音视频学习笔记
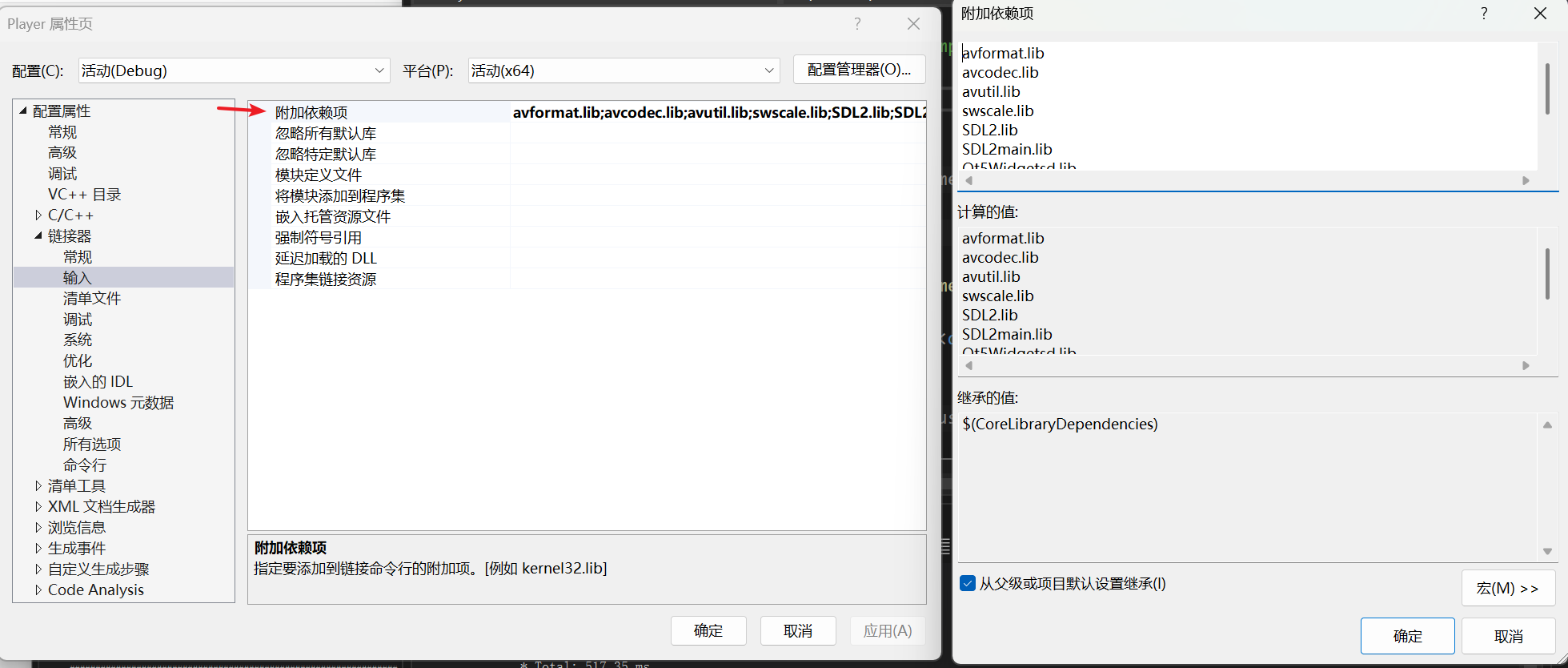
0.vs应用其他库配置
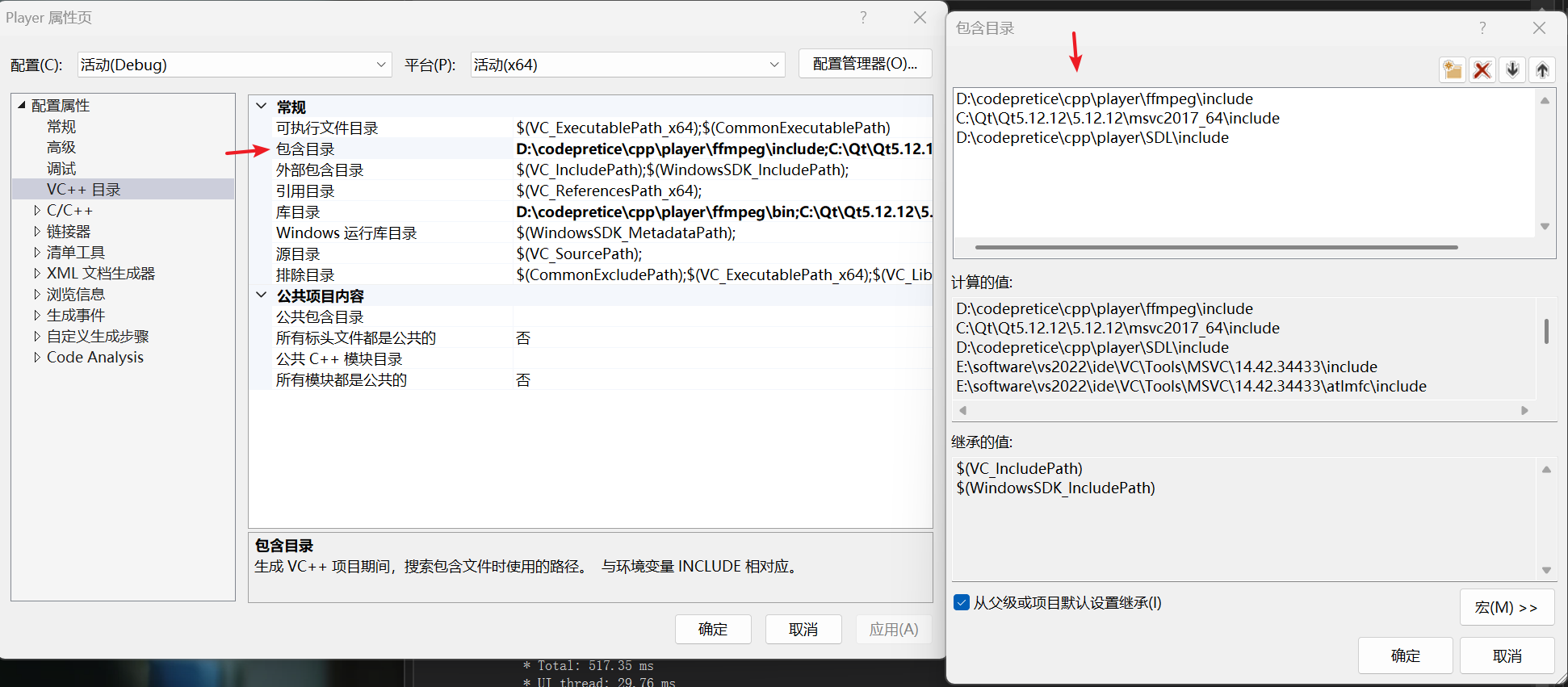
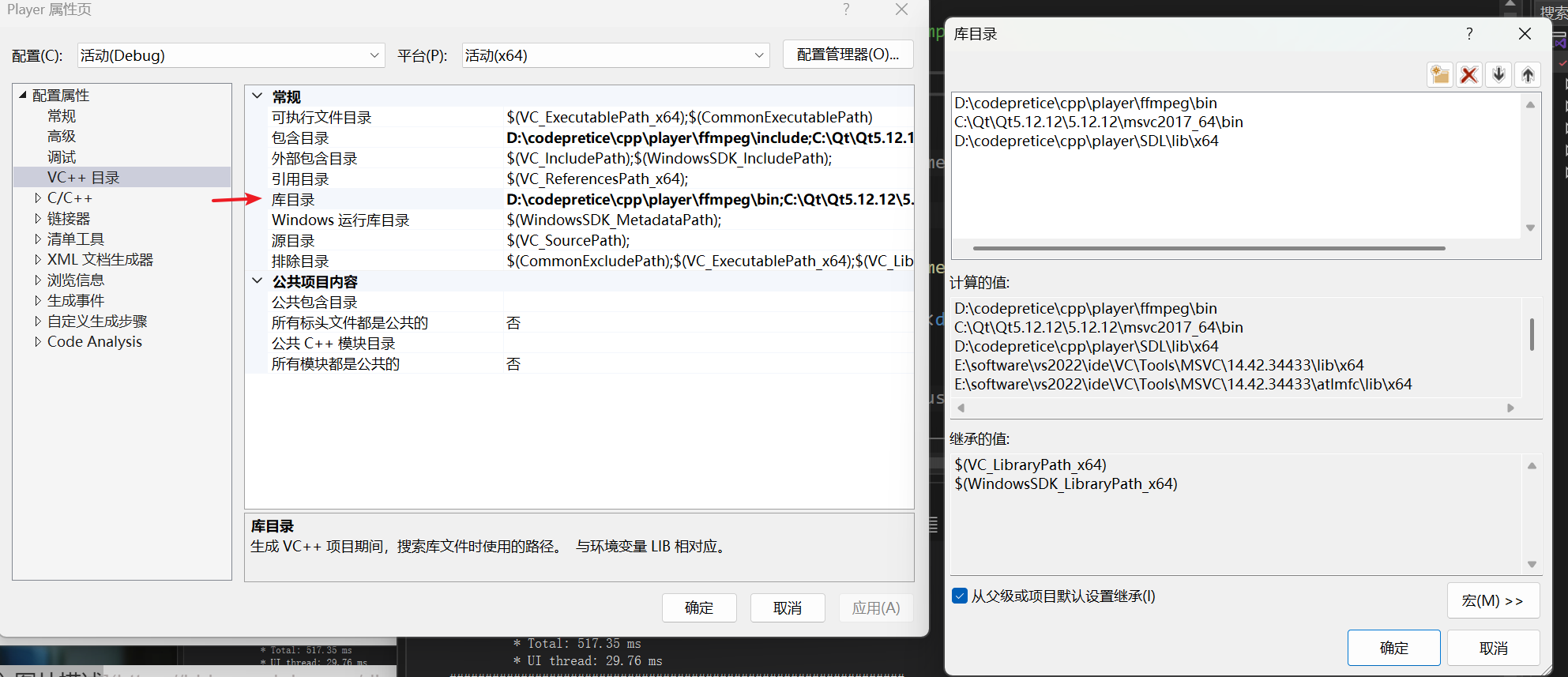
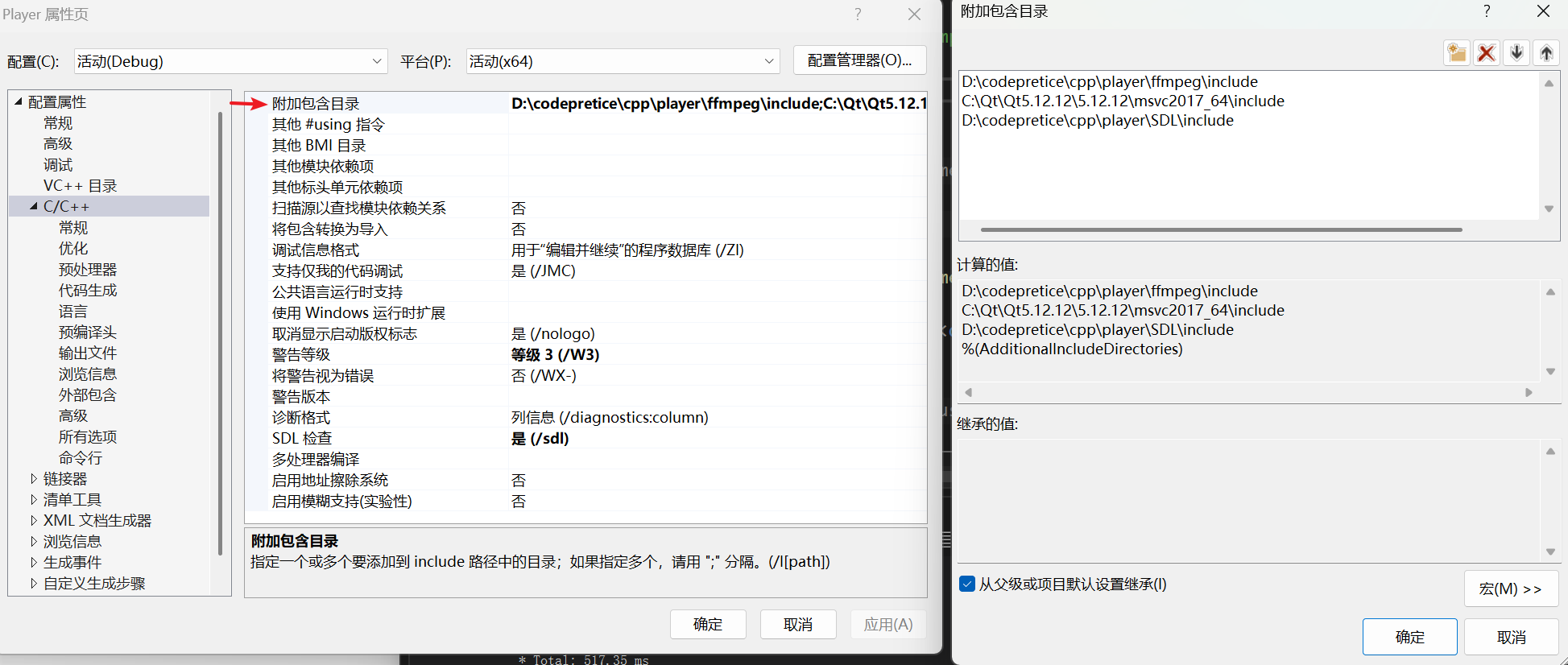
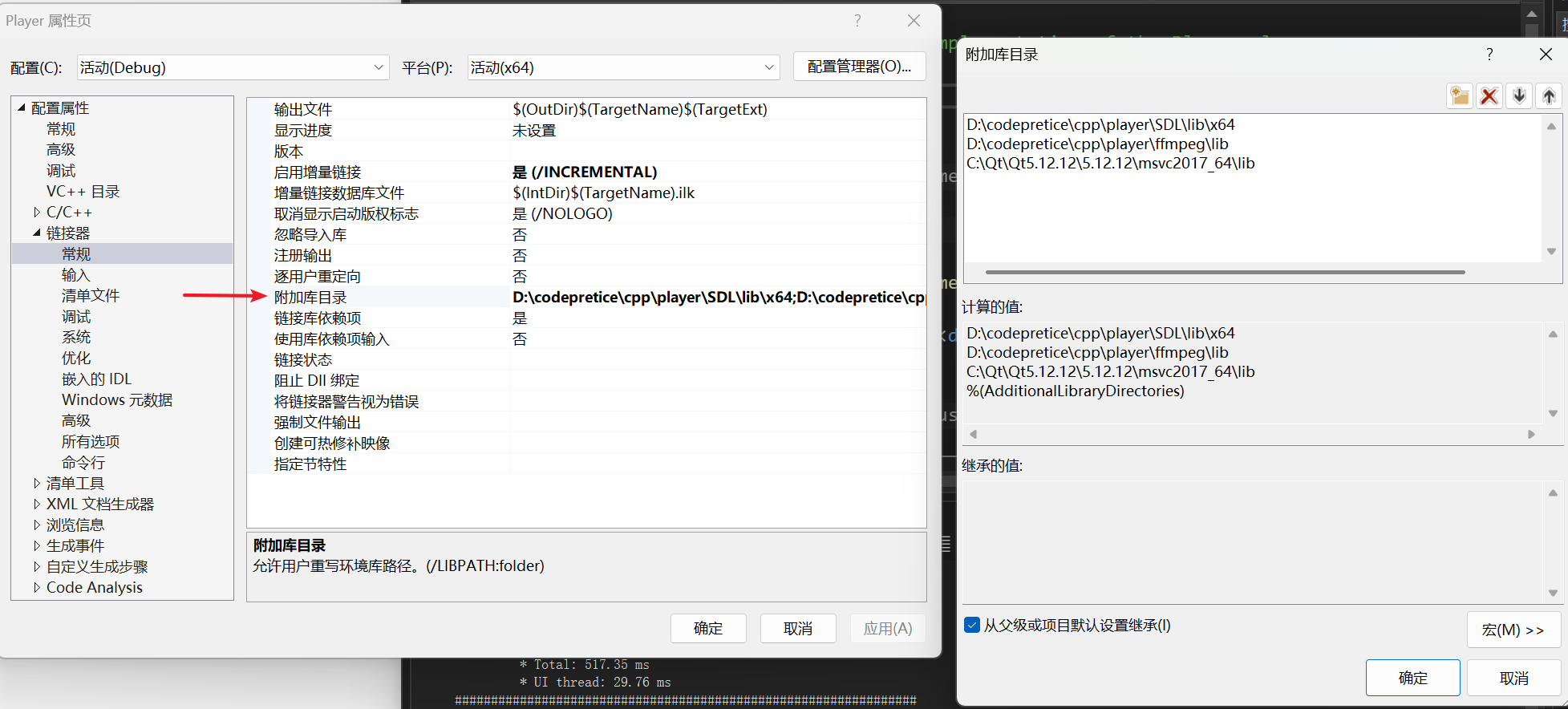
1基础
1.1视频基础
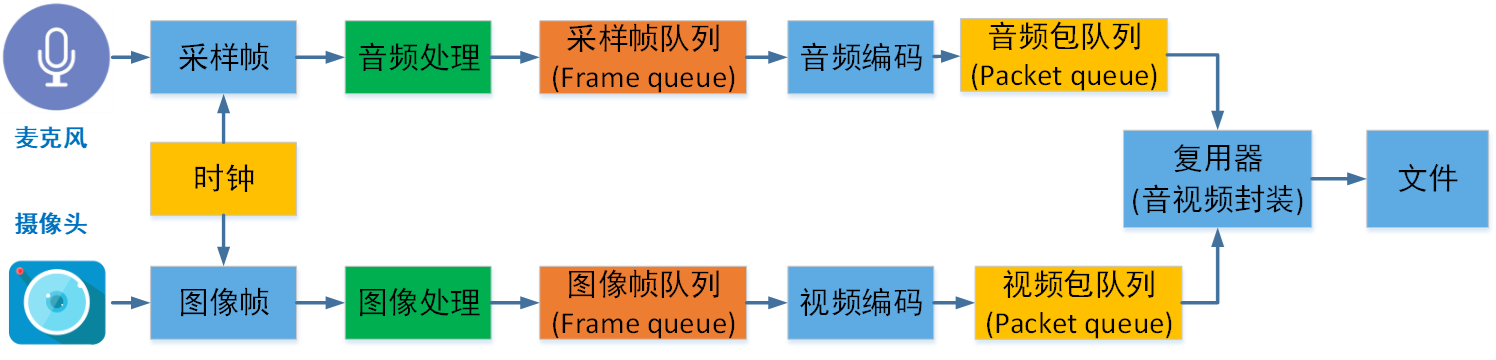
音视频录制原理
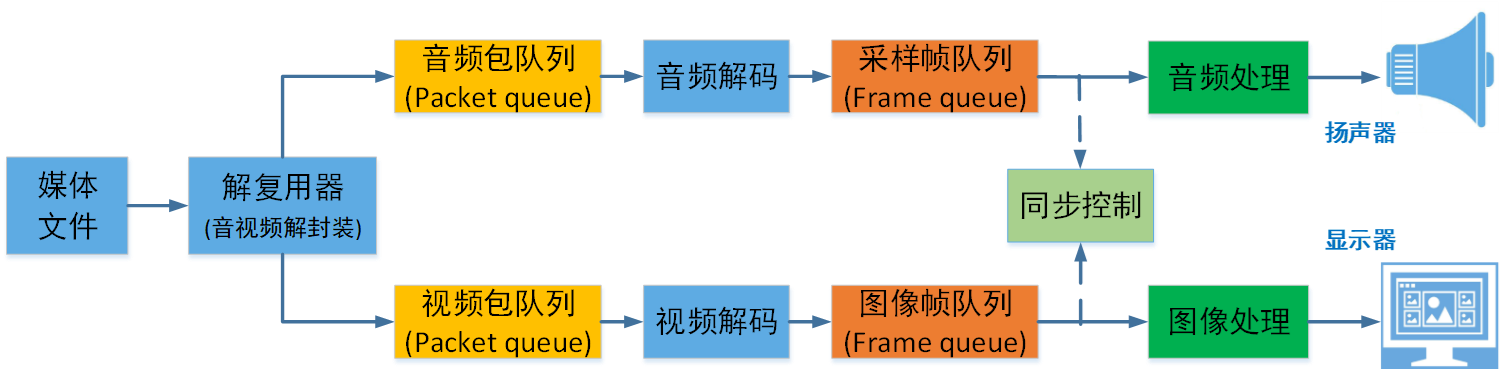
音视频播放原理
图像表示rgb

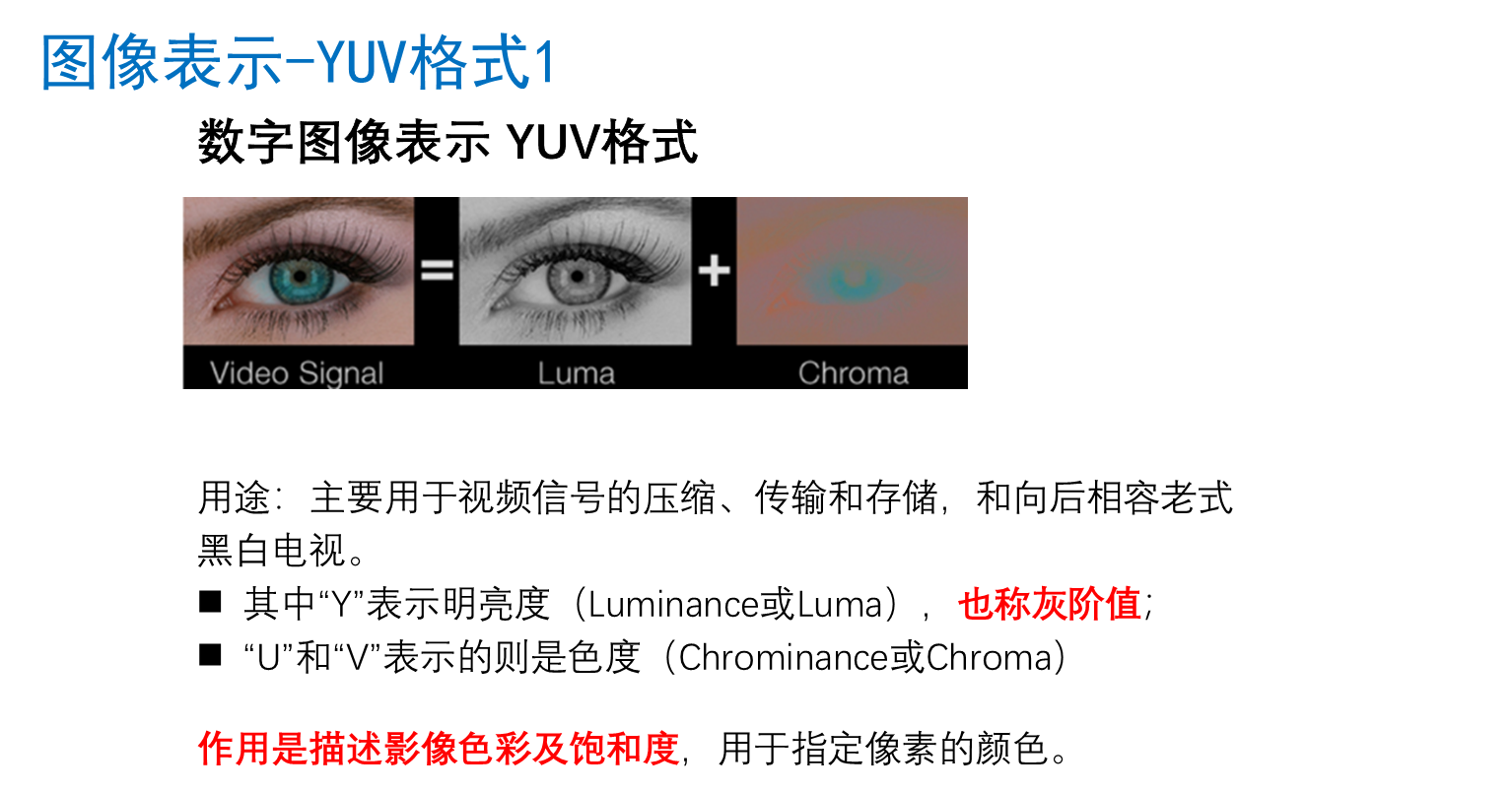
图像表示yuv
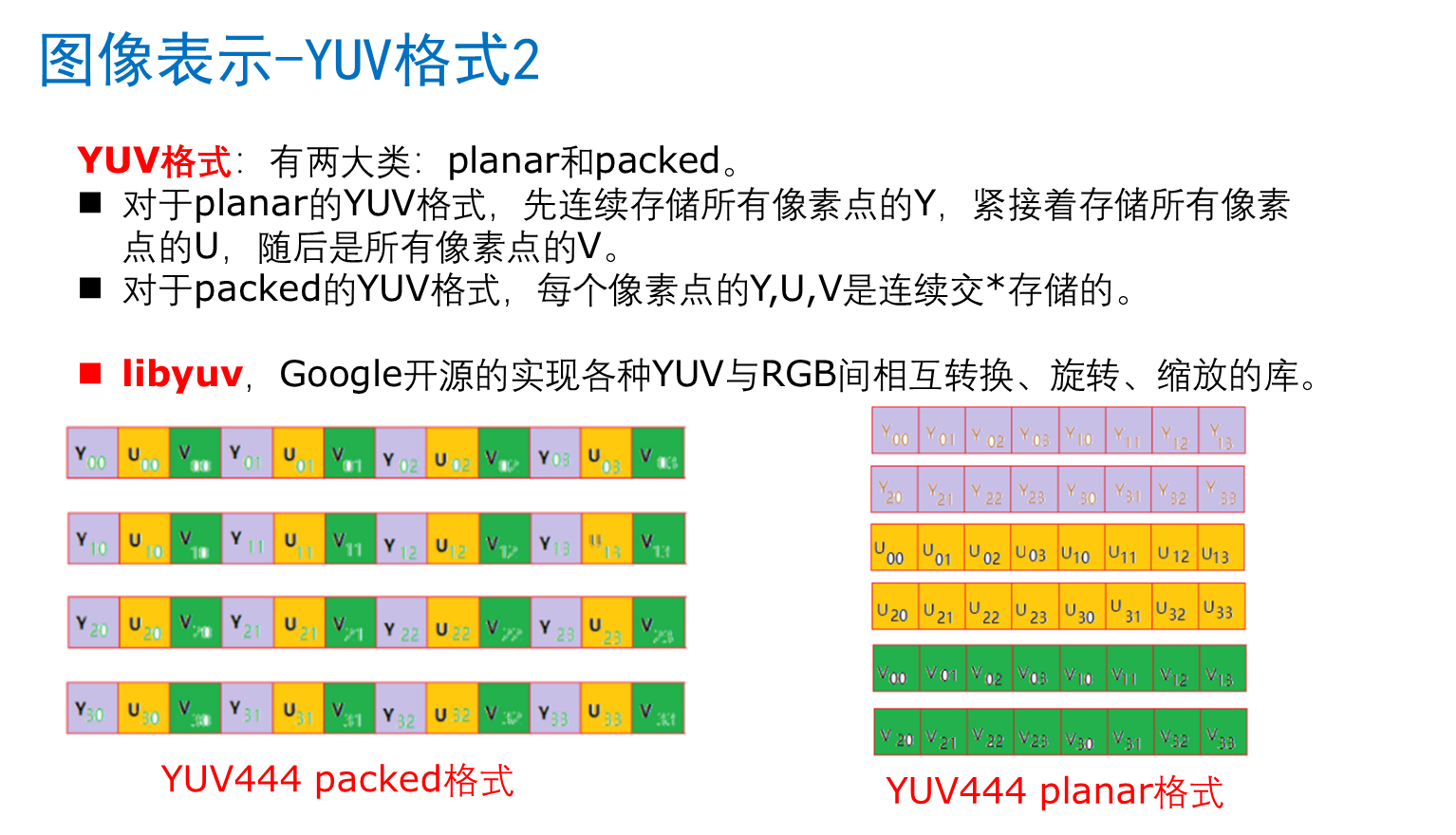
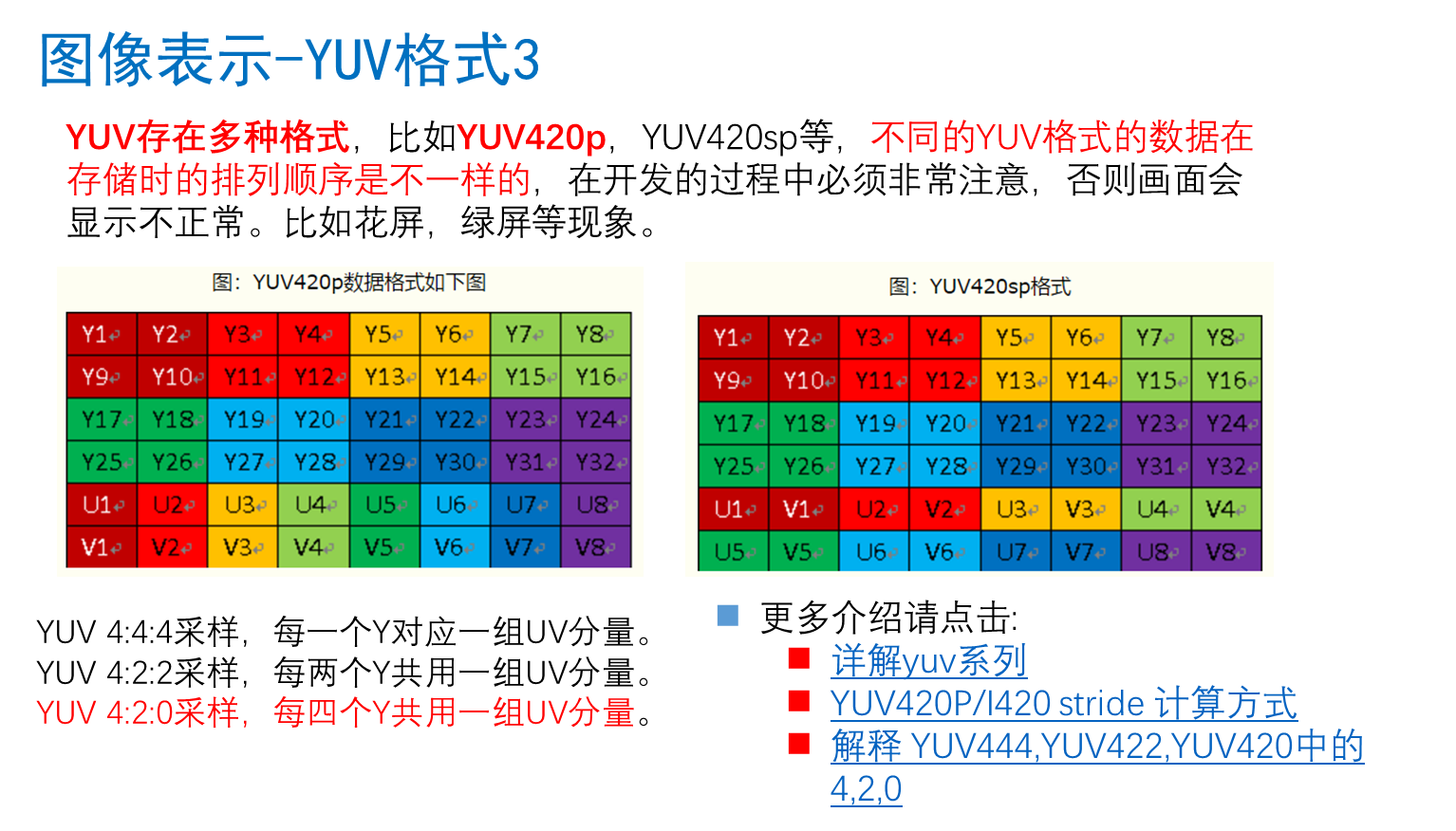
https://blog.51cto.com/u_7335580/2059670
https://blog.51cto.com/cto521/1944224
https://blog.csdn.net/mandagod/article/details/78605586?locationNum=7&fps=1
视频主要概念


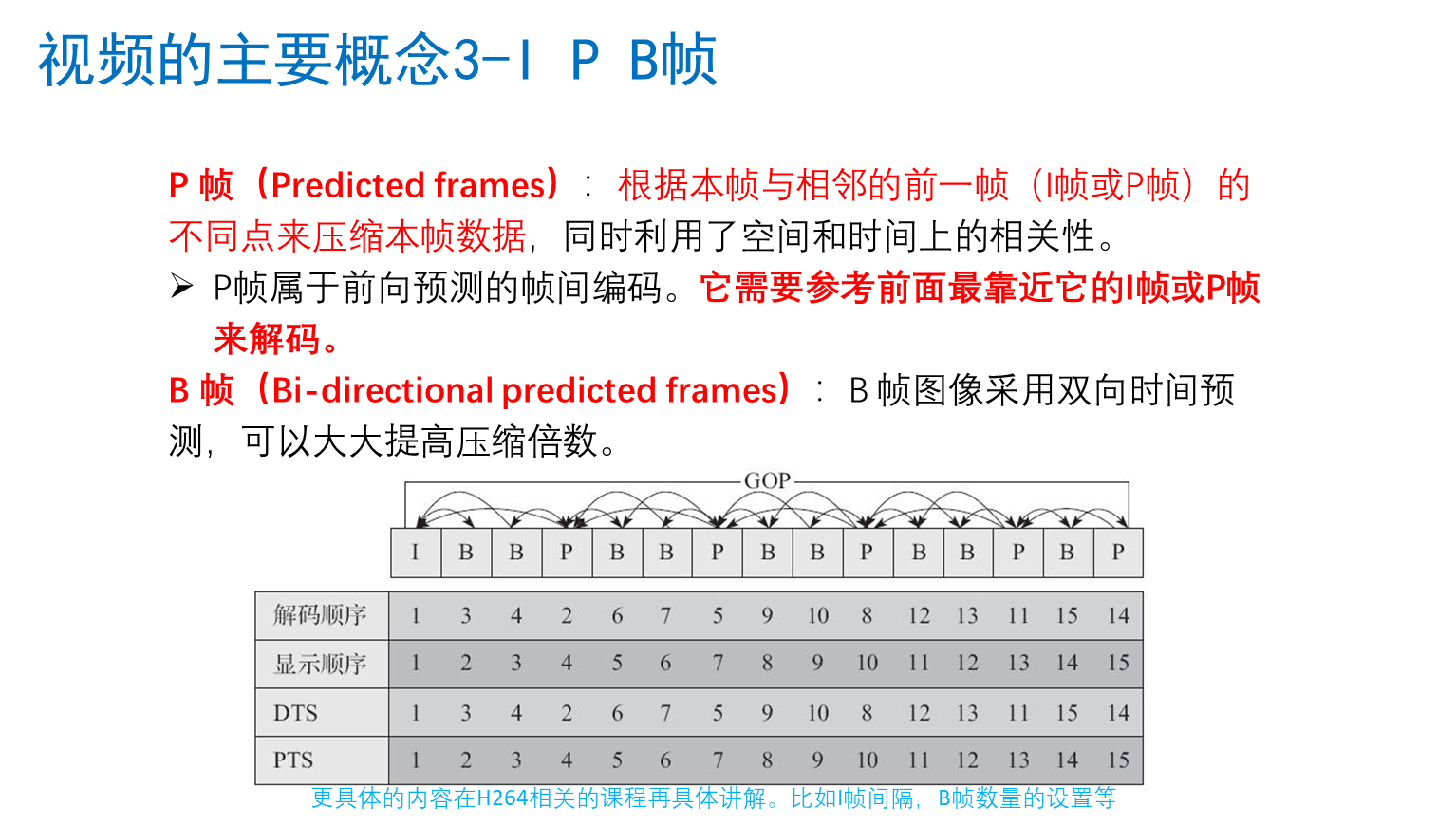
视频常用压缩算法

1.2音频基础
声音的物理性质
声音是一种由物体振动引发的物理现象,如小提琴的弦声等。物体的振动使其四周空气的压强产生变化,这种忽强忽弱变化以波的形式向四周传播,当被人耳所接收时,我们就听见了声音。
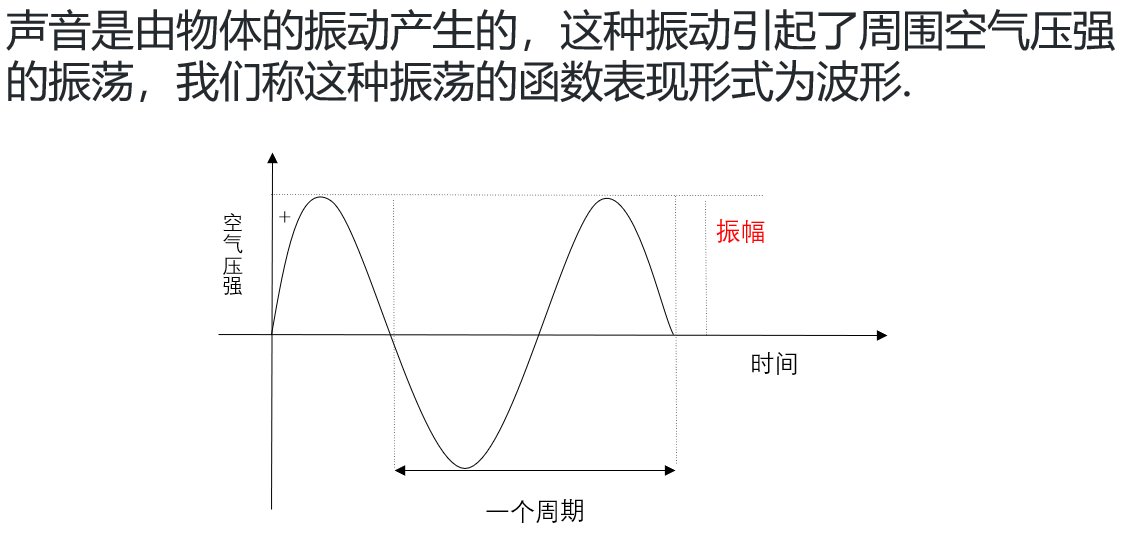
声音是由物体的振动产生的,这种振动引起了周围空气压强的振荡,我们称这种振荡的函数表现形式为波形.
声音的频率是周期的倒数,它表示的是声音在1秒钟内的周期数,单位是赫兹(Hz)。千赫(kHz),即1000Hz,表示每秒振动1000次。声音按频率可作如下划分:
次声 0~20Hz
人耳能听见的声音 20Hz~20KHz
超声 20KHz~1GHz
特超声 1GHz~10THz
声音有振幅,振幅的主观感觉是声音的大小。声音的振幅大小取决于空气压力波距平均值(也称平衡态)的最大偏移量。
数字音频
采样频率
根据Nyguist采样定律,要从采样中完全恢复原始信号波形,采样频率必须至少是信号中最高频率的两倍。
前面提到人耳能听到的频率范围是[20H~20kHz],所以采样频率一般为44.1Khz,这样就能保证声音到达20Khz也能被数字化,从而使得经过数字化处理之后,人耳听到的声音质量不会被降低。
采样频率:每秒钟采样的点的个数。常用的采样频率有:
22000(22kHz): 无线广播。
44100(44.1kHz): CD音质。
48000(48kHz): 数字电视,DVD。
96000(96kHz): 蓝光,高清DVD。
192000(192kHz): 蓝光,高清DVD。
采样量化
采样是在离散的时间点上进行的,而采样值本身在计算机中也是离散的。
采样值的精度取决于它用多少位来表示,这就是量化。例如8位量化可以表示256个不同值,而CD质量的16位量化可以表示65 536个值,范围为[-32768, 32767]。
下图是一个3位量化的示意图,可以看出3位量化只能表示8个值:0.75,0.5,0.25,0,─0.25,─0.5,─0.75和 ─1,因而量化位数越少,波形就越难辨认,还原后的声音质量也就越差(可能除了一片嗡嗡声之外什么都没有)
音频常见名词
采样频率:每秒钟采样的点的个数。
采样精度(采样深度):每个“样本点”的大小,常用的大小为8bit, 16bit,24bit。
通道数:单声道,双声道,四声道,5.1声道。
比特率:每秒传输的bit数,单位为:bps(Bit Per Second)间接衡量声音质量的一个标准。
没有压缩的音频数据的比特率 = 采样频率 * 采样精度 * 通道数。
码率: 压缩后的音频数据的比特率。常见的码率:
96kbps: FM质量 128-160kbps:一般质量音频。
192kbps: CD质量 256-320Kbps:高质量音频
码率越大,压缩效率越低,音质越好,压缩后数据越大。码率 = 音频文件大小/时长。
帧:每次编码的采样单元数,比如MP3通常是1152个采样点作为一个编码单元,AAC通常是1024个采样点作为一个编码单元。
帧长:可以指每帧播放持续的时间:每帧持续时间(秒) = 每帧采样点数 / 采样频率(HZ)
比如:MP3 48k, 1152个采样点,每帧则为 24毫秒
1152/48000= 0.024 秒 = 24毫秒;
也可以指压缩后每帧的数据长度。
交错模式:数字音频信号存储的方式。数据以连续帧的方式存放,即首先记录帧1的左声道样本和右声道样本,再开始帧2的记录
非交错模式:首先记录的是一个周期内所有帧的左声道样本,再记录所有右声道样本
音频编码原理简介
数字音频压缩编码在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩,降低数据量。数字音频压缩编码采取去除声音信号中冗余成分的方法来实现。所谓冗余成分指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助
冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为20Hz~20KHz,除此之外的其它频率人耳无法察觉,都可视为冗余信号。
此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应,主要表现在频谱掩蔽效应和时域掩蔽效应。
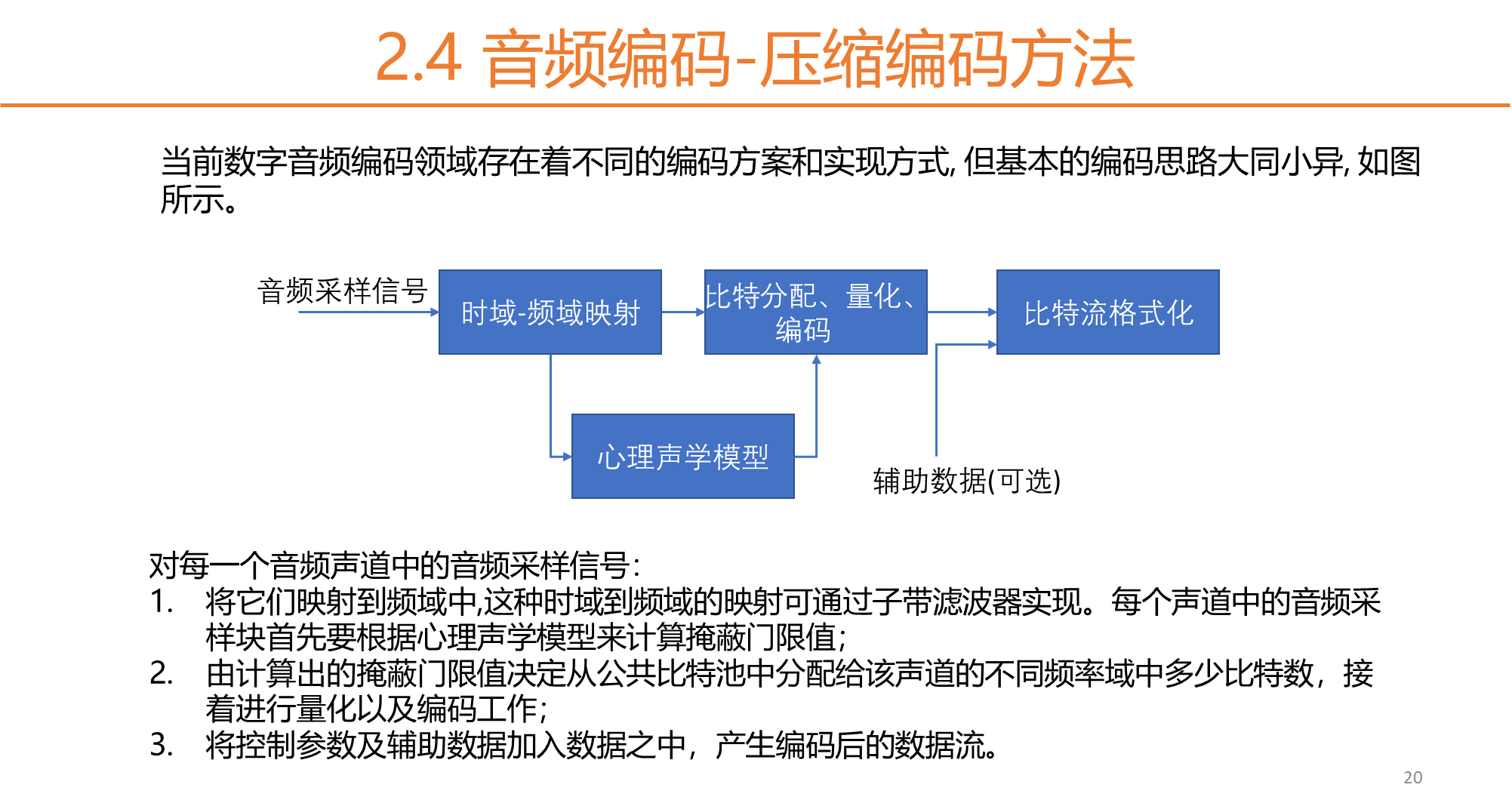
1.3封装格式与音视频同步
封装格式(也叫容器)就是将已经编码压缩好的视频流、音频流及字幕按照一定的方案放到一个文件中,便于播放软件播放。
一般来说,视频文件的后缀名就是它的封装格式。
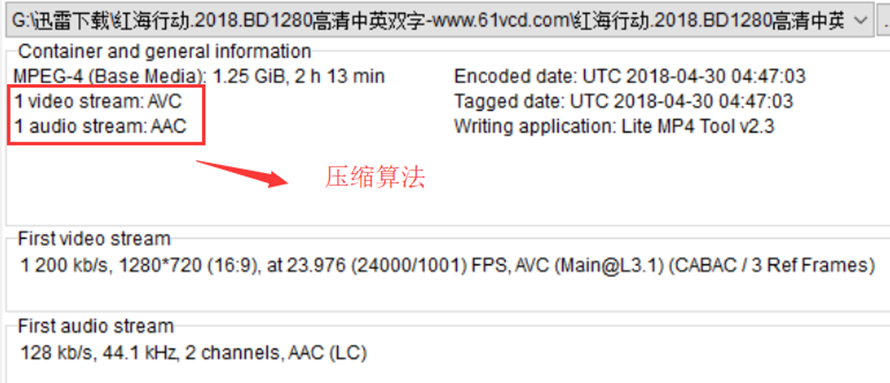
这里的压缩算法:
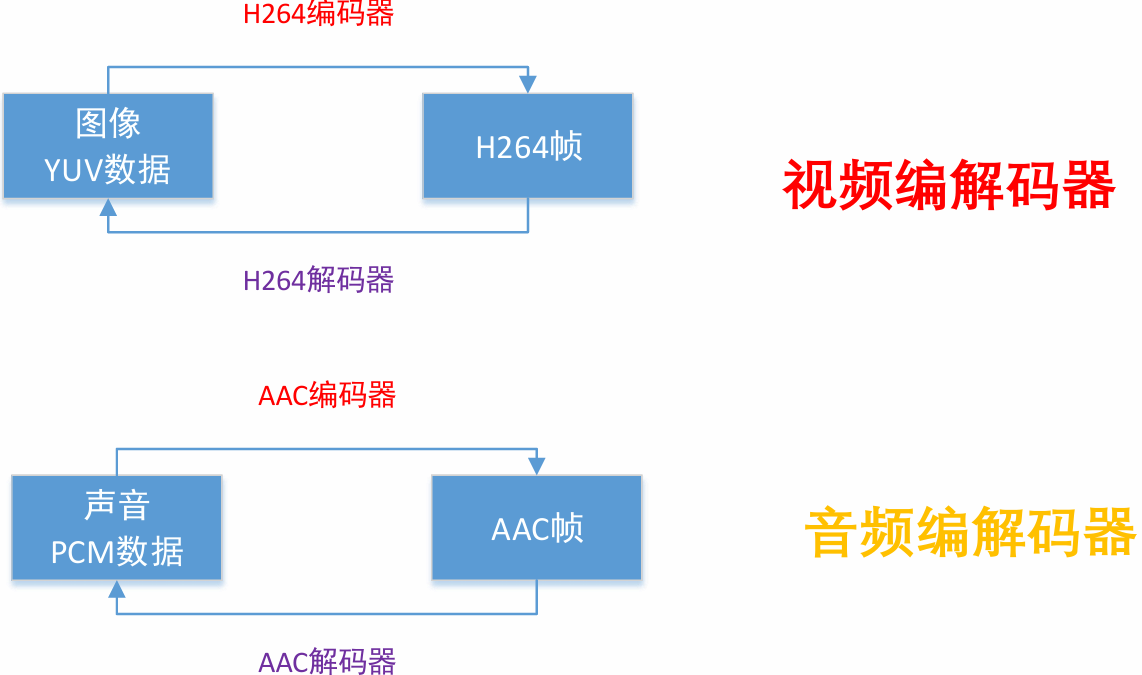
视频Video:使用了H264/AVC压缩算法
音频Audio:使用了AAC压缩算法
封装则使用MP4封装格式
常见的视频封装格式
H264+AAC封装为FLV或MP4是最为流行的模式
音视频同步概念
DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。
PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。
音视频同步方式
Audio Master:同步视频到音频
Video Master:同步音频到视频
External Clock Master:同步音频和视频到外部时钟。
一般情况下 Audio Master > External Clock Master > Video Master
2开发环境配置
2.1命令行环境搭建
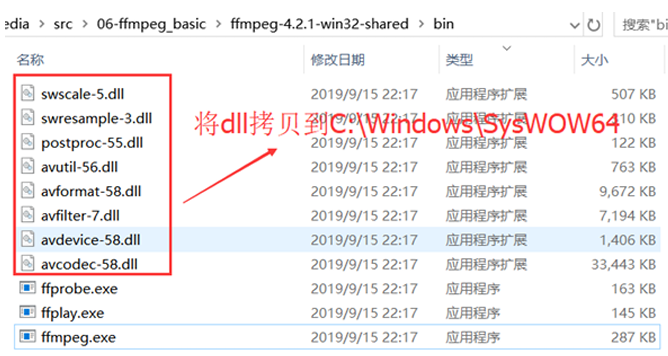
解压ffmpeg-4.2.1-win32-shared.zip
拷⻉可执⾏⽂件到C:\Windows
![[1]](https://i-blog.csdnimg.cn/direct/91a7f27aad7d4f2ba19f91dedede77ca.png)
拷⻉动态链接库到C:\Windows\SysWOW64
(WoW64 (Windows On Windows64 )是⼀个Windows操作系统的⼦系统,被设计⽤来处理许多在
32-bit Windows和64-bit Windows之间的不同的问题,使得可以在64-bit Windows中运⾏32-bit程
序。
3.SDL视频渲染
官网:https://www.libsdl.org/
文档:http://wiki.libsdl.org/Introduction
SDL(Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发库,使用C语言写成。SDL提供了数种控制图像、声音、输出入的函数,让开发者只要用相同或是相似的代码就可以开发出跨多个平台(Linux、Windows、Mac OS X等)的应用软件。目前SDL多用于开发游戏、模拟器、媒体播放器等多媒体应用领域。SDL主要用来辅助学习FFmpeg,
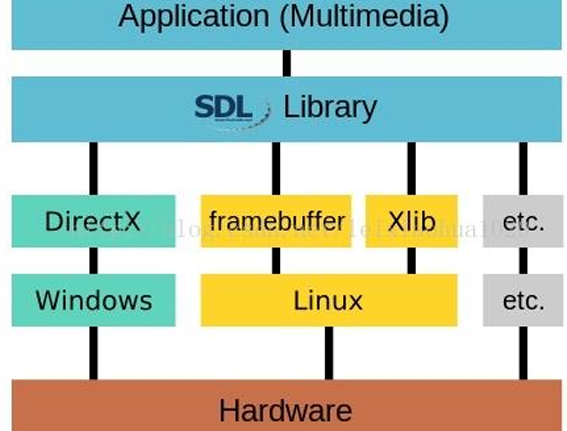
SDL子系统
SDL将功能分成下列数个子系统(subsystem):
◼ SDL_INIT_TIMER:定时器
◼ SDL_INIT_AUDIO:音频
◼ SDL_INIT_VIDEO:视频
◼ SDL_INIT_JOYSTICK:摇杆
◼ SDL_INIT_HAPTIC:触摸屏
◼ SDL_INIT_GAMECONTROLLER:游戏控制器
◼ SDL_INIT_EVENTS:事件
◼ SDL_INIT_EVERYTHING:包含上述所有选项
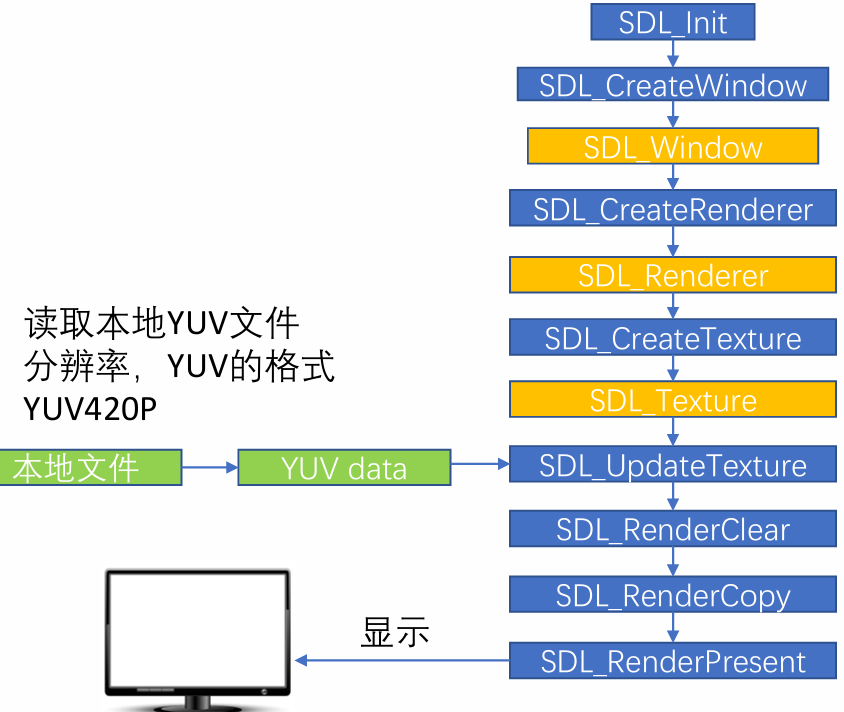
SDL Window显示:SDL视频显示函数简介
◼ SDL_Init():初始化SDL系统
◼ SDL_CreateWindow():创建窗口SDL_Window
◼ SDL_CreateRenderer():创建渲染器SDL_Renderer
◼ SDL_CreateTexture():创建纹理SDL_Texture
◼ SDL_UpdateTexture():设置纹理的数据
◼ SDL_RenderCopy():将纹理的数据拷贝给渲染器
◼ SDL_RenderPresent():显示
◼ SDL_Delay():工具函数,用于延时
◼ SDL_Quit():退出SDL系统
SDL Windows显示:SDL数据结构简介
◼ SDL_Window 代表了一个“窗口”
◼ SDL_Renderer 代表了一个“渲染器”
◼ SDL_Texture 代表了一个“纹理”
◼ SDL_Rect 一个简单的矩形结构
存储RGB和存储纹理的区别:
比如一个从左到右由红色渐变到蓝色的矩形,用存储RGB的话就需要把矩形中每个点的具体颜色
值存储下来;而纹理只是一些描述信息,比如记录了矩形的大小、起始颜色、终止颜色等信息,
显卡可以通过这些信息推算出矩形块的详细信息。所以相对于存储RGB而已,存储纹理占用的内存
要少的多
SDL事件
◼ 函数
• SDL_WaitEvent():等待一个事件
• SDL_PushEvent():发送一个事件
• SDL_PumpEvents():将硬件设备产生的事件放入事件队列,用于读取事件,在调用该函数之前,必须调用SDL_PumpEvents搜集键盘等事件
• SDL_PeepEvents():从事件队列提取一个事件
◼ 数据结构
• SDL_Event:代表一个事件
SDL线程
SDL多线程
◼ SDL线程创建:SDL_CreateThread
◼ SDL线程等待:SDL_WaitThead
◼ SDL互斥锁:SDL_CreateMutex/SDL_DestroyMutex
◼ SDL锁定互斥:SDL_LockMutex/SDL_UnlockMutex
◼ SDL条件变量(信号量):SDL_CreateCond/SDL_DestoryCond
◼ SDL条件变量(信号量)等待/通知:SDL_CondWait/SDL_CondSingal
SDL YUV显示:SDL视频显示的流程
SDL播放音频PCM-打开音频设备

SDL播放音频PCM-SDL_AudioCallback

4ffmpeg1
4.1ffmpeg命令(略)
4.2ffmpeg基础
播放器框架
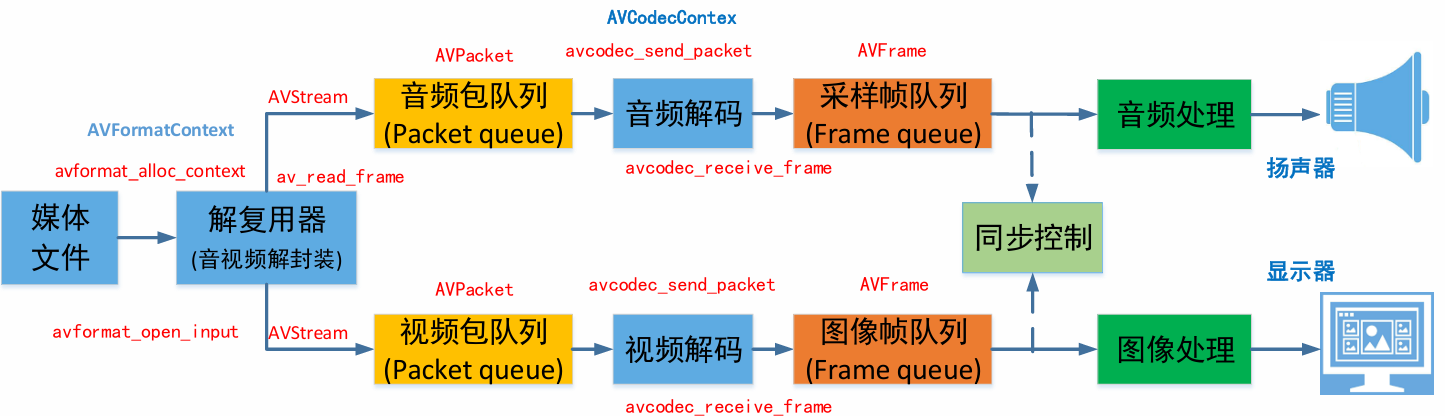
常用音视频术语
容器/文件(Conainer/File):即特定格式的多媒体文件,比如mp4、flv、mkv等。
• 媒体流(Stream):表示时间轴上的一段连续数据,如一段声音数据、一段视频数据或一段字幕数据,可以是压缩的,也可以是非压缩的,压缩的数据需要关联特定的编解码器(有些码流音频他是纯PCM)。
• 数据帧/数据包(Frame/Packet):通常,一个媒体流是由大量的数据帧组成的,对于压缩数据,帧对应着编解码器的最小处理单元,分属于不同媒体流的数据帧交错存储于容器之中。
• 编解码器:编解码器是以帧为单位实现压缩数据和原始数据之间的相互转换的。
复用器
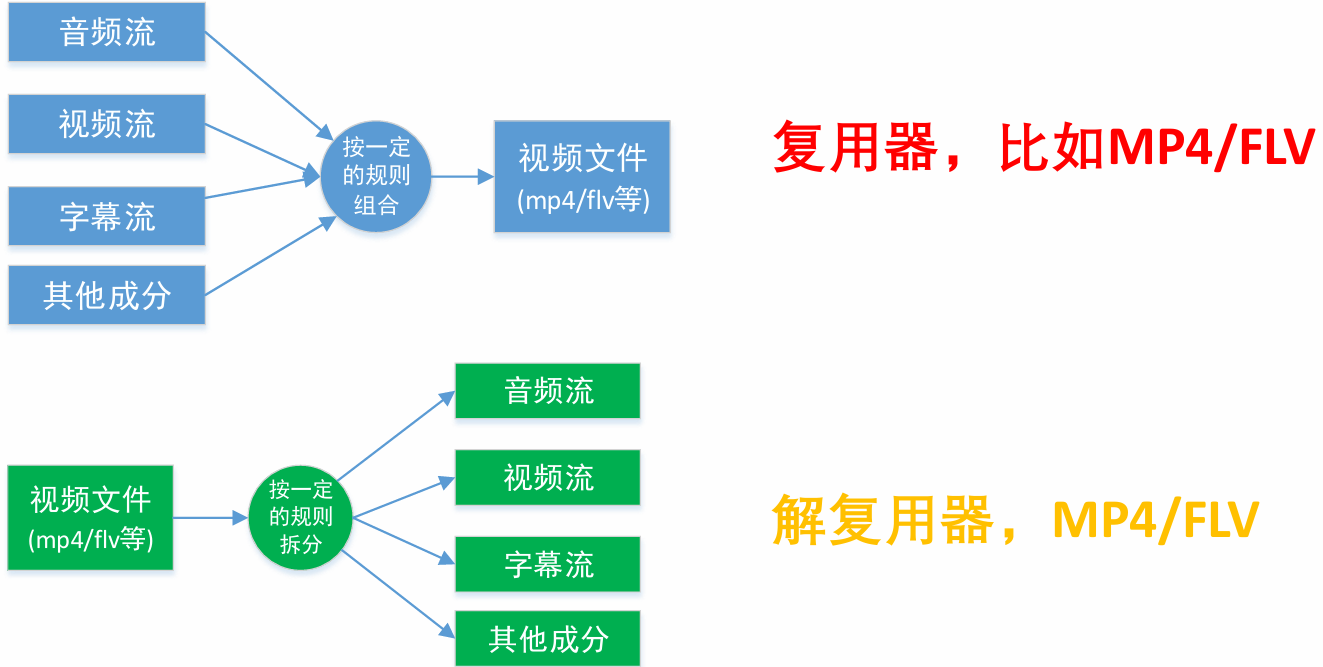
编解码器
FFmpeg库简介
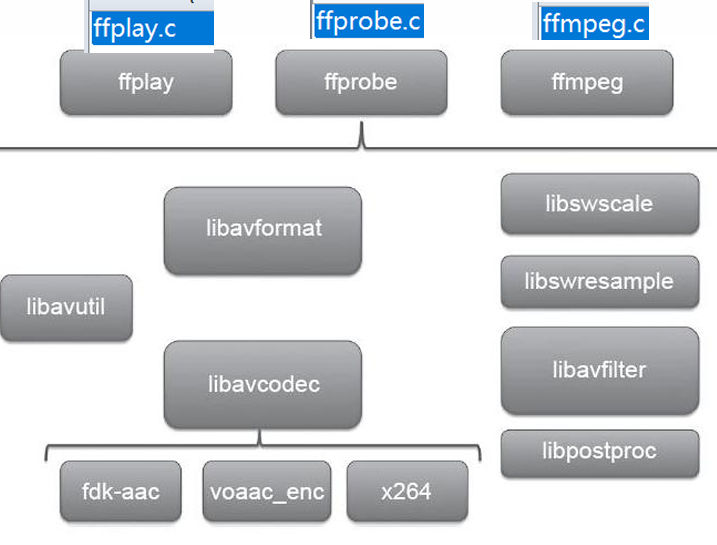
FFMPEG有8个常用库:
• AVUtil:核心工具库,下面的许多其他模块都会依赖该库做一些基本的音视频处理操作。
• AVFormat:文件格式和协议库,该模块是最重要的模块之一,封装了Protocol层和Demuxer、Muxer层,使得协议和格式对于开发者来说是透明的。
• AVCodec:编解码库,封装了Codec层,但是有一些Codec是具备自己的License的,FFmpeg是不会默认添加像libx264、FDK-AAC等库的,但是FFmpeg就像一个平台一样,可以将其他的第三方的Codec以插件的方式添加进来,然后为开发者提供统一的接口。
• AVFilter:音视频滤镜库,该模块提供了包括音频特效和视频特效的处理,在使用FFmpeg的API进行编解码的过程中,直接使用该模块为音视频数据做特效处理是非常方便同时也非常高效的一种方式。
AVDevice:输入输出设备库,比如,需要编译出播放声音或者视频的工具ffplay,就需要确保该模块是打开的,同时也需要SDL的预先编译,因为该设备模块播放声音与播放视频使用的都是SDL库。
• SwrRessample:该模块可用于音频重采样,可以对数字音频进行声道数、数据格式、采样率等多种基本信息的转换。
• SWScale:该模块是将图像进行格式转换的模块,比如,可以将YUV的数据转换为RGB的数据,缩放尺寸由1280720变为800480。
• PostProc:该模块可用于进行后期处理,当我们使用AVFilter的时候需要打开该模块的开关,因为Filter中会使用到该模块的一些基础函数。
FFmpeg函数简介
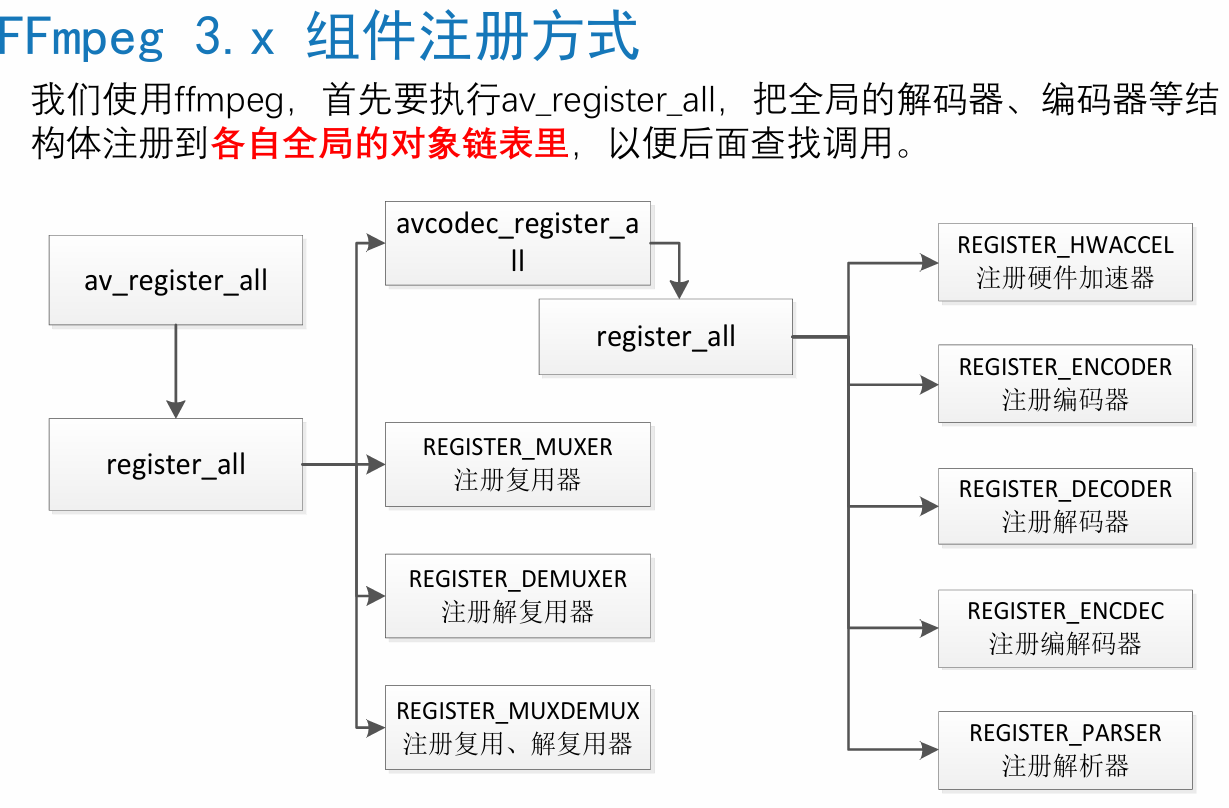
◼ av_register_all ():注册所有组件,4.0已经弃用
◼ avdevice_register_all()对设备进行注册,比如V4L2等。
◼ avformat_network_init();初始化网络库以及网络加密协议相关的库(比如openssl)
封装格式相关
◼ avformat_alloc_context();负责申请一个AVFormatContext结构的内存,并进行简单初始化
◼ avformat_free_context();释放该结构里的所有东西以及该结构本身
◼ avformat_close_input();关闭解复用器。关闭后就不再需要使用avformat_free_context 进行释放。
◼ avformat_open_input();打开输入视频文件
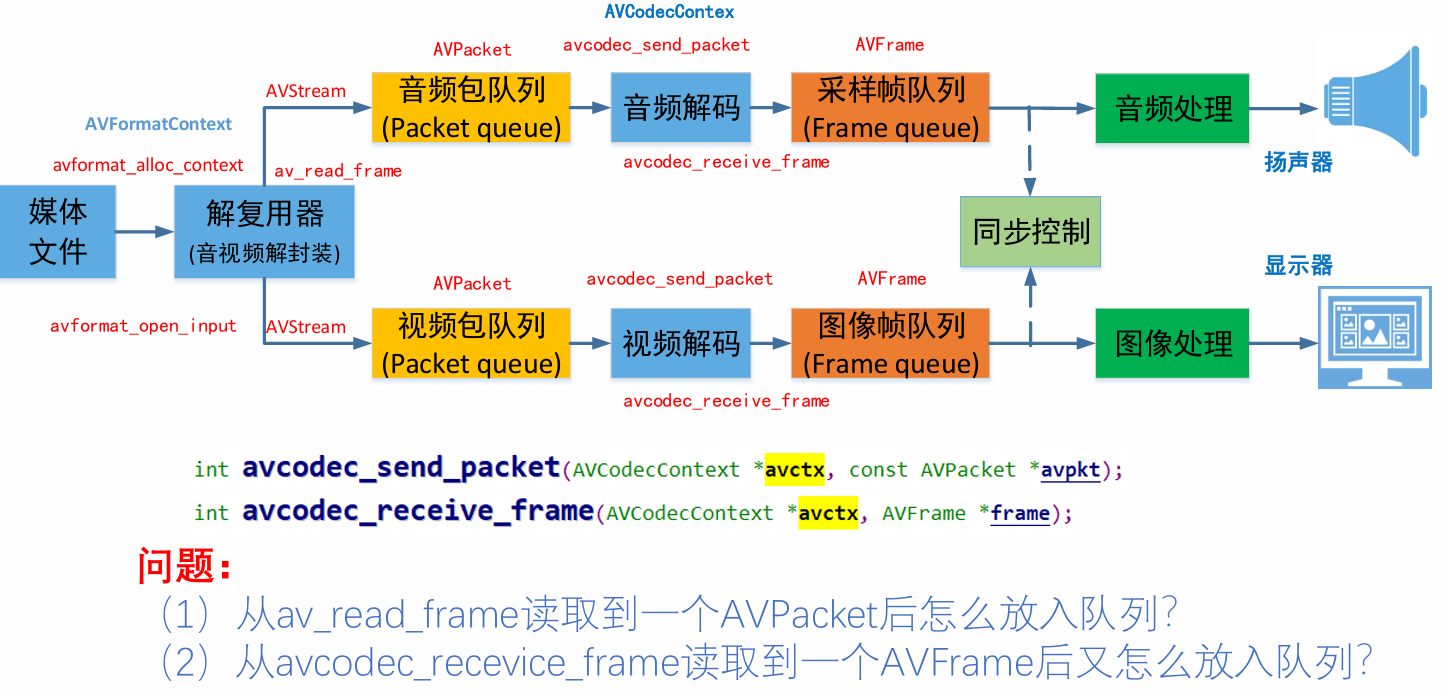
◼ avformat_find_stream_info():获取音视频文件信息
◼ av_read_frame(); 读取音视频包
◼ avformat_seek_file(); 定位文件
◼ av_seek_frame():定位文件
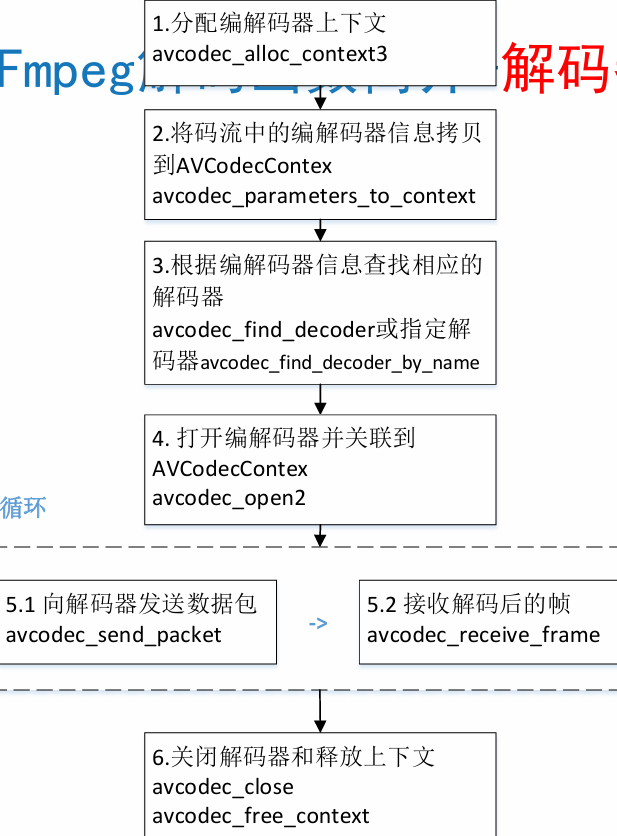
解码器相关
• avcodec_alloc_context3(): 分配解码器上下文
• avcodec_find_decoder():根据ID查找解码器
• avcodec_find_decoder_by_name():根据解码器名字
• avcodec_open2():打开编解码器
• avcodec_decode_video2():解码一帧视频数据
• avcodec_decode_audio4():解码一帧音频数据
• avcodec_send_packet(): 发送编码数据包
• avcodec_receive_frame(): 接收解码后数据
• avcodec_free_context():释放解码器上下文,包含了avcodec_close()
• avcodec_close():关闭解码器


FFmpeg数据结构简介
AVFormatContext 封装格式上下文结构体,也是统领全局的结构体,保存了视频文件封装格式相关信息。
AVInputFormat demuxer 每种封装格式(例如FLV, MKV, MP4, AVI)对应一个该结构体。
AVOutputFormat muxer
AVStream 视频文件中每个视频(音频)流对应一个该结构体。
AVCodecContext 编解码器上下文结构体,保存了视频(音频)编解码相关信息。
AVCodec 每种视频(音频)编解码器(例如H.264解码器)对应一个该结构体。
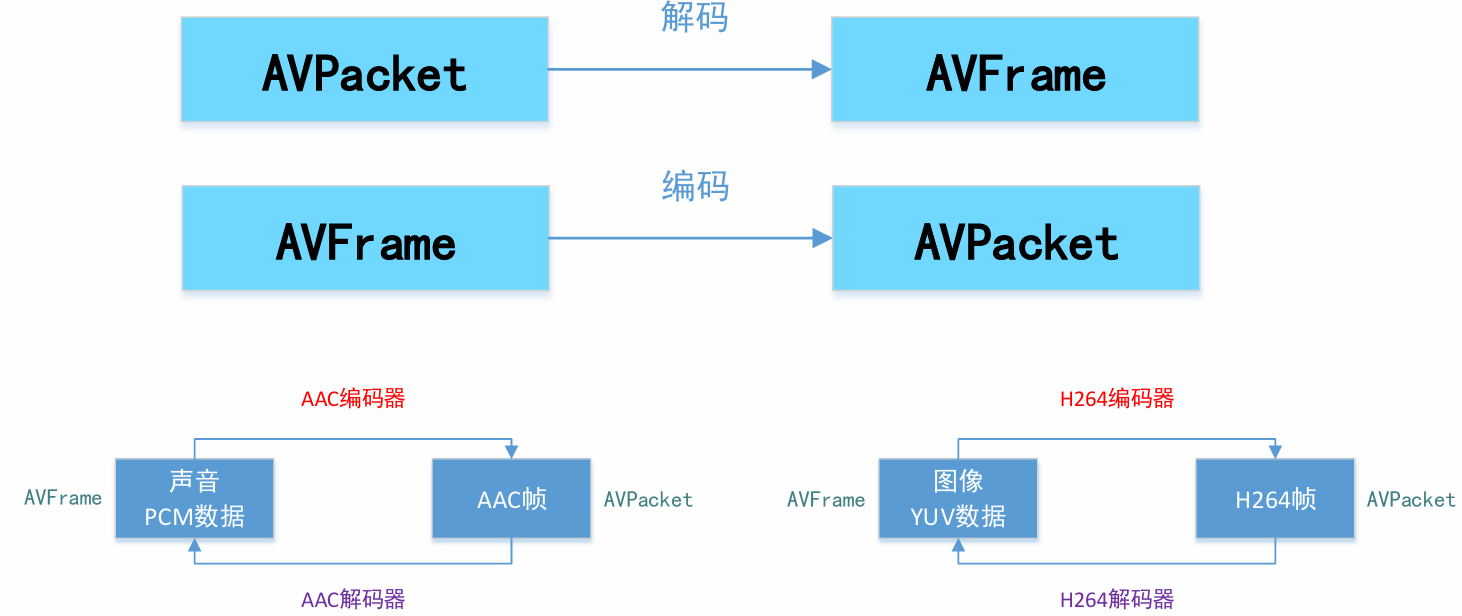
AVPacket 存储一帧压缩编码数据。
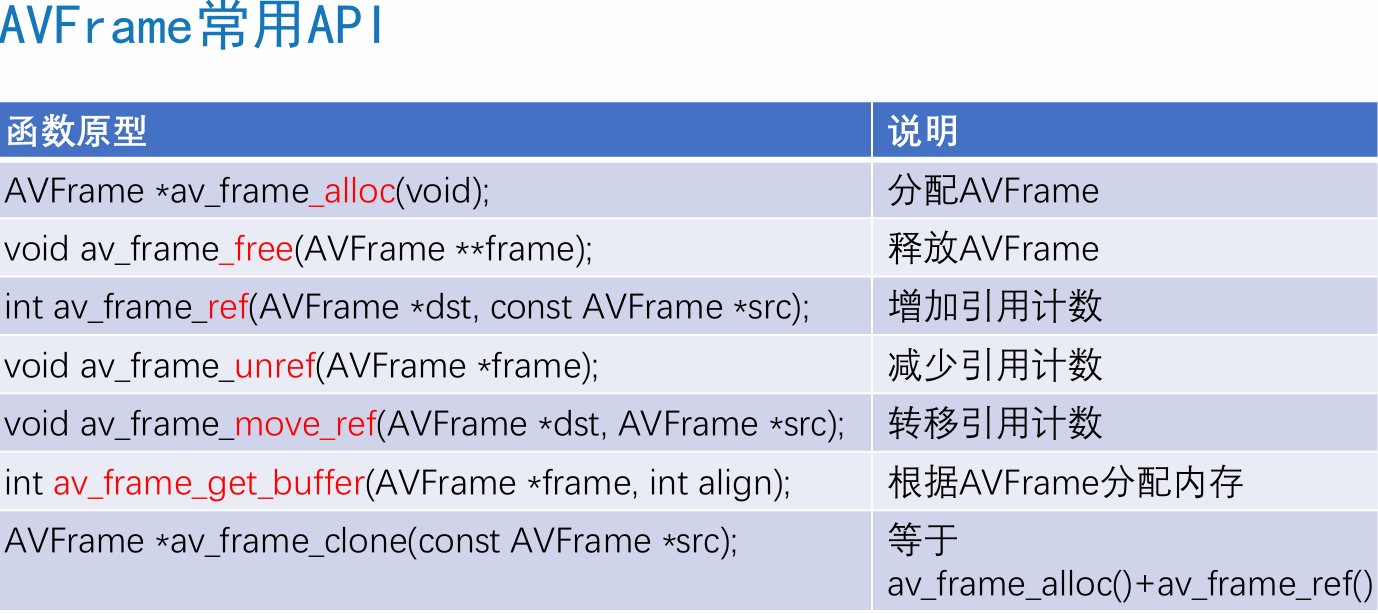
AVFrame 存储一帧解码后像素(采样)数据。
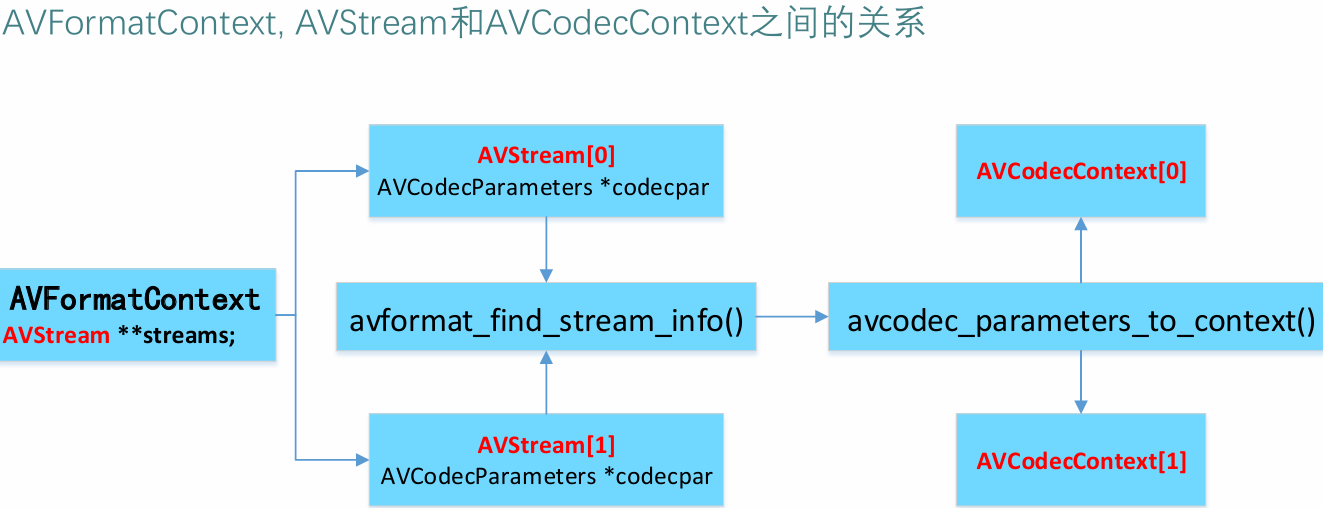
FFmpeg数据结构之间的关系


FFmpeg数据结构分析
◼ AVFormatContext
• iformat:输入媒体的AVInputFormat,比如指向AVInputFormat ff_flv_demuxer
• nb_streams:输入媒体的AVStream 个数
• streams:输入媒体的AVStream []数组
• duration:输入媒体的时长(以微秒为单位),计算方式可以参考av_dump_format()函数。
• bit_rate:输入媒体的码率
◼ AVInputFormat
• name:封装格式名称
• extensions:封装格式的扩展名
• id:封装格式ID
• 一些封装格式处理的接口函数,比如read_packet()
◼ AVStream
• index:标识该视频/音频流
• time_base:该流的时基,PTS*time_base=真正的时间(秒)
• avg_frame_rate: 该流的帧率
• duration:该视频/音频流长度
• codecpar:编解码器参数属性
◼ AVCodecParameters
• codec_type:媒体类型,比如AVMEDIA_TYPE_VIDEO AVMEDIA_TYPE_AUDIO等
• codec_id:编解码器类型, 比如AV_CODEC_ID_H264 AV_CODEC_ID_AAC等。
◼ AVCodecContext
• codec:编解码器的AVCodec,比如指向AVCodec ff_aac_latm_decoder
• width, height:图像的宽高(只针对视频)
• pix_fmt:像素格式(只针对视频)
• sample_rate:采样率(只针对音频)
• channels:声道数(只针对音频)
• sample_fmt:采样格式(只针对音频)
◼ AVCodec
• name:编解码器名称
• type:编解码器类型
• id:编解码器ID
• 一些编解码的接口函数,比如int (*decode)()
◼AVPacket
• pts:显示时间戳
• dts:解码时间戳
• data:压缩编码数据
• size:压缩编码数据大小
• pos:数据的偏移地址
• stream_index:所属的AVStream
◼ AVFrame
• data:解码后的图像像素数据(音频采样数据)
• linesize:对视频来说是图像中一行像素的大小;对音频来说是整个音频帧的大小
• width, height:图像的宽高(只针对视频)
• key_frame:是否为关键帧(只针对视频) 。
• pict_type:帧类型(只针对视频) 。例如I, P, B
• sample_rate:音频采样率(只针对音频)
• nb_samples:音频每通道采样数(只针对音频)
• pts:显示时间戳
4.3 FFmpeg内存模型
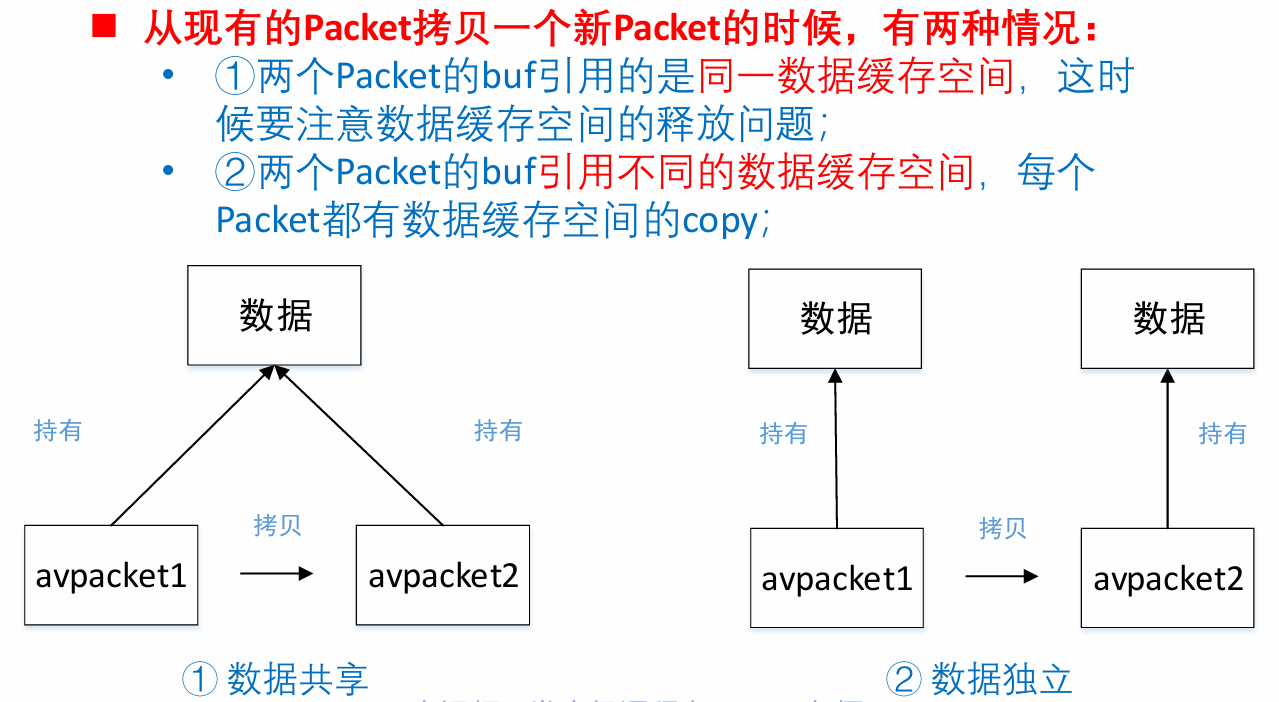
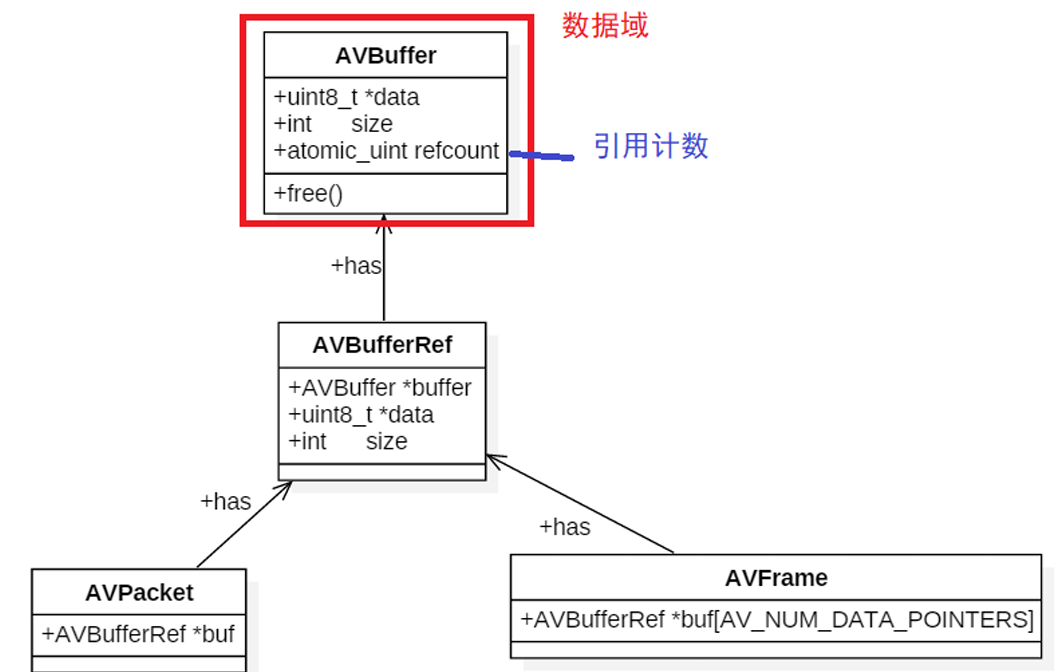
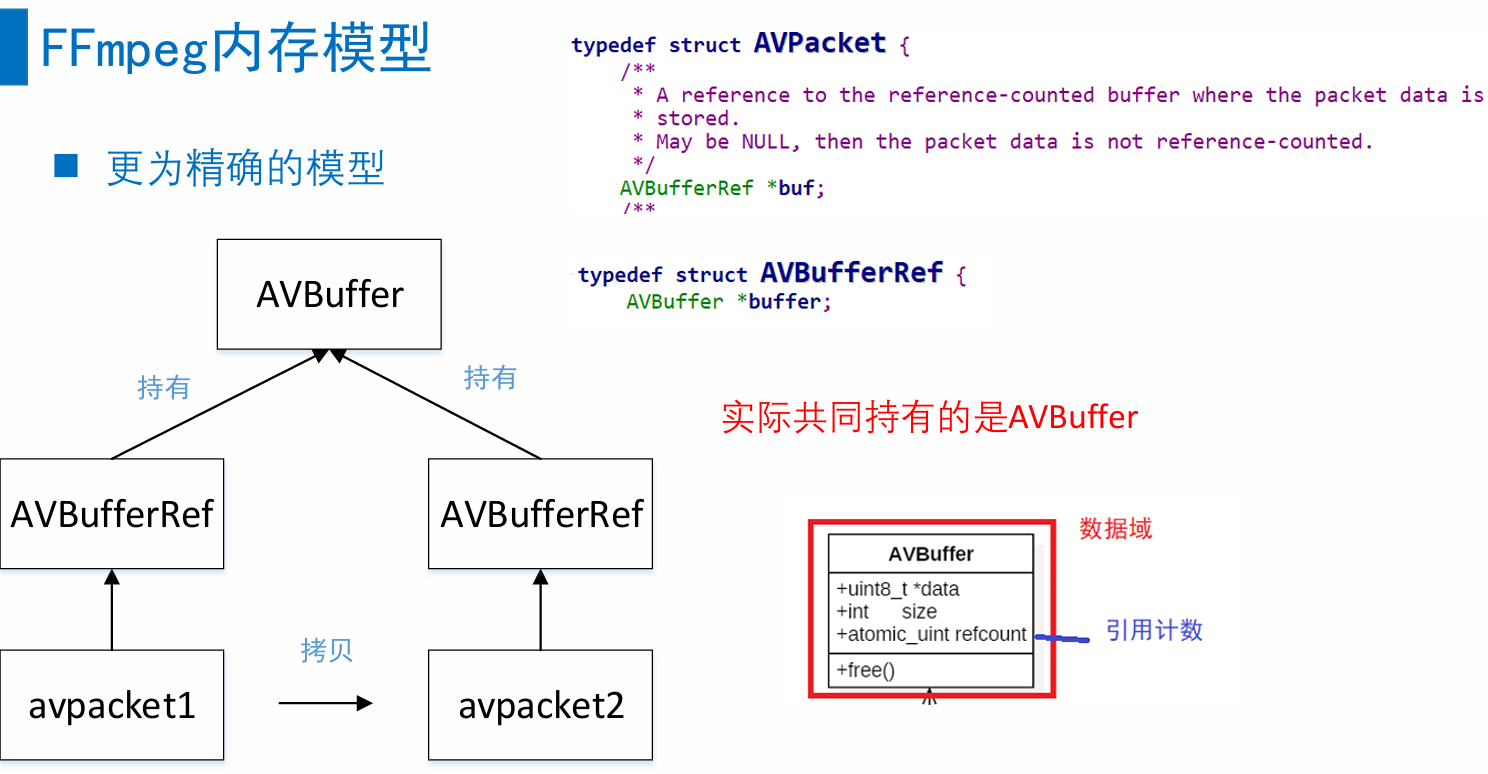
◼ 对于多个AVPacket共享同一个缓存空间,FFmpeg使用的引用计数的机制(reference-count):
◼ 初始化引用计数为0,只有真正分配AVBuffer的时候,引用计数初始化为1;
◼ 当有新的Packet引用共享的缓存空间时,就将引用计数+1;
◼ 当释放了引用共享空间的Packet,就将引用计数-1;引用计数为0时,就释放掉引用的缓存空间AVBuffer。
◼ AVFrame也是采用同样的机制。

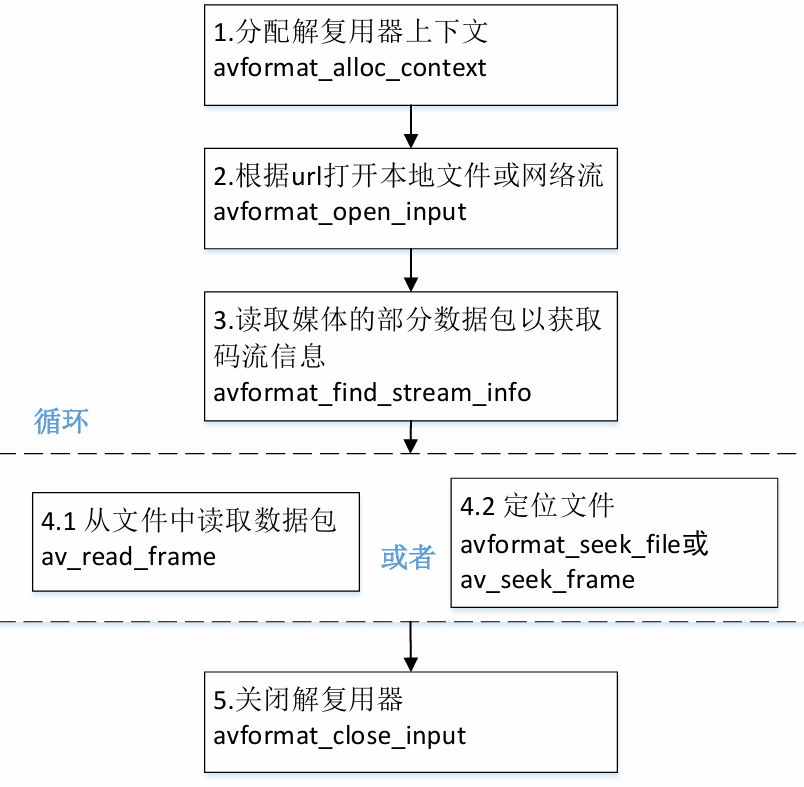
4.4ffmpeg解封装
封装格式相关函数
◼ avformat_alloc_context();负责申请一个AVFormatContext结构的内存,并进行简单初始化
◼ avformat_free_context();释放该结构里的所有东西以及该结构本身
◼ avformat_close_input();关闭解复用器。关闭后就不再需要使用avformat_free_context 进行释放。
◼ avformat_open_input();打开输入视频文件
◼ avformat_find_stream_info():获取音视频文件信息
◼ av_read_frame(); 读取音视频包
◼ avformat_seek_file(); 定位文件
◼ av_seek_frame():定位文件
解封装流程


AAC ADTS格式分析
AAC⾳频格式:Advanced Audio Coding(⾼级⾳频解码),是⼀种由MPEG-4标准定义的有损⾳频压缩格式,由Fraunhofer发展,Dolby, Sony和AT&T是主要的贡献者。
ADIF:Audio Data Interchange Format ⾳频数据交换格式。这种格式的特征是可以确定的找到这个⾳频数据的开始,不需进⾏在⾳频数据流中间开始的解码,即它的解码必须在明确定义的开始处进⾏。故这种格式常⽤在磁盘⽂件中。
ADTS的全称是Audio Data Transport Stream。是AAC⾳频的传输流格式。AAC⾳频格式在MPEG-2(ISO-13318-7 2003)中有定义。AAC后来⼜被采⽤到MPEG-4标准中。这种格式的特征是它是⼀个有同步字的⽐特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。
简单说,ADTS可以在任意帧解码,也就是说它每⼀帧都有头信息。ADIF只有⼀个统⼀的头,所以必须得到所有的数据后解码。
且这两种的header的格式也是不同的,⽬前⼀般编码后的和抽取出的都是ADTS格式的⾳频流。两者具体的组织结构如下所示:

有的时候当你编码AAC裸流的时候,会遇到写出来的AAC⽂件并不能在PC和⼿机上播放,很⼤的可能就是AAC⽂件的每⼀帧⾥缺少了ADTS头信息⽂件的包装拼接。
只需要加⼊头⽂件ADTS即可。⼀个AAC原始数据块⻓度是可变的,对原始帧加上ADTS头进⾏ADTS的封装,就形成了ADTS帧。
AAC⾳频⽂件的每⼀帧由ADTS Header和AAC Audio Data组成。结构体如下:
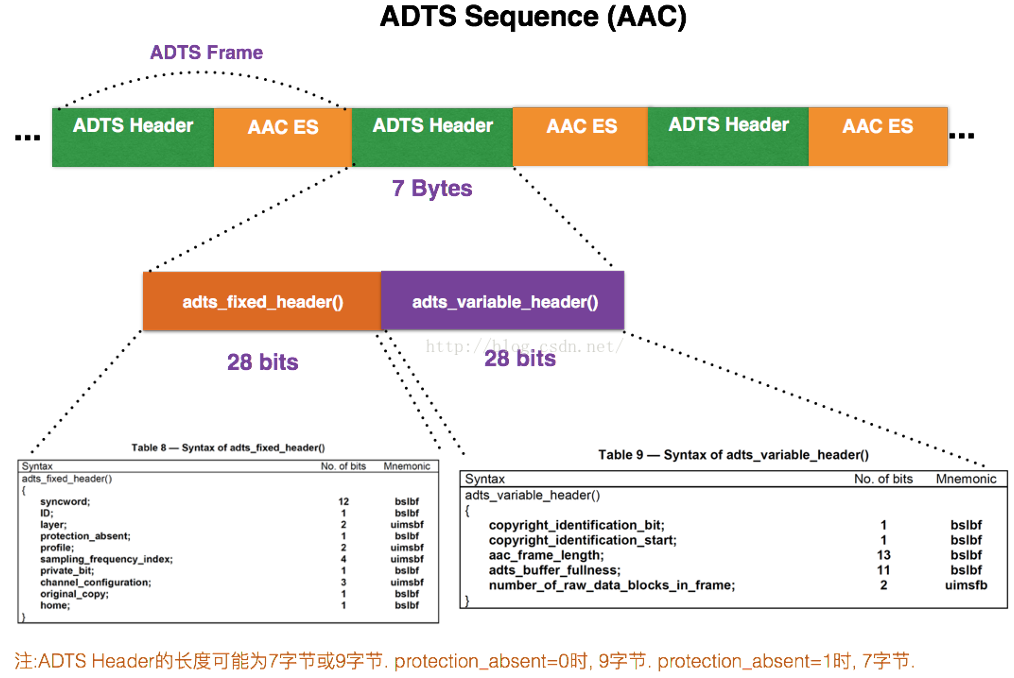
每⼀帧的ADTS的头⽂件都包含了⾳频的采样率,声道,帧⻓度等信息,这样解码器才能解析读取。
⼀般情况下ADTS的头信息都是7个字节,分为2部分:adts_fixed_header();adts_variable_header();
其⼀为固定头信息,紧接着是可变头信息。固定头信息中的数据每⼀帧都相同,⽽可变头信息则在帧与帧之间可变。
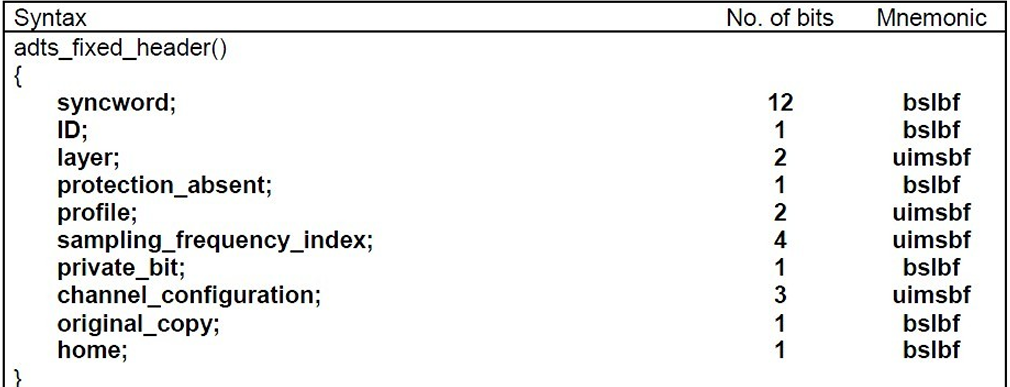
syncword :同步头 总是0xFFF, all bits must be 1,代表着⼀个ADTS帧的开始
ID:MPEG标识符,0标识MPEG-4,1标识MPEG-2
Layer:always: ‘00’
protection_absent:表示是否误码校验。Warning, set to 1 if there is no CRC and 0 if there is CRC
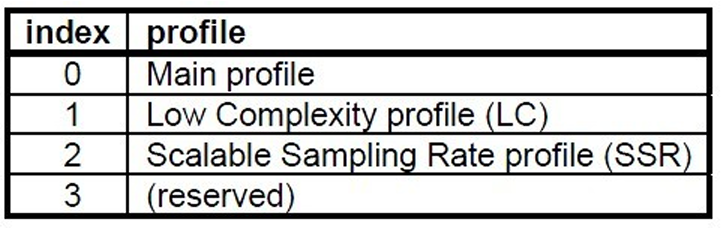
profile:表示使⽤哪个级别的AAC,如01 Low Complexity(LC)— AAC LC。有些芯⽚只⽀持AAC LC
在MPEG-2 AAC中定义了3种:
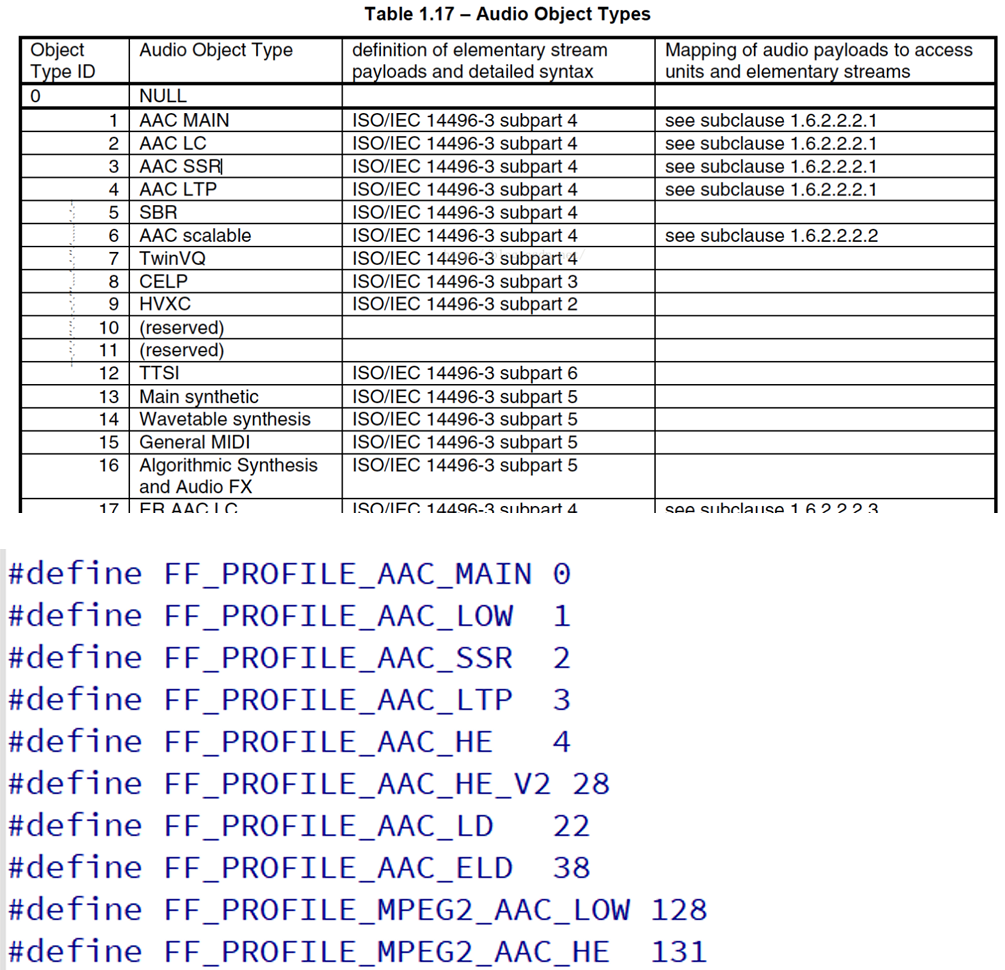
profile的值等于 Audio Object Type的值减1
profile = MPEG-4 Audio Object Type - 1
H264 NALU分析
流媒体编解码流程⼤致如下图所示:
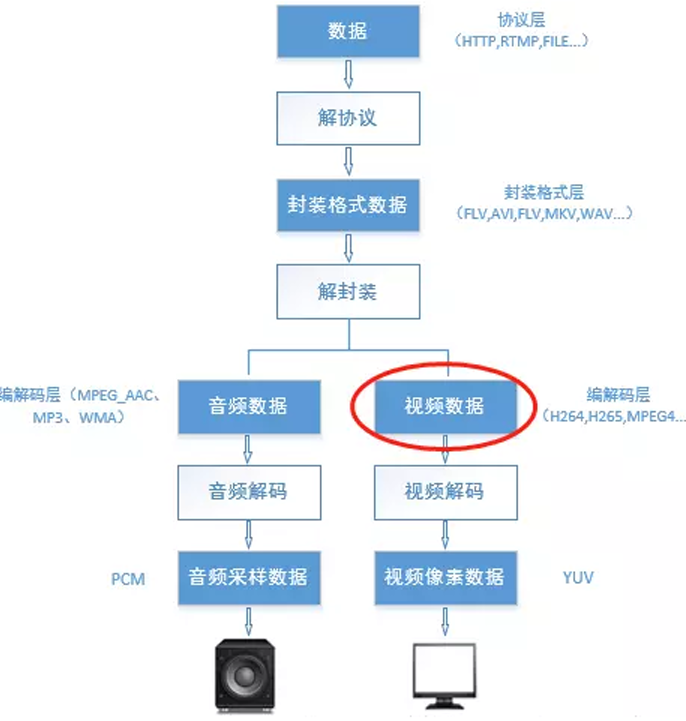
H264简介
H.264从1999年开始,到2003年形成草案,最后在2007年定稿有待核实。在ITU的标准⾥称为H.264,在MPEG的标准⾥是MPEG-4的⼀个组成部分–MPEG-4 Part 10,⼜叫Advanced Video Codec,因此常常称为MPEG-4 AVC或直接叫AVC。
H264 编解码解析
https://blog.csdn.net/u014253011/article/details/79967520
H264编码原理
在⾳视频传输过程中,视频⽂件的传输是⼀个极⼤的问题;⼀段分辨率为19201080,每个像素点为RGB占⽤3个字节,帧率是25的视频,对于传输带宽的要求是:19201080325/1024/1024=148.315MB/s,换成bps则意味着视频每秒带宽为1186.523Mbps,这样的速率对于⽹络存储是不可接受的。因此视频压缩和编码技术应运⽽⽣。
对于视频⽂件来说,视频由单张图⽚帧所组成,⽐如每秒25帧,但是图⽚帧的像素块之间存在相似性,因此视频帧图像可以进⾏图像压缩;H264采⽤了16*16的分块⼤⼩对,视频帧图像进⾏相似⽐较和压缩编码。
H264中的I帧、P帧和B帧
H264使⽤帧内压缩和帧间压缩的⽅式提⾼编码压缩率;H264采⽤了独特的I帧、P帧和B帧策略来实现,连续帧之间的压缩;


在视频编码序列中,GOP即Group of picture(图像组),指两个I帧之间的距离,Reference(参考周期)指两个P帧之间的距离。一个I帧所占用的字节数大于一个P帧,一个P帧所占用的字节数大于一个B帧。
所以在码率不变的前提下,GOP值越大,P、B帧的数量会越多,平均每个I、P、B帧所占用的字节数就越多,也就更容易获取较好的图像质量;Reference越大,B帧的数量越多,同理也更容易获得较好的图像质量。
需要说明的是,通过提高GOP值来提高图像质量是有限度的,在遇到场景切换的情况时,H.264编码器会自动强制插入一个I帧,此时实际的GOP值被缩短了。另一方面,在一个GOP中,P、B帧是由I帧预测得到的,当I帧的图像质量比较差时,会影响到一个GOP中后续P、B帧的图像质量,直到下一个GOP开始才有可能得以恢复,所以GOP值也不宜设置过大。同时,由于P、B帧的复杂度大于I帧,所以过多的P、B帧会影响编码效率,使编码效率降低。另外,过长的GOP还会影响Seek操作的响应速度,由于P、B帧是由前面的I或P帧预测得到的,所以Seek操作需要直接定位,解码某一个P或B帧时,需要先解码得到本GOP内的I帧及之前的N个预测帧才可以,GOP值越长,需要解码的预测帧就越多,seek响应的时间也越长。
H264编码结构解析
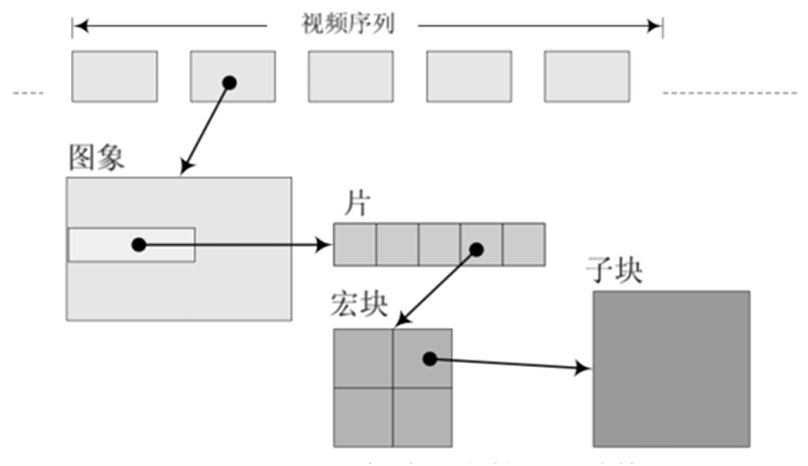
H264除了实现了对视频的压缩处理之外,为了⽅便⽹络传输,提供了对应的视频编码和分⽚策略;类似于⽹络数据封装成IP帧,在H264中将其称为组(GOP, group of pictures)、⽚(slice)、宏块(Macroblock)这些⼀起组成了H264的码流分层结构;
H264将其组织成为序列(GOP)、图⽚(pictrue)、⽚(Slice)、宏块(Macroblock)、⼦块(subblock)五个层次。GOP (图像组)主要⽤作形容⼀个IDR帧到下⼀个IDR帧之间的间隔了多少个帧。
H264将视频分为连续的帧进⾏传输,在连续的帧之间使⽤I帧、P帧和B帧。同时对于帧内⽽⾔,将图像分块为⽚、宏块和字块进⾏分⽚传输;通过这个过程实现对视频⽂件的压缩包装。
IDR(Instantaneous Decoding Refresh,即时解码刷新)
一个序列的第一个图像叫做IDR图像(立即刷新图像),IDR图像都是I帧图像。
I和IDR帧都使用帧内预测。I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。IDR就不允许这样。比如(解码的顺序):
· IDR1 P4 B2 B3 P7 B5 B6 I10 B8 B9 P13 B11 B12 P16 B14 B15 这里的B8可以跨过I10去参考P7
原始图像:IDR1 B2 B3 P4 B5 B6 P7 B8 B9 110
·IDR1 P4 B2 B3 P7 B5 B6 IDR8 P11 B9 B10 P14 B11 B12 这里的B9就只能参照IDR8和P11,不可以
参考IDR8前面的帧
其核心作用是,是为了解码的重同步,当解码器解码到IDR图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
下面是一个H264码流的举例(从码流的帧分析可以看出来B帧不能被当做参考帧)

NALU(Network Abstract Layer Unit)
NALU⾳视频编码在流媒体和⽹络领域占有重要地位;
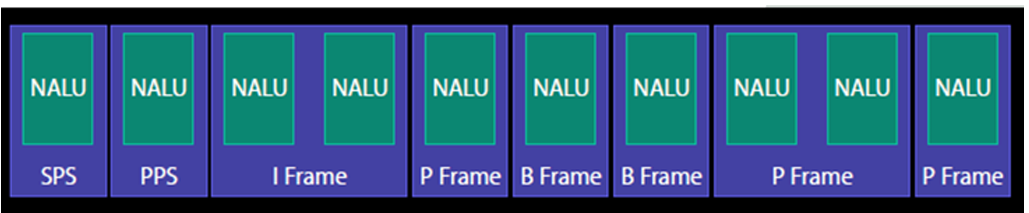
SPS:序列参数集,SPS中保存了一组编码视频序列(Codedvideo sequence)的全局参数。
PPS:图像参数集,对应的是一个序列中某一幅图像或者某几幅图像的参数。
I帧:帧内编码帧,可独立解码生成完整的图片。
P帧:前向预测编码帧,需要参考其前面的一个I或者B来生成一张完整的图片。
B帧:双向预测内插编码帧,则要参考其前一个I或者P帧及其后面的一个P帧来生成一张完整的图片。
发I帧之前,至少要发一次SPS和PPS。
NALU结构
H.264原始码流(裸流)是由一个接一个NALU组成,它的功能分为两层,VCL(视频编码层)和NAL(网络提取层):
·VCL:包括核心压缩引擎和块,宏块和片的语法级别定义,设计目标是尽可能地独立于网络进行高效的编码;
·NAL:负责将VCL产生的比特字符串适配到各种各样的网络和多元环境中,覆盖了所有片级以上的语法级别
在VCL进行数据传输或存储之前,这些编码的VCL数据,被映射或封装进NAL单元。(NALU)
一个NALU=一组对应于视频编码的NALU头部信息+一个原始字节序列负荷(RBSP,RaW Byte Sequence Payload).
NALU结构单元的主体结构如下所示;一个原始的H.264NALU单元通常由[StartCode][NALU Header][NALUPayload]三部分组成,其中Start Code用于标示这是一个NALU单元的开始,必须是”00000001"或"000001”,除此之外基本相当于一个NALheader +RBSP;

解析NALU
每个NAL单元是⼀个⼀定语法元素的可变⻓字节字符串,包括包含⼀个字节的头信息(⽤来表示数据类型),以及若⼲整数字节的负荷数据。

H.264标准指出,当数据流是储存在介质上时,在每个NALU前添加起始码:0x000001或0x00000001,用来指示一个NALU的起始和终止位置:
·在这样的机制下,在码流中检测起始码,作为一个NALU得起始标识,当检测到下一个起始码时,当前NALU结束。
·3字节的0x000001只有一种场合下使用,就是一个完整的帧被编为多个slice(片)的时候,包含这些slice的NALU使用3字节起始码。其余场合都是4字节0x00000001的。
H264 annexb模式
H264有两种封装
·一种是annexb模式,传统模式,有startcode,SPS和PPS是在ES中
·一种是mp4模式,一般mp4mkv都是mp4模式,没有startcode,SPS和PPS以及其它信息被封装在container中,每一个frame前面4个字节是这个frame的长度
很多解码器只支持annexb这种模式,因此需要将mp4做转换:在ffmpeg中用h264_mp4toannexb_filter可以做转换。实现:
const AVBitStreamFilter *bsfilter = av_bsf_get_by_name("h264_mp4toannexb");
AVBSFContext *bsf_ctx = NULL;
// 2 初始化过滤器上下⽂
av_bsf_alloc(bsfilter, &bsf_ctx); //AVBSFContext;
// 3 添加解码器属性
avcodec_parameters_copy(bsf_ctx->par_in, ifmt_ctx->streams[videoindex]->cod ecpar);
av_bsf_init(bsf_ctx);
FLV格式分析
FLV介绍
FLV(Flash Video)是Adobe公司推出的⼀种流媒体格式,由于其封装后的⾳视频⽂件体积⼩、封装简单等特点,⾮常适合于互联⽹上使⽤。⽬前主流的视频⽹站基本都⽀持FLV。采⽤FLV格式封装的⽂件后缀为.flv。
FLV封装格式是由⼀个⽂件头(file header)和 ⽂件体(file Body)组成。其中,FLV body由⼀对对的(Previous Tag Size字段 + tag)组成。Previous Tag Size字段 排列在Tag之前,占⽤4个字节。Previous Tag Size记录了前⾯⼀个Tag的⼤⼩,⽤于逆向读取处理。FLV header后的第⼀个Pervious Tag Size的值为0。
Tag⼀般可以分为3种类型:脚本(帧)数据类型、⾳频数据类型、视频数据。FLV数据以⼤端序进⾏存储,在解析时需要注意。⼀个标准FLV⽂件结构如下图:
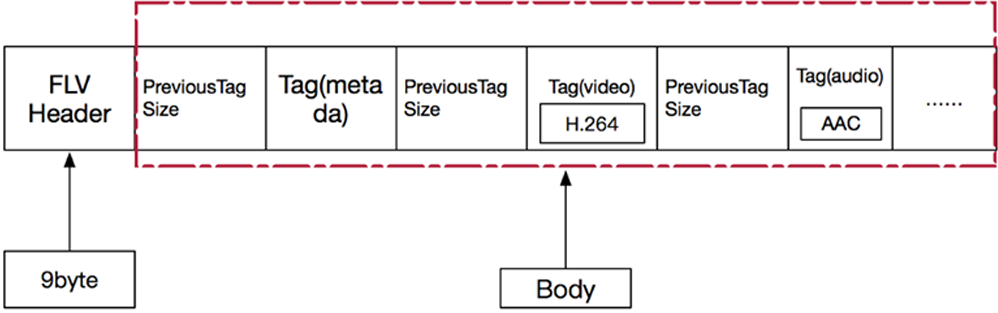
FLV⽂件的详细内容结构如下图:
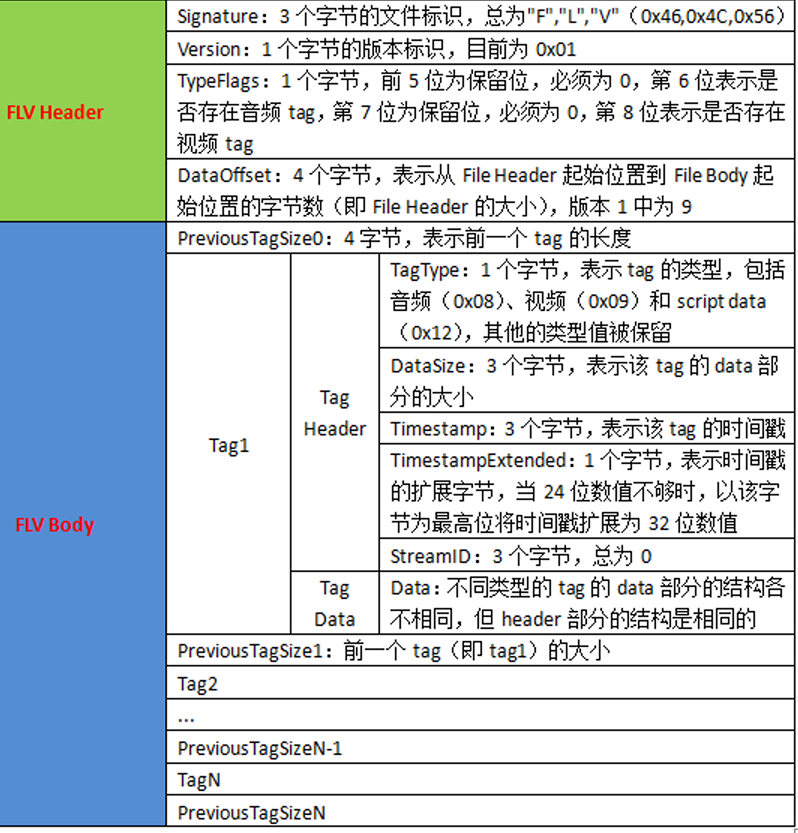
FLV解析框架
FLV header
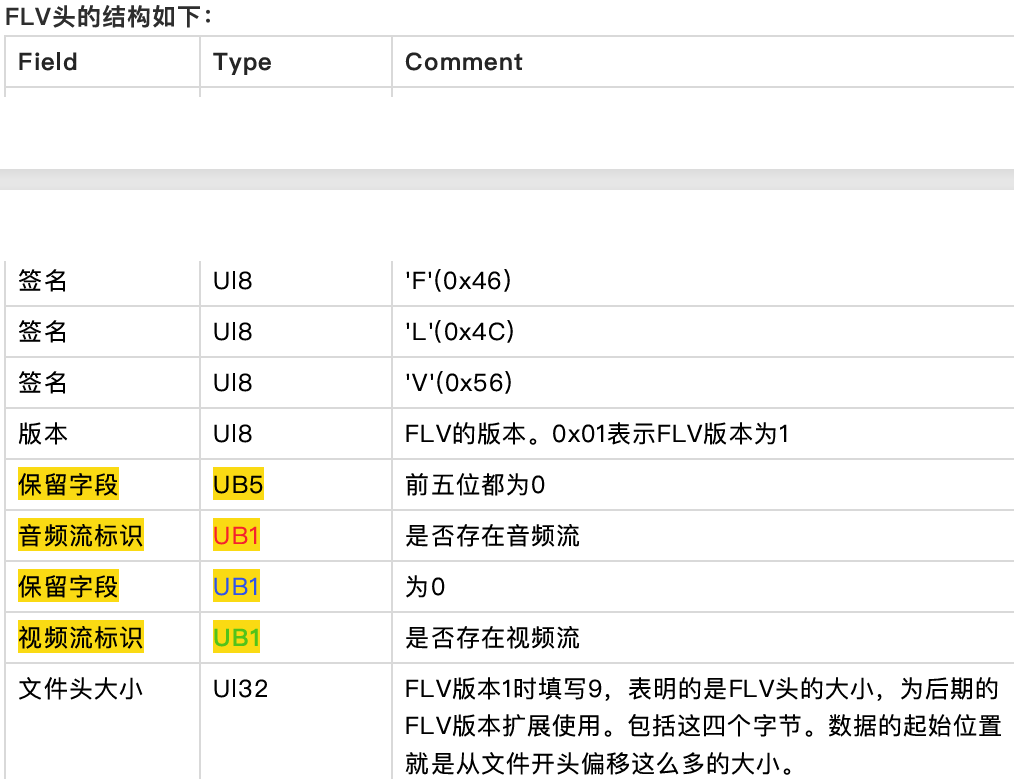
注:在下⾯的数据type中,UI表示⽆符号整形,后⾯跟的数字表示其⻓度是多少位。⽐如UI8,表示⽆符号整形,⻓度⼀个字节。UI24是三个字节,UI[8*n]表示多个字节。UB表示位域,UB5表示⼀个字节的5位。可以参考c中的位域结构体。
FLV头占9个字节,⽤来标识⽂件为FLV类型,以及后续存储的⾳视频流。⼀个FLV⽂件,每种类型的tag都属于⼀个流,也就是⼀个flv⽂件最多只有⼀个⾳频流,⼀个视频流,不存在多个独⽴的⾳视频流在⼀个⽂件的情况。
FLV头的结构如下:
FLV Body
FLV Header之后,就是FLV File Body。FLV File Body是由⼀连串的back-pointers + tags构成。
Back-pointer表示Previous Tag Size(前⼀个tag的字节数据⻓度),占4个字节。
FLV Tag
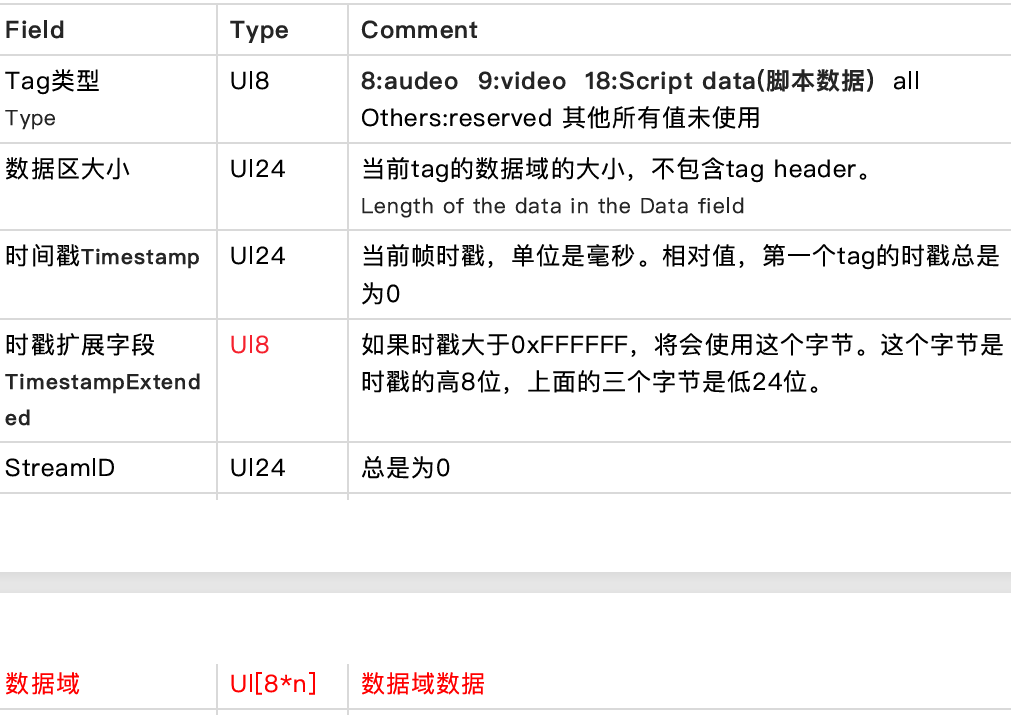
每⼀个Tag也是由两部分组成:tag header和tag data。Tag Header⾥存放的是当前tag的类型、数据区(tag data)的⻓度等信息。
tag header
tag header⼀般占11个字节的内存空间。FLV tag结构如下:
注意:
- flv⽂件中Timestamp和TimestampExtended拼出来的是dts。也就是解码时间。Timestamp和TimestampExtended拼出来dts单位为ms。(如果不存在B帧,当然dts等于pts)
- CompositionTime 表示PTS相对于DTS的偏移值, 在每个视频tag的第14~16字节。显示时间(pts) = 解码时间(tag的第5~8字节) + CompositionTime
CompositionTime的单位也是ms
Script Tag Data结构(脚本类型、帧类型)
Script data脚本数据就是描述视频或⾳频的信息的数据,如宽度、⾼度、时间等等,⼀个⽂件中通常只有⼀个元数据,⾳频tag和视频tag就是⾳视频信息了,采样、声道、频率,编码等信息。
该类型Tag⼜被称为MetaData Tag,存放⼀些关于FLV视频和⾳频的元信息,⽐如:duration、width、height等。通常该类型Tag会作为FLV⽂件的第⼀个tag,并且只有⼀个,跟在File Header后。该类型Tag DaTa的结构如下所示(source.200kbps.768x320.flv⽂件为例):

第⼀个AMF包: 第1个字节表示AMF包类型,⼀般总是0x02,表示字符串。第2-3个字节为UI16类型值,标识字符串的⻓度,⼀般总是0x000A(“ onMetaData”⻓度)。后⾯字节为具体的字符串,⼀般总为“ onMetaData”(6F,6E,4D,65,74,61,44,61,74,61)。
第⼆个AMF包: 第1个字节表示AMF包类型,⼀般总是0x08,表示数组。第2-5个字节为UI32类型值,表示数组元素的个数。后⾯即为各数组元素的封装,数组元素为元素名称和值组成的对。常⻅的数组元素如下表所示。
其余略
5 ffmpeg2
⾳频解码
⾳频解码过程

FFmpeg流程
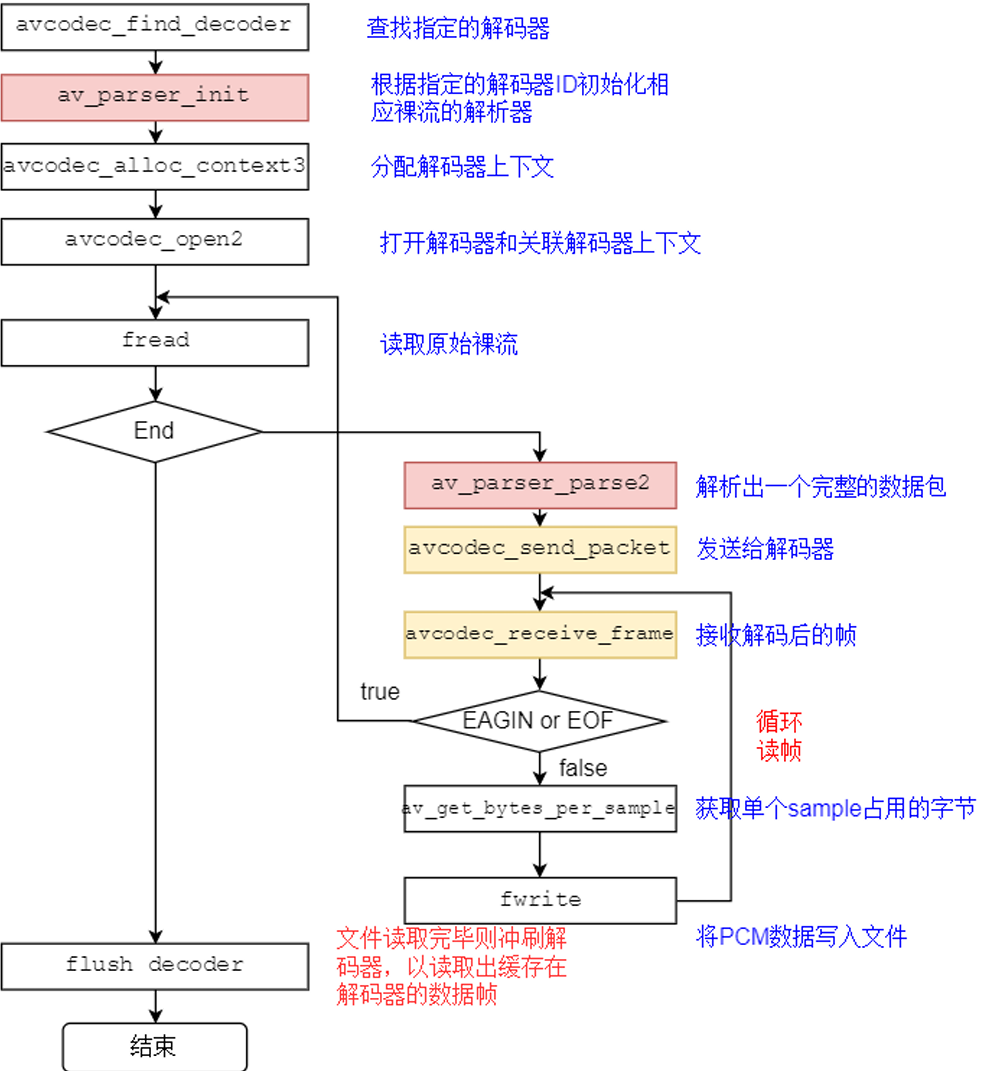
关键函数说明:
avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。
av_parser_init:初始化AVCodecParserContext。
avcodec_alloc_context3:为AVCodecContext分配内存。
avcodec_open2:打开解码器。
av_parser_parse2:解析获得⼀个Packet。
avcodec_send_packet:将AVPacket压缩数据给解码器。
avcodec_receive_frame:获取到解码后的AVFrame数据。
av_get_bytes_per_sample: 获取每个sample中的字节数。
关键数据结构说明:
AVCodecParser:⽤于解析输⼊的数据流并把它分成⼀帧⼀帧的压缩编码数据。⽐较形象的说法就是把⻓⻓的⼀段连续的数据“切割”成⼀段段的数据。
⽐如AAC aac_parser

avcodec编解码API介绍
avcodec_send_packet、avcodec_receive_frame的API是FFmpeg3版本加⼊的。
以下内容摘译⾃⽂档说明
FFmpeg提供了两组函数,分别⽤于编码和解码:
解码:avcodec_send_packet()、avcodec_receive_frame()。
解码:avcodec_send_frame()、avcodec_receive_packet()。
API的设计与编解码的流程⾮常贴切。
建议的使⽤流程如下:
- 像以前⼀样设置并打开AVCodecContext。
- 输⼊有效的数据:
解码:调⽤avcodec_send_packet()给解码器传⼊包含原始的压缩数据的AVPacket对象。
编码:调⽤ avcodec_send_frame()给编码器传⼊包含解压数据的AVFrame对象。
两种情况下推荐AVPacket和AVFrame都使⽤refcounted(引⽤计数)的模式,否则libavcodec可能不得不对输⼊的数据进⾏拷⻉。 - 在⼀个循环体内去接收codec的输出,即周期性地调⽤avcodec_receive_*()来接收codec输出的数据:
解码:调⽤avcodec_receive_frame(),如果成功会返回⼀个包含未压缩数据的AVFrame。
编码:调⽤avcodec_receive_packet(),如果成功会返回⼀个包含压缩数据的AVPacket。
反复地调⽤avcodec_receive_packet()直到返回 AVERROR(EAGAIN)或其他错误。返回AVERROR(EAGAIN)错误表示codec需要新的输⼊来输出更多的数据。对于每个输⼊的packet或frame,codec⼀般会输出⼀个frame或packet,但是也有可能输出0个或者多于1个。 - 流处理结束的时候需要flush(冲刷) codec。因为codec可能在内部缓冲多个frame或packet,出于性能或其他必要的情况(如考虑B帧的情况)。 处理流程如下:
调⽤avcodec_send_()传⼊的AVFrame或AVPacket指针设置为NULL。 这将进⼊draining mode(排⽔模式)。
反复地调⽤avcodec_receive_()直到返回AVERROR_EOF,该⽅法在draining mode时不会返回AVERROR(EAGAIN)的错误,除⾮你没有进⼊draining mode。
当重新开启codec时,需要先调⽤ avcodec_flush_buffers()来重置codec。
说明: - 编码或者解码刚开始的时候,codec可能接收了多个输⼊的frame或packet后还没有输出数据,直到内部的buffer被填充满。上⾯的使⽤流程可以处理这种情况。
- 理论上,只有在输出数据没有被完全接收的情况调⽤avcodec_send_()的时候才可能会发⽣AVERROR(EAGAIN)的错误。你可以依赖这个机制来实现区别于上⾯建议流程的处理⽅式,⽐如每次循环都调⽤avcodec_send_(),在出现AVERROR(EAGAIN)错误的时候再去调⽤avcodec_receive_*()。
- 并不是所有的codec都遵循⼀个严格、可预测的数据处理流程,唯⼀可以保证的是 “调⽤
avcodec_send_()/avcodec_receive_()返回AVERROR(EAGAIN)的时候去
avcodec_receive_()/avcodec_send_()会成功,否则不应该返回AVERROR(EAGAIN)的错误。
⼀般来说,任何codec都不允许⽆限制地缓存输⼊或者输出。 - 在同⼀个AVCodecContext上混合使⽤新旧API是不允许的,这将导致未定义的⾏为。
视频解码
视频解码对于FFmpeg⽽⾔,流程基本上和⾳频解码⼀致。
对于⾳频的resample和视频的rescale在⾳视频合成输出再做讲解。
视频解码过程
视频解码过程如下图所示:⼀般解出来的是420p

FFmpeg流程
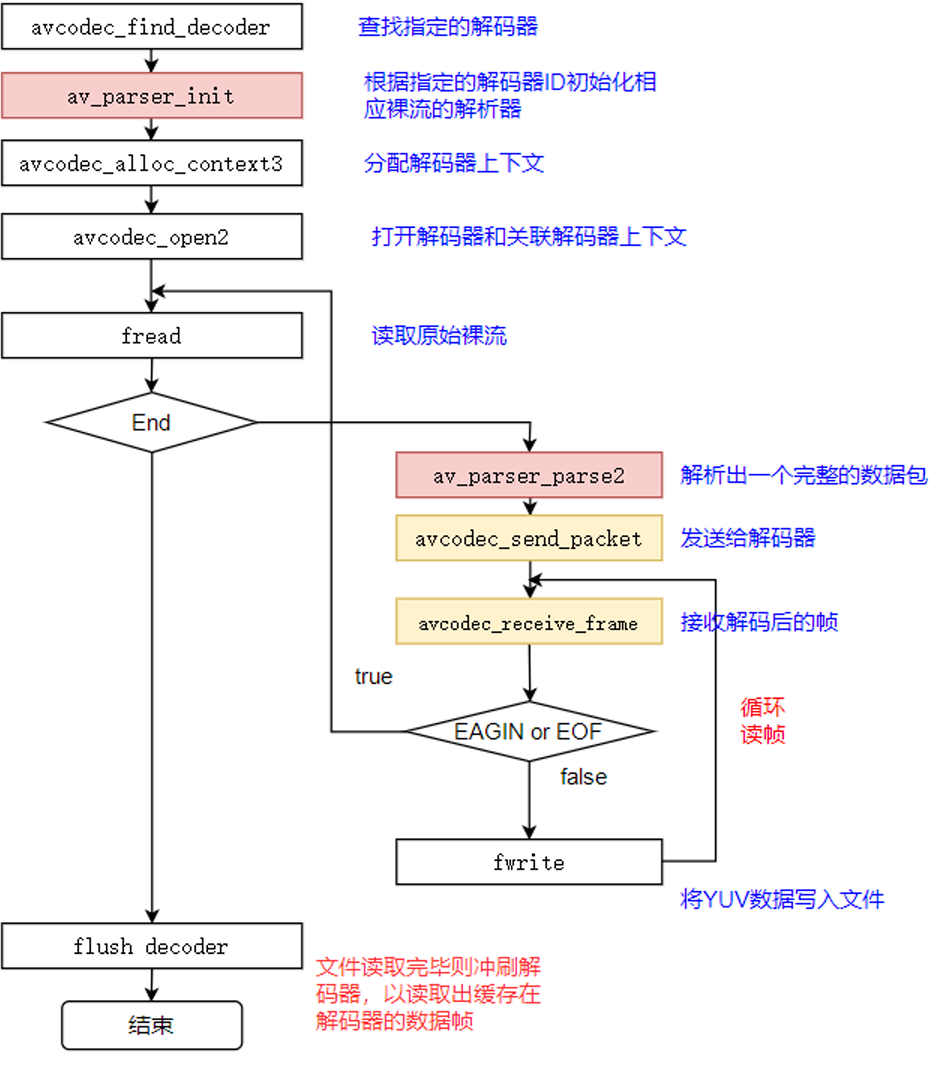
关键函数
关键函数说明:
avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。
av_parser_init:初始化AVCodecParserContext。
avcodec_alloc_context3:为AVCodecContext分配内存。
avcodec_open2:打开解码器。
av_parser_parse2:解析获得⼀个Packet。
avcodec_send_packet:将AVPacket压缩数据给解码器。
avcodec_receive_frame:获取到解码后的AVFrame数据。
av_get_bytes_per_sample: 获取每个sample中的字节数。
MP4格式封装解封装分析(略)
AVIO内存输入模式(略)
⾳频处理基本概念及⾳频重采样
官⽅参考⽂档:https://ffmpeg.org/doxygen/trunk/group__lswr.html
什么是重采样
所谓的重采样,就是改变⾳频的采样率、sample format、声道数等参数,使之按照我们期望的参数输出。
为什么要重采样?
当然是原有的⾳频参数不满⾜我们的需求,⽐如在FFmpeg解码⾳频的时候,不同的⾳源有不同的格式,采样率等,在解码后的数据中的这些参数也会不⼀致(最新FFmpeg 解码⾳频后,⾳频格式为AV_SAMPLE_FMT_FLTP,这个参数应该是⼀致的),如果我们接下来需要使⽤解码后的⾳频数据做其他操作,⽽这些参数的不⼀致导致会有很多额外⼯作,此时直接对其进⾏重采样,获取我们制定的⾳频参数,这样就会⽅便很多。
再⽐如在将⾳频进⾏SDL播放时候,因为当前的SDL2.0不⽀持planar格式,也不⽀持浮点型的,⽽最新的FFMPEG 16年会将⾳频解码为AV_SAMPLE_FMT_FLTP格式,因此此时就需要我们对其重采样,使之可以在SDL2.0上进⾏播放。
可调节的参数
通过重采样,我们可以对:
- sample rate(采样率)
- sample format(采样格式)
- channel layout(通道布局,可以通过此参数获取声道数
采样率
采样设备每秒抽取样本的次数
采样格式及量化精度(位宽)
每种⾳频格式有不同的量化精度(位宽),位数越多,表示值就越精确,声⾳表现⾃然就越精准。
FFMpeg中⾳频格式有以下⼏种,每种格式有其占⽤的字节数信息(libavutil/samplefmt.h):
enum AVSampleFormat {
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_S64, ///< signed 64 bits
AV_SAMPLE_FMT_S64P, /// < signed 64 bits, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
};
分⽚(plane)和打包(packed)
以双声道为例,带P(plane)的数据格式在存储时,其左声道和右声道的数据是分开存储的,左声道的
数据存储在data[0],右声道的数据存储在data[1],每个声道的所占⽤的字节数为linesize[0]和linesize[1];
不带P(packed)的⾳频数据在存储时,是按照LRLRLR…的格式交替存储在data[0]中,linesize[0]表示总的数据量。
声道分布(channel_layout)
声道分布在FFmpeg\libavutil\channel_layout.h中有定义,⼀般来说⽤的⽐较多的是AV_CH_LAYOUT_STEREO(双声道)和AV_CH_LAYOUT_SURROUND(三声道),这两者的定义如下:
#define AV_CH_LAYOUT_STEREO (AV_CH_FRONT_LEFT|AV_CH_FRONT_RIGHT)
#define AV_CH_LAYOUT_SURROUND (AV_CH_LAYOUT_STEREO|AV_CH_FRONT_CENTER)
⾳频帧的数据量计算
⼀帧⾳频的数据量(字节)=channel数 * nb_samples样本数 * 每个样本占⽤的字节数
如果该⾳频帧是FLTP格式的PCM数据,包含1024个样本,双声道,那么该⾳频帧包含的⾳频数据量是
210244=8192字节。
AV_SAMPLE_FMT_DBL : 210248 = 16384
⾳频播放时间计算
以采样率44100Hz来计算,每秒44100个sample,⽽正常⼀帧为1024个sample,可知每帧播放时间/1024=1000ms/44100,得到每帧播放时间=10241000/44100=23.2ms (更精确的是23.21995)
⼀帧播放时间(毫秒) = nb_samples样本数 1000/采样率 =
(1)10241000/44100=23.21995464852608ms ->约等于 23.2ms,精度损失了
0.011995464852608ms,如果累计10万帧,误差>1199毫秒,如果有视频⼀起的就会有⾳视频同步的问
题。 如果按着23.2去计算pts(0 23.2 46.4 )就会有累积误差。
(2)10241000/48000=21.33333333333333ms
FFmpeg重采样API
分配⾳频重采样的上下⽂
struct SwrContext *swr_alloc(void); 当设置好相关的参数后,使⽤此函数来初始化SwrContext结构体
int swr_init(struct SwrContext *s);
分配SwrContext并设置/重置常⽤的参数。
struct SwrContext *swr_alloc_set_opts(struct SwrContext *s, // ⾳频重采样上下⽂
int64_t out_ch_layout, // 输出的layout, 如:5.1声道
enum AVSampleFormat out_sample_fmt, // 输出的采样格式。Float, S16,⼀般选⽤是s16 绝⼤部分声卡⽀持
int out_sample_rate, //输出采样率
int64_t in_ch_layout, // 输⼊的layout
enum AVSampleFormat in_sample_fmt, // 输⼊的采样格式
int in_sample_rate, // 输⼊的采样率
int log_offset, // ⽇志相关,不⽤管先,直接为0
void *log_ctx // ⽇志相关,不⽤管先,直接为NULL
);
将输⼊的⾳频按照定义的参数进⾏转换并输出
int swr_convert(struct SwrContext *s, // ⾳频重采样的上下⽂
uint8_t **out, // 输出的指针。传递的输出的数组
int out_count, //输出的样本数量,不是字节数。单通道的样本数量。
const uint8_t **in , //输⼊的数组,AVFrame解码出来的DATA
int in_count // 输⼊的单通道的样本数量。
);
返回值 <= out_count
in和in_count可以设置为0,以最后刷新最后⼏个样本。
释放掉SwrContext结构体并将此结构体置为NULL;
void swr_free(struct SwrContext **s);
⾳频重采样,采样格式转换和混合库。
与lswr的交互是通过SwrContext完成的,SwrContext被分配给swr_alloc()或swr_alloc_set_opts()。 它是不透明的,所以所有参数必须使⽤AVOptions API设置。
为了使⽤lswr,你需要做的第⼀件事就是分配SwrContext。 这可以使⽤swr_alloc()或swr_alloc_set_opts()来完成。 如果您使⽤前者,则必须通过AVOptions API设置选项。 后⼀个函数提供了相同的功能,但它允许您在同⼀语句中设置⼀些常⽤选项。
例如,以下代码将设置从平⾯浮动样本格式到交织的带符号16位整数的转换,从48kHz到44.1kHz的下采样,以及从5.1声道到⽴体声的下混合(使⽤默认混合矩阵)。 这是使⽤swr_alloc()函数。同样的⼯作也可以使⽤swr_alloc_set_opts():⼀旦设置了所有值,它必须⽤swr_init()初始化。 如果需要更改转换参数,可以使⽤
AVOptions来更改参数,如上⾯第⼀个例⼦所述; 或者使⽤swr_alloc_set_opts(),但是第⼀个参数是分配的上下⽂。 您必须再次调⽤swr_init()。
SwrContext *swr = swr_alloc();
av_opt_set_channel_layout(swr, “in_channel_layout”, AV_CH_LAYOUT_POINT1, 0);
av_opt_set_channel_layout(swr, “out_channel_layout”, AV_CH_LAYOUT_STEREO, 0);
av_opt_set_int(swr, “in_sample_rate”, 48000, 0);
av_opt_set_int(swr, “out_sample_rate”, 44100, 0) ;
av_opt_set_sample_fmt(swr, “in_sample_fmt”, AV_SAMPLE_FMT_FLTP, 0 );
av_opt_set_sample_fmt(swr, “out_sample_fmt”, AV_SAMPLE_FMT_S16, 0);
SwrContext *swr = swr_alloc_set_opts(NULL, // we’re allocating a new context
AV_CH_LAYOUT_STEREO, // out_ch_layout
AV_SAMPLE_FMT_S16, // out_sample_fmt
44100, // out_sample_rate
AV_CH_LAYOUT_5POINT1, // in_ch_layout
AV_SAMPLE_FMT_FLTP, // in_sample_fmt
48000, // in_sample_rate
0, // log_offset
NULL); // log_ctx
转换本身通过重复调⽤swr_convert()来完成。 请注意,如果提供的输出空间不⾜或采样率转换完成后,样本可能会在swr中缓冲,这需要“未来”样本。 可以随时通过使⽤swr_convert()(in_count可以设置为0)来检索不需要将来输⼊的样本。 在转换结束时,可以通过调⽤具有NULL in和in incount的swr_convert()来刷新重采样缓冲区。
⾳频重采样⼯程范例
FFMpeg⾃带的resample例⼦:FFmpeg\doc\examples\resampling_audio.c,这⾥把最核⼼的
resample代码贴⼀下,在⼯程中使⽤时,注意设置的各种参数,给定的输⼊数据都不能错。