[自动化Adapt] 父子事件| 冗余过滤 | SQLite | SQLAlchemy | 会话工厂 | Alembic
第五章:事件处理与融合
欢迎回到OpenAdapt探索之旅~
在第四章:系统配置中,我们掌握了如何定制化系统参数。更早的第一章:录制引擎则展示了系统如何捕获海量原始操作数据。
假设我们需要训练机器人输入"hello"一词。原始指令可能包含:
- 按下’h’键
- 释放’h’键
- 按下’e’键
- 释放’e’键
- …(其余字母及符号操作)
这种原子化指令显然低效,更优方案是直接下达"输入hello"指令。这正是事件处理与融合组件的核心价值。
何为事件处理与融合?
事件处理与融合组件是OpenAdapt的"数据清洗器"与"智能调度中心",主要职责是将录制引擎捕获的原始事件流转化为简洁高效、语义明确的操作序列。
必要性分析
录制过程产生的原子事件包括:
- 大量冗余鼠标移动轨迹
- 每个字符的独立按键/释放事件
- 高频次点击操作
若直接回放所有原始事件,将导致效率低下与可靠性问题。例如,无实际交互意义的鼠标微移事件会浪费系统资源。
该组件通过两大核心机制优化流程:
冗余事件过滤:清除无效噪声数据(如无位移的鼠标事件、瞬态弹窗事件)事件智能聚合:将关联事件融合为高层语义动作(如将多次点击合并为双击事件)
目标是在保持回放精度的前提下,构建以用户意图为中心的高效操作叙事。
工作原理
当录制完成时,事件处理与融合组件开始处理录制引擎捕获的ActionEvent、WindowEvent、Screenshot及BrowserEvent数据流。
事件处理流程
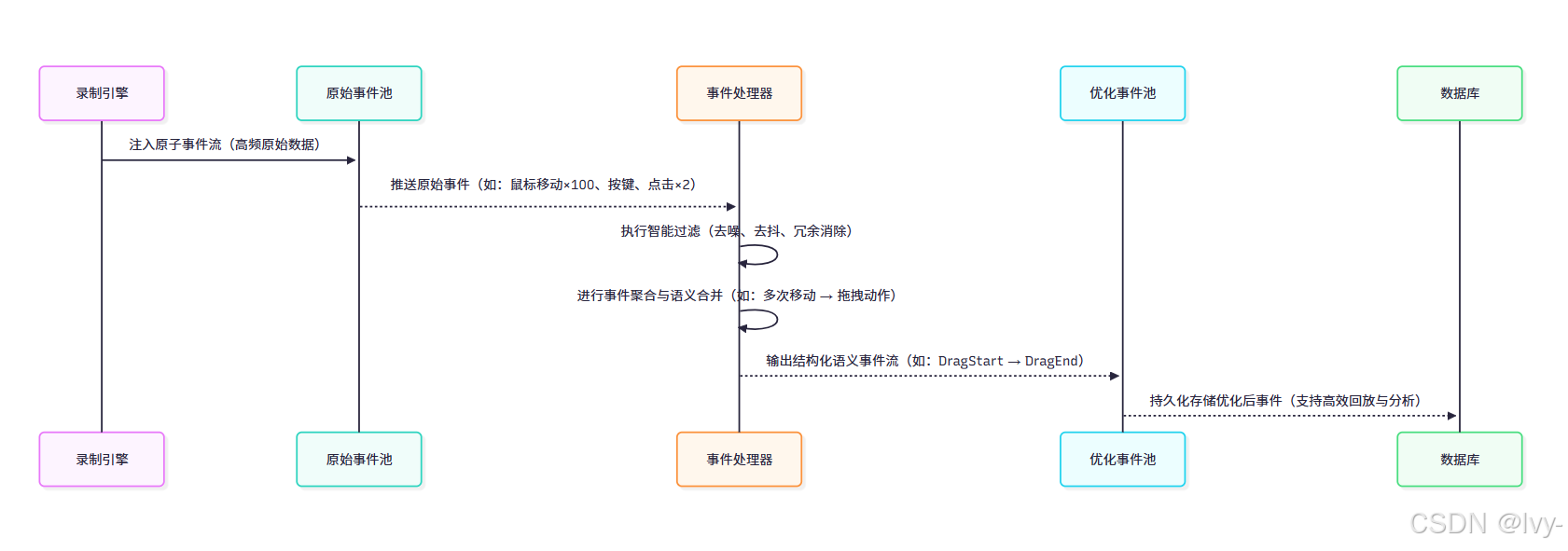
核心模块:events.py
事件处理逻辑集中实现在openadapt/events.py文件,包含多种专用处理函数。
主入口函数示例:
# 摘自openadapt/events.py(简化版)def get_events(db,recording,process: bool = True, # 关键处理开关meta: dict = None,
) -> list:"""获取并处理录制事件"""# 1. 从数据库提取原始事件action_events = crud.get_action_events(db, recording)window_events = crud.get_window_events(db, recording)screenshots = crud.get_screenshots(db, recording)browser_events = crud.get_browser_events(db, recording)if process: # 默认启用处理流程num_process_iters = 0while True: # 迭代优化直至收敛# 2. 执行核心融合逻辑action_events, window_events, screenshots, browser_events = merge_events(db, action_events, window_events, screenshots, browser_events)# 3. 终止条件判断(简化版)if num_process_iters == MAX_PROCESS_ITERS:breaknum_process_iters += 1return action_events # 返回优化后事件
该函数首先提取原始事件,随后通过merge_events函数迭代优化事件流,直至达到最大迭代次数或事件结构稳定。
事件融合调度器:merge_events
该函数作为处理流程的中枢,按序调用各类处理函数:
def merge_events(db,action_events: list,window_events: list,screenshots: list,browser_events: list,
) -> tuple:"""事件融合主逻辑"""# 处理函数执行队列process_fns = [remove_invalid_keyboard_events, # 无效键盘事件清理remove_redundant_mouse_move_events, # 冗余鼠标轨迹过滤merge_consecutive_keyboard_events, # 连续按键事件融合merge_consecutive_mouse_move_events, # 鼠标轨迹平滑merge_consecutive_mouse_scroll_events, # 滚轮事件聚合merge_consecutive_mouse_click_events, # 点击事件识别(单击/双击)]for process_fn in process_fns:action_events = process_fn(action_events)# 清理无效关联事件window_events = discard_unused_events(window_events, action_events, "window_event_timestamp")screenshots = discard_unused_events(screenshots, action_events, "screenshot_timestamp")browser_events = discard_unused_events(browser_events, action_events, "browser_event_timestamp")# 窗口事件最终校验window_events = filter_invalid_window_events(db, action_events)return action_events, window_events, screenshots, browser_events
典型处理函数
1. 键盘事件融合
将按键的press/release事件融合为type语义事件:
def merge_consecutive_keyboard_events(events: list) -> list:"""键盘事件聚合"""merged_events = []# 事件分组逻辑(简化为遍历)for event_group in event_groups:if len(event_group) == 1: # 孤立事件保持merged_event = event_group[0]else: # 创建父事件first_child = event_group[0]merged_event = create_parent_event(first_child,{"name": "type", # 新事件类型"children": event_group # 保留原子事件})merged_events.append(merged_event)return merged_events
2. 鼠标轨迹优化
清除无位移的冗余鼠标事件:
def remove_redundant_mouse_move_events(events: list) -> list:"""鼠标轨迹优化"""def is_same_pos(e1, e2) -> bool:return e1.mouse_x == e2.mouse_x and e1.mouse_y == e2.mouse_ycleaned_events = []# 三重滑动窗口检测for prev, curr, next in event_window:if curr.name == "move" and (is_same_pos(prev, curr) or is_same_pos(curr, next)):continue # 丢弃冗余事件cleaned_events.append(curr)return cleaned_events
父子事件关系
采用父子事件结构实现细粒度控制:
- 父事件:高层语义事件(如
type) - 子事件:原始原子事件(如
press/release)
优势包括:
- 回放效率:优先使用父事件进行快速回放
- 精度保障:必要时可追溯子事件实现精准还原
事件转换对照表
| 原始事件 | 处理后事件 | 优化效果 |
|---|---|---|
| 高频次鼠标移动事件 | 平滑轨迹事件 | 提升回放流畅度,降低资源消耗 |
| 单击(按下+释放) | 单次点击事件 | 表征完整交互单元 |
| 快速双击事件 | 双击事件 | 识别用户意图,提升操作语义化 |
| 连续字符输入事件 | 文本输入事件 | 简化回放逻辑,提高文本输入效率 |
| 同位置重复鼠标事件 | 事件合并或清除 | 减少数据噪声,优化存储空间 |
总结
本章揭示了事件处理与融合组件如何将原始事件流转化为高效语义化操作序列。
通过过滤冗余数据、识别用户意图、构建父子事件结构,OpenAdapt实现了精准且高效的回放机制。这种智能化的数据处理能力,是系统区别于简单宏录制工具的核心优势。
接下来我们将探索OpenAdapt的数据库管理机制,了解如何高效存储与检索海量操作数据。
下一章:数据库管理
第六章:数据库管理
在第五章:事件处理与融合中,我们见证了原始操作数据如何被转化为语义化操作序列。更早的第一章:录制引擎展示了数据捕获机制,第二章:数据模型则解析了数据结构化存储原理。
但优化后的操作数据最终存储何处?如何实现高效检索与回放?设想OpenAdapt如同创作多部著作(录制记录)的作家,每部著作包含大量页章(事件与截图),若无完善档案管理系统,必将陷入数据混沌。
这正是数据库管理组件的核心使命。
何为数据库管理?
数据库管理组件扮演OpenAdapt的"档案管理员",主要职责包括:
- 结构化存储:按数据模型规范归档录制数据,如同图书分类上架
- 高效检索:建立精准索引体系,支持快速定位目标数据
- 生命周期管理:实现基础数据操作:
- 增:新建录制记录及关联事件
- 查:检索与展示历史记录
- 改:更新记录属性(如标记隐私内容,详见第七章:隐私擦除)
- 删:清理失效数据
必要性分析
系统捕获的信息维度复杂(时间戳、坐标、文本、图像、窗口标题等),需可靠存储方案保障数据完整性。默认采用轻量级SQLite文件数据库,所有数据存储于单一文件,兼顾便携性与易用性。
典型用例:检索历史录制记录进行回放或清理过期数据,均依赖该组件实现。
SQLite应用前文传送:
[智能客服project] 架构 | 对话记忆 | 通信层
[Meetily后端框架] 多模型-Pydantic AI 代理-统一抽象 | SQLite管理
数据库管理
普通用户无需直接操作数据库文件,可通过可视化控制面板或命令行工具管理数据。
1. 查看录制记录
启动控制面板:
python -m openadapt.app.dashboard.run
浏览器访问面板后,"录制记录"模块将展示所有Recording数据实体,包含描述信息、时间戳等元数据。此为"查"操作的具体实现。
终端查询命令:
python -m openadapt.list
2. 删除录制记录
控制面板选中目标记录执行删除操作,此为"删"操作实例。系统将同步清理关联的录像文件及性能图表。
核心实现:crud.py模块
数据库交互逻辑集中于openadapt/db/crud.py文件,其名源自增删改查(CRUD)首字母缩写。
该模块作为系统"数据管理员",基于SQLAlchemy库实现与SQLite的交互。
数据流可视化
录制记录查询流程:
增删改查
增:新建录制记录
def insert_recording(session, recording_data):"""新建录制记录"""db_obj = Recording(**recording_data) # 创建数据实体session.add(db_obj) # 添加至临时会话session.commit() # 提交会话变更session.refresh(db_obj) # 刷新获取IDreturn db_obj
向数据库添加新记录。
-
recording_data是用户提供的数据(比如视频标题、时间等),代码将其转换为数据库对象db_obj。 -
session.add()将数据暂存,session.commit()正式保存到数据库,最后刷新获取自动生成的ID。 -
就像是往记事本里新增一页并自动编号。
查:获取事件数据
def get_action_events(session, recording):"""获取特定录制事件"""return (session.query(ActionEvent).filter(ActionEvent.recording_id == recording.id).order_by(ActionEvent.timestamp).all() # 返回有序事件列表)
通过录制ID查询关联的操作事件。
session.query()像在数据库里提问:“找所有属于这个录制的操作”.filter()精确筛选,.order_by()按时间戳排序,最终返回整理好的列表。- 类似在文件夹中按日期排序查找特定ID文件。
改:禁用隐私事件
def disable_action_event(session, event_id):"""标记禁用事件"""action_event = session.query(ActionEvent).get(event_id)if action_event:action_event.disabled = True # 设置禁用标志session.commit() # 提交变更
修改某条事件的禁用状态。先通过event_id找到具体事件对象,若存在则将其disabled属性设为True(类似打上禁用标签),session.commit()保存修改。
相当于把文件标记为"不可用"。
删:清理录制记录
def delete_recording(session, recording):"""删除录制记录及关联文件"""session.query(Recording).filter(Recording.id == recording.id).delete()session.commit()utils.delete_performance_plot(recording.timestamp) # 清理性能图表
删除操作分两步:
session.query().delete()从数据库移除录制记录utils.delete_performance_plot()同步删除关联的图表文件。
注意这是永久性删除,类似清空回收站并擦除磁盘数据。
🎢文件型数据库
以文件形式存储数据的数据库,数据按文件结构(如键值对、文档)直接存取,适合简单、小规模场景。例如SQLite、MongoDB的本地存储模式。
数据库连接SQLAlchemy
openadapt/db/db.py模块负责数据库连接管理:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmakerdef get_engine():"""数据库引擎初始化"""return create_engine(config.DB_URL, # 从配置获取数据库路径connect_args={"check_same_thread": False}, # 多线程支持echo=config.DB_ECHO # 调试模式SQL日志)# 全局会话工厂
Session = sessionmaker(bind=get_engine())
使用SQLAlchemy库创建数据库连接引擎和会话工厂,用于后续数据库操作。
主要组成部分:
create_engine()函数创建数据库引擎实例,参数包括:
config.DB_URL:数据库连接地址字符串connect_args={"check_same_thread": False}:允许多线程访问SQLite数据库echo=config.DB_ECHO:控制是否输出执行的SQL语句(调试用)
sessionmaker()创建会话工厂类Session:
- 绑定到前面创建的数据库引擎
- 后续通过
Session()可生成新的数据库会话实例
使用场景:
- 数据库引擎是SQLAlchemy的核心接口
- 会话工厂用于统一管理数据库会话
- 适合在Web应用等需要多线程访问数据库的场景
🎢会话工厂
会话(Session) :
在数据库中,会话指用户从连接到断开期间的所有操作和状态,相当于一次“对话”过程的完整记录,包括登录、执行命令、事务处理等,系统通过会话ID跟踪和管理这些活动。
会话工厂:
一个创建和管理数据库会话的中央工具,负责高效生成、复用和释放数据库连接,确保应用与数据库的交互安全且高性能。
数据安全机制
并发写锁控制
防止多进程并发写入冲突:
def acquire_db_lock(timeout=60):"""获取数据库写锁"""while os.path.exists(DATABASE_LOCK_FILE_PATH):if 相关进程存活:time.sleep(1)else:os.remove(锁文件)with open(锁文件, "w") as f:f.write(json.dumps({"pid": 当前进程ID}))
通过文件锁机制防止多个进程同时写入数据库,确保数据一致性。核心逻辑是通过检查锁文件的存在和内容来判断是否允许写入。
实现原理
锁文件检测:检查指定路径的锁文件是否存在。若存在,说明其他进程可能正在写入。
进程存活判断:若锁文件存在,进一步检查创建该锁的进程是否仍在运行。若进程已终止,删除旧锁文件(避免死锁)。
创建新锁:当前进程创建新锁文件并写入自身进程ID,标记为"正在占用"。其他进程检测到有效锁时会等待或放弃。
关键点:
- 超时机制:外部可通过
timeout参数控制等待锁的最长时间(代码片段未完整展示)。 - 原子性操作:依赖文件系统的原子性创建/删除,避免竞态条件。
- 进程标识:锁文件
记录进程ID,用于区分有效锁和僵尸锁。
🎢僵尸锁
僵尸锁是进程异常终止后遗留的未释放锁,操作系统通过记录进程ID识别并清理这些失效锁,确保资源不被无效占用。
前文传送:【Linux详解】进程的状态 | 运行 阻塞 挂起 | 僵尸和孤儿状态
结构迁移管理
Alembic工具实现数据库版本迁移:
# openadapt/alembic/context_loader.pydef load_alembic_context():"""执行数据库结构迁移"""config = Config("alembic.ini")command.upgrade(config, "head") # 升级至最新版本
Alembic是Python中用于数据库迁移(版本控制)的工具,帮助开发者管理数据库结构变更(如创建表、修改字段),类似Git对代码的版本管理。
链接:https://www.alembic.io/
Alembic源码理解 前文传送:Git CI/CD专栏
该脚本在系统启动时自动运行,确保表结构与数据模型定义同步更新。
功能矩阵
| 操作类型 | 描述 | 核心函数 |
|---|---|---|
| 增 | 插入新记录 | insert_recording, insert_action_event |
| 查 | 检索现有数据 | get_all_recordings, get_action_events |
| 改 | 更新记录属性 | disable_action_event |
| 删 | 删除数据 | delete_recording |
总结
本章深入剖析了数据库管理组件如何作为OpenAdapt的"数据档案馆"
-
通过CRUD操作实现数据全生命周期管理
-
掌握
crud.py模块的增删改查实现 -
db.py的连接管理机制 -
以及Alembic的结构迁移原理,可更高效地利用系统数据存储能力。
接下来我们将探索第七章:隐私擦除,了解如何保护敏感信息。
下一章:隐私擦除