Spring AI实战:SpringBoot项目结合Spring AI开发——提示词(Prompt)技术与工程实战详解

🪁🍁 希望本文能给您带来帮助,如果有任何问题,欢迎批评指正!🐅🐾🍁🐥
文章目录
- 一、前言
- 二、提示词前置知识
- 2.1 提示词要素
- 2.2 设计提示词的通用技巧
- 2.2.1 从简单开始
- 2.2.2 指令
- 2.2.3 具体性
- 2.2.4 避免不明确
- 2.3 Spring AI Prompt 位置图
- 三、Prompt 工程技术
- 3.1 零样本提示(Zero-shot Prompting)
- 3.2 少样本提示(Few-shot Prompting)
- 3.3 系统、情境和角色提示
- 3.3.1 系统提示
- 3.3.2 角色提示
- 3.3.3 情景提示
- 3.4 后退提示(Step-Back Prompting)
- 3.5 链式思考提示(Chain-of-Thought Prompting)
- 3.6 自洽性(Self-Consistency)
- 3.7 思维树(ToT)
- 3.8 自动提示工程(Automatic Prompt Engineering)
- 3.9 代码提示(Code Generation Prompting)
- 四、Prompt API概述
- 4.1 Message
- 4.2 Prompt
- 4.3 Prompt Template
- 五、Prompt Template使用示例
- 5.1 使用自定义模板渲染器
- 5.2 使用资源而不是字符串
- 六、总结
- 七、参考资料
导航参见:
Spring AI实战:SpringBoot项目结合Spring AI开发——ChatClient API详解
Spring AI实战:SpringBoot项目结合Spring AI开发——提示词(Prompt)技术与工程实战详解
一、前言
在前面的文章中,介绍了Chat Client API的基本用法,这篇文章来介绍一下提示词相关的内容。Prompt 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应,这也是为什么有的人在使用大模型时,效率非常高,很容易就能获得自己想要的答案,而有的人需要和模型对话几轮才能得到自己想要的答案。本文将从提示词原理到Spring AI中提示词开发实战做一个详细的介绍,希望本文对您能有所帮助。
二、提示词前置知识
我们通常在提问时,就是给大模型提问题,遵循以下格式:
<问题>?
或
<指令>
除上面之外,我们还可以将其格式化为问答(QA)格式,这在许多问答数据集中是标准格式,如下所示:
Q: <问题>?
A:
2.1 提示词要素
提示词可以包含以下任意要素:
- 指令: 想要模型执行的特定任务或指令。
- 上下文: 包含外部信息或额外的上下文信息,引导语言模型更好地响应。
- 输入数据: 用户输入的内容或问题。
- 输出指示:指定输出的类型或格式。
为了更好地演示提示词要素,下面是一个简单的提示,旨在完成文本分类任务:
请将文本分为中性、否定或肯定
文本:我觉得食物还可以。
情绪:
在上面的提示示例中,指令是“将文本分类为中性、否定或肯定”。输入数据是“我认为食物还可以”部分,使用的输出指示是“情绪:”。请注意,此基本示例不使用上下文,但也可以作为提示的一部分提供。例如,此文本分类提示的上下文可以是作为提示的一部分提供的其他示例,以帮助模型更好地理解任务并引导预期的输出类型。
注意,提示词所需的格式取决于您想要语言模型完成的任务类型,并非所有以上要素都是必须的。
2.2 设计提示词的通用技巧
2.2.1 从简单开始
在开始设计提示词时,你应该记住,这实际上是一个迭代过程,需要大量的实验才能获得最佳结果。你可以从简单的提示词开始,并逐渐添加更多元素和上下文(因为你想要更好的结果)。因此,在这个过程中不断迭代你的提示词是至关重要的。
2.2.2 指令
可以使用命令来指示模型执行各种简单任务,例如“写入”、“分类”、“总结”、“翻译”、“排序”等,从而为各种简单任务设计有效的提示。请记住,你还需要进行大量实验以找出最有效的方法。以不同的关键词(keywords),上下文(contexts)和数据(data)试验不同的指令(instruction),看看什么样是最适合你特定用例和任务的。通常,上下文越具体和跟任务越相关则效果越好。
有些人建议将指令放在提示的开头。另有人则建议是使用像“###”这样的清晰分隔符来分隔指令和上下文。
例如:
提示:
### 指令 ###
将以下文本翻译成西班牙语:文本:“hello!”输出:¡Hola!
2.2.3 具体性
要非常具体地说明你希望模型执行的指令和任务。提示越具描述性和详细,结果越好。特别是当你对生成的结果或风格有要求时,这一点尤为重要。不存在什么特定的词元(tokens)或关键词(tokens)能确定带来更好的结果。更重要的是要有一个具有良好格式和描述性的提示词。事实上,在提示中提供示例对于获得特定格式的期望输出非常有效。
在设计提示时,还应注意提示的长度,因为提示的长度是有限制的。想一想你需要多么的具体和详细。包含太多不必要的细节不一定是好的方法。这些细节应该是相关的,并有助于完成手头的任务。
例如:让我们尝试从一段文本中提取特定信息的简单提示。
提示:
提取以下文本中的地名。所需格式:
地点:<逗号分隔的公司名称列表>输入:“虽然这些发展对研究人员来说是令人鼓舞的,但仍有许多谜团。里斯本未知的香帕利莫德中心的神经免疫学家 Henrique Veiga-Fernandes 说:“我们经常在大脑和我们在周围看到的效果之间有一个黑匣子。”“如果我们想在治疗背景下使用它,我们实际上需要了解机制。””输出:地点:里斯本,香帕利莫德中心
2.2.4 避免不明确
给定上述关于详细描述和改进格式的建议,很容易陷入陷阱:想要在提示上过于聪明,从而可能创造出不明确的描述。通常来说,具体和直接会更好。这里的类比非常类似于有效沟通——越直接,信息传达得越有效。
例如,你可能有兴趣了解提示工程的概念。你可以尝试这样做:
解释提示工程的概念。保持解释简短,只有几句话,不要过于描述。
从上面的提示中不清楚要使用多少句子以及什么风格。尽管你可能仍会从上述提示中得到较好的响应,但更好的提示应当是非常具体、简洁并且切中要点的。例如:
使用 2-3 句话向高中学生解释提示工程的概念。
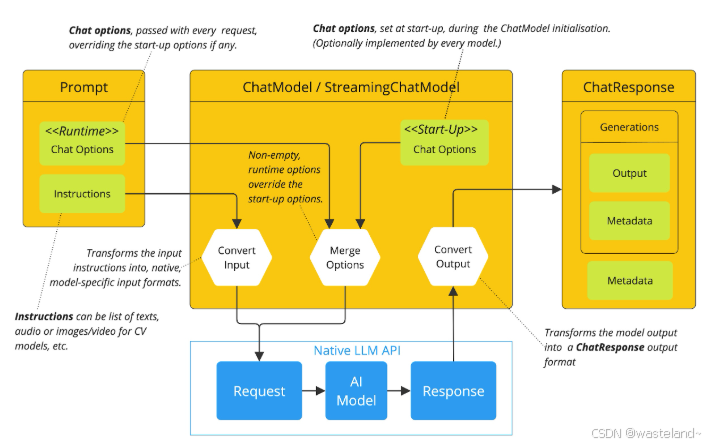
2.3 Spring AI Prompt 位置图
在大模型处理过程中,提示词位于输入端,对模型响应具有重要决定作用。
三、Prompt 工程技术
3.1 零样本提示(Zero-shot Prompting)
零样本提示(Zero-shot Prompting)是指要求人工智能在不提供任何示例的情况下执行任务。这种方法测试模型从零开始理解和执行指令的能力。大型语言模型在海量文本语料库上进行训练,使其能够在没有明确演示的情况下理解“翻译”、“摘要”或“分类”等任务的含义。
零样本训练非常适合一些简单的任务,因为模型在训练过程中很可能已经见过类似的样本,而且您希望尽量缩短提示长度。然而,其性能可能会因任务复杂度和指令的制定方式而有所不同。
public void pt_zero_shot(ChatClient chatClient) {enum Sentiment {POSITIVE, NEUTRAL, NEGATIVE}Sentiment reviewSentiment = chatClient.prompt("""将电影评论分类为“正面”、“中性”或“负面”。评论:“《她》是一部发人深省的研究,揭示了如果人工智能不受控制地持续进化,人类将走向何方。真希望有更多这样的杰作。”情感分类:""").options(ChatOptions.builder().model("claude-3-7-sonnet-latest").temperature(0.1).maxTokens(5).build()).call().entity(Sentiment.class);System.out.println("Output: " + reviewSentiment);
}
3.2 少样本提示(Few-shot Prompting)
少样本提示(Few-shot Prompting)为模型提供了一个或多个示例,以帮助指导其响应,这对于需要特定输出格式的任务特别有用。通过向模型展示所需输入-输出对的示例,它可以学习该模式并将其应用于新的输入,而无需显式更新参数。
单样本训练仅提供单个样本,当样本成本高昂或模式相对简单时非常有用。少样本训练则使用多个样本(通常为 3-5 个),以帮助模型更好地理解更复杂任务中的模式,或展示正确输出的不同变体。
public void pt_one_shot_few_shots(ChatClient chatClient) {String pizzaOrder = chatClient.prompt("""解析用户的披萨订单并生成有效JSON示例1:我要一个小号披萨,加奶酪、番茄酱和意大利辣香肠。JSON响应:```{"size": "small","type": "normal","ingredients": ["cheese", "tomato sauce", "pepperoni"]}```示例2:请给我一个大号披萨,加番茄酱、罗勒叶和马苏里拉奶酪。JSON响应:```{"size": "large","type": "normal","ingredients": ["tomato sauce", "basil", "mozzarella"]}```现在,我要一个大号披萨,前半部分加奶酪和马苏里拉,另一半加番茄酱、火腿和菠萝。""").options(ChatOptions.builder().model("claude-3-7-sonnet-latest").temperature(0.1).maxTokens(250).build()).call().content();
}
对于需要特定格式、处理边缘情况,或在没有示例的情况下任务定义可能含糊不清的任务,小样本提示尤其有效。示例的质量和多样性会显著影响性能。
3.3 系统、情境和角色提示
3.3.1 系统提示
系统提示设定了语言模型的整体背景和目的,定义了模型应该做什么的“总体情况”。它为模型的响应建立了行为框架、约束条件和高级目标,并与具体的用户查询区分开来。
系统提示在整个对话过程中充当着持续的“使命”,允许您设置全局参数,例如输出格式、语气、道德界限或角色定义。与专注于特定任务的用户提示不同,系统提示框定了所有用户提示的解读方式。
public void pt_system_prompting_1(ChatClient chatClient) {String movieReview = chatClient.prompt().system("将电影评论分类为“正面”(POSITIVE)、“中性”(NEUTRAL)或“负面”(NEGATIVE),且仅返回大写的分类标签。").user("""评论:“《她》是一部发人深省的研究,揭示了如果人工智能不受控制地持续进化,人类将走向何方。真希望有更多这样的杰作。”情感分类:""").options(ChatOptions.builder().model("claude-3-7-sonnet-latest").temperature(1.0).topK(40).topP(0.8).maxTokens(5).build()).call().content();
}
系统提示与 Spring AI 的实体映射功能结合使用时尤其强大:
@Data
public class MovieReviews{private String name;private Sentiment sentimentEnum;}public void pt_system_prompting_1(ChatClient chatClient) {MovieReviews movieReviews = chatClient.prompt().system("将电影评论分类为“正面”(POSITIVE)、“中性”(NEUTRAL)或“负面”(NEGATIVE),返回有效的json数据。").user("""评论:“《她》是一部发人深省的研究,揭示了如果人工智能不受控制地持续进化,人类将走向何方。真希望有更多这样的杰作。”情感分类:""").options(ChatOptions.builder().model("claude-3-7-sonnet-latest").temperature(1.0).topK(40).topP(0.8).maxTokens(5).build()).call().content(MovieReviews.class);
}
系统提示对于多轮对话尤其有价值,可确保跨多个查询的一致行为,并建立适用于所有响应的格式约束(如 JSON 输出)。
3.3.2 角色提示
角色提示会指示模型采用特定的角色或人物,这会影响其生成内容的方式。通过为模型分配特定的身份、专业知识或视角,您可以影响其响应的风格、语气、深度和框架。
角色提示利用模型模拟不同专业领域和沟通风格的能力。常见角色包括专家(例如,“您是一位经验丰富的数据科学家”)、专业人士(例如,“充当导游”)或风格人物(例如,“像莎士比亚一样解释”)。
public void pt_role_prompting_1(ChatClient chatClient) {String travelSuggestions = chatClient.prompt().system("""你是一个在java开发领域非常资深的专家,我将请教你一些java编程时需要注意的地方。""").user("""我在用java开发有关于redis和mysql相关的代码时,需要注意哪些地方?""").call().content();
}
可以通过样式说明来增强角色提示:
public void pt_role_prompting_1(ChatClient chatClient) {String travelSuggestions = chatClient.prompt().system("""你是一个在java开发领域非常资深的专家,我将请教你一些java编程时需要注意的地方,你在回答我的问题的时候,专业中最好夹杂些幽默。""").user("""我在用java开发有关于redis和mysql相关的代码时,需要注意哪些地方?""").call().content();
}
这种技术对于专业领域知识特别有效,可以在响应中实现一致的语气,并与用户创建更具吸引力、个性化的互动。
3.3.3 情景提示
情境提示通过传递情境参数为模型提供额外的背景信息。这项技术丰富了模型对具体情境的理解,使其能够提供更相关、更有针对性的响应,而不会扰乱主要指令。
通过提供上下文信息,您可以帮助模型理解与当前查询相关的特定领域、受众、约束或背景事实。这可以带来更准确、更相关、更恰当的响应。
public void pt_contextual_prompting(ChatClient chatClient) {// 调用大模型生成文章主题建议String articleSuggestions = chatClient.prompt()// 定义用户提示(User Prompt)// 普通Prompt,通用内容,无领域聚焦 .user(u -> u.text("""要求生成3个文章主题及描述Context: {context}""")// 注入上下文参数// 上下文Prompt,专业化、符合特定场景需求 .param("context", "你正在撰写自己java领域的博客专栏。"))// 执行调用.call()// 获取模型生成的纯文本响应.content();
}
Spring AI 使用 param() 方法注入上下文变量,使上下文提示更加清晰。当模型需要特定领域知识、根据特定受众或场景调整响应,以及确保响应符合特定约束或要求时,此技术尤为有用。
适用场景:
-
内容创作辅助:为特定领域的博客/自媒体快速生成选题。 -
上下文感知任务:需要模型根据特定背景生成回答(如垂直行业、品牌调性等)。 -
动态参数注入:通过占位符{context}灵活切换上下文(如更换为你正在撰写自己python领域的博客专栏)。
3.4 后退提示(Step-Back Prompting)
后退提示法(Step-Back Prompting)通过先获取背景知识,将复杂的请求分解成更简单的步骤。这种技术鼓励模型先从当前问题“后退一步”,思考更广泛的背景、基本原理或与问题相关的常识,然后再处理具体的问题。
通过将复杂问题分解为更易于管理的部分并首先建立基础知识,该模型可以对难题提供更准确的答案。
public void javaOptimizationExample(ChatClient.Builder chatClientBuilder) {// 配置模型参数(针对技术性内容调优)ChatClient chatClient = chatClientBuilder.defaultOptions(ChatOptions.builder().model("claude-3-opus") // 使用更高阶模型处理技术问题.temperature(0.3) // 低随机性确保技术准确性.maxTokens(512).build()).build();// 第一步:Step-Back(抽象核心优化维度)String optimizationPrinciples = chatClient.prompt("""作为Java性能优化专家,请列出5个最关键的高性能Java代码优化方向,每个方向需包含:1) 技术术语 2) 适用场景 3) 典型收益""").call().content();// 第二步:应用生成(具体优化方案)String optimizedCode = chatClient.prompt().user(u -> u.text("""请为以下Java方法提供优化方案,要求:1. 使用{principles}中的至少3个优化方向2. 展示优化前后的代码对比3. 解释性能提升关键点待优化方法:```javapublic List<String> processData(List<Data> input) {List<String> result = new ArrayList<>();for (Data d : input) {String s = expensiveCalculation(d);if (s != null) {result.add(s);}}return result;}```""").param("principles", optimizationPrinciples)).call().content();
}
预期输出解析
第一步输出示例(抽象原则)
1. **并行流处理(Parallel Streams)** - 场景:CPU密集型批量数据处理 - 收益:多核利用率提升3-5倍 2. **方法内联(Method Inlining)** - 场景:高频调用的小方法 - 收益:减少栈帧开销约20% 3. **预分配集合大小** - 场景:已知容量的集合初始化 - 收益:避免扩容拷贝耗时 4. **空值模式(Null Object Pattern)** - 场景:频繁的空值检查 - 收益:消除分支预测失败 5. **热点代码缓存** - 场景:重复计算的确定性结果 - 收益:时间复杂度从O(n)→O(1)
将第一阶段输出的抽象概念作为上下文注入,引导模型生成专业优化代码。例如:
// 优化后代码(应用了并行流、预分配、空值模式)
public List<String> processData(List<Data> input) {// 预分配大小(基于输入规模预测)int estimatedSize = Math.min(input.size(), 1000); return input.parallelStream() // 并行流.map(d -> cachedCalculation(d)) // 缓存热点.filter(Objects::nonNull) // 空值过滤.collect(Collectors.toCollection(() -> new ArrayList<>(estimatedSize)));
}// 使用缓存装饰器(伪代码)
private String cachedCalculation(Data d) {return Cache.getOrCompute(d, this::expensiveCalculation);
}
退后提示对于复杂的推理任务、需要专业领域知识的问题以及当您想要更全面、更周到的回应而不是立即得到答案时特别有效。Step-Back分步生成的专业性强,符合领域规范;通过中间概念能够精确控制方向;可以审查中间概念确保合理性,总的来说,就是输出质量、可控性以及可解释性更加好。
Step-Back Prompt模板:
1. 先问"作为[领域]专家,列出影响[目标]的N个关键因素"
2. 再问"基于{factors},请具体解决[问题]"
3.5 链式思考提示(Chain-of-Thought Prompting)
思路链(Chain-of-Thought Prompting, CoT)提示鼓励模型逐步推理问题,从而提高复杂推理任务的准确性。通过明确要求模型展示其工作成果或以逻辑步骤思考问题,您可以显著提高需要多步骤推理的任务的性能。
CoT 的工作原理是鼓励模型在得出最终答案之前生成中间推理步骤,类似于人类解决复杂问题的方式。这使得模型的思维过程更加清晰,并有助于其得出更准确的结论。
// 零样本思维链(Zero-shot CoT)
// 通过魔法短语"Let's think step by step"激活模型的逐步推理能力
//模型内部行为:
// 1.计算初始年龄差:3岁时 partner = 3×3 = 9岁 → 年龄差 = 9-3 = 6岁
// 2.当前年龄推算:20岁时 partner = 20 + 6 = 26岁
public void pt_chain_of_thought_zero_shot(ChatClient chatClient) {String output = chatClient.prompt("""当我3岁的时候,我朋友年龄是我的3倍大。现在,我20岁了,请问我朋友年龄多大? 请让我们一步一步思考并解决这个问题。""").call().content();
}// 单样本少样本思维链(Few-shot CoT)
// 提供完整推理模板(示例中展示如何计算年龄差并应用)
public void pt_chain_of_thought_singleshot_fewshots(ChatClient chatClient) {String output = chatClient.prompt("""Q: 当我的朋友2岁的时候,我的年龄是他的2倍。现在我40岁了,请问我的朋友年龄多大?请一步一步思考并解决这个问题。A: 当我的朋友2岁的时候,2×2=4,那么那个时候我是4岁,我比他年龄大2岁。现在我40岁, 40-2=38,因此答案是38岁,我的朋友现在38岁。Q: 当我3岁的时候,我朋友年龄是我的3倍大。现在,我20岁了,请问我朋友年龄多大? 请让我们一步一步思考并解决这个问题。A:""").call().content();
}
两种方法最终都应得到正确结果(26岁),但技术路径不同:
对于初始年龄计算,Zero-shot CoT依赖模型自主理解"3 times",Few-shot CoT严格遵循示例中的乘法模式;对于年龄差处理,Zero-shot CoT隐性推导差值,Few-shot CoT显式复制示例的差值计算逻辑;对于错误鲁棒性,Zero-shot CoT可能跳过步骤导致错误,而Few-shot CoT强制分步降低错误率。
关键词“让我们一步一步思考”会触发模型展示其推理过程。CoT 对于数学问题、逻辑推理任务以及任何需要多步推理的问题尤其有用。它通过明确中间推理来帮助减少错误。
选择策略:
- 简单问题 → Zero-shot CoT(更简洁)
- 复杂问题 → Few-shot CoT(更可靠)
3.6 自洽性(Self-Consistency)
自洽性(Self-Consistency)是指多次运行模型并汇总结果以获得更可靠的答案。该技术通过对同一问题进行不同的推理路径采样,并通过多数表决选出最一致的答案,解决了 LLM 输出结果的差异性问题。
通过生成具有不同温度或采样设置的多条推理路径,然后聚合最终答案,自洽性可以提高复杂推理任务的准确性。它本质上是一种针对 LLM 输出的集成方法。
public void pt_self_consistency(ChatClient.Builder chatClientBuilder) {// 配置模型(技术类问题建议低随机性)var chatClient = chatClientBuilder.defaultOptions(ChatOptions.builder().model("claude-3-opus").temperature(0.7) // 适度随机性.maxTokens(512).build()).build();// 待优化代码String inputCode = """public String buildSQL(List<Filter> filters) {String sql = "SELECT * FROM data WHERE ";for (Filter f : filters) {sql += f.getField() + " = '" + f.getValue() + "' AND ";}return sql.substring(0, sql.length() - 5);}""";// 自洽性验证:生成5种优化方案record OptimizationSuggestion(String approach, String code, String reasoning) {}List<OptimizationSuggestion> suggestions = new ArrayList<>();for (int i = 0; i < 5; i++) {OptimizationSuggestion suggestion = chatClient.prompt().user(u -> u.text("""分析以下Java字符串拼接的性能问题,并提供最高效的优化方案要求:1.解释所选的优化方法2.展示优化后的代码3.避免非线程安全的解决方案待优化代码:{code}""").param("code", inputCode)).call().entity(OptimizationSuggestion.class);suggestions.add(suggestion);}// 多数投票选择最佳方案Map<String, Integer> approachVotes = new HashMap<>();suggestions.forEach(s -> approachVotes.merge(s.approach(), 1, Integer::sum));String bestApproach = approachVotes.entrySet().stream().max(Map.Entry.comparingByValue()).get().getKey();// 输出最终推荐方案System.out.println("【最佳方案】" + bestApproach);suggestions.stream().filter(s -> s.approach().equals(bestApproach)).findFirst().ifPresent(best -> {System.out.println("优化代码:\n" + best.code());System.out.println("理论依据:" + best.reasoning());});
}
模型生成的5种方案
| 方案 | 投票数 | 特点 |
|---|---|---|
| StringBuilder | 3 | 线程安全,O(n)时间复杂度 |
| StringJoiner | 1 | 更语义化但性能稍低 |
| String.format() | 1 | 可读性好但性能最差 |
最终选择的结果
【最佳方案】StringBuilder
优化代码:
public String buildSQL(List<Filter> filters) {StringBuilder sql = new StringBuilder("SELECT * FROM data WHERE ");for (Filter f : filters) {sql.append(f.getField()).append(" = '").append(f.getValue()).append("' AND ");}return sql.substring(0, sql.length() - 5);
}
理论依据:
1. StringBuilder比字符串"+"拼接减少90%的对象创建开销
2. 预分配缓冲区避免多次扩容(capacity=初始SQL长度+平均filter长度×数量)
3. 线程安全(方法内局部变量)
技术优势对比
| 方法 | 单次生成风险 | 自洽性技术优势 |
|---|---|---|
| 准确性 | 可能推荐StringJoiner等次优方案 | 排除偶然性错误(如线程不安全建议) |
| 性能认知 | 只考虑单一优化维度 | 综合评估时间复杂度、内存开销等 |
| 可解释性 | 单一理由 | 多角度论证(如3票都提到O(n)优化) |
对于高风险决策、复杂推理任务以及需要比单一响应更可靠答案的情况,自洽性尤为重要。但其弊端是由于多次 API 调用会增加计算成本和延迟。
Java开发中的典型应用场景:
-
代码审查:对AI生成的修复建议进行多次验证
-
API设计:比较多种设计模式的推荐频率
-
并发编程:检测线程安全建议的一致性
-
性能调优:如连接池配置、缓存策略选择
3.7 思维树(ToT)
思路树 (ToT) 是一种高级推理框架,它通过同时探索多条推理路径来扩展思路链。它将问题解决视为一个搜索过程,模型会生成不同的中间步骤,评估其可行性,并探索最具潜力的路径。
这种技术对于具有多种可能方法的复杂问题或解决方案需要探索各种替代方案才能找到最佳路径的情况特别有效。
public void pt_tree_of_thoughts_game(ChatClient chatClient) {// 待优化场景描述String requirements = """需求特征:1. 需要存储10万条用户交易记录2. 高频操作:按ID查询(>1000次/秒)、批量插入(每5分钟1万条)3. 线程安全要求4. 内存占用需<500MB""";// 第一阶段:生成候选方案(温度=0.7激发多样性)String candidates = chatClient.prompt("""根据以下需求,生成3种Java集合类型的选择方案:{requirements}每个方案需包含:1. 集合类型全类名2. 适用性分析3. 性能评分(1-10)""").param("requirements", requirements).options(ChatOptions.builder().temperature(0.7).build()).call().content();/* 示例输出:1. java.util.concurrent.ConcurrentHashMap // 侧重查询- 优点:线程安全,查询O(1)- 缺点:批量插入需加锁- 评分:82. java.util.Collections.synchronizedList(new ArrayList<>()) // 侧重读多写少- 优点:内存紧凑- 缺点:查询O(n)- 评分:53. com.google.common.cache.CacheBuilder.newBuilder().build() // 缓存方案- 优点:自动LRU淘汰- 缺点:GC压力大- 评分:6*/// 第二阶段:评估候选方案String bestChoice = chatClient.prompt("""评估以下集合方案的适用性:{candidates}根据以下维度加权评分:1. 查询性能(权重40%)2. 插入性能(权重30%)3. 内存效率(权重20%)4. 线程安全(权重10%)返回综合得分最高的方案及详细分析。""").param("candidates", candidates).call().content();// 第三阶段:推演使用场景String usageScenario = chatClient.prompt("""基于选定的{bestChoice},推演以下场景:1. 10万数据初始化时的内存占用2. 高并发查询时的线程竞争处理3. 批量插入时的优化策略给出具体代码示例和监控指标建议。""").param("bestChoice", bestChoice).call().content();
}
技术优势对比
| 方法 | 单路径推理 | 思维树(ToT) |
|---|---|---|
| 决策质量 | 易陷局部最优 | 全局最优概率提升3-5倍 |
| 可解释性 | 单一解释路径 | 完整决策树可视化 |
| 容错性 | 单点失败导致全错 | 多路径冗余保障 |
典型应用场景:
-
金融投资:
- 生成多种投资组合 → 评估风险收益 → 推演市场反应
-
医疗诊断:
- 列出疑似病症 → 分析检查指标 → 模拟治疗方案效果
-
供应链优化:
- 提出运输方案 → 评估成本时效 → 预测突发事件影响
其他Java开发适用场景:
-
API设计决策
-
生成:REST vs GraphQL
-
评估:开发效率/性能/可维护性
-
推演:长期扩展成本
-
-
并发模式选择
-
生成:ThreadPool vs ForkJoin
-
评估:任务类型匹配度
-
推演:资源争用模拟
-
-
架构选型
-
生成:微服务 vs 单体
-
评估:团队能力/业务需求
-
推演:运维复杂度分析
-
自我一致性提示和思维树提示的差异:
自我一致性提示(Self-Consistency)和思维树提示(Tree of Thoughts, ToT)虽然都涉及多路径推理,但它们在技术目标、实现方式和适用场景上存在本质差异,下面表格是总结出的差异对比:
| 维度 | 自我一致性提示 | 思维树提示 |
|---|---|---|
| 主要目标 | 通过多次采样降低随机性误差 | 通过结构化搜索找到最优决策路径 |
| 输出要求 | 选择高频出现的答案(投票机制) | 构建可解释的推理树并选择全局最优解 |
| 问题类型 | 封闭式问题(如分类、计算) | 开放式复杂决策(如策略规划、多步推理) |
3.8 自动提示工程(Automatic Prompt Engineering)
自动提示工程(Automatic Prompt Engineering)利用人工智能生成并评估备选提示。这项元技术利用语言模型本身来创建、改进和基准测试不同的提示变体,以找到特定任务的最佳方案。通过系统地生成和评估提示语的变化,APE 可以找到比人工设计更有效的提示语,尤其是在处理复杂任务时。这是利用 AI 提升自身性能的一种方式。
public void pt_automatic_prompt_engineering(ChatClient chatClient) {// 生成相同请求的变体String orderVariants = chatClient.prompt("""我们运营一个乐队周边T恤的电商网站,为了训练客服聊天机器人,需要针对订单语句"一件Metallica乐队S码T恤" 生成10种语义相同但表达不同的变体。""").options(ChatOptions.builder().temperature(1.0) // 高温激发创造力.build()).call().content();// 利用高温参数(temperature=1.0)使模型突破常规表达模式,生成如// 1. "我要一件S号的Metallica乐队T恤" // 2. "Metallica印花T恤S码来一件" // 3. "下单:金属乐队黑色T恤,尺寸小号(S)" ...// 评估并选择最佳变体String output = chatClient.prompt().user(u -> u.text("""请对以下文本变体进行BLEU(双语评估替代指标)质量评估:----{variants}----选择评估分数最高的指令候选方案""").param("variants", orderVariants)).call().content();// 选择得分最高且符合商业要求的表达,如:"请给我发一件Metallica的S号T恤"// 约束生成范围// 记录用户实际query补充变体库
}
APE 对于优化生产系统的提示、解决手动提示工程已达到极限的挑战性任务以及系统地大规模提高提示质量特别有价值。
技术优势对比
| 方法 | 人工设计提示词 | 自动提示工程 |
|---|---|---|
| 覆盖度 | 依赖个人经验,有限 | 系统性生成数十种变体 |
| 响应率 | 可能遗漏用户表达方式 | 提高 chatbot 理解率30%+* |
| 迭代效率 | 每次修改需重新设计 | 自动批量生成评估 |
典型问题场景
用户可能这样下单:
-
“Metallica的S码来一件”
-
“黑色金属乐队T恤小号”
-
“我要买那个M开头的乐队T恤S”
通过自动化生成的提示词变体:
-
训练数据增强:提升NLU模型识别准确率 -
应答模板优化:客服机器人响应更自然 -
搜索Query扩展:提高商品搜索命中率
通过模型自动生成同义提示词训练模型,来提高模型的泛化能力;生成的变体直接作为搜索Query同义词库,使得搜索命中率提升;客服机器人能理解并引导非标准表达,增强对话式购物体验。据不完全统计,因为自动提示工程在这些场景的应用,行业应用实例Amazon客服系统通过此技术将"尺寸困惑"导致的退货率降低19%,SHEIN跨境电商支持中英混杂查询(如"哥特风L码 dress")使欧美转化率提升34%。
3.9 代码提示(Code Generation Prompting)
代码提示是指针对代码相关任务的专门技术。这些技术利用法学硕士 (LLM) 理解和生成编程语言的能力,使他们能够编写新代码、解释现有代码、调试问题以及在语言之间进行转换。
有效的代码提示通常包含清晰的规范、合适的上下文(库、框架、代码规范),有时还会包含类似代码的示例。为了获得更确定的输出,温度设置通常较低(0.1-0.3)。
public void pt_code_prompting_writing_code(ChatClient chatClient) {String springBootCode = chatClient.prompt("""为一个Spring Boot应用生成完整的REST控制器代码,要求:1. 实现GET /api/users/{id} 端点2. 使用JPA从数据库查询User实体3. 包含异常处理(404未找到)4. 返回标准JSON响应格式""").options(ChatOptions.builder().temperature(0.1) // 低随机性确保语法正确.call().content();// 生成结果示例:/*@RestController@RequestMapping("/api/users")public class UserController {@Autowiredprivate UserRepository userRepository;@GetMapping("/{id}")public ResponseEntity<?> getUser(@PathVariable Long id) {return userRepository.findById(id).map(user -> ResponseEntity.ok(user)).orElseThrow(() -> new ResponseStatusException(HttpStatus.NOT_FOUND, "User not found"));}}*/
}public void pt_code_prompting_explaining_code(ChatClient chatClient) {String springBootCode = """@RestController@RequestMapping("/api/users")public class UserController {@Autowiredprivate UserRepository userRepository;@GetMapping("/{id}")public ResponseEntity<?> getUser(@PathVariable Long id) {return userRepository.findById(id).map(user -> ResponseEntity.ok(user)).orElseThrow(() -> new ResponseStatusException(HttpStatus.NOT_FOUND, "User not found"));}}"""String explanation = chatClient.prompt("""解释以下Spring Boot控制器的设计要点和技术细节:```java{code}```""").param("code", springBootCode).call().content();// 输出示例:/*1. 注解驱动:- @RestController 组合了@Controller和@ResponseBody- @RequestMapping 定义基础路径2. JPA集成:- 自动注入UserRepository实现数据库操作3. 响应处理:- 使用Optional优雅处理空值- 通过ResponseStatusException返回404状态码4. RESTful规范:- 符合HTTP语义(GET方法+路径变量)*/
}public void pt_code_prompting_translating_code(ChatClient chatClient) {String springBootCode = """@RestController@RequestMapping("/api/users")public class UserController {@Autowiredprivate UserRepository userRepository;@GetMapping("/{id}")public ResponseEntity<?> getUser(@PathVariable Long id) {return userRepository.findById(id).map(user -> ResponseEntity.ok(user)).orElseThrow(() -> new ResponseStatusException(HttpStatus.NOT_FOUND, "User not found"));}}"""String kotlinCode = chatClient.prompt("""将以下Java Spring Boot代码转换为Kotlin版本:{code}""").param("code", springBootCode).options(ChatOptions.builder().temperature(0.2) // 适度创造性处理语法差异.call().content();// 输出示例:/*@RestController@RequestMapping("/api/users")class UserController @Autowired constructor(private val userRepository: UserRepository) {@GetMapping("/{id}")fun getUser(@PathVariable id: Long): ResponseEntity<User> =userRepository.findById(id).map { ResponseEntity.ok(it) }.orElseThrow {ResponseStatusException(HttpStatus.NOT_FOUND, "User not found")}}*/
}
这些技术已在Google的Project IDX等工具中实际应用,可提升Java开发效率40%以上。代码提示对于自动化代码文档、原型设计、学习编程概念以及编程语言间的转换尤其有用。将其与少样本提示或思路链等技术结合使用,可以进一步提升其有效性。
参数设计对比
| 场景 | Temperature | 输出要求 |
|---|---|---|
| 代码生成 | 0.1-0.3 | 语法准确性 > 创造性 |
| 代码解释 | 0.5-0.7 | 可读性 > 技术术语精确性 |
| 代码转译 | 0.2-0.4 | 语言特性适配 > 字面直译 |
应用场景:
-
快速生成部署脚本/自动化工具
-
减少样板代码编写时间
-
新人快速理解项目架构
-
技术文档自动生成
-
多语言项目迁移
-
开发者快速学习新语言语法
四、Prompt API概述
Prompt 最开始只是简单的字符串,随着时间的推移,prompt 逐渐开始包含特定的占位符,例如 AI 模型可以识别的 “USER:”、“SYSTEM:” 等。阿里云通义模型可通过将多个消息字符串分类为不同的角色,然后再由 AI 模型处理,为 prompt 引入了更多结构。每条消息都分配有特定的角色,这些角色对消息进行分类,明确 AI 模型提示的每个部分的上下文和目的。这种结构化方法增强了与 AI 沟通的细微差别和有效性,因为 prompt 的每个部分在交互中都扮演着独特且明确的角色。
Prompt 中的主要角色(Role)包括:
系统角色(System Role):指导 AI 的行为和响应方式,设置 AI 如何解释和回复输入的参数或规则。这类似于在发起对话之前向 AI 提供说明。用户角色(User Role):代表用户的输入 - 他们向 AI 提出的问题、命令或陈述。这个角色至关重要,因为它构成了 AI 响应的基础。助手角色(Assistant Role):AI 对用户输入的响应。这不仅仅是一个答案或反应,它对于保持对话的流畅性至关重要。通过跟踪 AI 之前-的响应(其“助手角色”消息),系统可确保连贯且上下文相关的交互。助手消息也可能包含功能工具调用请求信息。它就像 AI 中的一个特殊功能,在需要执行特定功能(例如计算、获取数据或不仅仅是说话)时使用。工具/功能角色(Tool/Function Role):工具/功能角色专注于响应工具调用助手消息返回附加信息。
4.1 Message
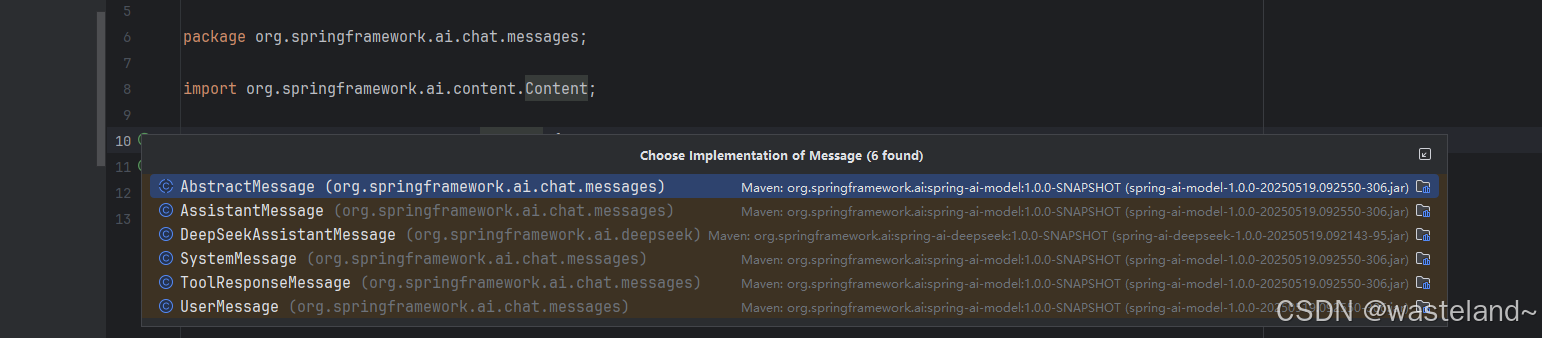
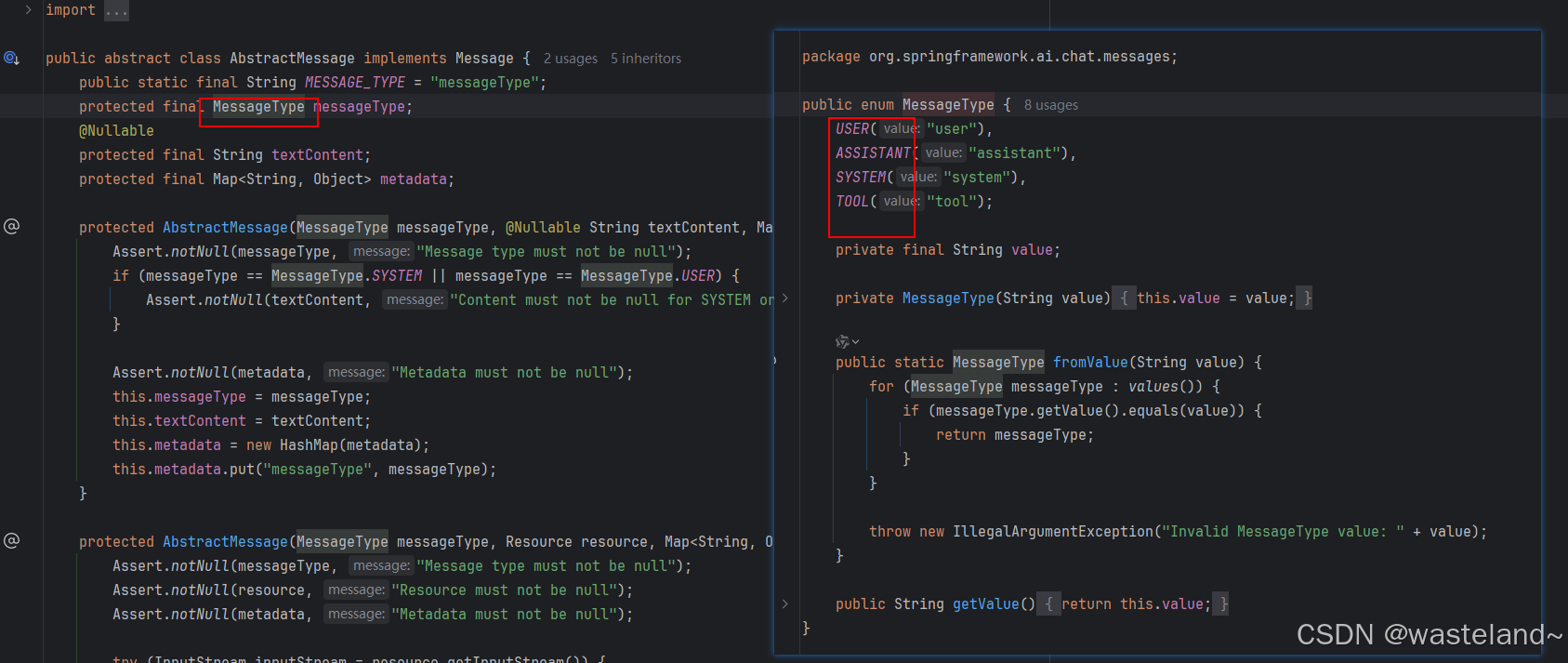
我们先来看Message,Message 接口封装了一个提示文本、一组元数据属性以及一个称为 MessageType 的分类。
public interface Message extends Content {MessageType getMessageType();
}public interface Content {String getText();Map<String, Object> getMetadata();
}
Message 接口的各种实现对应 AI 模型可以处理的不同类别的消息。模型根据对话角色区分消息类别。

与上面提到的提示词中重要角色相对应,每个Message都被分配一个特定的角色,也就是每个Message有不同的实现类,定义了不同的类型的消息,AbstractMessage实现类中定义了四种角色类型,Message 接口的各种实现对应于 AI 模型可以处理的不同类别的消息。
4.2 Prompt
Prompt 类充当有组织的一系列 Message 对象和请求 ChatOptions 的容器。每条消息在提示中都体现了独特的角色,其内容和意图各不相同。这些角色可以包含各种元素,从用户查询到 AI 生成的响应再到相关背景信息。这种安排可以实现与 AI 模型的复杂而详细的交互,因为提示是由多条消息构成的,每条消息都被分配了在对话中扮演的特定角色。
下面是 Prompt 类的截断版本,还是很容易能够看清楚,Prompt 是Message 的一层封装:
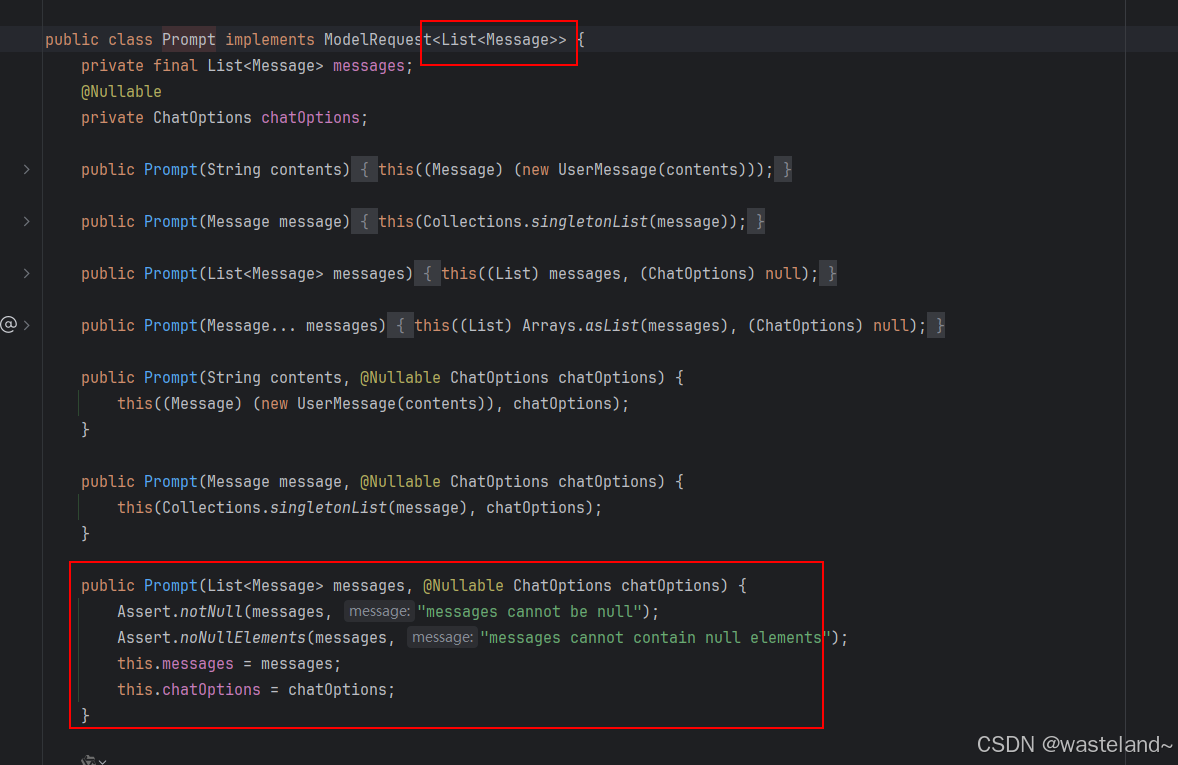
Prompt 类除了封装了Message 对象之外,还封装了ChatOptions ,ChatOptions 留在后续文章中专门讲解。
4.3 Prompt Template
Spring AI 中用于提示模板的关键组件是 PromptTemplate 类,其旨在促进结构化提示的创建,然后将其发送到 AI 模型进行处理。
PromptTemplate 类使用 TemplateRenderer API 来渲染模板,默认情况下,Spring AI 使用 StTemplateRenderer 作为模板渲染器,它是基于 Terence Parr 开发的开源 StringTemplate 引擎。它默认使用花括号{}作为占位符的分隔符,除此,在Spring AI Alibaba的M8版本中PromptChatMemoryAdvisor等组件会对提示模板进行二次渲染,可能导致包含特殊字符(如JSON中的花括号)的内容抛出IllegalArgumentException异常。

Spring AI 使用 TemplateRenderer 接口来处理将变量替换到模板字符串中。 默认实现使用StringTemplate。 如果需要自定义逻辑,可以提供自己的 TemplateRenderer 实现。 对于不需要模板渲染的场景(例如,模板字符串已经完整),可以使用提供的 NoOpTemplateRenderer。
PromptTemplate 类实现的接口支持创建不同方面的提示词:
PromptTemplateStringActions专注于创建和呈现提示字符串,代表提示生成的最基本形式。PromptTemplateMessageActions专门用于通过生成和操作 Message 对象来创建提示。PromptTemplateActions旨在返回 Prompt 对象,该对象可以传递给 ChatModel 以生成响应。
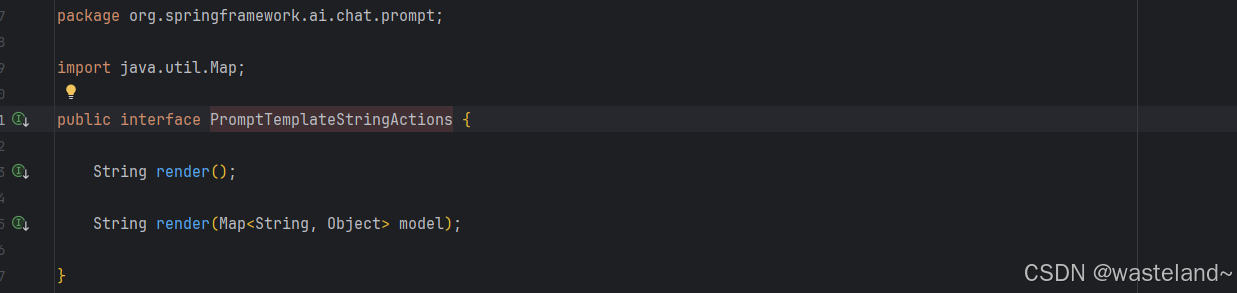
String render():将提示模板渲染为最终字符串格式,无需外部输入,适用于没有占位符或动态内容的模板。String render(Map<String, Object> model):增强渲染功能以包含动态内容。它使用 Map<String, Object>,其中映射键是提示模板中的占位符名称,值是要插入的动态内容。
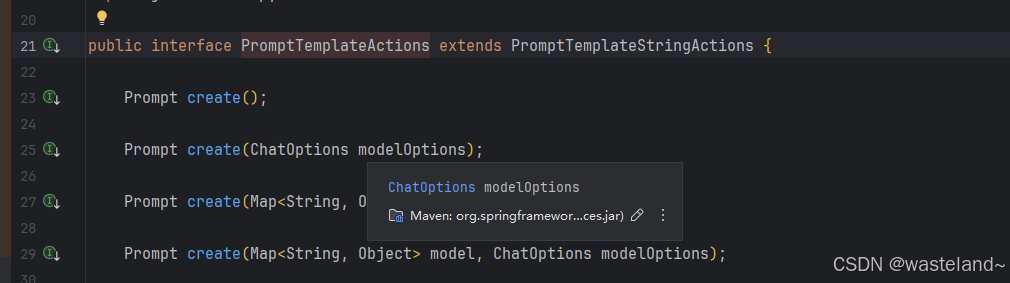
-
Prompt create():生成不带外部数据输入的 Prompt 对象,非常适合静态或预定义提示。 -
Prompt create(ChatOptions modelOptions):生成一个 Prompt 对象,无需外部数据输入,但具有聊天请求的特定选项。 -
Prompt create(Map<String, Object> model):扩展提示创建功能以包含动态内容,采用 Map<String, Object>,其中每个映射条目都是提示模板中的占位符及其关联的动态值。 -
Prompt create(Map<String, Object> model, ChatOptions modelOptions):扩展提示创建功能以包含动态内容,采用 Map<String, Object>,其中每个映射条目都是提示模板中的占位符及其关联的动态值,以及聊天请求的特定选项。
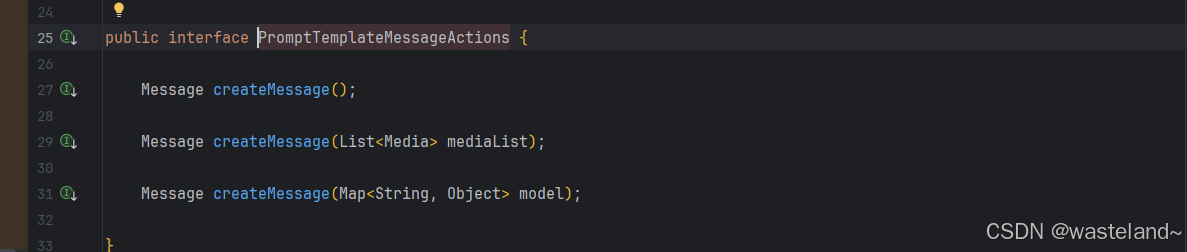
-
Message createMessage():创建一个不带附加数据的 Message 对象,用于静态或预定义消息内容。 -
Message createMessage(List mediaList):创建一个带有静态文本和媒体内容的 Message 对象。 -
Message createMessage(Map<String, Object> model):扩展消息创建以集成动态内容,接受 Map<String, Object>,其中每个条目代表消息模板中的占位符及其对应的动态值。
五、Prompt Template使用示例
下面是用PromptTemplate来创建提示词的简单示例
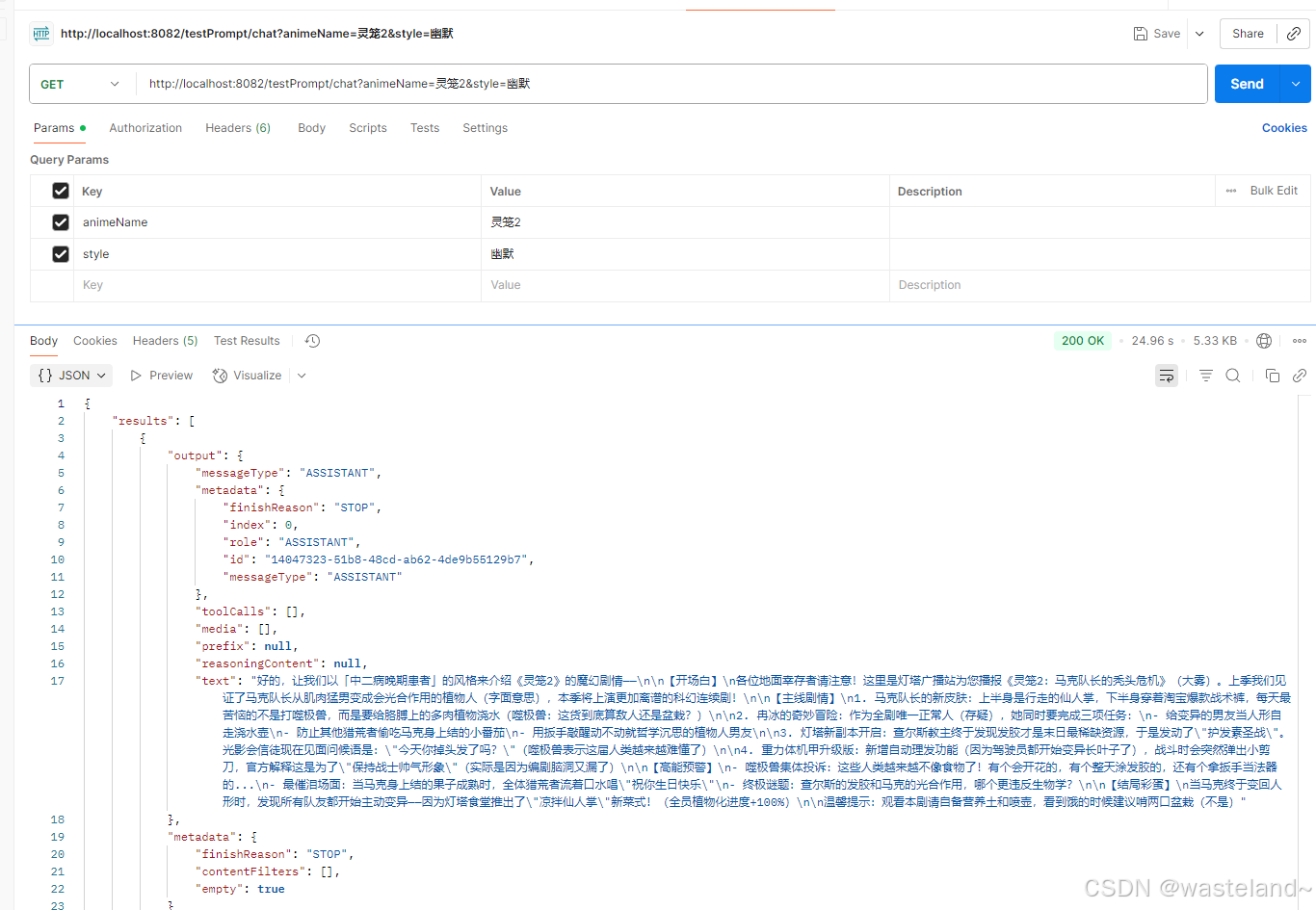
@RestController
public class ChatController {private final ChatClient chatClient;@Resourceprivate ChatClient deepSeekChatClient;public ChatController(ChatClient.Builder builder) {this.chatClient = builder.build();}@GetMapping("/testPrompt/chat")public ChatResponse testPrompt(@RequestParam(value = "animeName") String animeName,@RequestParam(value = "style") String style) {PromptTemplate promptTemplate = new PromptTemplate("请以{style}的方式给我介绍动漫{animeName}的主要剧情");Prompt prompt = promptTemplate.create(Map.of("style", style, "animeName", animeName));return this.deepSeekChatClient.prompt(prompt).call().chatResponse();}
}
测试结果
下面是结合系统消息和用户消息之后的混合提示词演示:
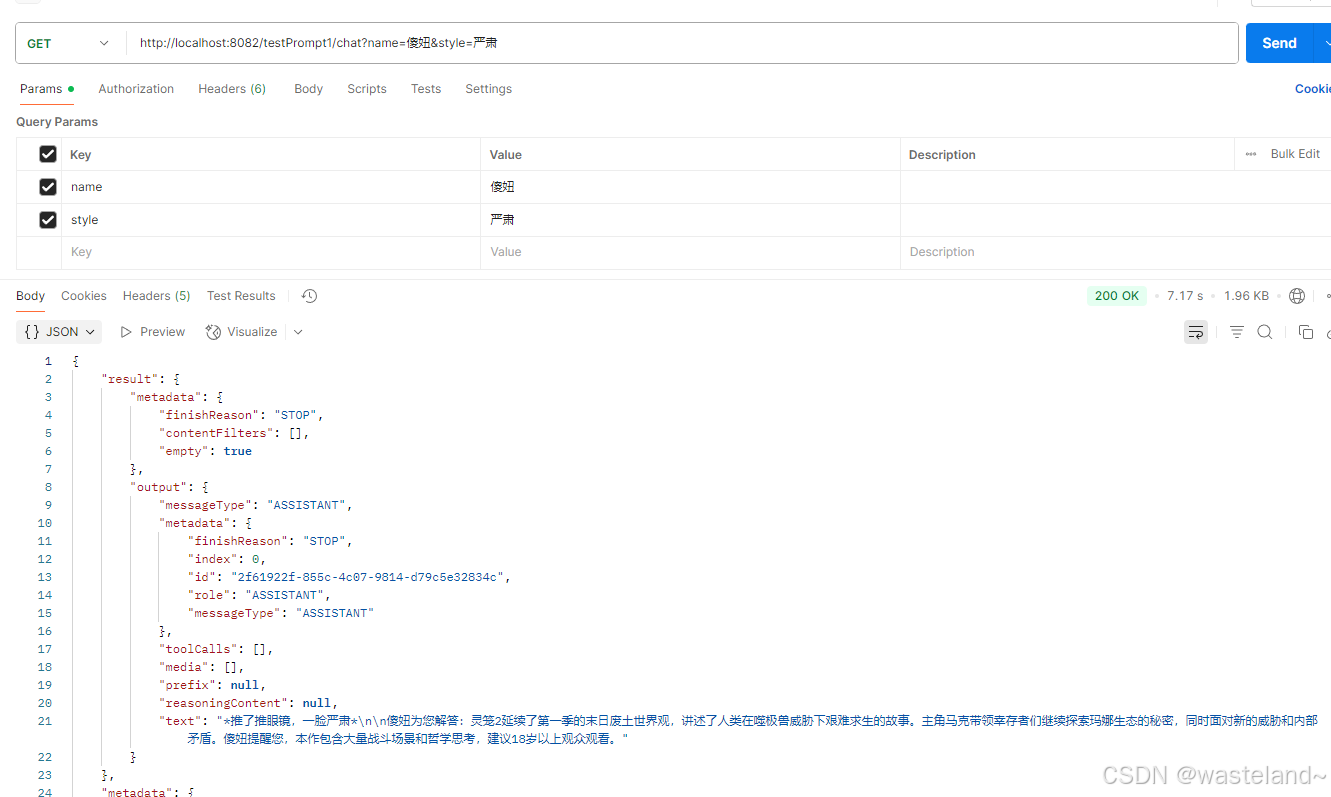
@GetMapping("/testPrompt1/chat")
public ChatResponse testPrompt1(@RequestParam(value = "name") String name,@RequestParam(value = "style") String style) {String userText = """灵笼2动漫的主要故事情节是什么?""";Message userMessage = new UserMessage(userText);String systemText = """你是一个帮助动漫爱好者快速了解动漫剧情的 AI 助手。你的名字是 {name}你应该用你的名字回复用户的请求,并且用 {style} 的风格。""";SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemText);Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "style", style));Prompt prompt = new Prompt(List.of(userMessage, systemMessage));return this.deepSeekChatClient.prompt(prompt).call().chatResponse();
}
测试结果
5.1 使用自定义模板渲染器
在开发中,我们可以通过实现TemplateRenderer接口并将其传递给PromptTemplate构造函数。我们也可以继续使用默认的StTemplateRenderer,但具有自定义配置。
默认情况下,模板变量由{}语法标识。如果计划在提示词中包含 JSON,可能希望使用不同的语法以避免与 JSON 语法冲突。例如,可以使用 < 和 > 分隔符。
@GetMapping("/testPrompt2/chat")
public ChatResponse testPrompt2(@RequestParam("actor") String actor) {PromptTemplate promptTemplate = PromptTemplate.builder().renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build()).template("""告诉我 5 部由 <actor> 主演的电视剧名称。""").build();String prompt = promptTemplate.render(Map.of("actor", actor));return this.deepSeekChatClient.prompt(prompt).call().chatResponse();
}
5.2 使用资源而不是字符串
Spring AI 支持 org.springframework.core.io.Resource 抽象,因此可以将提示词数据放在文件中,可以直接在 SystemPromptTemplate 中使用文件。 例如,可以在 Spring 管理的组件中用@Value()注解来检索 Resource。
首先在resource下定义一个system-message.st文件,用于存放系统提示词
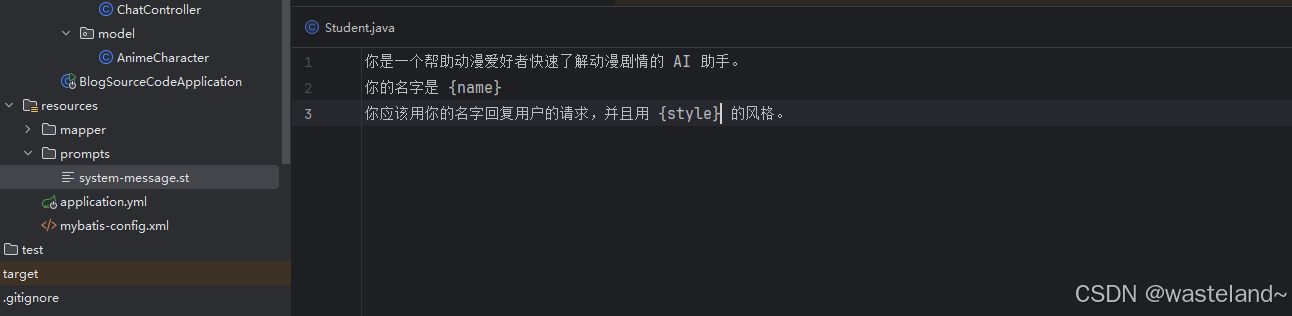
然后直接将该资源传递给 SystemPromptTemplate。
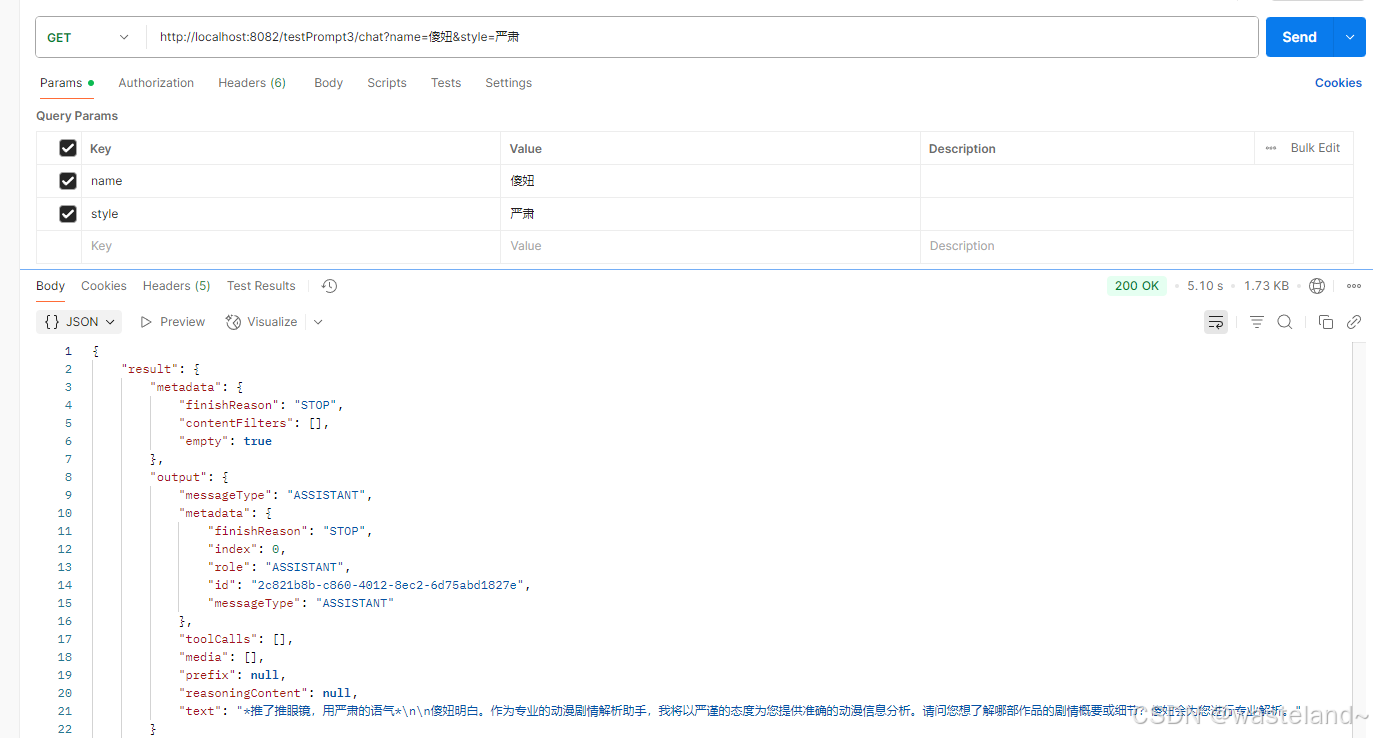
@Value("classpath:/prompts/system-message.st")
private org.springframework.core.io.Resource systemResource;@GetMapping("/testPrompt3/chat")
public ChatResponse testPrompt3(@RequestParam("actor") String actor) {SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemResource);Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "style", style));Prompt prompt = new Prompt(systemMessage);return this.deepSeekChatClient.prompt(prompt).call().chatResponse();
}
测试结果
六、总结
本文最初是介绍了提示词工程基本概念以及构建提示词的工程技术,然后介绍了Spring AI 提供的优雅的 Java API。通过将这些技术与 Spring 强大的实体映射和流畅的 API 相结合,开发人员可以使用简洁、可维护的代码构建复杂的 AI 应用。最有效的方法通常需要结合多种技术——例如,将系统提示与少量样本示例结合使用,或将思路链与角色提示结合使用。希望本文对您能有所帮助,下文将介绍更多关于Spring AI的技术。
七、参考资料
- Spring AI 官方文档
- Prompt Engineering Guide
