关系抽取笔记总结
一、课程目标
实现关系抽取任务
二、关系抽取应用的场景
知识图谱构建:必备环节--》关系抽取
信息检索和推荐
信息提取
三、关系抽取课程大纲内容
1.基于规则实现关系抽取任务
2.基于BiLSTM+Attention实现了关系任务分类
3.基于CasRel模型实现多元嵌套关系的抽取
四、关系抽取任务介绍
4.1 概念
定义:对于一段文本,抽取出其中的SPO三元组,
S:subject;主实体
P:predicate; 关系(预测)
O:object; 客实体
4.2 两大任务:
1.实现实体的抽取任务(NER)
2.基于实体实现关系的分类(RE)
4.3 主要实现方法
1.基于规则方式: 人为设定规则,抽取spo三元组
2.基于pipeline方式: 先完成实体抽取任务,然后在实体基础上完成关系分类
3.基于joint方式: 联合抽取任务,经过一个复杂的模型网络一次性抽取spo三元组
4.4 主要评价指标
precision: 预测为正类的样本中实际为正类的比例
recall: 实际为正类的样本中预测为正类的比例
F1-score: 2*p*r / (p+r)
4.5 主要问题
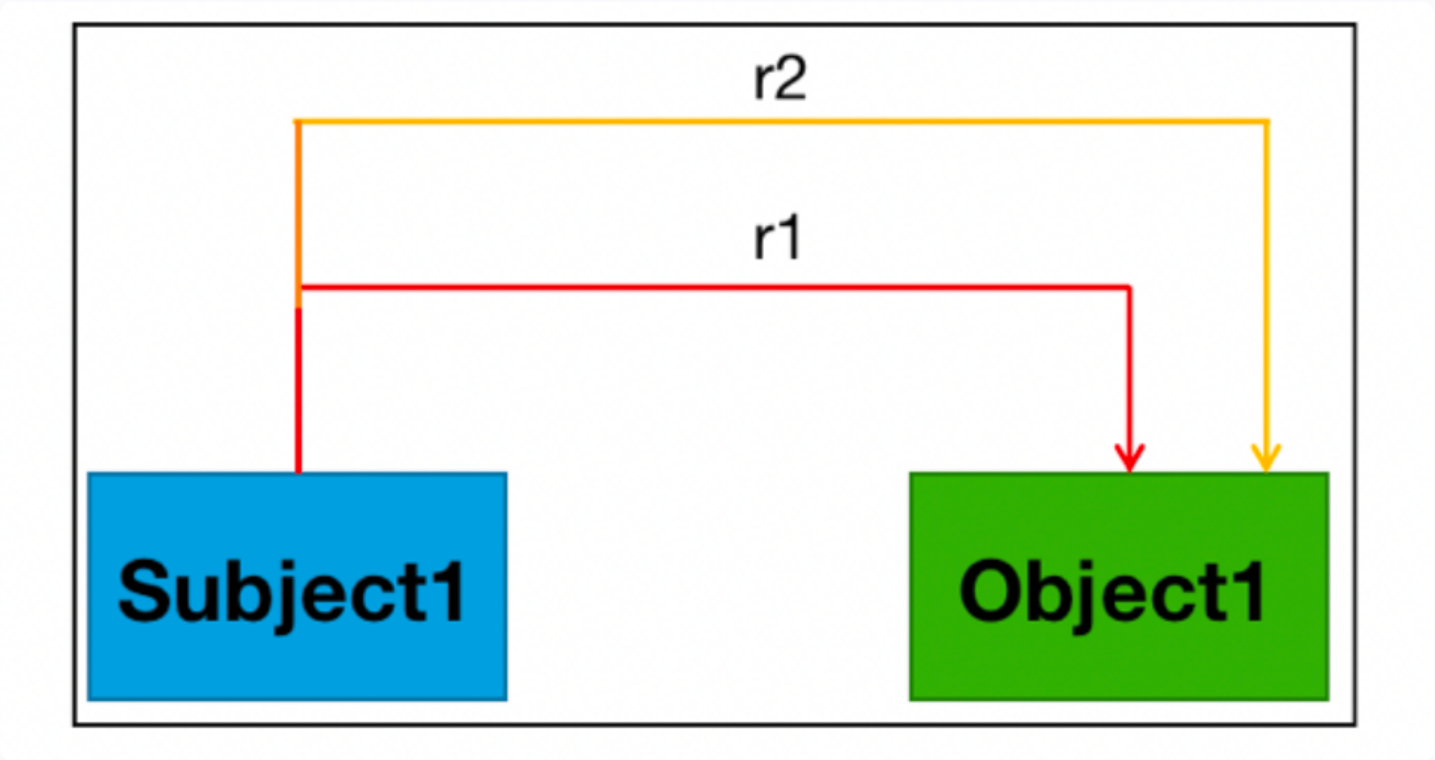
一对实体只有一种关系
eg: “《人间》是王菲演唱歌曲“中存在1种关系: (王菲-歌手-人间)
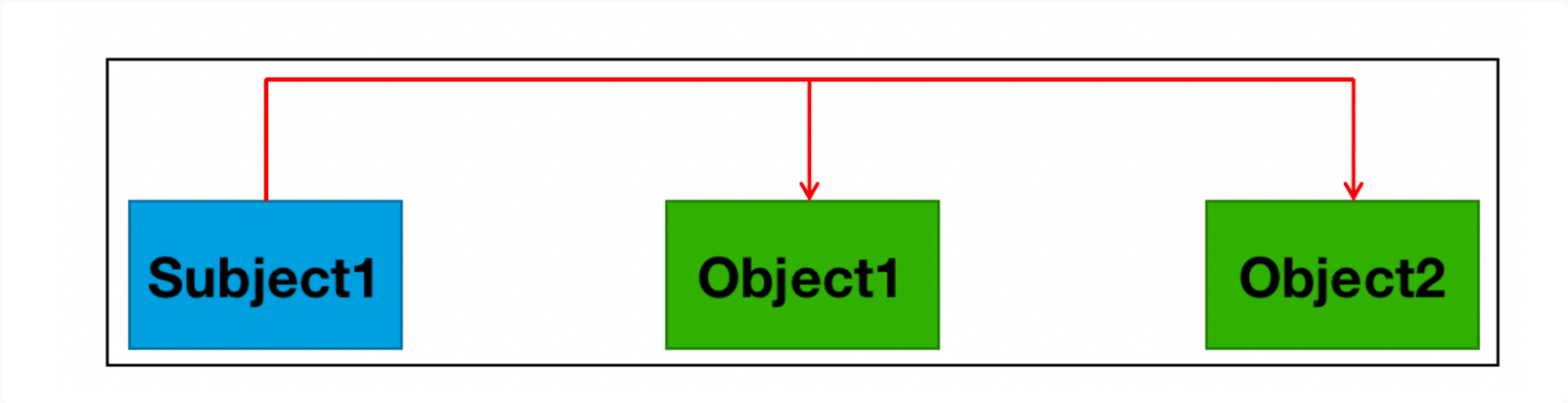
一个实体存在多种关系
eg:“叶春叙出生于浙江,毕业于黄埔军校”中存在两种关系: (叶春叙-毕业院校-黄埔军校) 、 (叶春叙-出生地-浙江)
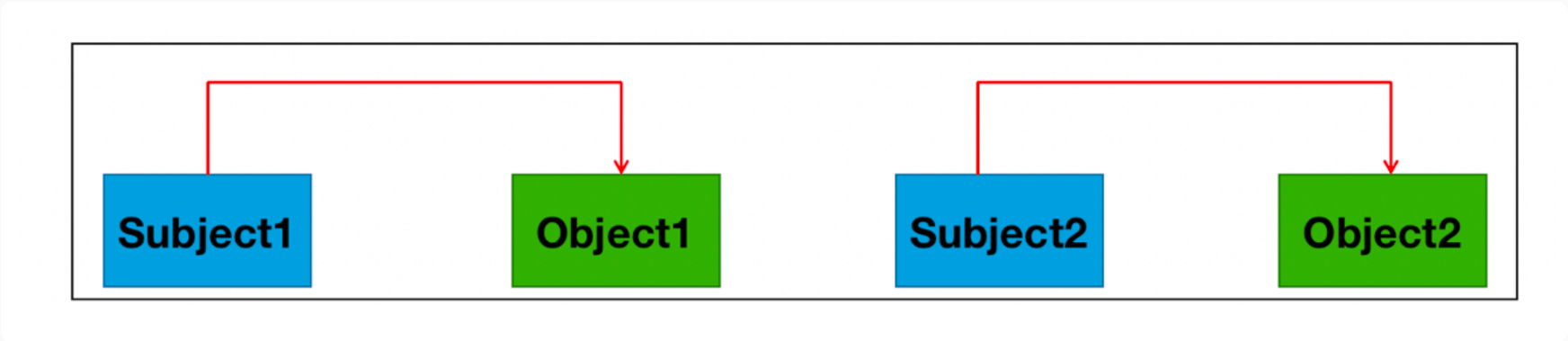
一对实体存在多种关系
eg: “周星驰导演了《功夫》,并担任男主角”中存在2种关系: (周星驰-演员-《功夫》) 、 (周星驰-导演-《功夫》)
五、基于规则实现关系抽取
5.1 实现原理
1. 定义关系集合类型:【夫妻关系、合作关系。。。】
2. 去除非实体和关系的文本
3. 基于实体列表和关系列表遵循就近原则匹配,实现spo三元组的组合(抽取)
5.2 代码实现
# 导入需要的工具包
import jieba
import jieba.posseg as pseg# 需要进行关系抽取的样本数据
samples = ["2014年1月8日,杨幂与刘恺威的婚礼在印度尼西亚巴厘岛举行","周星驰和吴孟达在《逃学威龙》中合作出演",'成龙出演了《警察故事》等多部经典电影']# 1。定义需要抽取的关系集合
relations2dict = {'夫妻关系':['结婚', '领证', '婚礼'],'合作关系': ['搭档', '合作', '签约'],'演员关系': ['出演', '角色', '主演']}# 2。遍历每一段文本,去除非实体和非关系的词语
for text in samples:print("原始文本:", text)# 定义空列表entityentites = [] # 存储实体relations = [] # 存储关系movie_name = [] # 存储电影名称for word, flag in pseg.lcut(text):# 寻找人名这个实体if flag == 'nr':entites.append(word)# 如果是电影名称需要特殊处理elif flag == 'x':if len(movie_name) == 0:movie_name.append(text.index(word))else:movie_name.append(text.index(word))entites.append(text[movie_name[0]+1: movie_name[1]])# 寻找关系else:for key, value in relations2dict.items():if word in value:relations.append(key)print(entites)print(relations)if len(entites) >= 2 and len(relations) >=1:print('提取结果:', entites[0] + '->' + relations[0] + '->' + entites[1])else:print("不好意思,暂时没有抽取出spo三元组")print('*'*80)
5.3 优缺点
简单、在较小的数据集上表现不错
泛化性能较差,可移植性较差