MySQL中COUNT(\*)、COUNT(1)和COUNT(column),到底用哪个?

前段时间做项目的Code Review,给团队成员强调了一点规则:判断一条数据是否存在时,不要查询列表之后,比较列表长度是否大于0来判断数据是否存在,而是要用COUNT语句直接查询符合条件的条数。
此时,有同学提出一个很好的问题:在使用COUNT语句时,应该使用COUNT(*)、COUNT(1),还是COUNT(column)呢?这篇文章就带大家重新梳理一下这三者的区别。
COUNT查询的性能排序
首先,直接给出结论:
COUNT(*) = COUNT(1) > COUNT(id,主键字段) > COUNT(字段)
所以,一般情况下直接使用COUNT(*)即可。
这可能很反直觉,因为通常我们在执行SELECT语句时有一个基本规则,需要使用哪些字段尽量在SELECT关键词后明确指出,而不是直接查询出所有的字段,比如SELECT * FROM table_a。
关于最终的结论,在阿里巴巴开发手册中也有明确的【强制】说明:
【强制】不要使用COUNT(列名)或COUNT(常量)来替代COUNT(),COUNT()是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。
说明:COUNT(*)会统计值为NULL的行,而COUNT(列名)不会统计此列为NULL值的行。
下面我们来分析一下为什么会得出上述结论。
COUNT(*) 与 COUNT(1)比较
在MySQL的官方文档中是这样介绍COUNT函数的:
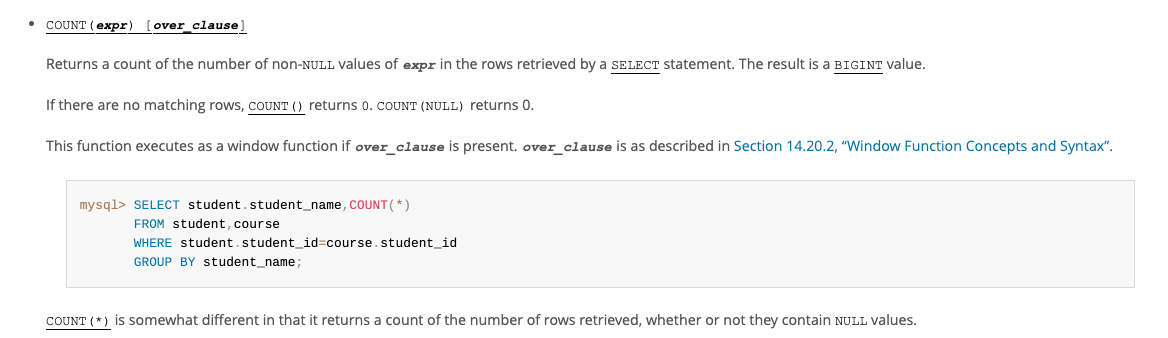
也就是说,COUNT(expr) 函数会返回SELECT语句检索的行中expr的值不为NULL的数量,结果是一个BIGINT值。如果查询结果没有命中任何记录,则返回0;需要注意的是COUNT(*) 的统计结果中,会包含值为NULL的行数。
在文档的后面,还有一段专门关于COUNT(*)和COUNT(1)性能的说明:
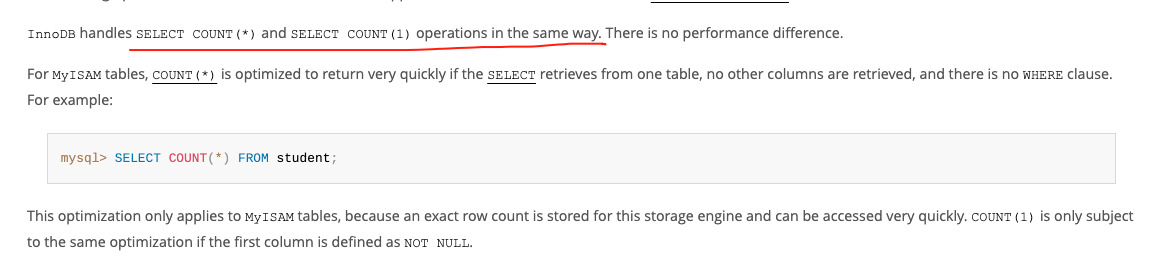
在上面的描述中,明确指出了:InnoDB 对SELECT COUNT(*)和SELECT COUNT(1)操作的处理方式完全相同,两者在性能上没有区别。
对于MyISAM表,COUNT(*) 操作经过优化,在以下情况下可以非常快速地返回结果:查询涉及的仅为一张表、不检索其他列,并且没有 WHERE 子句。例如:
mysql> SELECT COUNT(*) FROM student;
这种优化仅适用于MyISAM表,因为该存储引擎会存储准确的行数(row count),并且可以快速访问。至于COUNT(1),只有在第一列被定义为NOT NULL 时,才会享受相同的优化。
通过官方文档的说明,可以得出一个明确的结论:在InnoDB表的情况下,COUNT(*)和COUNT(1)的操作是一样的,在MyISAM表的情况下,COUNT(*) 相对于COUNT(1)要么效果一样,要么COUNT(*) 更优。
这也印证了最开始的结论:一般情况下直接使用COUNT(*)即可,在大多数情况下,COUNT(*)和COUNT(1)是一样的,在性能上没有差别。
COUNT()函数的含义
COUNT()是一个聚合函数,聚合函数有个特点,NULL值是不参与聚合函数计算的。而函数的参数不仅可以是字段名,也可以是其他任意表达式。
当使用COUNT(name) 时,name字段为一个表达式,底层会统计name 字段不为NULL的记录,也就是说会进行全表扫描,name不为NULL时,就会将变量count + 1。
在《高性能Mysql》一书中对COUNT()函数的作用介绍如下:
COUNT()是一个特殊的函数,有两种非常不同的作用:它可以统计某个列值的数量,也可以统计行数。在统计列值时要求列值是非空的(不统计NULL)。如果在COUNT()的括号中指定了列或者列的表达式,则统计的就是这个表达式有值的结果数。因为很多人对NULL理解有问题,所以这里很容易产生误解。
COUNT()的另一个作用是统计结果集的行数。当MySOL确认括号内的表达式值不可能为空时,实际上就是在统计行数。最简单的就是当使用COUNT(*)时,这种情况下通配符并不会像我们猜想的那样扩展成所有的列,实际上,它会忽略所有的列而直接统计所有的行数。
一个最常见的错误就是,在括号内指定了一个列却希望统计结果集的行数。如果希望知道的是结果集的行数,最好使用COUNT(*),这样写意义清晰,性能也会很好。
通过上述分析我们可以知道,COUNT(column)是统计非空列的行数,它也会遍历整张表,然后会对列对应的值做非空判断,非空的字段进行个数累加。当然这是列为主键索引时的操作。如果列不为主键索引时,那么查询时还需要进行回表操作,再根据主键获取数据,无疑又增加了一次IO,在性能上其实是不如COUNT(*)和COUNT(1)的。
至此,我们可以进一步得出结论:
COUNT(*) = COUNT(1) > COUNT(主键) > COUNT(非主键列)
使用建议
如果要获取一张表的确切行数,可以是优先使用使用 COUNT(*) 获取行数,这样写法清晰,性能较好,它也是SQL92定义的标准统计行数的语法,MySQL对其做了优化,尤其对于InnoDB表的优化更为明显。
同时,要避免使用 COUNT(column) 统计行数,除非你真的需要统计该列非空值的数量,否则容易产生误解。