以起始状态就可以这样表示

每个位置存一个-1(当然不一定非得是-1,但存-1比较好,后面会解释),现在就表示有10棵树,10个集合,这是在还没有合并之前的样子。
2、合并
接下来考虑的是如何将上面的并查集的数组中的10棵树合并成例子中的三棵树呢?
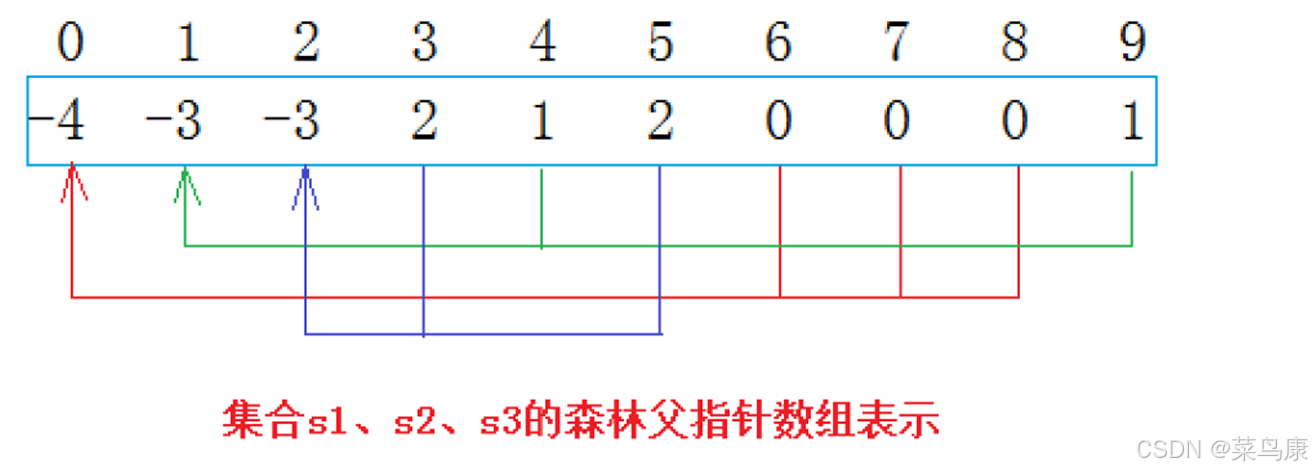
上图表达的意思:编号6,7,8同学属于0号小分队,该小分队中有4人(包含队长0);编号为4和9的同 学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的同学属于2号小分队,该小分队有3 个人(包含队长1)。
解释:
- 数组的下标对应集合中元素的编号
- 对于每个位置来说,如果它存的值是负数,那它就是根,如果不是负数,那它存的就是它的父/双亲结点的下标。
- 根结点的位置(即值为负数的位置),该位置存的值得绝对值就是对应这棵树上结点的个数(当然前提是起始时每个位置存的都是-1,所以为什么我们上面选择了-1作为初始值)。
上面我们考虑了单个学生之间的合并,那如果是在已经存在上面的小团体的情况下,团体与团体之间的合并该如何进行呢?
在公司工作一段时间后,西安小分队中8号同学与成都小分队4号同学奇迹般的走到了一起,两个小圈子的学生相互介绍,最后融合成了一个朋友圈

考虑我们像之前那样直接将8位置的值加到4位置上,然后8位置存4,可不可以,就像下面这样
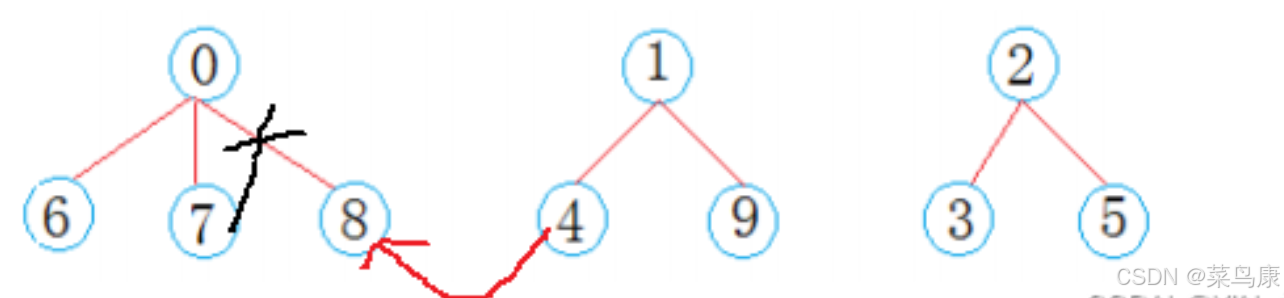
这是不对的,这样等于把8从原先的圈子脱离,然后加到4这棵树里面。 但是我们是要把这两个小集合合并,而且这样这两棵树根结点记录的个数也不对了 。
所以我们重点是要先找着两棵树的根,把它们的两个根合并了,对根进行操作才能算是合并两棵树。
2.1找根
接下来牵扯到的问题就是如何找根?
很简单,看这个位置存的值是不是负数,是负数的话就是根了;不是负数的话,存的就是根的下标,那就顺着父结点往上找,直到值为负数就是最上面的根了
如
4找到根是1,8找到根是0 然后让这两个根合并就行了,两个根你合并到我,我合并到你都可以 那比如我们这里让1合并到0(保持根上面一样小的做根),怎么做呢? 那就还是一样的逻辑:
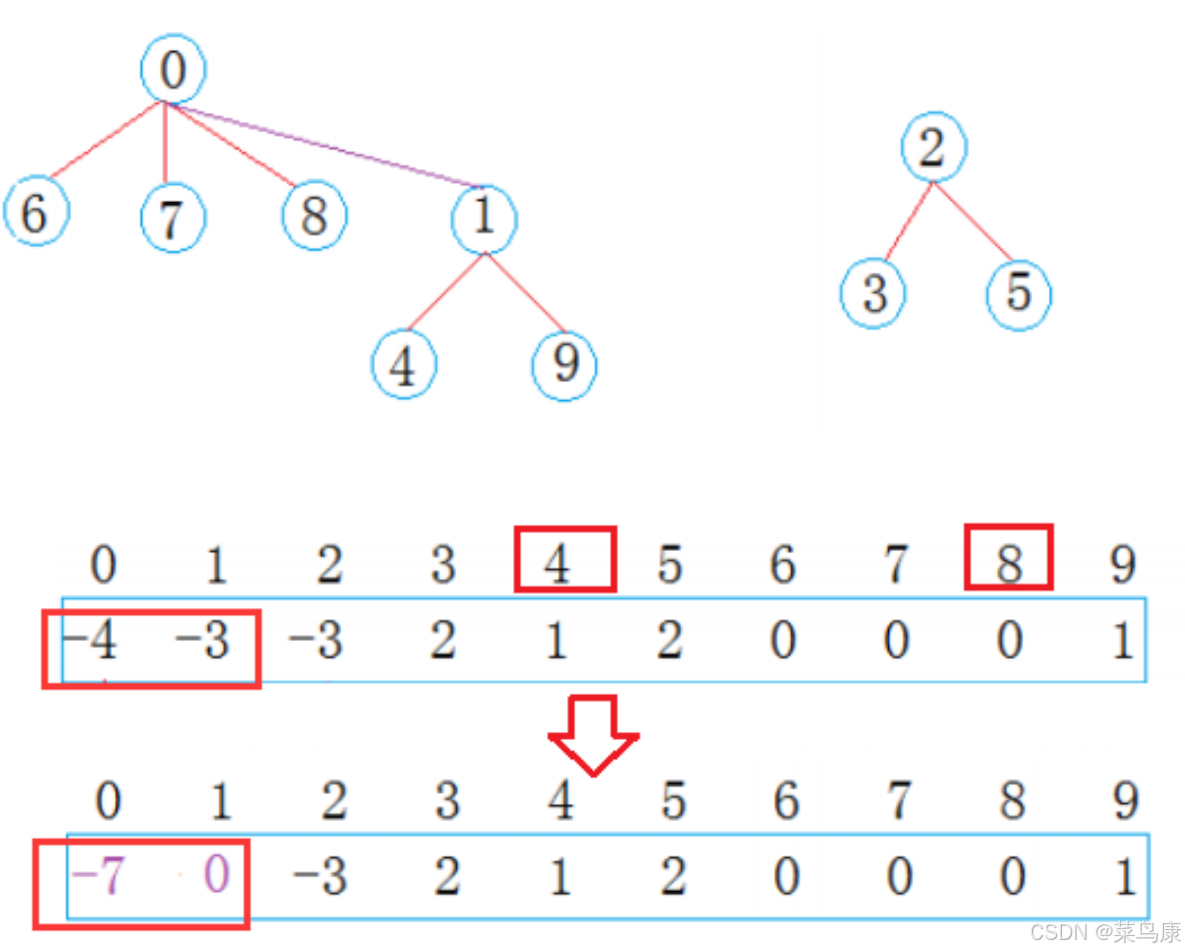
把1位置的值加到0位置上,然后1位置存0(即它的父亲的下标) 那此时0位置的值为-7,也表示0这棵树一共7个结点
现在0集合有7个人,2集合有3个人,总共两个朋友圈。
三、代码实现
1、并查集类
我们这里就不搞的像上面那样复杂了,因为我们上面的例子直接按编号去搞就行了。
那我们底层用一个vector就行了
class UnionFindSet
{
public:UnionFindSet(size_t n): _ufs(n, -1){}private:vector<int> _ufs;
};构造函数接受一个 size_t 类型的参数 n ,用于初始化一个大小为n 的向量 _ufs,其中每个元素初始值为-1。这个向量用于存储每个节点的父节点信息,初始时每个节点都是自己的父节点,因此值为-1表示没有父节点。
接下来实现几个接口:
2、找根
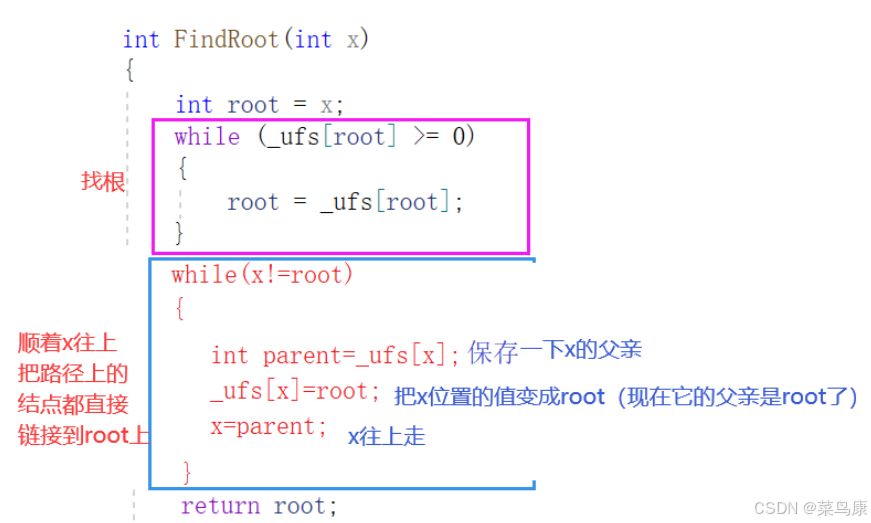
我们的思想是这样的:如果当前位置的值是负数,那就是根了;如果不是负数,顺着父结点往上找就可以了(不是负数的话存的就是父结点的下标),遇到负数就是根了
int FindRoot(int x){int root = x;while (_ufs[root] >= 0){root = _ufs[root];}3、合并
如果是两个单个元素的集合合并可以直接合(因为可以认为它们自己就是根),但是如果是两个多个元素的集合就不能直接合并,而是要找到两个根,把两个根进行合并 但是找到根之后我们要判断一下这两个根一样不一样,一样的话就没必要合并了(证明它们俩本来就在一个集合里或者是同一个值) 然后不同的话就进行合并
void Union(int x1, int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);// 如果本身就在一个集合就没必要合并了if (root1 == root2)return;// 控制数据量小的往大的集合合并if (abs(_ufs[root1]) < abs(_ufs[root2]))swap(root1, root2);_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}4、判断两个单个元素是否在一个集合里
判断这两个值所在集合的根一不一样就行了,一样就在一个集合,不一样就不在:
bool InSet(int x1, int x2){return FindRoot(x1) == FindRoot(x2);}5、并查集中集合个数
遍历数组统计一下有几个负数就有几个集合
size_t SetSize(){size_t size = 0;for (size_t i = 0; i < _ufs.size(); ++i){if (_ufs[i] < 0){++size;}}return size;}四、并查集的优化
1、优化一 高度优化
考虑下面两种情况下的找根效率
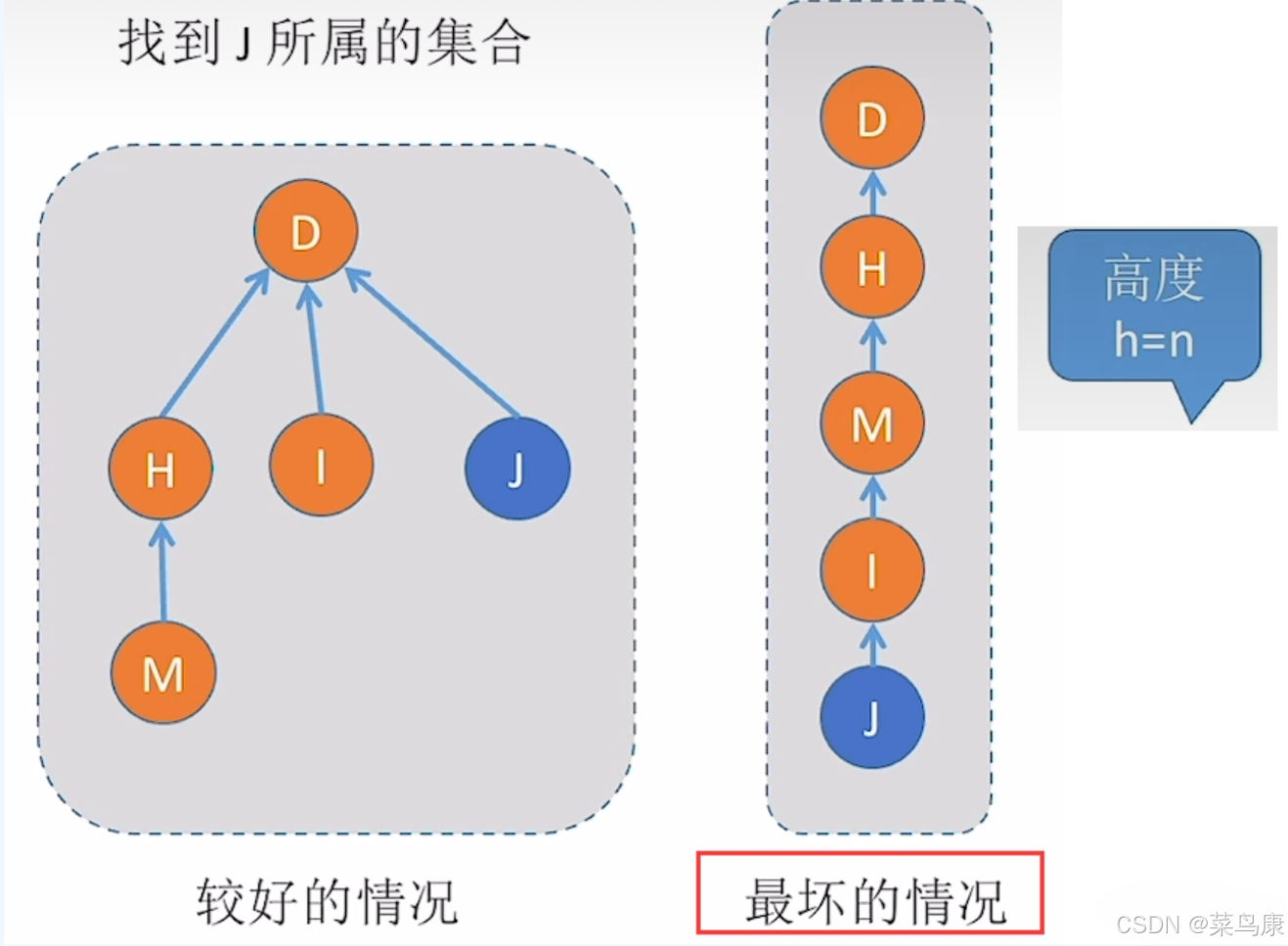
我们知道找根的效率是跟树的高度相关的,树越高效率越低。那么我们要做的第一步优化就是在两个集合合并的时候,将两棵树在合并的时候尽量使得其高度降低。
考虑每次合并的时候,让小树(结点数量小的树)合并到大树(结点数量多的树)上面。 如何获取结点的数量:根结点对应下标位置存的数据的绝对值就是此树结点的数量。

2、优化二 压缩路径
其实我们平时写都不太需要考虑这个东西,除非数据量特别大的时候,可能有些路径会比较长,导致效率变慢,这时候可以考虑进行一下压缩。
压缩呢其实就是在FindRoot这里面进行一些操作,举个例子简单给大家说一说:
比如如下情况
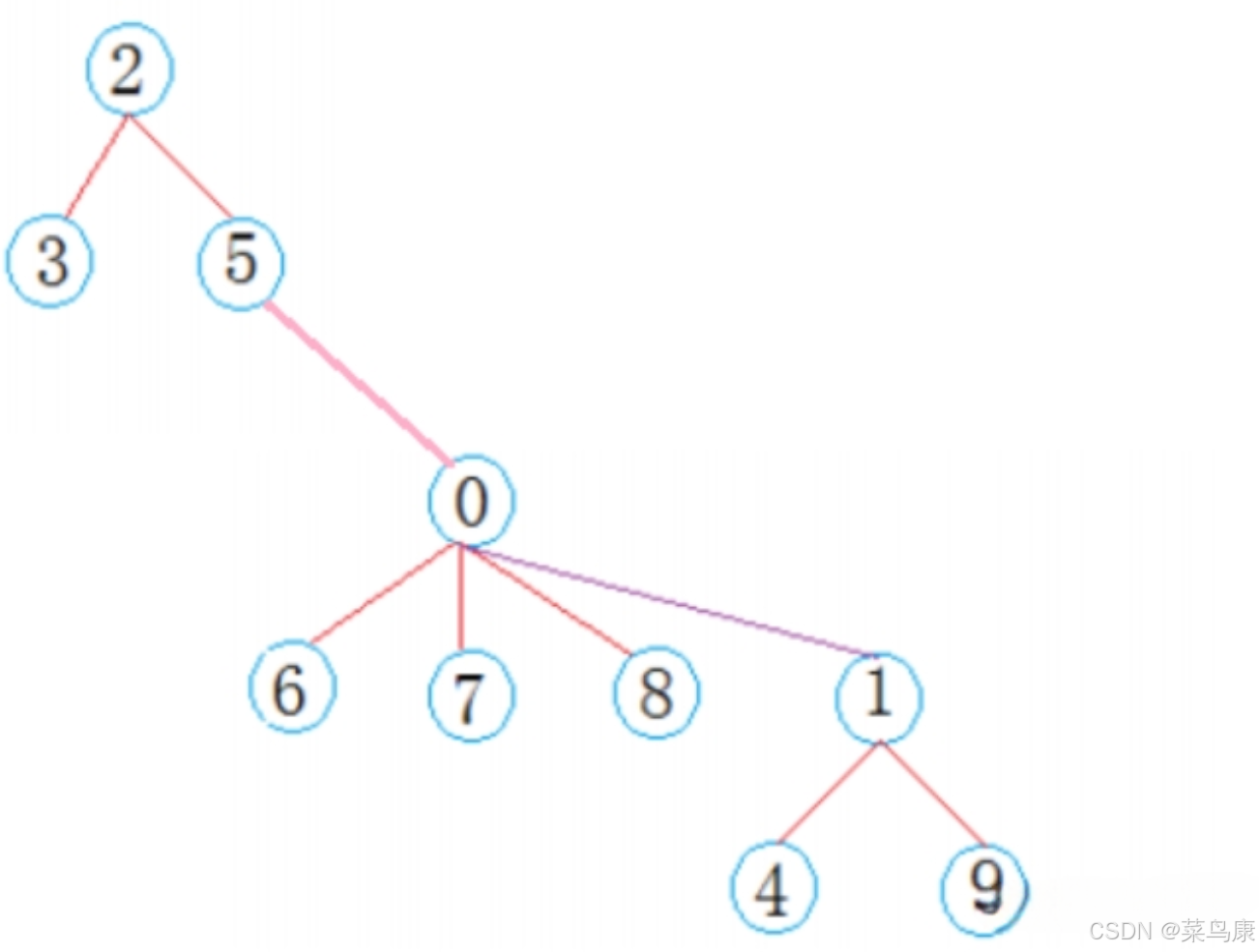
压缩的话就是查找谁就去压缩哪条路径。 比如Find 3的话,那里面判断一下,3的父亲直接就是2,就一层,那就不需要压缩。 再比如,查找6

那最后发现它返回的root是2,但是6直接的上一层的父亲并不是2, 那说明它们之间有间隔层,那就可以对这条路径压缩一下。 可以直接把6变成2的孩子,那后续再查找6的话就快了。 然后也可以直接把6的上一层父亲,0直接变成2的孩子
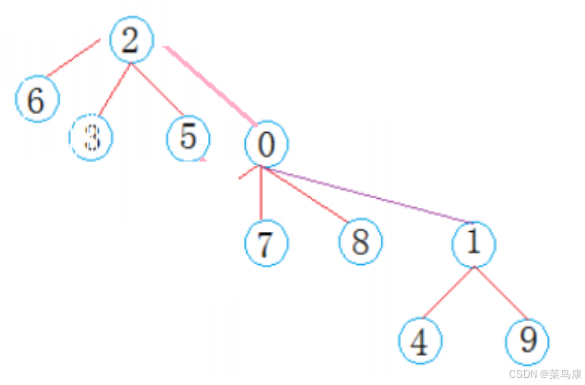
所以我们这样是边找边压缩,比如后面再找9的话,就可以再把9变成2的孩子,然后顺着这条路径再把1变成2的孩子(如果更长的情况就一直往上就行了) 就是在FindRoot里面再加一个压缩路径的代码,其实就是先找到根结点,然后把这条查找路径上所有的结点都直接链接到根结点上。在数据量比较小的情况下,所有路径都比较短的时候就完全没有必要做这个事情。
五、源码
#pragma once
#include <vector>
#include <map>//template<class T>
//class UnionFindSet
//{
//public:
// UnionFindSet(const T* a, size_t n)
// {
// for (size_t i = 0; i < n; ++i)
// {
// _a.push_back(a[i]);
// _indexMap[a[i]] = i;
// }
// }
//private:
// vector<T> _a; // 编号找人
// map<T, int> _indexMap; // 人找编号
//};class UnionFindSet
{
public:UnionFindSet(size_t n):_ufs(n, -1){}void Union(int x1, int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);// 如果本身就在一个集合就没必要合并了if (root1 == root2)return;// 控制数据量小的往大的集合合并if (abs(_ufs[root1]) < abs(_ufs[root2]))swap(root1, root2);_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}int FindRoot(int x){int root = x;while (_ufs[root] >= 0){root = _ufs[root];}// 路径压缩while (_ufs[x] >= 0){int parent = _ufs[x];_ufs[x] = root;x = parent;}return root;}bool InSet(int x1, int x2){return FindRoot(x1) == FindRoot(x2);}size_t SetSize(){size_t size = 0;for (size_t i = 0; i < _ufs.size(); ++i){if (_ufs[i] < 0){++size;}}return size;}private:vector<int> _ufs;
};void TestUnionFindSet()
{UnionFindSet ufs(10);ufs.Union(8, 9);ufs.Union(7, 8);ufs.Union(6, 7);ufs.Union(5, 6);ufs.Union(4, 5);ufs.FindRoot(6);ufs.FindRoot(9);
}六、总结
并查集一般可以解决一下问题:
- 查找元素属于哪个集合(找根) 沿着数组表示的树形关系往上一直找到根(即:树中中元素为负数的位置)
- 查看两个元素是否属于同一个集合沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在
- 将两个集合归并成一个集合
- 集合的个数遍历数组,数组中元素为负数的个数即为集合的个数
为什么并查集不可替代?
假设有 N 个元素(如网络节点、社交用户、像素等),需要支持:
- 查询:判断两个元素是否连通(属于同一集合)
- 合并:连接两个元素(合并两个集合)
使用传统数据结构时:
- 数组/链表:查询需 O(N),合并需 O(N)
- 平衡树:查询需 O(logN),合并需 O(N)(需重建树)
- 邻接矩阵:空间 O(N²),不适用于大规模数据
当 N 很大且操作频繁时(如百万级元素+千万级操作),这些方法效率过低。
当问题具有以下特征时,并查集是最佳选择:
- 动态连接:连接关系随时间变化
- 频繁查询:需要高速连通性判断
- 大规模数据:元素数量巨大(>10⁶)
- 无需完整路径:只需判断是否连通,不需具体路径
感谢阅读!