javacc学习笔记 03、编译原理实践 - JavaCC解析表达式并生成抽象语法树
文章目录
- 前言
- 本章节源码
- 前言
- 一、认识JavaCC
- 1.1、介绍JavaCC
- 1.2、JavaCC语法文件
- 二、表达式解析
- 表达式扫描器(词法)
- 表达式解析器(语法)
- 三、抽象语法树构建
- 抽象语法树的节点
- 自定义抽象语法树
- primary添加action行为
- term添加action行为
- expr节点添加action行为
- 自定义Calculator解析器
- 四、Vsitor模式遍历抽象语法树
- 案例实践:实现计算器(语义定义->语法解析->抽象语法树->计算-> 遍历语法树)
- 初步介绍
- 配置pom依赖
- Node类定义 & Calculator.jj(语义定义->语法解析)
- Calculator.jj(javacc语法定义)
- 定义Node相关实现类
- 编写Main测试语法树node构建
- 基于Visitor模式实现计算器计算功能
- 基于Visitor模式实现语法树可视化打印
- 总结
- 参考文章
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
本章节源码
当前文档配套相关源码地址:
- gitee:https://gitee.com/changluJava/demo-exer/tree/master/java-sqlparser/demo-javacc/javacc-learning
- github:https://github.com/changluya/Java-Demos/tree/master/java-sqlparser/demo-javacc/javacc-learning
前言
本章节大部分内容来源:编译原理实践 - JavaCC解析表达式并生成抽象语法树:https://liebing.org.cn/javacc-expression-ast.html
仅仅只是做归纳汇总
JavaCC实现表达式的解析, 并将解析结果生成为抽象语法树(Abstract Syntax Tree, AST).
对于表达式这种简单的”语言”, 可以边解析边计算从而直接得出结果, 生成抽象语法树有点”杀鸡焉用牛刀”了. 但是对于更加复杂的语言, 如通用计算机编程语言(C, Java等)或数据库查询语言SQL, 生成抽象语法树就是必须的了。
只有依托于抽象语法树才能进一步进行语义分析(如引用消解, 类型检查等), 代码生成或将SQL转化为关系代数等工作. 然而, 直接上手编写JavaCC的语法文件, 构建复杂语言的抽象语法树难度较大。
本文以表达式这个较为简单的”语言”为例, 通过编写JavaCC的语法文件将其转化为抽象语法树, 并使用Visitor模式访问抽象语法树对表达式进行计算. 这个例子可以说是”麻雀虽小, 五脏俱全”, 包含词法分析和语法分析的完整内容。
通过这个例子可以了解JavaCC语法文件的编写以及抽象语法树的构建方式, 在此基础上便可进一步构建更加复杂的语言的解析器
一、认识JavaCC
1.1、介绍JavaCC
Java Compiler Compiler (JavaCC) is the most popular parser generator for use with Java applications.
A parser generator is a tool that reads a grammar specification and converts it to a Java program that can recognize matches to the grammar.
Java 编译器编译器(JavaCC)是Java应用程序中最流行的解析器(Parser)生成器.
解析器生成器是一种工具, 它可以读取语法规范并将其转换为能够识别与语法匹配的Java程序.
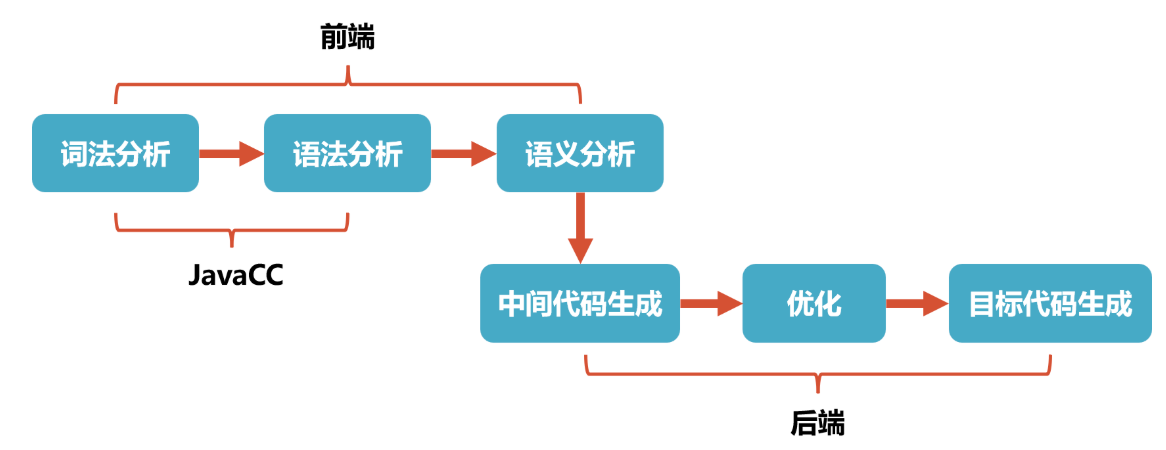
在编译器实现中, 首先要做的就是词法分析和语法分析:
- 词法分析:解析代码并生成Token(一个单词的字面和它的种类及语义值)序列, 词法分析的实现一般称为扫描器(Scanner);
- 语法分析:利用扫描器生成的Token序列来生成抽象语法树, 语法分析的实现一般称为解析器(Parser).
不依赖任何工具, 那就必须手写扫描器和解析器, 但是随着人们对编译原理的深入研究, 发现扫描器和解析器都可以根据一定的规则自动生成. 于是就出现了一系列的解析器生成器, 如Yacc, Anltr, JavaCC等。
这些解析器生成器都可以根据自定义的语法规则文件自动生成解析器代码, 比如JavaCC可以根据后缀为.jj的语法规则文件生成解析器的Java代码, 这就避免了手动编写扫描器和解析器的繁琐, 可以让我们专注于语法规则的设计.
1.2、JavaCC语法文件
JavaCC可根据用户编写的后缀名为.jj的语法规则文件自动生成解析器. 由于本文重点关注的是解析表达式并构建抽象语法树这个系统过程, 这里遵循”够用即可”的原则, 仅讲述在表达式解析中需要用到的语法. 关于JavaCC语法规则更详细的描述可见下面链接,其中”自制编译器”的第一, 二部分对JavaCC的语法规则有详尽的解释, 推荐阅读。
- JavaCC官方文档:https://javacc.github.io/javacc/tutorials/
- 自制编译器书籍:https://book.douban.com/subject/26806041/
JavaCC的语法文件一般包含如下内容:
options {JavaCC 的选项
}PARSER_BEGIN(解析器类名)
package 包名;
import 库名;public class 解析器类名 {任意的 Java 代码
}
PARSER_END(解析器类名)扫描器的描述解析器的描述
- 语法文件的开头是JavaCC选项的
options块, 可以省略; PARSER_BEGIN和PARSER_END之间是一个Java类, 可以支持任何Java语法, 这里定义的类成员变量或方法也能在解析器描述的actions中使用;- 最后是扫描器的描述和解析器的描述, 后面会进一步介绍.
有了以上概念之后, 我们可以看如下语法文件Adder.jj, 运行javacc Adder.jj命令即可生成一个Adder.java文件, 该文件是一个普通的Java类文件, 在命令行或IDE中编译运行后即可读取输入的整数加法表达式进行解析并计算。
options {STATIC = false;
}PARSER_BEGIN(Adder)
import java.io.*;public class Adder {public static void main(String[] args){for (String arg : args) {try{System.out.println(evaluate(arg));} catch (ParseException e) {e.printStackTrace();}}}public static long evaluate(String src) throws ParseException {Reader reader = new StringReader(src);return new Adder(reader).expr();}
}PARSER_END(Adder)// 扫描器的描述
SKIP : { <[" ", "\t", "\r", "\n"]> }TOKEN : { <INTEGER: (["0"-"9"])+> }// 解析器的描述
long expr():
{Token x, y;
}
{x=<INTEGER> "+" y=<INTEGER> <EOF>{return Long.parseLong(x.image) + Long.parseLong(y.image);}
}
-
在
PARSER_BEGIN和PARSER_END之间就是一个普通的Java类定义, 可以定义包含main函数在内的所有内容, 此外JavaCC还会自动生成以下构造函数, 上述文件中的evaluate方法就使用了参数为Reader的构造函数: -
Parser(InputStream s)Parser(InputStream s, String encoding)Parser(Reader r)Parser(××××TokenManager tm)
-
扫描器的描述主要是利用正则表达式描述各种Token
-
SKIP表示匹配的字符都可以跳过;TOKEN : { <INTEGER: (["0"-"9"])+> }表示定义了名为INTEGER的Token, 它可以由1个或多个数字组成.
-
解析器的描述支持扩展巴科斯范式(Extended Backus–Naur Form, EBNF), 可以在适当位置嵌入任意Java代码, 使用
Adder类所定义的成员变量或方法. 这是由于这里的expr()实际上会生成为Adder类中的一个同名方法. -
- 在
expr()之后的{}中可以定义任何临时变量, 这里的Token是JavaCC预定义的表示Token的类。 - 在之后的
{}中可定义方法体, 方法体支持EBNF, 在EBNF中可随时嵌入{}并在里面编写Java代码, 这在JavaCC中称为action. 比如在expr()中, 在解析到<INTEGER> "+" <INTEGER> <EOF>之后就会执行之后action中的代码. 这里只是简单的将对于的字符转换为整数相加后范围, 如果有需要也可以在action中添加生成抽象语法树的逻辑. 在EBNF中可以将任何元素赋值给临时变量。
- 在
二、表达式解析
表达式扫描器(词法)
为了构建表达式扫描器, 我们需要编写正则表达式, 以解析表达式中可能出现的所有字符, 并将其转化为相应的Token。
以下是表达式扫描器的描述, 第一个Token主要是数字的正则表达式, 第二个Token是一些三角函数, 读者可以加入更多的自定义Token, 比如sqrt等, 支持更丰富的运算。
SKIP : { " " | "\r" | "\t" }TOKEN:
{< NUMBER: (<DIGIT>)+ ( "." (<DIGIT>)+ )? >
| < DIGIT: ["0"-"9"] >
| < EOL: "\n" >
}TOKEN:
{<SIN: "sin">
| <COS: "cos">
| <TAN: "tan">
}
表达式解析器(语法)
表达式解析器的描述相对复杂一些, 为方便起见, 本文将表达式中可能出现的元素分为三类:
- primary:是表达式中的一个独立元素, 可以是一个数字(如123, 987.34), 也可以是括号包围的表达式(如(1+2)), 也可以是在数字或表达式上附带一元运算符形成的元素(如7!, sin(3*4+2))。由此可见这里的独立只是相对而言的, 表达式中可以有多个primary元素。
- term:是表达式中高优先级的元素, 需要优先计算, 它可以是一个单独的primary, 也可以是高优先级的二元运算符(和/)连接的元素, 如32, 9/3。
- expr:是一个表达式元素, 它可以是一个单独的term, 也可以是第优先级的二元运算符(+和-)连接的元素, 如3-2, 42+34。
依据上述描述的编写的词法解析规则如下, 为方便理解, 暂时去掉了所有action, 读者可根据注释仔细理解。
void expr(): { }
{term() ("+" expr() | "-" expr())* // term开头, 后面可能有+expr或-expr, 也可能没有
}void term(): { }
{primary() ("*" term() | "/" term())* // primary开头, 后面可能有*term或/term, 也可能没有
}void primary(): { }
{<NUMBER> // 数字, 如123, 789.98
| LOOKAHEAD(<NUMBER> "!") // 数字的阶乘, 如3!, 5!<NUMBER> "!"
| LOOKAHEAD("(" expr() ")" "!") // 表达式的阶乘, 如(3+2*3)!"(" expr() ")" "!"
| "+" primary() // "+"号前缀, 如+3, +(3+3*2)
| "-" primary() // "-"号前缀, 如-3, -(3+3*2)
| "(" expr() ")" // 括号包围的表达式, 如(3+3*2)
| <SIN> "(" expr() ")" // sin运算, 如sin(3), sin(3+3*4)
| <COS> "(" expr() ")" // cos运算, 如cos(3), cos(3+3*4)
| <TAN> "(" n=expr() ")" // tan运算, 如tan(3), tan(3+3*4)
}
三、抽象语法树构建
有了上述词法和语法描述就可以实现表达式的解析了, 但也仅仅是解析, 除了检查输入的表达式在语法上是否合规并没有其他任何作用。
要实现表达式的计算就需要在解析器语法描述的适当位置加入action。
对于表达式计算这种简单的应用我们可以直接在相应位置插入计算的代码, 类似于Adder.jj那样. 不过本文会在action中添加生成抽象语法树的代码, 从而将表达式转化为抽象语法树, 然后在使用Visitor模式遍历抽象语法树计算结果.
抽象语法树的节点
在插入action代码之前, 我们先来设计一下抽象语法树的各个节点.
首先, 抽象语法树需要一个抽象的节点基类Node。
Node类中只有一个属性sign用于指示当前节点的正负号. 抽象方法accept用于接收Visitor实现对节点的遍历。
public abstract class Node {protected int sign = 1;public int getSign() {return sign;}public void setSign(int sign) {this.sign = sign;}public abstract <T> T accept(ASTVisitor<T> visitor);
}
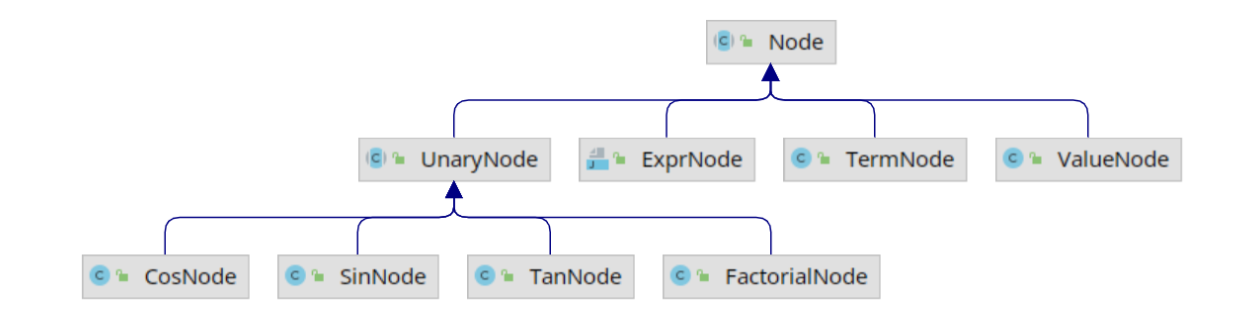
Node类有多个实现类:
ExprNode表示表示一个expr;TermNode表示一个term;UnaryNode表示一元运算符对应的节点, 有4个实现类;ValueNode表示一个数值节点.
各个类的继承关系如下图, 由于其实现较为简单, 这里不再展示完整的代码。
自定义抽象语法树
自定义抽象语法树实现代码来源:https://github.com/LB-Yu/data-systems-learning/tree/master/sql/javacc-learning/src/main/codegen
primary添加action行为
基于上述节点类, 我们便可在语法文件中添加action, 从而在解析的过程中构建抽象语法树。
primary添加action后如下, 其返回值为Node类型, 因为可能返回各种类型的节点, 这里统一用基类表示. 在每种情况后都增加了action, 其主要功能是为当前解析到的字符构建抽象语法树节点。
- 比如, 读到
<NUMBER>表示当前读到了一个数字, 之后就会创建一个ValueNode;LOOKAHEAD(<NUMBER> "!")表示超前扫描, 也就是说当扫描到<NUMBER>后还要继续往后扫描, 判断下一个字符是不是!, 如果不是则回到<NUMBER>的情况, 否则需要生成一个阶乘节点FactorialNode. 其他情况类似, 这里不再赘述.
Node primary():
{Token t;Token p;Node n;
}
{t=<NUMBER>{double number = Double.parseDouble(t.image);return new ValueNode(number);}
| LOOKAHEAD(<NUMBER> "!")t=<NUMBER> "!"{String value = t.image;double number = Double.parseDouble(value);return new FactorialNode(new ValueNode(number));}
| LOOKAHEAD("(" n=expr() ")" "!")"(" n=expr() ")" "!" { return new FactorialNode(n); }
| "+" n=primary() { return n; }
| "-" n=primary(){n.setSign(-1);return n;}
| "(" n=expr() ")" { return n; }
| <SIN> "(" n=expr() ")" { return new SinNode(n); }
| <COS> "(" n=expr() ")" { return new CosNode(n); }
| <TAN> "(" n=expr() ")" { return new TanNode(n); }
}
term添加action行为
term添加action之后如下, 其返回值同样为Node。
term可能有一个单独的primary组成, 也可能在之后*或/ 另一个term, 每种情况下的action都返回了对应的节点。
Node term():
{Node left;Node right;
}
{left=primary()("*" right=term() { return new TermNode(left, right, Operator.MUL); }| "/" right=term() { return new TermNode(left, right, Operator.DIV); })*{ return left; }
}
expr节点添加action行为
expr与term类似, 可能有一个单独的term组成, 也可能在之后+或-另一个expr, 每种情况都返回对应的节点.
Node expr():
{Node left;Node right;
}
{left=term()("+" right=expr() { return new ExprNode(left, right, Operator.PLUS); }| "-" right=expr() { return new ExprNode(left, right, Operator.MINUS); })*{ return left; }
}
自定义Calculator解析器
有了上述语法规则之后, 便可在PARSER_BEGIN和PARSER_END定义一个解析器类了. 这里我们将其称为Calculator.
PARSER_BEGIN(Calculator)
package javacc.learning.calculator.parser;import javacc.learning.calculator.ast.*;public class Calculator {public Node parse() throws ParseException {return expr();}
}
PARSER_END(Calculator)
四、Vsitor模式遍历抽象语法树
Vsitor模式遍历抽象语法树代码来源:https://github.com/LB-Yu/data-systems-learning/tree/master/sql/javacc-learning/src/main/codegen
生成抽象语法树, 相当于利用JavaCC将无结构的表达式字符串转化为了内存中结构化的树. 完成了抽象语法树的生成JavaCC的任务也就完成了, 之后如何通过抽象语法树计算表达式的结果就需要我们自己解决了。
- 在编译器中, 通常会将源代码解析为抽象语法树, 然后使用Visitor模式遍历抽象语法树进行语义分析, 如引用消解, 静态类型检查等. 这里我们也使用Visitor模式对表达式抽象语法树进行遍历计算结果。
为了遍历抽象语法树计算结果, 我们也可以不使用Visitor模式, 而利用多态实现不同节点的计算. 比如我们可以在Node中增加一个calculate抽象方法, 让每个实现类依据节点语义实现不同的计算方法. 这样当调用抽象语法树根节点的calculate方法后, 就会递归调用子节点的calculate方法直到叶节点返回结果。
public abstract class Node {...public abstract double calculate();
}public class ValueNode extends Node {...public double calculate() {return value;}
}public class SinNode extends UnaryNode {...public double calculate() {double value = node.calculate();double result = 1;for (int i = 1; i <= value; ++i) {result *= i;}return result * getSign();}
}
然而使用上述方法存在诸多缺点:
- 对不同的遍历场景需要为节点类添加不同的方法, 比如上面为了计算表达式结果添加了
calculate方法, 如果需要打印抽象语法树就需要再新增一个方法dump. 这样一旦有新的需求就必须不断改动节点类群, 由于节点类群众多, 修改相当困难. - 由于对于一种场景, 其实现逻辑都分散在各个节点类中, 不便于阅读相关代码。
由于上述缺点我们有必要引入Visitor模式对抽象语法树进行遍历. Visitor模式有一个抽象接口, 定义了对各种类型的节点进行访问的方法. 比如在表达式抽象语法树的遍历中, 我们定义了如下ASTVisitor接口, 其中包含对各种节点的visit方法。
public interface ASTVisitor<T> {T visit(ExprNode node);T visit(TermNode node);T visit(SinNode node);T visit(CosNode node);T visit(TanNode node);T visit(FactorialNode node);T visit(ValueNode node);
}
有了ASTVisitor接口, 我们只需在Node类中定义一个抽象方法accept用于实现不同场景下各个节点的遍历逻辑。
public abstract class Node {...public abstract <T> T accept(ASTVisitor<T> visitor);
}public class ValueNode extends Node {...@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}
}
有了上述接口之后, 我们只需要为不同的场景添加不同的实现类即可对抽象语法树进行遍历, 从而实现不同的逻辑. 以计算表达式结果为例, 可以添加如下实现类. 在实现类的visit方法中我们根据节点类型的不同编写对于的计算逻辑即可。
public class CalculateVisitor implements ASTVisitor<Double> {public double calculate(Node node) {return node.accept(this);}...@Overridepublic Double visit(FactorialNode node) {double value = node.getNode().accept(this);double result = 1;for (int i = 1; i <= value; ++i) {result *= i;}return result * node.getSign();}@Overridepublic Double visit(ValueNode node) {return node.getValue() * node.getSign();}
}
如果要添加新的遍历逻辑, 比如打印抽象语法树, 我们只需要新增一个DumpVisitor并实现相应的方法即可。
案例实践:实现计算器(语义定义->语法解析->抽象语法树->计算-> 遍历语法树)
初步介绍
上面四章节基本是来自于博客:https://liebing.org.cn/javacc-expression-ast.html 的学习过程翻译。
我按照博主的案例demo项目本地也跟着实现了一遍,对整个过程有了一点认知理解。
博客博主代码实现案例:https://github.com/LB-Yu/data-systems-learning/tree/master/sql/javacc-learning
本地案例demo:实现内容为 语义定义->语法解析->抽象语法树->计算-> 遍历语法
gitee:https://gitee.com/changluJava/demo-exer/tree/master_java_sqlparser/java-sqlparser
配置pom依赖
配置javacc插件工具,用于将jj文件转为Java代码:
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<build><plugins><plugin><groupId>org.codehaus.mojo</groupId><artifactId>javacc-maven-plugin</artifactId><version>2.6</version><executions><execution><goals><goal>javacc</goal></goals></execution></executions><configuration><sourceDirectory>${basedir}/src/main/codegen</sourceDirectory><includes><include>**/*.jj</include></includes><lookAhead>2</lookAhead><isStatic>false</isStatic></configuration></plugin></plugins>
</build>
Node类定义 & Calculator.jj(语义定义->语法解析)
目前这个过程是自定义Node类(搭配Calculator.jj匹配转换)以及进行语义token定义及解析(Calculator.jj)。
目前这部分内容为框住的部分:【语义定义->语法解析->抽象语法树】->计算表达式结果值-> 遍历打印语法树
Calculator.jj(javacc语法定义)
**下面可以分为三个部分:**扫描器、Token定义、解析器
- 扫描器:跳过的字段内容部分
- Token定义:这里定义了NUMBER、DIGIT、SIN、COS、TAN。你可以将其理解为用于匹配一段文本的变量标识(就和你用一段正则去匹配字符串文本里的值,你可以这样理解)
- 解析器:expr()、term()、primary()可以理解为组织匹配字符串文本中的行为,根据匹配到的不同模式内容去进行Node转换(其中的Node就是我们在ast包中定义的)构建,实际上抽象语法树就是expr()、term()过程中构建出来的。
options {STATIC=false;
}PARSER_BEGIN(Calculator)
package com.changlu.javacc.learning.Calculator.parser;import com.changlu.javacc.learning.Calculator.ast.*;public class Calculator {public Node parse() throws ParseException {return expr();}
}
PARSER_END(Calculator)// 扫描器的描述
// 这里含义:跳过空格、制表符、回车符
SKIP :
{" "
| "\r"
| "\t"
}// TOKEN定义
// TOKEN定义了如何识别和分类输入字符流中的标记
// <NUMBER: (<DIGIT>)+ ( "." (<DIGIT>)+ )?>:定义了一个名为NUMBER的标记类型。
// 它可以匹配一个或多个数字(通过(<DIGIT>)+),可选地后跟一个小数点及一个或多个数字(( "." (<DIGIT>)+ )?)。
// 含义:允许表示整数和小数
// <DIGIT: ["0"-"9"]>:定义了一个名为DIGIT的标记类型,它匹配任何一个数字字符(从'0'到'9')。
TOKEN :
{< NUMBER: (<DIGIT>)+ ( "." (<DIGIT>)+ )? >
| < DIGIT: ["0"-"9"] >
| < EOL: "\n" >
}// <SIN: "sin">:定义了一个名为SIN的标记类型,它匹配字符串"sin",通常代表正弦函数。
// <COS: "cos">:定义了一个名为COS的标记类型,它匹配字符串"cos",通常代表余弦函数。
// <TAN: "tan">:定义了一个名为TAN的标记类型,它匹配字符串"tan",通常代表正切函数。
TOKEN:
{<SIN: "sin">
| <COS: "cos">
| <TAN: "tan">
}// 解析器描述
// expr() 方法:处理加法和减法操作。
// 第一个{} 定义临时变量
// 第二个{} 编写解析到指定语法情况转换任务元素值赋值给临时变量
Node expr():
{Node left; // 左侧子节点Node right; // 右侧子节点
}
{left=term() // 调用 term() 解析乘法和除法表达式,并将结果赋值给 left。("+" right=expr() // 匹配 '+' 操作符,并递归调用 expr() 解析右侧表达式。{ return new ExprNode(left, right, Operator.PLUS); } // 创建并返回一个新的 ExprNode 表示加法操作。| "-" right=expr() // 或者匹配 '-' 操作符,并递归调用 expr() 解析右侧表达式。{ return new ExprNode(left, right, Operator.MINUS); } // 创建并返回一个新的 ExprNode 表示减法操作。)*{ return left; } // 如果没有匹配到任何操作符,则直接返回左侧节点 left。
}// term() 方法:处理乘法和除法操作。
Node term():
{Node left; // 左侧子节点Node right; // 右侧子节点
}
{left=primary() // 调用 primary() 解析基本元素,并将结果赋值给 left。("*" right=term() // 匹配 '*' 操作符,并递归调用 term() 解析右侧表达式。{ return new TermNode(left, right, Operator.MUL); } // 创建并返回一个新的 TermNode 表示乘法操作。| "/" right=term() // 或者匹配 '/' 操作符,并递归调用 term() 解析右侧表达式。{ return new TermNode(left, right, Operator.DIV); } // 创建并返回一个新的 TermNode 表示除法操作。)*{ return left; } // 如果没有匹配到任何操作符,则直接返回左侧节点 left。
}// primary解析方法:处理基本元素,如数字、括号内的表达式、负号、阶乘和三角函数。
// 解析数学表达式中的基本元素(如数字、括号内的表达式、以及一些函数调用)
Node primary():
{Token t;Token p;Node n;
}
{// 情况1:阶乘操作(如5!)LOOKAHEAD(<NUMBER> "!") // 确保接下来的输入是NUMBER后跟"!"t=<NUMBER> "!" // 匹配一个NUMBER类型的Token和随后的"!"{String value = t.image; // 获取Token的字符串表示double number = Double.parseDouble(value); // 将字符串转换为doublereturn new FactorialNode(new ValueNode(number)); // 返回一个新的阶乘节点}
|// 情况2:单独的数字t=<NUMBER>{double number = Double.parseDouble(t.image); // 将NUMBER类型的Token转换为doublereturn new ValueNode(number); // 返回一个值节点}
|// 情况3:括号内的表达式后跟阶乘操作(如(3+4)!)LOOKAHEAD("(" n=expr() ")" "!") // 确保接下来的输入是括号内的表达式后跟"!""(" n=expr() ")" "!" // 匹配括号内的表达式和随后的"!"{return new FactorialNode(n); // 返回一个新的阶乘节点}
|// 情况4:正号情况(实际上不做任何处理)"+" n=primary(){return n; // 直接返回子节点}
|// 情况5:负号情况(保存负号)"-" n=primary(){n.setSign(-1); // 设置节点的符号为-1return n; // 返回修改后的节点}
|// 情况6:括号内的表达式(优先级提升)"(" n=expr() ")"{return n; // 返回括号内的表达式节点}
|// 情况7:正弦函数(如sin(x))<SIN> "(" n=expr() ")"{return new SinNode(n); // 返回一个新的正弦节点}
|// 情况8:余弦函数(如cos(x))<COS> "(" n=expr() ")"{return new CosNode(n); // 返回一个新的余弦节点}
|// 情况9:正切函数(如tan(x))<TAN> "(" n=expr() ")"{return new TanNode(n); // 返回一个新的正切节点}
}
该文件用于放置到pom插件指定配置目录:
如何使用pom的javacc插件呢?
mvn javacc:javacc
执行命令将编译后的内容复制到parser目录下:
定义Node相关实现类
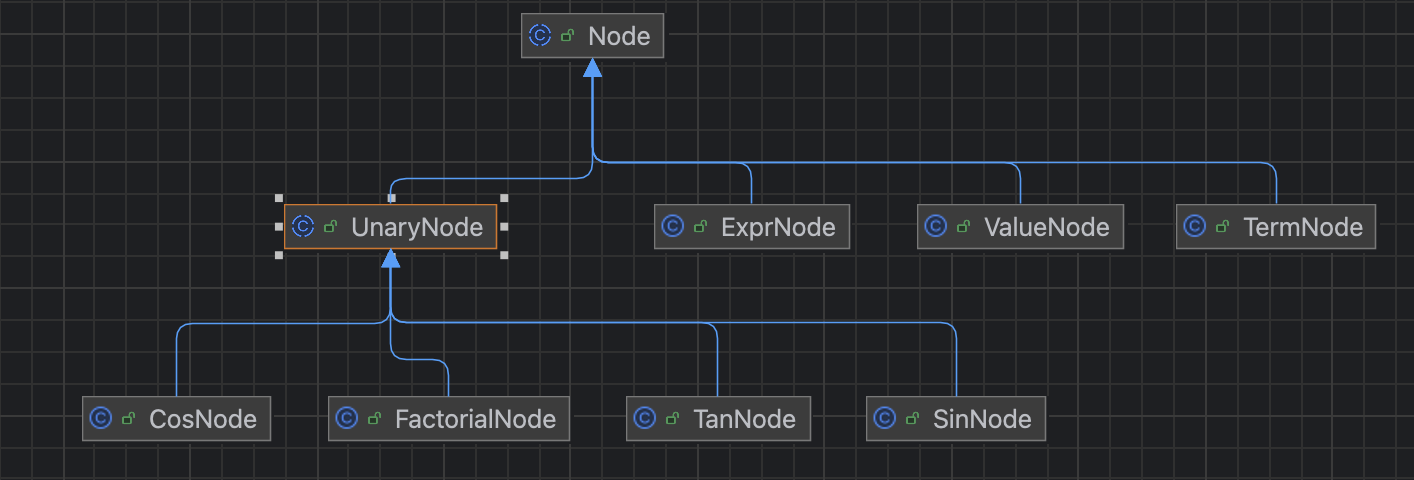
UnaryNode是带有保存依赖的node节点的。
- CosNode:处理cos函数表达式节点。
- FactorialNode:处理斐波那契表达式节点。
- TanNode:处理tan函数表达式节点。
- SinNode:处理sin函数表达式节点
ValueNode:确切保存数值表达式节点。
ExprNode:针对于±表达式(涵盖乘除)。
TermNode:针对于*/表达式。
说明:±、*/分开原因是因为要区分优先级,开始则是由ExprNode节点开始。
抽象基类Node:
public abstract class Node {protected int sign = 1;public int getSign() {return sign;}public void setSign(int sign) {this.sign = sign;}public abstract <T> T accept(ASTVisitor<T> visitor);
}
UnaryNode.java:
package javacc.learning.calculator.ast;public abstract class UnaryNode extends Node {protected Node node;public Node getNode() {return node;}
}
CosNode.java:处理cos函数表达式节点。
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class CosNode extends UnaryNode {public CosNode(Node node) {this.node = node;}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}
}
FactorialNode.java:处理斐波那契表达式节点。
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class FactorialNode extends UnaryNode {public FactorialNode(Node node) {this.node = node;}@Overridepublic String toString() {if (node instanceof ValueNode) {return (sign == 1 ? "" : "-") + node + "!";} else {return (sign == 1 ? "" : "-") + "(" + node + ")" + "!";}}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}
}
TanNode.java:处理tan函数表达式节点。
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class TanNode extends UnaryNode {public TanNode(Node node) {this.node = node;}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}
}
SinNode.java:处理sin函数表达式节点
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class SinNode extends UnaryNode {public SinNode(Node node) {this.node = node;}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}
}
ValueNode.java:确切保存数值表达式节点
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class ValueNode extends Node {protected double value;public ValueNode(double value) {this.value = value;}public double getValue() {return value;}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}@Overridepublic String toString() {return (sign == 1 ? "" : "-") + value;}
}
ExprNode.java:针对于±表达式(涵盖乘除)
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class ExprNode extends Node {private final Node left;private final Node right;private final Operator op;public ExprNode(Node left, Node right, Operator op) {this.left = left;this.right = right;this.op = op;}public Node getLeft() {return left;}public Node getRight() {return right;}public Operator getOp() {return op;}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}@Overridepublic String toString() {return (sign == 1 ? "" : "-") + String.format("%s %s %s", left, op, right);}
}
TermNode.java:针对于*/表达式
package javacc.learning.calculator.ast;import javacc.learning.calculator.visitor.ASTVisitor;public class TermNode extends Node {private final Node left;private final Node right;private final Operator op;public TermNode(Node left, Node right, Operator op) {this.left = left;this.right = right;this.op = op;}public Node getLeft() {return left;}public Node getRight() {return right;}public Operator getOp() {return op;}@Overridepublic <T> T accept(ASTVisitor<T> visitor) {return visitor.visit(this);}@Overridepublic String toString() {return (sign == 1 ? "" : "-") + String.format("%s %s %s", left.toString(), op, right.toString());}
}
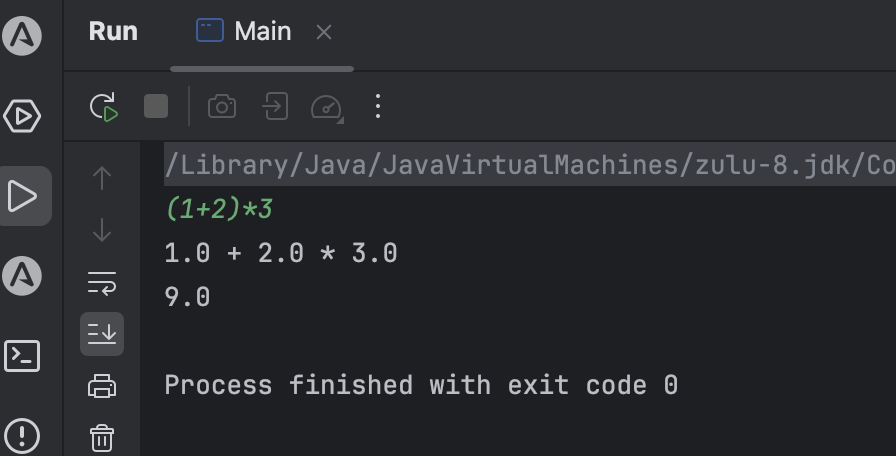
编写Main测试语法树node构建
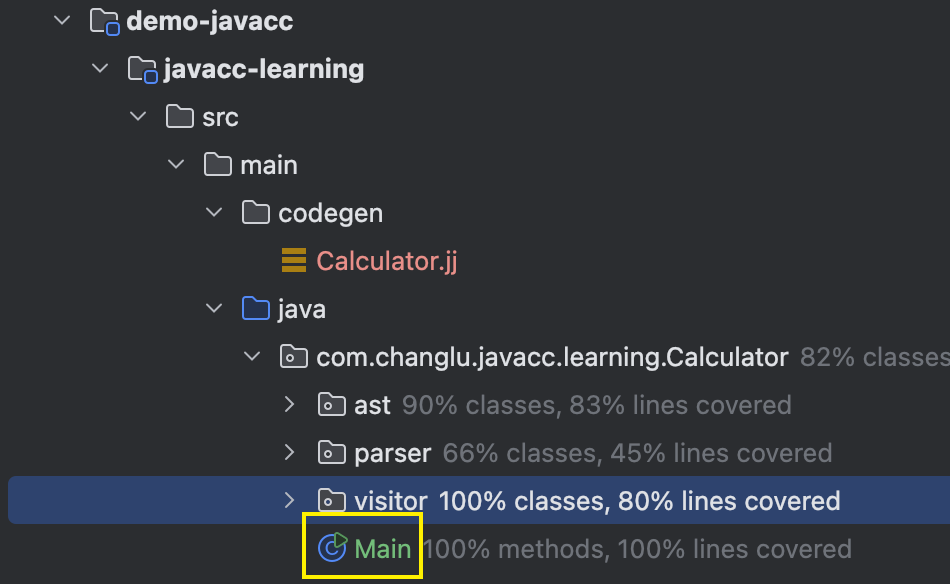
public class Main {public static void main(String[] args) throws Exception{Calculator calculator = new Calculator(System.in);// 解析为抽象语法树Node node = calculator.parse();System.out.println(node);}}
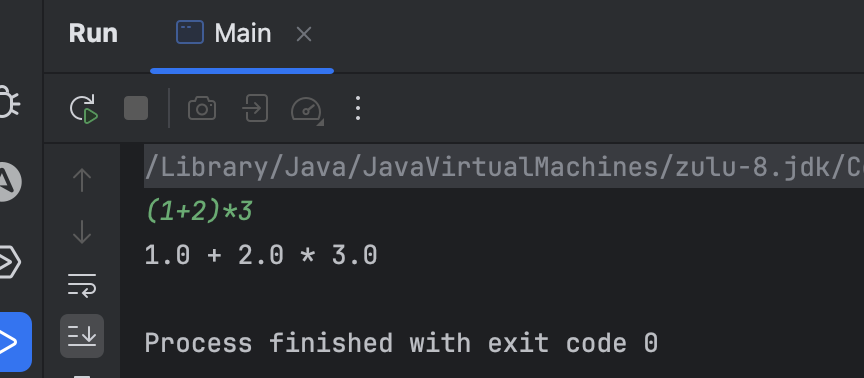
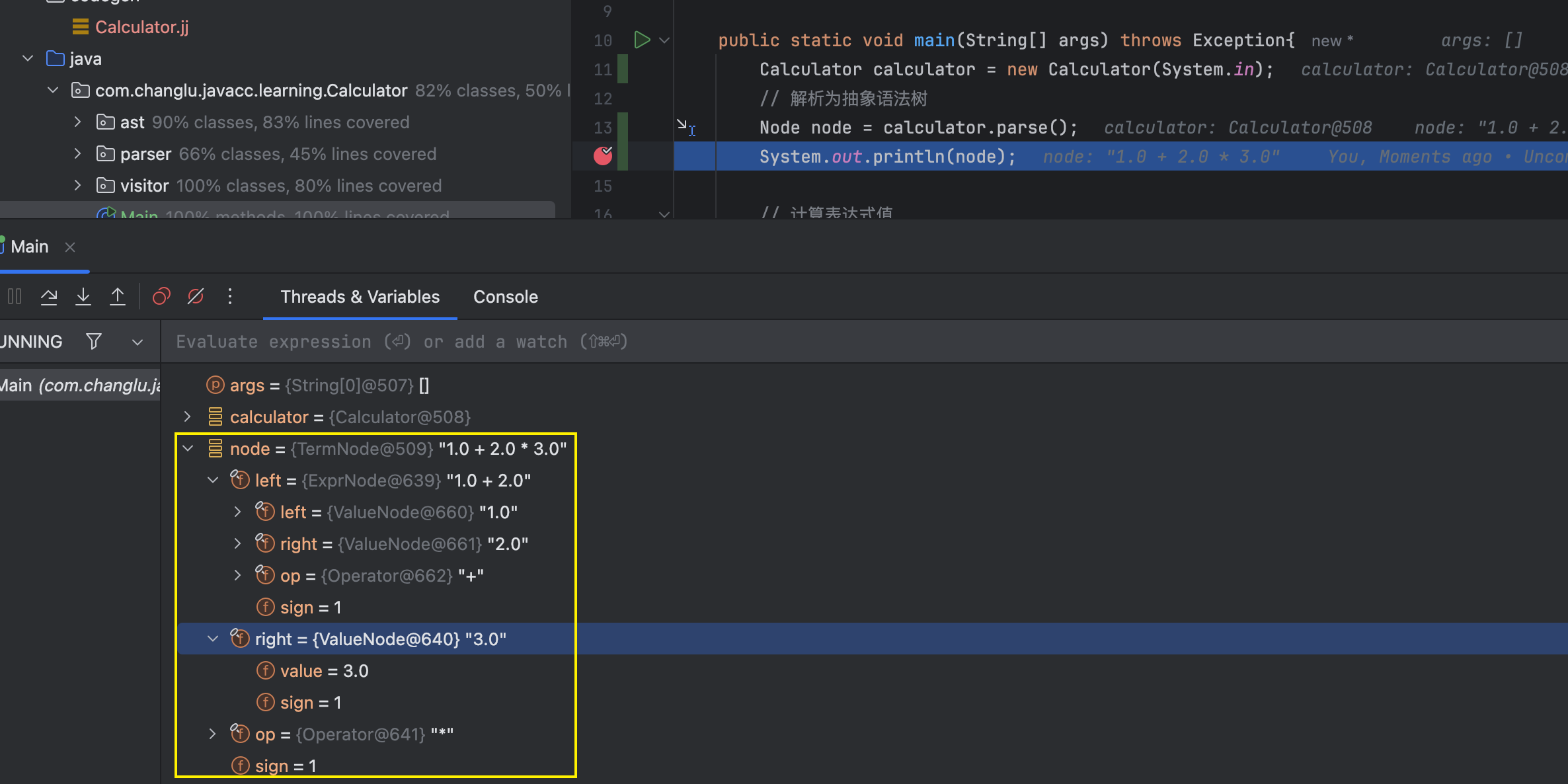
基于Visitor模式实现计算器计算功能
说明:在之前定义Nod类的时候实现了一个抽象方法,所有的子类Node都实现了该方法。
public abstract <T> T accept(ASTVisitor<T> visitor);
这里我们需要定义一个ASTVisitor接口:
public interface ASTVisitor<T> {T visit(ExprNode node);T visit(TermNode node);T visit(SinNode node);T visit(CosNode node);T visit(TanNode node);T visit(FactorialNode node);T visit(ValueNode node);}
后续如果有其他node,扩展只需要在这个接口里补充一个对应node的visit方法即可。
核心计算表达式,我们单独实现一个CalculateVisitor即可实现对各个不同Node进行处理的逻辑。
package com.changlu.javacc.learning.Calculator.visitor;import com.changlu.javacc.learning.Calculator.ast.*;public class CalculateVisitor implements ASTVisitor<Double>{public double calculate(Node node) {return node.accept(this);}@Overridepublic Double visit(ExprNode node) {Double leftValue = node.getLeft().accept(this);double rightValue = node.getRight().accept(this);switch (node.getOp()) {case PLUS:return (leftValue + rightValue) * node.getSign();case MINUS:return (leftValue - rightValue) * node.getSign();default:throw new IllegalArgumentException("Illegal operator for expr node");}}@Overridepublic Double visit(TermNode node) {double leftValue = node.getLeft().accept(this);double rightValue = node.getRight().accept(this);switch (node.getOp()) {case MUL:return leftValue * rightValue * node.getSign();case DIV:return leftValue / rightValue * node.getSign();default:throw new IllegalArgumentException("Illegal operator for term node");}}@Overridepublic Double visit(SinNode node) {return Math.sin(node.getNode().accept(this)) * node.getSign();}@Overridepublic Double visit(CosNode node) {return Math.cos(node.getNode().accept(this)) * node.getSign();}@Overridepublic Double visit(TanNode node) {return Math.tan(node.getNode().accept(this)) * node.getSign();}@Overridepublic Double visit(FactorialNode node) {Double value = node.getNode().accept(this);double result = 1;for (int i = 1; i <= value; i++) {result *= i;}return result * node.getSign();}@Overridepublic Double visit(ValueNode node) {return node.getValue();}
}
补充下测试:
public class Main {public static void main(String[] args) throws Exception{Calculator calculator = new Calculator(System.in);// 解析为抽象语法树Node node = calculator.parse();System.out.println(node);// 计算表达式值CalculateVisitor calculateVisitor = new CalculateVisitor();System.out.println(calculateVisitor.calculate(node));}}
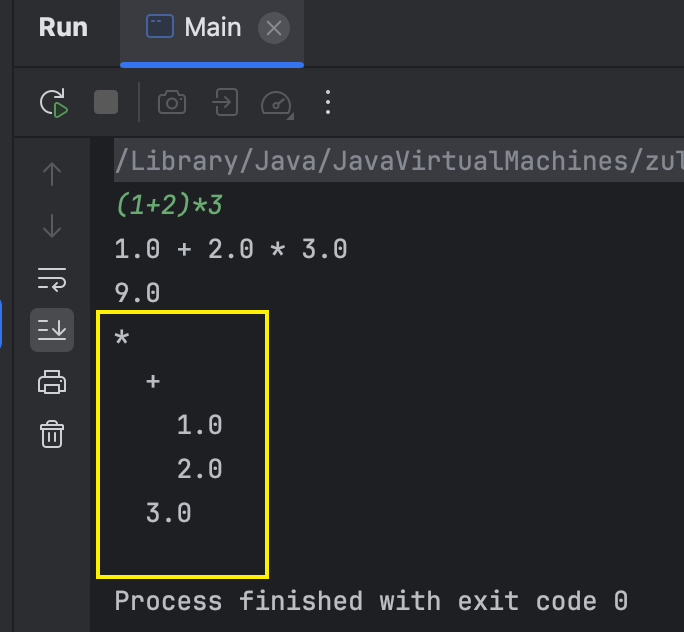
基于Visitor模式实现语法树可视化打印
实现DumpVisitor类来实现语法树可视化打印,基于ASTVisitor接口即可:实现逻辑同样也是根据不同的node来进行逻辑处理
package com.changlu.javacc.learning.Calculator.visitor;import com.changlu.javacc.learning.Calculator.ast.*;/*** 打印AstNode树*/
public class DumpVisitor implements ASTVisitor<Void>{private int level = 0;public void dump(Node node) {node.accept(this);}@Overridepublic Void visit(ExprNode node) {printIndent(level);System.out.println(node.getOp());++level;node.getLeft().accept(this);node.getRight().accept(this);--level;return null;}@Overridepublic Void visit(TermNode node) {printIndent(level);System.out.println(node.getOp());++level;node.getLeft().accept(this);node.getRight().accept(this);--level;return null;}@Overridepublic Void visit(SinNode node) {printIndent(level);System.out.println("sin");++level;node.getNode().accept(this);--level;return null;}@Overridepublic Void visit(CosNode node) {printIndent(level);System.out.println("cos");++level;node.getNode().accept(this);--level;return null;}@Overridepublic Void visit(TanNode node) {printIndent(level);System.out.println("tan");++level;node.getNode().accept(this);--level;return null;}@Overridepublic Void visit(FactorialNode node) {printIndent(level);System.out.println("!");++level;node.getNode().accept(this);--level;return null;}@Overridepublic Void visit(ValueNode node) {printIndent(level);System.out.println(node);return null;}public void printIndent(int level) {for (int i = 0; i < level * 2; ++i) {System.out.print(" ");}}
}
这里我们单独定义了一个depth深度,来进行信息打印。
测试一下,在Main类中补充下main方法:
package com.changlu.javacc.learning.Calculator;import com.changlu.javacc.learning.Calculator.ast.Node;
import com.changlu.javacc.learning.Calculator.parser.Calculator;
import com.changlu.javacc.learning.Calculator.visitor.CalculateVisitor;
import com.changlu.javacc.learning.Calculator.visitor.DumpVisitor;public class Main {public static void main(String[] args) throws Exception{Calculator calculator = new Calculator(System.in);// 解析为抽象语法树Node node = calculator.parse();System.out.println(node);// 计算表达式值CalculateVisitor calculateVisitor = new CalculateVisitor();System.out.println(calculateVisitor.calculate(node));// 采用visitor模式遍历抽象语法树DumpVisitor dumpVisitor = new DumpVisitor();dumpVisitor.dump(node);}}
总结
讲述了使用JavaCC构建解析器并生成抽象语法树的方法。 由于通用编程语言一般较为复杂解析难度大, 直接看这些语言的语法文件有时难
以理解从解析到抽象语法树构建这个系统流程。
前文也说到, 表达式这种简单场景完全可以不构建抽象语法树, 但本文还是”费劲”构建并用Visitor模式进行遍历, 目的是理解语法分析到抽象
语法树构建和遍历的整个流程. 理解了本文所描述的内容之后, 再去看通用编程语言的编译前端或SQL解析就会变得一目了然了, 因为框架
原理都是一样的, 无非是要在语法文件中逐步添加更多的规则, 增加更多类型的抽象语法树节点, 实现更多类型的Visitor类以支持不同类型
的语义分析。
参考文章
[1]. 编译原理实践 - JavaCC解析表达式并生成抽象语法树:https://liebing.org.cn/javacc-expression-ast.html
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue—校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅