深度学习零基础入门(4)-卷积神经网络架构
许久不见~
本节我们延续上一节的话题来看看卷积神经网络的架构,看看具体的卷积、池化等操作
卷积神经网络详解:从基础操作到整体架构
一、卷积操作:特征提取的核心
卷积是卷积神经网络(CNN)的核心操作,灵感来源于人类视觉系统。在图像处理中,卷积可表示为:
(I∗K)(i,j)=∑m∑nI(i+m,j+n)⋅K(m,n)(I * K)(i,j) = \sum_{m}\sum_{n} I(i+m,j+n) \cdot K(m,n)(I∗K)(i,j)=m∑n∑I(i+m,j+n)⋅K(m,n)
其中:
- III 是输入图像矩阵
- KKK 是卷积核(滤波器)
- (i,j)(i,j)(i,j) 是输出位置坐标
卷积过程图解:
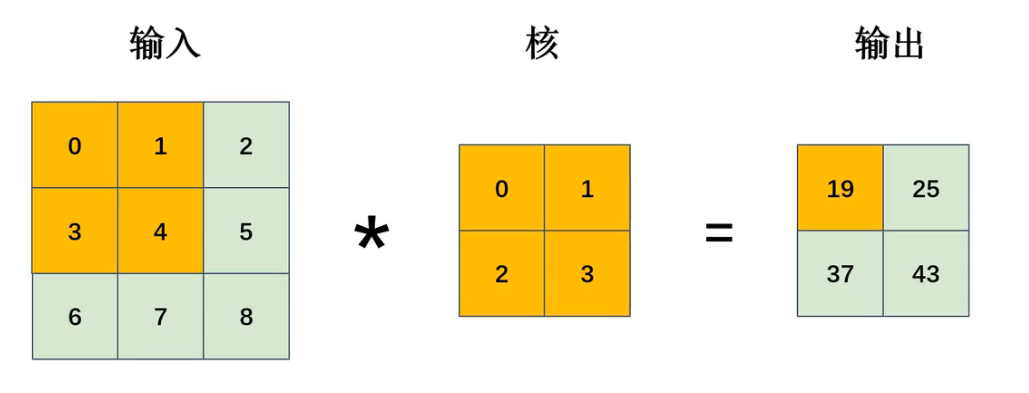
计算示例(左上角位置):
(0×0)+(1×1)+(3×2)+(4×3)=19(0×0) + (1×1) + (3×2) + (4×3) = 19(0×0)+(1×1)+(3×2)+(4×3)=19
简单来说就是对应相乘然后求和
卷积核本质是特征检测器,不同核可提取边缘、纹理等特征:
- 垂直边缘检测核:[10−110−110−1]\begin{bmatrix}1 & 0 & -1 \\ 1 & 0 & -1 \\ 1 & 0 & -1\end{bmatrix}111000−1−1−1
- 水平边缘检测核:[111000−1−1−1]\begin{bmatrix}1 & 1 & 1 \\ 0 & 0 & 0 \\ -1 & -1 & -1\end{bmatrix}10−110−110−1
至于特征是什么,你就当做是属性或者本质来理解吧
二、步幅(Stride):控制计算密度
步幅定义卷积核每次移动的像素数。设步幅为SSS:
- S=1S=1S=1:滑动间隔1像素(输出尺寸最大)
- S=2S=2S=2:滑动间隔2像素(输出尺寸减半)
步幅影响图解:
S=1时移动路径: S=2时移动路径:
→→→→→ → → →
↓↓ ↓ ↓
→→→→→ → → →
↓↓
→→→→→
数学意义:步幅增加会降低特征图分辨率,但能显著减少计算量,适用于深层网络。
三、填充(Padding):边界信息保护
填充是在输入图像边缘添加像素(通常为0),解决两个核心问题:
- 边界信息丢失(角落像素参与计算次数少)
- 输出尺寸收缩
常用填充模式:
| 类型 | 公式 | 输出尺寸 | 特点 |
|---|---|---|---|
| Valid | P=0P=0P=0 | W−FS+1\frac{W-F}{S}+1SW−F+1 | 无填充,输出缩小 |
| Same | P=F−12P=\frac{F-1}{2}P=2F−1 | WWW | 输入输出同尺寸 |
填充量PPP的计算:
P=⌊F−12⌋P = \left\lfloor \frac{F-1}{2} \right\rfloorP=⌊2F−1⌋
其中FFF为卷积核尺寸
填充效果示例(3x3核,Same填充):
原始输入: 填充后(P=1):
1 2 3 0 0 0 0 0
4 5 6 → 0 1 2 3 0
7 8 9 0 4 5 6 00 7 8 9 00 0 0 0 0
四、池化层:空间信息压缩
池化层通过降采样减少参数量,增强特征不变性。
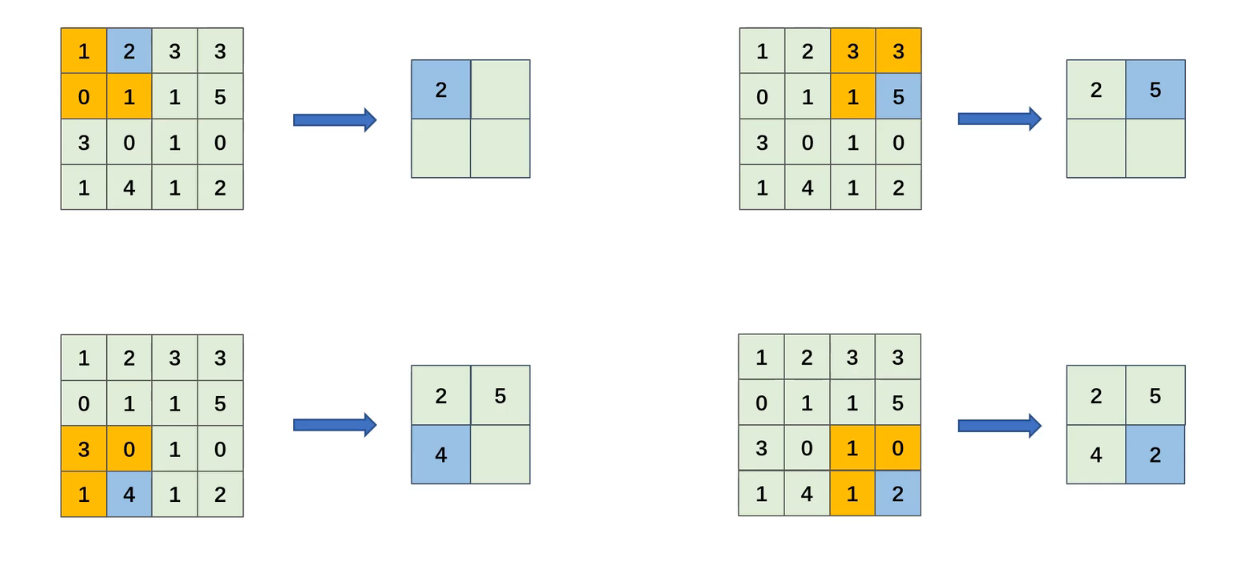
1. 最大值池化(Max Pooling)
输出(i,j)=maxm,n∈R输入(i×S+m,j×S+n) \text{输出}(i,j) = \max_{m,n \in \mathcal{R}} \text{输入}(i×S+m, j×S+n) 输出(i,j)=m,n∈Rmax输入(i×S+m,j×S+n)
可以这样来理解,在一个区域内挑选最大的
-
-
历史:1980年福岛邦彦在Neocognitron首次提出,1998年LeNet-5正式应用
-
特点:保留显著特征,对噪声鲁棒
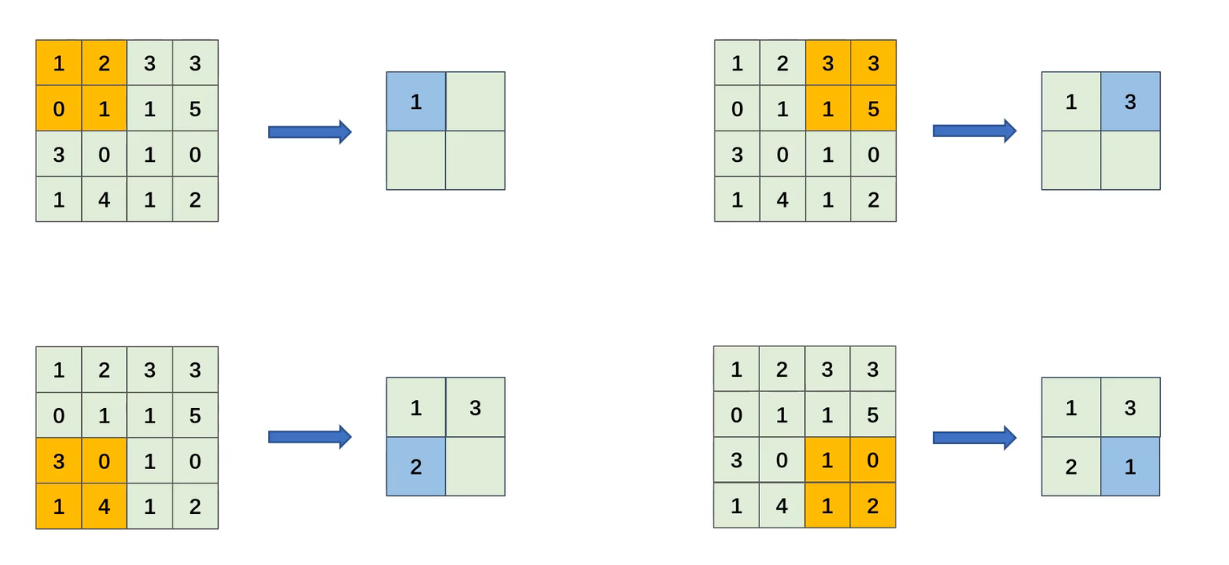
2. 平均池化(Average Pooling)
输出(i,j)=1∣R∣∑m,n∈R输入(i×S+m,j×S+n) \text{输出}(i,j) = \frac{1}{|\mathcal{R}|} \sum_{m,n \in \mathcal{R}} \text{输入}(i×S+m, j×S+n) 输出(i,j)=∣R∣1m,n∈R∑输入(i×S+m,j×S+n)
平均池化就是将这个区域内的值求平均数
-
-
历史:2012年AlexNet首次大规模应用,缓解过拟合
-
特点:保留整体特征分布,平滑特征图
池化过程图解(2x2池化窗口,S=2):
输入矩阵: 最大值池化: 平均池化:
[1 5 0 2] [5 2] [3.0 1.5]
[3 2 4 1] → [4 3] [3.5 2.5]
[7 0 3 5] [7 5] [3.5 4.0]
[2 6 1 4]
在这里我们将池化的核叫做感受眼 池化只算一种操作而不是卷积网络中的一层,但是它依旧会影响输入输出的特征图大小
五、输出特征图计算通式
给定参数:
- 输入尺寸:W×H×DinW \times H \times D_{in}W×H×Din
- 卷积核尺寸:FH×FW×DinFH \times FW \times D_{in}FH×FW×Din
- 卷积核通道数:DDD
- 步幅:SSS
- 填充:PPP
输出特征图尺寸:通道数由卷积核的通道数决定
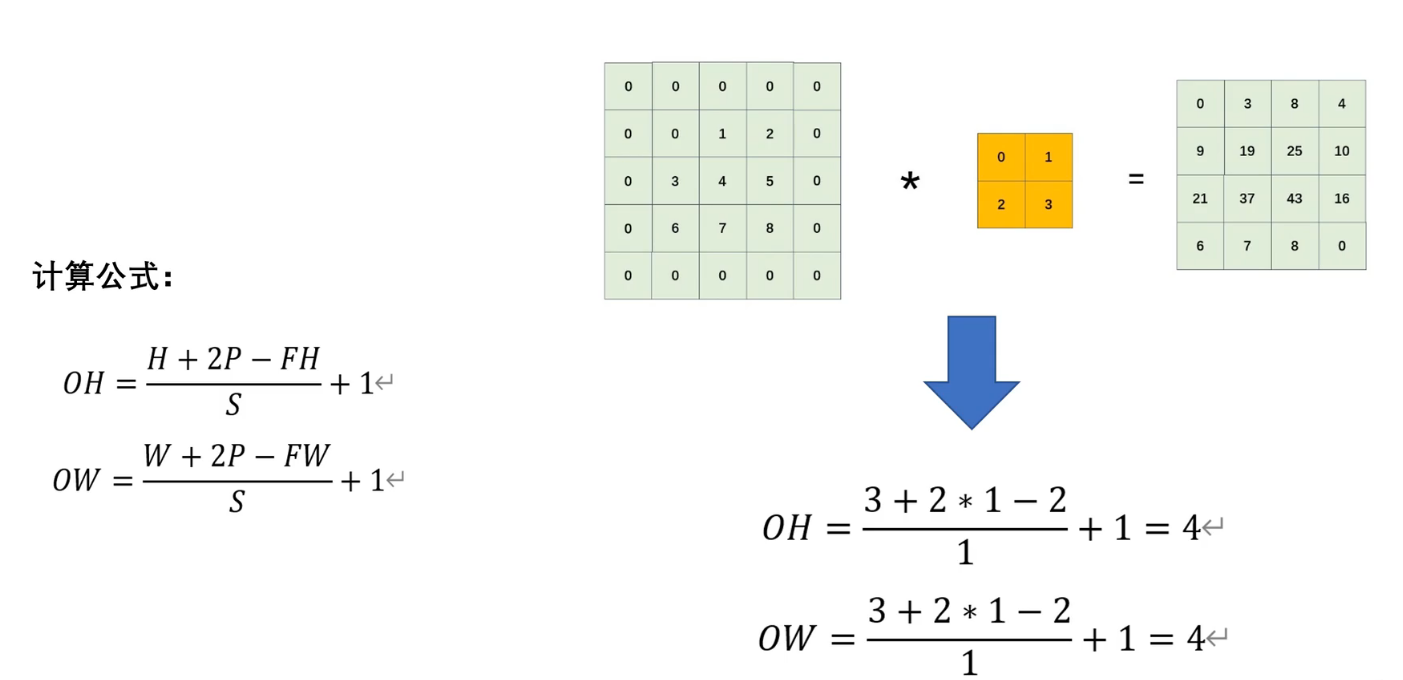
计算示例:
- 输入:224×224×3224 \times 224 \times 3224×224×3 图像
- 卷积核:7×7×37 \times 7 \times 37×7×3,K=64K=64K=64
- S=2S=2S=2,P=3P=3P=3
- 输出:Wout=⌊(224−7+6)/2⌋+1=112W_{out} = \lfloor(224-7+6)/2\rfloor+1 = 112Wout=⌊(224−7+6)/2⌋+1=112
- 最终输出:112×112×64112 \times 112 \times 64112×112×64
六、多通道卷积运算
多通道卷积是CNN处理彩色图像的关键,运算过程分三步:
-
输入结构:DinD_{in}Din通道输入(如RGB三通道)
输入∈RW×H×Din \text{输入} \in \mathbb{R}^{W \times H \times D_{in}} 输入∈RW×H×Din -
卷积核结构:每个卷积核包含DinD_{in}Din个通道的权重
Kk∈RF×F×Din(k=1,2,...,K) K_k \in \mathbb{R}^{F \times F \times D_{in}} \quad (k=1,2,...,K) Kk∈RF×F×Din(k=1,2,...,K) -
计算过程:
输出k(i,j)=∑d=1Din(∑m=0F−1∑n=0F−1Id(i+m,j+n)⋅Kk(d)(m,n))+bk \text{输出}_k(i,j) = \sum_{d=1}^{D_{in}} \left( \sum_{m=0}^{F-1} \sum_{n=0}^{F-1} I_d(i+m,j+n) \cdot K_k^{(d)}(m,n) \right) + b_k 输出k(i,j)=d=1∑Din(m=0∑F−1n=0∑F−1Id(i+m,j+n)⋅Kk(d)(m,n))+bk
多通道卷积示意图:
输入通道(3通道) 卷积核组(2个核)
[ R ] [ K1_R ] [ K2_R ]
[ G ] * [ K1_G ] [ K2_G ] = 输出特征图(2通道)
[ B ] [ K1_B ] [ K2_B ]
为什么会是这样呢?对于输入的3通道 ,每一个通道会和卷积核的一个通道进行卷积计算然后进行叠加,得到一个通道的输出,卷积核有多少的通道就会进行多少次这样的计算,因此由卷积核的通道(核的数量)决定本层的输出通道数
七、卷积神经网络整体架构
典型CNN包含以下层级结构:
1. 输入层
- 接收W×H×CW \times H \times CW×H×C张量
- 预处理:归一化、数据增强
2. 卷积块(重复N次)
这一块代码你可能还看不懂,没有关系,我们下一节具体来讲解
# 典型卷积块代码实现
def conv_block(x, filters, kernel_size=3):x = Conv2D(filters, kernel_size, padding='same')(x)x = BatchNormalization()(x)x = ReLU()(x)return x
- 卷积层:提取局部特征
- 激活函数:引入非线性(常用ReLU:f(x)=max(0,x)f(x)=\max(0,x)f(x)=max(0,x))
- 批归一化:加速训练
3. 池化层
- 空间降维:通常2×22\times22×2窗口,S=2S=2S=2
- 位置:每1-2个卷积块后
4. 全连接层
- 特征整合:将3D特征展平为1D向量
Flatten:RW×H×D→RN(N=W×H×D) \text{Flatten}: \mathbb{R}^{W\times H\times D} \to \mathbb{R}^{N} \quad (N=W\times H\times D) Flatten:RW×H×D→RN(N=W×H×D) - 分类输出:Softmax激活函数
5. 经典架构演进
| 网络 | 创新点 | 深度 | Top-5错误率 |
|---|---|---|---|
| LeNet-5 (1998) | 首个实用CNN架构 | 7层 | - |
| AlexNet (2012) | ReLU/Dropout/多GPU训练 | 8层 | 16.4% |
| VGG (2014) | 3x3小卷积核堆叠 | 16-19层 | 7.3% |
| ResNet (2015) | 残差连接解决梯度消失 | 50-152层 | 3.57% |
现代CNN架构特征:
- 深度堆叠:16~100+层
- 残差连接:H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x
- 瓶颈结构:1x1卷积降维
- 注意力机制:通道/空间注意力
- 轻量化设计:深度可分离卷积
八、端到端计算流程示例
以10x10 RGB图像分类为例:
- 输入层:10×10×310 \times 10 \times 310×10×3
- 卷积层1:32个3×33\times33×3核,S=1,P=1 → 10×10×3210 \times 10 \times 3210×10×32
- 池化层1:2x2 MaxPooling, S=2 → 5×5×325 \times 5 \times 325×5×32
- 卷积层2:64个3×33\times33×3核,S=1,P=1 → 5×5×645 \times 5 \times 645×5×64
- 池化层2:2x2 MaxPooling, S=2 → 2×2×642 \times 2 \times 642×2×64
- 全连接层:Flatten → 256256256神经元
- 输出层:Softmax → 类别概率
参数量计算:
- 卷积层1:(3×3×3+1)×32=896(3×3×3+1)×32 = 896(3×3×3+1)×32=896
- 卷积层2:(3×3×32+1)×64=18,496(3×3×32+1)×64 = 18,496(3×3×32+1)×64=18,496
- 全连接层:(256+1)×10=2,570(256+1)×10 = 2,570(256+1)×10=2,570
- 总计:21,962参数(传统神经网络需数百万参数)
九、卷积神经网络优势
-
局部连接:每个神经元仅连接局部区域,大幅减少参数量
参数量=(F×F×Din+1)×Dout \text{参数量} = (F \times F \times D_{in} + 1) \times D_{out} 参数量=(F×F×Din+1)×Dout -
权值共享:同一卷积核在整张图像滑动,增强泛化能力
-
平移不变性:池化操作使特征对位置变化鲁棒
-
层次化特征:
- 浅层:边缘/纹理
- 中层:部件组合
- 深层:语义对象
本介绍涵盖卷积神经网络核心组件及其数学原理,通过系统阐述,由基础操作延伸至架构设计,结合公式推导和概念图解,构建完整的知识体系。实际实现时需结合PyTorch/TensorFlow等框架,通过反向传播优化卷积核权重。
So,我们下一节来看看经典的神经网络的参数然后直接进行实战练习吧~